↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) are rapidly advancing but suffer from a lack of transparency in data sources and model development processes. Existing high-performing models often lack publicly available datasets, hindering open-source development. This paper aims to address this issue by providing extensive data and insights into building better LLMs.
The researchers introduce RedPajama, comprising two datasets: RedPajama-V1, which replicates the LLaMA training dataset, and RedPajama-V2, a massive web-only dataset augmented with quality metadata. They conduct various experiments using these datasets to evaluate the relationship between data quality and LLM performance, showcasing how RedPajama can advance the development of transparent and high-performing LLMs. The availability of these datasets and accompanying analysis encourages broader participation in developing better LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the lack of transparency and data availability in large language model (LLM) development. By releasing two massive, open datasets – RedPajama-V1 (a reproduction of the LLaMA dataset) and RedPajama-V2 (a web-only dataset with quality signals) – and providing detailed analysis and ablation studies, it empowers researchers to develop more transparent and performant open-source LLMs. It also facilitates further research into optimal data composition and filtering techniques for LLMs, setting a new standard for future high-quality web datasets. This significantly impacts the LLM field by fostering collaboration, accelerating open-source model development and promoting the understanding of the relationship between training data and model performance.
Visual Insights#

🔼 This figure illustrates the various open-source large language models (LLMs) that have been trained using the RedPajama datasets. RedPajama-V1 and RedPajama-V2 are shown as the foundational datasets. Several downstream LLMs, such as OpenELM, OLMo, Snowflake’s Arctic, and the RedPajama-INCITE models, are depicted as having been trained with data from these datasets, highlighting the contribution of RedPajama to the open-source LLM ecosystem. The figure also shows SlimPajama, a cleaned and deduplicated version of RedPajama-V1.
read the caption
Figure 1: The ecosystem around the RedPajama datasets. RedPajama has provided pretraining data for multiple open-source LLMs, including OpenELM [36], OLMo [19], Snowflake’s Arctic [54] and RedPajama-INCITE. SlimPajama is a cleaned and deduplicated version of RedPajama-V1.
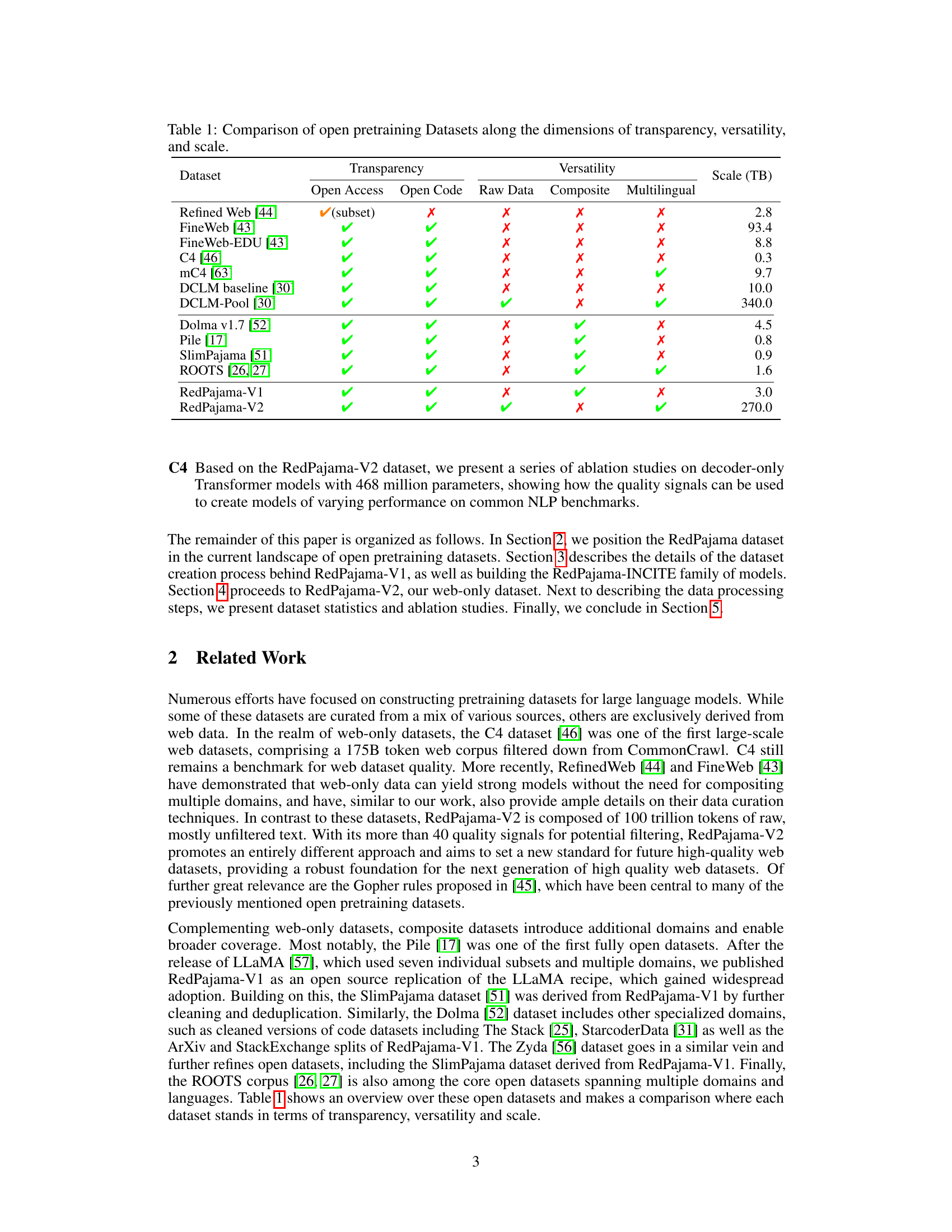
| Dataset | Transparency | Versatility | Scale (TB) | |||||
|---|---|---|---|---|---|---|---|---|
| Open Access | Open Code | Raw Data | Composite | Multilingual | ||||
| Refined Web [44] | ✔(subset) | ✗ | ✗ | ✗ | ✗ | 2.8 | ||
| FineWeb [43] | ✔ | ✔ | ✗ | ✗ | ✗ | 93.4 | ||
| FineWeb-EDU [43] | ✔ | ✔ | ✗ | ✗ | ✗ | 8.8 | ||
| C4 [46] | ✔ | ✔ | ✗ | ✗ | ✗ | 0.3 | ||
| mC4 [63] | ✔ | ✔ | ✗ | ✗ | ✔ | 9.7 | ||
| DCLM baseline [30] | ✔ | ✔ | ✗ | ✗ | ✗ | 10.0 | ||
| DCLM-Pool [30] | ✔ | ✔ | ✔ | ✗ | ✔ | 340.0 | ||
| Dolma v1.7 [52] | ✔ | ✔ | ✗ | ✔ | ✗ | 4.5 | ||
| Pile [17] | ✔ | ✔ | ✗ | ✔ | ✗ | 0.8 | ||
| SlimPajama [51] | ✔ | ✔ | ✗ | ✔ | ✗ | 0.9 | ||
| ROOTS [26, 27] | ✔ | ✔ | ✗ | ✔ | ✔ | 1.6 | ||
| RedPajama-V1 | ✔ | ✔ | ✗ | ✔ | ✗ | 3.0 | ||
| RedPajama-V2 | ✔ | ✔ | ✔ | ✗ | ✔ | 270.0 |
🔼 This table compares several open-source large language model (LLM) pretraining datasets across three key aspects: transparency (whether the dataset’s creation process and composition are openly documented and accessible), versatility (the range of sources and domains included in the dataset), and scale (the total size of the dataset in terabytes). It provides a valuable overview of the characteristics of different publicly available datasets, aiding researchers in selecting appropriate datasets for their own work. Each dataset is assessed based on whether it has open access, open source code, and whether it contains raw data or only a composite, as well as if it is multilingual.
read the caption
Table 1: Comparison of open pretraining Datasets along the dimensions of transparency, versatility, and scale.
In-depth insights#
Open LLM Datasets#
The landscape of open large language model (LLM) datasets is complex and dynamic. Accessibility is a major hurdle; while some datasets are publicly available, many remain proprietary, hindering open research and development. Transparency is another key issue; the composition and curation methods of many datasets are opaque, making it difficult to evaluate their impact and potential biases. Scale presents a third challenge, as high-performance LLMs require massive datasets, demanding significant computational resources and expertise to curate. Therefore, initiatives like the RedPajama project are critical for fostering progress in open LLMs by addressing these challenges; providing large, openly licensed datasets with associated metadata and quality signals is crucial. This enhances reproducibility, comparability, and allows researchers to effectively curate subsets better suited to specific tasks and avoiding potential biases. The long-term goal is a collaborative ecosystem where open datasets drive innovation and democratize access to this transformative technology.
RedPajama-V1/V2#
The RedPajama project introduces two significant open-source datasets for large language model (LLM) training: RedPajama-V1 and RedPajama-V2. RedPajama-V1 serves as a meticulously recreated replication of the LLaMA training dataset, offering transparency and accessibility to researchers. However, RedPajama-V2 represents a substantial departure, focusing exclusively on a massive web-only dataset. Unlike V1, it prioritizes scale and versatility, providing raw, unfiltered web data exceeding 100 trillion tokens along with comprehensive quality signals. These signals empower researchers to curate high-quality subsets, facilitating the development and evaluation of novel data filtering techniques. The difference in approach between the two highlights a shift from precise replication to a broader, more flexible resource for LLM development.
Ablation Studies#
Ablation studies, in the context of large language model (LLM) research, are crucial for understanding the contribution of different dataset components or model features to overall performance. They involve systematically removing or altering specific aspects of the system and observing the impact on downstream tasks. In the RedPajama paper, ablation studies likely investigated the effects of various data filtering techniques on model quality. The results would highlight the importance of specific data characteristics and the effectiveness of different data cleaning strategies. By removing certain data subsets (e.g., low-quality web data or duplicated content), researchers could assess the impact on benchmark scores, perplexity, and other relevant metrics. Such analyses would reveal which data sources and filtering methods are most vital for training high-performing and robust LLMs. This is particularly important because open-source LLMs often face challenges in data quality. The ablation studies’ findings could guide future dataset creation and curation efforts for open-source LLM projects, providing valuable insights into how data composition and quality control significantly influence model performance and generalization.
Data Quality Signals#
The concept of ‘Data Quality Signals’ is crucial for training robust large language models (LLMs). The paper highlights the importance of not just quantity but also quality of data. Instead of filtering out noisy web data, the authors propose enriching the dataset with various quality signals. These signals provide crucial metadata, allowing for more nuanced curation. This approach prioritizes versatility, enabling users to build datasets tailored to specific needs, rather than prescribing a single ‘perfect’ dataset. Transparency is also key; making quality signals openly available fosters research into better data filtering methods. The use of multiple signals covering natural language, repetitiveness, content quality, and ML-based heuristics, ensures a multifaceted understanding of data quality. This strategy facilitates iterative dataset improvement, promoting the development of higher-performing and more reliable LLMs.
Future Research#
Future research directions stemming from the RedPajama project are plentiful. Improving data filtering techniques is crucial, exploring more sophisticated methods beyond simple heuristics. This involves investigating advanced machine learning models for quality assessment, possibly incorporating multi-modal analysis to enhance filtering precision. Addressing biases and ethical concerns inherent in large language models trained on web data is also paramount; research on bias detection and mitigation strategies would significantly contribute to responsible development. Furthermore, the scalability of data processing and model training is a major challenge. Future work could focus on developing more efficient and sustainable data curation and training processes, particularly for handling datasets of this magnitude. Finally, investigation into the relationship between dataset diversity, quality signals, and downstream model performance warrants further study, ultimately guiding best practices for creating optimal LLMs.
More visual insights#
More on figures

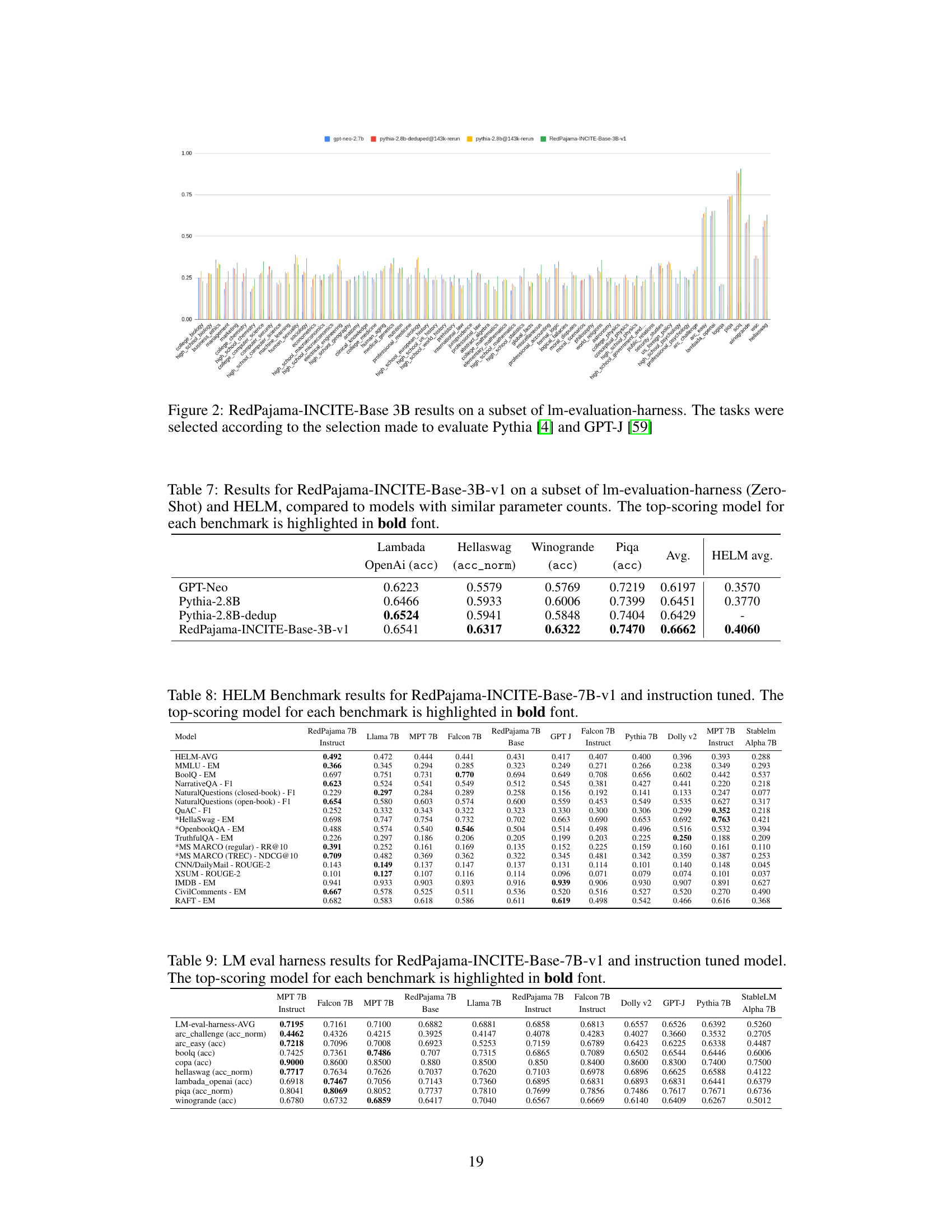
🔼 Figure 2 presents a comparison of the RedPajama-INCITE-Base 3B model’s performance against other open-source language models, namely Pythia and GPT-J, across a subset of tasks from the lm-evaluation-harness benchmark. The selected tasks were chosen to align with the evaluation performed in the original Pythia and GPT-J papers. This allows for a direct comparison of the RedPajama model to these established benchmarks. The figure provides a visual representation of the performance differences on each task, highlighting the relative strengths and weaknesses of the RedPajama model.
read the caption
Figure 2: RedPajama-INCITE-Base 3B results on a subset of lm-evaluation-harness. The tasks were selected according to the selection made to evaluate Pythia [4] and GPT-J [59]

🔼 This figure shows the chronological count of documents from the Common Crawl dataset for each snapshot, both before and after deduplication. The deduplication process starts with the most recent snapshot and proceeds sequentially to the oldest. The graph visually demonstrates how the number of documents changes over time as the deduplication process removes redundant entries. The x-axis represents the Common Crawl snapshots in chronological order, and the y-axis represents the number of documents.
read the caption
Figure 3: Chronological count of documents for each CommonCrawl snapshot before and after deduplication. Deduplication is performed sequentially, starting from the most recent snapshot and iterating until the oldest snapshot.

🔼 This figure displays histograms visualizing the distributions of six quality metrics generated by the CCNet pipeline. These metrics offer insights into the characteristics of text data used to train large language models. The metrics shown represent various aspects of text quality, such as language identification score, text length (in characters and lines), and perplexity scores from a language model trained on Wikipedia. Understanding these distributions helps in assessing the quality and diversity of the training data and potentially informs data filtering strategies for improved model performance.
read the caption
Figure 4: Histograms for the quality signals computed by the CCNet [61] pipeline.

🔼 This figure displays histograms visualizing the distributions of several Machine Learning (ML)-based quality signals. These signals are used to evaluate the quality of text data within the RedPajama-V2 dataset. Each histogram represents a different quality metric, providing a visual representation of its frequency distribution. This allows for the assessment of the dataset’s quality and facilitates informed decisions regarding data filtering and selection for downstream tasks. The specific metrics shown are detailed in Section 4.1.2 of the paper.
read the caption
Figure 5: Histograms for ML-based quality signals.

🔼 This figure presents histograms visualizing the distributions of various natural language-based quality signals extracted from the RedPajama-V2 dataset. These signals help assess the quality and characteristics of text documents, such as the proportion of uppercase words, the frequency of unique words, and the presence of certain punctuation marks. The distributions provide insights into the nature and variability of the web data included in the dataset, highlighting potential issues such as the prevalence of non-natural language content or repetitive text.
read the caption
Figure 6: Histograms for Natural language based quality signals.

🔼 This figure displays histograms visualizing the distribution of several quality metrics related to text repetitiveness within the RedPajama-V2 dataset. These metrics help assess the quality of the text data by quantifying the amount of repeated content. The histograms show how frequently different levels of repetitiveness occur across the dataset, offering valuable insights into the dataset’s composition and potential biases arising from redundant information.
read the caption
Figure 7: Histograms for quality signals measuring the repetitiveness of text.

🔼 This figure visualizes the topical clusters within the RedPajama-V2 dataset, specifically focusing on the 2021-04 snapshot’s 2 million unfiltered documents. Nomic Atlas, a topic modeling tool, was used to analyze the data using gte-large-en-v1.5 embeddings. The visualization helps understand the thematic distribution and relationships within the vast dataset.
read the caption
Figure 8: Visualization of topical clusters appearing in the RedPajama-V2 dataset. The clusters are computed in Nomic Atlas [41] based on gte-large-en-v1.5 embeddings for 2M documents of the unfiltered 2021-04 snapshot.
More on tables
| Dataset Slice | Token Count |
|---|---|
| CommonCrawl | 878B |
| C4 | 175B |
| GitHub | 59B |
| Books | 26B |
| ArXiv | 28B |
| Wikipedia | 24B |
| StackExchange | 20B |
| Total | 1.2T |
🔼 This table presents the token counts for each data source used in creating the RedPajama-V1 dataset, which is a reproduction of the LLaMA training dataset. The total number of tokens across all sources is shown, along with the breakdown for each individual component: Common Crawl, C4, GitHub, Books, Wikipedia, Stack Exchange, and ArXiv. This provides a quantitative overview of the dataset’s composition.
read the caption
Table 2: Token counts for the RedPajama-V1 dataset.
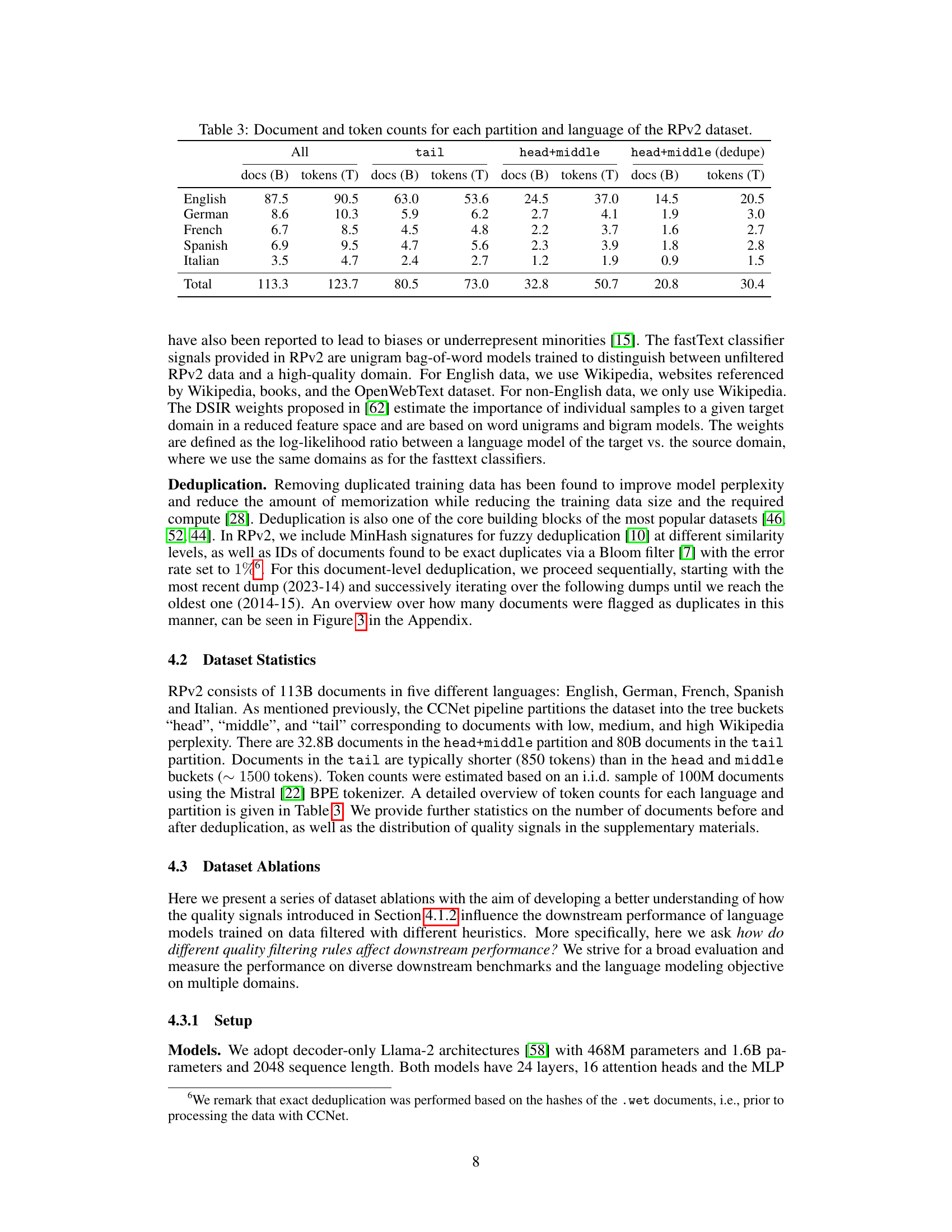
| All | tail | head+middle | head+middle (dedupe) | |
|---|---|---|---|---|
| docs (B) | tokens (T) | docs (B) | tokens (T) | |
| English | 87.5 | 90.5 | 63.0 | 53.6 |
| German | 8.6 | 10.3 | 5.9 | 6.2 |
| French | 6.7 | 8.5 | 4.5 | 4.8 |
| Spanish | 6.9 | 9.5 | 4.7 | 5.6 |
| Italian | 3.5 | 4.7 | 2.4 | 2.7 |
| Total | 113.3 | 123.7 | 80.5 | 73.0 |
🔼 This table presents a detailed breakdown of the RedPajama-V2 (RPv2) dataset, categorized by language and data partition. It shows the number of documents (in billions) and tokens (in trillions) within each partition (head, middle, tail, and the combined head+middle). The head+middle partition also includes a deduplicated count, representing the number of unique documents after removing duplicates. This allows for a comprehensive understanding of the dataset’s size and composition across different languages and quality levels.
read the caption
Table 3: Document and token counts for each partition and language of the RPv2 dataset.
| Task | Type | Random | Metric | Agg. BM-Eval |
|---|---|---|---|---|
| ANLI [40] | Natural language inference | 25.0 | acc | |
| ARC-c [13] | Natural language inference | 25.0 | acc_norm | |
| ARC-e [13] | Natural language inference | 25.0 | acc_norm | ✔ |
| Winogrande [48] | Coreference resolution | 50.0 | acc | ✔ |
| Hellaswag [64] | Sentence completion | 25.0 | acc_norm | ✔ |
| LAMBADA [42] | Sentence completion | 0.0 | acc | ✔ |
| CoQA [47] | Conversational QA | 0.0 | F1 | ✔ |
| MMLU [20] | Multiple-choice QA | 25.0 | acc | ✔ |
| OpenbookQA [38] | Multiple-choice QA | 25.0 | acc_norm | ✔ |
| PIQA [5] | Multiple-choice QA | 50.0 | acc_norm | ✔ |
| PubMedQA [23] | Multiple-choice QA | 33.3 | acc | ✔ |
| SciQ [60] | Multiple-choice QA | 25.0 | acc_norm | ✔ |
| SocialIQA [50] | Multiple-choice QA | 25.0 | acc | |
| TruthfulQA [33] | Multiple-choice QA | 25.0 | acc |
🔼 This table lists the benchmarks used to evaluate the performance of language models trained on different subsets of the RedPajama-V2 dataset. The benchmarks cover a range of natural language processing tasks, including natural language inference, coreference resolution, sentence completion, and question answering. The ‘Agg. BM-Eval’ column indicates which benchmark scores were included in the aggregated scores reported in Tables 5 and 6, which summarizes the overall performance across multiple benchmarks. This helps readers understand which tasks were considered most important in the overall evaluation.
read the caption
Table 4: Benchmarks used in our ablations. The column “Agg. BM-Eval” indicates whether the score is used in the aggregate scores reported in Tables 5 and 6.
| Dataset | Deduplication | Rule-based | ML Heuristics | Agg. BM-Eval (↑) | Val-Perplexity (↓) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exact | Fuzzy | C4 | Gopher | Classif. | DSIR | PPL | Avg. | Norm. Avg. | Rank-Score | Pile | Paloma | |
| C4 | 35.8 | 0.140 | 0.472 | 29.5 | 39.5 | |||||||
| Dolma-v1.7 CC | 36.0 | 0.140 | 0.511 | 21.4 | 38.3 | |||||||
| FineWeb | 36.5 | 0.146 | 0.644 | 26.8 | 33.6 | |||||||
| RefinedWeb | 37.9 | 0.165 | 0.650 | 19.1 | 32.8 | |||||||
| RPv1-CC | ✔(sharded) | ✔ (Wiki-Ref.) | 35.6 | 0.127 | 0.461 | 18.7 | 31.5 | |||||
| RPv2 (2023-14) | 36.4 | 0.141 | 0.594 | 19.7 | 31.1 | |||||||
| RPv2 (2023-14) | ✔ | 36.2 | 0.138 | 0.472 | 19.5 | 39.9 | ||||||
| RPv2 (2023-14) | ✔ | ✔ (full) | 37.6 | 0.160 | 0.700 | 24.9 | 34.5 | |||||
| RPv2 (2023-14) | ✔ | 36.8 | 0.150 | 0.622 | 36.3 | 56.9 | ||||||
| RPv2 (2023-14) | ✔ | ✔ (natlang) | 37.2 | 0.154 | 0.639 | 23.6 | 38.2 | |||||
| RPv2 (2023-14) | ✔ | ✔ (Rep.) | 37.5 | 0.158 | 0.633 | 20.4 | 36.0 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | 35.3 | 0.128 | 0.517 | 35.0 | 54.2 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (full) | 36.7 | 0.149 | 0.556 | 43.8 | 63.9 | ||||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (Rep.) | ✔ (Palm-mix) | 35.9 | 0.138 | 0.439 | 44.3 | 89.9 | |||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (Rep.) | ✔ (Palm-mix) | 35.9 | 0.139 | 0.483 | 43.8 | 67.1 | |||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (natlang) | ✔ (Palm-mix) | 36.7 | 0.152 | 0.550 | 41.8 | 67.9 | |||
| RPv2 (9 Dumps) | ✔ | ✔ (line-filter) | ✔ (natlang) | ✔ (Palm-mix) | 36.4 | 0.144 | 0.539 | 32.4 | 52.9 | |||
| RPv2 (9 Dumps) | ✔ | custom-rules | ✔ (Wiki-Ref.) | Pwiki>30 | 35.8 | 0.130 | 0.467 | 18.5 | 39.7 | |||
| RPv2 (9 Dumps) | ✔ | custom-rules + Gopher-Rep. | ✔ (Wiki-Ref.) | Pwiki>30 | 35.9 | 0.133 | 0.500 | 19.8 | 45.8 |
🔼 This table presents a performance comparison of a 468M parameter language model trained on various datasets. The datasets include different versions of the RedPajama dataset filtered using various techniques, alongside other state-of-the-art open web datasets. The model’s performance is evaluated across several NLP benchmarks. The results are summarized using three metrics: average accuracy, Rank-Score, and a normalized average score. The best, second-best, and third-best performing datasets for each metric are highlighted to facilitate comparison.
read the caption
Table 5: Evaluations for the 468M parameter LM for different dataset filters and other SOTA web datasets. The Benchmark scores are aggregated from the benchmarks outlined in Table 3, using (1) the average accuracy, (2) the Rank-Score, and (3) the normalized average score. The best score is indicated in bold underlined font, the second-best is bolded, and the third is in italics underlined.
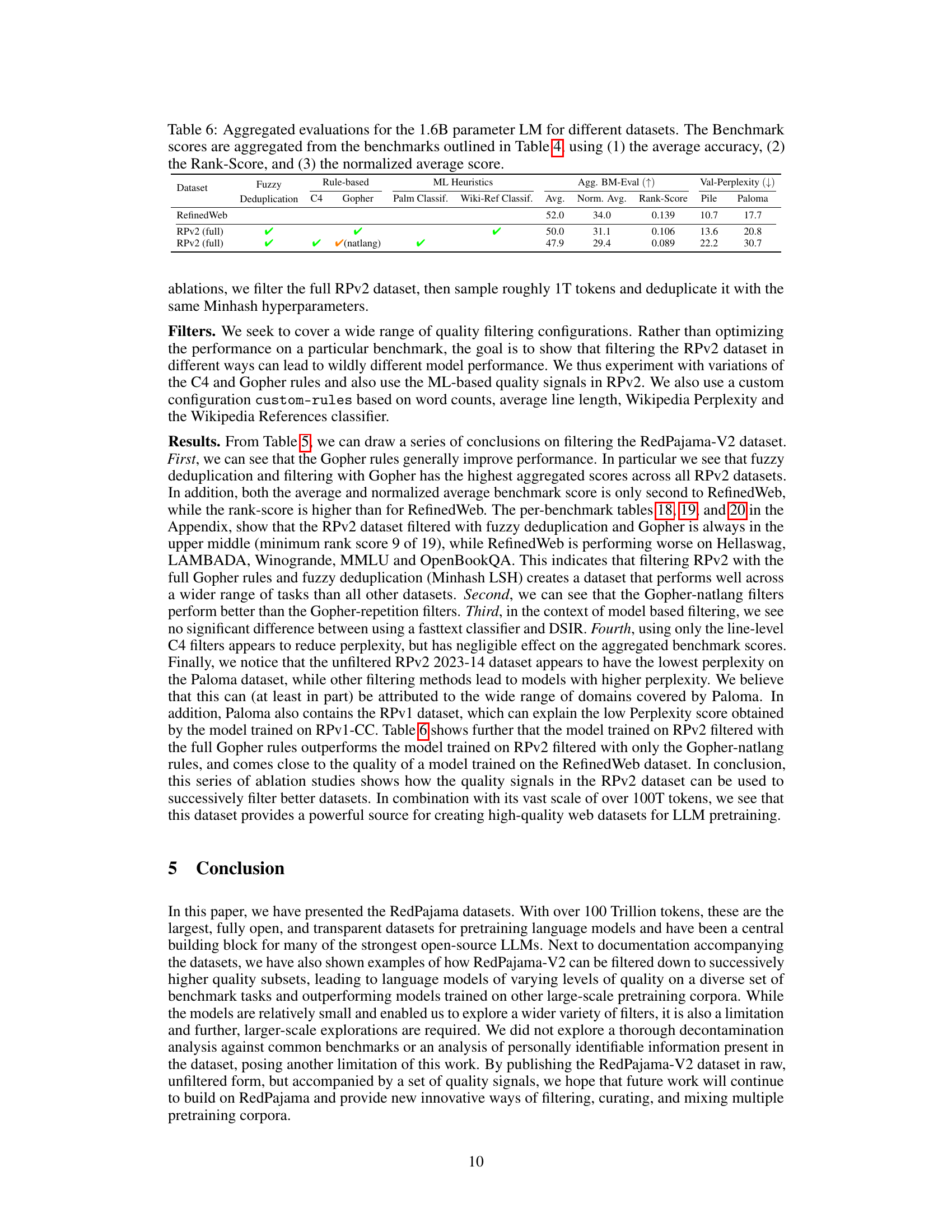
| Dataset | Fuzzy Deduplication | Rule-based C4 | Rule-based Gopher | Rule-based Palm Classif. | Rule-based Wiki-Ref Classif. | Rule-based Avg. | Rule-based Norm. Avg. | ML Heuristics Rank-Score | ML Heuristics Pile | ML Heuristics Paloma | Agg. BM-Eval (↑) | Val-Perplexity (↓) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RefinedWeb | 52.0 | 34.0 | 0.139 | 10.7 | 17.7 | |||||||
| RPv2 (full) | ✔ | ✔ | ✔ | 50.0 | 31.1 | 0.106 | 13.6 | 20.8 | ||||
| RPv2 (full) | ✔ | ✔ | ✔(natlang) | ✔ | ✔ | 47.9 | 29.4 | 0.089 | 22.2 | 30.7 |
🔼 Table 6 presents a performance comparison of a 1.6B parameter Language Model (LM) trained on various datasets. The table shows aggregated benchmark scores, calculated using three metrics derived from the benchmarks listed in Table 4. These metrics are the average accuracy across benchmarks, the Rank-Score (a measure of ranking performance), and a normalized average score. The datasets used are compared in terms of their performance using these three metrics. The table is useful for understanding how data filtering techniques and dataset composition affect the overall performance of the LM.
read the caption
Table 6: Aggregated evaluations for the 1.6B parameter LM for different datasets. The Benchmark scores are aggregated from the benchmarks outlined in Table 4, using (1) the average accuracy, (2) the Rank-Score, and (3) the normalized average score.
| Model | Lambada (acc) | Hellaswag (acc_norm) | Winogrande (acc) | Piqa (acc) | Avg. | HELM avg. |
|---|---|---|---|---|---|---|
| GPT-Neo | 0.6223 | 0.5579 | 0.5769 | 0.7219 | 0.6197 | 0.3570 |
| Pythia-2.8B | 0.6466 | 0.5933 | 0.6006 | 0.7399 | 0.6451 | 0.3770 |
| Pythia-2.8B-dedup | 0.6524 | 0.5941 | 0.5848 | 0.7404 | 0.6429 | - |
| RedPajama-INCITE-Base-3B-v1 | 0.6541 | 0.6317 | 0.6322 | 0.7470 | 0.6662 | 0.4060 |
🔼 This table presents a comparative analysis of the RedPajama-INCITE-Base-3B-v1 language model’s performance against other models with similar parameter counts across various benchmarks, including both zero-shot and few-shot evaluations from the lm-evaluation-harness and HELM. The results showcase RedPajama-INCITE-Base-3B-v1’s strengths and weaknesses relative to other open-source models. The top performing model for each benchmark is clearly highlighted.
read the caption
Table 7: Results for RedPajama-INCITE-Base-3B-v1 on a subset of lm-evaluation-harness (Zero-Shot) and HELM, compared to models with similar parameter counts. The top-scoring model for each benchmark is highlighted in bold font.
| Model | RedPajama 7B (Instruct) | Llama 7B | MPT 7B | Falcon 7B (Base) | GPT J | Falcon 7B (Instruct) | Pythia 7B | Dolly v2 | MPT 7B (Instruct) | Stablelm Alpha 7B |
|---|---|---|---|---|---|---|---|---|---|---|
| HELM-AVG | 0.492 | 0.472 | 0.444 | 0.441 | 0.431 | 0.417 | 0.407 | 0.400 | 0.396 | 0.393 |
| MMLU - EM | 0.366 | 0.345 | 0.294 | 0.285 | 0.323 | 0.249 | 0.271 | 0.266 | 0.238 | 0.349 |
| BoolQ - EM | 0.697 | 0.751 | 0.731 | 0.770 | 0.694 | 0.649 | 0.708 | 0.656 | 0.602 | 0.442 |
| NarrativeQA - F1 | 0.623 | 0.524 | 0.541 | 0.549 | 0.512 | 0.545 | 0.381 | 0.427 | 0.441 | 0.220 |
| NaturalQuestions (closed-book) - F1 | 0.229 | 0.297 | 0.284 | 0.289 | 0.258 | 0.156 | 0.192 | 0.141 | 0.133 | 0.247 |
| NaturalQuestions (open-book) - F1 | 0.654 | 0.580 | 0.603 | 0.574 | 0.600 | 0.559 | 0.453 | 0.549 | 0.535 | 0.627 |
| QuAC - F1 | 0.252 | 0.332 | 0.343 | 0.322 | 0.323 | 0.330 | 0.300 | 0.306 | 0.299 | 0.352 |
| HellaSwag - EM | 0.698 | 0.747 | 0.754 | 0.732 | 0.702 | 0.663 | 0.690 | 0.653 | 0.692 | 0.763 |
| OpenbookQA - EM | 0.488 | 0.574 | 0.540 | 0.546 | 0.504 | 0.514 | 0.498 | 0.496 | 0.516 | 0.532 |
| TruthfulQA - EM | 0.226 | 0.297 | 0.186 | 0.206 | 0.205 | 0.199 | 0.203 | 0.225 | 0.250 | 0.188 |
| MS MARCO (regular) - RR@10 | 0.391 | 0.252 | 0.161 | 0.169 | 0.135 | 0.152 | 0.225 | 0.159 | 0.160 | 0.161 |
| MS MARCO (TREC) - NDCG@10 | 0.709 | 0.482 | 0.369 | 0.362 | 0.322 | 0.345 | 0.481 | 0.342 | 0.359 | 0.387 |
| CNN/DailyMail - ROUGE-2 | 0.143 | 0.149 | 0.137 | 0.147 | 0.137 | 0.131 | 0.114 | 0.101 | 0.140 | 0.148 |
| XSUM - ROUGE-2 | 0.101 | 0.127 | 0.107 | 0.116 | 0.114 | 0.096 | 0.071 | 0.079 | 0.074 | 0.101 |
| IMDB - EM | 0.941 | 0.933 | 0.903 | 0.893 | 0.916 | 0.939 | 0.906 | 0.930 | 0.907 | 0.891 |
| CivilComments - EM | 0.667 | 0.578 | 0.525 | 0.511 | 0.536 | 0.520 | 0.516 | 0.527 | 0.520 | 0.270 |
| RAFT - EM | 0.682 | 0.583 | 0.618 | 0.586 | 0.611 | 0.619 | 0.498 | 0.542 | 0.466 | 0.616 |
🔼 This table presents the HELM benchmark results for two language models: the RedPajama-INCITE-Base-7B-v1 (a base, pretrained model) and its instruction-tuned counterpart. For various NLP tasks, the table compares their performance to other leading open-source LLMs of similar size. The top-performing model for each benchmark is highlighted in bold font, allowing for a direct comparison of performance across different models on a range of evaluation metrics.
read the caption
Table 8: HELM Benchmark results for RedPajama-INCITE-Base-7B-v1 and instruction tuned. The top-scoring model for each benchmark is highlighted in bold font.
| Model | LM-eval-harness-AVG | arc_challenge (acc_norm) | arc_easy (acc) | boolq (acc) | copa (acc) | hellaswag (acc_norm) | lambada_openai (acc) | piqa (acc_norm) | winogrande (acc) |
|---|---|---|---|---|---|---|---|---|---|
| MPT 7B (Instruct) | 0.7195 | 0.4462 | 0.7218 | 0.7425 | 0.9000 | 0.7717 | 0.6918 | 0.8041 | 0.6780 |
| Falcon 7B | 0.7161 | 0.4326 | 0.7096 | 0.7361 | 0.8600 | 0.7634 | 0.7467 | 0.8069 | 0.6732 |
| MPT 7B | 0.7100 | 0.4215 | 0.7008 | 0.7486 | 0.8500 | 0.7626 | 0.7056 | 0.8052 | 0.6859 |
| RedPajama 7B (Base) | 0.6882 | 0.3925 | 0.6923 | 0.707 | 0.880 | 0.7037 | 0.7143 | 0.7737 | 0.6417 |
| Llama 7B | 0.6881 | 0.4147 | 0.5253 | 0.7315 | 0.8500 | 0.7620 | 0.7360 | 0.7810 | 0.7040 |
| RedPajama 7B (Instruct) | 0.6858 | 0.4078 | 0.7159 | 0.6865 | 0.850 | 0.7103 | 0.6895 | 0.7699 | 0.6567 |
| Falcon 7B (Instruct) | 0.6813 | 0.4283 | 0.6789 | 0.7089 | 0.8400 | 0.6978 | 0.6831 | 0.7856 | 0.6669 |
| Dolly v2 | 0.6557 | 0.4027 | 0.6423 | 0.6502 | 0.8600 | 0.6896 | 0.6893 | 0.7486 | 0.6140 |
| GPT-J | 0.6526 | 0.3660 | 0.6225 | 0.6544 | 0.8300 | 0.6625 | 0.6831 | 0.7617 | 0.6409 |
| Pythia 7B | 0.6392 | 0.3532 | 0.6338 | 0.6446 | 0.7400 | 0.6588 | 0.6441 | 0.7671 | 0.6267 |
| StableLM Alpha 7B | 0.5260 | 0.2705 | 0.4487 | 0.6006 | 0.7500 | 0.4122 | 0.6379 | 0.6736 | 0.5012 |
🔼 Table 9 presents the results of evaluating the RedPajama-INCITE-Base-7B-v1 and its instruction-tuned counterpart on a range of benchmarks commonly used for language model evaluation. The table compares the performance of these models against other prominent open-source language models, such as Llama-7B, Falcon-7B, and MPT-7B, highlighting their strengths and weaknesses across various tasks. The top-performing model for each benchmark is clearly indicated in bold.
read the caption
Table 9: LM eval harness results for RedPajama-INCITE-Base-7B-v1 and instruction tuned model. The top-scoring model for each benchmark is highlighted in bold font.
| Subset | Uncertainty | Decision |
|---|---|---|
| CommonCrawl | Which snapshots were used? | We use the first snapshot from 2019 to 2023. |
| What classifier was used, and how was it constructed? | We use a fasttext classifier with unigram features and use 300k training samples. | |
| What threshold was used to classify a sample as high quality? | We set the threshold to match the token count reported in LLama. | |
| GitHub | Quality filtering heuristics | We remove any file • with a maximum line length of more than 1000 characters. • with an average line length of more than 100 characters. • with a proportion of alphanumeric characters of less than 0.25. • with a ratio between the number of alphabetical characters and the number of tokens of less than 1.5. whose extension is not in the following set of whitelisted extensions: .asm, .bat, .cmd, .c, .h, .cs, .cpp, .hpp, .c++, .h++, .cc, .hh, .C, .H, .cmake, .css, .dockerfile, .f90, .f, .f03, .f08, .f77, .f95, .for, .fpp, .go, .hs, .html, .java, .js, .jl, .lua, .md, .markdown, .php, .php3, .php4, .php5, .phps, .phpt, .pl, .pm, .pod, .perl, .ps1, .psd1, .psm1, .py, .rb, .rs, .sql, .scala, .sh, .bash, .command, .zsh, .ts, .tsx, .tex, .vb, Dockerfile, Makefile, .xml, .rst, .m, .smali |
| Wikipedia | Which Wikipedia dump was used? | We used the most recent at the time of data curation (2023-03-20). |
| Books | How were the books deduplicated? | We use SimHash to perform near deduplication. |
🔼 This table details the ambiguities encountered during the recreation of the original LLaMA training dataset for the RedPajama-V1 project and the decisions made to address them. It covers data sources like Common Crawl, GitHub, and Wikipedia, highlighting uncertainties in the original LLaMA dataset description regarding data selection criteria, processing techniques, and quality filtering methods. For each source, the table lists the uncertainties and the choices made by the RedPajama-V1 team to resolve those issues.
read the caption
Table 10: Overview over the different uncertainties and decisions made during the construction of the RedPajama-V1 dataset.
| Annotation Tag | Description |
|---|---|
| ccnet_bucket | head, middle or tail bucket of the perplexity score |
| ccnet_language_score | score of the language identification model |
| ccnet_length | number of characters |
| ccnet_nlines | number of lines |
| ccnet_original_length | number of characters before line-level deduplication |
| ccnet_original_nlines | number of lines before line-level deduplication |
| ccnet_perplexity | perplexity of an LM trained on Wikipedia |
🔼 This table lists quality signals derived from the CCNet pipeline, a data processing framework used in creating the RedPajama-V2 dataset. Each signal provides metadata about the text documents, such as the document’s length, language, and perplexity score, helping to assess the quality of the web data.
read the caption
Table 11: Quality signals originating from the CCNet pipeline [61].
| Annotation Tag | Description | Reference(s) |
| rps_doc_curly_bracket | The ratio between the number of occurrences of ’{’ or ’}’ and the number of characters in the raw text. | [46] |
| rps_doc_frac_all_caps_words | The fraction of words in the content that only consist of uppercase letters. This is based on the raw content. | [34] |
| rps_doc_frac_lines_end_with_ellipsis | The fraction of lines that end with an ellipsis, where an ellipsis is defined as either "…" or "U+2026". | [44, 45] |
| rps_doc_frac_no_alph_words | The fraction of words that contain no alphabetical character. | [44, 45] |
| rps_doc_lorem_ipsum | The ratio between the number of occurrences of ’lorem ipsum’ and the number of characters in the content after normalisation. | [46] |
| rps_doc_mean_word_length | The mean length of words in the content after normalisation. | [44, 45] |
| rps_doc_stop_word_fraction | The ratio between the number of stop words and the number of words in the document. Stop words are obtained from https://github.com/6/stopwords-json. | [44, 45] |
| rps_doc_symbol_to_word_ratio | The ratio of symbols to words in the content. Symbols are defined as U+0023 (#), "…", and U+2026. | [44, 45] |
| rps_doc_frac_unique_words | The fraction of unique words in the content. This is also known as the degeneracy of a text sample. Calculated based on the normalised content. | [34] |
| rps_doc_unigram_entropy | The entropy of the unigram distribution of the content. This measures the diversity of the content and is computed using where the sum is taken over counts of unique words in the normalised content. | - |
| rps_doc_word_count | The number of words in the content after normalisation. | [44, 45] |
| rps_lines_ending_with_terminal_punctution_mark | Indicates whether a line ends with a terminal punctuation mark. A terminal punctuation mark is defined as one of: ".", "!", "?", "”". | [46] |
| rps_lines_javascript_counts | The number of occurrences of the word "javascript" in each line. | [46] |
| rps_lines_num_words | The number of words in each line. This is computed based on the normalised text. | [46, 44] |
| rps_lines_numerical_chars_fraction | The ratio between the number of numerical characters and total number of characters in each line. This is based on the normalised content. | [44] |
| rps_lines_start_with_bulletpoint | Whether the lines that start with a bullet point symbol. The following set of unicodes are considered a bullet point: U+2022 (bullet point), U+2023 (triangular bullet point), U+25B6 (black right pointing triangle), U+25C0 (black left pointing triangle), U+25E6 (white bullet point), U+2013 (en dash) U+25A0 (black square), U+25A1 (white square), U+25AA (black small square), U+25AB (white small square). | [43, 45] |
| rps_lines_uppercase_letter_fraction | The ratio between the number of uppercase letters and total number of characters in each line. This is based on the raw text. | [44] |
| rps_doc_num_sentences | The number of sentences in the content. | [46] |
🔼 This table lists quality signals used to assess the natural language quality of text documents. Each signal is described, indicating how it measures the extent to which text resembles human-written language rather than machine-generated or non-language content. References to prior works which introduced each signal are included for further study.
read the caption
Table 12: Summary of quality signals which measure how much a document corresponds to natural language.
| Annotation Tag | Description | Reference(s) |
|---|---|---|
| rps_doc_books_importance | Given a bag of 1,2-wordgram model trained on Books $p$, and a model trained on the source domain $q$, This is the logarithm of the ratio $p/q$. | [62] |
| rps_doc_openwebtext_importance | Given a bag of 1,2-wordgram model trained on OpenWebText $p$, and a model trained on the source domain $q$, this is the logarithm of the ratio $p/q$. | [62] |
| rps_doc_wikipedia_importance | Given a bag of 1,2-wordgram model trained on Wikipedia articles $p$, and a model trained on the source domain $q$, this is the logarithm of the ratio $p/q$. | [62] |
| rps_doc_ml_wikiref_score | Fasttext classifier prediction for the document being a Wikipedia reference. This is the same fasttext model used in the RedPajama-1T dataset. Only applies to English data. | [57] |
| rps_doc_ml_palm_score | Fasttext classifier prediction for the document being a Wikipedia article, OpenWebText sample or a RedPajama-V1 book. Only for English data. | [12], [16] |
| rps_doc_ml_wikipedia_score | Fasttext classifier prediction for the document being a Wikipedia article. This is used for non-English data | - |
🔼 This table lists quality signals derived from machine learning (ML) heuristics. These signals are used to assess the quality of text documents by comparing them to reference datasets. Specifically, they measure how similar a document’s textual characteristics are to those found in high-quality datasets such as Books, OpenWebText, and Wikipedia.
read the caption
Table 13: Quality signals based on ML heuristics.
| Annotation Tag | Description | Reference(s) |
|---|---|---|
| rps_doc_frac_chars_dupe_10grams | The fraction of characters in duplicate word 10grams. | [43, 45] |
| rps_doc_frac_chars_dupe_5grams | The fraction of characters in duplicate word 5grams. | [43, 45] |
| rps_doc_frac_chars_dupe_6grams | The fraction of characters in duplicate word 6grams. | [43, 45] |
| rps_doc_frac_chars_dupe_7grams | The fraction of characters in duplicate word 7grams. | [43, 45] |
| rps_doc_frac_chars_dupe_8grams | The fraction of characters in duplicate word 8grams. | [43, 45] |
| rps_doc_frac_chars_dupe_9grams | The fraction of characters in duplicate word 9grams. | [43, 45] |
| rps_doc_frac_chars_top_2gram | The fraction of characters in the top word 2gram. | [43, 45] |
| rps_doc_frac_chars_top_3gram | The fraction of characters in the top word 3gram. | [43, 45] |
| rps_doc_frac_chars_top_4gram | The fraction of characters in the top word 4gram. | [43, 45] |
🔼 This table lists quality signals that assess the repetitiveness of text. It provides a comprehensive overview of various metrics used to quantify text repetition within the RedPajama-V2 dataset. Each row represents a specific signal, offering its name, a description explaining how the signal measures repetitiveness (e.g., the fraction of characters within duplicate n-grams), and its reference to the source where it was initially described.
read the caption
Table 14: Summary of Quality signals which measure how repetitive text is.
| Annotation Tag | Description | Reference(s) |
|---|---|---|
| rps_doc_ldnoobw_words | The number of sequences of words that are contained in the List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words blocklist. The blocklist is obtained from https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words. | [46] |
| rps_doc_ut1_blacklist | A categorical id corresponding to the list of categories of the domain of the document. Categories are obtained from https://dsi.ut-capitole.fr/blacklists/ | [44] |
🔼 This table lists quality signals in the RedPajama-V2 dataset that assess the toxicity of text documents. It details the specific annotation tags used, a description of what each tag measures (e.g., presence of offensive words), and the sources or methods used to calculate these metrics.
read the caption
Table 15: Summary of Quality signals which are based on the content of the text, measuring toxicity.
| Cluster Topics | Document |
|---|---|
| (broad - medium - specific) | |
| Election - Health (2) - COVID Testing | immediately moving to the Purple Tier. This is the most restrictive level in the State’s effort to control the spread of COVID-19. Businesses and residents must comply with the Purple Tier restrictions by Tuesday, Nov. 17. To determine restrictions by industry, business and activity, visit: https://covid19.ca.gov/safer-economy/ Read the full news release here: www.gov.ca.gov/2020/11/16/governor-newsom-announces-new-immediate-actions-to-curb-covid-19-transmission/ Watch the Governor’s press conference during which he made the announcement today here: www.facebook.com/CAgovernor/videos/376746553637721 According to County of Orange officials, schools that have not already opened must continue with remote classes and cannot reopen in-person. Read the County’s release here: https://cms.ocgov.com/civicax/filebank/blobdload.aspx?BlobID=118441 The California Department of Public Health has also issued a travel advisory encouraging Californians to stay home or in their region and avoid non-esse |
| Religion/Spirituality - Gaming - Gaming (3) | Top 100 Employers, and one of Canada’s Top Employers for Young People multiple years running! At Ubisoft Toronto, we look for people who are excited to create the future of games in one of the most diverse cities in the world. We believe that embracing our differences helps us build stronger creative teams and develop better games for all players. We are an equal-opportunity employer and welcome applications from all interested candidates. We strongly encourage applications from Indigenous people, racialized people, neurodivergent people, people with disabilities, people from gender and sexually diverse communities and/or people with intersectional identities. We are committed to providing reasonable accommodation for people with disability upon request. If this sounds like your kind of studio, what are you waiting for? Apply to join us now! We thank you for your interest, however, only those candidates selected for an interview will be contacted. No agencies please. Senior Game Design |
| Education - Golf - Rotary Meetings | what’s happening. Conversely, some people rely on the newsletter. Thus, the more avenues to inform people, the better. attendance at many social functions is poor, possibly due to the limited advertising reach. In practical terms, it means that social functions may be advertised in the OOC newsletter (current practice) the schedule, as is done for outdoor activities such as hikes the OOC’s Facebook group As when social functions are advertised in the newsletter, the person organizing the social function can choose how much location information to provide, especially if it is to be held at someone’s residence. OOC bylaw Article 3, Section 9 (f) states (highlighting added) (f) Social Coordinator: Shall be responsible for coordinating all social events for Club members only, and for preparing a schedule of these outings, not to be advertised to non-members. The executive voted to amend this statement by removing the limitation per Paragraph 3 of “Article 5 - Amending Formula” of the Const |
🔼 This table presents examples of documents from the RedPajama-V2 dataset and their corresponding cluster topics as determined by Nomic Atlas. It showcases the diversity of topics covered in the dataset and how Nomic Atlas groups similar documents together based on semantic meaning.
read the caption
Table 16: Examples of documents and corresponding cluster topics from Nomic Atlas [41].
| Cluster Topics | Document |
|---|---|
| (broad - medium - specific) | |
| Online Privacy - Privacy Policy - Contracts | shall be governed by the laws of the Federal Republic of Germany under exclusion of the UN Convention on the International Sale of Goods (CISG), without prejudice to any mandatory conflict of laws and consumer protection provisions. 11.2 If the Customer is an entrepreneur according to Sec. 14 German Civil Code (“BGB”), a legal person under public law or a special fund under public law the courts at the place of business of the vendor shall have exclusive jurisdiction in respect of all disputes arising out of or in connection with the relevant contract. 11.3 In the event that one or more provisions of the contract should be or become invalid or unenforceable, the validity of the remaining provisions shall not be affected thereby. The invalid or unenforceable provision shall be deemed to be replaced - as existent - with statutory provisions. In case of an unacceptable rigor to one of the parties, the contract shall be deemed invalid as a whole. 11.4 In case of deviations of these General |
| Religion/Spirituality - Film/Movie - Movie | Movie of Nelson Mandela’s life premieres in South Africa Nov. 04 - Stars Idris Elba and Naomie Harris attend the premiere of “Mandela: Long Walk to Freedom,” based on the autobiography of anti-apartheid icon Nelson Mandela. Matthew Stock reports. |
| Election - Election (2) - Healthcare (4) | McAuliffe revived that language as an amendment to the budget. He also called on the General Assembly to immediately convene a special joint committee that had been created to assess the impact that repealing the ACA would have had on Virginia. The legislature will gather April 5 to consider the governor’s amendments and vetoes, but leaders said Monday that McAuliffe’s new budget language stands no better chance this time. In a joint statement, the Republican leadership of the House of Delegates said expanding Medicaid would lead to increased costs and eventually blow a hole in the state budget. “The lack of action in Washington has not changed that and in fact, the uncertainty of federal health policy underscores the need to be cautious over the long term,” the leaders, including House Speaker William J. Howell (R-Stafford) and the man selected to replace him as speaker when he retires next year, Del. Kirk Cox (R-Colonial Heights), said via email. “Virginians can barely afford our cu |
🔼 This table presents example documents from the RedPajama-V2 dataset and their corresponding cluster topics as determined by Nomic Atlas, a tool for topic modeling and clustering. It shows how Nomic Atlas groups similar documents based on semantic meaning, illustrating the diversity of topics within the RedPajama-V2 dataset.
read the caption
Table 17: Examples of documents and corresponding cluster topics from Nomic Atlas [41].
| Dataset | Deduplication | Deduplication | Rule-based | Rule-based | ML Heuristics | ML Heuristics | ML Heuristics | Natural Language Inference | Natural Language Inference | Natural Language Inference | Coref. Res. | Sentence Completion | Sentence Completion |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exact | Fuzzy | C4 | Gopher | Classif. | DSIR | PPL | ANLI | ARC-c | ARC-e | Winogrande | Hellaswag | LAMBADA | |
| C4 | 33.8 | 22.0 | 37.0 | 51.9 | 32.9 | 15.5 | |||||||
| Dolma-v1.7 CC | 33.5 | 24.0 | 38.3 | 49.6 | 32.3 | 17.3 | |||||||
| FineWeb | 34.0 | 23.4 | 37.7 | 51.8 | 32.8 | 18.1 | |||||||
| RefinedWeb | 32.8 | 22.6 | 38.3 | 51.9 | 31.6 | 17.8 | |||||||
| RPv1-CC | ✓ (Wiki-Ref.) | 33.9 | 22.4 | 37.5 | 52.6 | 29.7 | 19.0 | ||||||
| RPv2 (2023-14) | 33.3 | 22.2 | 38.5 | 52.4 | 31.5 | 18.2 | |||||||
| RPv2 (2023-14) | ✓ | 33.9 | 22.1 | 38.1 | 50.6 | 31.3 | 18.0 | ||||||
| RPv2 (2023-14) | ✓ | 34.1 | 22.3 | 38.3 | 52.2 | 32.1 | 18.7 | ||||||
| RPv2 (2023-14) | ✓ | ✓ | 33.4 | 22.7 | 38.9 | 51.1 | 32.4 | 17.5 | |||||
| RPv2 (2023-14) | ✓ | ✓ (natlang) | Wiki-middle | 33.4 | 24.2 | 37.7 | 49.8 | 33.1 | 19.2 | ||||
| RPv2 (2023-14) | ✓ | ✓ (Rep.) | Wiki-middle | 34.2 | 23.1 | 37.4 | 50.8 | 32.5 | 18.5 | ||||
| RPv2 (9 Dumps) | ✓ | ✓ | 34.3 | 23.5 | 38.6 | 51.5 | 32.0 | 17.2 | |||||
| RPv2 (9 Dumps) | ✓ | ✓ | ✓ (full) | 33.5 | 23.3 | 38.4 | 50.2 | 32.8 | 16.8 | ||||
| RPv2 (9 Dumps) | ✓ | ✓ | ✓ (Rep.) | ✓ (Palm-mix) | 33.8 | 21.9 | 38.0 | 52.5 | 32.0 | 17.3 | |||
| RPv2 (9 Dumps) | ✓ | ✓ | ✓ (Rep.) | ✓ (Palm-mix) | 34.6 | 23.3 | 38.6 | 52.2 | 32.7 | 16.4 | |||
| RPv2 (9 Dumps) | ✓ | ✓ | ✓ (natlang) | ✓ (Palm-mix) | 34.8 | 23.0 | 39.2 | 53.0 | 32.3 | 16.9 | |||
| RPv2 (9 Dumps) | ✓ | ✓ (line-filter) | ✓ (natlang) | ✓ (Palm-mix) | 33.7 | 22.9 | 38.5 | 50.9 | 32.3 | 19.9 | |||
| RPv2 (9 Dumps) | ✓ | custom-rules | ✓ (Wiki-Ref.) | Pwiki>30 | 33.2 | 23.0 | 37.9 | 49.6 | 30.1 | 18.7 | |||
| RPv2 (9 Dumps) | ✓ | custom-rules + Gopher-Rep | ✓ (Wiki-Ref.) | Pwiki>30 | 33.0 | 23.8 | 38.9 | 50.5 | 30.0 | 18.9 |
🔼 This table presents the performance of a 468M parameter language model trained on various datasets. The datasets include different versions of the RedPajama dataset filtered using various rules (exact deduplication, fuzzy deduplication, rule-based filtering, Gopher filtering, classification-based filtering, ML heuristic filtering, and DSIR filtering), along with other established web datasets such as C4, Dolma-v1.7 CC, FineWeb, and RefinedWeb. The model’s performance is evaluated on a selection of downstream tasks (Natural Language Inference, Coreference Resolution, Sentence Completion), with the top-performing dataset for each metric highlighted.
read the caption
Table 18: Evaluations for the 468M parameter LM for different dataset filters and other strong web datasets. The top-scoring dataset for each metric is indicated in bolded underlined, the top-2 is bolded, and the third-scoring dataset is in italics underlined.
| Dataset | Deduplication | Rule-based | ML Heuristics | MMLU | Stem | Humanities | Other | Social Sciences | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C4 | 24.9 | 26.4 | 24.1 | 25.8 | 23.4 | |||||||
| Dolma-v1.7 CC | 26.0 | 27.8 | 24.5 | 26.2 | 26.1 | |||||||
| FineWeb | 26.2 | 25.4 | 25.1 | 25.8 | 29.3 | |||||||
| RefinedWeb | 24.8 | 23.9 | 23.7 | 26.5 | 25.6 | |||||||
| RPv1-CC | ✔ (Wiki-Ref.) | 25.1 | 25.1 | 23.7 | 24.0 | 28.5 | ||||||
| RPv2 (2023-14) | 26.3 | 26.7 | 25.3 | 24.1 | 29.6 | |||||||
| RPv2 (2023-14) | ✔ | 26.4 | 26.8 | 25.3 | 25.2 | 28.8 | ||||||
| RPv2 (2023-14) | ✔ | ✔ (full) | 27.0 | 28.8 | 24.8 | 25.6 | 30.0 | |||||
| RPv2 (2023-14) | ✔ | ✔ | 25.4 | 27.8 | 24.1 | 26.1 | 24.1 | |||||
| RPv2 (2023-14) | ✔ | ✔ (natlang) | Wiki-middle | 26.1 | 27.4 | 25.2 | 24.6 | 27.7 | ||||
| RPv2 (2023-14) | ✔ | ✔ (Rep.) | Wiki-middle | 25.5 | 24.3 | 25.2 | 27.8 | 24.8 | ||||
| RPv2 (9 Dumps) | ✔ | ✔ | 26.3 | 28.3 | 25.3 | 25.8 | 26.6 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (full) | 25.6 | 28.0 | 25.1 | 24.9 | 24.4 | ||||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (Rep.) | ✔ (Palm-mix) | 24.4 | 26.9 | 23.7 | 24.8 | 22.7 | |||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (Rep.) | ✔ (Palm-mix) | 24.9 | 26.1 | 24.0 | 26.3 | 23.8 | |||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (natlang) | ✔ (Palm-mix) | 25.3 | 27.8 | 24.2 | 25.4 | 24.5 | |||
| RPv2 (9 Dumps) | ✔ | ✔ (line-filter) | ✔ (natlang) | ✔ (Palm-mix) | 25.1 | 27.5 | 24.0 | 25.0 | 24.4 | |||
| RPv2 (9 Dumps) | ✔ | custom-rules | ✔ (Wiki-Ref.) | $P_{wiki} > 30$ | 27.0 | 27.9 | 25.1 | 26.0 | 30.0 | |||
| RPv2 (9 Dumps) | ✔ | custom-rules + Gopher-Rep | ✔ (Wiki-Ref.) | $P_{wiki} > 30$ | 25.9 | 25.8 | 24.3 | 27.1 | 27.2 |
🔼 This table presents the results of a 5-shot evaluation on the Massive Multitask Language Understanding (MMLU) benchmark and its subtasks. The evaluation uses a language model with 468 million parameters. Multiple datasets were used to train the model, and the table shows the performance achieved on each dataset. The top-performing dataset for each metric is highlighted. The highlighting differentiates between the top performer, the second-best, and the third-best datasets.
read the caption
Table 19: Evaluations in the 5-shot setting on MMLU and subtasks for the 468M parameter LM. The top-scoring dataset for each metric is indicated in bolded underlined, the top-2 is bolded, and the third-scoring dataset is in italics underlined.
| Dataset | Deduplication | Rule-based | ML Heuristics | CoQA | OpenbookQA | PIQA | PubMedQA | SciQ | SocialIQA | TruthfulQA | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exact | Fuzzy | C4 | Gopher | Classif. | DSIR | PPL | ||||||||
| C4 | 3.8 | 30.2 | 64.4 | 46.0 | 51.7 | 33.4 | 33.3 | |||||||
| Dolma-v1.7 CC | 5.2 | 28.2 | 65.3 | 42.6 | 55.2 | 31.6 | 33.2 | |||||||
| FineWeb | 9.0 | 29.4 | 64.5 | 41.4 | 54.3 | 32.4 | 33.5 | |||||||
| RefinedWeb | 13.2 | 28.6 | 64.4 | 52.2 | 56.4 | 32.8 | 33.3 | |||||||
| RPv1-CC | ✔ (Wiki-Ref.) | 11.6 | 25.4 | 57.3 | 40.6 | 56.7 | 33.1 | 33.9 | ||||||
| RPv2 (2023-14) | 12.5 | 29.2 | 61.6 | 40.8 | 53.0 | 32.9 | 31.4 | |||||||
| RPv2 (2023-14) | ✔ | 11.8 | 27.6 | 61.1 | 43.6 | 53.7 | 32.5 | 33.4 | ||||||
| RPv2 (2023-14) | ✔ | 11.3 | 28.8 | 62.8 | 51.0 | 53.9 | 32.6 | 32.6 | ||||||
| RPv2 (2023-14) | ✔ | ✔ | 5.8 | 28.8 | 63.4 | 49.6 | 54.7 | 36.6 | 33.8 | |||||
| RPv2 (2023-14) | ✔ | Wiki-middle | 11.3 | 28.4 | 63.5 | 49.6 | 53.6 | 32.8 | 33.4 | |||||
| RPv2 (2023-14) | ✔ | Wiki-middle | 11.9 | 29.4 | 63.1 | 52.6 | 53.4 | 32.5 | 31.6 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | 6.6 | 29.0 | 62.0 | 36.2 | 53.7 | 33.2 | 34.3 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | 5.8 | 28.6 | 62.8 | 51.2 | 54.8 | 34.4 | 31.2 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | 6.0 | 29.4 | 61.6 | 45.4 | 52.2 | 33.4 | 33.1 | |||||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (Palm-mix) | 5.4 | 29.4 | 62.5 | 45.0 | 51.7 | 34.0 | 33.7 | ||||
| RPv2 (9 Dumps) | ✔ | ✔ | ✔ (Palm-mix) | 4.9 | 28.0 | 62.9 | 52.8 | 52.0 | 33.0 | 33.6 | ||||
| RPv2 (9 Dumps) | ✔ | ✔ (line-filter) | ✔ (natlang) | ✔ (Palm-mix) | 6.4 | 27.0 | 63.2 | 47.8 | 52.9 | 32.8 | 32.0 | |||
| RPv2 (9 Dumps) | ✔ | custom-rules | ✔ (Wiki-Ref.) | Pwiki>30 | 10.0 | 27.8 | 59.6 | 41.2 | 55.8 | 33.3 | 32.0 | |||
| RPv2 (9 Dumps) | ✔ | custom-rules + Gopher-Rep | ✔ (Wiki-Ref.) | Pwiki>30 | 9.3 | 28.0 | 59.2 | 43.4 | 54.9 | 33.0 | 33.3 |
🔼 This table presents the results of an evaluation of various datasets used to train a 468M parameter language model on multiple-choice question answering tasks. The evaluation metrics include accuracy scores across several different benchmarks. The table highlights the top-performing datasets for each metric, indicating the top dataset with bolded underlined text, the second-best with bolded text, and the third-best with italicized underlined text.
read the caption
Table 20: Evaluations on multiple choice tasks for the 468M parameter LM. The top-scoring dataset for each metric is indicated in bolded underlined, the top-2 is bolded, and the third-scoring dataset is in italics underlined.
| Dataset | Fuzzy Deduplication | Rule-based C4 | Rule-based Gopher | ANLI | ARC-c | ARC-e | Winogrande | Hellaswag | LAMBADA | Coref. Res. | Sentence Completion |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RefinedWeb | 33.6 | 26.9 | 51.7 | 54.4 | 55.8 | 47.9 | |||||
| RPv2 (full) | ✔ | ✔ | WikiRef | 32.4 | 27.9 | 51.3 | 56.4 | 47.4 | 47.4 | ||
| RPv2 (full) | ✔ | ✔ | ✔(natlang) | Palm-Mix | 33.6 | 28.7 | 52.4 | 54.5 | 53.1 | 42.9 |
🔼 This table presents the results of downstream task accuracy achieved by a 1.6 billion parameter language model (LM) trained on various datasets. Each dataset was used to train the LM using 350 billion tokens. The table displays the accuracy scores across several downstream tasks, including various Natural Language Inference (NLI) tasks, Coreference Resolution, and Sentence Completion tasks. The results offer a comparison of how different datasets impact the performance of the LM on various tasks.
read the caption
Table 21: Downstream task accuracy for a 1.6B LM trained on different datasets over 350B tokens.
| Dataset | Fuzzy Deduplication | Rule-based C4 | Rule-based Gopher | Rule-based MMLU | ML Heuristics | MMLU MMLU | MMLU Stem | MMLU Humanities | MMLU Other | MMLU Social Sciences |
|---|---|---|---|---|---|---|---|---|---|---|
| RefinedWeb | 25.3 | 24.9 | 24.9 | 27.0 | 24.7 | |||||
| RPv2 (full) | ✔ | ✔ | WikiRef | 25.2 | 26.0 | 26.7 | 23.9 | 23.3 | ||
| RPv2 (full) | ✔ | ✔ | ✔ (natlang) | Palm-Mix | 24.7 | 25.7 | 25.4 | 23.8 | 23.4 |
🔼 This table presents the results of a 5-shot evaluation of a 1.6B parameter language model on the Massive Multitask Language Understanding (MMLU) benchmark and its subtasks. The evaluation measures the model’s performance across various subdomains of MMLU, providing insights into its capabilities in different areas of knowledge and reasoning. The table likely compares the model’s performance across different dataset variations, allowing for analysis of how data composition influences model capabilities.
read the caption
Table 22: Evaluations in the 5-shot setting on MMLU and subtasks for the 1.6B parameter LM.
| Dataset | Fuzzy Deduplication | Rule-based C4 | Rule-based Gopher | ML Heuristics WikiRef | CoQA | OpenbookQA | PIQA | PubMedQA | SciQ | SocialIQA | TruthfulQA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RefinedWeb | 47.4 | 31.6 | 73.8 | 57.0 | 75.3 | 41.0 | 36.6 | ||||
| RPv2 (full) | ✔ | ✔ | 43.7 | 32.6 | 67.4 | 55.6 | 72.7 | 40.4 | 36.9 | ||
| RPv2 (full) | ✔ | ✔ | ✔(natlang) | Palm-Mix | 22.1 | 32.2 | 71.3 | 55.2 | 71.0 | 42.2 | 35.7 |
🔼 This table presents the performance of a 1.6B parameter language model on various multiple-choice question answering benchmarks. The model was trained on the RedPajama-V2 dataset, with different filtering techniques applied to the data. The results show how different data filtering methods affect the model’s performance across a variety of tasks and datasets. The table includes a variety of metrics to evaluate performance, such as accuracy and F1-score, allowing for a comprehensive assessment of the model’s capabilities under diverse conditions.
read the caption
Table 23: Evaluations on multiple choice tasks for the 1.6B parameter LM.
Full paper#