↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
The field of Large Language Models (LLMs) has seen significant progress, but this progress is heavily concentrated on English, leaving a notable gap for other languages, including German. Existing German LLMs often rely on multilingual training or fine-tuning from English models, leading to performance issues. There is a lack of transparency regarding the German-language data used to train these models.
This paper introduces LLäMmlein, two German-only decoder-only LLMs, built completely from scratch. The researchers openly released the models, their training data, and code to foster collaboration and reproducibility within the German NLP community. They achieved competitive performance on various benchmarks, providing insights into resource allocation for future model development and highlighting the effectiveness of training German-specific LLMs from scratch.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the scarcity of high-quality German language models. By openly releasing two new German-only LLMs, along with their training data and code, it fosters collaboration and reproducibility in German NLP research. The findings about training efficiency and performance scaling offer valuable insights for future model development and resource allocation. This directly contributes to reducing the language gap in the LLM field and accelerating progress in German NLP.
Visual Insights#

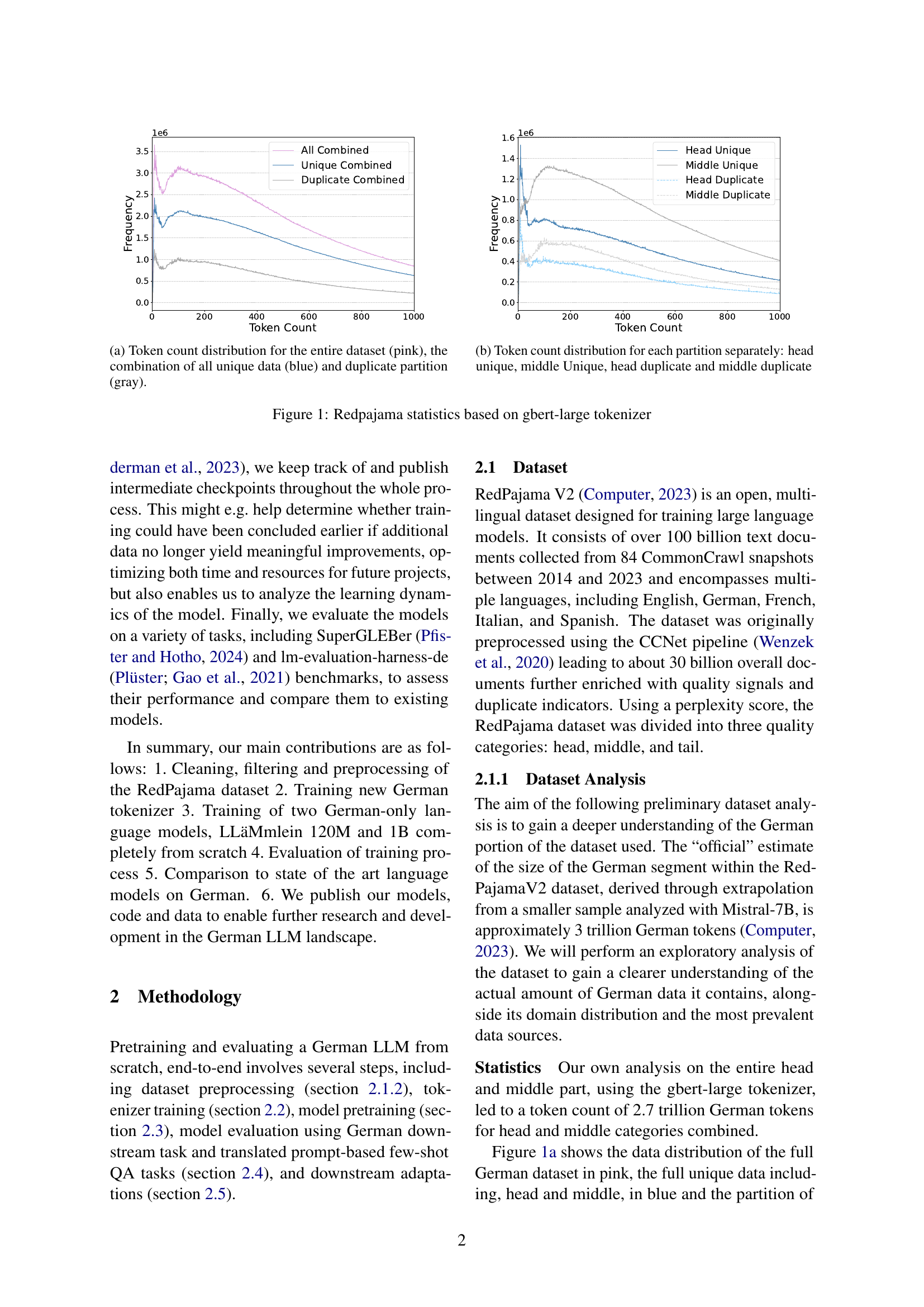
🔼 This figure shows the distribution of token counts in the RedPajama dataset. The pink curve represents the distribution for the entire dataset, combining unique and duplicate entries. The blue curve shows the distribution if only the unique data points are considered. Finally, the gray curve shows the distribution of only the duplicate data points.
read the caption
(a) Token count distribution for the entire dataset (pink), the combination of all unique data (blue) and duplicate partition (gray).
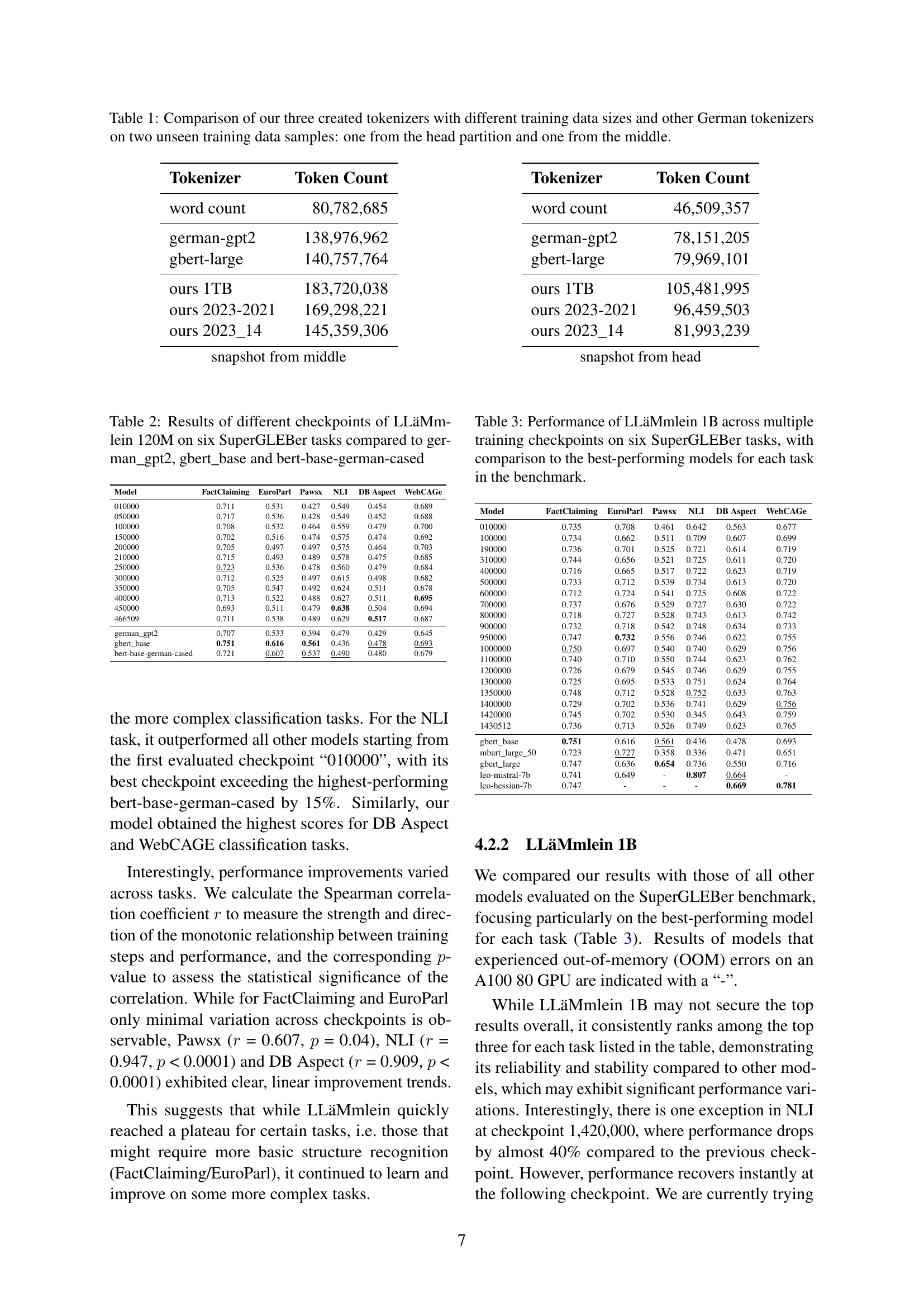
| Tokenizer | Token Count |
|---|---|
| word count | 80,782,685 |
| german-gpt2 | 138,976,962 |
| gbert-large | 140,757,764 |
| ours 1TB | 183,720,038 |
| ours 2023-2021 | 169,298,221 |
| ours 2023_14 | 145,359,306 |
🔼 This table compares the performance of four different German tokenizers: two existing tokenizers (german-gpt2 and gbert-large) and two newly trained tokenizers created by the authors of the paper, each trained on different amounts of data (1TB, 2023-2021, and 2023_14). The comparison is based on the token counts generated by each tokenizer when applied to two unseen samples from the RedPajama dataset (one from the ‘head’ partition and one from the ‘middle’ partition). The table shows how the choice of tokenizer and the amount of training data affect the token count, offering insights into the efficiency and performance of each.
read the caption
Table 1: Comparison of our three created tokenizers with different training data sizes and other German tokenizers on two unseen training data samples: one from the head partition and one from the middle.
In-depth insights#
German LLM Gap#
The German LLM gap highlights the significant disparity between the resources and advancements in English-language LLMs versus those in German. English enjoys a dominant position, fueled by substantial investment from large tech companies and research institutions, leading to frequent model updates and readily available datasets. Conversely, German LLM development lags behind, hampered by a lack of comparable resources and open-source data. This disparity affects the quality and availability of German LLMs, often resulting in models that are smaller, less sophisticated, and trained on data that may not fully reflect the nuances of the German language. This gap is not only a technical challenge but also has implications for research, limiting access to high-quality language models for German-focused studies. Addressing the German LLM gap requires concerted efforts towards funding, data collection, and open-source contributions to foster innovation and create a more level playing field in the LLM landscape.
Scratch Training#
Training language models from scratch offers several key advantages. It promotes transparency and reproducibility, allowing researchers to fully understand the model’s architecture and training process. This contrasts with using pre-trained models where the data and training specifics may be opaque. Scratch training enables fine-grained control over the model’s development, facilitating experimentation with different architectures, training datasets, and hyperparameters to optimize for specific languages or tasks. However, scratch training requires significant computational resources and expertise, demanding substantial time and energy investments compared to fine-tuning pre-trained models. Despite the challenges, the rewards in terms of understanding and control justify the effort, especially when targeting languages under-represented in the existing LLM ecosystem. The resultant models provide a valuable benchmark for comparing against pre-trained models, highlighting the effectiveness of various training approaches and data preprocessing techniques.
Tokenizer Impact#
A tokenizer’s impact on a language model’s performance is multifaceted and significant. The choice of tokenizer directly influences the model’s vocabulary and ability to represent nuances in language. A well-trained tokenizer, tailored to the specific characteristics of the target language (e.g., German), is crucial for achieving high performance. The paper investigates this by training custom tokenizers with various vocabulary sizes and comparing them to existing tokenizers like German-gpt2 and gbert-large. The findings highlight the importance of optimizing tokenizer training data; smaller, carefully curated datasets sometimes yielded superior results compared to massive datasets, illustrating that data quality trumps quantity. This underscores the necessity of a meticulous data preprocessing phase and suggests that even in the absence of massive resources, a well-chosen, targeted approach to tokenizer training can yield effective results, thereby significantly impacting the overall performance of the downstream language models. Finally, the observed impact is not merely quantitative, but also qualitative; the specific tokenizer choices fundamentally shape how the model processes and understands language, demonstrating its influence across various downstream tasks.
Scaling Effects#
Analyzing scaling effects in large language models (LLMs) reveals crucial insights into resource allocation and performance. The paper investigates this by training two German-only LLMs, one with 120 million and the other with 1 billion parameters. Results demonstrate a positive correlation between model size and performance, generally aligning with expectations. However, performance improvements plateaued early on certain tasks, even with increased model size. This suggests that simply increasing model size isn’t always the most efficient approach to enhancing performance on all tasks. Further research should focus on optimizing resource allocation, potentially concentrating resources on tasks where scaling shows significant gains, rather than evenly distributing resources across the board. Understanding this plateauing effect is critical for cost-effective LLM development. The findings highlight the importance of studying the learning dynamics and the relationship between model size, specific task performance, and resource utilization for efficient German LLM development.
Future of German LLMs#
The future of German LLMs hinges on addressing the current data scarcity and fostering collaboration. While English LLMs benefit from massive datasets and substantial industry investment, German LLMs lag behind. Open-sourcing models and datasets, as done by the authors with LLäMmlein, is crucial for accelerating progress. This allows researchers to build upon existing work, identify limitations more easily and avoid redundant efforts. Focusing on German-specific datasets and tasks is also key. Multilingual models, while convenient, often underperform on less-resourced languages. To truly thrive, future development needs a stronger emphasis on high-quality, German-centric data, possibly through crowdsourcing or innovative data augmentation techniques. Furthermore, research into efficient model training is vital. Larger models are not always better; efficient, smaller models trained on high-quality data can be highly competitive and more accessible. Finally, the community must invest in open-source tools and benchmarks for training and evaluation to ensure reproducibility and facilitate comparison of different approaches. Ultimately, a collaborative, open-source approach will be essential for propelling German LLMs forward.
More visual insights#
More on figures

🔼 This figure shows the distribution of token counts within four distinct subsets of the RedPajama dataset. The dataset has been partitioned based on token count and duplicate status. The four subsets are: tokens from the ‘head’ portion of the dataset that are unique; tokens from the ‘middle’ portion that are unique; tokens from the ‘head’ portion that are duplicates; and tokens from the ‘middle’ portion that are duplicates. Each subset’s distribution is displayed separately to reveal variations in token length across the data quality levels.
read the caption
(b) Token count distribution for each partition separately: head unique, middle Unique, head duplicate and middle duplicate

🔼 This figure presents a statistical analysis of the RedPajama dataset, specifically focusing on the token count distribution. Subfigure (a) shows the overall distribution, differentiating between all data, unique data, and duplicate data. Subfigure (b) further breaks down the unique and duplicate data into ‘head’ and ‘middle’ sections, which represent different quality levels within the dataset, based on a perplexity score. The tokenizer used for this analysis is gbert-large.
read the caption
Figure 1: Redpajama statistics based on gbert-large tokenizer

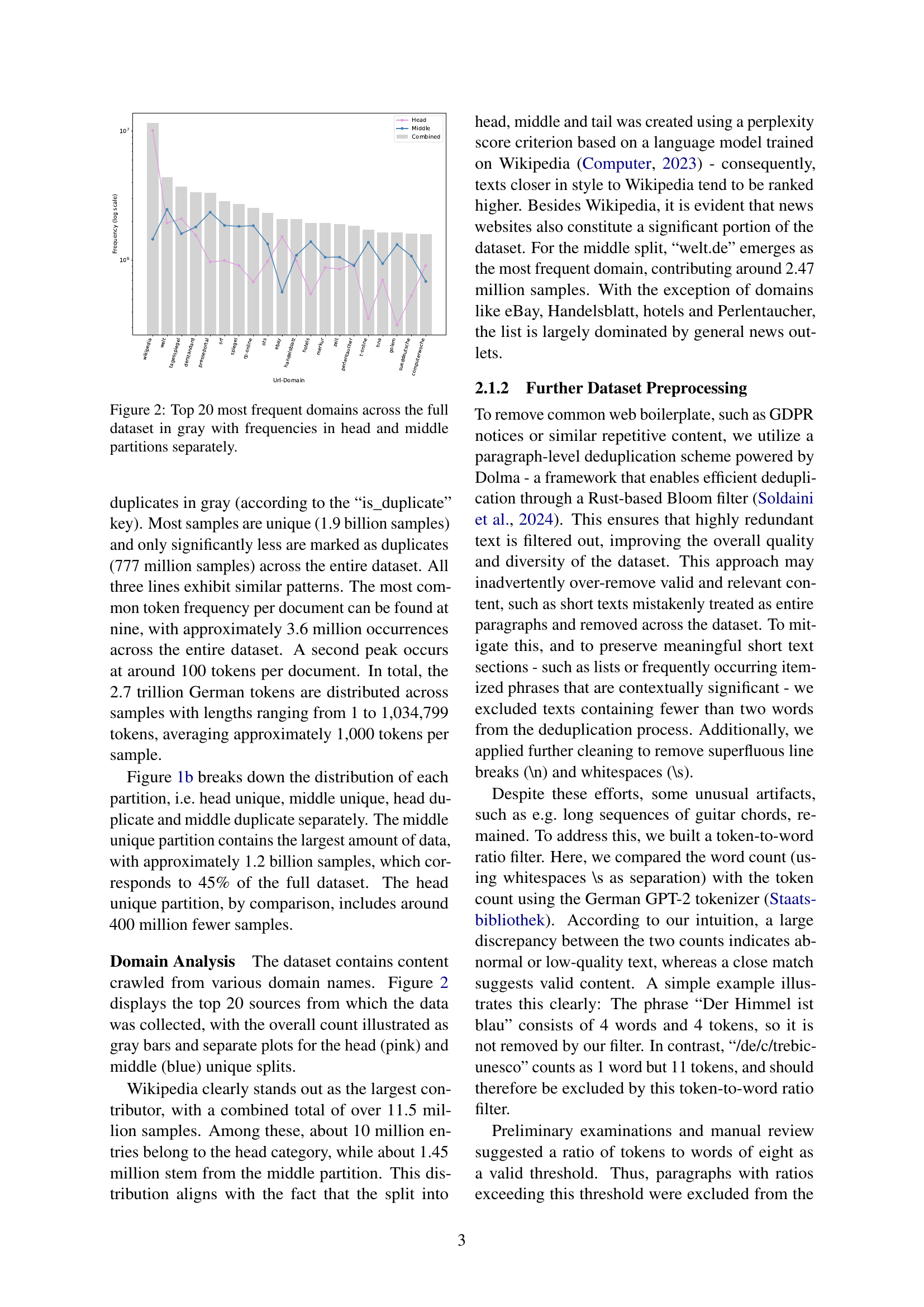
🔼 This bar chart visualizes the top 20 most frequent domains found within a large dataset used for training a German language model. The dataset is divided into ‘head’ and ‘middle’ partitions based on data quality, with the full dataset’s distribution shown in gray for comparison. The chart displays the frequency of each domain in the full dataset, as well as the frequencies specific to the head and middle partitions, allowing for a comparison of domain distribution across different data quality levels. This helps understand the composition of the training data and its potential biases.
read the caption
Figure 2: Top 20 most frequent domains across the full dataset in gray with frequencies in head and middle partitions separately.

🔼 This figure displays the training loss curve for the LLäMmlein 120M language model. The x-axis represents the training step, and the y-axis shows the loss value. Multiple lines are shown, each representing a separate training run. Each run was interrupted at some point and then resumed from the latest checkpoint, with each interruption and subsequent resumption represented by a different color. The plot allows visualization of the model’s training progress and highlights the impact of training interruptions on the overall training dynamics.
read the caption
Figure 3: Loss curve of LLäMmlein 120M model. Each color indicates a run, resumed after a training interruption.

🔼 This figure displays the training loss curve for the LLäMmlein 1B language model. Multiple lines represent separate training runs, each a different color. The training was interrupted multiple times, and each interruption and subsequent resumption is shown as a separate colored line. Examining the graph allows for the analysis of training dynamics and the impact of interruptions.
read the caption
Figure 4: Loss curve of LLäMmlein 1B model. Each color indicates a run, resumed after a training interruption.

🔼 The figure shows the token count distribution for a sample of the dataset’s middle partition, comparing counts generated by different tokenizers. This helps illustrate how different tokenizers process the text differently and produce varying token counts for the same dataset.
read the caption
snapshot from middle

🔼 This figure displays the token count distribution for a sample of the German dataset from the ‘head’ partition. The head partition is a subset of the RedPajama V2 dataset containing high-quality German text, as determined by a perplexity score based on a language model trained on Wikipedia. The token counts are generated using the gbert-large tokenizer. The distribution shows how many tokens each document contains, providing insights into the dataset’s characteristics.
read the caption
snapshot from head

🔼 This figure shows the token count distribution for the entire RedPajama dataset, highlighting the proportion of unique and duplicate data. The combination of unique and duplicate data is displayed to show the distribution of all combined data. The graph aids in understanding the dataset’s composition and potential redundancy during preprocessing.
read the caption
(a)

🔼 This figure shows the token count distribution for each partition of the RedPajama dataset separately. These partitions are categorized by the quality and duplication status of the text data: head unique, middle unique, head duplicate, and middle duplicate. The x-axis represents the token count, and the y-axis represents the frequency of documents with that token count. The chart helps visualize how the dataset is distributed across different token lengths and duplication levels.
read the caption
(b)
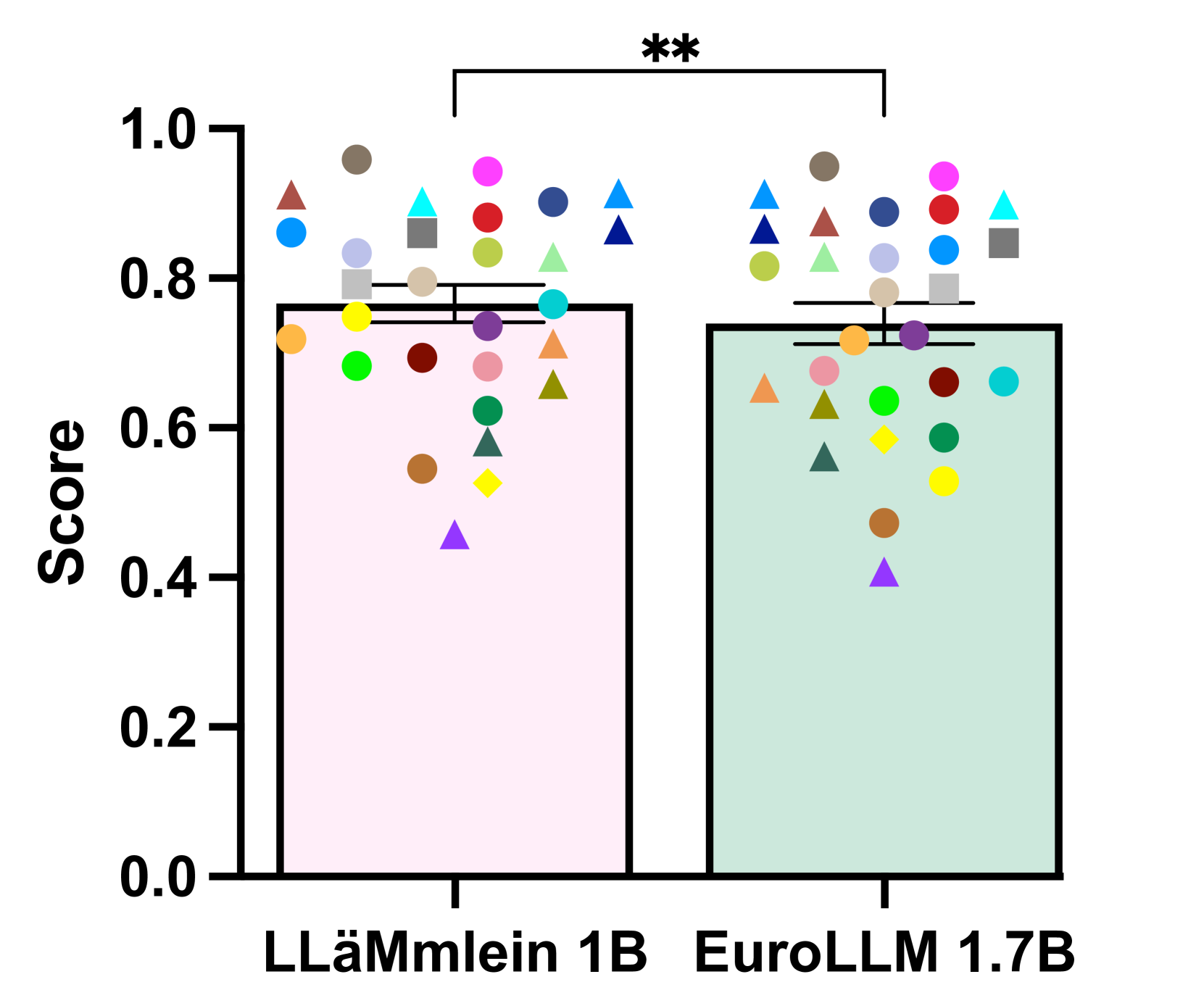
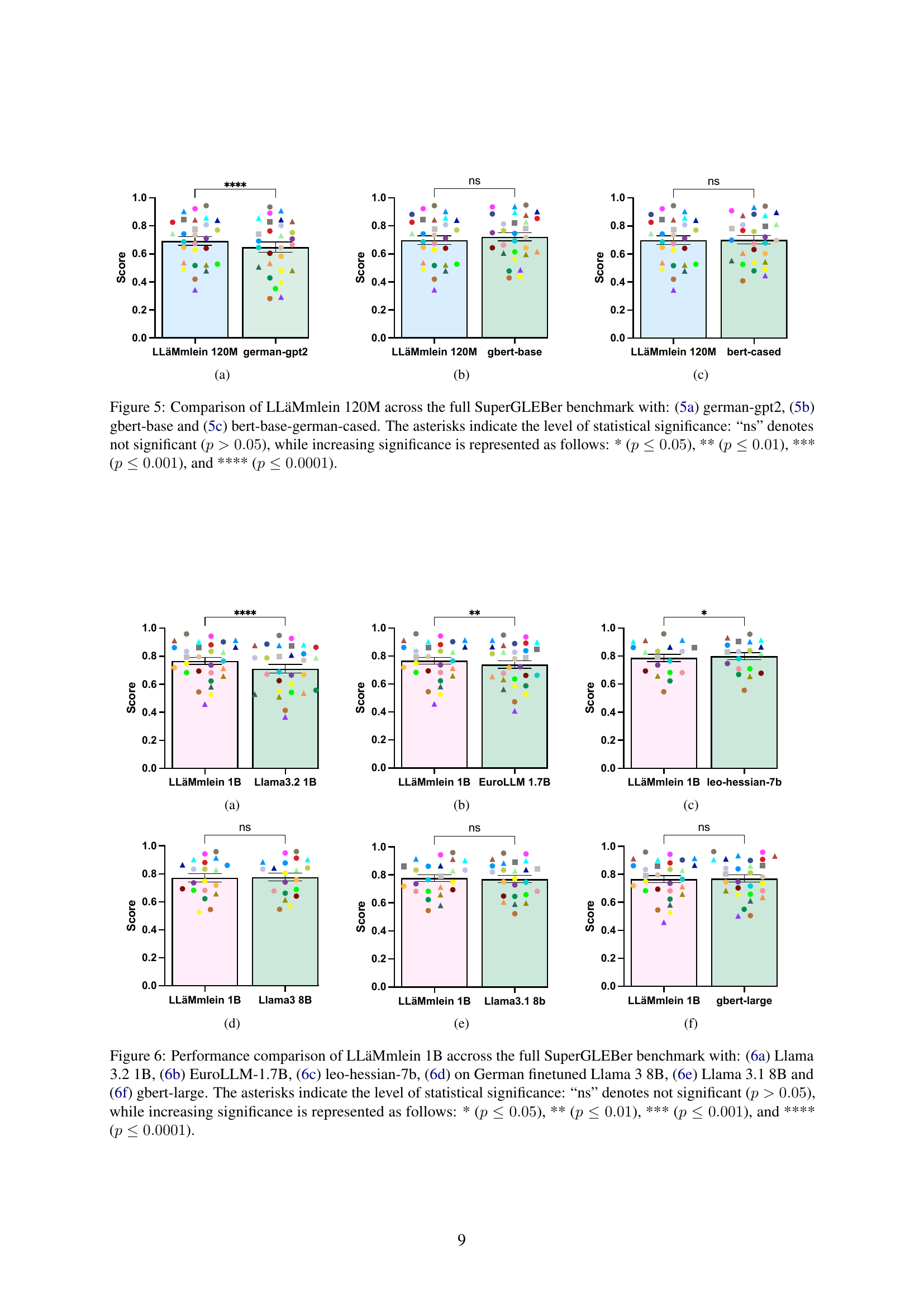
🔼 This figure shows the comparison of LLäMmlein 120M across the full SuperGLEBer benchmark with bert-base-german-cased. The asterisks represent the statistical significance of the differences. ’ns’ means not significant (p > 0.05); * indicates p < 0.05; ** indicates p < 0.01; *** indicates p < 0.001; and **** indicates p < 0.0001.
read the caption
(c)
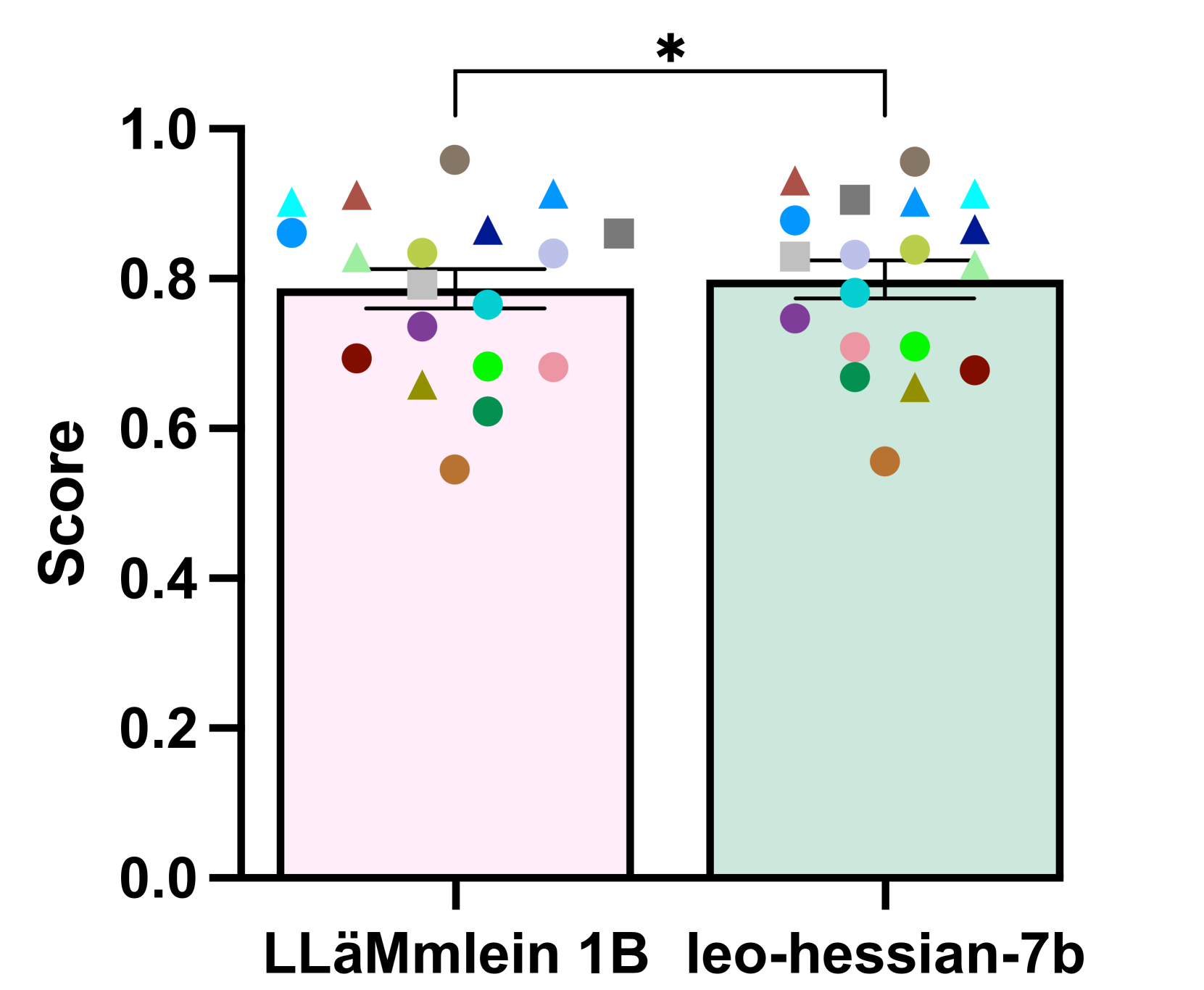
🔼 Figure 5 presents a comparative analysis of LLäMmlein 120M’s performance against three other German Language Models (GLMs): german-gpt2, gbert-base, and bert-base-german-cased. The evaluation is conducted across the complete SuperGLEBer benchmark, a comprehensive suite of tasks designed to assess various aspects of GLM capabilities. The figure uses bar graphs to visually represent the performance scores of each model on each task within the benchmark. Asterisks above the bars indicate the statistical significance of performance differences, with ’ns’ representing no significant difference (p>0.05), and increasing numbers of asterisks denoting progressively higher levels of significance (p≤0.05, p≤0.01, p≤0.001, p≤0.0001). This allows for a direct visual comparison of LLäMmlein 120M’s strengths and weaknesses against established models in the German NLP landscape.
read the caption
Figure 5: Comparison of LLäMmlein 120M across the full SuperGLEBer benchmark with: (5(a)) german-gpt2, (5(b)) gbert-base and (5(c)) bert-base-german-cased. The asterisks indicate the level of statistical significance: “ns” denotes not significant (p>0.05𝑝0.05p>0.05italic_p > 0.05), while increasing significance is represented as follows: * (p≤0.05𝑝0.05p\leq 0.05italic_p ≤ 0.05), ** (p≤0.01𝑝0.01p\leq 0.01italic_p ≤ 0.01), *** (p≤0.001𝑝0.001p\leq 0.001italic_p ≤ 0.001), and **** (p≤0.0001𝑝0.0001p\leq 0.0001italic_p ≤ 0.0001).

🔼 Token count distribution across the entire dataset, unique data, and duplicate data partitions. It shows the frequency of documents containing a given number of tokens. This helps to understand the data distribution and the relative proportions of unique versus duplicate content in the dataset. The graph shows that most samples have around 1,000 tokens, and the distribution of token counts is heavily right skewed (long tail).
read the caption
(a)

🔼 The figure shows the token count distribution for each partition of the RedPajama dataset separately. These partitions are: head unique, middle unique, head duplicate, and middle duplicate. This visualization helps to understand the distribution of unique and duplicate text segments within the different quality levels (head and middle) of the dataset. The x-axis represents the token count, and the y-axis represents the frequency of document lengths.
read the caption
(b)
More on tables
| Tokenizer | Token Count |
|---|---|
| word count | 46,509,357 |
| german-gpt2 | 78,151,205 |
| gbert-large | 79,969,101 |
| ours 1TB | 105,481,995 |
| ours 2023-2021 | 96,459,503 |
| ours 2023_14 | 81,993,239 |
🔼 This table presents the performance of LLäMmlein 120M, a German language model, at various checkpoints during its training. The results are compared against three other German models: german_gpt2, gbert_base, and bert-base-german-cased. The comparison is made across six different tasks from the SuperGLEBer benchmark, illustrating the model’s progress and its performance relative to established baselines.
read the caption
Table 2: Results of different checkpoints of LLäMmlein 120M on six SuperGLEBer tasks compared to german_gpt2, gbert_base and bert-base-german-cased
| Model | FactClaiming | EuroParl | Pawsx | NLI | DB Aspect | WebCAGe |
|---|---|---|---|---|---|---|
| 010000 | 0.711 | 0.531 | 0.427 | 0.549 | 0.454 | 0.689 |
| 050000 | 0.717 | 0.536 | 0.428 | 0.549 | 0.452 | 0.688 |
| 100000 | 0.708 | 0.532 | 0.464 | 0.559 | 0.479 | 0.700 |
| 150000 | 0.702 | 0.516 | 0.474 | 0.575 | 0.474 | 0.692 |
| 200000 | 0.705 | 0.497 | 0.497 | 0.575 | 0.464 | 0.703 |
| 210000 | 0.715 | 0.493 | 0.489 | 0.578 | 0.475 | 0.685 |
| 250000 | 0.723 | 0.536 | 0.478 | 0.560 | 0.479 | 0.684 |
| 300000 | 0.712 | 0.525 | 0.497 | 0.615 | 0.498 | 0.682 |
| 350000 | 0.705 | 0.547 | 0.492 | 0.624 | 0.511 | 0.678 |
| 400000 | 0.713 | 0.522 | 0.488 | 0.627 | 0.511 | 0.695 |
| 450000 | 0.693 | 0.511 | 0.479 | 0.638 | 0.504 | 0.694 |
| 466509 | 0.711 | 0.538 | 0.489 | 0.629 | 0.517 | 0.687 |
| german_gpt2 | 0.707 | 0.533 | 0.394 | 0.479 | 0.429 | 0.645 |
| gbert_base | 0.751 | 0.616 | 0.561 | 0.436 | 0.478 | 0.693 |
| bert-base-german-cased | 0.721 | 0.607 | 0.537 | 0.490 | 0.480 | 0.679 |
🔼 This table presents the performance of the LLäMmlein 1B language model at various checkpoints during its training. It shows the model’s scores on six different tasks from the SuperGLEBer benchmark, comparing its performance at different training stages. The comparison is made against the best performing models for each task reported in the benchmark. This allows for an assessment of the model’s progress throughout training and its overall capabilities compared to existing state-of-the-art models.
read the caption
Table 3: Performance of LLäMmlein 1B across multiple training checkpoints on six SuperGLEBer tasks, with comparison to the best-performing models for each task in the benchmark.
| Model | FactClaiming | EuroParl | Pawsx | NLI | DB Aspect | WebCAGe |
|---|---|---|---|---|---|---|
| 010000 | 0.735 | 0.708 | 0.461 | 0.642 | 0.563 | 0.677 |
| 100000 | 0.734 | 0.662 | 0.511 | 0.709 | 0.607 | 0.699 |
| 190000 | 0.736 | 0.701 | 0.525 | 0.721 | 0.614 | 0.719 |
| 310000 | 0.744 | 0.656 | 0.521 | 0.725 | 0.611 | 0.720 |
| 400000 | 0.716 | 0.665 | 0.517 | 0.722 | 0.623 | 0.719 |
| 500000 | 0.733 | 0.712 | 0.539 | 0.734 | 0.613 | 0.720 |
| 600000 | 0.712 | 0.724 | 0.541 | 0.725 | 0.608 | 0.722 |
| 700000 | 0.737 | 0.676 | 0.529 | 0.727 | 0.630 | 0.722 |
| 800000 | 0.718 | 0.727 | 0.528 | 0.743 | 0.613 | 0.742 |
| 900000 | 0.732 | 0.718 | 0.542 | 0.748 | 0.634 | 0.733 |
| 950000 | 0.747 | 0.732 | 0.556 | 0.746 | 0.622 | 0.755 |
| 1000000 | 0.750 | 0.697 | 0.540 | 0.740 | 0.629 | 0.756 |
| 1100000 | 0.740 | 0.710 | 0.550 | 0.744 | 0.623 | 0.762 |
| 1200000 | 0.726 | 0.679 | 0.545 | 0.746 | 0.629 | 0.755 |
| 1300000 | 0.725 | 0.695 | 0.533 | 0.751 | 0.624 | 0.764 |
| 1350000 | 0.748 | 0.712 | 0.528 | 0.752 | 0.633 | 0.763 |
| 1400000 | 0.729 | 0.702 | 0.536 | 0.741 | 0.629 | 0.756 |
| 1420000 | 0.745 | 0.702 | 0.530 | 0.345 | 0.643 | 0.759 |
| 1430512 | 0.736 | 0.713 | 0.526 | 0.749 | 0.623 | 0.765 |
| gbert_base | 0.751 | 0.616 | 0.561 | 0.436 | 0.478 | 0.693 |
| mbart_large_50 | 0.723 | 0.727 | 0.358 | 0.336 | 0.471 | 0.651 |
| gbert_large | 0.747 | 0.636 | 0.654 | 0.736 | 0.550 | 0.716 |
| leo-mistral-7b | 0.741 | 0.649 | - | 0.807 | 0.664 | - |
| leo-hessian-7b | 0.747 | - | - | - | 0.669 | 0.781 |
🔼 This table presents a performance comparison of the LLäMmlein 120M language model against other models on the
lm-evaluation-harness-debenchmark. The benchmark includes four translated tasks: TruthfulQA, ARC-Challenge, HellaSwag, and MMLU. The table allows for a quantitative assessment of LLäMmlein 120M’s capabilities relative to existing models across diverse question answering, common sense reasoning, and factual knowledge tasks.read the caption
Table 4: Performance comparison of LLäMmlein 120M to other language models on the lm-evaluation-harness-de including the four translated tasks: TruthfulQA, ARC-Challenge, HellaSwag and MMLU.
| Model | TruthfulQA | ARC-Challenge | HellaSwag | MMLU |
|---|---|---|---|---|
| german gpt2 | 0.261 | 0.432 | 0.195 | 0.236 |
| LLäMmlein 120M | 0.247 | 0.404 | 0.194 | 0.238 |
| LLäMmlein 120M Alpaka | 0.266 | 0.439 | 0.178 | 0.235 |
🔼 This table presents a performance comparison of various large language models (LLMs) on a German language evaluation benchmark. The models compared include LLäMmlein 1B (and instruction-tuned variants), Llama 3.2 1B, and several larger models. The benchmark used is
lm-evaluation-harness-de, and the specific tasks assessed are TruthfulQA, ARC-Challenge, HellaSwag, and MMLU. The results show the accuracy of each model on each task, allowing for a comparison of performance across different model sizes and training methodologies (base vs. instruction-tuned). This helps evaluate the effectiveness of LLäMmlein 1B relative to other state-of-the-art models, particularly considering its smaller size and training approach.read the caption
Table 5: Performance comparison of LLäMmlein 1B and its Instruction tuned variants as well as the similar sized Llama 3.2 1B and various larger models on the lm-evaluation-harness-de including the four tasks: TruthfulQA, ARC-Challenge, HellaSwag and MMLU.
Full paper#