↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
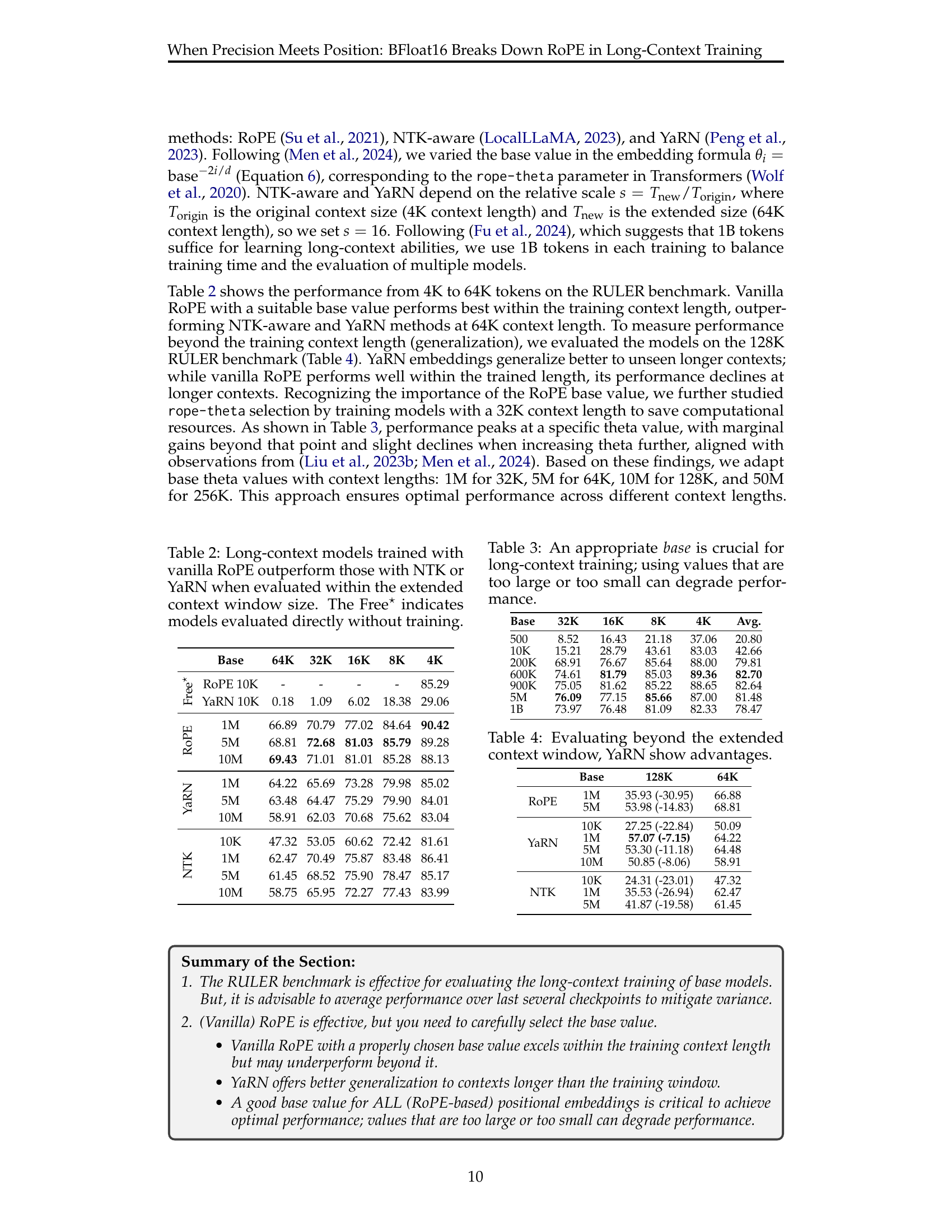
Large language models (LLMs) are increasingly focusing on handling longer text sequences, which necessitates advanced positional encoding techniques like Rotary Positional Embedding (RoPE). However, using RoPE with reduced precision arithmetic, such as BFloat16, which is commonly used to reduce memory and computational costs, causes unexpected numerical issues. These issues become more severe as the text length increases, significantly impacting the accuracy of the positional encoding. This is a critical challenge in scaling LLMs to process longer sequences effectively.
To address this, the researchers propose AnchorAttention, a new attention method that improves upon existing solutions. AnchorAttention is a plug-and-play method which focuses on the first token as an anchor. It is designed to mitigate numerical issues by leveraging the first token in the context window as an anchor that remains constant across all documents. This strategy reduces unnecessary attention calculations while effectively maintaining the contextual information needed for longer sequence processing. The experimental results demonstrate that AnchorAttention significantly improves the long-context performance of LLMs across various datasets and models, and also speeds up the training process. The findings provide valuable insights into the challenges of long-context training and introduce a potentially impactful solution to address these issues.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical issue in long-context training of large language models (LLMs), which is a very active area of research. The findings challenge the prevailing assumption about the robustness of RoPE under BFloat16 and open new avenues for improving long-context performance and reducing training time. This is highly relevant for researchers working on LLMs, attention mechanisms, and efficient training strategies.
Visual Insights#

🔼 Figure 1 illustrates the impact of positional shifts on attention mechanisms, specifically focusing on the effects of using BFloat16 precision with Rotary Positional Embeddings (RoPE). The left panel displays the attention difference (D) against varying positional shifts (Δ1), holding Δ2 constant at 16. It highlights a significant discrepancy between pretrained models using BFloat16 (blue) versus Float32 (yellow) and randomly initialized models (green), demonstrating that BFloat16 breaks RoPE’s relative positional encoding, and that this effect is amplified by pretraining. The middle panel shows per-token attention differences between Δ1=0 and Δ2=16, revealing the first token’s disproportionate contribution to the observed discrepancies. The right panel illustrates the attention logit difference for the first token as sequence length increases, indicating that the discrepancies become more pronounced with longer sequences.
read the caption
Figure 1: Effects of positional shifts on attention computations under different settings. Left: Attention difference D𝐷Ditalic_D (Eq. 4) plotted against varying positional shift Δ1subscriptΔ1\Delta_{1}roman_Δ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT (with Δ2=16subscriptΔ216\Delta_{2}=16roman_Δ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT = 16 fixed). Pretrained models under BFloat16 (blue line) exhibit significant discrepancies compared to Float32 (yellow line) and random initialization (green line), indicating that the relative positional encoding property of RoPE is broken under BFloat16 and that pretraining amplifies this effect. Middle: Per-token attention differences between Δ1=0subscriptΔ10\Delta_{1}=0roman_Δ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT = 0 and Δ2=16subscriptΔ216\Delta_{2}=16roman_Δ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT = 16, highlighting the first token accounts for most of the attention difference observed. Right: Attention logit difference (Eq. 5) for the first token as sequence length increases, showing increased discrepancies with longer sequences.
| Long-context Continuous Training | ||
|---|---|---|
| Data | UpSampledMix / SlimPajama128K/ SlimPajama64K | |
| UpSampledMix-128K: | 58% CC, 20% C4, 7% GitHub, 6% ArXiv, 5% Books, 4% Wiki, 2% StackExchange | |
| SlimPajama-128K: | 53% CC, 27% C4, 5% GitHub, 5% ArXiv, 4% Books, 3% Wiki, 3% StackExchange | |
| SlimPajama-64K: | 54% CC, 25% C4, 5% ArXiv, 5% GitHub, 4% Books, 3% Wiki, 3% StackExchange | |
| Model | Initialization: | Llama-2-7B / Llama-3-8B / Qwen-1.5-1.8B / Mistral-7B-v0.3 |
| RoPE: | 16K: 1×10⁶, 64K: 5×10⁶, 128K: 1×10⁷ | |
| Attention: | Full attention/ Intra-doc attention / Intra-doc attention with Reset | |
| AnchorAttention / AnchorAttention with Tag | ||
| Optim. | AdamW (weight decay = 0.1, β₁=0.9, β₂=0.95) | |
| LR: | 2e-5 Steps: 2000 steps | |
| Batch size: | 8 (0.5M token for 64K, 1M tokens for 128K) |
🔼 This table details the configurations used for training the long-context continuous models. It includes information on the datasets used (UpSampledMix, SlimPajama-128K, and SlimPajama-64K), specifying their composition from different sources (Common Crawl, C4, GitHub, ArXiv, Books, Wikipedia, and StackExchange). The table also lists the model initializations, model architectures (LLaMA-2-7B, LLaMA-3-8B, Qwen-1.5-1.8B, and Mistral-7B-v0.3), types of attention mechanisms employed (Full Attention, Intra-doc Attention, Intra-doc Attention with Reset, Anchor Attention, and AnchorAttention with Tag), the optimizer (AdamW) used, learning rate, batch size, and number of steps taken in the training process.
read the caption
Table 1: The training Configuration.
In-depth insights#
RoPE’s Precision Limits#
The heading “RoPE’s Precision Limits” aptly captures a critical finding: the inherent limitations of the Rotary Position Embedding (RoPE) mechanism when implemented with reduced precision, specifically BFloat16. The core issue stems from the accumulation of numerical errors during long-context training. BFloat16’s limited precision causes RoPE’s relative positional encoding, a key advantage for handling long sequences, to deviate from its intended behavior. This deviation is not uniform; the first token in the sequence is particularly affected, exacerbating the problem as context length grows. This highlights a crucial trade-off: while lower-precision formats like BFloat16 offer memory and computational efficiency, they compromise RoPE’s accuracy, especially in demanding long-context scenarios. Addressing this limitation is paramount for the advancement of large language models capable of processing exceptionally long sequences.
Anchor Attention Design#
Anchor Attention, designed to address numerical instability in RoPE with BFloat16, cleverly uses a shared anchor token visible to all documents within the context window. This innovative approach significantly reduces computational cost by limiting unnecessary attention computations, while maintaining semantic coherence. By treating the first token as a fixed anchor with a consistent position ID, it resolves the accumulating numerical issues arising from BFloat16’s limited precision, particularly impacting the first token in long sequences. The design is plug-and-play, easily integrating into existing attention mechanisms. Its effectiveness is demonstrated by improved long-context performance and reduced training time compared to standard full attention, showcasing a substantial improvement in long-context tasks while preserving performance on general tasks. The simplicity and efficiency of Anchor Attention makes it a promising strategy for efficiently training large language models in long-context scenarios.
Long-Context Benchmarks#
Evaluating the capabilities of large language models (LLMs) to handle long contexts requires specialized benchmarks. These benchmarks must go beyond simple perplexity scores, which are insufficient for capturing the nuances of long-range dependencies and contextual understanding. Effective long-context benchmarks need to incorporate tasks that explicitly test the model’s ability to integrate information from extended sequences, such as multi-document question answering or tasks requiring reasoning across extensive stretches of text. The choice of benchmark should also consider the types of tasks that leverage long-context understanding, such as summarizing extensive documents or making predictions based on long temporal spans. A robust benchmark will use varied datasets representing diverse text types and lengths to ensure the evaluation is thorough and generalizable, and will evaluate metrics beyond simple accuracy, also focusing on factors like efficiency and latency. Furthermore, a good benchmark should allow for scalability, allowing for easy adaptation to different models and context lengths. Such a comprehensive evaluation would help to accurately measure the performance of LLMs and guide future research in enhancing long-context understanding.
BFloat16’s Impact#
The research paper investigates the effects of using BFloat16 precision in training large language models (LLMs) with Rotary Position Embedding (RoPE). BFloat16’s reduced precision significantly impacts RoPE’s ability to maintain its relative positional encoding properties, especially as context window sizes increase. This breakdown is primarily attributed to numerical errors accumulating during computation, with the first token’s contribution being particularly significant. The impact is not uniform across tokens; the initial tokens show disproportionately large deviations from expected behavior. This suggests a potential sensitivity of RoPE to lower precision representations, particularly when dealing with extensive sequences. This finding is critical because RoPE is a cornerstone of many LLMs designed for long context processing. Addressing this limitation is crucial for scaling LLMs to longer contexts while retaining efficiency and avoiding performance degradation. The authors propose AnchorAttention, a novel attention method aiming to mitigate these issues by treating the first token as an anchor, which preserves the essential properties of RoPE under BFloat16.
Future Research#
Future research directions stemming from this work could profitably explore the precise role of the first token in attention mechanisms, particularly concerning its influence on positional encoding and potential connections to phenomena like attention sinks. A deeper investigation into the interaction between the first token’s absolute position and relative positional encoding offered by RoPE is needed, potentially through rigorous experimentation and theoretical modeling. Furthermore, a more comprehensive exploration of data utilization strategies like domain tagging and interleaved chunks, specifically considering their interactions with AnchorAttention, would be insightful. This could involve refining these techniques to maximize their effectiveness within the AnchorAttention framework or developing complementary approaches. Finally, expanding the investigation to include a broader range of model architectures and datasets would help to establish the generalizability and robustness of AnchorAttention in various scenarios, providing additional insights and possibly unveiling new limitations or opportunities for improved long-context performance.
More visual insights#
More on figures

🔼 Figure 2 illustrates three different attention mechanisms used in long-context training. The left panel shows standard intra-document attention, where each token attends only to tokens within the same document. The middle panel depicts an improved version of intra-document attention where the positional IDs are reset at the beginning of each document to handle the numerical issues caused by BFloat16 and RoPE. The right panel shows AnchorAttention, a novel method proposed in the paper. In AnchorAttention, the first token of each document serves as a shared anchor token (denoted as \mathscr{A}) with a fixed position ID, making it visible to all documents within the context window while avoiding unnecessary attention computations between different documents. This approach maintains semantic coherence and mitigates the numerical instability caused by BFloat16 precision issues.
read the caption
Figure 2: Illustrations of different attention paradigms. Left: Standard intra-document attention. Middle: Our improved version, intra-document attention with position ID reset per document. Right: AnchorAttention incorporating a shared anchor token, 𝒜𝒜\mathscr{A}script_A.

🔼 Figure 3 presents the results of an experiment comparing two methods of handling positional IDs in long-context training with BFloat16 precision. The first method assigns continuous IDs from the beginning of the sequence, while the second resets the ID at the start of each document. The figure shows that resetting positional IDs consistently improves performance, particularly on the RULER benchmark, as the context length increases. This contradicts the theoretical expectations of RoPE, which suggests that relative positional encoding should be maintained regardless of constant positional shifts. The improved performance with resetting IDs implies there is a deviation in RoPE’s relative positional encoding when BFloat16 is used, especially in long sequences.
read the caption
Figure 3: Resetting position IDs improves performance, contradicting theoretical predictions of RoPE.

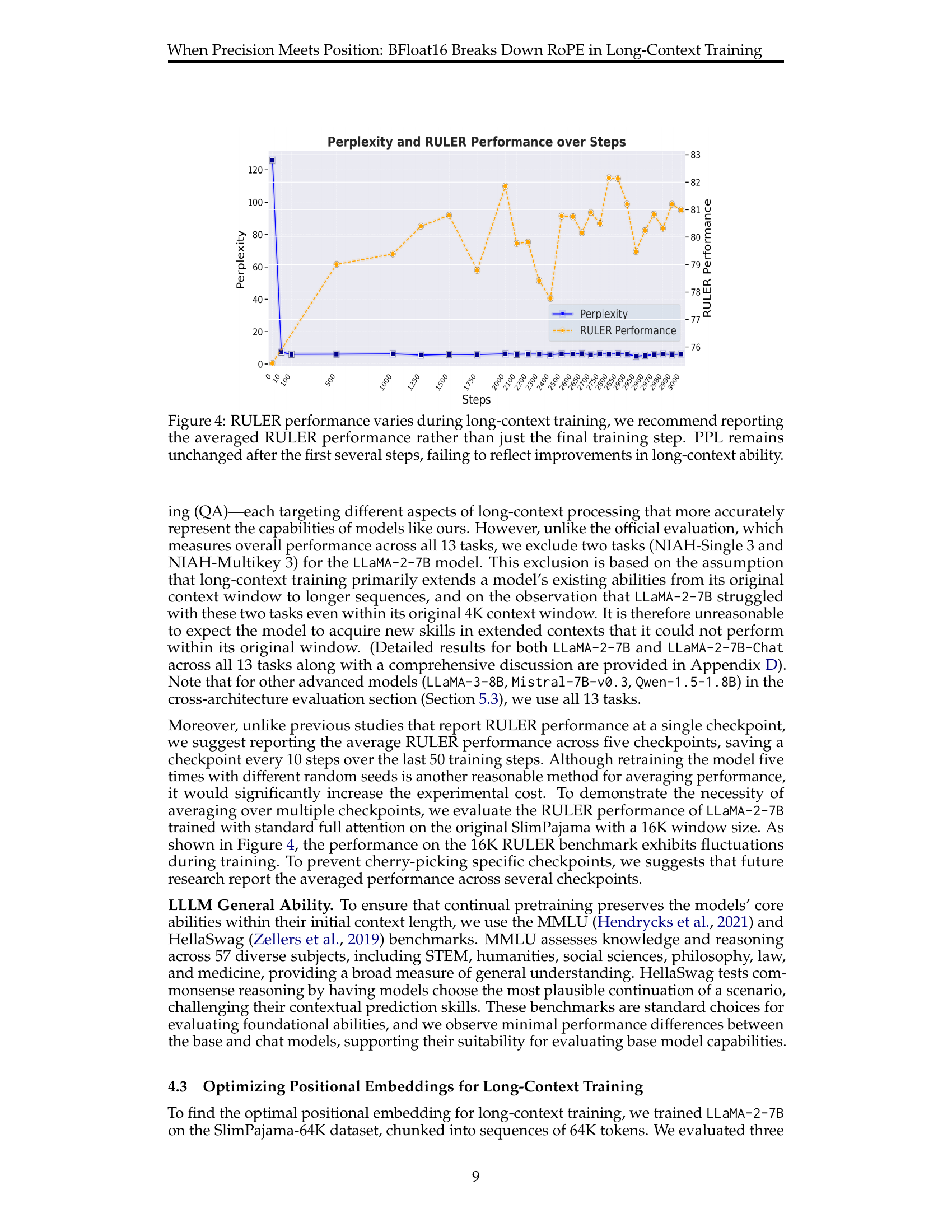
🔼 Figure 4 illustrates the fluctuations in RULER (long-context understanding benchmark) performance and perplexity (PPL) scores throughout the long-context training process. While perplexity shows little change after the initial training steps, the RULER scores demonstrate variability. This highlights that using only the final training step’s RULER score can be misleading, and that an average of RULER scores over multiple checkpoints is recommended for a more accurate representation of model progress in long-context understanding.
read the caption
Figure 4: RULER performance varies during long-context training, we recommend reporting the averaged RULER performance rather than just the final training step. PPL remains unchanged after the first several steps, failing to reflect improvements in long-context ability.

🔼 Figure 5 illustrates three different attention mechanisms applied to long document sequences. The left panel shows AnchorAttention with domain tagging, where each document is prepended with a tag indicating its source domain (e.g., ‘Wikipedia’ or ‘StackExchange’). This tag is masked during loss calculation, allowing the model to learn domain-specific information while preventing conflicts. The middle panel depicts intra-document attention with interleaved chunks. Here, documents are divided into smaller chunks, these chunks are shuffled randomly while keeping the order within each document intact, creating a mixed sequence. This technique aims to improve long-context learning by exposing the model to various combinations of information segments. The right panel presents AnchorAttention with interleaved chunks. This combines the strategies from the left and middle panels to address both the issue of document domain bias and the long-context challenge of handling long sequences in a single pass.
read the caption
Figure 5: Illustrations of domain tagging and interleaved chunks. Left: AnchorAttention with domain tagging, where 𝒯1subscript𝒯1\mathscr{T}_{1}script_T start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT denotes the domain of document d1subscriptd1\textbf{{d}}_{1}d start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT. Middle: Intra-document attention with interleaved chunks; documents are split into shuffled, interleaved chunks, preserving the original order within each document. Right: AnchorAttention with interleaved chunks.

🔼 This figure compares the estimated training time needed to process 1 billion tokens at various context lengths using different attention mechanisms: Full Attention and AnchorAttention. The results show that AnchorAttention significantly reduces training time compared to Full Attention. The reduction is more than 50% across all context lengths tested.
read the caption
Figure 6: Estimated training time required to process 1 billion tokens at various context lengths using different attention mechanisms. Our AnchorAttention reduce more than 50%percent5050\%50 % of time needed by Full Attention.

🔼 Figure 7 visualizes the attention score differences observed when using BFloat16 precision for individual samples. It shows how attention computations deviate from the expected results based on the relative positional properties of Rotary Positional Embedding (RoPE). The plots depict the attention difference (calculated using Equation 4) for multiple samples, revealing the consistency of this deviation. The left plot varies positional shift Δ₁ while keeping Δ₂ fixed at 16, demonstrating the impact of shift on attention scores. The right plot reverses this, keeping Δ₁ fixed at 0 and varying Δ₂, showing the impact of the second shift parameter. The figure highlights the discrepancy between the attention computations under BFloat16 and the expected results if the computations were done under higher precision. This visual evidence helps support the paper’s claim that the limited precision of BFloat16 leads to deviations in RoPE’s relative positional encoding, especially in long sequences.
read the caption
Figure 7: Visualization of attention score differences under BFloat16 for individual samples.

🔼 This figure displays the distribution of training data sequence lengths for both the original and upsampled versions of the SlimPajama dataset. It shows four histograms: one each for the original 64K and 128K token sequences, and one each for the 64K and 128K upsampled sequences. The histograms visualize the frequency with which different lengths of sequences appear in the dataset. By comparing the original and upsampled distributions, one can observe the effects of upsampling on the distribution of sequence lengths. Specifically, it highlights the increased proportion of longer sequences in the upsampled data compared to the original dataset. This is because the upsampling method aims to increase the number of longer sequences to better train the model to handle long contexts.
read the caption
Figure 8: Training Data Sequence Length Distribution
More on tables
| Attention Mechanism | 128K | 64K | 32K | 16K | 8K | 4K |
|---|---|---|---|---|---|---|
| SlimPajama-64K | ||||||
| Full Attention | \setminus | 66.40 | 71.78 | 77.63 | 83.86 | 89.84 |
| Intra-Doc Attention | \setminus | 69.97 | 74.70 | 79.15 | 83.50 | 89.62 |
| + Reset | \setminus | 70.03 | 74.18 | 80.27 | 84.51 | 89.52 |
| + Interleaved Chunks | \setminus | 60.59 | 66.52 | 71.70 | 79.70 | 84.71 |
| AnchorAttention | \setminus | 73.25 | 75.97 | 82.91 | 85.48 | 90.69 |
| + Tag | \setminus | 73.88 | 74.21 | 82.46 | 85.13 | 89.93 |
| + Interleaved Chunks | \setminus | 66.77 | 69.73 | 77.81 | 85.35 | 89.31 |
| SlimPajama-128K | ||||||
| Full Attention | 62.75 | 70.56 | 71.38 | 81.65 | 83.61 | 88.85 |
| Intra-Doc Attention | 64.31 | 70.87 | 72.07 | 82.60 | 84.11 | 88.98 |
| + Reset | 65.75 | 73.34 | 73.30 | 82.82 | 84.43 | 90.01 |
| + Interleaved Chunks | 53.74 | 61.08 | 65.51 | 75.25 | 80.59 | 82.71 |
| AnchorAttention | 66.15 | 77.69 | 74.28 | 83.67 | 86.41 | 90.60 |
| + Tag | 65.46 | 74.67 | 75.77 | 83.07 | 84.07 | 89.09 |
| UpSampledMix-128K | ||||||
| Full Attention | 63.70 | 71.45 | 72.69 | 82.57 | 84.55 | 90.08 |
| Intra-Doc Attention | 63.96 | 74.52 | 76.53 | 82.46 | 86.61 | 90.35 |
| + Reset | 64.10 | 74.55 | 77.73 | 82.82 | 87.16 | 89.98 |
| AnchorAttention | 65.24 | 76.11 | 79.51 | 86.54 | 87.43 | 90.44 |
| + Tag | 66.85 | 73.52 | 77.18 | 81.62 | 84.90 | 89.01 |
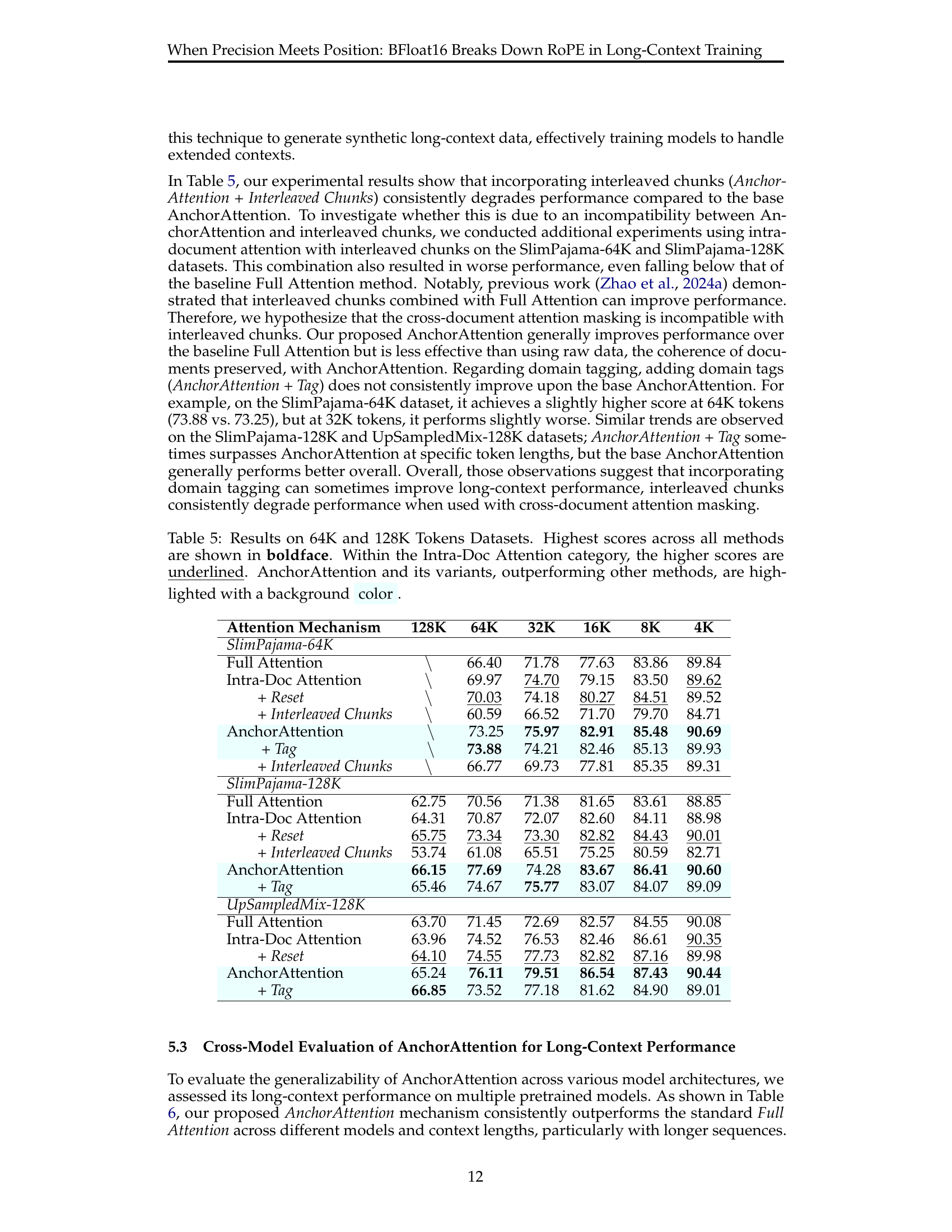
🔼 This table presents the results of experiments evaluating different attention mechanisms on datasets with 64K and 128K tokens. The goal was to compare the performance of full attention, intra-document attention (with and without position ID reset), and the proposed AnchorAttention (with and without domain tagging and interleaved chunks). The metrics used to assess performance aren’t explicitly stated in the caption but are presumably related to long-context understanding, as indicated by the dataset sizes. The table highlights the best-performing method in each scenario. Bold text indicates the overall best performance for each row, while underlined text denotes the best performance within the ‘Intra-Document Attention’ category. The AnchorAttention methods and variants, due to their superior performance, are highlighted with a shaded background.
read the caption
Table 5: Results on 64K and 128K Tokens Datasets. Highest scores across all methods are shown in boldface. Within the Intra-Doc Attention category, the higher scores are underlined. AnchorAttention and its variants, outperforming other methods, are highlighted with a background color.
| Attention Mechanism | 128K | 64K | 32K | 16K | 8K | 4K |
|---|---|---|---|---|---|---|
| LLaMA-3-8B | ||||||
| Full Attention | 34.02 | 61.80 | 72.09 | 79.99 | 82.43 | 83.68 |
| AnchorAttention | 51.49 | 70.99 | 83.06 | 86.90 | 88.09 | 88.72 |
| + Tag | 49.67 | 70.37 | 84.14 | 87.13 | 88.36 | 88.97 |
| Mistral-7B-v0.3 | ||||||
| Full Attention | 45.64 | 49.05 | 54.49 | 64.06 | 69.99 | 72.80 |
| AnchorAttention | 47.46 | 61.26 | 68.53 | 73.47 | 76.06 | 78.94 |
| + Tag | 49.61 | 56.80 | 64.13 | 69.47 | 74.65 | 77.34 |
| Qwen-1.5-1.8B | ||||||
| Full Attention | 33.56 | 41.77 | 47.01 | 56.15 | 61.33 | 67.26 |
| AnchorAttention | 34.32 | 44.31 | 48.63 | 56.90 | 62.62 | 68.61 |
| + Tag | 35.84 | 43.91 | 50.70 | 57.39 | 61.96 | 67.41 |
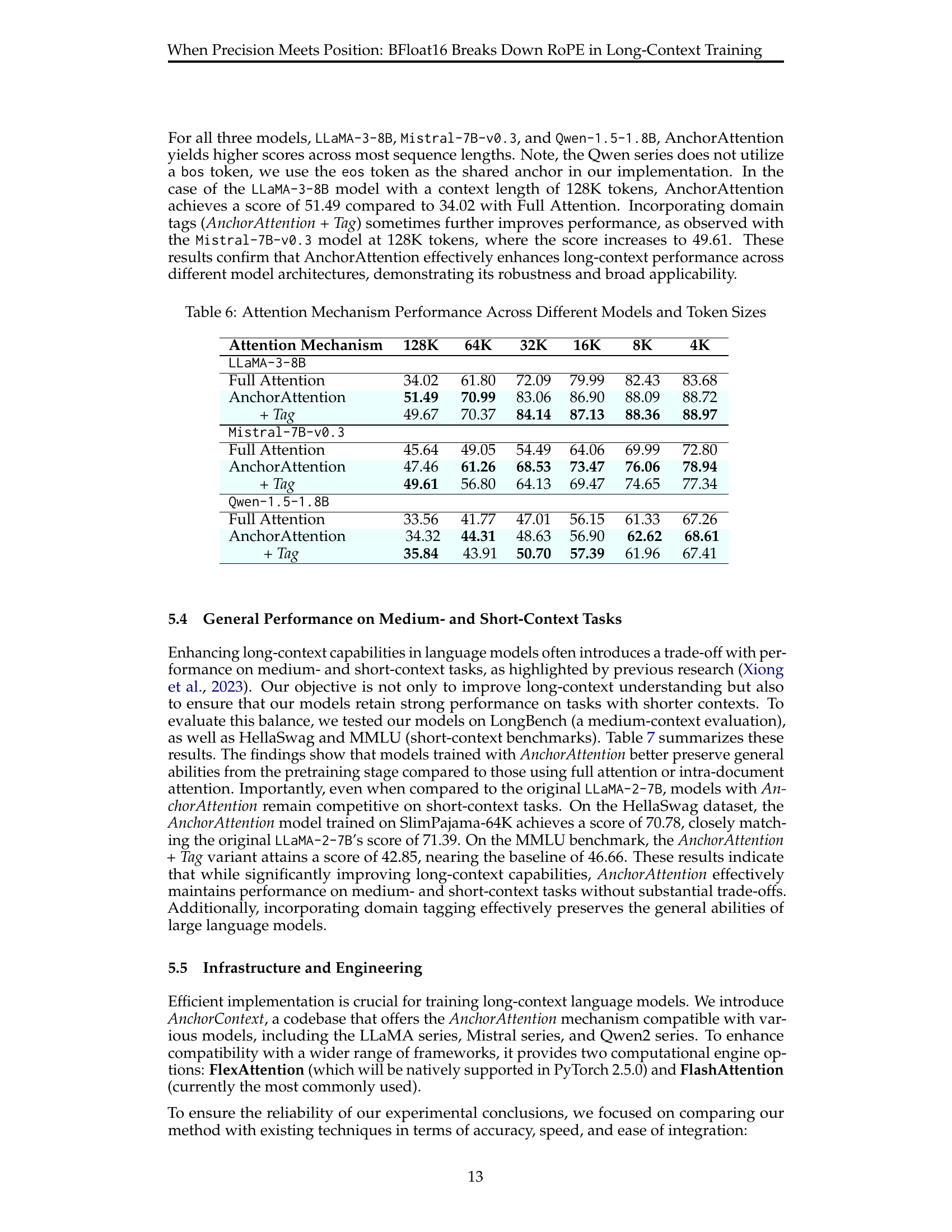
🔼 This table presents the performance of different attention mechanisms (Full Attention, AnchorAttention, and AnchorAttention with domain tags) across various model architectures (LLaMA-3-8B, Mistral-7B-v0.3, and Qwen-1.5-1.8B) and different context lengths (4K, 8K, 16K, 32K, 64K, and 128K tokens). It showcases the impact of AnchorAttention in enhancing long-context performance across diverse models and sequence lengths. The results are reported as scores, likely representing a metric measuring the model’s ability to correctly perform tasks given a long context.
read the caption
Table 6: Attention Mechanism Performance Across Different Models and Token Sizes
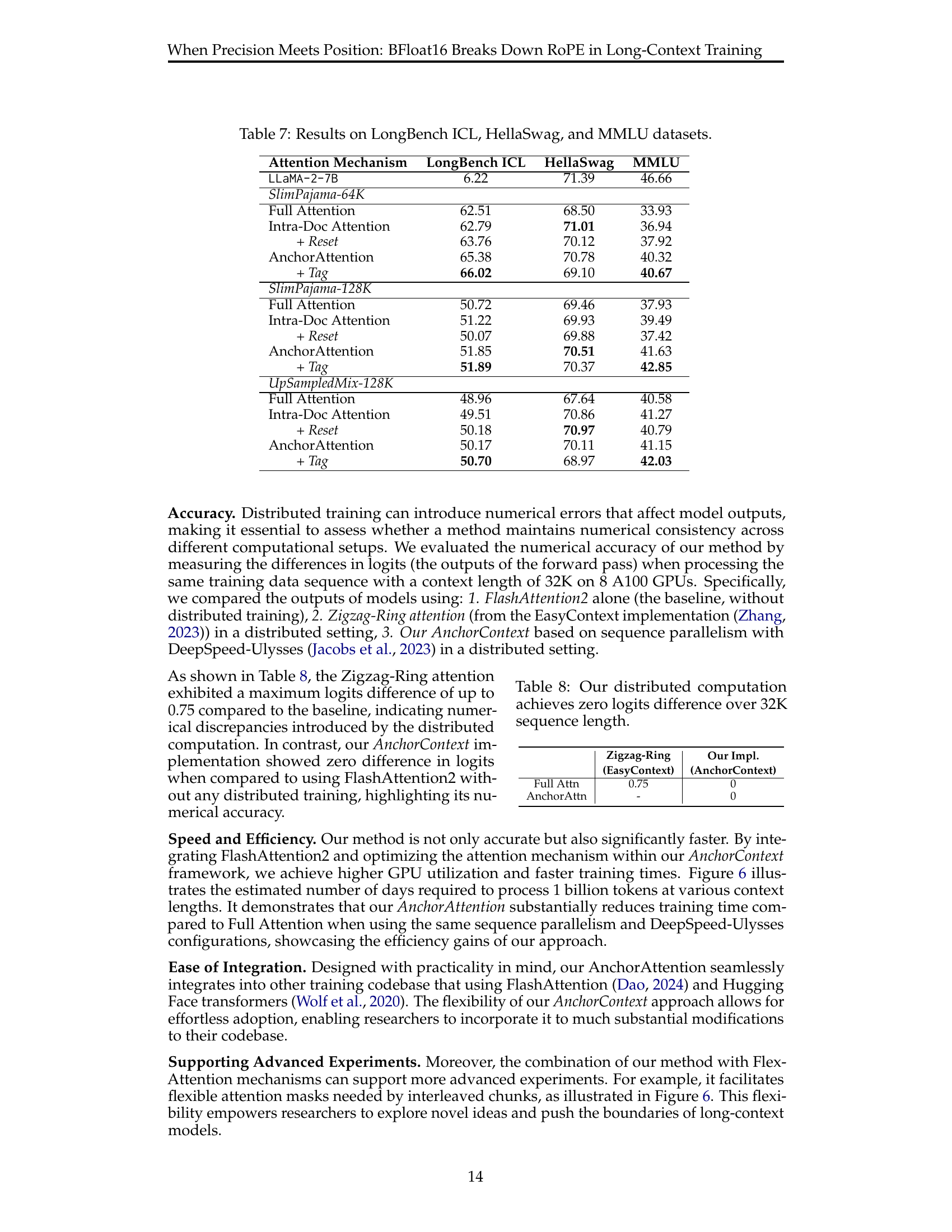
| Attention Mechanism | LongBench ICL | HellaSwag | MMLU |
|---|---|---|---|
| LLaMA-2-7B | 6.22 | 71.39 | 46.66 |
| SlimPajama-64K | |||
| Full Attention | 62.51 | 68.50 | 33.93 |
| Intra-Doc Attention | 62.79 | 71.01 | 36.94 |
| + Reset | 63.76 | 70.12 | 37.92 |
| AnchorAttention | 65.38 | 70.78 | 40.32 |
| + Tag | 66.02 | 69.10 | 40.67 |
| SlimPajama-128K | |||
| Full Attention | 50.72 | 69.46 | 37.93 |
| Intra-Doc Attention | 51.22 | 69.93 | 39.49 |
| + Reset | 50.07 | 69.88 | 37.42 |
| AnchorAttention | 51.85 | 70.51 | 41.63 |
| + Tag | 51.89 | 70.37 | 42.85 |
| UpSampledMix-128K | |||
| Full Attention | 48.96 | 67.64 | 40.58 |
| Intra-Doc Attention | 49.51 | 70.86 | 41.27 |
| + Reset | 50.18 | 70.97 | 40.79 |
| AnchorAttention | 50.17 | 70.11 | 41.15 |
| + Tag | 50.70 | 68.97 | 42.03 |
🔼 This table presents the performance of different attention mechanisms (Full Attention, Intra-Document Attention with and without Position ID reset, and Anchor Attention with and without domain tagging) on three benchmark datasets: LongBench ICL (In-context learning), HellaSwag (commonsense reasoning), and MMLU (multi-task language understanding). It shows the performance of models trained on different datasets (SlimPajama-64K, SlimPajama-128K, and UpSampledMix-128K) to assess the effectiveness of the proposed AnchorAttention method in various contexts.
read the caption
Table 7: Results on LongBench ICL, HellaSwag, and MMLU datasets.
| Zigzag-Ring (EasyContext) | Our Impl. (AnchorContext) | |
|---|---|---|
| Full Attn | 0.75 | 0 |
| AnchorAttn | - | 0 |
🔼 This table presents the results of a numerical accuracy experiment comparing three different methods for distributed training of long-context models. The methods are: 1. FlashAttention2 (baseline, no distributed training), 2. Zigzag-Ring attention (from EasyContext implementation), and 3. AnchorContext (the authors’ proposed method using sequence parallelism with DeepSpeed-Ulysses). The experiment measured the difference in attention logits (model outputs) when processing the same 32K-length sequence on 8 A100 GPUs for each method. The table shows that the authors’ method (AnchorContext) achieved zero difference in logits, demonstrating superior numerical stability compared to the other methods.
read the caption
Table 8: Our distributed computation achieves zero logits difference over 32K sequence length.
| Mixture Ratio | C4 | Arxiv | Github | StackExchange | CommonCrawl | Wikipedia | Books | |
|---|---|---|---|---|---|---|---|---|
| 128K (Rotated) | ||||||||
| Up-sampled Data Mixture | ||||||||
| Mixture Ratio | 52.34% | 1.01% | 3.68% | 4.56% | 33.40% | 4.79% | 0.21% | |
| Token Ratio | 19.53% | 5.86% | 6.61% | 1.64% | 58.14% | 3.51% | 4.69% | |
| Original SlimPajama | ||||||||
| 128K (Rotated) | Mixture Ratio | 55.32% | 0.30% | 3.65% | 5.06% | 31.01% | 4.59% | 0.06% |
| Token Ratio | 26.50% | 4.64% | 5.05% | 3.18% | 53.42% | 3.34% | 3.88% | |
| 64K (Rotated) | Mixture Ratio | 55.05% | 0.40% | 3.66% | 4.97% | 31.23% | 4.58% | 0.10% |
| Token Ratio | 25.43% | 5.22% | 5.05% | 2.95% | 54.24% | 3.24% | 3.86% |
🔼 This table presents a detailed breakdown of the data distribution across various domains within the training datasets. It compares the original SlimPajama dataset with the upsampled versions used in the experiments, highlighting the mixture ratio (percentage of total sequences from each domain) and the token ratio (percentage of total tokens from each domain). The domains covered are: C4, ArXiv, GitHub, StackExchange, Common Crawl, Wikipedia, and Books. By examining these ratios, we can understand how the dataset composition varies between the original and upsampled versions, allowing for a better understanding of the impact of data composition on model performance.
read the caption
Table 9: Domain and Token Distributions
| Model | NIAH Single 1 | NIAH Single 2 | NIAH Single 3 | NIAH Multikey 1 | NIAH Multikey 2 | NIAH Multikey 3 | NIAH Multivalue | NIAH Multiquery | VT | CWE | FWE | QA 1 | QA 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama2 7B | 100.0 | 100.0 | 99.8 | 97.2 | 87.8 | 44.0 | 99.1 | 99.35 | 59.0 | 24.46 | 91.73 | 61.2 | 43.0 | |
| + Chat | 95.2 | 100.0 | 99.8 | 93.2 | 90.0 | 70.2 | 95.8 | 98.7 | 88.4 | 34.26 | 85.93 | 64.8 | 39.4 | |
| + Yarn 64K | 73.0 | 24.4 | 8.0 | 18.0 | 5.8 | 0.8 | 5.9 | 6.35 | 54.2 | 18.16 | 57.8 | 38.6 | 27.6 | |
| + Chat + Yarn 64K | 67.4 | 48.8 | 32.4 | 30.2 | 16.4 | 4.8 | 48.0 | 34.75 | 54.16 | 43.48 | 82.07 | 41.2 | 25.0 |
🔼 This table presents the performance of different large language models (LLMs) on various tasks within a 4,000-token context window. The models include the base LLaMA-2-7B model and variations incorporating chat capabilities and different positional encoding methods (Yarn). Performance is evaluated across several task types, including those focusing on common word extraction (CWE), filtering words (FWE), question answering (QA), and the identification of needles within a haystack (NIAH). The results demonstrate how different model architectures and enhancements affect performance across various tasks with a restricted context length.
read the caption
Table 10: Results of different models across various tasks on 4,00040004,0004 , 000 context length.
| 4,000 | 4,096 | |
|---|---|---|
| LLaMA-2-7B | 24.46 | 76.8 |
🔼 This table presents the performance of the LLaMA-2-7B language model on the Common Word Extraction (CWE) task within the RULER benchmark, comparing its accuracy at two different context lengths: 4,000 and 4,096 tokens. The results illustrate how a slight change in context length significantly impacts the model’s performance on this specific task, demonstrating the sensitivity of CWE to variations in the context window size.
read the caption
Table 11: Performance of LLaMA-2-7B on Common Word Extraction (CWE) with different context lengths.
| Code Completion | ICL | Multi-Doc QA | Single-Doc QA | Summarization | Synthetic | |
|---|---|---|---|---|---|---|
| SlimPajama-64K | ||||||
| Full Attention | 60.52 | 62.51 | 9.68 | 17.34 | 16.09 | 2.87 |
| Cross-Doc Attention | 62.95 | 62.79 | 9.51 | 16.82 | 16.73 | 2.94 |
| - reset | 62.76 | 63.76 | 9.30 | 16.40 | 14.61 | 3.74 |
| AnchorAttention | 62.04 | 65.38 | 9.72 | 18.60 | 17.56 | 4.24 |
| - tag | 63.53 | 66.02 | 9.51 | 18.28 | 15.30 | 5.24 |
| SlimPajama-128K | ||||||
| Full Attention | 54.17 | 50.72 | 6.36 | 16.43 | 13.30 | 2.04 |
| Cross-Doc Attention | 54.59 | 51.22 | 6.42 | 15.59 | 13.92 | 3.63 |
| - reset | 52.51 | 50.07 | 6.30 | 16.64 | 14.45 | 4.18 |
| AnchorAttention | 54.14 | 51.85 | 6.32 | 17.74 | 12.67 | 3.89 |
| - tag | 55.81 | 51.89 | 5.93 | 17.67 | 12.43 | 3.41 |
| UpSampledMix-128K | ||||||
| Full Attention | 53.13 | 48.96 | 6.12 | 14.66 | 12.77 | 4.13 |
| Cross-Doc Attention | 54.16 | 49.51 | 5.72 | 14.62 | 14.38 | 2.57 |
| - reset | 54.29 | 50.18 | 5.57 | 14.30 | 15.23 | 2.55 |
| AnchorAttention | 53.90 | 50.17 | 6.30 | 18.29 | 13.78 | 6.13 |
| - tag | 55.13 | 49.70 | 5.65 | 16.90 | 15.53 | 4.20 |
🔼 This table presents a comprehensive comparison of performance metrics across various attention mechanisms and datasets used in the paper. It shows the results on the Longbench benchmark, broken down by specific sub-tasks (Code Completion ICL, Multi-Doc QA, Single-Doc QA, Summarization, and Synthetic). The datasets compared are SlimPajama-64K, SlimPajama-128K, and UpSampledMix-128K. For each dataset and task, the table displays performance scores for different attention methods: Full Attention, Cross-Document Attention, Cross-Document Attention with Position ID Reset, Anchor Attention, and Anchor Attention with Domain Tags. This allows for a detailed analysis of how different attention strategies impact performance across various tasks and dataset configurations.
read the caption
Table 12: Performance Metrics across Different Attention Mechanisms and Datasets.
Full paper#