↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current large multimodal model (LMM) evaluation methods for video analysis rely heavily on traditional benchmarks using multiple-choice questions. These methods often fail to capture the nuances of real-world user interaction and are expensive and time-consuming. This paper addresses these issues by proposing a new evaluation method.
The proposed method, VideoAutoArena, uses Large Language Models (LLMs) to simulate human users, generating open-ended and adaptive questions. It incorporates an automated judging system and a fault-driven evolution strategy to enhance scalability and rigor. The results demonstrate that VideoAutoArena effectively differentiates among state-of-the-art LMMs and aligns well with human judgment, offering a cost-effective and scalable evaluation framework.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video analysis and multimodal learning. It introduces VideoAutoArena, a novel and scalable automated evaluation framework addressing the limitations of existing benchmarks. This significantly reduces the high cost and time associated with human annotation, and opens new avenues for research on LMM evaluation. The fault-driven evolution strategy enhances evaluation rigor, while VideoAutoBench provides a streamlined alternative for quick assessments.
Visual Insights#

🔼 This figure illustrates the VideoAutoArena, a novel automated benchmark for evaluating large multimodal models (LMMs) in video analysis. Unlike traditional methods relying on human annotation, VideoAutoArena uses LMMs to simulate user behavior, generating open-ended, adaptive questions to assess LMM performance. The system includes a peer battle mechanism where two LMMs answer the same question and an automated judging system to determine the better response. The figure showcases four sample frames from a Singapore travel vlog video used in the benchmark, highlighting the type of video content analyzed.
read the caption
Figure 1: An overview of our VideoAutoArena, where we leverage LMMs for user simulation to automatically evaluate LMMs in video analysis, offering an efficient alternative to costly and time-consuming human annotations, distinct from platforms like LMSYS Chatbot Arena [14] and WildVision Arena [45]. In this figure, we showcase 4 sampled frames from a Singapore travel vlog video.
| Benchmark | Venue | Long Video Included | User-Centric | Scalable | Open-Ended | Automated |
|---|---|---|---|---|---|---|
| MVBench [35] | CVPR 24 | ✗ | ✗ | ✗ | ✗ | ✓ |
| MLVU [78] | Arxiv 24 | ✓ | ✗ | ✗ | ✗ | ✓ |
| LVBench [58] | Arxiv 24 | ✓ | ✗ | ✗ | ✗ | ✓ |
| VideoMME [20] | Arxiv 24 | ✓ | ✗ | ✗ | ✗ | ✓ |
| LongVideoBench [59] | NeurIPS 24 | ✓ | ✗ | ✗ | ✗ | ✓ |
| WildVision Video Arena [45] | NeurIPS 24 | ? | ✓ | ✗ | ✓ | ✗ |
| VideoAutoArena (Ours) | - | ✓ | ✓ | ✓ | ✓ | ✓ |
🔼 Table 1 compares several recent popular benchmarks for video analysis, highlighting key differences in their features. These features include whether the benchmark uses videos of long duration, whether the evaluation is user-centric (focuses on real-world user needs and questions), scalability of the evaluation (ability to handle a large number of models and videos), whether the benchmark uses open-ended questions (allowing for more complex and nuanced responses) rather than multiple choice questions, and finally, whether the evaluation process is automated.
read the caption
Table 1: Comparison of recent popular benchmarks for video analysis. WildVision video data are not yet publicly available.
In-depth insights#
Auto Arena Eval#
An ‘Auto Arena Eval’ system for evaluating large multimodal models (LMMs) in video analysis would necessitate a robust and scalable infrastructure. Automated user simulation is crucial to generate diverse and realistic queries, mimicking real-world user interaction with video content. This requires sophisticated techniques like persona generation and context-aware question formulation. A pairwise comparison approach (peer battles) allows for relative ranking of LMMs, reducing the need for absolute scoring which is often subjective. The system should incorporate automatic judging mechanisms that align with human preferences, possibly through a combination of rule-based and machine learning methods. Fault-driven evolution, where question difficulty increases based on LMM performance, ensures continuous improvement and rigorous evaluation. The effectiveness of the ‘Auto Arena Eval’ system hinges on the accuracy of its automated components and their ability to capture the nuances of human judgment. Benchmarking against human evaluation provides a crucial validation step, quantifying the level of alignment and identifying areas for improvement.
User Sim LMMs#
Employing Large Multimodal Models (LMMs) for user simulation in evaluating video analysis capabilities presents a significant advancement. User Sim LMMs offer a scalable alternative to expensive and time-consuming human annotation, a crucial limitation of traditional methods. By simulating diverse user personas and their associated question-asking styles, User Sim LMMs create a more realistic and comprehensive evaluation benchmark. This approach allows for a deeper understanding of model strengths and weaknesses in handling complex, real-world video analysis tasks. The automated nature of User Sim LMMs facilitates continuous and efficient model comparison, allowing for dynamic ranking and iterative model improvement. However, challenges remain in ensuring the realism and diversity of simulated users, as well as in developing robust and unbiased automated judging systems. The future development of User Sim LMMs will depend on progress in LLM capabilities, specifically in natural language generation and nuanced user persona modeling.
Fault-Driven Evol#
The concept of “Fault-Driven Evol” suggests an iterative process of improving a system, specifically an AI model for video analysis, by focusing on its weaknesses. It implies that the system isn’t just evaluated passively; rather, its shortcomings are actively analyzed to generate increasingly complex and challenging questions. This approach goes beyond traditional benchmarking by dynamically adapting the evaluation to push the model’s boundaries. This iterative refinement, driven by identified faults, is crucial for achieving robust and generalizable performance. The method’s effectiveness stems from the use of a feedback loop where the model’s deficiencies inform the creation of more difficult scenarios, ensuring it is constantly tested and improved in user-centric ways. This is a significant departure from static benchmark tests and more closely resembles real-world usage, where the challenges and types of questions are rarely constant. The ultimate goal is to develop more resilient and sophisticated models able to handle the unpredictable nature of actual user interactions and diverse video analysis tasks.
ELO Ranking Sys#
An ELO ranking system, when applied to a multimodal model evaluation arena like the one described, provides a robust and dynamic mechanism for comparing model performance. Its strength lies in its continuous and adaptive nature, allowing for a fluid recalibration of model rankings as new comparisons are made. This contrasts with static benchmarks that offer only a snapshot in time. The system’s reliance on pairwise comparisons, simulating real-world user interactions, makes the rankings more meaningful and reflective of actual user preference. The use of an ELO system allows for a fair comparison even if models have not competed against each other directly. However, it is important to acknowledge potential limitations, such as the system’s sensitivity to the initial ratings and the potential for biases in the questions used to generate the comparisons. To mitigate these limitations, the research may utilize various techniques, such as incorporating a large number of battles and employing methods to minimize stylistic bias and improve question selection. The key benefit remains the system’s ability to provide a continuously updated and relative ranking across multiple models, highlighting strengths and weaknesses in a dynamic and user-centric evaluation framework.
Benchmark Limits#
The heading ‘Benchmark Limits’ prompts a critical examination of current video analysis benchmarks. A thoughtful analysis would explore their inherent constraints, such as the reliance on multiple-choice questions, which may not fully capture the nuances of real-world user interactions. The limited scope of current benchmarks and the lack of user-centric evaluation also need to be addressed, which would highlight the need for benchmarks that evaluate a model’s ability to handle complex, open-ended questions in diverse contexts. An ideal benchmark would emphasize scalability and cost-effectiveness, as well as its ability to accurately assess various aspects of model performance. Investigating these limitations is key to developing more comprehensive and realistic evaluations for large multimodal models, ultimately advancing the field of video analysis.
More visual insights#
More on figures

🔼 This figure shows two pie charts visualizing the distribution of videos used in the VideoAutoArena benchmark. The left chart presents the video categories, indicating the proportion of videos in each category (Movie, Life Vlogs, Geography, History, News Programs, Art, STEM, Computer Science, Cooking Recipes, and Travel Guides). The right chart displays the video duration distribution, showing the percentage of videos falling within four duration ranges: (8s, 15s], (15s, 60s], (180s, 600s], and (900s, 3600s]. The total number of videos used (2881) is indicated in both charts.
read the caption
Figure 2: Video statistics by category and duration.
🔼 This figure showcases examples of user personas synthesized by VideoAutoArena, categorized by their relevance to the video content (highly related, moderately related, and unrelated). For each persona, a corresponding question is generated to exemplify how user simulation produces open-ended questions for video understanding tasks. The questions are designed to assess the models’ video analysis abilities from a user-centric perspective. The figure also contrasts the question styles of VideoAutoArena with those of existing benchmarks (LongVideoBench and VideoMME), highlighting how VideoAutoArena’s approach better reflects realistic user inquiries.
read the caption
Figure 3: Examples of synthesized personas with three levels of relevance and corresponding synthesized questions. We also compare the style of our questions with those in popular long-video benchmarks, including LongVideoBench and VideoMME.

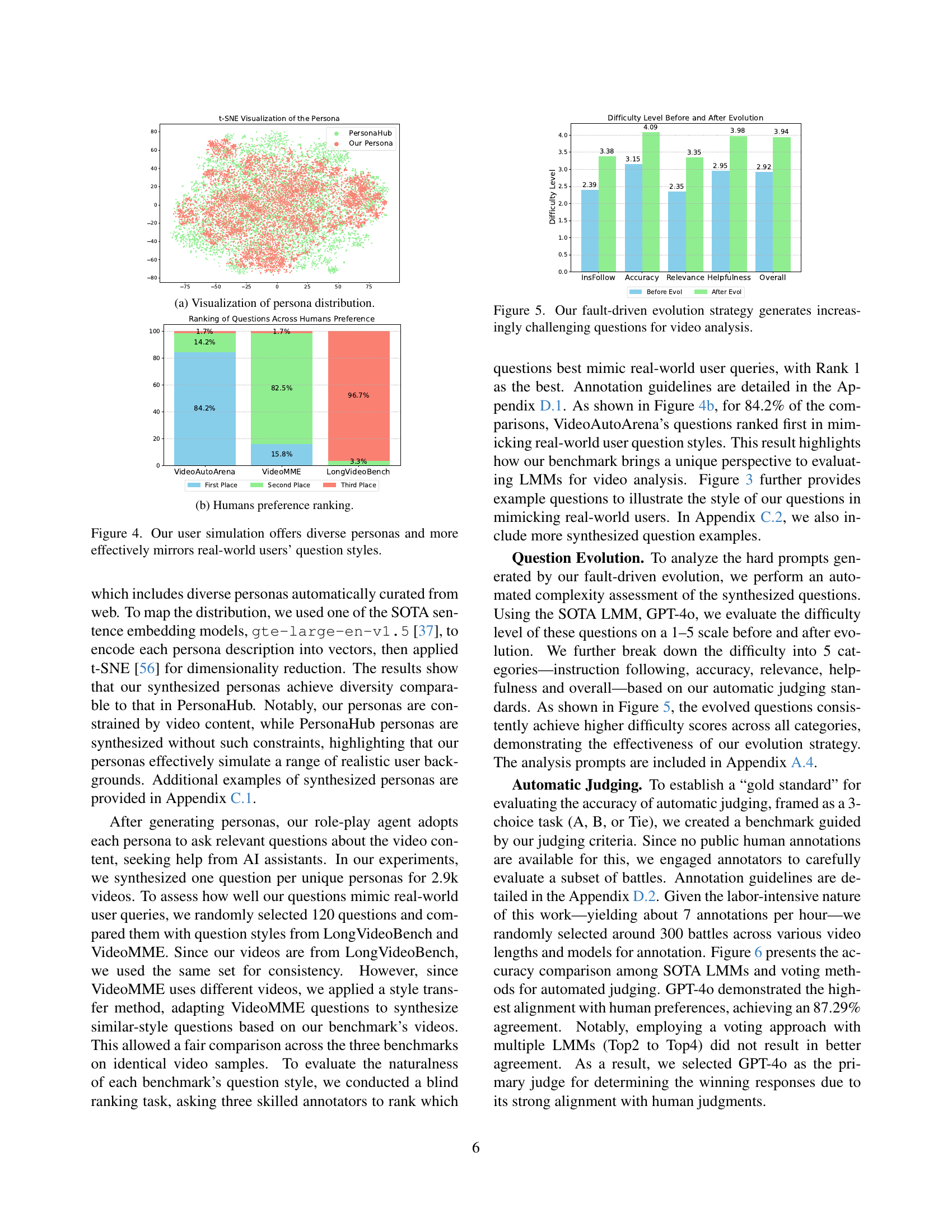
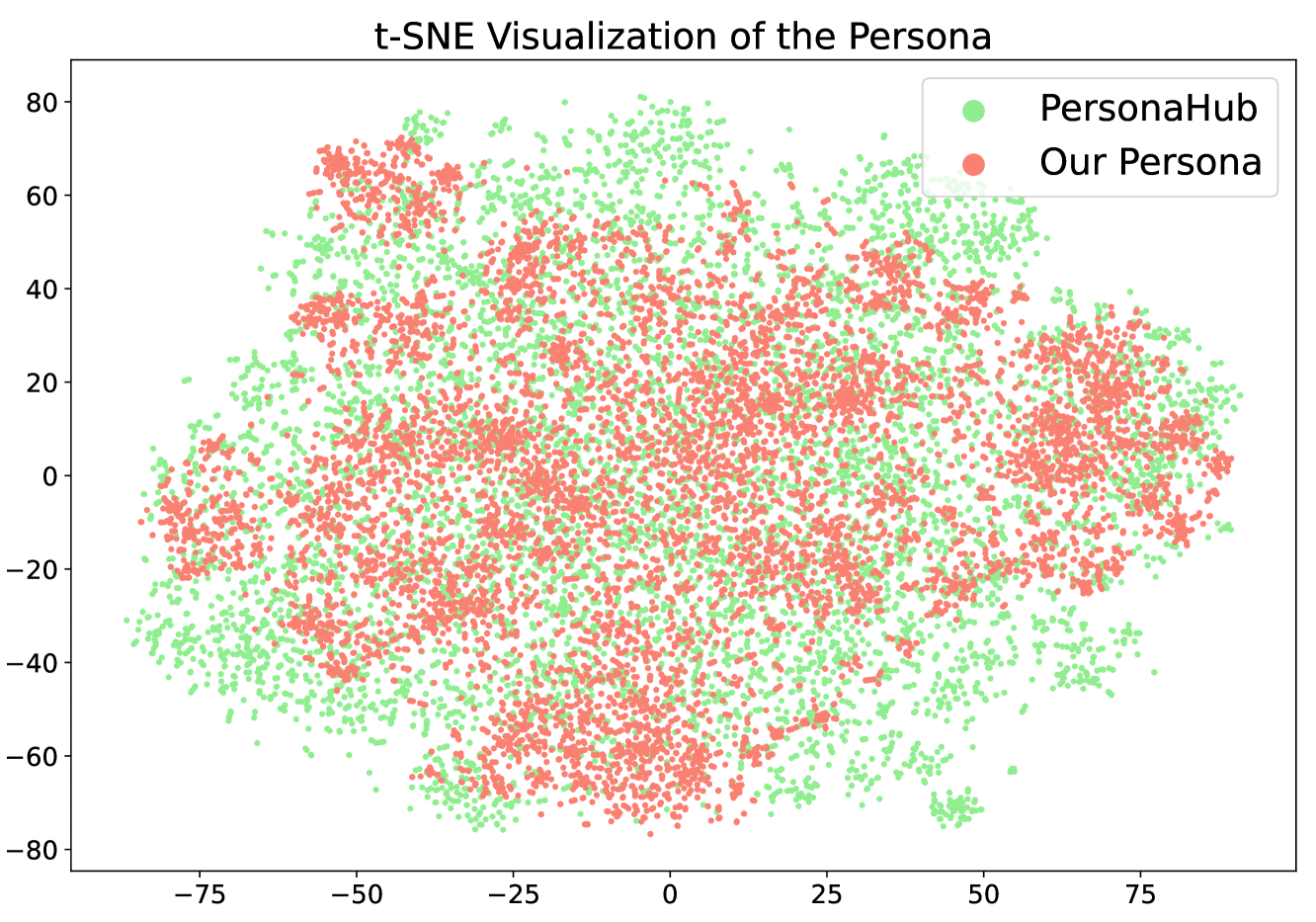
🔼 This visualization uses t-SNE to reduce the dimensionality of persona vectors, derived from a sentence embedding model encoding persona descriptions. It compares the distribution of automatically generated personas from VideoAutoArena with those from the PersonaHub dataset. This allows for a visual comparison of the diversity and representativeness of the user personas generated by VideoAutoArena relative to a well-established, publicly available persona dataset.
read the caption
(a) Visualization of persona distribution.

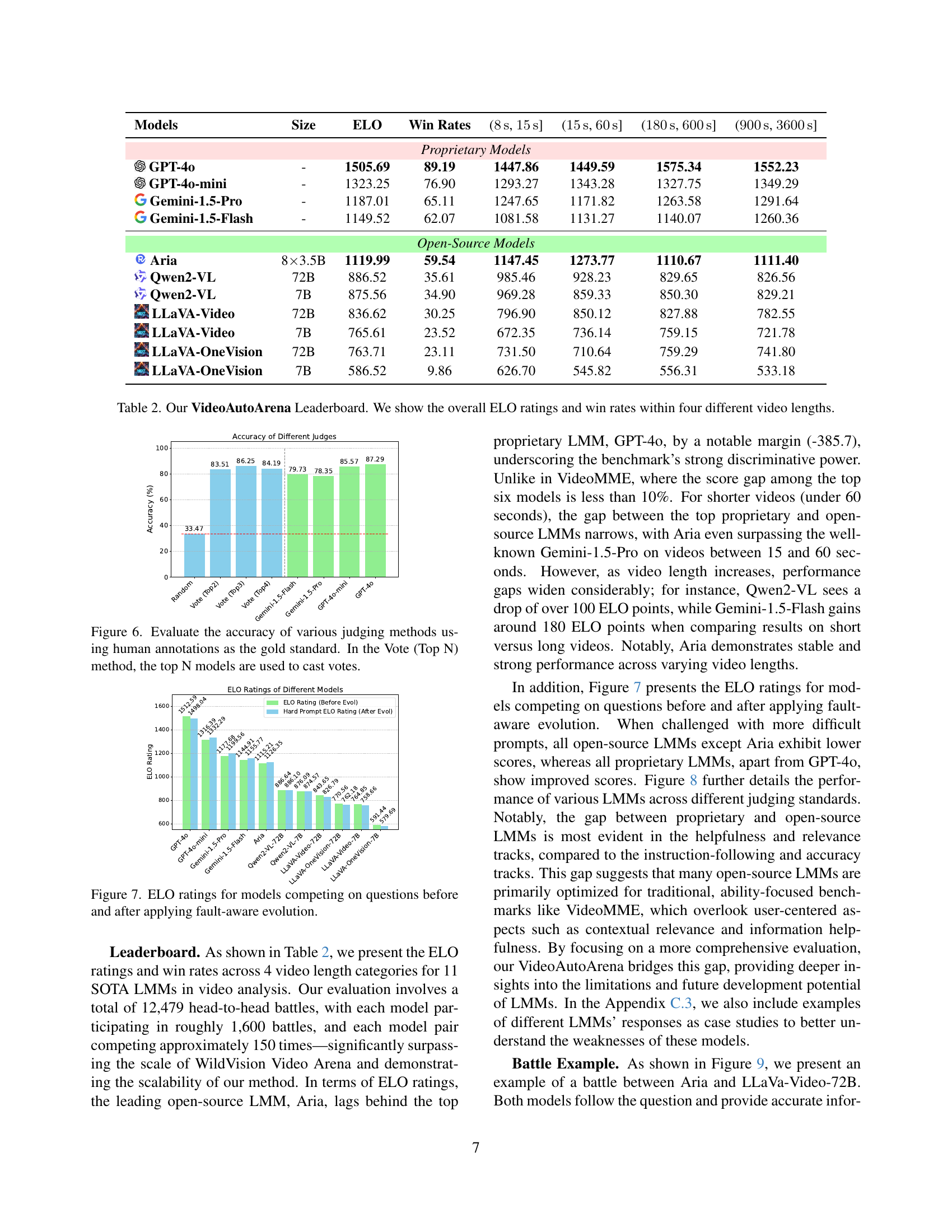
🔼 This figure presents a bar chart comparing the ranking of questions from VideoAutoArena, VideoMME, and LongVideoBench, based on human preference. The chart shows the percentage of times each benchmark’s questions were ranked first, second, or third by human evaluators. This indicates how well each benchmark’s question style mirrors real-world user queries in video analysis.
read the caption
(b) Humans preference ranking.

🔼 This figure visualizes the distribution of personas generated by VideoAutoArena and compares it to the distribution of personas from PersonaHub. The left-hand panel (4a) uses t-SNE to project the high-dimensional persona embeddings into a 2D space, showing a wider spread of our generated personas compared to PersonaHub. The right-hand panel (4b) shows a bar chart comparing the ranking of questions across humans, based on whether the question style best reflects real-world user questions. VideoAutoArena outperforms VideoMME and LongVideoBench, indicating its questions more accurately simulate real user queries.
read the caption
Figure 4: Our user simulation offers diverse personas and more effectively mirrors real-world users’ question styles.

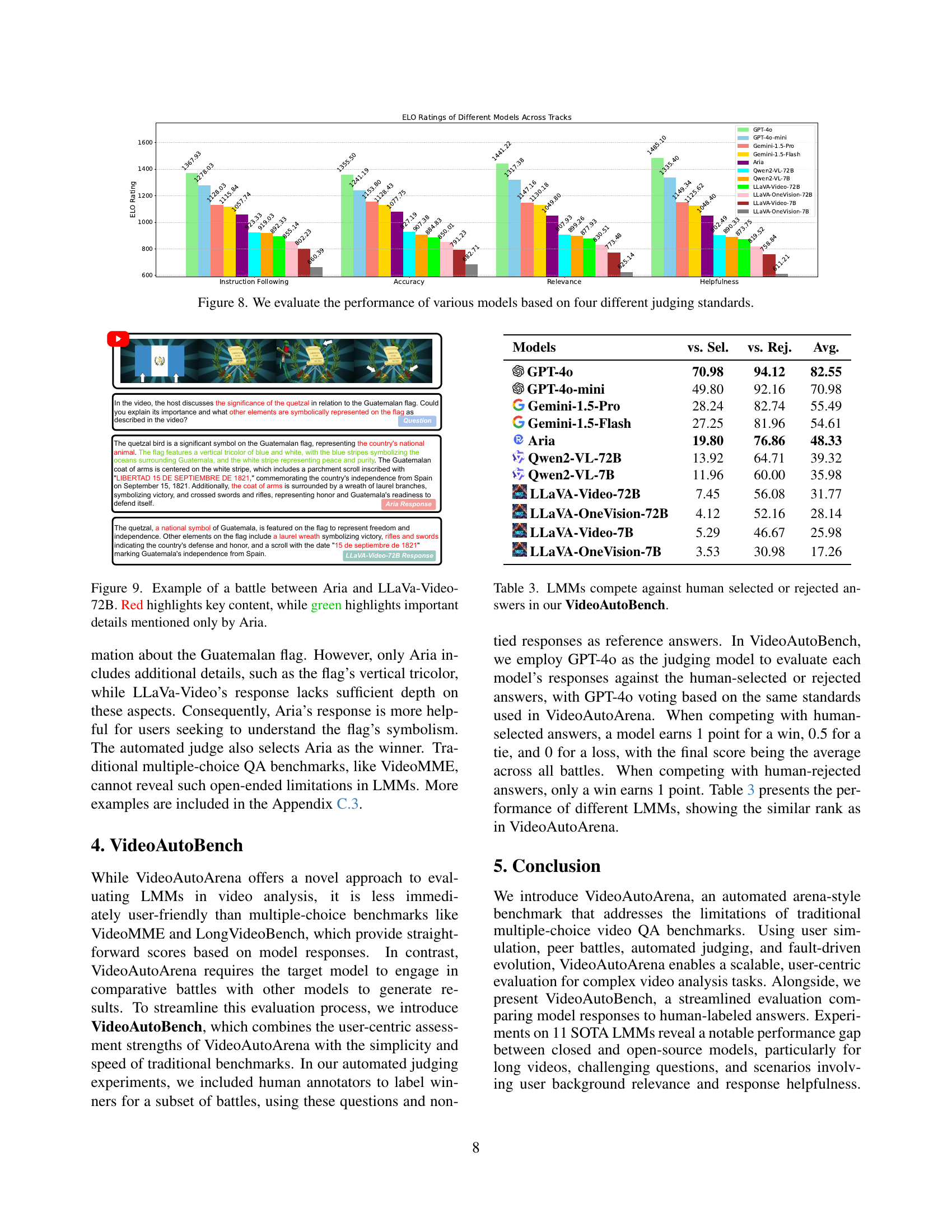
🔼 This figure demonstrates how the fault-driven evolution strategy in VideoAutoArena progressively increases the difficulty of questions posed to large multimodal models (LMMs). It shows that by iteratively analyzing model responses and identifying weaknesses, the system generates increasingly complex and nuanced questions designed to push the models’ video analysis capabilities. The graph likely displays metrics (e.g., question complexity scores or model performance) over a series of evolving questions, illustrating the improvement in question difficulty achieved by the fault-driven evolution strategy.
read the caption
Figure 5: Our fault-driven evolution strategy generates increasingly challenging questions for video analysis.

🔼 This figure displays the accuracy of different judging methods for evaluating large multimodal models (LMMs) in video analysis. The accuracy of each method is measured against human annotations, which serve as the gold standard. Specifically, it compares the accuracy of using a single SOTA LMM (GPT-40) as a judge against using a voting system based on the top N performing LMMs. The voting system uses the top 2, 3, and 4 models’ judgments to arrive at a final decision. This demonstrates the effectiveness of utilizing a single, high-performing model versus a consensus-based approach for automating the judging process in a scalable and efficient video analysis benchmark.
read the caption
Figure 6: Evaluate the accuracy of various judging methods using human annotations as the gold standard. In the Vote (Top N) method, the top N models are used to cast votes.

🔼 This figure displays the ELO ratings of eleven large multimodal models (LMMs) before and after applying a fault-driven evolution strategy. The fault-driven evolution progressively increases the complexity of the questions asked to the models, testing their capabilities more rigorously. The comparison allows for an assessment of how well each model adapts to more challenging video analysis scenarios.
read the caption
Figure 7: ELO ratings for models competing on questions before and after applying fault-aware evolution.

🔼 This figure displays a bar chart visualizing the performance of eleven large multimodal models (LMMs) across four evaluation metrics: Instruction Following, Accuracy, Relevance, and Helpfulness. Each bar represents an LMM’s score on a specific metric, allowing for a comparison of model strengths and weaknesses across various aspects of video understanding. The chart offers insights into how different models perform on user-centric evaluation standards, highlighting the importance of assessing LMMs beyond traditional accuracy metrics.
read the caption
Figure 8: We evaluate the performance of various models based on four different judging standards.

🔼 This figure showcases a comparison between two large multimodal models (LLMs), Aria and LLaVa-Video-72B, in a head-to-head comparison on a video analysis task. The models were asked the same question about the video. The responses are shown side-by-side. Key information correctly identified by both models is highlighted in red. Information correctly mentioned only by Aria, demonstrating its superior performance on this specific task, is highlighted in green. This example illustrates the type of detailed comparison used in the VideoAutoArena benchmark to automatically evaluate different LLMs on their ability to understand and respond to video analysis queries.
read the caption
Figure 9: Example of a battle between Aria and LLaVa-Video-72B. Red highlights key content, while green highlights important details mentioned only by Aria.

🔼 This figure shows the prompt used in the VideoAutoArena framework for generating user personas based on video content. The prompt instructs the language model to generate three personas: one with a background highly relevant to the video, one with a moderately relevant background, and one with an unrelated background. For each persona, a short paragraph description is requested to simulate real users’ diverse backgrounds and motivations for seeking video analysis assistance.
read the caption
Figure 10: The prompt for video content-constrained persona generation.

🔼 This figure shows the prompt used to instruct a large language model (LLM) to generate questions for video analysis. The prompt simulates a real user by providing a persona (a description of a user’s background, interests, etc.) and then asks the LLM to create a question about a video that would align with that persona. The prompt emphasizes generating a high-quality, realistic question that a real user would ask, rather than a question designed purely for testing the LLM’s capabilities. The prompt also includes instructions for the LLM to provide an ideal response to the question it generated, which helps to evaluate the LLM’s overall video understanding capabilities.
read the caption
Figure 11: The prompt for persona-constrained video question asking.

🔼 This figure shows the prompt used in the VideoAutoArena framework to generate new questions for model evaluation. The process is iterative and designed to increase the complexity of the questions. The prompt instructs the agent to analyze responses from two models, identify their faults and weaknesses, and generate a new, more challenging question targeting those weaknesses. The goal is to create a progressively more difficult evaluation by focusing on model shortcomings in previous rounds. The new question should still align with the user’s persona, but focus on areas where the previous models showed flaws in their understanding of the video.
read the caption
Figure 12: The prompt for our fault-driven evolution generates new questions based on the responses from the two models.

🔼 This figure displays the prompt used by the researchers for their automatic judging process in VideoAutoArena. The prompt instructs the judge (an LLM) to evaluate two model responses to a video-related question based on four criteria: Instruction Following, Accuracy, Relevance, and Helpfulness. The judge must analyze each response for these criteria and then provide an overall judgment: Model A wins, Model B wins, Tie (both good), or Tie (both bad). The detailed criteria for each of the four dimensions are also provided.
read the caption
Figure 13: The prompt for our automatic judging.

🔼 This figure shows the prompt used to automatically evaluate the complexity of questions generated for VideoAutoArena. The prompt presents two questions to the evaluator, who must rate each question across four criteria (Instruction Following, Accuracy, Relevance, Helpfulness) on a scale of 1-5 (1 being easiest, 5 being hardest). The evaluator then provides an overall difficulty score for each question. This process helps to ensure that the questions used in VideoAutoArena are progressively challenging and suitable for evaluating the capabilities of large multimodal models (LMMs).
read the caption
Figure 14: The prompt for question complexity evaluation.

🔼 This figure showcases examples of user simulations generated by VideoAutoArena for five diverse videos, representing different domains: Movies, Computer Science, Life Vlogs, Art, and News Programs. For each video, VideoAutoArena simulates a user persona, generating corresponding questions to assess LMMs’ video understanding capabilities. The figure displays four representative frames from each video to illustrate the variety of content used in the benchmark and to highlight the diverse contexts within which user simulations are generated.
read the caption
Figure 15: Examples of our user simulation include five videos from diverse domains: Movies, Computer Science, Life Vlogs, Art, and News Programs. To save space, we only showcase 4 frames of each video.

🔼 This figure shows a battle between two large multimodal models (LMMs), Aria and GPT-40, in the VideoAutoArena benchmark. A question is posed regarding the PC-DAN (Point Cloud Deep Affinity Network) method for 3D multi-object tracking, specifically how it uses point clouds and its advantages in autonomous vehicles. The responses from Aria and GPT-40 are presented, highlighting differences in their level of detail, technical accuracy, and relevance to the user’s background. A judging section follows, evaluating each response based on four criteria: Instruction Following, Accuracy, Relevance, and Helpfulness. The final judgement indicates which model is superior based on this evaluation.
read the caption
Figure 16: Example of the battle between Aria and GPT-4o.

🔼 This figure shows a battle between two large multimodal models (LMMs): GPT-40-mini and LLaVa-Video-72B, in the VideoAutoArena benchmark. Both models receive the same video and a question from a simulated user persona (an art teacher seeking lesson plan ideas). The models’ responses are evaluated based on instruction following, accuracy, relevance, and helpfulness, with GPT-40-mini ultimately deemed the better response. The figure illustrates the automated evaluation process in VideoAutoArena, showing how the benchmark generates comparable responses and compares their quality using automated metrics. The comparative results show that GPT-40-mini produced a more detailed and helpful response for teaching purposes.
read the caption
Figure 17: Example of the battle between GPT-4o-mini and LLaVa-Video-72B.

🔼 This figure shows a side-by-side comparison of the responses generated by Qwen2-VL-72B and LLaVa-Video-7B to the same question. The question is posed within the context of a video about foraging for herbs and making tea, connecting it to folklore and personal stories. The figure highlights how each model addresses the question, allowing for a qualitative assessment of their strengths and weaknesses in terms of instruction following, accuracy, relevance, and helpfulness in this specific context. The automatic judging section determines which model’s answer is better, based on predefined criteria.
read the caption
Figure 18: Example of the battle between Qwen2-VL-72B and LLaVa-Video-7B.

🔼 This figure showcases a comparison of responses generated by Aria and Qwen2-VL-72B to a user’s question about a historical artifact called the ‘Mantuan Roundel.’ The user, described in a persona, asks about the significance of the materials and techniques used in the artifact, and how they reflect Renaissance artistic practices. Both models attempt to answer, but the figure highlights that Aria provides a more detailed and accurate response, including specific details about the materials and techniques (gilding, silvering) and connecting them to specific themes in Renaissance art. The automatic judging system in the VideoAutoArena framework favors Aria’s response as more helpful and relevant.
read the caption
Figure 19: Example of the battle between Aria and Qwen2-VL-72B.
More on tables
| Models | Size | ELO | Win Rates | (8s, 15s) | (15s, 60s) | (180s, 600s) | (900s, 3600s) |
|---|---|---|---|---|---|---|---|
Proprietary Models | |||||||
| - | 1505.69 | 89.19 | 1447.86 | 1449.59 | 1575.34 | 1552.23 | |
| - | 1323.25 | 76.90 | 1293.27 | 1343.28 | 1327.75 | 1349.29 | |
| - | 1187.01 | 65.11 | 1247.65 | 1171.82 | 1263.58 | 1291.64 | |
| - | 1149.52 | 62.07 | 1081.58 | 1131.27 | 1140.07 | 1260.36 | |
Open-Source Models | |||||||
| 8 × 3.5B | 1119.99 | 59.54 | 1147.45 | 1273.77 | 1110.67 | 1111.40 | |
| 72B | 886.52 | 35.61 | 985.46 | 928.23 | 829.65 | 826.56 | |
| 7B | 875.56 | 34.90 | 969.28 | 859.33 | 850.30 | 829.21 | |
| 72B | 836.62 | 30.25 | 796.90 | 850.12 | 827.88 | 782.55 | |
| 7B | 765.61 | 23.52 | 672.35 | 736.14 | 759.15 | 721.78 | |
| 72B | 763.71 | 23.11 | 731.50 | 710.64 | 759.29 | 741.80 | |
| 7B | 586.52 | 9.86 | 626.70 | 545.82 | 556.31 | 533.18 |
🔼 This table presents the results of the VideoAutoArena benchmark, which automatically evaluates large multimodal models (LMMs) in video analysis. It shows the overall ELO rating for each of the 11 models tested, reflecting their relative performance across multiple video lengths. Win rates are also provided for four distinct video duration ranges (8-15s, 15-60s, 180-600s, 900-3600s). The ELO ratings represent a continuous comparison across multiple models and video lengths, facilitating a dynamic and fair assessment of LMM video analysis capabilities.
read the caption
Table 2: Our VideoAutoArena Leaderboard. We show the overall ELO ratings and win rates within four different video lengths.
| Models | vs. Sel. | vs. Rej. | Avg. |
|---|---|---|---|
 | 70.98 | 94.12 | 82.55 |
| 49.80 | 92.16 | 70.98 |
 | 28.24 | 82.74 | 55.49 |
| 27.25 | 81.96 | 54.61 |
 | 19.80 | 76.86 | 48.33 |
 | 13.92 | 64.71 | 39.32 |
| 11.96 | 60.00 | 35.98 |
 | 7.45 | 56.08 | 31.77 |
| 4.12 | 52.16 | 28.14 |
| 5.29 | 46.67 | 25.98 |
| 3.53 | 30.98 | 17.26 |
🔼 This table presents the results of a benchmark called VideoAutoBench. VideoAutoBench uses human annotations from a subset of battles (model comparisons) in VideoAutoArena to create a gold standard. GPT-40, a large language model, is then used as an automatic judge to compare the model’s answers against these human-selected answers (correct responses) and human-rejected answers (incorrect responses). The table shows how well each model performs compared to these human judgments, providing a streamlined and cost-effective evaluation method for large multimodal models (LMMs) in video analysis.
read the caption
Table 3: LMMs compete against human selected or rejected answers in our VideoAutoBench.
Full paper#