↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
The Segment Anything Model 2 (SAM 2) shows promise in object segmentation but struggles with visual object tracking, particularly in complex scenes with fast-moving or self-occluding objects. The fixed memory approach in SAM 2 also contributes to tracking errors by not considering memory quality. These limitations hinder its effectiveness for real-time applications.
To address these issues, this paper introduces SAMURAI. This enhanced model incorporates motion cues into the prediction process to improve tracking accuracy, especially in crowded scenes. SAMURAI uses a motion-aware memory selection mechanism to prioritize relevant memories. The results demonstrate significant improvements in success rate and precision compared to existing trackers, achieving competitive results with fully supervised methods. This zero-shot approach allows for generalization without needing dataset-specific fine-tuning, making it highly valuable for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves visual object tracking, a crucial task in computer vision. SAMURAI’s zero-shot learning approach avoids the need for extensive training data, making it more accessible and adaptable to real-world applications. The proposed motion-aware memory and motion modeling offer new avenues for enhancing tracking accuracy and robustness in complex scenarios, advancing current research on efficient and generalizable tracking algorithms. The findings could impact various applications like autonomous driving, robotics, and video surveillance.
Visual Insights#

🔼 Figure 1 illustrates two common scenarios where the Segment Anything Model 2 (SAM 2) fails during visual object tracking. The first case shows that in crowded scenes with similar-looking objects, SAM 2 prioritizes the mask with the highest Intersection over Union (IoU) score, neglecting crucial motion cues, which often leads to inaccurate tracking of the target object. The second case demonstrates how the fixed-window memory mechanism of SAM 2 indiscriminately stores the previous frames, without assessing the quality of the memories. This results in irrelevant or low-quality memory features being stored, especially during object occlusions, further compromising the tracking accuracy.
read the caption
Figure 1: Illustration of two common failure cases in visual object tracking using SAM 2: (1) In a crowded scene with similar appearances between target and background objects, SAM 2 tends to ignore the motion cue and predict where the mask has the higher IoU score. (2) The original memory bank simply chooses and stores the previous n𝑛nitalic_n frames into the memory bank, resulting in introducing some bad features during occlusion.
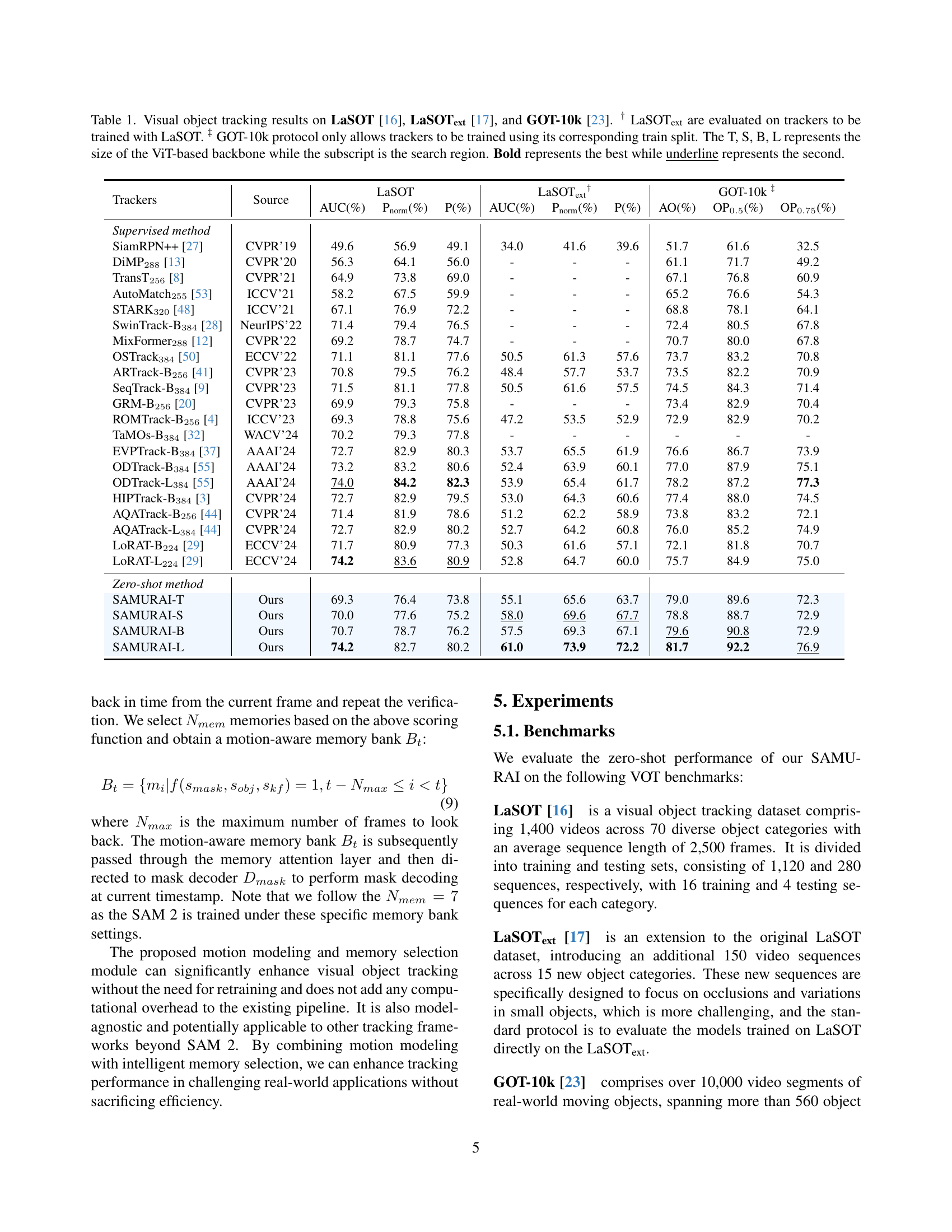
| Trackers | Source | LaSOT | AUC(%) | Pnorm(%) | P(%) | LaSOText† | AUC(%) | Pnorm(%) | P(%) | GOT-10k‡ | AO(%) | OP0.5(%) | OP0.75(%) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Supervised method | ||||||||||||||
| SiamRPN++ [27] | CVPR’19 | 49.6 | 56.9 | 49.1 | 34.0 | 41.6 | 39.6 | 51.7 | 61.6 | 32.5 | ||||
| DiMP288 [13] | CVPR’20 | 56.3 | 64.1 | 56.0 | - | - | - | 61.1 | 71.7 | 49.2 | ||||
| TransT256 [8] | CVPR’21 | 64.9 | 73.8 | 69.0 | - | - | - | 67.1 | 76.8 | 60.9 | ||||
| AutoMatch255 [53] | ICCV’21 | 58.2 | 67.5 | 59.9 | - | - | - | 65.2 | 76.6 | 54.3 | ||||
| STARK320 [48] | ICCV’21 | 67.1 | 76.9 | 72.2 | - | - | - | 68.8 | 78.1 | 64.1 | ||||
| SwinTrack-B384 [28] | NeurIPS’22 | 71.4 | 79.4 | 76.5 | - | - | - | 72.4 | 80.5 | 67.8 | ||||
| MixFormer288 [12] | CVPR’22 | 69.2 | 78.7 | 74.7 | - | - | - | 70.7 | 80.0 | 67.8 | ||||
| OSTrack384 [50] | ECCV’22 | 71.1 | 81.1 | 77.6 | 50.5 | 61.3 | 57.6 | 73.7 | 83.2 | 70.8 | ||||
| ARTrack-B256 [41] | CVPR’23 | 70.8 | 79.5 | 76.2 | 48.4 | 57.7 | 53.7 | 73.5 | 82.2 | 70.9 | ||||
| SeqTrack-B384 [9] | CVPR’23 | 71.5 | 81.1 | 77.8 | 50.5 | 61.6 | 57.5 | 74.5 | 84.3 | 71.4 | ||||
| GRM-B256 [20] | CVPR’23 | 69.9 | 79.3 | 75.8 | - | - | - | 73.4 | 82.9 | 70.4 | ||||
| ROMTrack-B256 [4] | ICCV’23 | 69.3 | 78.8 | 75.6 | 47.2 | 53.5 | 52.9 | 72.9 | 82.9 | 70.2 | ||||
| TaMOs-B384 [32] | WACV’24 | 70.2 | 79.3 | 77.8 | - | - | - | - | - | - | ||||
| EVPTrack-B384 [37] | AAAI’24 | 72.7 | 82.9 | 80.3 | 53.7 | 65.5 | 61.9 | 76.6 | 86.7 | 73.9 | ||||
| ODTrack-B384 [55] | AAAI’24 | 73.2 | 83.2 | 80.6 | 52.4 | 63.9 | 60.1 | 77.0 | 87.9 | 75.1 | ||||
| ODTrack-L384 [55] | AAAI’24 | 74.0 | 84.2 | 82.3 | 53.9 | 65.4 | 61.7 | 78.2 | 87.2 | 77.3 | ||||
| HIPTrack-B384 [3] | CVPR’24 | 72.7 | 82.9 | 79.5 | 53.0 | 64.3 | 60.6 | 77.4 | 88.0 | 74.5 | ||||
| AQATrack-B256 [44] | CVPR’24 | 71.4 | 81.9 | 78.6 | 51.2 | 62.2 | 58.9 | 73.8 | 83.2 | 72.1 | ||||
| AQATrack-L384 [44] | CVPR’24 | 72.7 | 82.9 | 80.2 | 52.7 | 64.2 | 60.8 | 76.0 | 85.2 | 74.9 | ||||
| LoRAT-B224 [29] | ECCV’24 | 71.7 | 80.9 | 77.3 | 50.3 | 61.6 | 57.1 | 72.1 | 81.8 | 70.7 | ||||
| LoRAT-L224 [29] | ECCV’24 | 74.2 | 83.6 | 80.9 | 52.8 | 64.7 | 60.0 | 75.7 | 84.9 | 75.0 | ||||
| Zero-shot method | ||||||||||||||
| SAMURAI-T | Ours | 69.3 | 76.4 | 73.8 | 55.1 | 65.6 | 63.7 | 79.0 | 89.6 | 72.3 | ||||
| SAMURAI-S | Ours | 70.0 | 77.6 | 75.2 | 58.0 | 69.6 | 67.7 | 78.8 | 88.7 | 72.9 | ||||
| SAMURAI-B | Ours | 70.7 | 78.7 | 76.2 | 57.5 | 69.3 | 67.1 | 79.6 | 90.8 | 72.9 | ||||
| SAMURAI-L | Ours | 74.2 | 82.7 | 80.2 | 61.0 | 73.9 | 72.2 | 81.7 | 92.2 | 76.9 |
🔼 Table 1 presents a comprehensive comparison of visual object tracking results achieved by various methods on three benchmark datasets: LaSOT, LaSOText, and GOT-10k. For LaSOText, only trackers trained using LaSOT data are evaluated. The GOT-10k protocol restricts training to its designated train split. The table details performance metrics (AUC, precision, and success rate), differentiating the results based on the size of the Vision Transformer (ViT) backbone used (T, S, B, L) and the search region. The best performing method for each metric is highlighted in bold, while the second-best is underlined. This provides a clear understanding of the relative strengths and weaknesses of different visual tracking approaches across various datasets and model sizes.
read the caption
Table 1: Visual object tracking results on LaSOT [16], LaSOTextext{}_{\text{ext}}start_FLOATSUBSCRIPT ext end_FLOATSUBSCRIPT [17], and GOT-10k [23]. ††\dagger† LaSOTextext{}_{\text{ext}}start_FLOATSUBSCRIPT ext end_FLOATSUBSCRIPT are evaluated on trackers to be trained with LaSOT. ‡‡\ddagger‡ GOT-10k protocol only allows trackers to be trained using its corresponding train split. The T, S, B, L represents the size of the ViT-based backbone while the subscript is the search region. Bold represents the best while underline represents the second.
In-depth insights#
SAMURAI’s Motion Focus#
SAMURAI’s core innovation lies in its motion-aware design, improving upon the static nature of the original SAM model. Motion modeling, likely employing a Kalman filter or similar technique, provides robust prediction of object movement. This predictive ability is crucial for handling fast-moving objects and maintaining consistent object identity despite occlusion or appearance changes. The motion-aware memory selection mechanism is equally significant. It intelligently prioritizes relevant historical frames based on a hybrid scoring system that factors in both motion and affinity scores. By discarding less relevant, potentially confusing frames, the tracker prevents error propagation and significantly enhances robustness, particularly in crowded scenes. This dynamic memory management is a key differentiator, addressing the limitations of SAM’s fixed-window memory approach and leading to improved accuracy and efficiency. In essence, SAMURAI’s focus on motion provides a powerful mechanism to deal with temporal complexities inherent in visual object tracking. It transforms a primarily static segmentation model into a robust and accurate real-time tracking solution.
Memory Enhancement#
The paper focuses on enhancing the memory mechanism of the Segment Anything Model (SAM) for improved visual object tracking. The core idea revolves around a motion-aware memory selection strategy, moving beyond SAM’s simple fixed-window approach. This enhancement involves a scoring system that considers not only mask affinity but also motion cues and object occurrence. By incorporating temporal context, the model avoids error propagation and improves accuracy in challenging scenarios, especially when dealing with occlusion and crowded scenes. The use of a Kalman filter further refines object location predictions, aiding in the selection process. This thoughtful approach to memory management is crucial for robust tracking, particularly in dynamic and complex visual environments, and demonstrates the power of selectively choosing pertinent historical information rather than relying on all previous frames. This motion modeling and optimized memory selection, working in tandem, constitute the key to SAMURAI’s superior performance.
Zero-Shot Tracking#
Zero-shot visual object tracking, a significant area of research, focuses on tracking objects in video without the need for object-specific training data. This presents a considerable challenge, as it requires the tracker to generalize effectively to unseen objects. The paper’s SAMURAI model addresses this challenge by cleverly adapting the Segment Anything Model (SAM). SAMURAI’s strength lies in its ability to leverage motion information and a refined memory selection mechanism. By incorporating motion cues, it can predict object movement more accurately, reducing the reliance on visual similarity alone which often fails with fast-moving objects or in crowded scenes. The motion-aware memory effectively filters out irrelevant or low-quality memory frames, improving the model’s ability to maintain consistent object identity throughout video sequences, even amidst occlusions. This approach achieves state-of-the-art performance on several benchmarks, showcasing the potential of zero-shot methods and the power of effective temporal context integration in visual tracking.
Benchmark Results#
The benchmark results section of a research paper is critical for evaluating the proposed method’s performance. It should present a comprehensive comparison against existing state-of-the-art techniques across multiple relevant datasets, using standard evaluation metrics. A strong benchmark section will not only report quantitative results like AUC, precision, and success rate but also provide detailed analysis of the results, including error visualizations and discussions of performance variations across different scenarios. The choice of benchmarks themselves is crucial; they must be widely accepted and representative of the problem domain. A thoughtful analysis might highlight strengths and weaknesses of the proposed method in specific scenarios, indicating areas for future improvement. Robust error analysis can reveal limitations, helping to refine future research directions. Finally, a clear presentation of the results—using tables, graphs, and concise descriptions—is essential to make the findings easily understandable and readily comparable with prior work.
Future Enhancements#
Future work could explore several promising avenues to enhance SAMURAI. Improving the motion model beyond a simple Kalman filter, perhaps using more sophisticated methods like deep learning-based approaches, could lead to more robust tracking in complex scenarios with non-linear object movement. Developing a more adaptive memory selection mechanism is key. The current hybrid scoring system works well but might benefit from incorporating additional factors such as object appearance changes or interactions between objects. Investigating different prompt strategies for the mask decoder could also enhance accuracy and efficiency. Furthermore, exploring techniques for handling more extreme occlusions or challenging scenarios (e.g., severe viewpoint changes, extreme lighting conditions) would be highly valuable. Finally, extending SAMURAI to handle multiple object tracking would represent a significant advancement, but requires addressing the complexities of object association and ID switching.
More visual insights#
More on figures

🔼 This figure provides a detailed overview of the SAMURAI visual object tracking system. It illustrates the flow of data through the various components: the image encoder processes the input video frames; a motion modeling module refines the positional information; the sparse prompt tokens guide the initial mask selection; the memory attention layer incorporates historical context from the motion-aware memory selection mechanism, which only selects relevant frames based on both mask affinity and motion cues; a mask decoder outputs a set of predicted masks and related scores; finally, the multi-mask selection component chooses the most accurate mask.
read the caption
Figure 2: The overview of our SAMURAI visual object tracker.

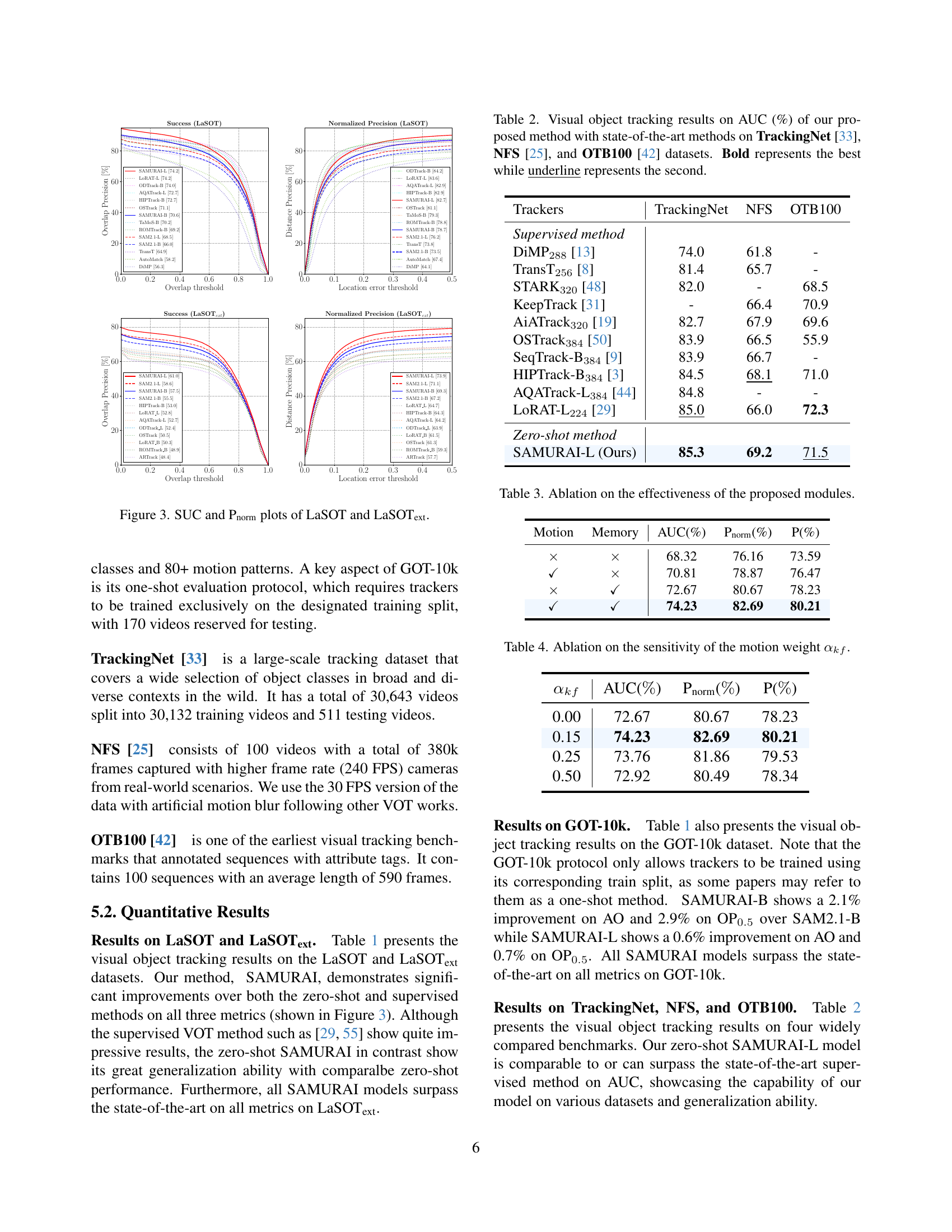
🔼 Figure 3 presents the success plots (SUC) and normalized precision plots (Pnorm) for the LaSOT and LaSOText datasets. These plots illustrate the performance of the SAMURAI tracker and other trackers (both supervised and zero-shot) across different overlap thresholds (for SUC) and location error thresholds (for Pnorm). The SUC plot shows the percentage of frames where the tracker successfully keeps track of the object, while the Pnorm plot shows the precision of the tracker’s bounding box predictions, normalized by the object’s size. The plots allow for a visual comparison of the relative performance of SAMURAI and competing trackers across varying tracking difficulty levels.
read the caption
Figure 3: SUC and Pnormnorm{}_{\text{norm}}start_FLOATSUBSCRIPT norm end_FLOATSUBSCRIPT plots of LaSOT and LaSOTextext{}_{\text{ext}}start_FLOATSUBSCRIPT ext end_FLOATSUBSCRIPT.

🔼 This figure compares the visual object tracking performance of SAMURAI against other state-of-the-art methods. The top row shows how traditional VOT (Visual Object Tracking) methods often fail in crowded scenes with similar-looking objects, frequently losing track of the target. The bottom row demonstrates that even the SAM (Segment Anything Model)-based baseline tracker struggles because of its fixed-window memory approach. This fixed memory results in accumulated errors and incorrect object identification (ID switches) over time. In contrast, SAMURAI’s improved motion modeling and memory selection strategies mitigate these issues, enabling more accurate and stable tracking.
read the caption
Figure 4: Visualization of tracking results comparing SAMURAIwith existing methods. (Top) Conventional VOT methods often struggle in crowded scenarios where the target object is surrounded by objects with similar appearances. (Bottom) The baseline SAM-based method suffers from fixed-window memory composition, leading to error propagation and reduced overall tracking accuracy due to ID switches.
More on tables
| Trackers | TrackingNet | NFS | OTB100 |
|---|---|---|---|
| Supervised method | |||
| DiMP288 [13] | 74.0 | 61.8 | - |
| TransT256 [8] | 81.4 | 65.7 | - |
| STARK320 [48] | 82.0 | - | 68.5 |
| KeepTrack [31] | - | 66.4 | 70.9 |
| AiATrack320 [19] | 82.7 | 67.9 | 69.6 |
| OSTrack384 [50] | 83.9 | 66.5 | 55.9 |
| SeqTrack-B384 [9] | 83.9 | 66.7 | - |
| HIPTrack-B384 [3] | 84.5 | 68.1 | 71.0 |
| AQATrack-L384 [44] | 84.8 | - | - |
| LoRAT-L224 [29] | 85.0 | 66.0 | 72.3 |
| Zero-shot method | |||
| SAMURAI-L (Ours) | 85.3 | 69.2 | 71.5 |
🔼 Table 2 presents a comparison of the Area Under the Curve (AUC) metric for visual object tracking performance. It contrasts the proposed SAMURAI method with several state-of-the-art techniques across three benchmark datasets: TrackingNet, NFS, and OTB100. The AUC values reflect the overall tracking accuracy of each method. The best performance on each dataset is highlighted in bold, while the second-best is underlined.
read the caption
Table 2: Visual object tracking results on AUC (%) of our proposed method with state-of-the-art methods on TrackingNet [33], NFS [25], and OTB100 [42] datasets. Bold represents the best while underline represents the second.
| Motion | Memory | AUC(%) | Pnorm(%) | P(%) |
|---|---|---|---|---|
| × | × | 68.32 | 76.16 | 73.59 |
| ✓ | × | 70.81 | 78.87 | 76.47 |
| × | ✓ | 72.67 | 80.67 | 78.23 |
| ✓ | ✓ | 74.23 | 82.69 | 80.21 |
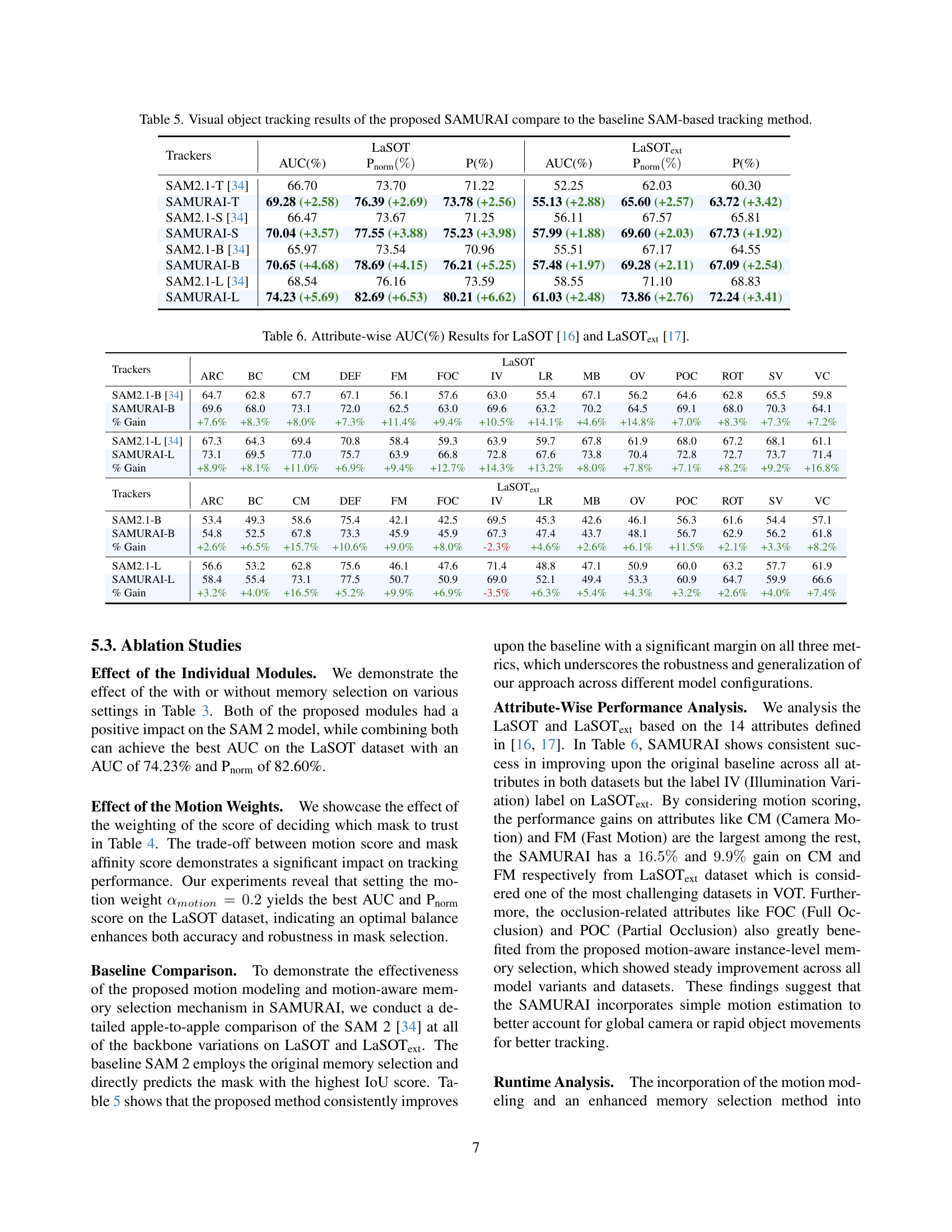
🔼 This table presents an ablation study evaluating the impact of the proposed modules (motion modeling and motion-aware memory selection) on the overall performance of the SAMURAI visual object tracker. It shows the AUC, precision, and success rate achieved by the model with different combinations of these modules, demonstrating their individual and combined contributions to improved accuracy. The results help quantify the effectiveness of each component.
read the caption
Table 3: Ablation on the effectiveness of the proposed modules.
| α_{kf} | AUC(%) | P_{norm}(%) | P(%) |
|---|---|---|---|
| 0.00 | 72.67 | 80.67 | 78.23 |
| 0.15 | 74.23 | 82.69 | 80.21 |
| 0.25 | 73.76 | 81.86 | 79.53 |
| 0.50 | 72.92 | 80.49 | 78.34 |
🔼 This ablation study investigates the impact of the motion weight αkf (alpha_{kf}) on the performance of the SAMURAI model. The study varies the αkf value and reports the resulting Area Under the Curve (AUC), normalized precision (Pnorm), and precision (P) metrics on the LaSOT dataset. This shows how sensitive the model’s performance is to different levels of weighting given to motion information in the tracking process.
read the caption
Table 4: Ablation on the sensitivity of the motion weight αkfsubscript𝛼𝑘𝑓\alpha_{kf}italic_α start_POSTSUBSCRIPT italic_k italic_f end_POSTSUBSCRIPT.
| Trackers | LaSOT AUC(%) | LaSOT Pnorm(%) | LaSOT P(%) | LaSOText AUC(%) | LaSOText Pnorm(%) | LaSOText P(%) |
|---|---|---|---|---|---|---|
| SAM2.1-T [34] | 66.70 | 73.70 | 71.22 | 52.25 | 62.03 | 60.30 |
| SAMURAI-T | 69.28 (+2.58) | 76.39 (+2.69) | 73.78 (+2.56) | 55.13 (+2.88) | 65.60 (+2.57) | 63.72 (+3.42) |
| SAM2.1-S [34] | 66.47 | 73.67 | 71.25 | 56.11 | 67.57 | 65.81 |
| SAMURAI-S | 70.04 (+3.57) | 77.55 (+3.88) | 75.23 (+3.98) | 57.99 (+1.88) | 69.60 (+2.03) | 67.73 (+1.92) |
| SAM2.1-B [34] | 65.97 | 73.54 | 70.96 | 55.51 | 67.17 | 64.55 |
| SAMURAI-B | 70.65 (+4.68) | 78.69 (+4.15) | 76.21 (+5.25) | 57.48 (+1.97) | 69.28 (+2.11) | 67.09 (+2.54) |
| SAM2.1-L [34] | 68.54 | 76.16 | 73.59 | 58.55 | 71.10 | 68.83 |
| SAMURAI-L | 74.23 (+5.69) | 82.69 (+6.53) | 80.21 (+6.62) | 61.03 (+2.48) | 73.86 (+2.76) | 72.24 (+3.41) |
🔼 This table presents a comparison of the performance of the proposed SAMURAI visual object tracking method against a baseline SAM-based tracking method. It shows the AUC, normalized precision (Pnorm), and precision (P) scores achieved by both methods on the LaSOT and LaSOText datasets, broken down by different sizes of the model (T, S, B, L). The results highlight the improvements in tracking accuracy achieved by SAMURAI compared to the baseline method across various metrics and model sizes.
read the caption
Table 5: Visual object tracking results of the proposed SAMURAI compare to the baseline SAM-based tracking method.
| Trackers | LaSOT | LaSOText |
|---|---|---|
| SAM2.1-B [34] | 64.7 | 53.4 |
| SAMURAI-B | 69.6 | 54.8 |
| % Gain | +7.6% | +2.6% |
| SAM2.1-L [34] | 67.3 | 56.6 |
| SAMURAI-L | 73.1 | 58.4 |
| % Gain | +8.9% | +3.2% |
| ARC | BC | |
| SAM2.1-B [34] | 62.8 | 67.7 |
| SAMURAI-B | 68.0 | 73.1 |
| % Gain | +8.3% | +8.0% |
| SAM2.1-L | 64.3 | 69.4 |
| SAMURAI-L | 69.5 | 77.0 |
| % Gain | +8.1% | +11.0% |
🔼 Table 6 presents a detailed breakdown of the Area Under the Curve (AUC) performance metric for the LaSOT and LaSOText datasets, categorized by various attributes. These attributes represent different challenges in visual object tracking, such as changes in illumination, motion blur, occlusion, and object scale. The table compares the performance of the baseline SAM2.1 method with the enhanced SAMURAI tracker for each attribute, highlighting where SAMURAI offers significant improvements and demonstrating its robustness across diverse tracking conditions.
read the caption
Table 6: Attribute-wise AUC(%) Results for LaSOT [16] and LaSOTextext{}_{\text{ext}}start_FLOATSUBSCRIPT ext end_FLOATSUBSCRIPT [17].
Full paper#