↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) struggle with low-resource languages due to limited training data, making adaptation expensive and resource-intensive. This significantly hinders research and development efforts in these crucial language communities. Current methods often rely on extensive computational power, making them inaccessible to many researchers.
This paper introduces UnifiedCrawl, a method to efficiently collect and process significantly larger amounts of text data for low-resource languages from Common Crawl. Using minimal computational resources and QLoRA (Quantized Low-Rank Adaptation), they fine-tune multilingual LLMs, achieving substantial performance gains on various tasks. This work democratizes LLM adaptation for low-resource languages by making it more accessible and cost-effective using consumer-grade hardware.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UnifiedCrawl, a novel method for efficiently collecting and processing large text datasets for low-resource languages. This addresses a significant bottleneck in large language model (LLM) adaptation and is crucial for advancing NLP research in under-resourced language communities. The efficient data collection, coupled with the use of QLoRA, makes LLM fine-tuning accessible to researchers with limited computational resources, opening up new avenues for research and development.
Visual Insights#

🔼 This figure illustrates the overall process of the proposed method. It starts with collecting data using UnifiedCrawl, which filters and extracts relevant data from the Common Crawl corpus. Then, a pre-trained multilingual language model is fine-tuned using an efficient adapter method (QLORA) on the data generated from UnifiedCrawl. Finally, this fine-tuned model is used for downstream tasks such as few-shot prompting.
read the caption
Figure 1: High-Level Overview of our Method
| Language (ISO) | Fraction of CC | # Speakers(M) | Geographical Region |
|---|---|---|---|
| Hausa (hau) | 0.0036% | 80 | Nigeria, Chad, Cameroon, Ghana |
| Pashto (pus) | 0.0033% | 60 | Afghanistan, Pakistan |
| Amharic (amh) | 0.0036% | 60 | Ethiopia |
| Yoruba (yor) | 0.0011% | 50 | Benin, Nigeria, Togo |
| Sundanese (sun) | 0.0011% | 40 | Indonesia |
| Sindhi (snd) | 0.0017% | 30 | Pakistan, India |
| Zulu (zul) | 0.0016% | 30 | South Africa, Lesotho |
🔼 This table lists seven low-resource languages selected for data collection and evaluation in the paper. For each language, it provides its ISO code, the approximate fraction of its presence in the Common Crawl dataset (specifically the CC-MAIN-2023-14 archive), the estimated number of speakers in millions, and the geographical regions where these languages are primarily spoken.
read the caption
Table 1: Details of 7 languages used for Data Collection Evaluation
In-depth insights#
LLM Low-Resource#
The concept of “LLM Low-Resource” highlights a critical challenge in the field of large language models (LLMs): their underperformance on languages with limited data. While LLMs excel with abundant data, their capabilities drastically diminish when applied to low-resource languages, often producing incoherent or nonsensical outputs. This limitation stems from the fact that most LLMs are trained primarily on high-resource languages like English, creating a significant bias. The scarcity of training data for low-resource languages directly impacts the models’ ability to learn the nuances of these languages, leading to poor generalization and reduced accuracy. Addressing this necessitates innovative approaches to data acquisition and model adaptation, focusing on efficient methods for collecting and utilizing limited data to enhance performance and promote linguistic inclusivity. UnifiedCrawl, as presented in the research paper, offers a promising solution by efficiently aggregating data from the Common Crawl corpus, which potentially addresses this issue.
UnifiedCrawl Method#
The UnifiedCrawl method presents a novel approach to address the challenges of data scarcity in low-resource languages for Large Language Model (LLM) training. Its core innovation lies in efficiently filtering and extracting monolingual corpora from the massive Common Crawl dataset using minimal computational resources. This is achieved through a multi-stage pipeline: first, leveraging DuckDB for in-memory filtering of the Common Crawl index to select relevant language shards; second, employing optimized HTTP Range Requests to download only necessary WARC files; third, utilizing Trafilatura for efficient text extraction from HTML sources; and finally, applying substring deduplication to enhance data quality. The method’s efficiency is remarkable, enabling the processing of the entire Common Crawl dataset using only consumer-grade hardware and modest storage. This makes affordable adaptation of LLMs to low-resource languages feasible, a significant step towards democratizing access to advanced AI capabilities. The resulting UnifiedCrawl dataset is shown to be significantly larger than previously available resources, providing crucial training data for improved performance of LLMs on previously underserved languages.
QLORA Fine-tuning#
The concept of “QLORA Fine-tuning” centers on efficiently adapting large language models (LLMs) for low-resource languages. Traditional fine-tuning of LLMs is computationally expensive, requiring substantial GPU memory and time. QLORA, or Quantized Low-Rank Adaptation, addresses this limitation by using quantization to reduce the memory footprint of LLMs and employing low-rank adapters to only train a small subset of parameters. This approach significantly minimizes VRAM usage, making it feasible to fine-tune large models on consumer-grade hardware. The paper highlights how this method leads to improved performance on low-resource languages, as demonstrated by reduced perplexity scores and enhanced performance in few-shot prompting tasks. QLORA’s efficiency is particularly crucial for adapting LLMs to languages with limited training data, offering a cost-effective and accessible solution for expanding the reach of AI to a broader range of linguistic communities.
Dataset Extraction#
The process of dataset extraction is a crucial step in the research paper, focusing on efficiently acquiring textual data from the Common Crawl corpus for low-resource languages. The researchers cleverly leverage the Common Crawl’s index to filter relevant data, minimizing resource usage. DuckDB, an in-memory database, is employed to efficiently filter this massive index, which is particularly important given the scale of the Common Crawl. They further optimize the process through multiprocessing, distributing the work across multiple CPU cores to accelerate data acquisition. The careful selection of WARC files using HTTP range requests is another key element, downloading only the necessary sections for their chosen languages. This method minimizes both bandwidth consumption and storage needs, enabling the entire process to run on consumer-grade hardware. Finally, text is extracted from downloaded WARC files, utilizing Trafilatura, a tool designed to efficiently extract text from HTML content, and substring deduplication is applied to enhance the quality and efficiency of the final dataset. Overall, their approach demonstrates an innovative, efficient, and cost-effective method of extracting vast amounts of monolingual data for low-resource languages, making it accessible for researchers with limited resources.
Future Directions#
The research paper’s ‘Future Directions’ section would ideally delve into expanding the data collection pipeline to encompass more low-resource languages, addressing the current limitations of time and storage. Improving data quality and diversity through enhanced extraction methods is crucial. Exploration of alternative model architectures like BLOOM and mT5 during fine-tuning warrants investigation to potentially enhance performance. A more comprehensive evaluation across diverse downstream tasks is also needed to validate real-world performance gains. Finally, developing a robust technique capable of effectively broadening access to LLMs for low-resource languages should be a significant focus. This includes addressing the challenges of democratizing AI and achieving inclusivity in natural language processing.
More visual insights#
More on figures

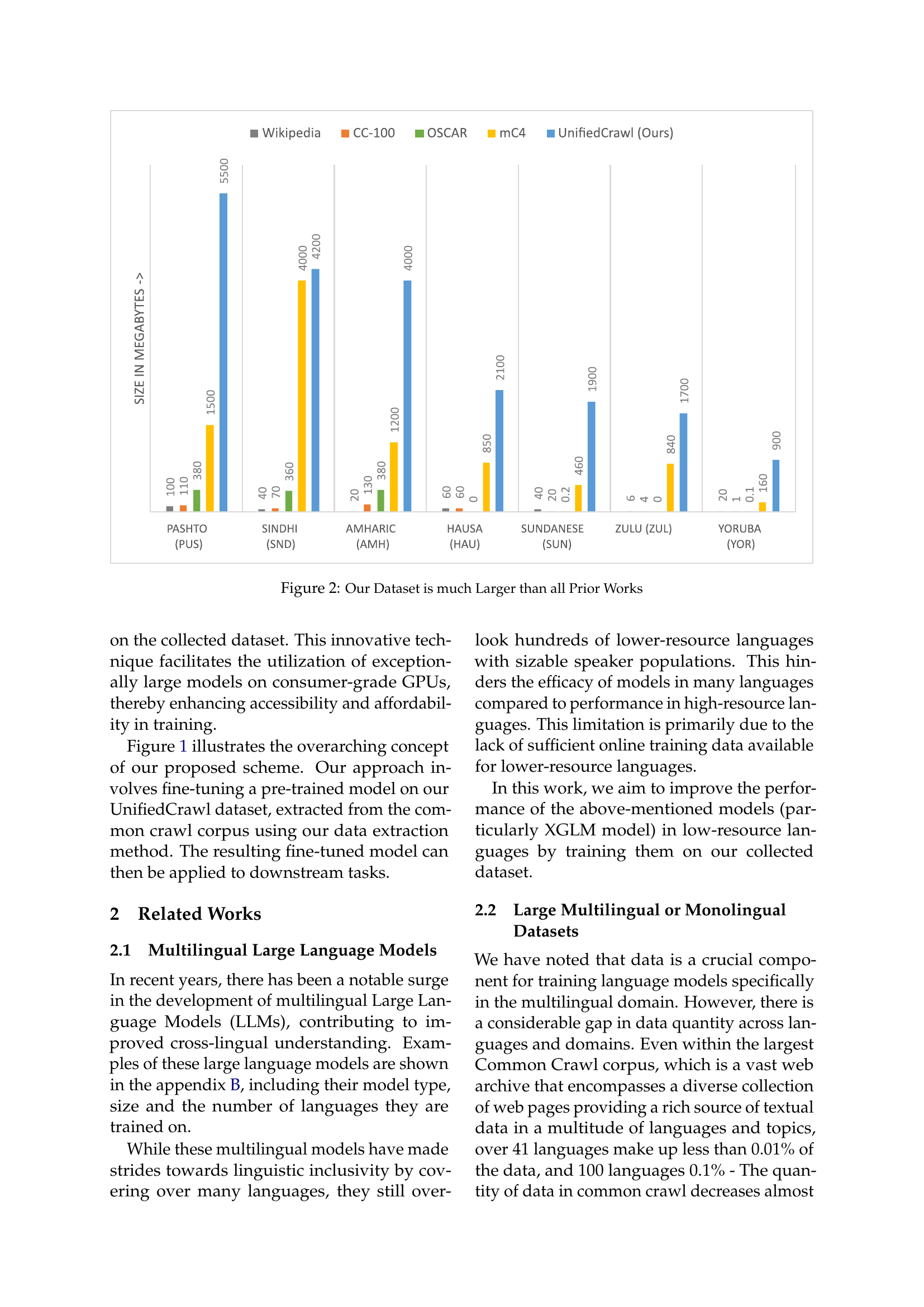
🔼 This figure compares the sizes of the dataset created by the authors (UnifiedCrawl) and other existing datasets for various low-resource languages. The bar chart visually represents the size of each dataset in megabytes. It highlights the significant advantage of UnifiedCrawl, which is substantially larger than datasets such as Wikipedia, CC-100, OSCAR, and mC4 for the selected languages (Pashto, Sindhi, Amharic, Hausa, Sundanese, Zulu, Yoruba). This demonstrates the substantial increase in training data available for low-resource languages, which is a crucial aspect of the paper.
read the caption
Figure 2: Our Dataset is much Larger than all Prior Works

🔼 This figure illustrates the data extraction framework of UnifiedCrawl. It starts by filtering the Common Crawl index using DuckDB for a specific low-resource language. It then extracts relevant WARC files using HTTP Range Requests to reduce storage and download time. The HTML contents are extracted using the WARCIO and Trafilatura libraries. Finally, a substring deduplication step removes redundancy. The resulting deduplicated text forms the UnifiedCrawl dataset.
read the caption
Figure 3: UnifiedCrawl: Data Extraction Framework
More on tables
| Languages (ISO) | Size | Max Size |
|---|---|---|
| Hausa (hau) | 2.1 | 7 |
| Pashto (pus) | 5.5 | 20 |
| Amharic (amh) | 4.0 | 24 |
| Yoruba (yor) | 0.9 | 2 |
| Sundanese (sun) | 1.9 | 6 |
| Sindhi (snd) | 4.2 | 15 |
| Zulu (zul) | 1.7 | 6 |
🔼 This table presents the sizes of the UnifiedCrawl datasets for seven different low-resource languages. The ‘Size’ column indicates the size of the dataset containing only the specified language, while the ‘Max Size’ column provides an estimated upper bound on the dataset size if documents containing multiple languages are included. The sizes are given in gigabytes (GB).
read the caption
Table 2: UnifiedCrawl-Language Dataset Size. The Size and Max Size are in GBs
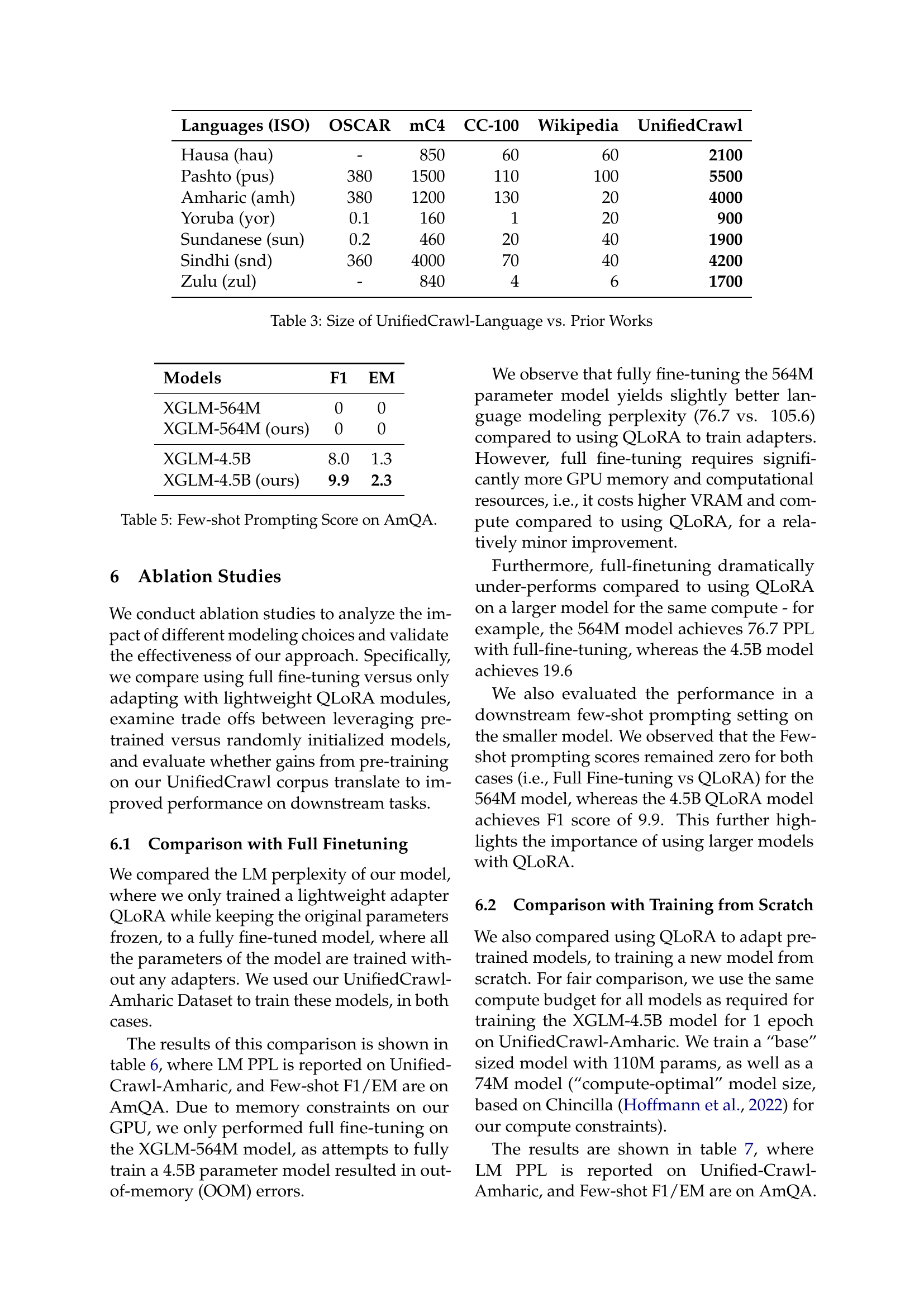
| Languages (ISO) | OSCAR | mC4 | CC-100 | Wikipedia | UnifiedCrawl |
|---|---|---|---|---|---|
| Hausa (hau) | - | 850 | 60 | 60 | 2100 |
| Pashto (pus) | 380 | 1500 | 110 | 100 | 5500 |
| Amharic (amh) | 380 | 1200 | 130 | 20 | 4000 |
| Yoruba (yor) | 0.1 | 160 | 1 | 20 | 900 |
| Sundanese (sun) | 0.2 | 460 | 20 | 40 | 1900 |
| Sindhi (snd) | 360 | 4000 | 70 | 40 | 4200 |
| Zulu (zul) | - | 840 | 4 | 6 | 1700 |
🔼 This table compares the size of the UnifiedCrawl dataset for several low-resource languages to the size of other commonly used datasets in prior works, such as OSCAR, mC4, CC-100, and Wikipedia. The size of each dataset is presented in Megabytes (MB). It highlights the significantly larger scale of the UnifiedCrawl dataset compared to existing resources for the same low-resource languages.
read the caption
Table 3: Size of UnifiedCrawl-Language vs. Prior Works
| Models | PPL |
|---|---|
| XGLM-564M | 14,974.70 |
| XGLM-564M (ours) | 105.5 |
| XGLM-4.5B | 35.6 |
| XGLM-4.5B (ours) | 19.6 |
🔼 This table presents the results of language modeling evaluation on the Amharic language. It compares the perplexity (PPL) scores of the original XGLM-564M and XGLM-4.5B models with their counterparts fine-tuned using QLoRA on the UnifiedCrawl-Amharic dataset. Lower perplexity indicates better performance in predicting the next word in a sequence.
read the caption
Table 4: Language Modeling Evaluation on Amharic
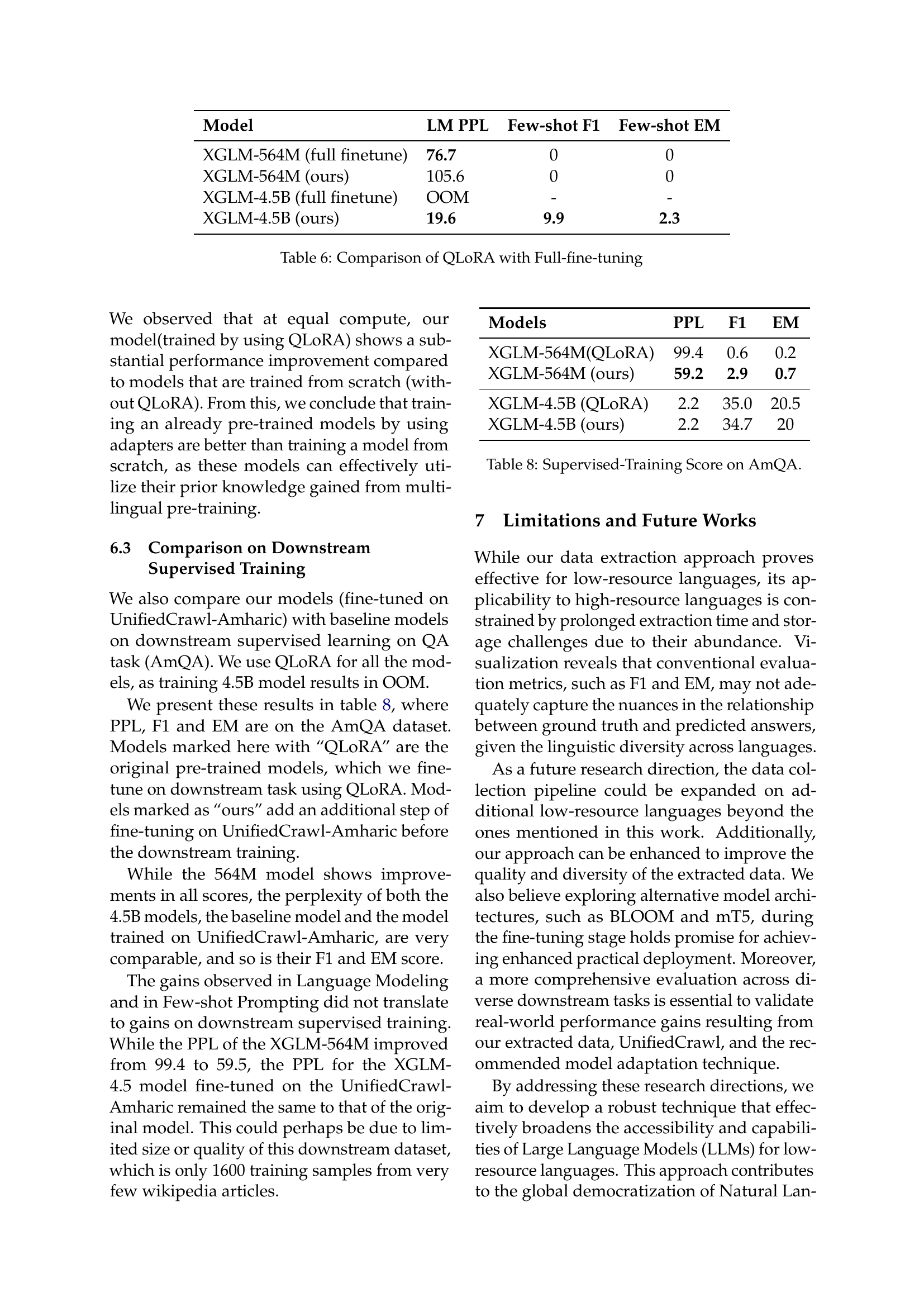
| Models | F1 | EM |
|---|---|---|
| XGLM-564M | 0 | 0 |
| XGLM-564M (ours) | 0 | 0 |
| XGLM-4.5B | 8.0 | 1.3 |
| XGLM-4.5B (ours) | 9.9 | 2.3 |
🔼 This table presents the results of few-shot prompting on the Amharic Question Answering (AmQA) dataset. It compares the performance of several XGLM models, both original and fine-tuned using QLoRA on the UnifiedCrawl-Amharic dataset. The results are measured using F1 and Exact Match (EM) scores, common metrics for evaluating question answering performance.
read the caption
Table 5: Few-shot Prompting Score on AmQA.
| Model | LM PPL | Few-shot F1 | Few-shot EM |
|---|---|---|---|
| XGLM-564M (full finetune) | 76.7 | 0 | 0 |
| XGLM-564M (ours) | 105.6 | 0 | 0 |
| XGLM-4.5B (full finetune) | OOM | - | - |
| XGLM-4.5B (ours) | 19.6 | 9.9 | 2.3 |
🔼 This table compares the performance of using the QLoRA method (Quantized Low-Rank Adaptation) versus full fine-tuning for training large language models. It shows the Language Modeling Perplexity (LM PPL) on the UnifiedCrawl-Amharic dataset and the few-shot prompting F1 and EM scores on the AmQA (Amharic Question Answering) dataset for both XGLM-564M and XGLM-4.5B models. The results highlight the trade-off between model size, training method, and performance.
read the caption
Table 6: Comparison of QLoRA with Full-fine-tuning
| Model | LM PPL | Few-shot F1 | Few-shot EM |
|---|---|---|---|
| GPT2-74M (scratch) | 105.2 | 1.2 | 0 |
| GPT2-110M (scratch) | 106.1 | 1.3 | 0 |
| XGLM-4.5B (Ours) | 19.6 | 9.9 | 2.3 |
🔼 This table compares the performance of fine-tuning a pre-trained language model using the QLoRA method against training a model from scratch. It shows the language modeling perplexity (LM PPL) on the Amharic language dataset and the few-shot prompting F1 and EM scores on the AmQA Question Answering dataset for different model sizes. The results highlight the efficiency and effectiveness of QLoRA in achieving comparable or better performance with significantly reduced computational resources.
read the caption
Table 7: Comparison of QLoRA with training from scratch
| Models | PPL | F1 | EM |
|---|---|---|---|
| XGLM-564M (QLoRA) | 99.4 | 0.6 | 0.2 |
| XGLM-564M (ours) | 59.2 | 2.9 | 0.7 |
| XGLM-4.5B (QLoRA) | 2.2 | 35.0 | 20.5 |
| XGLM-4.5B (ours) | 2.2 | 34.7 | 20 |
🔼 This table presents the results of supervised training on the Amharic Question Answering (AmQA) dataset. It compares the performance of several models, including the original XGLM-564M and XGLM-4.5B models, and their respective counterparts fine-tuned using QLoRA on the UnifiedCrawl-Amharic dataset. The evaluation metrics used are Perplexity (PPL), F1 score, and Exact Match (EM) score, providing a comprehensive assessment of the models’ performance on a downstream question-answering task.
read the caption
Table 8: Supervised-Training Score on AmQA.
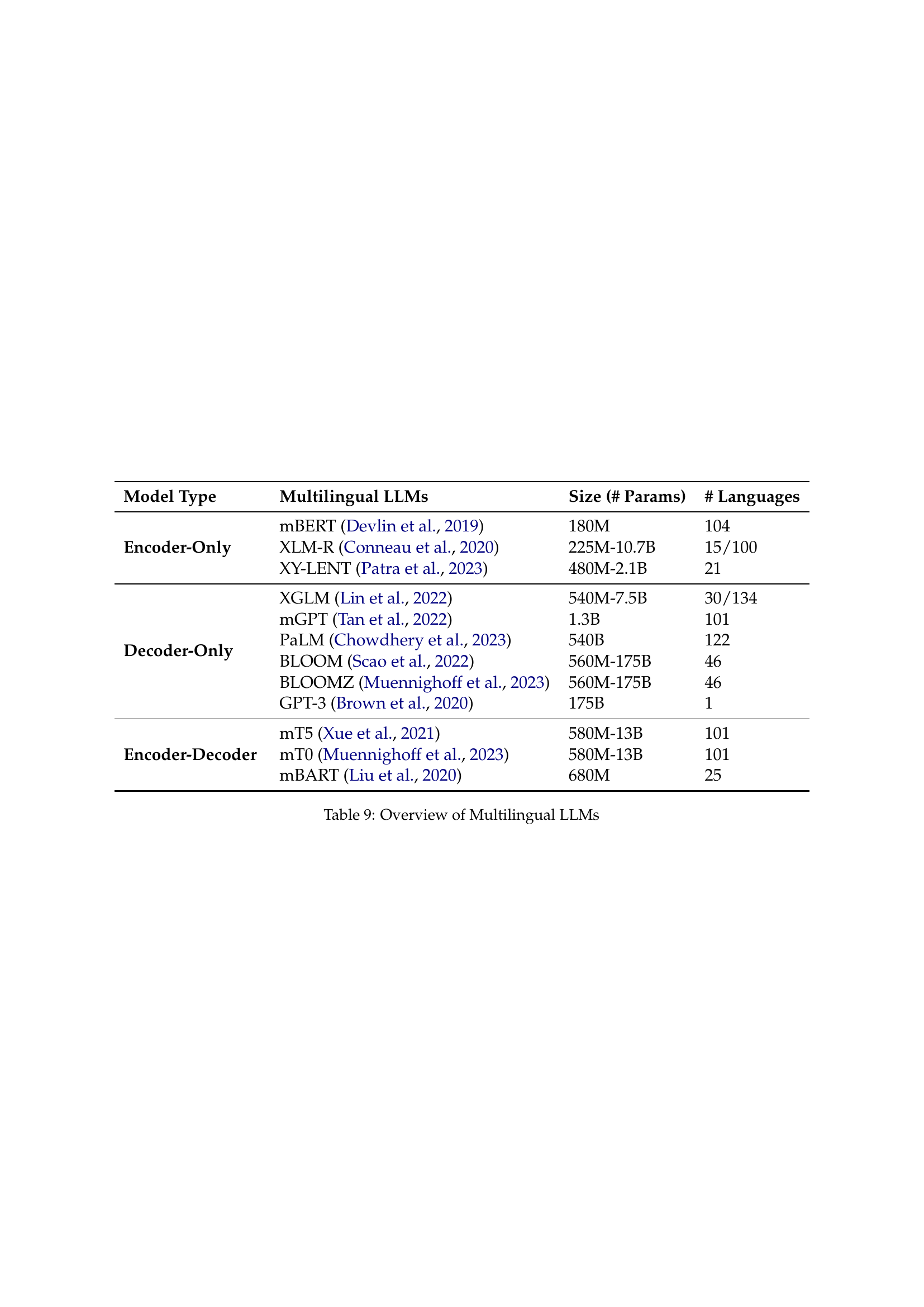
| Model Type | Multilingual LLMs | Size (# Params) | # Languages |
|---|---|---|---|
| Encoder-Only | mBERT Devlin et al. (2019) | 180M | 104 |
| XLM-R Conneau et al. (2020) | 225M-10.7B | 15/100 | |
| XY-LENT Patra et al. (2023) | 480M-2.1B | 21 | |
| Decoder-Only | XGLM Lin et al. (2022) | 540M-7.5B | 30/134 |
| mGPT Tan et al. (2022) | 1.3B | 101 | |
| PaLM Chowdhery et al. (2023) | 540B | 122 | |
| BLOOM Scao et al. (2022) | 560M-175B | 46 | |
| BLOOMZ Muennighoff et al. (2023) | 560M-175B | 46 | |
| GPT-3 Brown et al. (2020) | 175B | 1 | |
| Encoder-Decoder | mT5 Xue et al. (2021) | 580M-13B | 101 |
| mT0 Muennighoff et al. (2023) | 580M-13B | 101 | |
| mBART Liu et al. (2020) | 680M | 25 |
🔼 This table provides an overview of various multilingual Large Language Models (LLMs), categorized by their model type (Encoder-Only, Decoder-Only, or Encoder-Decoder), size (in number of parameters), and the number of languages they support. It showcases the diversity of approaches and scales in multilingual LLM development.
read the caption
Table 9: Overview of Multilingual LLMs
Full paper#