↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for evaluating video generation models often fall short of accurately reflecting human perception. Existing metrics are inconsistent with human judgment and don’t account for the unique challenges of generative models, leading to an incomplete understanding of model performance. This necessitates a more comprehensive and human-aligned evaluation framework.
The researchers introduce VBench++, a new benchmark suite designed to address these issues. VBench++ evaluates video generation quality across 16 carefully chosen dimensions, using a hierarchical and disentangled approach. It includes a human preference annotation dataset to validate its alignment with human perception, offers valuable insights into model strengths and weaknesses, and supports various video generation tasks. The full open-sourcing of VBench++, including prompts, evaluation methods, generated videos, and human preference annotations, further promotes collaboration and progress in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation because it introduces VBench++, a comprehensive and versatile benchmark suite that addresses the limitations of existing evaluation metrics. It provides valuable insights into model performance, enabling researchers to better understand model strengths and weaknesses, improve model training, and accelerate progress in the field. The open-sourcing of VBench++ further enhances its impact by facilitating wider adoption and collaboration.
Visual Insights#

🔼 VBench++ is a comprehensive and versatile benchmark suite for evaluating video generation models. It decomposes video quality into multiple well-defined dimensions, using a hierarchical structure. For each dimension and content category, a prompt suite provides test cases, generating videos from various models. Each dimension has a tailored evaluation method, and human preference annotation validates the results. VBench++ supports text-to-video and image-to-video tasks, and includes an adaptive image suite for fair evaluations. Besides technical quality, it assesses model trustworthiness, providing a holistic performance view. The benchmark is continuously updated with new models to reflect the evolving field of video generation.
read the caption
Figure 1: Overview of VBench++. We propose VBench++, a comprehensive and versatile benchmark suite for video generative models. We design a comprehensive and hierarchical Evaluation Dimension Suite to decompose “video generation quality' into multiple well-defined dimensions to facilitate fine-grained and objective evaluation. For each dimension and each content category, we carefully design a Prompt Suite as test cases, and sample Generated Videos from a set of video generation models. For each evaluation dimension, we specifically design an Evaluation Method Suite, which uses a carefully crafted method or designated pipeline for automatic objective evaluation. We also conduct Human Preference Annotation for the generated videos for each dimension and show that VBench++ evaluation results are well aligned with human perceptions. VBench++ can provide valuable insights from multiple perspectives. VBench++ supports a wide range of video generation tasks, including text-to-video and image-to-video, with an adaptive Image Suite for fair evaluation across different settings. It evaluates not only technical quality but also the trustworthiness of generative models, offering a comprehensive view of model performance. We continually incorporate more video generative models into VBench++ to inform the community about the evolving landscape of video generation.
| Loose Definision of Image Resolution | Image Area (W×H) | Percentage | Image Side Length (W and H) | Percentage |
|---|---|---|---|---|
| <1K | <1920×1080 | 0.0% | W<1920 or H<1080 | 0.3% |
| [1K, 2K) | [1920×1080, 2560×1440) | 3.4% | (1920≤W and 1080≤H) and (W<2560 or H<1440) | 5.4% |
| [2K, 4K) | [2560×1440, 3840x2160) | 6.8% | (2560≤W and 1440≤H) and (W<3840 or H<2160) | 23.1% |
| [4K, 8K) | [3840×2160, 7680×4320) | 85.6% | (3840≤W and 2160≤H) and (W<7680 or H<4320) | 68.7% |
| ≥8K | ≥7680×4320 | 4.2% | 7680≤W and 4320≤H | 2.5% |
🔼 Table 1 presents the resolution distribution of the Image Suite used in the VBench++ benchmark. The Image Suite is primarily composed of high-resolution images (4K or higher). The table provides a detailed breakdown of the image resolutions based on two different metrics: total pixel count (image area) and the length of the image’s sides (width and height). This allows for a comprehensive understanding of the resolution characteristics of the image dataset used in the benchmark.
read the caption
TABLE I: Image Suite Resolution Distribution. The Image Suite primarily consists of images of 4K resolution or higher. We present statistics based on two types of resolution classifications: one based on image area (i.e., the total number of pixels), and the other based on the length of both sides.
In-depth insights#
VBench++: Overview#
VBench++, as a proposed comprehensive and versatile benchmark suite for video generative models, offers a multi-faceted evaluation approach. Its hierarchical structure breaks down video quality into core dimensions like Video Quality and Video-Condition Consistency, each further subdivided for granular analysis. This detailed approach allows for a more nuanced understanding of model strengths and weaknesses beyond traditional metrics. Human alignment is a key feature, with human preference annotations used to validate the benchmark’s alignment with human perception, crucial for ensuring evaluation relevance. The incorporation of both text-to-video and image-to-video generation tasks, along with an adaptive Image Suite, broadens the scope and ensures fairness across different generation paradigms. Finally, the inclusion of trustworthiness dimensions, assessing cultural fairness and bias, adds a crucial ethical layer to the evaluation, moving beyond pure technical performance.
Multi-dimensional Eval#
A multi-dimensional evaluation approach for video generation models offers significant advantages over traditional single-metric evaluations. Instead of relying on a single, potentially misleading score, it allows for a more nuanced understanding of model strengths and weaknesses across various aspects of video quality. By decomposing video quality into several distinct dimensions (e.g., temporal consistency, visual fidelity, semantic accuracy, etc.), researchers gain granular insights into how well different models perform on each aspect. This facilitates a more objective comparison and helps identify specific areas needing improvement. Further, human alignment in the design and validation of these dimensions ensures the evaluation correlates well with human perception, increasing reliability and relevance. A multi-dimensional approach also provides valuable guidance for future model development by highlighting trade-offs between different aspects of video quality and revealing areas where current models fall short. It facilitates a more complete and insightful understanding, surpassing limitations of single-metric evaluations.
Human Perception#
In evaluating video generative models, aligning with human perception is paramount. Subjective human judgment of video quality differs significantly from objective metrics like FID and FVD. Therefore, a key challenge is creating evaluation dimensions that truly capture how humans perceive and assess video generation quality across various attributes. This requires careful consideration of how people rate individual aspects such as motion smoothness, color accuracy, subject consistency, and overall aesthetic appeal. A strong evaluation framework must incorporate human preference annotations directly to verify and calibrate automated metrics. This human-centric approach helps identify discrepancies between automatic scores and what is visually pleasing or realistic to people, ultimately enabling the development of more effective video generation models that meet actual user expectations. Disentangling different dimensions of video quality is crucial for nuanced understanding and improvements. A comprehensive methodology with human-in-the-loop feedback guarantees alignment with human sensibilities and ensures that model development and evaluation stay rooted in human visual perception.
I2V & Trustworthiness#
The section ‘I2V & Trustworthiness’ would explore the intersection of image-to-video (I2V) generation and the crucial aspect of model trustworthiness. It would likely delve into how biases present in the input images or the I2V model itself might propagate into the generated videos, potentially creating unfair or harmful representations. Assessing fairness across different cultural backgrounds and demographics would be essential, investigating if the model generates videos with biases reflecting societal prejudices. The evaluation would likely include metrics for detecting bias in skin tone, gender, and cultural representation within the generated videos. Furthermore, the discussion would likely address the safety implications of I2V models. The generation of unsafe or inappropriate content (e.g., violence, hate speech) is a key concern. This section would likely examine how the model’s training data and architecture affect the generation of such content. Proposed solutions could include methods for bias mitigation, safety filters, and techniques for improving the overall fairness and responsibility of I2V model outputs.
Future Directions#
Future research in video generation should prioritize addressing the trade-offs between temporal consistency and dynamic content generation. Current models often excel in one area at the expense of the other, highlighting the need for techniques that seamlessly integrate both. Furthermore, research should explore ways to improve compositionality and spatial reasoning within generated videos to better handle complex scenes involving multiple objects and their interactions. Improving model trustworthiness is crucial, requiring strategies to mitigate biases and ensure content safety across diverse cultures and demographics. Finally, developing more sophisticated evaluation metrics that align closely with human perception will be essential for tracking progress and guiding future development. Addressing these areas will ultimately lead to more realistic, engaging, and ethically responsible video generation models.
More visual insights#
More on figures

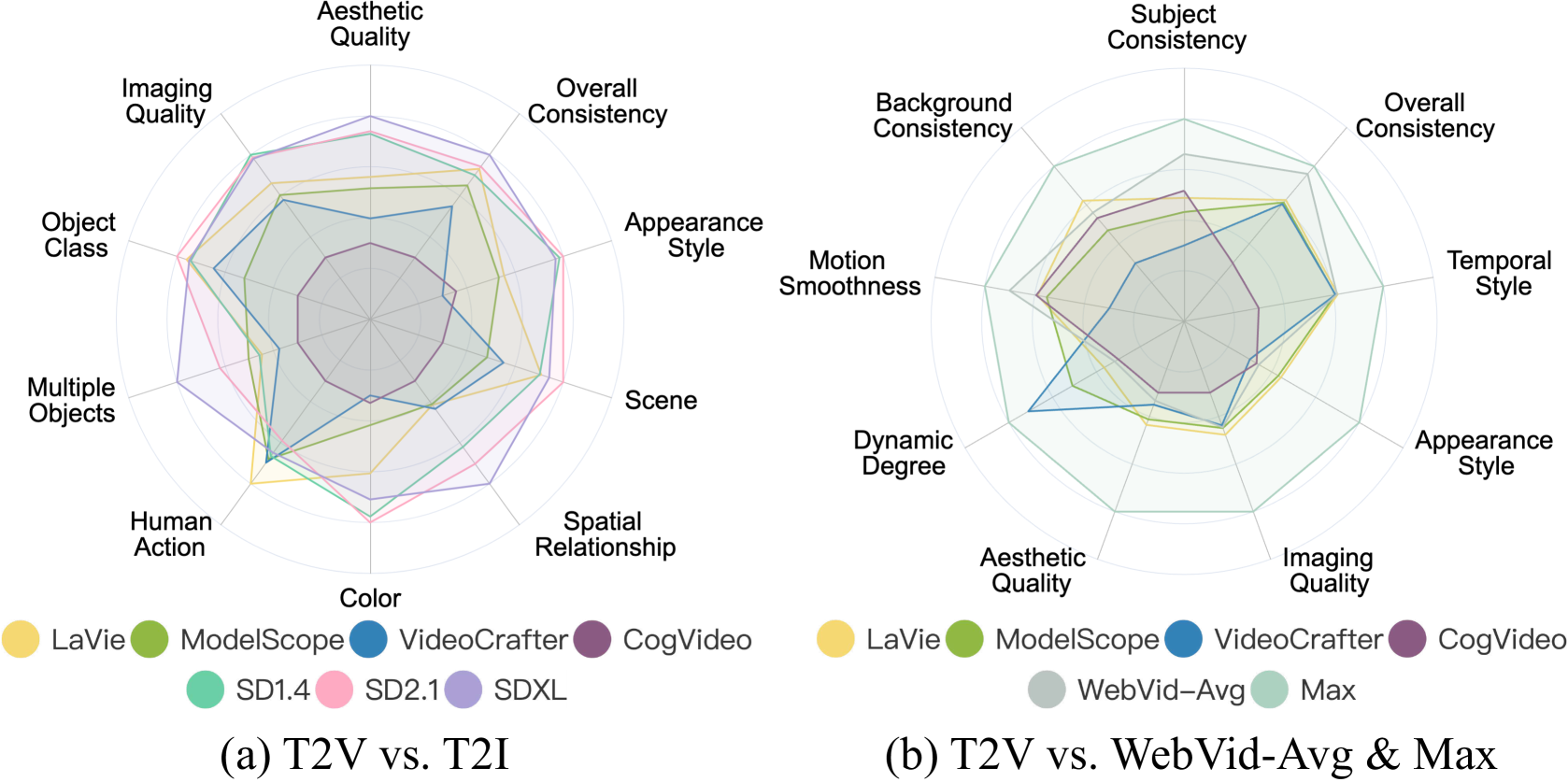
🔼 This figure displays a radar chart visualizing the performance of four different text-to-video generative models across sixteen distinct evaluation dimensions defined in the VBench benchmark. Each dimension represents a specific aspect of video generation quality. The radar chart allows for a visual comparison of the models’ strengths and weaknesses across these various dimensions. For precise numerical data, refer to Table II within the paper.
read the caption
(a) Text-to-Video Generative Models. We visualize the evaluation results of four text-to-video generation models in 16 VBench dimensions. For comprehensive numerical results, please refer to Table II.

🔼 This figure displays a comparison of six different image-to-video generation models. Each model’s performance is visually represented, likely using a radar chart or similar visualization, across multiple dimensions of video quality. The specific dimensions assessed are not shown in the caption, but are detailed elsewhere in the paper. For precise numerical data on the performance of each model, readers are referred to Table III.
read the caption
(b) Image-to-Video Generative Models. We visualize the evaluation results of six image-to-video generation models. See Table III for comprehensive numerical results.

🔼 This figure (c) presents a radar chart visualizing the trustworthiness of several video generative models. Each model’s performance is shown across multiple trustworthiness dimensions, including cultural fairness, gender bias, skin tone bias, and safety. The radar chart provides a visual comparison of the models’ strengths and weaknesses in these aspects, allowing for quick identification of models that are particularly strong or weak in certain dimensions. The caption encourages readers to consult Table IV for a detailed numerical breakdown of the results displayed visually in the chart.
read the caption
(c) Trustworthiness of Video Generative Models. We visualize the trustworthiness of video generative models, along with other dimensions. For comprehensive numerical results, please refer to Table IV.

🔼 This figure presents a visual comparison of various text-to-video and image-to-video generative models, evaluated using the VBench++ benchmark suite. The results are normalized across dimensions for easy comparison. Each subfigure focuses on a specific aspect of model performance. Subfigure (a) displays results for text-to-video models, subfigure (b) shows results for image-to-video models, and subfigure (c) illustrates model trustworthiness across several dimensions.
read the caption
Figure 2: VBench++ Evaluation Results. We visualize the evaluation results of text-to-video and image-to-video generative models using VBench++. We normalize the results per dimension for clearer comparisons.

🔼 Figure 3 presents a statistical overview of the prompt suites used in the VBench++ benchmark. The left panel displays a word cloud illustrating the frequency distribution of words across all prompts. This provides a visual representation of the types of scenes and objects frequently featured in the test cases. The right panel presents a bar chart showing the number of prompts used for each of the 16 evaluation dimensions and also broken down by eight different content categories (Animal, Architecture, Food, Human, Lifestyle, Plant, Scenery, Vehicles). This visualization helps to understand the scope and balance of the prompt suites in terms of both the granularity of evaluation and diversity of content.
read the caption
Figure 3: Prompt Suite Statistics. The two graphs provide an overview of our prompt suites. Left: the word cloud to visualize word distribution of our prompt suites. Right: the number of prompts across different evaluation dimensions and different content categories.

🔼 This figure shows the user interface for human annotation in the VBench++ system. The top part displays the prompt used to generate videos and the question annotators need to answer to provide their preference. The right side shows the three options annotators have for providing their preference: ‘A is better’, ‘Same quality’, and ‘B is better’. The bottom left corner displays controls for video playback, allowing annotators to stop and replay the videos as needed to make their judgment.
read the caption
Figure 4: Interface for Human Preference Annotation. Top: prompt and question. Right: choices that annotators can make. Bottom left: control for stop and playback.

🔼 This figure illustrates the image cropping pipeline used for portrait images in the Image Suite. The pipeline ensures that the main content remains centered and unaltered regardless of the final aspect ratio. It starts with an initial crop to a 1:1 aspect ratio, followed by a second crop to a 16:9 aspect ratio. Additional crops with intermediate aspect ratios (7:4 and 8:5) are then generated by interpolating between the 1:1 and 16:9 crops.
read the caption
(a) Cropping Pipeline for Portrait Images.

🔼 This figure illustrates the image cropping pipeline used for landscape-oriented images in the Image Suite of VBench++. The pipeline ensures that the main content remains centered and unaltered after cropping the images to various aspect ratios (1:1, 7:4, 8:5, and 16:9). It starts by first cropping to a 16:9 aspect ratio. Then, another crop to a 1:1 aspect ratio is performed. Finally, additional crops are generated between the 16:9 and 1:1 bounding boxes to achieve the other aspect ratios.
read the caption
(b) Cropping Pipeline for Landscape Images.

🔼 This figure illustrates the adaptive cropping pipeline used to prepare the Image Suite for the image-to-video (I2V) task. The pipeline handles both portrait and landscape images. For portrait images (height greater than width), a 1:1 crop is performed first (red box), followed by a 16:9 crop (yellow box). Intermediate aspect ratios (7:4 and 8:5) are generated by interpolating between these two crops. Landscape images (width greater than height) are processed similarly, but the initial crop is 16:9, followed by a 1:1 crop, with interpolation generating the intermediate ratios. This ensures consistent image content across various aspect ratios, crucial for fair I2V model evaluation.
read the caption
Figure 5: Image Suite Pipeline for Adaptive Aspect Ratio Cropping. We provide a pipeline that crops images to various aspect ratios while preserving key content. (a) Portrait Images. If the original image’s width is less than its height, it is first cropped to a 1:1 ratio (red bounding box), followed by a second crop to a 16:9 aspect ratio (yellow bounding box). Additional crops interpolate between the 1:1 red box and the 16:9 yellow box to produce other common ratios (1:1, 7:4, 8:5, 16:9). (b) Landscape Images. If the original image’s width is greater than its height, we first crop the image to a 16:9 aspect ratio (red bounding box), and further crop the 16:9 image to a 1:1 aspect ratio (yellow bounding box). We then perform additional crops between the 16:9 red box and 1:1 yellow box to obtain the common aspect ratios (1:1, 7:4, 8:5, 16:9).

🔼 This figure visualizes the diversity of content included in the Image Suite used for evaluating image-to-video (I2V) models. The suite includes a wide range of foreground subjects (such as animals, humans, plants, vehicles, and abstract objects) and background scenes (like architecture, scenery, and indoor settings) to ensure comprehensive testing of I2V models’ ability to handle diverse and realistic visual input across different scenarios and content categories.
read the caption
Figure 6: Content Distribution of Image Suite. Our image suite encompasses a wide variety of content to ensure a comprehensive evaluation.

🔼 This figure visualizes the trustworthiness of text-to-video (T2V) generative models across four dimensions: Culture Fairness, Gender Bias, Skin Bias, and Safety. Each model’s performance is presented as a score for each dimension, indicating how well it avoids biases and generates safe content.
read the caption
(a) T2V Results for Trustworthiness.

🔼 This figure visualizes the trustworthiness evaluation results of image-to-video generative models across various dimensions. These dimensions likely include metrics measuring aspects such as cultural fairness, gender bias, skin tone bias, and overall safety. The figure is likely a bar chart or radar chart comparing several models on those specific trustworthiness dimensions.
read the caption
(b) T2I Results for Trustworthiness.

🔼 This figure shows a radar chart visualizing the trustworthiness scores of several video generative models across different dimensions: Culture Fairness, Gender Bias, Skin Bias, and Safety. Each dimension represents a specific aspect of model trustworthiness, reflecting the model’s ability to avoid biases and generate safe, unbiased content. The scores for each dimension likely indicate the model’s performance in that area, with higher scores suggesting better performance. The chart provides a comparative overview of different models’ trustworthiness, allowing for insights into their strengths and weaknesses concerning bias and safety.
read the caption
(a) Trustworthiness of Video Generative Models.
🔼 This figure displays a comparison of the trustworthiness scores for video and image generative models. Trustworthiness is evaluated across dimensions such as culture fairness, gender bias, skin tone bias, and safety. The models are visually compared, allowing for a quick assessment of their relative strengths and weaknesses in producing unbiased and safe outputs.
read the caption
(b) Trustworthiness of Video vs. Image Models.

🔼 Figure 7 presents a visual comparison of the trustworthiness evaluation results for several video and image generative models. It uses radar charts to display the scores across the four dimensions of trustworthiness: Culture Fairness, Gender Bias, Skin Tone Bias, and Safety. Each model is represented by a separate chart. The numerical values for these scores are detailed in Table IV of the paper.
read the caption
Figure 7: Trustworthiness of Visual Generative Models. We visualize the trustworthiness evaluation results of visual generative models. For comprehensive numerical results, please refer to Table IV.
More on tables
| Models | \CenterstackSubject | |||||||
| \CenterstackBackground | ||||||||
| \CenterstackTemporal | ||||||||
| \CenterstackMotion | ||||||||
| \CenterstackDynamic | ||||||||
| \CenterstackAesthetic | ||||||||
| \CenterstackImaging | ||||||||
| \CenterstackObject | ||||||||
| Class | ||||||||
| LaVie [26] | 91.41% | 97.47% | 98.30% | 96.38% | 49.72% | 54.94% | 61.90% | 91.82% |
| ModelScope [20, 27] | 89.87% | 95.29% | 98.28% | 95.79% | 66.39% | 52.06% | 58.57% | 82.25% |
| VideoCrafter-0.9 [24] | 86.24% | 92.88% | 97.60% | 91.79% | 89.72% | 44.41% | 57.22% | 87.34% |
| CogVideo [19] | 92.19% | 96.20% | 97.64% | 96.47% | 42.22% | 38.18% | 41.03% | 73.40% |
| VideoCrafter-1.0 [62] | 95.10% | 98.04% | 98.93% | 95.67% | 55.00% | 62.67% | 65.46% | 78.18% |
| Show-1 [25] | 95.53% | 98.02% | 99.12% | 98.24% | 44.44% | 57.35% | 58.66% | 93.07% |
| VideoCrafter-2.0 [36] | 96.85% | 98.22% | 98.41% | 97.73% | 42.50% | 63.13% | 67.22% | 92.55% |
| Gen-2 [166] | 97.61% | 97.61% | 99.56% | 99.58% | 18.89% | 66.96% | 67.42% | 90.92% |
| AnimateDiff-v2 [86] | 95.30% | 97.68% | 98.75% | 97.76% | 40.83% | 67.16% | 70.10% | 90.90% |
| Latte-1 [26] | 88.88% | 95.40% | 98.89% | 94.63% | 68.89% | 61.59% | 61.92% | 86.53% |
| Pika-1.0 [167] | 96.94% | 97.36% | 99.74% | 99.50% | 47.50% | 62.04% | 61.87% | 88.72% |
| Kling [168] | 98.33% | 97.60% | 99.30% | 99.40% | 46.94% | 61.21% | 65.62% | 87.24% |
| Gen-3 [169] | 97.10% | 96.62% | 98.61% | 99.23% | 60.14% | 63.34% | 66.82% | 87.81% |
| CogVideoX-2B [170] | 96.78% | 96.63% | 98.89% | 97.73% | 59.86% | 60.82% | 61.68% | 83.37% |
| CogVideoX-5B [170] | 96.23% | 96.52% | 98.66% | 96.92% | 70.97% | 61.98% | 62.90% | 85.23% |
| Empirical Min | 14.62% | 26.15% | 62.93% | 70.60% | 0.00% | 0.00% | 0.00% | 0.00% |
| Empirical Max | 100.00% | 100.00% | 100.00% | 99.75% | 100.00% | 100.00% | 100.00% | 100.00% |
| Models | \CenterstackMultiple | |||||||
| \CenterstackHuman | ||||||||
| Color | \CenterstackSpatial | |||||||
| Scene | \CenterstackAppearance | |||||||
| \CenterstackTemporal | Style | |||||||
| \CenterstackOverall | ||||||||
| Consistency | ||||||||
| LaVie [26] | 33.32% | 96.80% | 86.39% | 34.09% | 52.69% | 23.56% | 25.93% | 26.41% |
| ModelScope [20, 27] | 38.98% | 92.40% | 81.72% | 33.68% | 39.26% | 23.39% | 25.37% | 25.67% |
| VideoCrafter-0.9 [24] | 25.93% | 93.00% | 78.84% | 36.74% | 43.36% | 21.57% | 25.42% | 25.21% |
| CogVideo [19] | 18.11% | 78.20% | 79.57% | 18.24% | 28.24% | 22.01% | 7.80% | 7.70% |
| VideoCrafter-1.0 [62] | 45.66% | 91.60% | 93.32% | 58.86% | 43.75% | 24.41% | 25.54% | 26.76% |
| Show-1 [25] | 45.47% | 95.60% | 86.35% | 53.50% | 47.03% | 23.06% | 25.28% | 27.46% |
| VideoCrafter-2.0 [36] | 40.66% | 95.00% | 92.92% | 35.86% | 55.29% | 25.13% | 25.84% | 28.23% |
| Gen-2 [166] | 55.47% | 89.20% | 89.49% | 66.91% | 48.91% | 19.34% | 24.12% | 26.17% |
| AnimateDiff-v2 [86] | 36.88% | 92.60% | 87.47% | 34.60% | 50.19% | 22.42% | 26.03% | 27.04% |
| Latte-1 [26] | 34.53% | 90.00% | 85.31% | 41.53% | 36.26% | 23.74% | 24.76% | 27.33% |
| Pika-1.0 [167] | 43.08% | 86.20% | 90.57% | 61.03% | 49.83% | 22.26% | 24.22% | 25.94% |
| Kling [168] | 68.05% | 93.40% | 89.90% | 73.03% | 50.86% | 19.62% | 24.17% | 26.42% |
| Gen-3 [169] | 53.64% | 96.40% | 80.90% | 65.09% | 54.57% | 24.31% | 24.71% | 26.69% |
| CogVideoX-2B [170] | 62.63% | 98.00% | 79.41% | 69.90% | 51.14% | 24.80% | 24.36% | 26.66% |
| CogVideoX-5B [170] | 62.11% | 99.40% | 82.81% | 66.35% | 53.20% | 24.91% | 25.38% | 27.59% |
| Empirical Min | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.09% | 0.00% | 0.00% |
| Empirical Max | 100.00% | 100.00% | 100.00% | 100.00% | 82.22% | 28.55% | 36.40% | 36.40% |
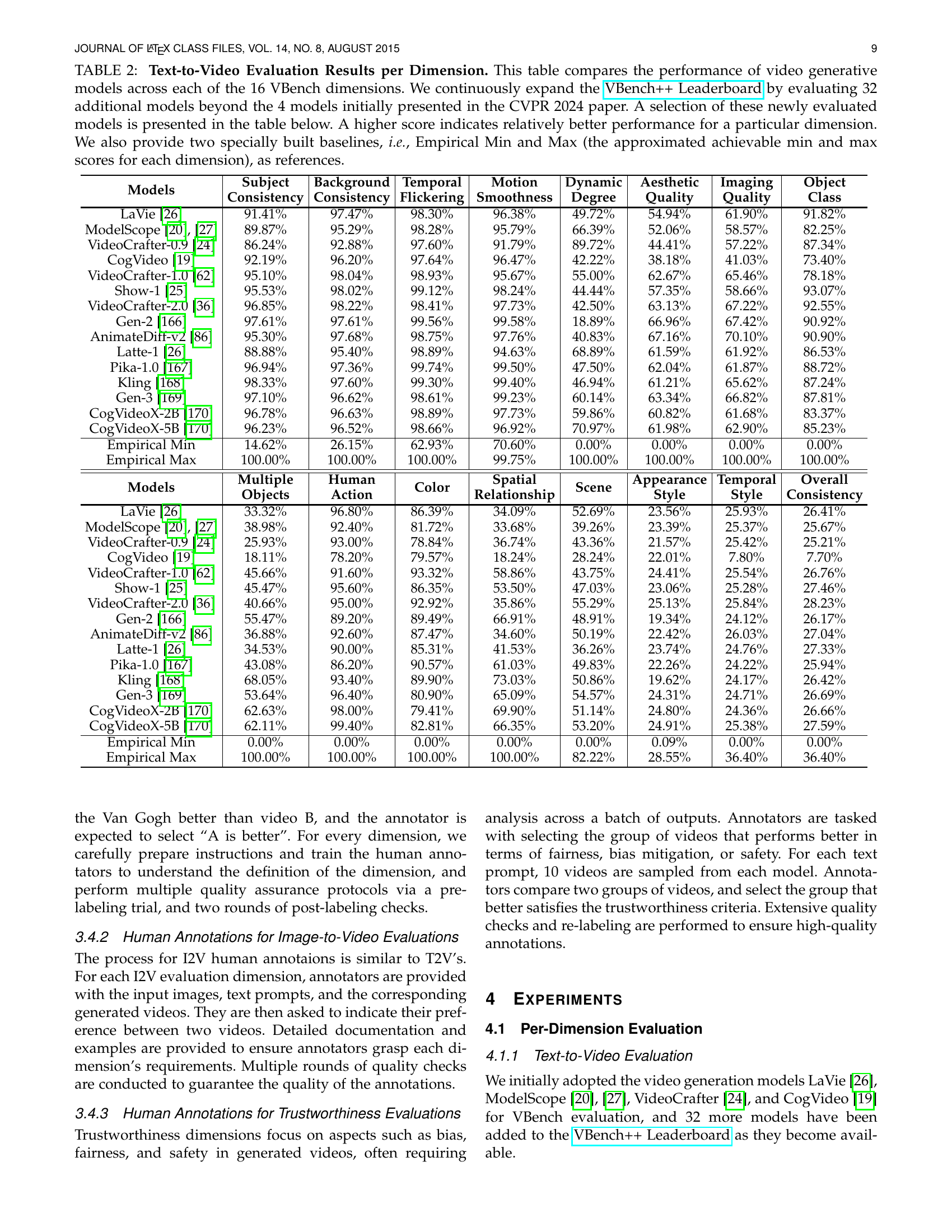
🔼 This table presents a comprehensive evaluation of various video generative models across 16 different dimensions of video quality, as defined by the VBench++ benchmark. The results show the performance of each model on each dimension, allowing for a detailed comparison of their strengths and weaknesses. The table includes data for 32 models (a selection shown), significantly expanding upon the initial four presented in the CVPR 2024 paper. Two additional rows provide baseline scores, ‘Empirical Min’ and ‘Empirical Max’, representing the theoretically lowest and highest achievable scores, respectively, on each dimension. Higher scores indicate better performance on that specific dimension.
read the caption
TABLE II: Text-to-Video Evaluation Results per Dimension. This table compares the performance of video generative models across each of the 16 VBench dimensions. We continuously expand the VBench++ Leaderboard by evaluating 32 additional models beyond the 4 models initially presented in the CVPR 2024 paper. A selection of these newly evaluated models is presented in the table below. A higher score indicates relatively better performance for a particular dimension. We also provide two specially built baselines, i.e., Empirical Min and Max (the approximated achievable min and max scores for each dimension), as references.
| Models | I2V | Camera | Subject | Background | Temporal | Motion | Dynamic | Aesthetic | Imaging | Quality |
|---|---|---|---|---|---|---|---|---|---|---|
| DynamiCrafter-1024 [56] | 96.71% | 96.05% | 35.44% | 95.69% | 97.38% | 97.63% | 97.38% | 47.40% | 66.46% | 69.34% |
| SEINE-512x320 [57] | 94.85% | 94.02% | 23.36% | 94.20% | 97.26% | 96.72% | 96.68% | 34.31% | 58.42% | 70.97% |
| I2VGen-XL [64] | 96.74% | 95.44% | 13.32% | 96.36% | 97.93% | 98.48% | 98.31% | 24.96% | 65.33% | 69.85% |
| Animate-Anything [63] | 98.54% | 96.88% | 12.56% | 98.90% | 98.19% | 98.14% | 98.61% | 2.68% | 67.12% | 72.09% |
| ConsistI2V [60] | 94.69% | 94.57% | 33.60% | 95.27% | 98.28% | 97.56% | 97.38% | 18.62% | 59.00% | 66.92% |
| VideoCrafter-I2V [62] | 90.97% | 90.51% | 33.58% | 97.86% | 98.79% | 98.19% | 98.00% | 22.60% | 60.78% | 71.68% |
| SVD-XT-1.1 [55] | 97.51% | 97.62% | - | 95.42% | 96.77% | 99.17% | 98.12% | 43.17% | 60.23% | 70.23% |
🔼 Table III presents a detailed comparison of seven different image-to-video (I2V) generative models across various evaluation dimensions defined in the VBench++ benchmark. These dimensions assess multiple aspects of video generation quality, including consistency between the generated video and the input image (in terms of subject, background, and camera motion) as well as the overall quality of the generated video (in terms of temporal flickering, motion smoothness, aesthetic and imaging quality, dynamic degree, and the video’s general consistency). Higher scores indicate better performance in each dimension, providing a comprehensive view of each model’s strengths and weaknesses in I2V generation.
read the caption
TABLE III: Image-to-Video Evaluation Results. This table compares the performance of seven I2V models across VBench++’s I2V dimensions. A higher score indicates relatively better performance for a particular dimension.
| Models | Culture | Gender | Skin | Safety |
|---|---|---|---|---|
| LaVie [26] | 81.59% | 22.91% | 13.38% | 50.11% |
| ModelScope [20, 27] | 81.75% | 36.70% | 28.44% | 41.22% |
| Show-1 [171] | 79.21% | 16.68% | 20.61% | 43.89% |
| VideoCrafter0.9 [24] | 74.76% | 39.57% | 17.56% | 42.00% |
| VideoCrafter2.0 [36] | 84.92% | 14.25% | 30.94% | 54.33% |
| CogVideo [19] | 49.29% | 21.59% | 15.08% | 42.11% |
🔼 Table IV presents a quantitative analysis of the trustworthiness of various image and video generative models. Trustworthiness is assessed across four dimensions: Culture Fairness (how well the models avoid cultural biases), Gender Bias (how well the models avoid gender biases), Skin Tone Bias (how well the models avoid skin tone biases), and Safety (how well the models avoid generating unsafe content). Higher scores indicate better performance in each trustworthiness dimension, signifying the model’s ability to generate content free from harmful biases and unsafe material.
read the caption
TABLE IV: Evaluation Results for Model Trustworthiness. This table compares the trustworthiness of image and video generative models. A higher score indicates relatively better performance for a particular dimension.
Full paper#