↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) are prone to misuse when prompted to perform tasks beyond their intended scope. Existing guardrails often rely on limited real-world data, leading to high error rates and poor generalization. This limits the practical applications of LLMs, especially in sensitive areas. The problem is exacerbated in pre-production environments where real-world data is scarce.
This research introduces a flexible methodology for developing guardrails without needing real-world data. By using LLMs to generate a synthetic dataset of on-topic and off-topic prompts, the researchers trained and evaluated models that outperform existing methods. The key innovation is framing the problem as classifying user prompt relevance to the system prompt, which allows the guardrails to generalize effectively to other misuse types like jailbreaks and harmful prompts. The project also open-sources the dataset and models, facilitating further research and development in LLM safety.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM safety and robustness. It introduces a novel, data-free guardrail development methodology that directly addresses the scarcity of real-world data in pre-production environments. The open-sourcing of the synthetic dataset and guardrail models greatly facilitates future research and enables faster development of safer LLMs. This work significantly contributes to the growing field of LLM safety and directly impacts the responsible deployment of powerful language models.
Visual Insights#

🔼 This figure shows two examples of user prompts given to a large language model (LLM). The first example is an on-topic prompt, meaning it is relevant to the task the LLM was designed to perform. The second example is an off-topic prompt, meaning it is irrelevant to the task. The system prompt defines the LLM’s intended task, and the goal is to develop a guardrail that can correctly classify whether a user prompt is on-topic or off-topic with respect to the system prompt. This is crucial for ensuring the LLM is used appropriately and does not produce unexpected or harmful outputs.
read the caption
Figure 1. Example of on- and off-topic user prompts: The goal is to correctly classify if a prompt is off-topic or not, with respect to the system prompt
| Approach | Model | ROC-AUC | F1 | Precision | Recall |
|---|---|---|---|---|---|
| Fine-tuned cross-encoder classifier | stsb-roberta-base | 0.99 | 0.99 | 0.99 | 0.99 |
| Fine-tuned bi-encoder classifier | jina-embeddings-v2-small-en | 0.99 | 0.97 | 0.99 | 0.95 |
| Cosine similarity | bge-large-en-v1.5 | 0.89 | 0.59 | 0.97 | 0.42 |
| KNN | bge-large-en-v1 | 0.90 | 0.75 | 0.94 | 0.63 |
| Pre-trained cross-encoder | stsb-roberta-base | 0.73 | 0.68 | 0.53 | 0.93 |
| Pre-trained colbert | Colbert v2 | 0.78 | 0.72 | 0.72 | 0.73 |
| Prompt engineering | GPT 4o (2024-08-06) | - | 0.95 | 0.94 | 0.97 |
| Prompt engineering | GPT 4o Mini (2024-07-18) | - | 0.91 | 0.85 | 0.91 |
| Zero-shot classifier | GPT 4o Mini (2024-07-18) | 0.99 | 0.97 | 0.95 | 0.99 |
🔼 This table presents the performance of different models and baselines on a synthetic dataset generated by GPT 40 (on August 6th, 2024). It shows the results of evaluating various approaches to off-topic prompt detection, including fine-tuned and pre-trained models, as well as simpler heuristics such as cosine similarity. The metrics reported are ROC-AUC, F1 score, precision, and recall. The large dataset size (N=17,201) allows for robust comparisons, and the inclusion of baselines facilitates the assessment of the improvement provided by the fine-tuned models. The purpose of the table is to compare the performance of the proposed methodology and models against common approaches and to highlight the advantage gained by using a synthetic dataset.
read the caption
Table 1. Performance on Synthetic Dataset Generated by GPT 4o (2024-08-06) (N=17,201)
In-depth insights#
LLM Off-Topic Use#
LLM off-topic use presents a significant challenge in deploying these powerful models safely and effectively. The core issue is users prompting LLMs to perform tasks outside their intended design and capabilities. This can lead to inaccurate, irrelevant, or even harmful outputs, undermining the LLM’s intended function and potentially causing reputational or legal issues for the deploying organization. Current guardrails often rely on pre-defined rules or curated datasets, leading to high false positive rates and limited adaptability to evolving misuse patterns. A more robust solution requires a dynamic approach that can adapt to new and unforeseen off-topic prompts. This necessitates moving beyond static rule sets and embracing a flexible methodology like the one explored in the paper, which uses LLMs to generate synthetic data to train and benchmark off-topic detectors. This addresses limitations caused by data scarcity in pre-production environments and improves generalization, reducing false positives and increasing efficacy. The key takeaway is the need for proactive, adaptive guardrails that leverage the power of LLMs themselves to mitigate the risks associated with off-topic use.
Synthetic Data Gen#
The section on ‘Synthetic Data Generation’ is crucial because it addresses the core challenge of limited real-world data in the pre-production phase of LLM development. The authors cleverly leverage LLMs themselves to generate a synthetic dataset, thus creating a strong baseline for initial model training and evaluation. This approach offers a solution to the impracticality of relying on curated examples or real-world data, which often suffers from high false-positive rates and limited adaptability. The use of LLMs to generate diverse prompts, by varying length and randomness, ensures a comprehensive dataset that mirrors the variety and unpredictability of real-world user interactions. This approach highlights a major contribution: the creation of open-source resources to benchmark and train guardrails for wider adoption and further research within the community. The strategic move of framing prompt detection as a classification task of system prompt relevance also allows the developed guardrails to effectively generalize across multiple misuse categories. Therefore, the methodology presented is not just efficient but also highly flexible and generalizable for detecting off-topic prompts and improving LLM safety and compliance.
Guardrail Models#
Guardrail models, in the context of large language models (LLMs), are safety mechanisms designed to prevent LLMs from generating undesirable or harmful outputs. These models act as filters, scrutinizing both inputs (user prompts) and outputs (LLM responses) to ensure they align with intended functionality and safety parameters. Effective guardrail models are crucial for mitigating risks associated with LLM deployment, particularly in sensitive domains like healthcare and finance. The development of robust guardrail models presents several challenges, including the need for generalizability across various misuse categories (off-topic, jailbreak, harmful prompts), the scarcity of real-world data in pre-production environments, and the high false-positive rates often associated with existing methods. A key innovation involves utilizing LLMs to generate synthetic datasets, thereby circumventing the limitations of real-world data and enabling the development of effective classifiers that can identify potentially harmful inputs and outputs. The approach emphasizes a flexible, data-free methodology, focusing on qualitative problem analysis and a thorough understanding of the model’s intended behavior. Fine-tuning embedding and cross-encoder models on these synthetic datasets has proven effective in improving the performance of guardrail models. Open-sourcing these datasets and models facilitates collaborative research and accelerates progress in LLM safety. The overall aim is to establish a more reliable and safer deployment process for LLMs by implementing comprehensive guardrail models, which are crucial for widespread adoption and trustworthy use.
Generalization Test#
A crucial aspect of evaluating any machine learning model, especially one intended for real-world applications like the off-topic prompt detection guardrails discussed in this paper, is its generalization ability. A dedicated ‘Generalization Test’ section would be essential to assess how well the model performs on unseen data, beyond the training and validation sets. This would involve evaluating the model’s performance on data from various sources, potentially including diverse language styles, different system prompts with varying complexities, and possibly even data generated by different LLMs. The key is to test the model’s robustness against data it hasn’t encountered during training, thus gauging its capacity to effectively handle a broader spectrum of inputs. A strong emphasis should be placed on the types of unseen data used, ensuring that they accurately represent the real-world scenarios where the model would be deployed. This would also include a detailed analysis of metrics like precision, recall, and F1-score, and more importantly, a qualitative assessment of the model’s outputs in these diverse scenarios. Any significant drop in performance on unseen data would highlight weaknesses in the model’s generalization abilities, indicating a need for further refinement or retraining. The results of this test section would provide valuable insight into the practical applicability and reliability of the model in a production environment.
Future Work#
Future research directions stemming from this work could focus on several key areas. Improving the synthetic data generation process is crucial; exploring techniques to reduce bias in synthetic datasets and create more diverse and realistic prompts is needed. Investigating the model’s performance across different languages and cultural contexts would greatly enhance its generalizability. Addressing the limitations of relying on synthetic data by incorporating active learning techniques, which integrate real-world feedback into model training, is a significant improvement area. Furthermore, exploring the effectiveness of different prompt engineering strategies and evaluating the guardrail’s performance with larger, more complex LLMs are important next steps. Finally, understanding the inherent trade-offs between accuracy and latency, and optimizing model architecture to improve efficiency would make these guardrails more practical for real-world applications.
More visual insights#
More on figures

🔼 This figure illustrates a three-step methodology for developing guardrails to enhance the safety and reliability of LLMs. Step 1 involves a qualitative analysis of potential vulnerabilities and the definition of acceptable and unacceptable behaviors. Step 2 leverages LLMs to generate synthetic datasets representing diverse use cases, which enhances realism by incorporating few-shot examples and randomizing input parameters. Step 3 focuses on training transformer-based classifiers using this synthetic data, specifically designed to accurately identify and effectively mitigate undesirable inputs. The entire process facilitates the creation of operational guardrails deployable before full deployment of the LLM, making it a pre-deployment approach.
read the caption
Figure 2. Our Guardrail Development Methdology

🔼 This figure illustrates the architectures of two different models used for off-topic prompt detection: a fine-tuned bi-encoder classifier and a fine-tuned cross-encoder classifier. The bi-encoder model processes the system prompt and user prompt separately through embedding models, applies cross-attention to allow interaction between the two representations, and then uses a projection and classification layer to predict whether the prompt is on-topic or off-topic. The cross-encoder model concatenates the system and user prompts before feeding them into a pre-trained cross-encoder model, followed by a classification layer for prediction. Both models provide a probability score from 0 to 1 (0 = on-topic, 1 = off-topic).
read the caption
Figure 3. Summary of the two modelling approaches for the off-topic prompt detection

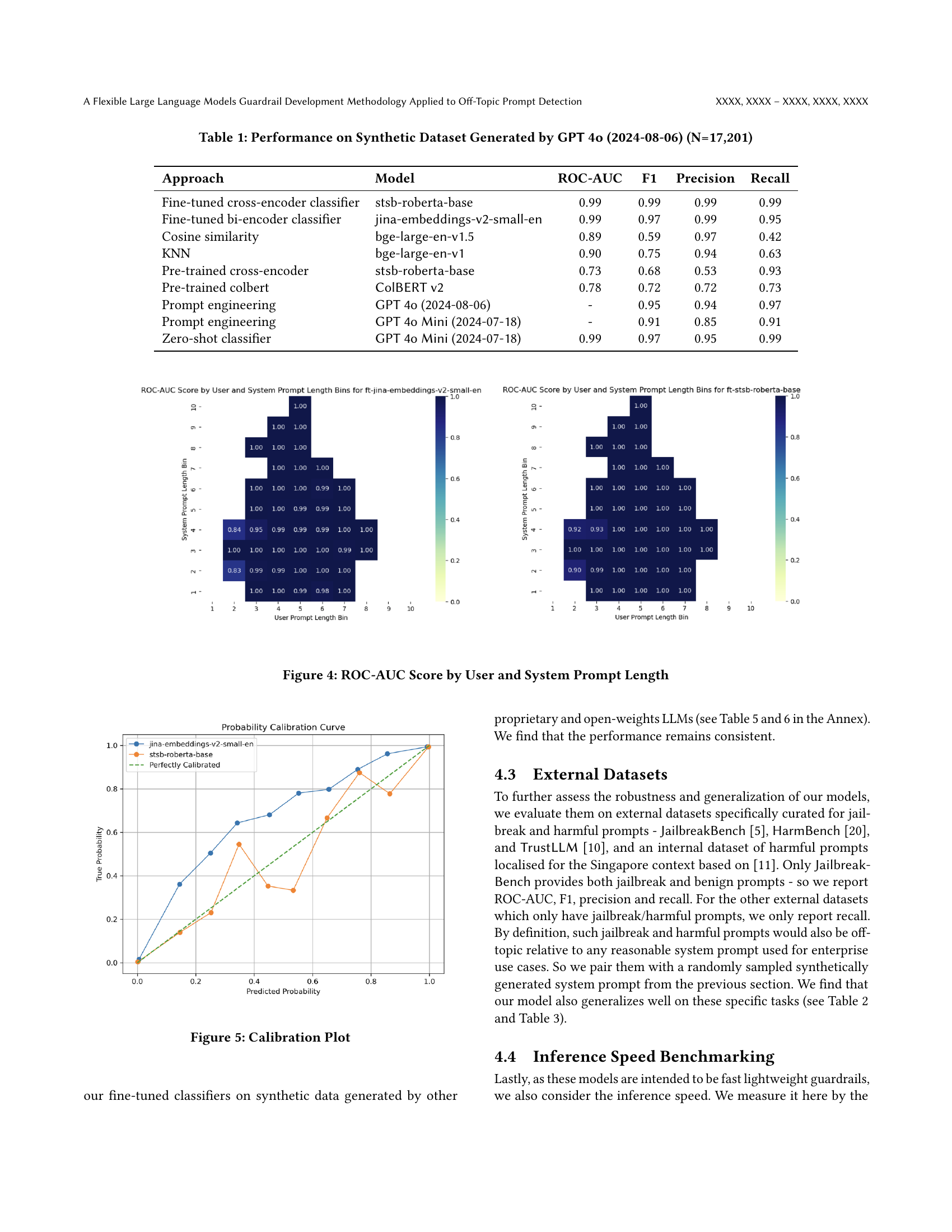
🔼 This figure shows the relationship between the length of user prompts and system prompts and the ROC-AUC score achieved by the fine-tuned bi-encoder and cross-encoder models for off-topic prompt detection. It visualizes how the model’s performance (as measured by ROC-AUC) varies depending on the lengths of both prompt types. The heatmaps allow for easy visual comparison of ROC-AUC across various lengths of system prompts and user prompts.
read the caption
Figure 4. ROC-AUC Score by User and System Prompt Length

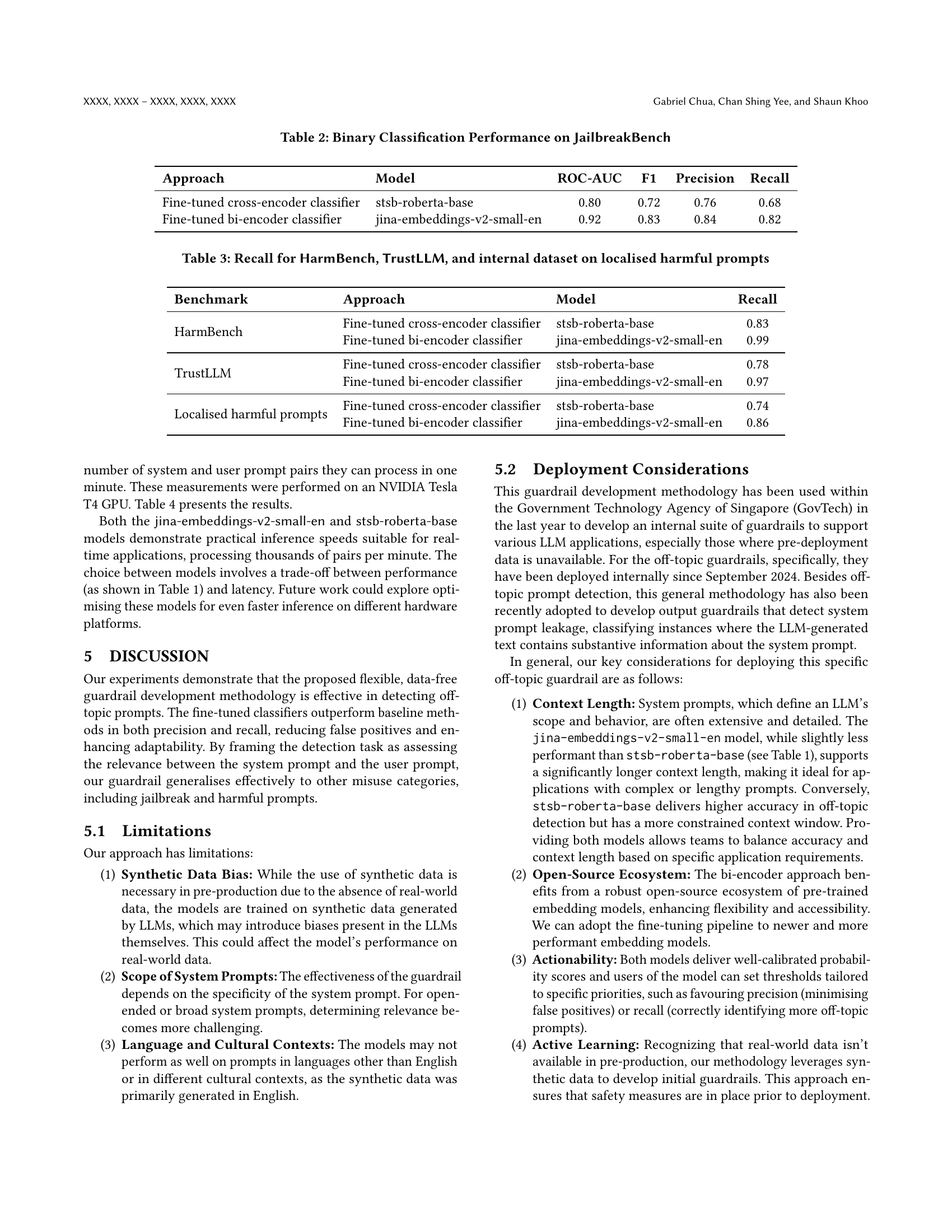
🔼 This calibration plot displays the reliability of the probability scores outputted by the fine-tuned bi-encoder and cross-encoder models. It shows the relationship between the predicted probability (the model’s confidence in its prediction) and the actual probability (the true rate of correct predictions). A perfectly calibrated model would show a diagonal line, indicating that a predicted probability of 0.8 means that the model is correct 80% of the time. Deviations from this line indicate areas where the model is either overconfident (predicting higher probabilities than it should) or underconfident (predicting lower probabilities than it should). This plot helps to evaluate the trustworthiness of the probability scores produced by the models, which is important for decision making, as developers may choose to apply different thresholds for flagging or taking actions based on confidence levels.
read the caption
Figure 5. Calibration Plot
More on tables
| Approach | Model | ROC-AUC | F1 | Precision | Recall |
|---|---|---|---|---|---|
| Fine-tuned cross-encoder classifier | stsb-roberta-base | 0.80 | 0.72 | 0.76 | 0.68 |
| Fine-tuned bi-encoder classifier | jina-embeddings-v2-small-en | 0.92 | 0.83 | 0.84 | 0.82 |
🔼 This table presents the results of a binary classification task using the JailbreakBench dataset. It shows the performance of fine-tuned cross-encoder and bi-encoder classifiers, comparing their performance metrics such as ROC-AUC, F1 score, precision, and recall. The table allows readers to compare the effectiveness of different model architectures (cross-encoder vs. bi-encoder) in detecting jailbreak attempts on LLMs.
read the caption
Table 2. Binary Classification Performance on JailbreakBench
| Benchmark | Approach | Model | Recall |
|---|---|---|---|
| HarmBench | Fine-tuned cross-encoder classifier | stsb-roberta-base | 0.83 |
| Fine-tuned bi-encoder classifier | jina-embeddings-v2-small-en | 0.99 | |
| TrustLLM | Fine-tuned cross-encoder classifier | stsb-roberta-base | 0.78 |
| Fine-tuned bi-encoder classifier | jina-embeddings-v2-small-en | 0.97 | |
| Localised harmful prompts | Fine-tuned cross-encoder classifier | stsb-roberta-base | 0.74 |
| Fine-tuned bi-encoder classifier | jina-embeddings-v2-small-en | 0.86 |
🔼 This table presents the recall scores achieved by two fine-tuned models (fine-tuned cross-encoder classifier and fine-tuned bi-encoder classifier) when evaluated against three different datasets containing harmful or inappropriate prompts: HarmBench, TrustLLM, and an internal dataset specific to Singapore. The internal dataset contains localized harmful prompts, reflecting the nuances of the Singaporean context. The table highlights the models’ performance in identifying harmful content within each dataset, showcasing their ability to generalize across diverse resources.
read the caption
Table 3. Recall for HarmBench, TrustLLM, and internal dataset on localised harmful prompts
| Approach | Model | Processed Pairs Per Minute | Latency Per Pair (s) |
|---|---|---|---|
| Fine-tuned bi-encoder classifier | jina-embeddings-v2-small-en | 2,216 | 0.027 |
| Fine-tuned cross-encoder classifier | stsb-roberta-base | 1,919 | 0.031 |
🔼 This table presents the inference speed of two fine-tuned models (fine-tuned bi-encoder classifier and fine-tuned cross-encoder classifier) used for off-topic prompt detection. It shows the number of prompt pairs each model can process per minute and the latency (in seconds) for processing a single pair. This data is important for evaluating the real-time performance and suitability of these models for deployment as guardrails.
read the caption
Table 4. Inference Speed Benchmarking
Full paper#