↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) based on transformers are computationally expensive and memory-intensive due to their quadratic complexity. State space models (SSMs) offer an alternative with constant complexity, but they struggle with memory recall. Existing hybrid models combining transformers and SSMs suffer from performance bottlenecks when one architecture type is less suitable for specific tasks.
This paper introduces Hymba, a new family of small language models that uses a hybrid-head architecture. This architecture combines transformer attention heads and SSM heads in parallel within the same layer. This allows Hymba to leverage both high-resolution recall of attention heads and the efficient context summarization of SSM heads. Hymba also uses learnable meta tokens that are prepended to input sequences to further enhance performance. Experimental results show that Hymba achieves state-of-the-art results, outperforming existing sub-2B public models and even surpassing Llama-3.2-3B in terms of accuracy, cache size, and throughput.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Hymba, a novel architecture that significantly improves the performance and efficiency of small language models. It addresses the limitations of existing transformer-based models by combining attention mechanisms with state space models. The findings are relevant to ongoing research on efficient and high-performing language models, and the proposed architecture opens up new avenues for further investigation in the field.
Visual Insights#

🔼 Figure 1 illustrates the architecture of Hymba’s hybrid-head module, which combines transformer attention and state space model (SSM) mechanisms. Panel (a) shows the internal structure of this module: input tokens are processed in parallel by both attention and SSM heads, generating attention features and SSM features, respectively. These features are then gated, normalized, and combined to produce the final output. Panel (b) provides an alternative interpretation by focusing on the memory aspects. The attention heads act as a snapshot memory, storing high-resolution details, while the SSM heads act as a fading memory, providing efficient context summarization. Meta tokens, prepended to the prompts, are also shown and act as a form of learned memory initialization, influencing both heads. This hybrid approach aims to leverage the strengths of both attention (high-resolution recall) and SSMs (efficient processing) for enhanced efficiency and performance.
read the caption
Figure 1: (a) Visualize the hybrid-head module in Hymba; (b) Interpret from the memory aspect.
| Design | Configuration | Param. Ratio | Avg. (General) ↑ | Avg. (Recall) ↑ | Throughput (Token/s) ↑ | Cache (MB) ↓ |
|---|---|---|---|---|---|---|
| Attn/Mamba Ratio | 1) Mamba Heads Only | 0:1 | 42.98 | 19.23 | 4720.8 | 1.87 |
| 2) Mamba + 4 Attn Heads | 1:8.48 | 44.20 | 44.65 | 3278.1 | 99.09 | |
| 3) Mamba + 8 Attn Heads | 1:4.24 | 44.95 | 52.53 | 1816.5 | 197.39 | |
| 4) Mamba + 16 Attn Heads | 1:2.12 | 45.08 | 56.46 | 656.6 | 394.00 | |
| 5) 4) + GQA | 1:3.64 | 45.19 | 49.90 | 876.7 | 148.24 | |
| 6) Attn Heads Only (Llama) | 1:0 | 44.08 | 39.98 | 721.1 | 414.72 | |
| Sliding Window | 7) 5) + All SWA’s | 1:3.64 | 44.42 | 29.78 | 4485.09 | 5.51 |
| 8) 5) + SWA’s + Full Attn | 1:3.64 | 44.56 | 48.79 | 2399.7 | 41.19 | |
| 9) 8) + Cross-layer KV sharing | 1:5.23 | 45.16 | 48.04 | 2756.5 | 39.42 | |
| 10) 6) + Same KV compression | 1:0 | 43.60 | 28.18 | 3710.0 | 28.98 | |
| Fusion | 11) 9) Replace Mean by Concat | 1: 5.82 | 44.56 | 48.94 | 1413.9 | 39.42 |
| Meta Tokens | 12) 1) + Meta Tokens | 0:1 | 44.01 | 19.34 | 4712.8 | 1.87 |
| 13) 9) + Meta Tokens | 1:5.23 | 45.53 | 51.79 | 2695.8 | 40.01 |
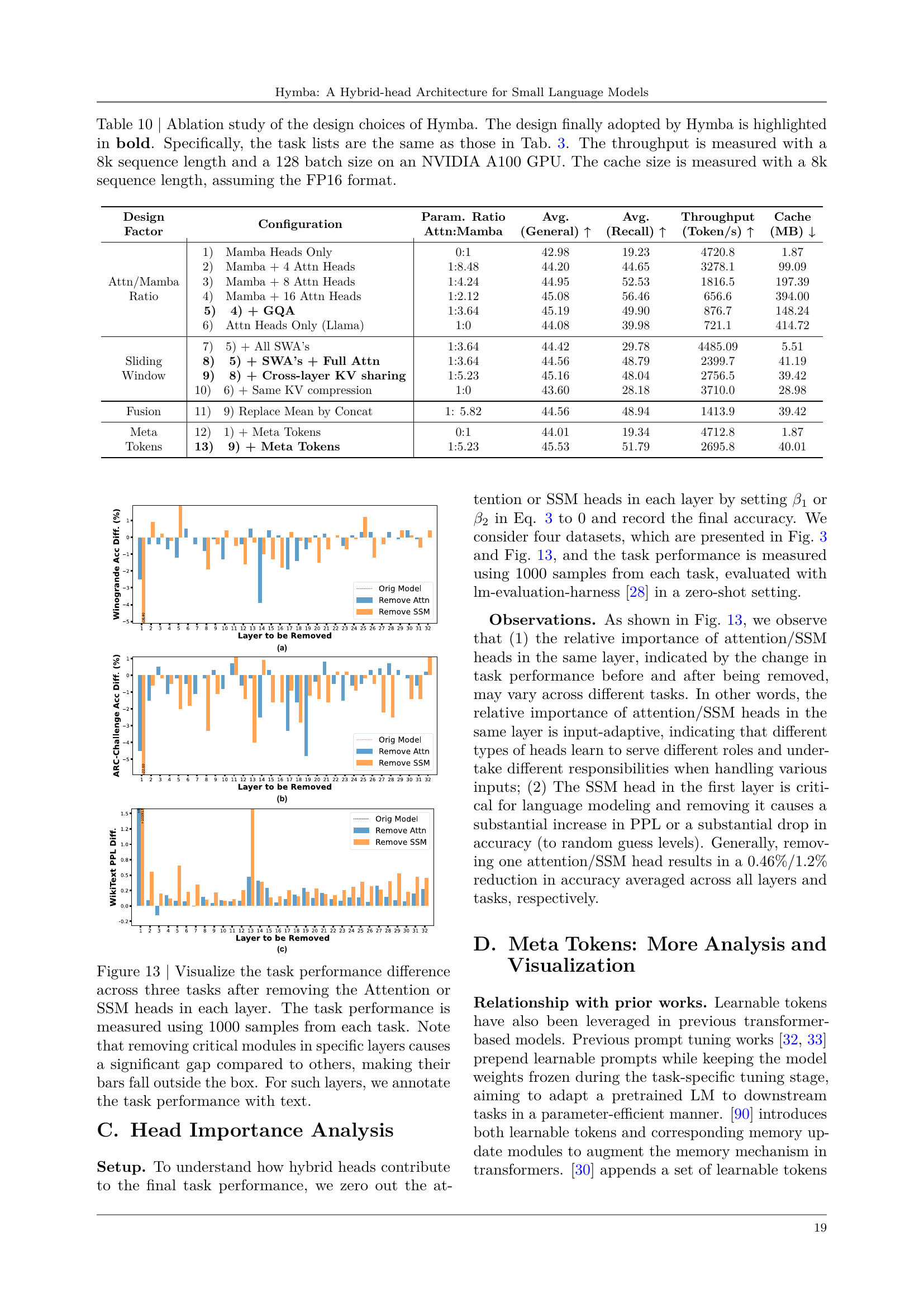
🔼 This table presents a detailed ablation study illustrating the design choices and their impact on the Hymba language model. It tracks the model’s performance across various configurations, evaluating both commonsense reasoning (averaged over eight tasks) and recall accuracy (averaged across two tasks). The metrics reported include throughput (measured on an NVIDIA A100 GPU with a sequence length of 8k and batch size of 128), and cache size (measured with an 8k sequence length using the FP16 format). The table provides insights into the design decisions made to balance efficiency and performance. Each row represents a specific configuration variation, allowing readers to observe the effects of individual design choices.
read the caption
Table 1: Design roadmap of our Hymba model. We evaluate the models’ (1) commonsense reasoning accuracy, averaged over 8 tasks, and (2) recall accuracy, averaged over 2 tasks, which corresponds to retrieving relevant information from past input. The throughput is on NVIDIA A100, sequence length 8k, batch size 128. The cache size is measured with a 8k sequence length, assuming the FP16 format.
In-depth insights#
Hybrid-Head Design#
The core of the proposed architecture is the hybrid-head design, which cleverly integrates transformer attention mechanisms with state space models (SSMs) within the same layer. This parallel processing allows the model to simultaneously leverage the strengths of both, namely, the high-resolution recall of attention and the efficient context summarization of SSMs. This combination is crucial as it addresses the limitations of using either method alone: attention’s quadratic complexity and SSMs’ struggles with memory recall. The integration of these complementary mechanisms leads to a model that’s both efficient and highly effective, achieving state-of-the-art results for small language models. The authors further enhance this design by incorporating learnable meta tokens and cross-layer key-value sharing, streamlining performance and reducing cache size. The synergistic combination of attention and SSM heads within the hybrid design forms the core innovation, making the model highly adaptable to diverse tasks while maintaining efficiency.
Meta Token Impact#
The concept of ‘Meta Token Impact’ in the context of language models is intriguing. These meta tokens, prepended to input sequences, act as a form of learned cache initialization, guiding attention and improving the model’s focus on relevant information. They seem to mitigate the “forced-to-attend” problem, addressing the issue of attention mechanisms being overly drawn to initial tokens. The impact is multifaceted: improved reasoning and recall accuracy are observed across various tasks, suggesting an enhanced ability to process and retain critical information. Furthermore, by acting as a compressed representation of world knowledge, meta tokens may alleviate attention dilution. Ultimately, the inclusion of meta tokens represents a significant advancement, enhancing efficiency and performance by acting as a learned, compressed memory aid and attention guide within the model architecture.
KV Cache Tuning#
Optimizing Key-Value (KV) cache memory is crucial for efficient large language models (LLMs). Strategies to reduce KV cache size include combining global and local attention mechanisms, leveraging the strengths of sliding window attention for local contexts while strategically using full attention for crucial global information. Cross-layer KV sharing is another technique, exploiting the high correlation between consecutive layers’ KV caches to reduce redundancy and memory footprint. The impact of these optimizations is significant, as shown by improvements in both throughput and model performance, demonstrating a successful trade-off between efficiency and accuracy. Learnable meta tokens prepended to input sequences are also suggested as a method to further enhance memory efficiency and address the ‘attention drain’ problem by providing context summarization and alleviating the burden on the attention mechanism. The effectiveness of these methods shows that a well-tuned KV cache is essential for creating faster, more efficient, and higher-performing small LLMs.
Small LM Benchmarks#
A dedicated section on ‘Small LM Benchmarks’ would be crucial for evaluating the proposed Hymba architecture’s performance. It should include a comparison against existing state-of-the-art (SOTA) small language models across various benchmark datasets. Key metrics should encompass average task accuracy, cache size, and throughput. The benchmarks should cover diverse task types, such as commonsense reasoning, question answering, and recall-intensive tasks, to provide a thorough performance assessment. Careful selection of benchmark datasets is essential to ensure the results are both relevant and representative of real-world applications. Furthermore, the section should explicitly mention the hardware used for evaluation to provide context and allow for reproducibility. Finally, a detailed breakdown of results across different model sizes within the ‘small LM’ category would showcase Hymba’s scaling capabilities, revealing its efficacy across various resource constraints. Transparency and completeness are critical; any limitations of the benchmarks or potential biases must be clearly disclosed to maintain the integrity and trustworthiness of the results.
Future Directions#
Future research should explore several promising avenues. Improving the efficiency of the hybrid-head architecture is crucial, potentially through more sophisticated fusion methods or specialized hardware acceleration. Further investigation into the optimal balance between attention and SSM heads across different tasks and input lengths would also yield valuable insights. Expanding the capabilities of learnable meta-tokens warrants attention, possibly by incorporating external knowledge sources or developing more advanced meta-learning techniques. Finally, applying Hymba to a wider range of downstream tasks and exploring its suitability for diverse language modalities (e.g., code, speech, multi-modal) will be important future steps.
More visual insights#
More on figures

🔼 This figure compares the performance of the Hymba-1.5B language model against other publicly available language models with fewer than 2 billion parameters. The comparison focuses on three key metrics: average accuracy across several benchmark tasks (5-shot MMLU, ARC-C, ARC-E, PIQA, Hellaswag, Winogrande, and SQUAD-C), cache size relative to sequence length, and throughput (tokens per second). The throughput was measured using an NVIDIA A100 GPU with specific settings (sequence length of 8k, batch size of 128, PyTorch). To address out-of-memory (OOM) errors during throughput testing, the batch size was halved until the OOM issue was resolved, ensuring the maximum possible throughput is reported.
read the caption
Figure 2: Performance comparison of Hymba-1.5B against sub-2B models in terms of average task accuracy, cache size (MB) relative to sequence length, and throughput (tok/sec). Specifically, the tasks include 5-shot MMLU, ARC-C, ARC-E, PIQA, Hellaswag, Winogrande, and SQuAD-C, and the throughput is measured on an NVIDIA A100 with a sequence length of 8k and a batch size of 128 using PyTorch. For models encountering out-of-memory (OOM) issues during throughput measurement, we halve the batch size until the OOM is resolved. This approach is used to measure the maximal achievable throughput without OOM.

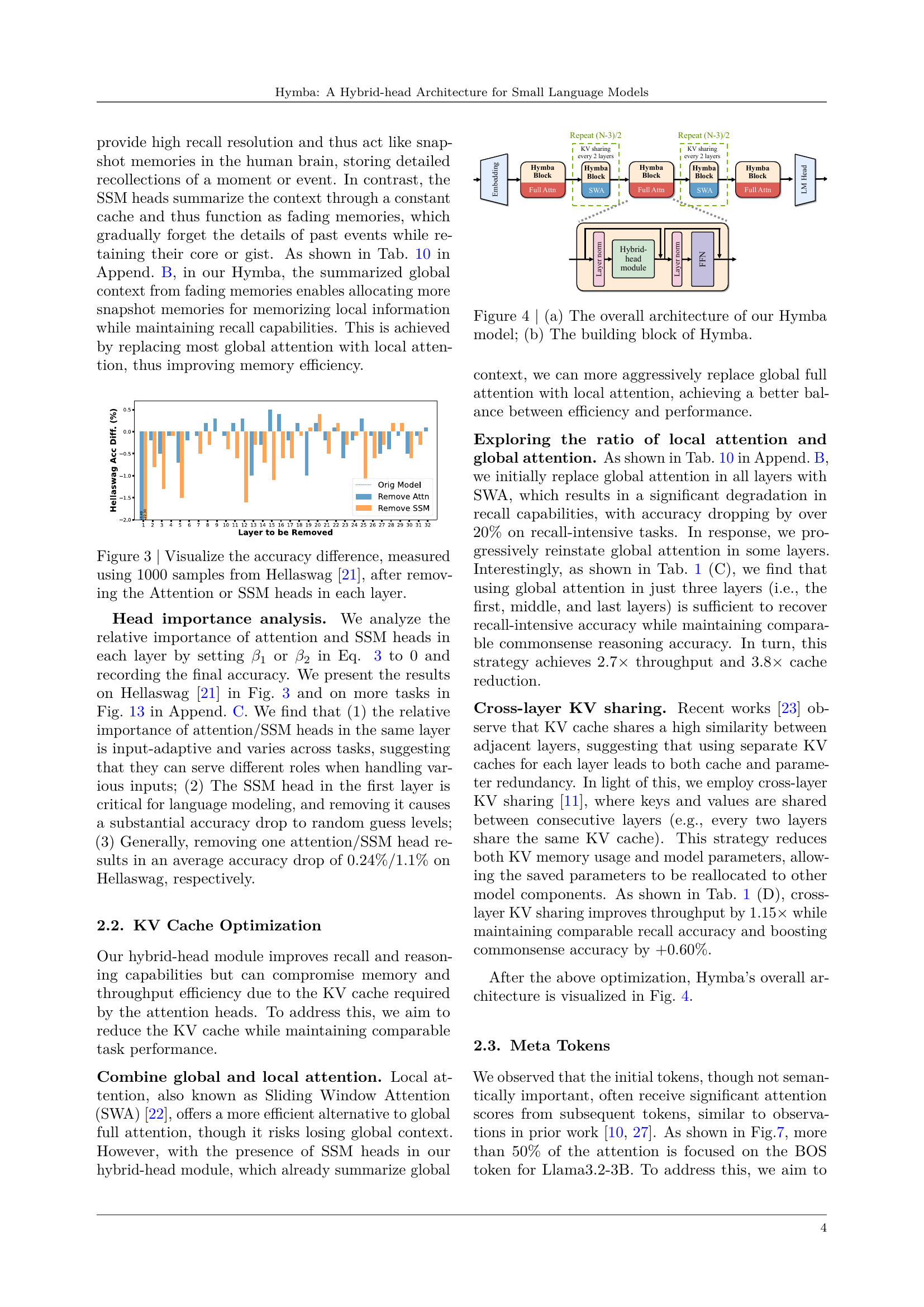
🔼 This figure shows the impact of removing either the attention heads or the SSM heads in each layer of the Hymba model on the Hellaswag accuracy. For each layer, the model was tested with and without attention heads and then with and without SSM heads. The difference in accuracy from the original model is displayed for each layer. This allows for a visualization of the relative importance of each head type across different layers in the model’s performance on Hellaswag.
read the caption
Figure 3: Visualize the accuracy difference, measured using 1000 samples from Hellaswag [21], after removing the Attention or SSM heads in each layer.

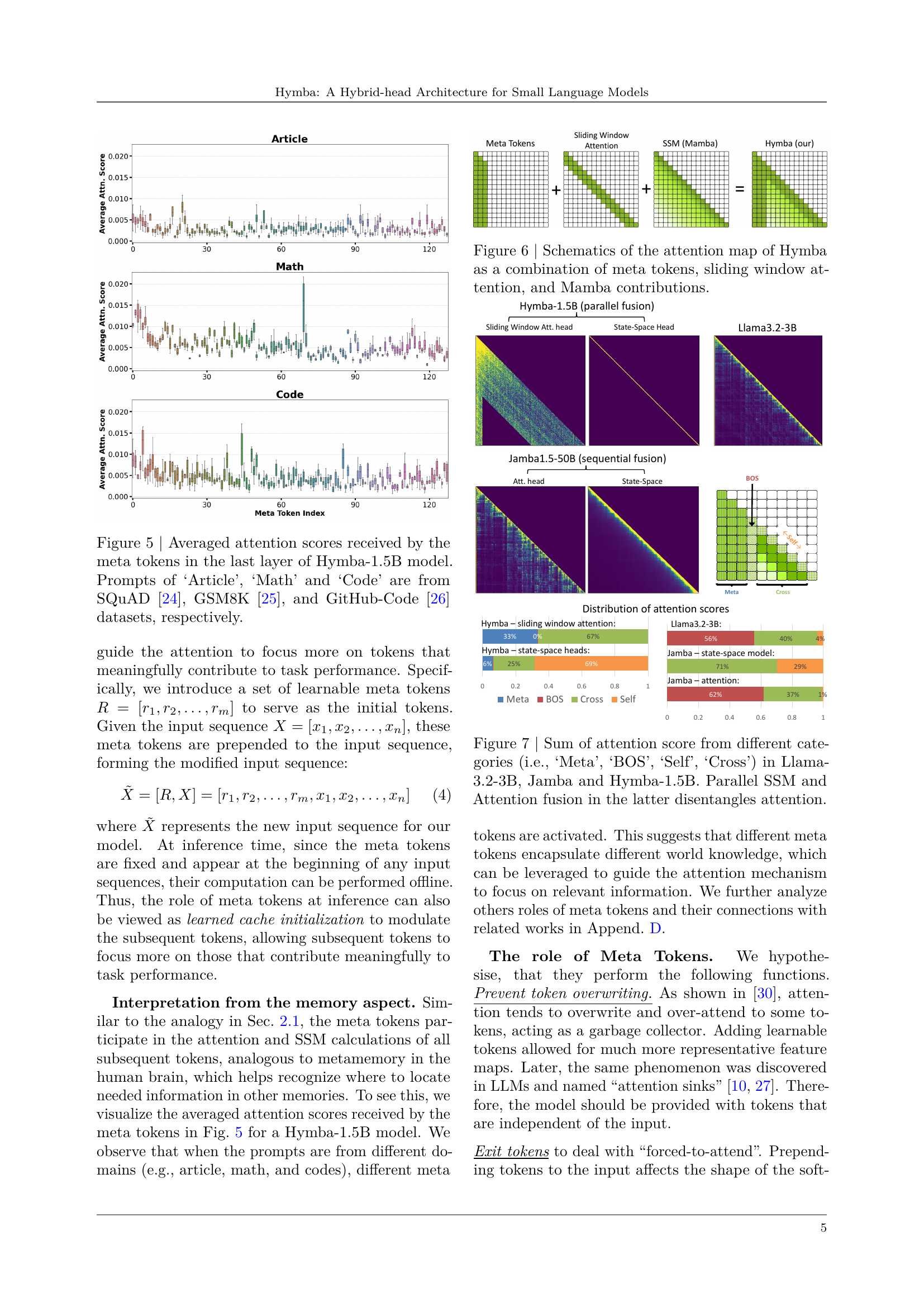
🔼 Figure 4 illustrates the architecture of the Hymba model. Part (a) shows the overall architecture, highlighting the repeated stacking of the building blocks to achieve the desired depth of the network. Part (b) details the structure of a single Hymba building block, which is composed of hybrid modules that process the input in parallel using both attention and state space model (SSM) heads. The building block design promotes complementary processing of input features, enhancing both efficient context summarization and high-resolution recall. The overall architecture leverages this design by stacking the efficient modules, leading to improved performance across various tasks.
read the caption
Figure 4: (a) The overall architecture of our Hymba model; (b) The building block of Hymba.

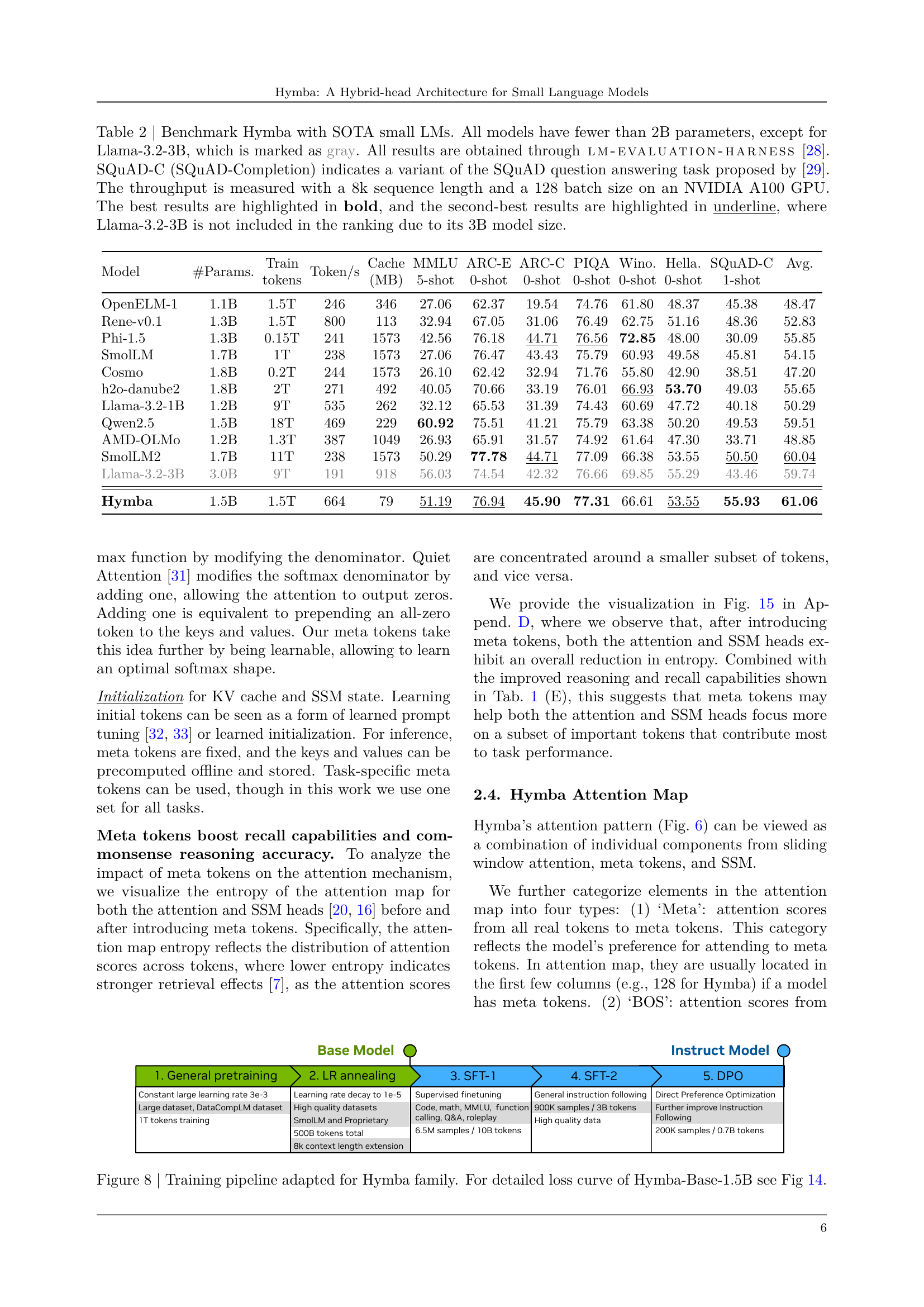
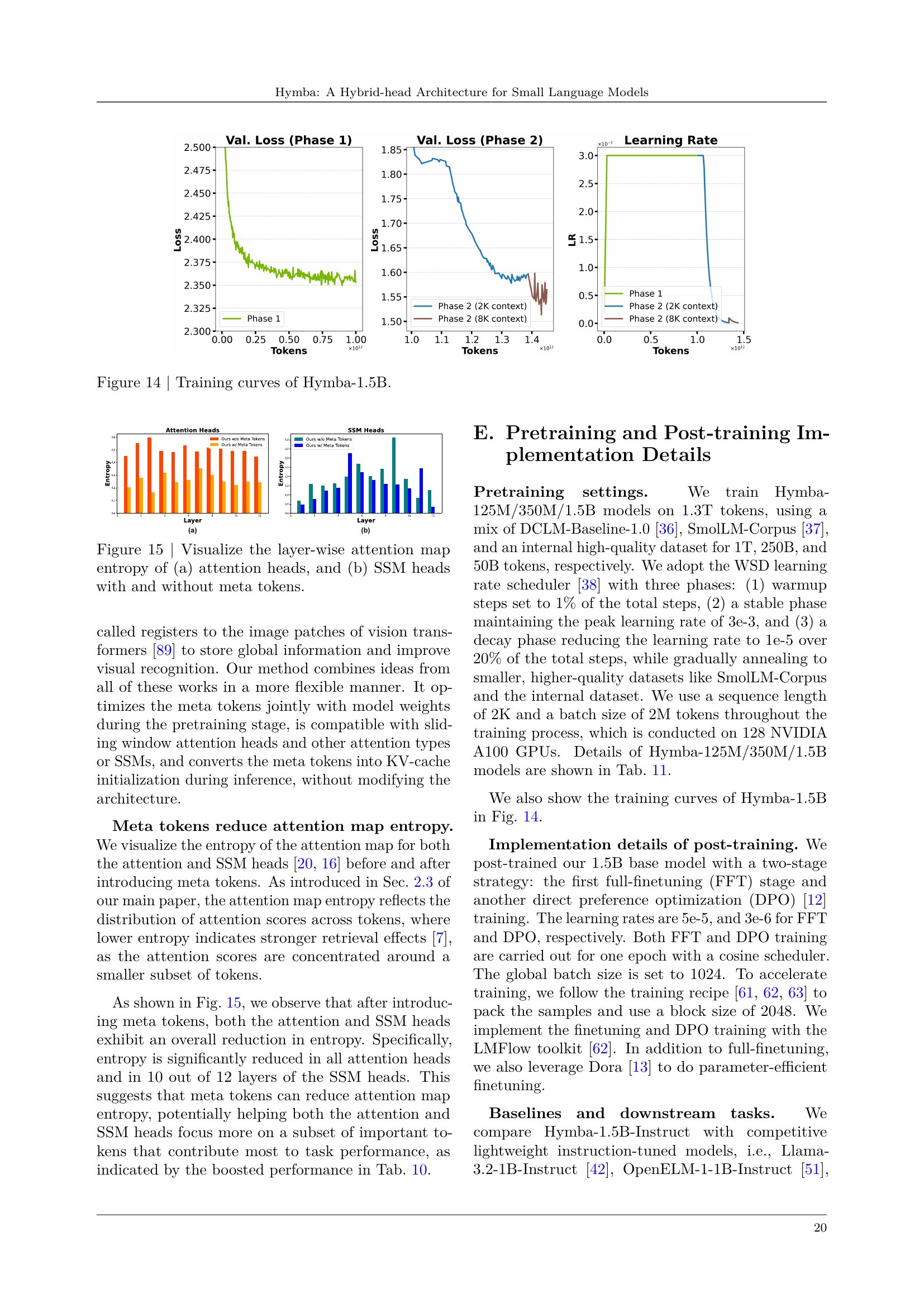
🔼 This figure displays the average attention scores given to each meta token in the final layer of the Hymba-1.5B model. The attention scores are averaged across multiple inputs, each starting with a different prompt type from three distinct datasets: SQuAD (for article prompts), GSM8K (for math prompts), and GitHub-Code (for code prompts). The visualization shows how different prompts elicit varied attention patterns among the meta tokens, suggesting that these tokens learn to represent different aspects of knowledge relevant to the given task.
read the caption
Figure 5: Averaged attention scores received by the meta tokens in the last layer of Hymba-1.5B model. Prompts of ‘Article’, ‘Math’ and ‘Code’ are from SQuAD [24], GSM8K [25], and GitHub-Code [26] datasets, respectively.

🔼 This figure illustrates the attention mechanism in Hymba, highlighting how meta tokens, sliding window attention, and Mamba (state space model) components interact. It shows a schematic representation of the attention map, visually demonstrating the contributions of each component to the overall attention process. The different colors or shading likely represent the strength of attention weights, showing how information flows through the model. By visualizing the attention map in this way, the figure helps explain how Hymba combines the strengths of high-resolution attention with efficient context summarization from the state space model, ultimately improving performance.
read the caption
Figure 6: Schematics of the attention map of Hymba as a combination of meta tokens, sliding window attention, and Mamba contributions.

🔼 This figure compares the attention patterns of three different language models: Llama-3.2-3B, Jamba, and Hymba-1.5B. It breaks down the attention scores into four categories: ‘Meta’ (attention to the added meta tokens), ‘BOS’ (attention to the beginning-of-sequence token), ‘Self’ (attention to the same token), and ‘Cross’ (attention to other tokens). The visualization helps to illustrate how the models allocate attention differently. Hymba’s parallel architecture of combining attention and state-space model (SSM) heads leads to a more balanced and less concentrated attention distribution, as opposed to Llama’s strong focus on the BOS token and Jamba’s intermediate approach. The differences highlight Hymba’s improved ability to disentangle attention.
read the caption
Figure 7: Sum of attention score from different categories (i.e., ‘Meta’, ‘BOS’, ‘Self’, ‘Cross’) in Llama-3.2-3B, Jamba and Hymba-1.5B. Parallel SSM and Attention fusion in the latter disentangles attention.

🔼 This figure illustrates the training pipeline used to develop the Hymba family of language models. It highlights the key stages involved in creating both the base and instruct versions of the models. The process starts with general pretraining on a large dataset and proceeds through learning rate annealing, supervised fine-tuning (SFT) in two phases, and direct preference optimization (DPO). This pipeline enables the creation of models that perform well across a range of tasks, as shown by the detailed loss curve for the Hymba-Base-1.5B model in Figure 14.
read the caption
Figure 8: Training pipeline adapted for Hymba family. For detailed loss curve of Hymba-Base-1.5B see Fig 14.

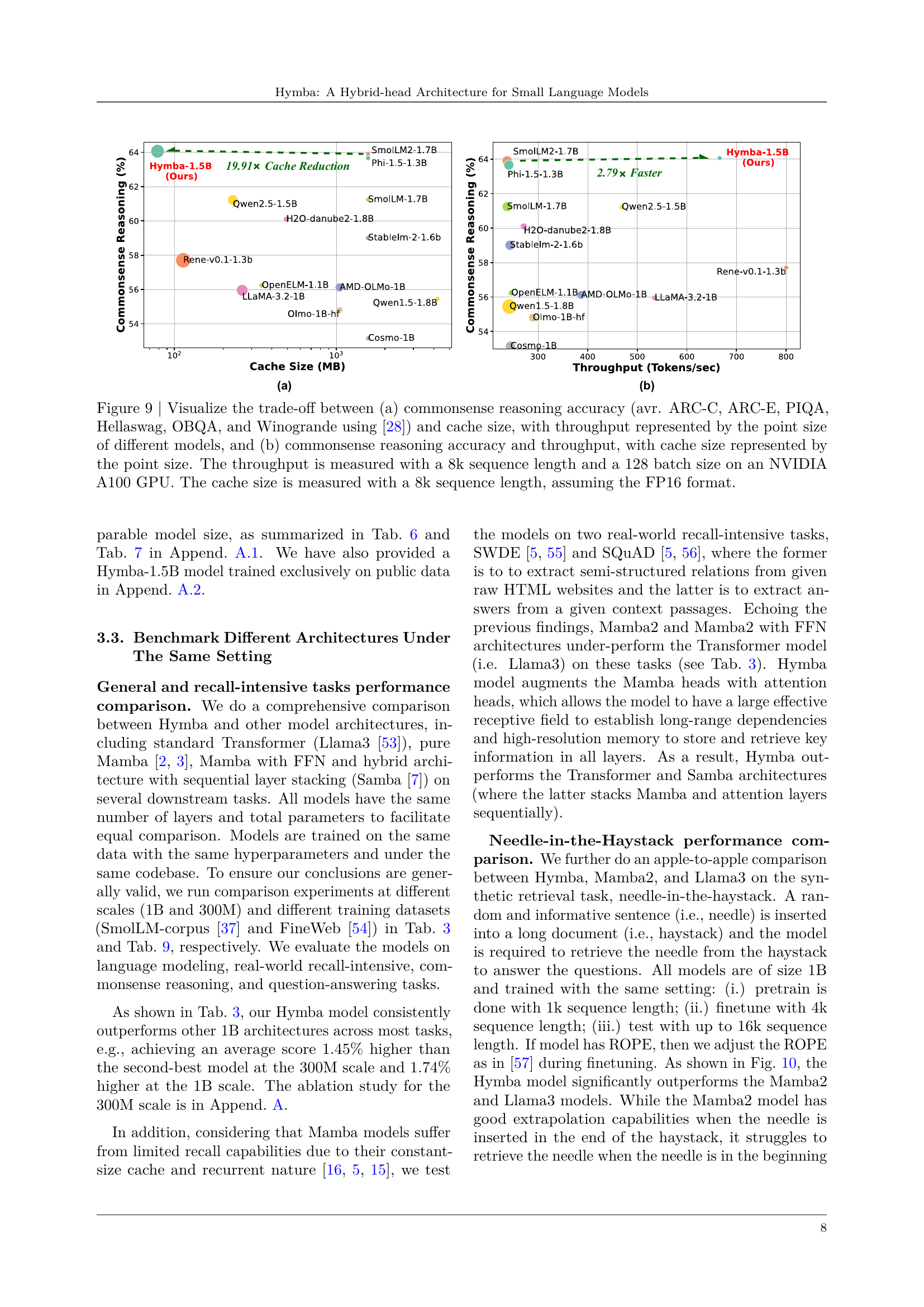
🔼 Figure 9 presents a comparison of various language models’ performance in commonsense reasoning tasks, illustrating the trade-off between accuracy and resource efficiency. Subfigure (a) shows the relationship between accuracy and cache size, where the size of the data points represents the throughput of each model. Subfigure (b) displays the relationship between accuracy and throughput, with point size indicating cache size. All measurements were taken using an 8k sequence length and a 128 batch size on an NVIDIA A100 GPU. The cache size is based on FP16 format.
read the caption
Figure 9: Visualize the trade-off between (a) commonsense reasoning accuracy (avr. ARC-C, ARC-E, PIQA, Hellaswag, OBQA, and Winogrande using [28]) and cache size, with throughput represented by the point size of different models, and (b) commonsense reasoning accuracy and throughput, with cache size represented by the point size. The throughput is measured with a 8k sequence length and a 128 batch size on an NVIDIA A100 GPU. The cache size is measured with a 8k sequence length, assuming the FP16 format.

🔼 Figure 10 presents a comparison of the performance of different language models on a synthetic ’needle-in-the-haystack’ task, where the goal is to locate a specific sentence within a longer document. The models compared are Hymba, Mamba2, and Llama3, all trained under identical conditions (apple-to-apple). The x-axis represents the length of the input sequence (document), showing how the model performs as the sequence length increases. The vertical white line at 4k tokens indicates the sequence length used during the finetuning phase. The graph likely shows the models’ ability to extrapolate to longer sequences beyond what they saw during training. The purpose is to assess the models’ ability to maintain performance when faced with a large context, highlighting differences in the recall capabilities and extrapolation performance of the various architectures.
read the caption
Figure 10: Needle-in-the-haystack performance comparison across different architecture under apple-to-apple setting. The white vertical line represents the finetuning sequence length (4k).

🔼 Figure 11 shows the relationship between effective receptive field (ERF) and cache size for different language model architectures. ERF is a measure of how far information can effectively propagate within a model. The figure compares models with various designs, including the proposed Hymba model (parallel fusion), a sequential fusion model like Samba, Llama3 (Transformer with global attention), and Mamba (a State Space Model with constant size cache). The x-axis represents cache size, while the y-axis represents ERF. It demonstrates the superior performance of the Hymba architecture’s parallel fusion approach that achieves a high ERF while maintaining a cache size comparable to the sequential fusion model. This indicates the parallel design is more efficient in terms of memory usage and information propagation compared to the other architectures.
read the caption
Figure 11: Visualize the ERF and cache size trade-off.

🔼 Figure 12 presents a comparative analysis of the output magnitudes and gate magnitudes for both attention heads and SSM heads across different layers of the Hymba model. The left panel shows that SSM heads consistently exhibit larger output magnitudes compared to attention heads, a characteristic attributed to their inherent structural differences. The right panel demonstrates how the relative magnitudes of the gates for both attention and SSM heads dynamically change across various layers during the model’s learning process. This visualization highlights the interplay and complementary roles of attention and SSM mechanisms within the Hymba architecture.
read the caption
Figure 12: Left: visualization of output magnitudes of attention and SSM heads. SSM heads consistently have higher output magnitude than attention heads due to their structure. Right: visualization of attention and SSM heads’ gate magnitudes. Through model learning, the relative magnitudes of attention and SSM gates vary across different layers.

🔼 This figure displays ablation study results showing the impact of removing either attention heads or SSM heads on three different tasks. The x-axis represents the layer number. The y-axis represents the performance change (difference) relative to a baseline model with all heads intact. Each bar represents a layer, with the height indicating the performance change when that layer’s attention or SSM head is removed. Note that some performance drops are so significant that the bars extend beyond the chart’s limits; these are annotated with text directly on the chart.
read the caption
Figure 13: Visualize the task performance difference across three tasks after removing the Attention or SSM heads in each layer. The task performance is measured using 1000 samples from each task. Note that removing critical modules in specific layers causes a significant gap compared to others, making their bars fall outside the box. For such layers, we annotate the task performance with text.

🔼 This figure shows the training curves for the Hymba-1.5B model. It displays the validation loss and learning rate over the course of the training process. The training process is divided into two phases, each with a different context length (2K tokens and 8K tokens). The plot shows how the validation loss changes over the training epochs, indicating the model’s performance during training, and how the learning rate is adjusted during these phases.
read the caption
Figure 14: Training curves of Hymba-1.5B.
More on tables
| Design | |
|---|---|
| Factor |
🔼 This table compares the performance of the Hymba-1.5B language model against other state-of-the-art (SOTA) small language models. It includes metrics such as average task accuracy across various benchmarks (MMLU, ARC-E, ARC-C, PIQA, Winogrande, Hellaswag, and SQUAD-C), cache size (in MB), and throughput (tokens per second). The comparison highlights Hymba’s performance advantages in terms of accuracy, efficiency (cache size and throughput), especially in comparison to models with similar parameter counts. Llama-3.2-3B, despite its superior performance, is excluded from the primary ranking due to exceeding the 2B parameter limit.
read the caption
Table 2: Benchmark Hymba with SOTA small LMs. All models have fewer than 2B parameters, except for Llama-3.2-3B, which is marked as gray. All results are obtained through lm-evaluation-harness [28]. SQuAD-C (SQuAD-Completion) indicates a variant of the SQuAD question answering task proposed by [29]. The throughput is measured with a 8k sequence length and a 128 batch size on an NVIDIA A100 GPU. The best results are highlighted in bold, and the second-best results are highlighted in underline, where Llama-3.2-3B is not included in the ranking due to its 3B model size.
| Param. Ratio | |
|---|---|
| Attn:Mamba |
🔼 This table presents a detailed comparison of five different language model architectures, all with 1 billion parameters. The models are: Hymba (the authors’ proposed model), pure Mamba2, Mamba2 with feed-forward networks (FFN), Llama3, and Samba (a hybrid architecture). All models were trained from scratch using the same dataset (SmolLM-Corpus) and training process for 100 billion tokens. The models are evaluated using zero-shot settings on various tasks through HuggingFace’s
lm-evaluation-harness, measuring their performance on language modeling, recall-intensive tasks, commonsense reasoning, and question answering. The best and second-best performing models for each task are highlighted.read the caption
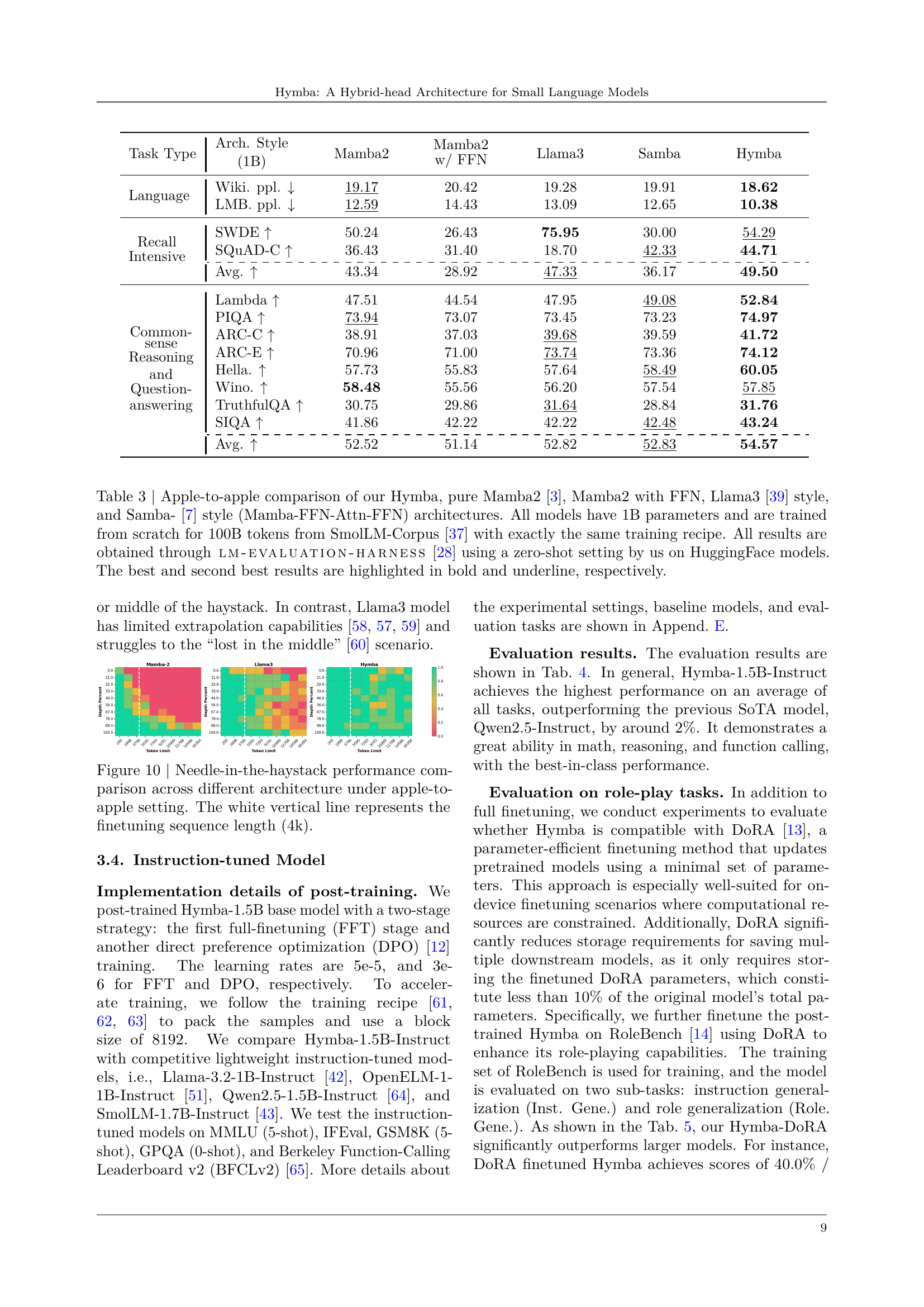
Table 3: Apple-to-apple comparison of our Hymba, pure Mamba2 [3], Mamba2 with FFN, Llama3 [39] style, and Samba- [7] style (Mamba-FFN-Attn-FFN) architectures. All models have 1B parameters and are trained from scratch for 100B tokens from SmolLM-Corpus [37] with exactly the same training recipe. All results are obtained through lm-evaluation-harness [28] using a zero-shot setting by us on HuggingFace models. The best and second best results are highlighted in bold and underline, respectively.
| Avg. | |
|---|---|
| (General) ↑ |
🔼 This table compares the performance of several lightweight instruction-tuned language models on various downstream tasks. The models are evaluated on their ability to perform instruction following and function calling. Note that OpenELM and SmolLM models do not support function calling, resulting in zero accuracy for those categories. The best and second-best results for each task are highlighted.
read the caption
Table 4: The comparison between lightweight instruction-tuned models. The best and second-best results are highlighted in bold and underlined, respectively. ∗ OpenELM and SmolLM cannot understand function calling, leading to 0 accuracy in most categories.
| Avg. | |
|---|---|
| (Recall) ↑ |
🔼 This table presents a comparison of the performance of a DoRA (Direct Preference Optimization)-finetuned Hymba 1.5B model against several baseline models on the RoleBench benchmark. RoleBench is a dataset designed to evaluate the capabilities of language models in role-playing scenarios. The table likely shows metrics such as accuracy or other relevant performance measures on specific role-playing tasks within RoleBench. The baseline models are presumably other LLMs, some potentially much larger than Hymba, making the comparison interesting in terms of parameter efficiency and performance.
read the caption
Table 5: The comparison between DoRA-finetuned Hymba and baselines on RoleBench. All baseline results are from [14].
| Throughput | |
|---|---|
| (Token/s) ↑ |
🔼 This table compares the performance of Hymba-125M against other state-of-the-art (SOTA) small language models with fewer than 200 million parameters. The models are evaluated on several downstream tasks using the Huggingface/LightEval benchmark, following the methodology described in Ben Allal et al. [43]. The table shows the performance of each model across various tasks, providing a comprehensive comparison of Hymba-125M against its competitors.
read the caption
Table 6: Benchmark Hymba with SOTA tiny LMs, all of which have fewer than 200M parameters. All results are obtained through Huggingface/LightEval, following Ben Allal et al. [43].
| Cache | (MB) ↓ |
|---|
🔼 This table compares the performance of Hymba language models (specifically, the 125M and 350M parameter versions) against other state-of-the-art (SOTA) tiny language models on various benchmark tasks. The comparison focuses on models with fewer than 400M parameters. The results are obtained using the Huggingface/LightEval framework, following the methodology outlined by Ben Allal et al. [43]. The benchmark tasks evaluate performance across different aspects of language understanding including commonsense reasoning, question answering, and recall-intensive tasks.
read the caption
Table 7: Benchmark Hymba with SOTA tiny LMs, all of which have fewer than 400M parameters. All results are obtained through Huggingface/LightEval, following Ben Allal et al. [43].
| Attribute | 125M | 350M | 1.5B |
|---|---|---|---|
| Blocks | 24 | 32 | 32 |
| Hidden Size | 512 | 768 | 1600 |
| SSM State | 16 | 16 | 16 |
| Attn. Heads | 8 | 12 | 25 |
| Query Groups | 4 | 4 | 5 |
| Num. Full Attn | 3 | 3 | 3 |
| Window Size | 1024 | 1024 | 1024 |
| MLP Hidden | 1664 | 2432 | 5504 |
| Tie Embedding | True | True | True |
| Parameters | 125M | 350M | 1.52B |
🔼 This table compares the performance of the Hymba-1.5B language model trained on both public and private datasets against other state-of-the-art (SOTA) small language models. It specifically focuses on models with fewer than 2 billion parameters, except for Llama-3.2-3B which is included for comparative purposes and highlighted as an exception. The evaluation metrics include average task accuracy across several benchmarks (5-shot MMLU, ARC-E, ARC-C, PIQA, Winogrande, HellaSwag, and SQUAD-C), cache size, and throughput. The table highlights the performance difference between Hymba trained on its proprietary, high-quality dataset and a version trained exclusively on publicly available datasets, illustrating the impact of data quality on model performance.
read the caption
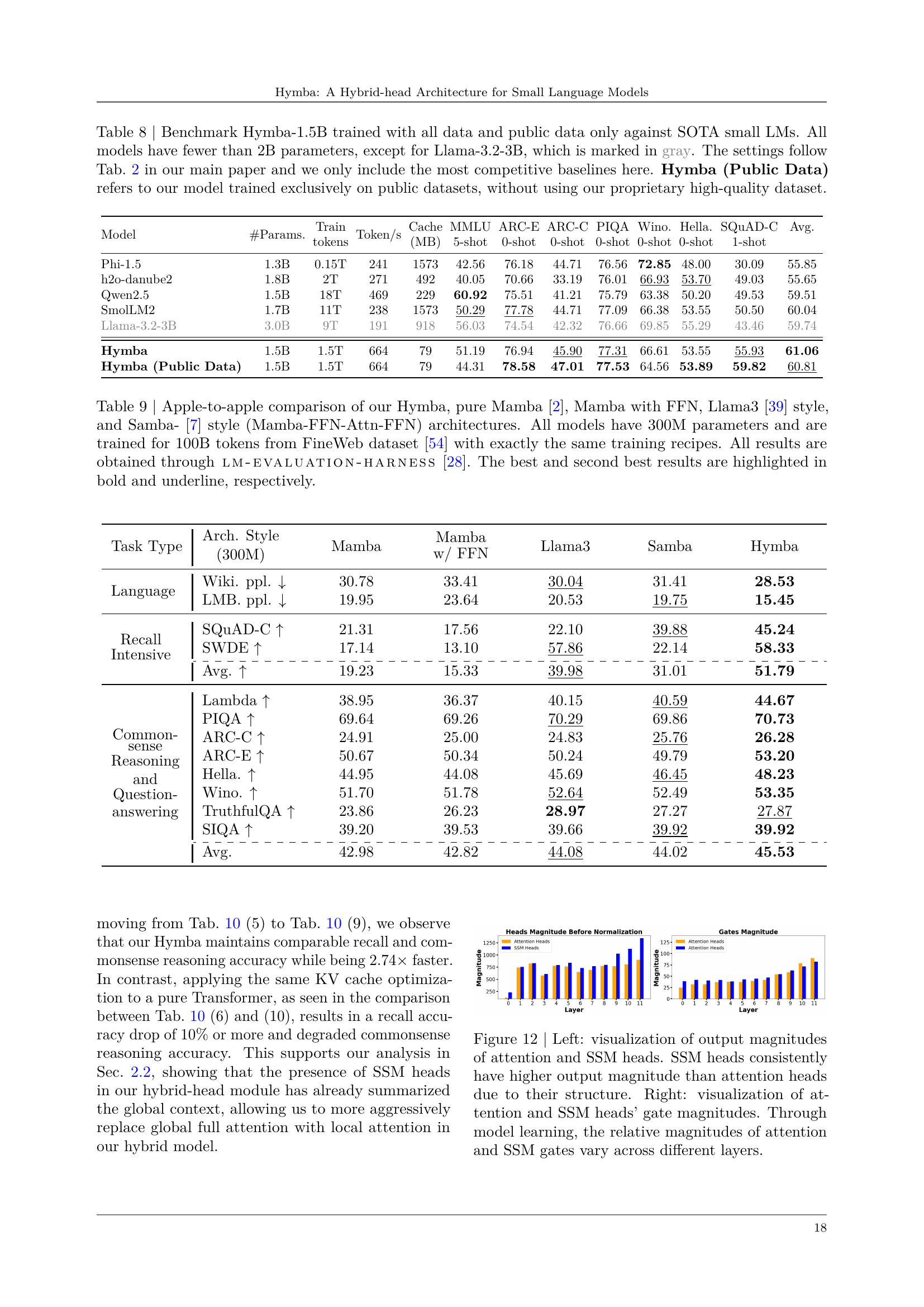
Table 8: Benchmark Hymba-1.5B trained with all data and public data only against SOTA small LMs. All models have fewer than 2B parameters, except for Llama-3.2-3B, which is marked in gray. The settings follow Tab. 2 in our main paper and we only include the most competitive baselines here. Hymba (Public Data) refers to our model trained exclusively on public datasets, without using our proprietary high-quality dataset.
Full paper#