↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image editing methods using diffusion models often suffer from inconsistent results and lack diversity in generated images. The traditional UNet architecture’s coarse-to-fine structure is well understood for editing, but newer diffusion models employing the Diffusion Transformer (DiT) lack such structure, making it difficult to perform consistent image edits. Many methods need fine-tuning, which is time consuming.
The proposed method, Stable Flow, tackles this issue. It leverages the reduced diversity of flow-based DiT models to achieve consistent edits via selective injection of attention features into identified “vital layers.” This automated identification of vital layers, crucial for image formation, allows for various editing tasks (non-rigid, object manipulation, scene changes) using a single mechanism. The method also includes an improved real-image inversion technique, addressing previous limitations in applying this method to real-world images.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel training-free method for image editing using diffusion models. It addresses the limitations of existing methods by leveraging the reduced diversity of flow-based models and introducing an automatic method to identify “vital layers” crucial for image formation. This work has significant implications for various creative applications and paves the way for future research in image manipulation.
Visual Insights#

🔼 This figure showcases the versatility of the Stable Flow method in performing various image editing tasks without any additional training. It demonstrates the method’s ability to seamlessly handle different editing styles such as non-rigid transformations (e.g., changing the pose of a dog), adding objects (e.g., placing a dog next to an avocado), removing objects (e.g., removing a plastic bag), and performing global scene edits (e.g., changing the scene from daytime to nighttime). The consistent results across diverse edit types highlight the unified mechanism at the core of the Stable Flow approach.
read the caption
Figure 1: Stable Flow. Our training-free editing method is able to perform various types of image editing operations, including non-rigid editing, object addition, object removal, and global scene editing. These different edits are done using the same mechanism.
 |
|  |
|  |
|  |
| (2) FLUX [46] |
|
| (2) FLUX [46] |  |
|  |
|  |
|  |
| (3) Stable Flow |
|
| (3) Stable Flow |  |
|  |
|  |
|  |
| | “A photo of a | + “dog wearing | + “cat wearing | + “casting |
| | dog and a cat… | a blue hat | yellow glasses | shadows |
|
| | “A photo of a | + “dog wearing | + “cat wearing | + “casting |
| | dog and a cat… | a blue hat | yellow glasses | shadows |🔼 This table presents a quantitative comparison of different image editing methods, including the proposed ‘Stable Flow’ method and several baselines. The comparison is based on three metrics: text similarity (how well the generated image matches the text description), image similarity (how similar the generated image is to the original image), and image-text direction similarity (how well the changes in the image align with the changes specified in the text prompt). The results reveal that while some baselines show high text similarity, they often fall short in image and image-text direction similarity. In contrast, the Stable Flow method demonstrates superior performance in both image similarity and alignment between image and text changes.
read the caption
Table 1: Quantitative Comparison. We compare our method against the baselines in terms of text similarity (CLIPtxtsubscriptCLIP𝑡𝑥𝑡\text{CLIP}_{txt}CLIP start_POSTSUBSCRIPT italic_t italic_x italic_t end_POSTSUBSCRIPT), image similarity (CLIPimgsubscriptCLIP𝑖𝑚𝑔\text{CLIP}_{img}CLIP start_POSTSUBSCRIPT italic_i italic_m italic_g end_POSTSUBSCRIPT) and image-text direction similarity (CLIPdirsubscriptCLIP𝑑𝑖𝑟\text{CLIP}_{dir}CLIP start_POSTSUBSCRIPT italic_d italic_i italic_r end_POSTSUBSCRIPT). As can be seen, P2P+NTI [34, 53], Instruct-P2P [17], and MasaCTRL [18] suffer from low similarity to the text prompt. SDEdit [94] and MagicBrush [97] adhere more to the text prompt, but they struggle with image similarity and image-text direction similarity. Our method, on the other hand, achieves better image and image-text direction similarity.
In-depth insights#
Diffusion Model Edits#
Diffusion models, known for their impressive image generation capabilities, have recently become the focus of research for image editing. The core idea is leveraging the inherent properties of diffusion models to perform edits without the need for extensive retraining. This training-free approach offers significant advantages in terms of efficiency and flexibility. However, a key challenge lies in understanding and controlling the diffusion process to achieve specific and consistent edits. The success of diffusion-based editing hinges on identifying crucial layers or mechanisms within the diffusion model that are most receptive to external guidance, such as text prompts or masks. This selective manipulation allows for targeted alterations while preserving the integrity of other image regions. A promising avenue is exploring the limited diversity of some diffusion models; this characteristic, sometimes viewed as a limitation, can be leveraged to constrain the diffusion process and thus stabilize edits. Research efforts are focused on refining methods for identifying vital layers automatically and developing more sophisticated injection techniques to guide the diffusion trajectory, enabling finer control over the editing outcomes. The exploration of diverse editing operations, like non-rigid transformations, object addition, or global scene changes, adds further complexity and pushes the boundaries of training-free image manipulation.
Vital Layer Detection#
The concept of “Vital Layer Detection” in the context of diffusion models for image editing is crucial. The authors cleverly address the challenge of modifying diffusion transformer (DiT) models, which lack the clear coarse-to-fine structure of UNets. Identifying vital layers, those essential for image formation, is key to performing controlled edits without disrupting other parts of the image. The method proposed for this detection involves measuring the perceptual impact of bypassing each layer, which is a clever way to assess its importance. This approach is significant because it allows for the consistent injection of features into the model at the right level, enabling various editing operations including non-rigid editing, object replacement, and scene editing. The automation of the process makes this method highly practical and applicable to diverse applications. By focusing edits on the vital layers, the authors significantly improve the stability and quality of the output images. The technique essentially leverages the limited generation diversity inherent in flow-based models to its advantage. This is a significant advancement in training-free image editing, highlighting a novel understanding of and approach towards DiT models.
Training-Free Editing#
The concept of “Training-Free Editing” in the context of image manipulation using diffusion models is a significant advancement. It addresses the limitations of traditional methods that require extensive retraining for each new editing task. The core idea is to leverage the inherent properties of diffusion models, specifically their reduced diversity, to perform consistent and controlled edits without needing additional training. This is achieved by selectively injecting information from a reference image into specific layers of the pre-trained model, identified as “vital layers.” The method’s strength lies in its ability to perform various editing operations (non-rigid transformations, object addition/removal, scene editing) using a unified mechanism. Identifying these vital layers automatically is crucial for effective and stable editing, and the proposed method accomplishes this by analyzing layer importance. A noteworthy aspect is the introduction of “latent nudging” to enhance the inversion of real images into the model’s latent space, significantly improving the accuracy of image reconstruction and preventing unwanted artifacts during the editing process. Overall, training-free editing offers a highly efficient and versatile approach to image manipulation, potentially revolutionizing various creative applications.
Real Image Inversion#
The section on “Real Image Inversion” highlights a critical challenge in applying generative models to real-world images: the need to translate real images into the latent space of the model before editing. The authors point out that existing ODE (Ordinary Differential Equation) solvers struggle to perfectly reconstruct the original image, leading to artifacts or unwanted changes. Their proposed solution, latent nudging, addresses this issue by applying a small perturbation to the image latent before inversion. This technique improves reconstruction accuracy and results in more stable and consistent edits, showcasing a thoughtful approach to a crucial preprocessing step for effective real-image manipulation.
Future Work#
Future research directions stemming from this Stable Flow model could explore expanding the range of supported image editing tasks. While impressive results were shown for non-rigid edits, object addition/removal, and scene changes, the framework’s potential might extend to more complex manipulations, such as detailed texture synthesis, style transfer applied to specific objects, or seamless image composition. A key area to investigate would be improving the method’s robustness to noisy or ambiguous inputs, perhaps using more sophisticated prompt parsing or incorporating image segmentation techniques. Additionally, exploring alternative diffusion models beyond FLUX would validate the methodology’s generalizability and potentially reveal new layers that would benefit from targeted attention injection. Finally, enhancing the image inversion process for greater accuracy and efficiency, especially with real-world images that may present unique challenges, is crucial. This would further solidify the training-free editing approach and expand its applicability to a wider range of imaging contexts.
More visual insights#
More on figures

🔼 This figure compares the results of three different diffusion models when performing text-driven image editing using the same initial seed. The first model, SDXL, shows significant diversity in the generated images, with variations in the identities of the dog and cat and changes in the environment. The second model, FLUX, provides more stable results but still exhibits some unintended inconsistencies (e.g., posture changes in the dog, color variations in the cat, and background changes). Stable Flow, the authors’ proposed method, demonstrates consistent and stable image edits, preserving unrelated image content across different editing prompts.
read the caption
Figure 2: Leveraging Reduced Diversity. Using the same initial seed with different editing prompts, diffusion models such as (1) SDXL generate diverse results (different identities of the dog and the cat), while (2) FLUX generates a more stable (less diverse) set of results out-of-the-box. However, there are still some unintended differences (the dog is standing in the leftmost column and sitting in the others, the color of the cat is changing, and the road is different on the right). Using our approach, (3) Stable Flow, the edits are stable, maintaining consistency of the unrelated content.

🔼 This figure illustrates the concept of layer removal in Diffusion Transformer (DiT) models for image editing. The left panel shows the architecture of a text-to-image DiT model, highlighting its consecutive layers connected by residual connections. Each layer is a multimodal diffusion transformer block processing combined text and image embeddings. The right panel details the ablation process: for each layer, the layer is bypassed using its residual connection, generating an image. The generated image from the ablated model is then compared to that of the complete model using a perceptual similarity metric to determine the importance of the removed layer. This method helps identify crucial layers for image generation.
read the caption
Figure 3: Layer Removal. (Left) Text-to-image DiT models consist of consecutive layers connected through residual connections [33]. Each layer implements a multimodal diffusion transformer block [25] that processes a combined sequence of text and image embeddings. (Right) For each DiT layer, we performe an ablation by bypassing the layer using its residual connection. Then, we compare the generated result on the ablated model with the complete model using a perceptual similarity metric.

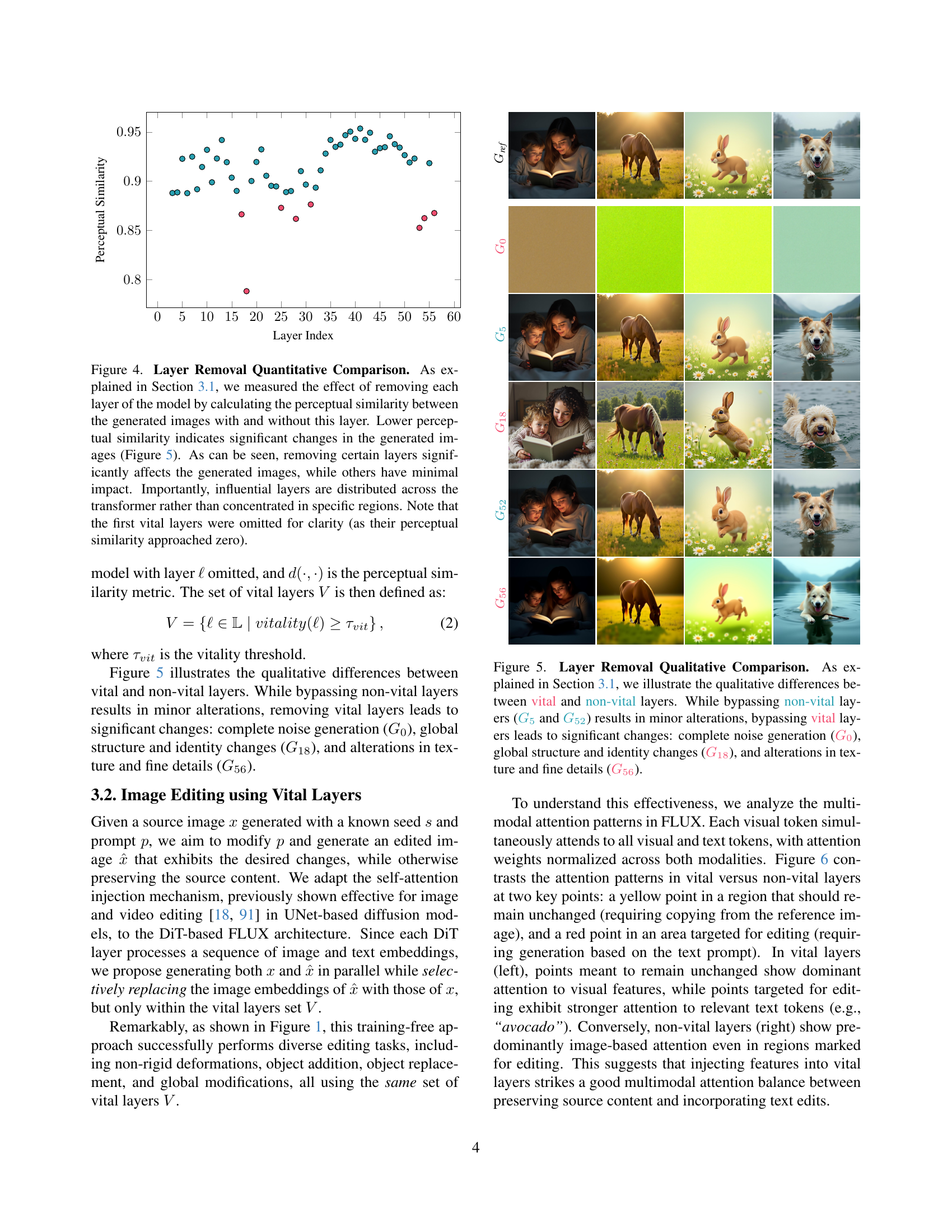
🔼 This figure shows a graph plotting the perceptual similarity of images generated with and without individual layers of a diffusion model. The x-axis represents the layer index and the y-axis represents the perceptual similarity, measured using a metric (likely LPIPS or similar). Each point on the graph corresponds to a single layer, indicating the effect of removing that layer on the image generation process. A lower perceptual similarity means that removing the layer caused more significant changes in the output image. The results demonstrate that some layers (‘vital layers’) have a substantially larger impact than others, which supports the idea of a non-uniform distribution of importance across different layers of the diffusion model. The vital layers that strongly influence image generation are not clustered together but are spread out across the model.
read the caption
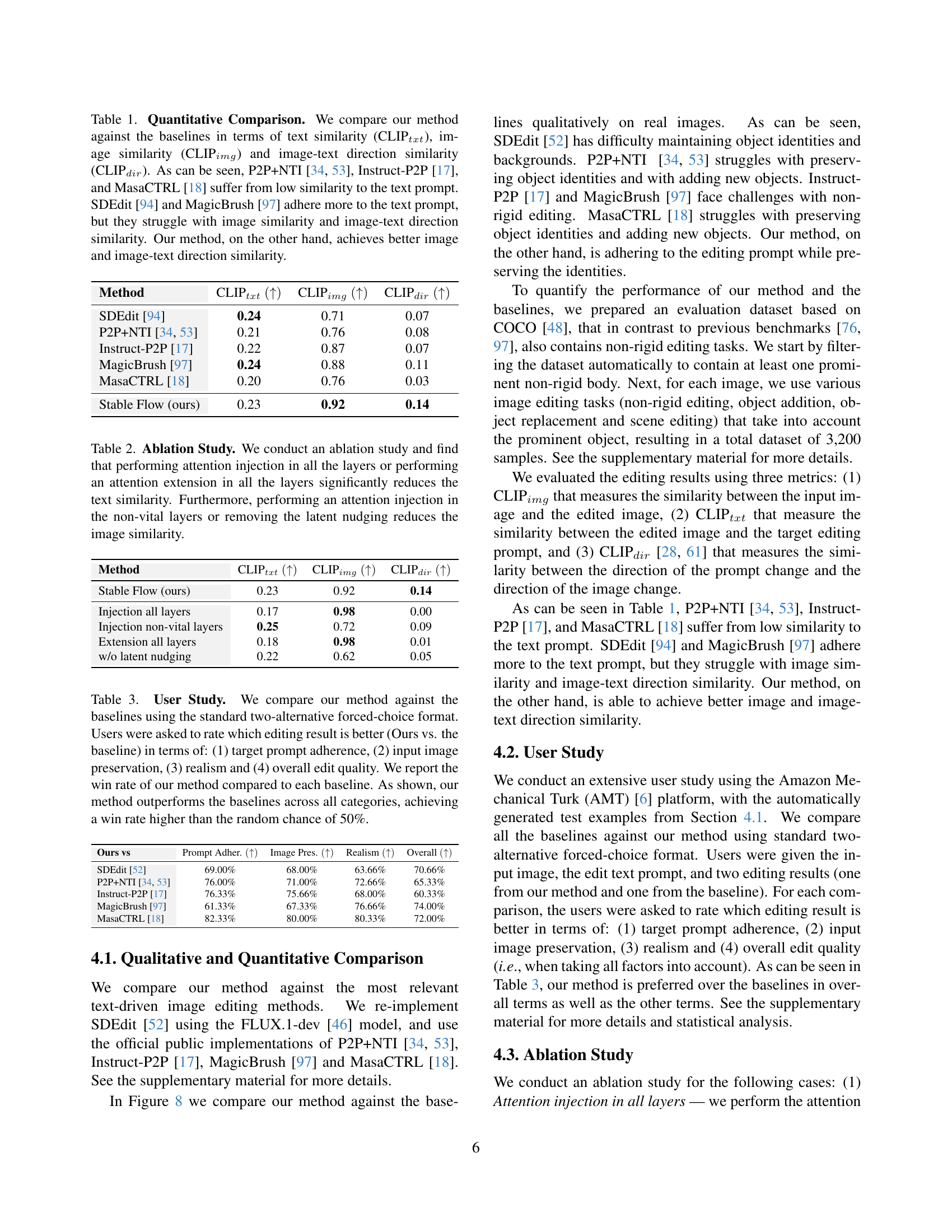
Figure 4: Layer Removal Quantitative Comparison. As explained in Section 3.1, we measured the effect of removing each layer of the model by calculating the perceptual similarity between the generated images with and without this layer. Lower perceptual similarity indicates significant changes in the generated images (Figure 5). As can be seen, removing certain layers significantly affects the generated images, while others have minimal impact. Importantly, influential layers are distributed across the transformer rather than concentrated in specific regions. Note that the first vital layers were omitted for clarity (as their perceptual similarity approached zero).
More on tables
 |
|  |
|  |
|  |
| $G_0$ |
|
| $G_0$ |  |
|  |
|  |
|  |
| $G_5$ |
|
| $G_5$ |  |
|  |
|  |
|  |
| $G_{18}$ |
|
| $G_{18}$ |  |
|  |
|  |
|  |
| $G_{52}$ |
|
| $G_{52}$ |  |
|  |
|  |
|  |
| $G_{56}$ |
|
| $G_{56}$ |  |
|  |
|  |
|  |
|🔼 This ablation study investigates the impact of different modifications to the Stable Flow model on text and image similarity. The model’s performance is evaluated across four scenarios: injecting attention in all layers, injecting attention only into non-vital layers, extending attention across all layers, and removing latent nudging. The results reveal that applying attention injection or extension across all layers significantly diminishes text similarity. Moreover, confining attention injection to non-vital layers or omitting latent nudging leads to a substantial reduction in image similarity.
read the caption
Table 2: Ablation Study. We conduct an ablation study and find that performing attention injection in all the layers or performing an attention extension in all the layers significantly reduces the text similarity. Furthermore, performing an attention injection in the non-vital layers or removing the latent nudging reduces the image similarity.
 |
|  |
|  |
| (b) w nudging |
|
| (b) w nudging |  |
|  |
| | Input image | Reconstruction | “Raising its hand” |
|
| | Input image | Reconstruction | “Raising its hand” |🔼 This table presents the results of a user study comparing the performance of the proposed Stable Flow method against several existing image editing methods. Participants used a two-alternative forced-choice format to rate the quality of image edits produced by each method. The ratings focused on four key aspects: how well the edit followed the text instructions (prompt adherence), how well the original image features were preserved, the realism of the edited images, and the overall perceived quality. The table shows the win rate for Stable Flow against each baseline method, demonstrating its superior performance in all aspects across all baselines.
read the caption
Table 3: User Study. We compare our method against the baselines using the standard two-alternative forced-choice format. Users were asked to rate which editing result is better (Ours vs. the baseline) in terms of: (1) target prompt adherence, (2) input image preservation, (3) realism and (4) overall edit quality. We report the win rate of our method compared to each baseline. As shown, our method outperforms the baselines across all categories, achieving a win rate higher than the random chance of 50%.
🔼 This table presents the statistical significance of the user study comparing the proposed method against several baselines. The user study employed a two-alternative forced-choice format where participants rated pairs of edited images. A binomial test was used to determine if the win rates for the proposed method were significantly different from a random chance of 50%. The p-values reported indicate that for all four metrics (prompt adherence, image preservation, realism, and overall quality), the differences between the proposed method and the baselines are statistically significant, with p-values less than 5%. This means the results are highly unlikely to be due to random chance, demonstrating the superiority of the proposed method.
read the caption
Table 4: User Study Statistical Significance. A binomial statistical test of the user study results suggests that our results are statistically significant (p-value <5%absentpercent5<5\%< 5 %).
Full paper#