↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Foundation models, while powerful, face challenges in effective supervision for capability enhancement. Traditional data-centric approaches are costly and unsustainable. This necessitates exploration of novel supervision methods. The limitations of handcrafted features and the increasing cost of human annotation highlight the need for more automated, scalable approaches to improving model performance.
This paper introduces “verifier engineering,” a novel post-training paradigm that uses automated verifiers for verification tasks. This process is systematically categorized into three essential stages: search, verify, and feedback. The paper reviews state-of-the-art research within each stage, demonstrating that verifier engineering can enhance model capabilities by providing more effective supervision signals than traditional methods. It offers a unified framework covering various approaches, potentially paving the way for achieving Artificial General Intelligence (AGI).
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with foundation models. It introduces verifier engineering, a novel post-training paradigm that offers a more scalable and effective approach to enhancing model capabilities than traditional methods. The framework is versatile and can be applied to various tasks, opening new avenues for research and development in AI. The paper’s systematic categorization of the process and comprehensive review of existing approaches make it an essential resource for the field.
Visual Insights#

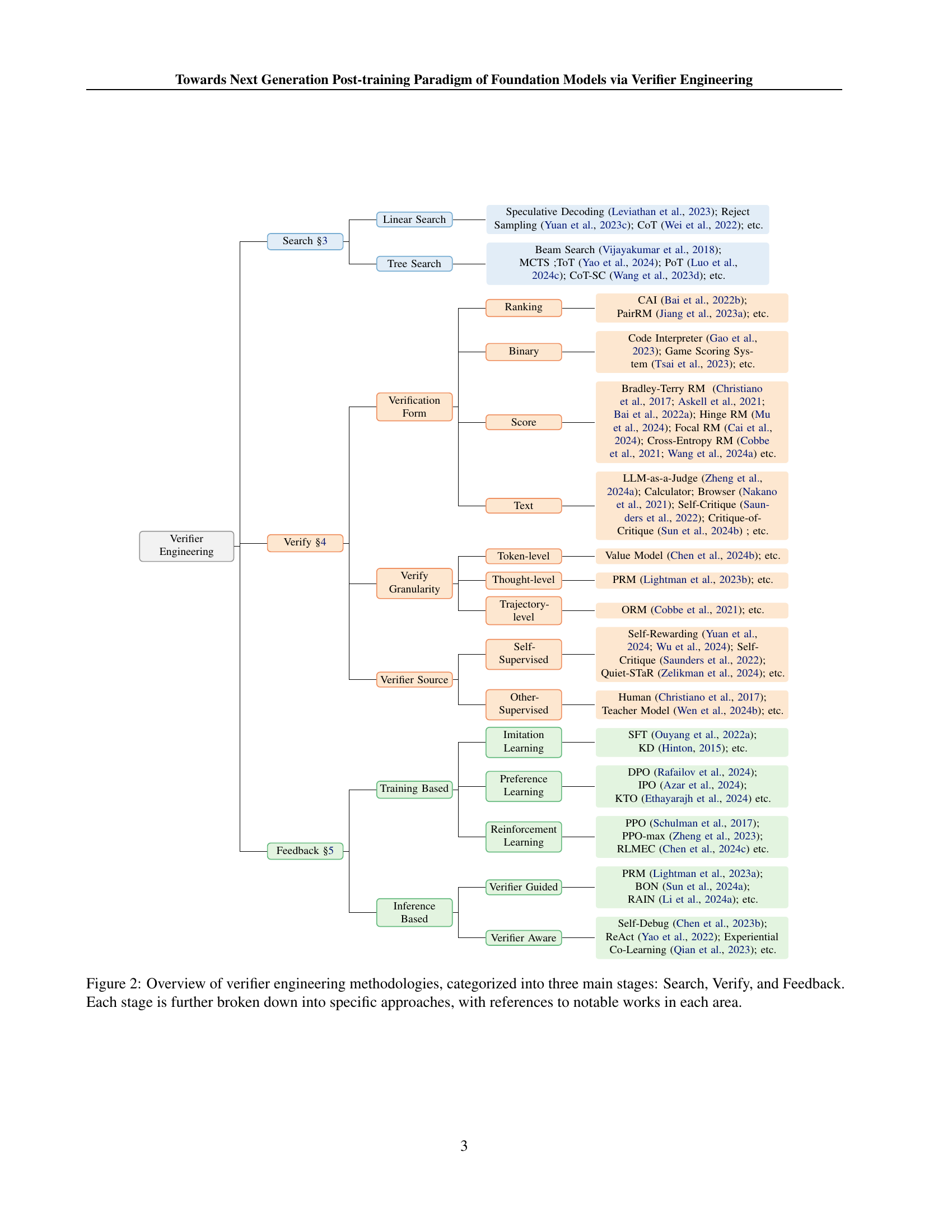
🔼 The figure illustrates the three main stages of verifier engineering: Search, Verify, and Feedback. The process starts with an instruction, followed by generating multiple candidate responses (Search). Each candidate is then evaluated using various verifiers (Verify), culminating in a feedback loop to refine the model’s output distribution (Feedback). The diagram shows how different existing methods, such as RLHF, OmegaPRM, and Experiential Co-learning, fit into this framework.
read the caption
Figure 1: Framework of verifier engineering: The fundamental stages of verifier engineering include Search, Verify, and Feedback. Given an instruction, the process begins with generating candidate responses (Search), followed by evaluating these candidates using appropriate verifier combinations (Verify), and concludes with optimizing the model’s output distribution (Feedback). This framework can explain various approaches, from training-based methods like RLHF (Ouyang et al., 2022a) to inference-based techniques such as OmegaPRM (Luo et al., 2024b) and Experiential Co-Learning (Qian et al., 2023). We systematically categorize existing approaches into these three stages in Table 3.
| Feature Engineering | Data Engineering | Verifier Engineering |
|---|---|---|
| Representative Models | Machine Learning Models | Deep Learning Models |
| e.g. | SVM, XGBoost | CNN, LSTM |
| Supervision | Manual Features | Human Annotations |
| Scope | Task-Specific | Multiple Related Tasks |
| Generalization | Limited | Relatively high |
| Scalability | Limited | Moderate |
🔼 This table compares three different paradigms in machine learning: feature engineering, data engineering, and verifier engineering. It highlights key differences across several dimensions, including the types of machine learning models used, the nature of supervision signals (manual features, human annotations, verifier feedback), the scope of tasks addressed (task-specific versus multiple related tasks or general intelligence), and the relative levels of generalization and scalability achieved by each approach. It illustrates the evolution of machine learning from handcrafted features to data-driven approaches and finally to a new paradigm using verifiers for providing feedback.
read the caption
Table 1: Comparison of feature engineering, data engineering, and verifier engineering
In-depth insights#
Verifier Engineering#
Verifier engineering presents a novel post-training paradigm for foundation models, addressing the challenges of providing effective supervision. It leverages automated verifiers to perform verification tasks, providing meaningful feedback to enhance model capabilities. This approach systematically categorizes the process into three stages: search, verify, and feedback. The search stage focuses on generating candidate responses, while the verify stage evaluates these responses using a suite of verifiers. Feedback, the final stage, uses the verification results to refine model output distribution via methods like supervised fine-tuning or reinforcement learning. Verifier engineering offers a fundamental shift from traditional data engineering, potentially leading to a more efficient and cost-effective way to improve foundation models and paving a path toward Artificial General Intelligence. Its key innovation lies in replacing expensive, time-consuming human evaluation with automated verification, enabling scalability and broader application. However, effective implementation requires addressing challenges like balancing exploration and exploitation during search, designing robust and diverse verifiers, and developing efficient strategies for feedback integration. The effectiveness of this approach ultimately hinges on the quality and diversity of the verifiers employed, as well as the ability of the feedback mechanisms to improve the model’s generalization capabilities.
Search Strategies#
Effective search strategies are crucial for efficient verifier engineering. Linear search, proceeding sequentially, is computationally inexpensive but risks early errors. Tree search, exploring multiple paths concurrently, offers greater potential but demands more resources. The choice depends on the task complexity and computational budget. Balancing exploration and exploitation is key; excessive exploration wastes resources while excessive exploitation limits discovery of optimal solutions. Therefore, advanced techniques like beam search and Monte Carlo Tree Search, which strategically balance exploration and exploitation, are particularly valuable. Goal-aware search further enhances efficiency by directly incorporating the desired outcome into the search process, prioritizing paths more likely to achieve the verification goal. Ultimately, the selection of a search strategy should be tailored to the specific application, balancing computational cost against the need to thoroughly explore the solution space.
Verifier Taxonomy#
A robust verifier taxonomy is crucial for advancing verifier engineering. Categorizing verifiers based on various criteria like verification form (binary, score, ranking, text), granularity (token, thought, trajectory), source (program-based, model-based), and training requirements (yes/no) allows for a systematic understanding of their strengths and weaknesses. This multifaceted approach enables researchers to select optimal verifiers for specific tasks and to design effective combinations. The taxonomy highlights trade-offs between accuracy and generalization: program-based verifiers offer deterministic outputs but lack flexibility, while model-based verifiers are adaptable but introduce uncertainty. Further research should explore the development of new verifier types and combinations to address limitations and to enhance the overall efficiency and robustness of the verifier engineering pipeline. The taxonomy serves as a foundational tool for evaluating existing methods, guiding future research directions, and ultimately contributing to the creation of more powerful and reliable foundation models.
Feedback Methods#
Feedback methods in post-training of foundation models are crucial for optimizing model capabilities. The paper explores two primary approaches: training-based feedback, which involves updating model parameters using data efficiently obtained through searching and verifying, and inference-based feedback, which modifies the output distribution without changing model parameters. Training-based feedback encompasses imitation learning, preference learning, and reinforcement learning, each leveraging verification results in different ways. Imitation learning directly uses verified high-quality data to fine-tune the model. Preference learning uses pairwise comparisons of candidate responses, ranked by verifiers, to optimize model preferences. Reinforcement learning utilizes reward signals from verifiers to guide iterative model improvements. Inference-based feedback is further categorized into verifier-guided and verifier-aware methods. Verifier-guided methods select outputs without direct model interaction, while verifier-aware methods directly incorporate feedback into model operations. The choice of feedback method depends on factors like robustness to noise, impact on model capabilities, and cross-query generalization. Finding a balance between exploration and exploitation during feedback is key to avoiding both under- and over-optimization. The paper emphasizes the need for careful verifier design, efficient search, and robust evaluation methods to maximize the impact of the feedback process. Systematically evaluating feedback approaches remains a challenge; thus, further research is needed to optimize these methods for achieving Artificial General Intelligence.
Future Challenges#
Future research in verifier engineering faces several key challenges. Improving search efficiency is crucial, as exhaustive searches are computationally expensive. More sophisticated methods are needed to balance exploration and exploitation effectively. Developing robust and versatile verifiers is another major challenge. Creating a system that seamlessly integrates multiple verifiers with diverse capabilities and handles conflicting verification results remains an open problem. Designing effective feedback mechanisms is critical for maximizing the impact of verification on model performance. The optimal approach must balance online and offline feedback strategies, consider the model’s capacity, and ensure effective generalization to unseen data. Addressing these challenges requires a multidisciplinary approach that incorporates elements of machine learning, software engineering, and human-computer interaction, ultimately aiming to create robust, reliable and efficient verifier engineering techniques for the enhancement of foundation models.
More visual insights#
More on tables
| Verifier Type | Verification Form | Verify Granularity | Verifier Source | Extra Training |
|---|---|---|---|---|
| Golden Annotation | Binary/Text | Thought Step/Full Trajectory | Program Based | No |
| Rule-based | Binary/Text | Thought Step/Full Trajectory | Program Based | No |
| Code Interpreter | Binary/Score/Text | Token/Thought Step/Full Trajectory | Program Based | No |
| ORM | Binary/Score/Rank/Text | Full Trajectory | Model Based | Yes |
| Language Model | Binary/Score/Rank/Text | Thought Step/Full Trajectory | Model Based | Yes |
| Tool | Binary/Score/Rank/Text | Token/Thought Step/Full Trajectory | Program Based | No |
| Search Engine | Text | Thought Step/Full Trajectory | Program Based | No |
| PRM | Score | Token/Thought Step | Model Based | Yes |
| Knowledge Graph | Text | Thought Step/Full Trajectory | Program Based | No |
🔼 This table categorizes verifiers based on four key characteristics: the format of their output (binary, score, ranking, or text), the level of detail they examine (token, thought, or trajectory), whether they are program-based or model-based, and whether they require additional training. This provides a structured overview of the diverse types of verifiers used in verifier engineering, highlighting the trade-offs between different approaches.
read the caption
Table 2: A comprehensive taxonomy of verifiers across four dimensions: verification form, verify granularity, verifier source, and the need for extra training.
| Method | Search | Verify | Feedback | Task |
|---|---|---|---|---|
| STar (Zelikman et al., 2022a), RFT (Yuan et al., 2023c) | Linear | Golden Annotation | Imitation Learning | Math |
| CAG (Pan et al., 2024) | Linear | Golden Annotation | Imitation Learning | RAG |
| Self-Instruct (Wang et al., 2023e) | Linear | Rule-based | Imitation Learning | General |
| Code Alpaca (Chaudhary, 2023), WizardCoder (Luo et al., 2024d) | Linear | Rule-based | Imitation Learning | Code |
| ILF-Code (Chen et al., 2024a) | Linear | Rule-based & Code interpreter | Imitation Learning | Code |
| RAFT (Dong et al., 2023), RRHF (Yuan et al., 2023a) | Linear | ORM | Imitation Learning | General |
| SSO (Xiang et al., 2024) | Linear | Rule-based | Preference Learning | Alignment |
| CodeUltraFeedback (Weyssow et al., 2024) | Linear | Language Model | Preference Learning | Code |
| Self-Rewarding (Yuan et al., 2024) | Linear | Language Model | Preference Learning | Alignment |
| StructRAG (Li et al., 2024b) | Linear | Language Model | Preference Learning | RAG |
| LLAMA-BERRY (Zhang et al., 2024a) | Tree | ORM | Preference Learning | Reasoning |
| Math-Shepherd (Wang et al., 2024b) | Linear | Golden Annotation & Rule-based | Reinforcement Learning | Math |
| RLTF (Liu et al., 2023b), PPOCoder (Shojaee et al., 2023b) | Linear | Code Interpreter | Reinforcement Learning | Code |
| RLAIF (Lee et al., 2023) | Linear | Language Model | Reinforcement Learning | General |
| SIRLC (Pang et al., 2023) | Linear | Language Model | Reinforcement Learning | Reasoning |
| RLFH (Wen et al., 2024d) | Linear | Language Model | Reinforcement Learning | Knowledge |
| RLHF (Ouyang et al., 2022a) | Linear | ORM | Reinforcement Learning | Alignment |
| Quark (Lu et al., 2022) | Linear | Tool | Reinforcement Learning | Alignment |
| ReST-MCTS (Zhang et al., 2024b) | Tree | Language Model | Reinforcement Learning | Math |
| CRITIC (Gou et al., 2024) | Linear | Code Interpreter & Tool & Search Engine | Verifier-Aware | Math, Code & Knowledge & General |
| Self-Debug (Chen et al., 2023c) | Linear | Code Interpreter | Verifier-Aware | Code |
| Self-Refine (Madaan et al., 2023) | Linear | Language Model | Verifier-Aware | Alignment |
| ReAct (Yao et al., 2022) | Linear | Search Engine | Verifier-Aware | Knowledge |
| Constrative decoding (Li et al., 2023a) | Linear | Language Model | Verifier-Guided | General |
| Chain-of-verfication (Dhuliawala et al., 2023) | Linear | Language Model | Verifier-Guided | Knowledge |
| Inverse Value Learning (Lu et al., 2024) | Linear | Language Model | Verifier-Guided | General |
| PRM (Lightman et al., 2023b) | Linear | PRM | Verifier-Guided | Math |
| KGR (Guan et al., 2023) | Linear | Knowledge Graph | Verifier-Guided | Knowledge |
| UoT (Hu et al., 2024) | Tree | Language Model | Verifier-Guided | General |
| ToT (Yao et al., 2024) | Tree | Language Model | Verifier-Guided | Reasoning |
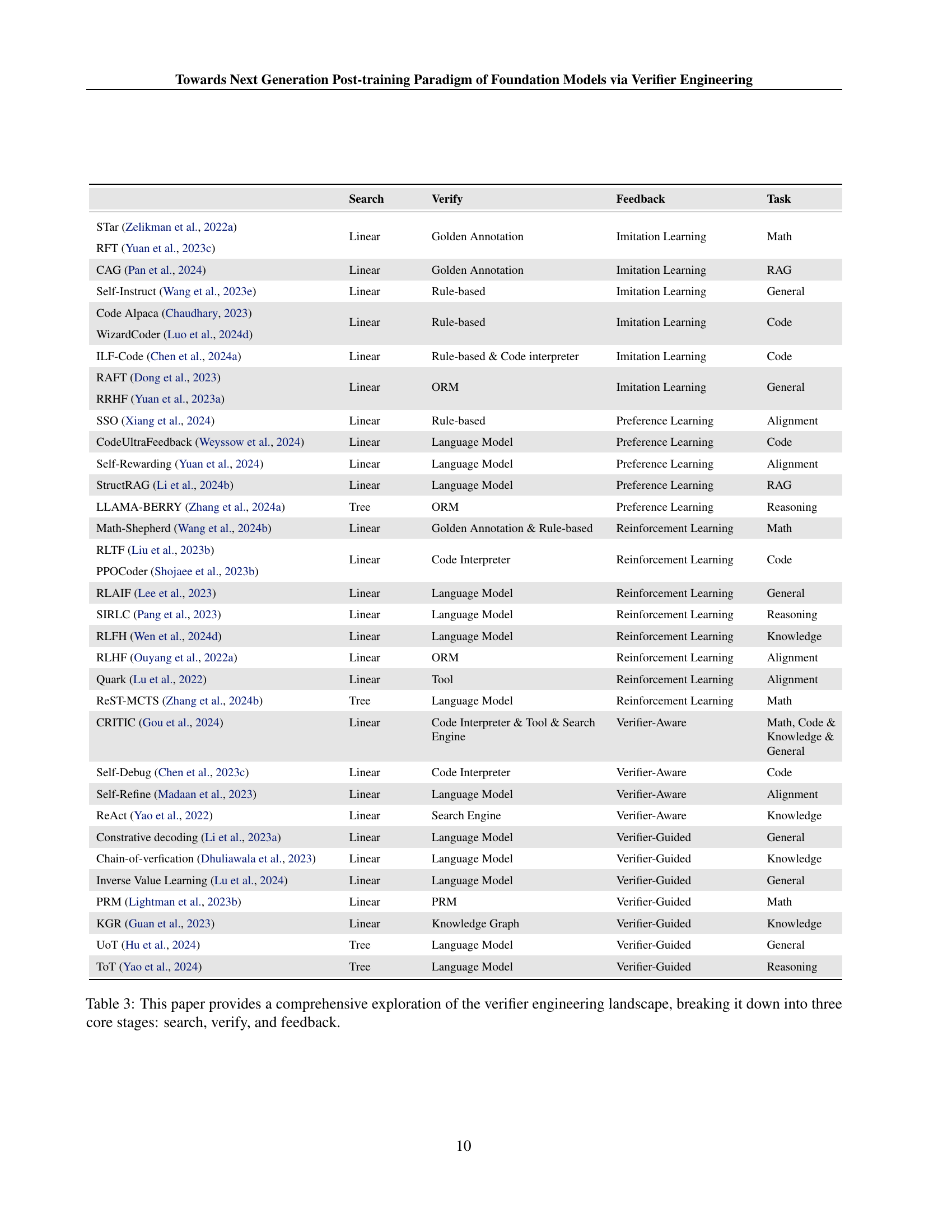
🔼 This table provides a comprehensive overview of various methods used in verifier engineering, categorized into three core stages: search, verification, and feedback. Each row represents a different approach or technique, detailing the search strategy employed (linear or tree-based), the type of verifier used (e.g., golden annotation, reward model), the feedback mechanism (e.g., imitation, reinforcement, preference learning), and the specific task the method is applied to (e.g., math, code, reasoning). The table aims to illustrate the diversity of techniques within each stage of verifier engineering and their applications to different tasks.
read the caption
Table 3: This paper provides a comprehensive exploration of the verifier engineering landscape, breaking it down into three core stages: search, verify, and feedback.
Full paper#