↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Open-vocabulary semantic segmentation is challenging due to the need for extensive training data. Existing methods often underperform or require computationally expensive techniques. This paper introduces ITACLIP, a training-free approach that addresses these issues.
ITACLIP enhances the CLIP model with architectural modifications, utilizing self-attention mechanisms to refine feature extraction. It also incorporates large language models to generate richer class descriptions and applies image augmentation techniques to improve input data representation. The results demonstrate that ITACLIP significantly outperforms existing methods on various benchmarks, providing a highly effective and efficient solution for open-vocabulary semantic segmentation.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents ITACLIP, a novel training-free method for semantic segmentation that surpasses current state-of-the-art techniques. Its innovative architectural enhancements and integration of LLMs offer a scalable and cost-effective solution for open-vocabulary segmentation tasks. This opens avenues for researchers working with limited annotated data and promotes advancements in zero-shot learning within computer vision.
Visual Insights#

🔼 Figure 1 presents a qualitative comparison of three different training-free semantic segmentation methods: ITACLIP (the authors’ method), SCLIP [60], and NACLIP [24]. The figure showcases the segmentation results for several images from the COCO-Stuff dataset [8]. Each image is accompanied by its ground truth segmentation mask and the segmentation masks generated by the three methods. This visual comparison allows for a direct assessment of the relative performance of the different approaches in terms of accuracy and detail.
read the caption
Figure 1: Qualitative comparison of training-free semantic segmentation methods. We compare ITACLIP with SCLIP [60] and NACLIP [24] using images from the COCO-Stuff [8] dataset. Additional visualizations are included in the Appendix.
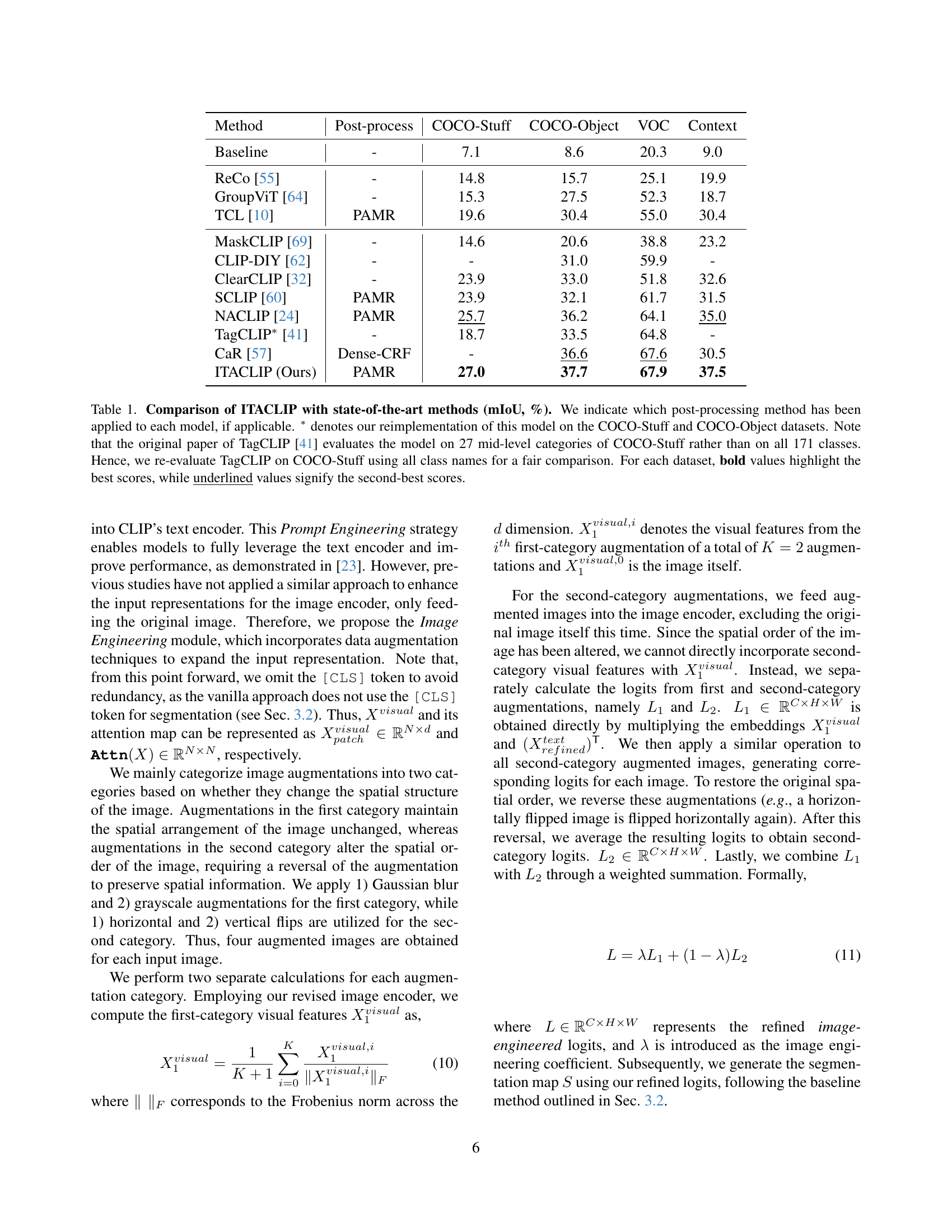
| Method | Post-process | COCO-Stuff | COCO-Object | VOC | Context |
|---|---|---|---|---|---|
| Baseline | - | 7.1 | 8.6 | 20.3 | 9.0 |
| ReCo [55] | - | 14.8 | 15.7 | 25.1 | 19.9 |
| GroupViT [64] | - | 15.3 | 27.5 | 52.3 | 18.7 |
| TCL [10] | PAMR | 19.6 | 30.4 | 55.0 | 30.4 |
| MaskCLIP [69] | - | 14.6 | 20.6 | 38.8 | 23.2 |
| CLIP-DIY [62] | - | - | 31.0 | 59.9 | - |
| ClearCLIP [32] | - | 23.9 | 33.0 | 51.8 | 32.6 |
| SCLIP [60] | PAMR | 23.9 | 32.1 | 61.7 | 31.5 |
| NACLIP [24] | PAMR | 25.7 | 36.2 | 64.1 | 35.0 |
| TagCLIP* [41] | - | 18.7 | 33.5 | 64.8 | - |
| CaR [57] | Dense-CRF | - | 36.6 | 67.6 | 30.5 |
| ITACLIP (Ours) | PAMR | 27.0 | 37.7 | 67.9 | 37.5 |
🔼 Table 1 presents a comparison of the ITACLIP model’s performance against other state-of-the-art methods for semantic segmentation. The comparison is based on four common datasets: COCO-Stuff, COCO-Object, VOC, and Context. The mIoU (mean Intersection over Union) metric is used to evaluate the performance of each model on each dataset. The table also indicates which post-processing methods (if any) were applied to each model for a fair comparison. A note is included to explain that the TagCLIP results presented were re-implemented by the authors of this paper, using all class names instead of the original paper’s 27 mid-level categories, to provide a consistent and fair comparison across all models. The best score for each dataset is highlighted in bold, with the second-best score underlined.
read the caption
Table 1: Comparison of ITACLIP with state-of-the-art methods (mIoU, %). We indicate which post-processing method has been applied to each model, if applicable. ∗ denotes our reimplementation of this model on the COCO-Stuff and COCO-Object datasets. Note that the original paper of TagCLIP [41] evaluates the model on 27 mid-level categories of COCO-Stuff rather than on all 171 classes. Hence, we re-evaluate TagCLIP on COCO-Stuff using all class names for a fair comparison. For each dataset, bold values highlight the best scores, while underlined values signify the second-best scores.
In-depth insights#
CLIP Enhancement#
CLIP enhancement is a significant area of research focusing on improving the capabilities of CLIP (Contrastive Language-Image Pre-training) models. Core enhancements revolve around architectural modifications, such as enhancing the attention mechanisms within the model or modifying the final layer of the Vision Transformer to better capture spatial information crucial for tasks like semantic segmentation. Another key area is data augmentation, which aims to enrich the input image representations by applying various transformations, thereby improving the model’s robustness and generalization performance. Further research is incorporating large language models (LLMs) to augment the text input by generating synonyms or definitions, leveraging the open-vocabulary capabilities of CLIP more effectively. The combination of these improvements showcases a promising direction for future research; refined architectural changes in the model coupled with sophisticated data augmentation and LLM-based text enhancement could potentially lead to significant breakthroughs in training-free semantic segmentation and various open-vocabulary computer vision tasks.
Arch. Modifications#
The architectural modifications section of this paper focuses on enhancing CLIP’s performance for semantic segmentation. Key changes include replacing the standard self-attention mechanism with self-self attention (query-query and key-key), removing the feed-forward network (FFN) in the final layer, and incorporating attention maps from intermediate layers into the final layer’s calculations. These modifications aim to improve the model’s ability to localize objects accurately and utilize richer feature representations from across different levels of the network. The rationale is that combining self-attention with intermediate attention maps better captures spatial context and enhances the model’s ability to generate more precise segmentation masks, ultimately improving the accuracy of the segmentation results. The removal of the FFN is driven by the observation that it may hinder performance in dense prediction tasks. Overall, the architectural changes represent a thoughtful refinement of CLIP’s architecture targeted towards improving semantic segmentation, rather than a complete redesign.
LLM Integration#
LLM integration in this research paper significantly enhances the capabilities of training-free semantic segmentation. The approach leverages LLMs not just for simple class name expansion but for generating richer contextual information, including synonyms and definitions. This contextual enrichment allows the model to better understand and represent the semantic nuances of each class, leading to improved segmentation accuracy. The integration is systematic, using LLMs as a tool to generate auxiliary textual data for each class, which is then processed along with the original class names by the model’s text encoder. This contrasts with more ad-hoc methods, making the approach more robust and scalable across various datasets. A key takeaway is that LLM integration is not simply about enhancing text data, but about providing a more robust understanding of the semantic space that directly improves the image analysis and classification. The strategic use of LLMs as a data augmentation tool within a systematic framework showcases a powerful and efficient approach to boost training-free semantic segmentation performance.
Image Engineering#
The concept of ‘Image Engineering’ in the context of training-free semantic segmentation is a powerful innovation. It cleverly addresses the limitations of relying solely on the original image by augmenting the input data. This augmentation strategy, carefully categorized into transformations preserving spatial structure (e.g., Gaussian blur, grayscale) and those altering it (e.g., horizontal/vertical flips), significantly enriches the model’s understanding of the input. The reversal of spatially-altering augmentations is a crucial detail ensuring the preservation of crucial positional information. This dual approach allows for a robust exploration of image features, creating more comprehensive image embeddings. The combination of these augmented features with the original image representation effectively leverages the strengths of both while mitigating potential weaknesses of solely relying on the output from either strategy. This multi-faceted approach, therefore, demonstrates a sophisticated understanding of the challenges inherent in training-free methods and offers a very promising solution for improving their performance.
Zero-shot OVSS#
Zero-shot Open-Vocabulary Semantic Segmentation (OVSS) tackles a significant challenge in computer vision: segmenting images into classes not seen during model training. This is a substantial leap from traditional semantic segmentation which relies on predefined classes, thereby limiting generalizability. Zero-shot OVSS leverages the power of Vision Language Models (VLMs), like CLIP, which learn representations of both images and text. This allows the model to understand the semantic meaning of class names, even unseen ones, through textual descriptions and generalize to new image-class pairings. The key to success lies in effective bridging of the image and text modalities, allowing the model to map the visual features to the correct textual label. The approach is highly appealing because of its potential for reducing the need for extensive pixel-level annotations during training, which is usually costly and time-consuming. However, zero-shot OVSS still faces limitations, particularly in accuracy and robustness. Performance often lags behind supervised methods. Further research focuses on improving the accuracy and capability of VLMs to transfer knowledge effectively for improved zero-shot segmentation performance.
More visual insights#
More on figures

🔼 Figure 2 illustrates the ITACLIP model architecture. The model takes an original image as input and augments it using various techniques. Both the original and augmented images are fed into a modified image encoder, which incorporates architectural enhancements (self-attention modifications and removal of the feed-forward network). The encoder outputs image embeddings. Simultaneously, an LLM generates auxiliary text (definitions or synonyms) for each class label, which is then processed by a text encoder to create text embeddings. Image and text embeddings are combined using weighted summations controlled by parameters λ (lambda) for image engineering and α (alpha) for auxiliary text integration. The final output is a refined segmentation map.
read the caption
Figure 2: Overview of ITACLIP. Our method integrates image, text, and architectural enhancements to produce a more accurate segmentation map. We apply various data augmentation techniques, then process both the original and augmented images through a modified image encoder to obtain image embeddings. We also utilize an LLM to generate auxiliary texts (e.g., definitions or synonyms) for each original class name. The λ𝜆\lambdaitalic_λ and α𝛼\alphaitalic_α symbols denote the image engineering and auxiliary text coefficients used in weighted summations, respectively.

🔼 This figure visualizes attention maps from different layers of a CLIP-ViT-B/16 model for a single randomly selected image patch. The red rectangle highlights the location of the chosen patch within the image. The visualization shows how the attention mechanism focuses on different aspects of the image at different layers. Shallow layers show localized attention around the patch, while deeper layers exhibit more global attention, encompassing semantically relevant regions beyond the immediate patch. Layer 12, the final layer of the model, provides the most informative attention map for object recognition. This figure demonstrates the concept of how the attention evolves across layers, emphasizing the spatial and contextual information captured at different depths. The inclusion of attention maps from multiple layers is critical to the model’s proposed architecture.
read the caption
Figure 3: Visualization of attention maps from various layers for a selected patch. The red rectangle indicates the position of the randomly selected patch. Note that we use CLIP-ViT-B/16 as our visual backbone, with Layer 12 serving as the final layer.

🔼 This figure shows the prompt used to generate definitions using the LLaMa language model. The prompt instructs the model to provide concise definitions of given words, similar to the example definitions provided. The example definitions are of ‘house’ and ‘car’. The input word for the prompt in the example is ‘bicycle’. The model’s generated response is also displayed, demonstrating how the model produces a short definition of the input word in the style of the provided examples. This process is a component of the ITACLIP model’s auxiliary text generation.
read the caption
(a) We employ the illustrated prompt to generate definitions.

🔼 This figure shows the prompt used to generate synonyms for a given word using the LLaMa language model. The prompt instructs the model to provide a single-word synonym for a given word, and if a synonym does not exist, to provide the closest meaning. The example illustrates the input word ‘aeroplane’ and the model’s output, ‘aircraft’. This process aids in enriching the text input to the CLIP model by providing additional textual information beyond the original class names, thereby enhancing the segmentation accuracy.
read the caption
(b) We employ the illustrated prompt to generate synonyms.

🔼 This figure shows the process of generating auxiliary texts (definitions and synonyms) for a given class name using the LLaMa 3 language model. Panel (a) illustrates generating definitions using a prompt that requests a brief definition and examples to guide the model in creating an appropriate definition. Panel (b) shows how synonyms are generated using a prompt requesting a single-word synonym or the closest meaning if a synonym does not exist.
read the caption
Figure 4: Procedure for generating auxiliary texts for a given class name.
More on tables
| Attention Combination | VOC |
|---|---|
| q-k | 19.0 |
| q-q | 58.9 |
| k-k | 52.2 |
| v-v | 57.7 |
| q-q + k-k | 67.9 |
| q-q + v-v | 64.9 |
| q-q + k-k + v-v | 66.4 |
🔼 This table presents the results of an ablation study on the impact of different self-attention mechanisms within the ITACLIP model. Specifically, it investigates the performance of various combinations of self-attention types (query-query, key-key, and value-value) on the Pascal VOC dataset. The goal is to determine which combination yields the best segmentation performance, providing insights into the effectiveness of different self-attention strategies.
read the caption
Table 2: Self-self attention combinations. We evaluate our method with different self-self attention combinations on Pascal VOC. v-v represents the value-value attention.
| Method | FFN | Stuff | Object | VOC | Context |
|---|---|---|---|---|---|
| ITACLIP | ✓ | 26.3 | 36.9 | 66.3 | 36.3 |
| ITACLIP | ✗ | 27.0 | 37.7 | 67.9 | 37.5 |
🔼 This table presents the ablation study results focusing on the impact of removing the feed-forward network (FFN) from the final layer of the Vision Transformer (ViT) in the ITACLIP model. It shows the mean Intersection over Union (mIoU) scores for different semantic segmentation datasets: COCO-Stuff (evaluating ‘stuff’ classes), COCO-Object (evaluating ‘object’ classes which are simplified from COCO-Stuff), and Pascal VOC. The results demonstrate how removing the FFN affects the performance of the model on various datasets.
read the caption
Table 3: Removing the feed-forward block. “Stuff” and “Object” refer to the COCO-Stuff and COCO-Object, respectively.
| Intermediate Layers () | VOC |
|---|---|
| ✗ | 65.0 |
| {7} | 65.4 |
| {8} | 65.5 |
| {7, 8} | 65.5 |
| {7, 8, 10} | 65.6 |
| {7, 8, 9, 10} | 65.5 |
🔼 This table investigates the effect of incorporating attention maps from intermediate layers of the CLIP model’s visual encoder into the final layer’s attention map for improved semantic segmentation. The experiment focuses on the Pascal VOC dataset. The rows represent different combinations of intermediate layers included, while the columns present the resulting mean Intersection over Union (mIoU) scores. The ‘X’ entry indicates that only the final layer’s attention map was used, serving as a baseline for comparison.
read the caption
Table 4: Impact of selected intermediate layers. We assess ITACLIP with various intermediate layers on Pascal VOC. ✗ indicates that the model does not use intermediate layers for evaluation.
| Method | PAMR | Stuff | Object | VOC | Context |
|---|---|---|---|---|---|
| ITACLIP | ✗ | 26.3 | 36.4 | 65.6 | 36.0 |
| ITACLIP | ✓ | 27.0 | 37.7 | 67.9 | 37.5 |
🔼 Table 5 presents a comparison of the performance of the ITACLIP model with and without the application of post-processing using Pixel-Adaptive Mask Refinement (PAMR). The table shows the mean Intersection over Union (mIoU) scores achieved on four semantic segmentation benchmark datasets: COCO-Stuff, COCO-Object, Pascal VOC, and Pascal Context. This allows for assessing the impact of PAMR on the model’s overall accuracy and highlighting its contribution to enhancing segmentation quality.
read the caption
Table 5: Influence of post-processing operation. Comparing the performance of ITACLIP with and without PAMR on all datasets.
| Method | LTG | IE | Context | Stuff |
|---|---|---|---|---|
| ITACLIP | ✗ | ✗ | 34.3 | 24.5 |
| ITACLIP | ✓ | ✗ | 34.6 | 24.8 |
| ITACLIP | ✓ | ✓ | 35.4 | 25.4 |
🔼 This table presents an ablation study evaluating the impact of two key modules in the ITACLIP model: Image Engineering (IE) and LLM-based Text Generation (LTG). It shows the model’s performance on the Pascal Context and COCO-Stuff datasets with different combinations of these modules enabled or disabled. The results demonstrate the individual and combined contributions of each module to the overall segmentation accuracy.
read the caption
Table 6: Effect of Image Engineering and LLM-based Text Generation modules. LTG and IE represent the LLM-based Text Generation and Image Engineering modules, respectively.
| Method | Stride | Stuff | Object | VOC | Context |
|---|---|---|---|---|---|
| ITACLIP | 224 | 25.3 | 36.7 | 66.1 | 36.9 |
| ITACLIP | 112 | 26.6 | 37.4 | 67.1 | 37.4 |
| ITACLIP | 56 | 26.9 | 37.7 | 67.9 | 37.5 |
| ITACLIP | 28 | 27.0 | 37.7 | 67.9 | 37.5 |
🔼 This table investigates the impact of different stride values on the performance of the ITACLIP model across four semantic segmentation datasets: COCO-Stuff, COCO-Object, Pascal VOC, and Pascal Context. The stride value affects the speed and resolution of the segmentation process, with smaller strides potentially offering better accuracy at the cost of increased computational time. The results show how the mIoU score varies across different stride values for each dataset, enabling the researchers to determine the optimal balance between computational efficiency and segmentation quality.
read the caption
Table 7: Role of stride value. We investigate the role of the stride value in our method across all four datasets.
| λ | α | Context |
|---|---|---|
| 0.75 | 0.15 | 36.0 |
| 0.6 | 0.15 | 35.9 |
| 0.5 | 0.15 | 35.8 |
| 0.75 | 0.2 | 35.9 |
| 0.5 | 0.2 | 35.7 |
| 0.6 | 0.2 | 35.9 |
| 0.6 | 0.1 | 35.9 |
| 0.5 | 0.1 | 35.8 |
🔼 This table presents an ablation study analyzing the effect of the hyperparameters λ (lambda), representing the Image Engineering coefficient, and α (alpha), representing the Auxiliary Text coefficient, on the model’s performance. The experiment is conducted without the post-processing technique PAMR to isolate the impact of λ and α. Different values for λ and α are tested to determine their influence on model performance, measured on several benchmark datasets.
read the caption
Table 8: Effect of Hyperparameters. λ𝜆\lambdaitalic_λ and α𝛼\alphaitalic_α denote the Image Engineering and Auxiliary Text Coefficients, respectively. The experiments are conducted without applying PAMR.
| Hyperparameter | Stuff | Object | VOC | Context |
|---|---|---|---|---|
| λ | 0.75 | 0.75 | 0.7 | 0.75 |
| α | 0.2 | 0.1 | 0.05 | 0.15 |
🔼 Table 9 shows the values used for the hyperparameters λ (lambda) and α (alpha) in the ITACLIP model experiments. Lambda controls the weighting between first-category and second-category image features during image engineering, while alpha balances the contribution of original class names and LLM-generated auxiliary texts in the text embeddings. These hyperparameters were tuned and set for all four datasets used in the ITACLIP model evaluation (COCO-Stuff, COCO-Object, Pascal Context, Pascal VOC).
read the caption
Table 9: Hyperparameter values used in our experiments.
| Backbone | VOC |
|---|---|
| ViT-L/14 | 53.3 |
| ViT-B/32 | 56.7 |
| ViT-B/16 | 67.9 |
🔼 This table presents a comparison of the performance of the ITACLIP model when using different visual backbones. It shows the mean Intersection over Union (mIoU) scores achieved on the Pascal VOC dataset for three different visual backbone architectures: ViT-L/14, ViT-B/32, and ViT-B/16. The results highlight the impact of the visual backbone choice on the overall model performance, indicating which architecture is most effective for the ITACLIP semantic segmentation method.
read the caption
Table 10: Impact of different visual backbones. We compare the performance of ITACLIP with different visual backbones.
| Method | Background Set | Object |
|---|---|---|
| ITACLIP | ✗ | 34.5 |
| ITACLIP | ✓ | 37.7 |
🔼 This table presents an ablation study evaluating the impact of using a defined background set on the performance of the ITACLIP model for semantic segmentation on the COCO-Object dataset. The results demonstrate a significant improvement in performance when a specific background set is included in the model’s input, highlighting its importance in distinguishing between foreground and background elements. The table compares the mIoU scores obtained with and without this defined background set, clearly showing the benefit of using it.
read the caption
Table 11: Effect of background set. ITACLIP performs better when the background set is employed.
Full paper#