↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current Large Language Models (LLMs) and Vision Language Models (VLMs) show promise in reasoning but struggle with complex, dynamic, real-world tasks requiring long-term planning and continuous interaction. Existing benchmarks are insufficient, focusing on short-horizon tasks and lacking robust evaluation methodologies for complex capabilities.
This research introduces BALROG, a new benchmark designed to evaluate LLMs and VLMs through challenging games of varying difficulty. BALROG uses fine-grained metrics and includes an extensive evaluation of various models, revealing significant deficiencies in vision-based decision-making. The benchmark is open-source and user-friendly to facilitate future research and development in the agentic AI community.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces BALROG, a novel benchmark for evaluating the agentic capabilities of LLMs and VLMs. This addresses a significant gap in the field by providing a rigorous and comprehensive evaluation framework for long-horizon, interactive tasks. This will significantly advance the development of truly autonomous agents, spurring further research on improving LLM/VLM reasoning and decision-making abilities.
Visual Insights#

🔼 This figure shows the architecture of the BALROG benchmark, which is designed to evaluate the performance of large language models (LLMs) in long-context interactive tasks. The benchmark uses a modular design, allowing researchers to easily test new models and inference methods. The main components include: agent.py (where the agent’s logic for decision making resides), client.py (handling interactions with various LLMs/APIs), env_wrapper.py (standardizing interactions with different game environments), and evaluator.py (running episodes and collecting performance metrics). The diagram illustrates how these components interact during the evaluation process.
read the caption
Figure 1: An overview of the BALROG Benchmark for evaluating LLMs on long-context interactive tasks. Submissions of new inference-time methods for improving the capabilities of an existing model via an “agentic strategy” need only modify the agent.py file. Similarly, benchmarking a new model zero-shot can be done by adjusting a configuration file in client.py. The agent class includes a prompt builder to manage observation history, and a client that abstracts the complexities of various APIs and model-serving frameworks. The env_wrapper.py file standardizes interaction across settings, and the evaluator executes agents and collects performance metrics.
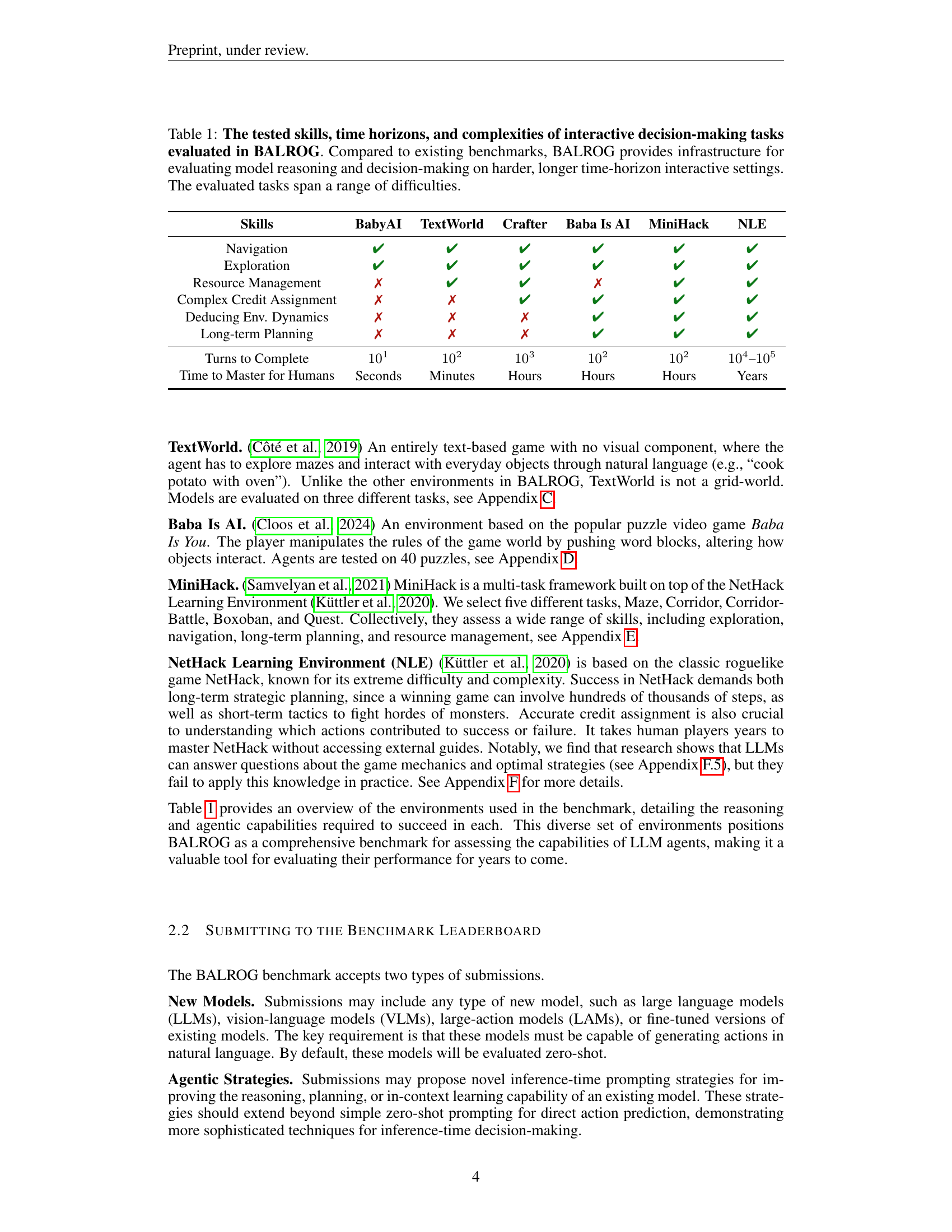
| Skills | BabyAI | TextWorld | Crafter | Baba Is AI | MiniHack | NLE |
|---|---|---|---|---|---|---|
| Navigation | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Exploration | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Resource Management | ✗ | ✔ | ✔ | ✗ | ✔ | ✔ |
| Complex Credit Assignment | ✗ | ✗ | ✔ | ✔ | ✔ | ✔ |
| Deducing Env. Dynamics | ✗ | ✗ | ✗ | ✔ | ✔ | ✔ |
| Long-term Planning | ✗ | ✗ | ✗ | ✔ | ✔ | ✔ |
| Turns to Complete | 101 | 102 | 103 | 102 | 104–105 | |
| Time to Master for Humans | Seconds | Minutes | Hours | Hours | Hours | Years |
🔼 Table 1 presents a comparison of six interactive decision-making tasks across various aspects: the skills required (navigation, exploration, resource management, credit assignment, understanding environment dynamics, and long-term planning), the time horizon (seconds to years), and the difficulty for human players to master. It highlights that BALROG, unlike previous benchmarks, offers a platform to rigorously evaluate AI models’ reasoning abilities in complex scenarios demanding more extended interactions and greater difficulty, thus bridging the gap between simpler benchmarks and true real-world application.
read the caption
Table 1: The tested skills, time horizons, and complexities of interactive decision-making tasks evaluated in BALROG. Compared to existing benchmarks, BALROG provides infrastructure for evaluating model reasoning and decision-making on harder, longer time-horizon interactive settings. The evaluated tasks span a range of difficulties.
In-depth insights#
Agentic LLM Games#
The concept of “Agentic LLM Games” proposes a fascinating intersection of large language models (LLMs) and interactive game environments. It highlights the potential of using games as sophisticated benchmarks to evaluate the emergent reasoning and decision-making abilities of LLMs. Instead of relying on static datasets, games offer dynamic, multi-step challenges that demand strategic planning, adaptation, and long-term reasoning. The complexity and diversity of games are ideally suited for revealing the strengths and limitations of LLMs, particularly in areas such as spatial reasoning, long-term planning, and environmental interaction. By measuring an LLM’s success in achieving in-game objectives, researchers can gain insights into its ability to generalize knowledge, learn from feedback, and manage resources effectively. Developing such benchmarks allows for more robust and nuanced evaluations compared to traditional, static datasets. However, challenges remain in balancing the difficulty of game environments with the current capabilities of LLMs, as well as ensuring that games are designed to effectively test specific agentic skills rather than simply measuring memorization or pattern recognition.
BALROG Benchmark#
The BALROG benchmark is a significant contribution to the field of AI, specifically in evaluating the agentic capabilities of Large Language Models (LLMs) and Vision Language Models (VLMs). It addresses the critical need for robust benchmarks that go beyond simple, short-horizon tasks by using a diverse set of challenging games. This approach is crucial because real-world applications necessitate LLMs that can engage in long-term planning, spatial reasoning, and continuous decision-making, all of which are tested in BALROG. The benchmark’s fine-grained metrics and open-source nature allow for a thorough evaluation and encourage community participation, fostering further research and development. The inclusion of both language-only and vision-language modalities allows for the assessment of models across different capabilities, highlighting the specific challenges associated with incorporating visual information. Overall, BALROG is a valuable resource for the agentic AI community, pushing the boundaries of LLM evaluation and driving progress in building more capable and robust AI systems.
Vision-Language Gap#
The concept of a “Vision-Language Gap” in the context of large language models (LLMs) and vision-language models (VLMs) highlights the significant discrepancy between their performance on tasks involving both visual and textual information versus those involving only text. The core issue lies in the models’ inability to effectively integrate and reason with visual input, especially in complex scenarios requiring spatial reasoning, long-term planning, and continuous interaction. While LLMs excel at processing and generating text, VLMs often struggle to translate visual data into meaningful actions or decisions within a dynamic environment. This gap suggests a need for improved model architectures that can seamlessly bridge the vision and language modalities, enabling a more holistic understanding and effective response to multimodal inputs. Current research should focus on developing techniques for robust feature extraction from images and effective fusion of visual and textual features within an integrated framework. Overcoming this gap is crucial for developing truly versatile and robust AI agents capable of operating in real-world environments where interactions involve both visual and textual data. Addressing the vision-language gap may involve exploring alternative training strategies and architectures, such as incorporating reinforcement learning to enhance the models’ ability to learn from experience within visual contexts and improve their ability to make informed, visually grounded decisions. This research will also benefit from the development of new benchmark datasets which explicitly target this gap.
Long-Horizon Limits#
The heading ‘Long-Horizon Limits’ suggests an exploration of the challenges faced by current AI models in tasks requiring extended temporal reasoning. This would likely involve a discussion of planning limitations: how far into the future can models effectively plan and account for cascading consequences of actions? The analysis might delve into model architectures and their inherent limitations in maintaining coherent context and representations across numerous timesteps. Further, the investigation could address the data scarcity problem: training datasets rarely contain sufficiently long sequences of events to adequately train models for long-horizon decision-making. This section likely involves a comparison of model performance on tasks with varying temporal horizons, potentially highlighting a significant drop-off in accuracy as task complexity increases. Another aspect could be the computational cost: handling long sequences demands significant computational resources, raising challenges regarding scalability and real-time applicability. Finally, a key point might be the emergent behavior aspect; does unpredictable or unexpected behavior emerge as the time horizon extends, and how can this be addressed? Overall, ‘Long-Horizon Limits’ appears to be a critical examination of current AI capabilities and a pathway for future research.
Future Research#
The “Future Research” section of this paper could explore several promising avenues. In-context learning and few-shot prompting are crucial for improving model performance in long-horizon tasks. This involves adapting models to out-of-distribution scenarios using few-shot examples. Advanced reasoning strategies, such as chain-of-thought and self-refinement, could be investigated to enhance the decision-making processes of LLMs in the complex game environments. Multi-agent collaborations and tool use would significantly increase the complexity and realism of the benchmark, testing the limits of current LLM capabilities in complex interactions. The inherent challenges of visual processing within LLMs and VLMs should also be addressed, as current models struggle with integrating visual information effectively. This requires deeper investigation into model architectures and training methodologies to enable more robust vision-based decision-making. Finally, a thorough analysis of the computational limitations of LLMs is needed, examining the scalability and efficiency of models across various tasks.
More visual insights#
More on figures

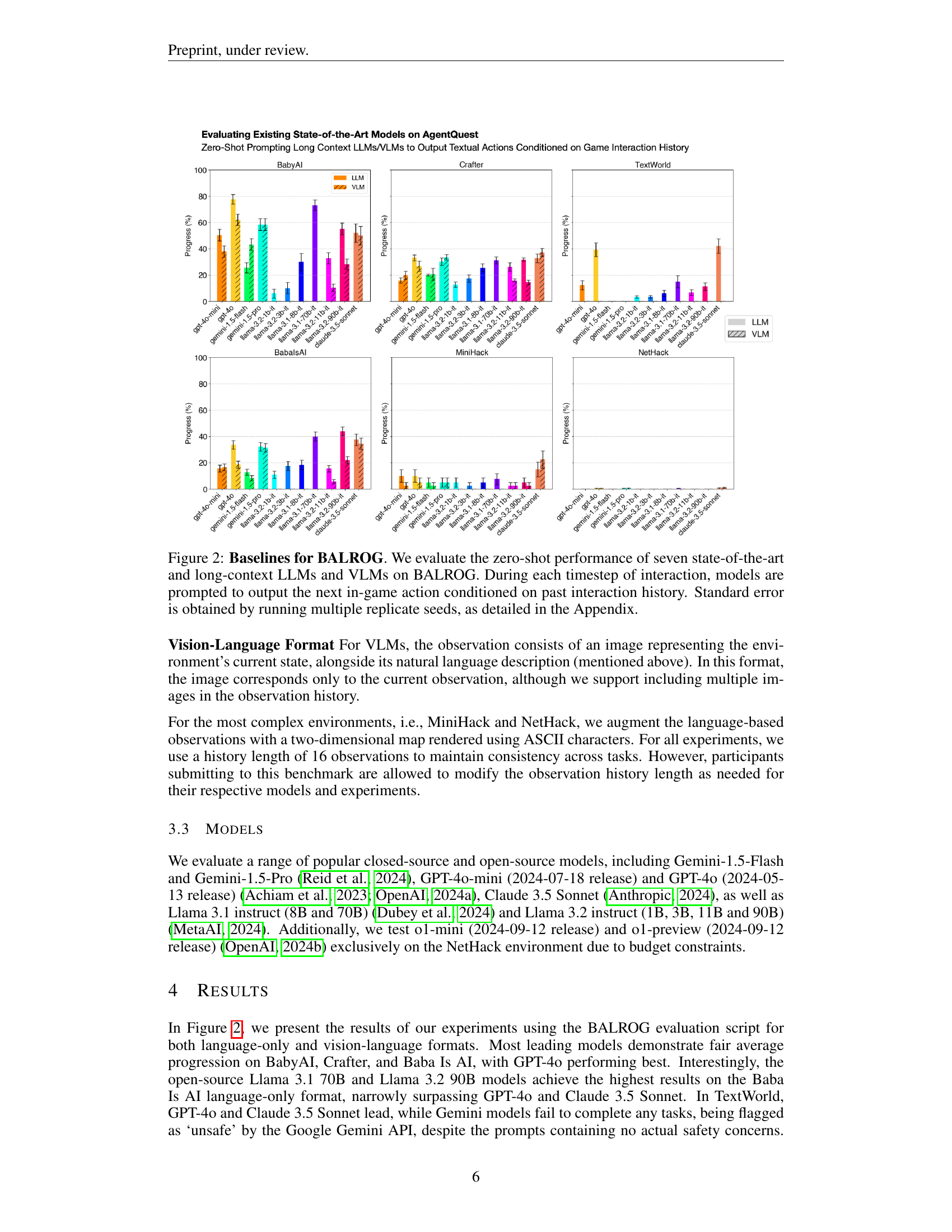
🔼 This figure displays the zero-shot performance of seven state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs) on the BALROG benchmark across four different games: BabyAI, Crafter, TextWorld, and MiniHack. Each model’s performance is represented by a bar graph showing the percentage of progress achieved in each game. The x-axis shows the different LLMs and VLMs tested, and the y-axis represents the percentage of game completion. Error bars indicate the standard error calculated from multiple runs to account for randomness in the games and agents’ behaviors. The results show significant variations in performance across different models and game types, with some models excelling in simpler games while failing to make progress in more complex ones.
read the caption
Figure 2: Baselines for BALROG. We evaluate the zero-shot performance of seven state-of-the-art and long-context LLMs and VLMs on BALROG. During each timestep of interaction, models are prompted to output the next in-game action conditioned on past interaction history. Standard error is obtained by running multiple replicate seeds, as detailed in the Appendix.

🔼 This table presents the average progress percentage achieved by different Language Models (LLMs) across various tasks in the BALROG benchmark, specifically focusing on tasks where only textual information (language) is provided as input to the models. The results illustrate the relative performance of each LLM in terms of successfully completing the given tasks using only language-based decision-making. Higher percentages indicate better performance.
read the caption
Table 2: Language-Only Performance

🔼 This table presents the average progress (%) achieved by various Vision-Language Models (VLMs) on the BALROG benchmark. The VLMs were evaluated using a combination of visual and textual information from the game environments. The results show the average performance across multiple runs, indicating the effectiveness of each model in integrating both visual and textual cues for decision-making in challenging game scenarios. The models tested include Claude 3.5-sonnet, GPT-40, Gemini-1.5-Pro, Gemini-1.5-flash, and several versions of the LLaMa model.
read the caption
Table 3: Vision-Language Performance

🔼 This table presents the average performance of various Large Language Models (LLMs) on the BabyAI tasks. The performance metric is the average progress percentage across five different BabyAI tasks, calculated using 25 separate runs for each model. The results show the zero-shot performance of each LLM; that is, the performance achieved by the model without any fine-tuning or additional training on the BabyAI environment. Higher percentages indicate better performance.
read the caption
Table 4: LLM Performance on BabyAI

🔼 This table presents the average progress percentage achieved by various Vision-Language Models (VLMs) on the BabyAI tasks within the BALROG benchmark. The results show the average performance across multiple runs, with standard errors indicating the variability of the results. Lower numbers indicate lower performance. The models tested include: gpt-40, gemini-1.5-pro, claude-3.5-sonnet, gemini-1.5-flash, llama-3.2-11B-it, llama-3.1-8B-it, llama-3.2-3B-it, and llama-3.2-1B-it.
read the caption
Table 5: VLM Performance on BabyAI

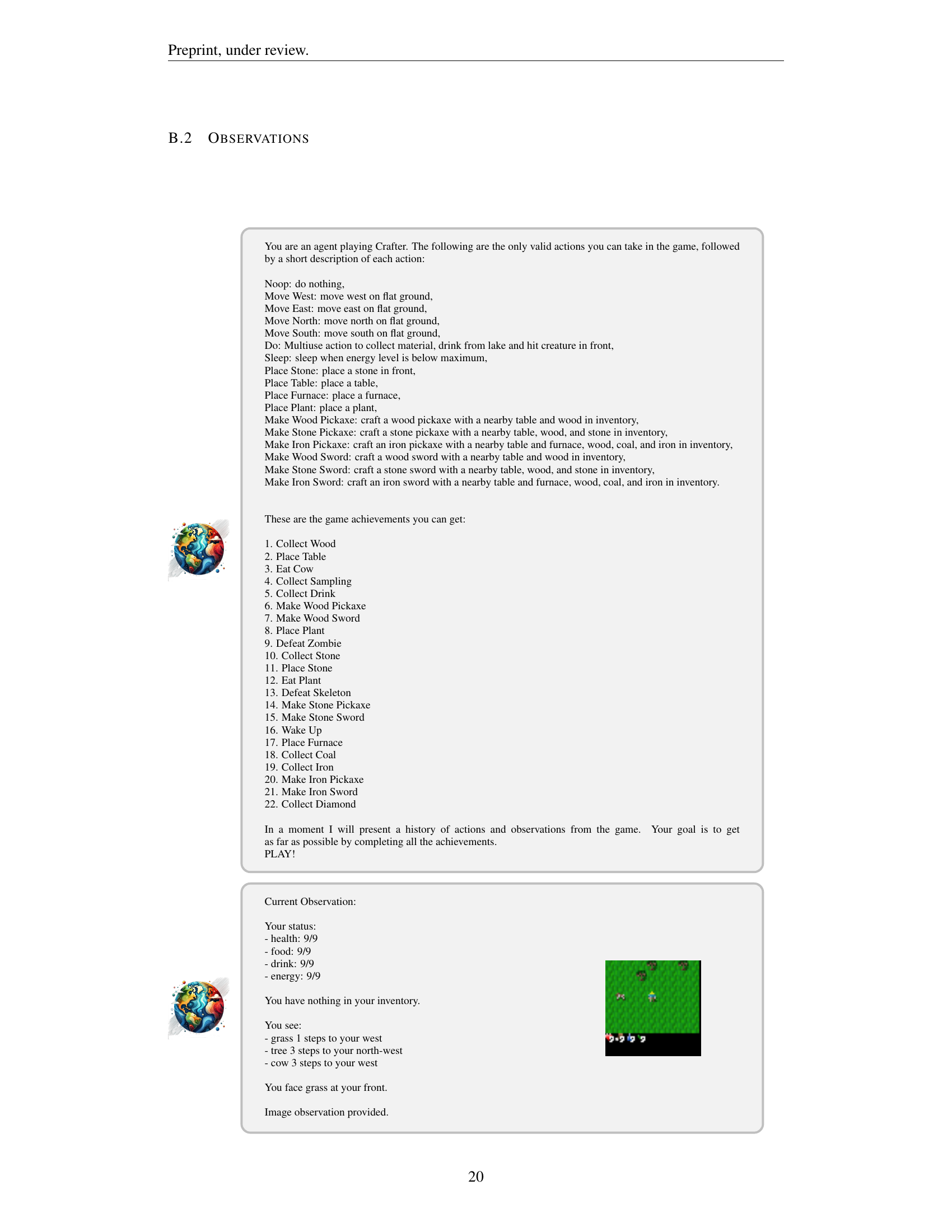
🔼 Figure 3 shows three examples of procedurally generated game maps from the Crafter environment. Each map is unique, featuring different terrain types, resource locations, and overall layouts. The procedural generation ensures that agents playing Crafter cannot rely on memorization of specific map features, requiring them to adapt their strategies to new and unforeseen environments in each playthrough.
read the caption
Figure 3: Crafter’s examples of unique procedurally generated maps.

🔼 This table presents the performance of different Large Language Models (LLMs) on the Crafter game environment. The performance metric is ‘Average Progress (%)’, representing the average progress achieved by each LLM in completing the game’s tasks. The results show the average progress and the associated standard error, calculated across multiple runs for each model. This allows for a comparison of how well each LLM performs in terms of the long-term planning, resource management, and exploration skills that are necessary to succeed in the Crafter game.
read the caption
Table 6: LLM Performance on Crafter

🔼 This table presents the average performance of various Vision-Language Models (VLMs) on the Crafter game environment. The performance is measured as the average progress percentage achieved by each VLM, taking into account standard errors derived from multiple runs. The table helps to compare the relative effectiveness of different VLMs in this specific game environment, which requires a combination of language understanding and visual perception.
read the caption
Table 7: VLM Performance on Crafter

🔼 This figure shows a screenshot of the TextWorld game interface. The top part displays the game’s narrative text, providing instructions and descriptions of the game environment and the player’s actions. Below the text is a visual representation of the game world, showing the player’s position and the location of various objects, including a carrot, lettuce, a knife, a stove, and a cookbook. On the right-hand side of the interface, the game’s inventory and statistics are shown, helping the user to keep track of the player’s possessions and progress within the game. The image demonstrates the combination of textual and visual information provided to the agents within the BALROG benchmark.
read the caption
Figure 4: TextWorld interface along with visualization.

🔼 The image shows a Baba Is You puzzle. The goal is to reach the green door, which is currently blocked by a ‘wall is stop’ rule. To solve the puzzle, the agent must move the text blocks to create a new rule, such as ‘door is win’, thereby changing the game’s rules and making it possible to reach the goal.
read the caption
Figure 5: One of the Baba Is AI puzzles, where the agent has to break the “wall is stop” rule, create new rule “door is win” and go to green door to solve the task.
More on tables
| Model | Average Progress (%) |
|---|---|
| gpt-4o | 32.34 ± 1.49 |
| claude-3.5-sonnet | 29.98 ± 1.98 |
| llama-3.1-70b-it | 27.88 ± 1.43 |
| llama-3.2-90B-it | 23.66 ± 1.09 |
| gemini-1.5-pro | 21.00 ± 1.18 |
| gpt-4o-mini | 17.36 ± 1.35 |
| llama-3.1-8b-it | 14.14 ± 1.51 |
| llama-3.2-11B-it | 13.54 ± 1.05 |
| gemini-1.5-flash | 9.73 ± 0.77 |
| llama-3.2-3B-it | 8.47 ± 1.12 |
| llama-3.2-1B-it | 6.32 ± 1.00 |
🔼 This table presents the average performance of various Large Language Models (LLMs) on the TextWorld environment, specifically focusing on three distinct tasks: Treasure Hunter, Cooking Game, and Coin Collector. The average progress is measured as a percentage, indicating how well each LLM performed in completing these tasks. The results showcase the relative strengths and weaknesses of different LLMs in handling text-based game environments and complex reasoning tasks.
read the caption
Table 8: LLM Performance on Textworld
| Model | Average Progress (%) |
|---|---|
| claude-3.5-sonnet | 29.08 ± 2.21 |
| gemini-1.5-pro | 25.76 ± 1.36 |
| gpt-4o | 22.56 ± 1.44 |
| gpt-4o-mini | 15.36 ± 1.29 |
| gemini-1.5-flash | 14.94 ± 1.40 |
| llama-3.2-90B-it | 13.43 ± 1.16 |
| llama-3.2-11B-it | 6.91 ± 0.84 |
🔼 Table 15 assesses the ability of various LLMs to apply their NetHack knowledge. It evaluates three aspects: the correctness of their answers to NetHack-related questions (compared to the NetHack Wiki), whether they correctly identify actions to avoid, and whether their in-game behavior reflects this understanding. A tilde (~) indicates a partially correct answer. N/A signifies that the agent did not encounter a situation requiring that specific knowledge.
read the caption
Table 15: Comparison of each LLMs (ability to apply) knowledge in Nethack. We manually grade the responses to each question based on the correctness of the response given (i.e. does the response match information from the Nethack wiki), the correctness of their conclusion (i.e. does the LLM correctly identify that such behaviour should be avoided), and whether an LLM agent’s behaviour during evaluation is consistent with the ground truth (i.e. does the agent successfully avoid the behaviours indicated in the questions). For answers that are partially correct, we award a ∼similar-to\simbold_∼ . We record behaviour as N/A when the agent does not encounter scenarios where knowledge of the corresponding question should be applied.
Full paper#