↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multi-modal Large Language Models (MLLMs) are powerful but struggle with complex visual reasoning tasks. Existing approaches often lack sufficient high-quality training data and efficient training strategies. This paper introduces Insight-V, which aims to solve these problems.
Insight-V uses a two-step pipeline to automatically generate long, structured reasoning data without human intervention. A novel multi-agent system further enhances the reasoning process by separating reasoning and summarization tasks. The system incorporates an iterative DPO (Direct Preference Optimization) algorithm to enhance the reasoning quality. This system is shown to significantly improve the performance of LLaVA-NeXT and a strong baseline MLLM across several visual reasoning benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the crucial challenge of enabling multi-modal large language models (MLLMs) to perform complex visual reasoning tasks. Current methods struggle with long-chain reasoning in visual contexts due to data scarcity and training limitations. The proposed Insight-V system offers a novel approach to generating high-quality data and improving the training process, significantly advancing the field and opening new avenues of research in MLLMs.
Visual Insights#

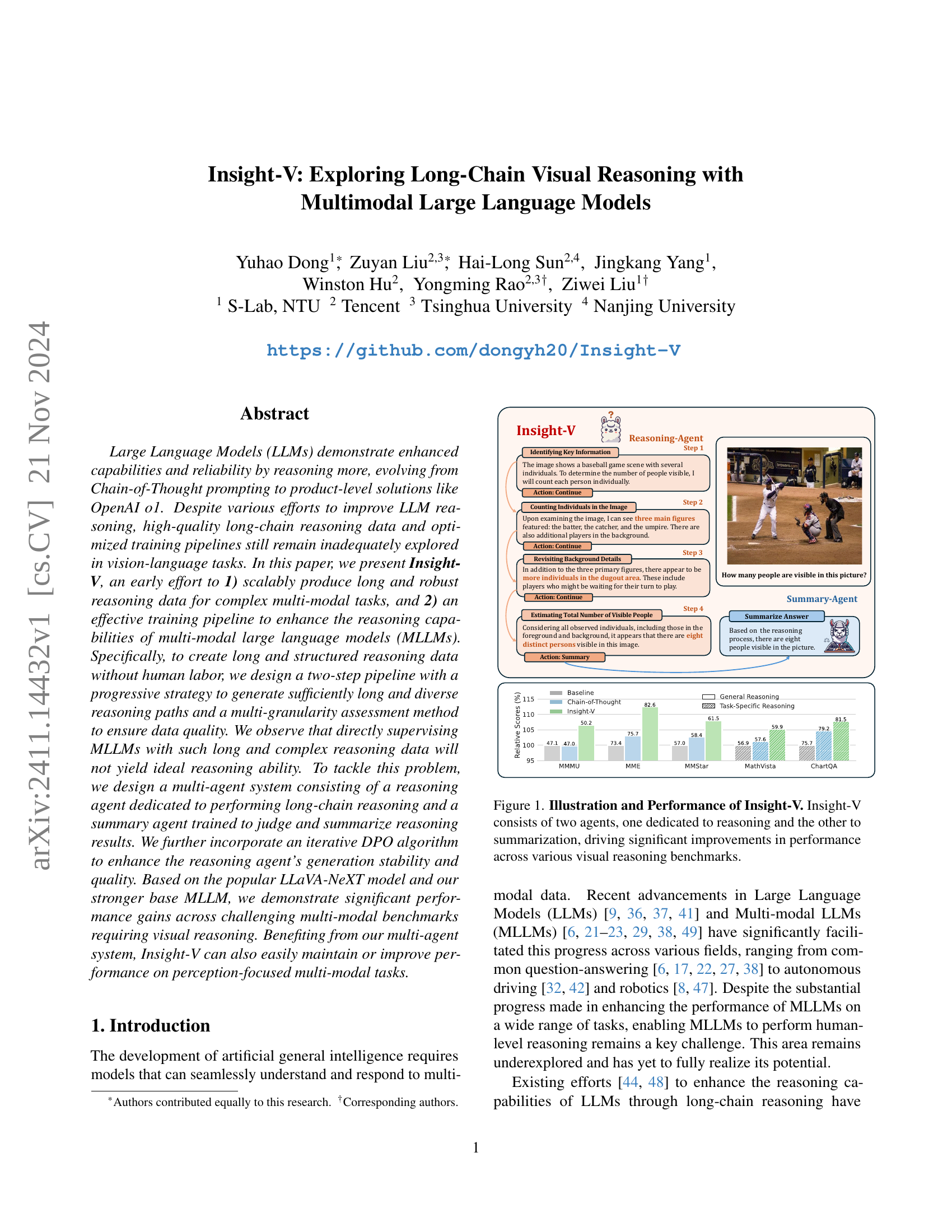
🔼 Insight-V is a novel multi-agent system designed to enhance visual reasoning capabilities in multimodal large language models (MLLMs). It consists of two agents: a reasoning agent that generates detailed, step-by-step reasoning processes for visual reasoning tasks, and a summarization agent that evaluates the reasoning process and produces a concise, accurate final answer. The figure illustrates the architecture of Insight-V, highlighting the collaborative workflow between the two agents. The bar chart presents a performance comparison of Insight-V against various baseline methods across several visual reasoning benchmarks, showcasing the significant performance improvements achieved by Insight-V.
read the caption
Figure 1: Illustration and Performance of Insight-V. Insight-V consists of two agents, one dedicated to reasoning and the other to summarization, driving significant improvements in performance across various visual reasoning benchmarks.
| Model | Size | MMMU | MMMU-Pro | MMBench | MME | ChartQA | MMStar | MathVista | Average |
|---|---|---|---|---|---|---|---|---|---|
| DeepSeek-VL [29] | 7B | 35.4 | - | 73.5 | -/- | 59.1 | 37.1 | 36.1 | - |
| VILA-1.5 [20] | 8B | 38.6 | - | 75.3 | 1634.9/- | - | 39.7 | - | - |
| Cambrian-1 [43] | 8B | 42.7 | - | 75.9 | 1547.1/- | 73.3 | - | 49.0 | - |
| InternLM-XComposer2 [7] | 7B | 41.1 | - | 77.6 | 2220.4 | 71.8 | 56.2 | 59.5 | - |
| POINTS [26] | 7B | 51.4 | - | 78.0 | 2184.1 | - | 60.9 | 63.0 | - |
| IXC-2.5 [55] | 7B | 42.9 | - | 79.4 | 2233.1 | 82.2 | 59.9 | 63.7 | - |
| Bunny-LLaMA3 [12] | 8B | 43.4 | - | 77.2 | 1588.9/321.1 | - | - | 34.4 | - |
| MM-1.5 [54] | 7B | 41.8 | - | - | 1514.9/346.4 | 78.6 | - | 47.6 | - |
| MiniCPM-LLaMA3-V 2.5 [49] | 8B | 45.8 | 19.6 | 77.2 | 2024.6 | - | 51.8 | 54.3 | - |
| MiniCPM-V-2.6 [50] | 7B | 49.8 | 27.2 | 78.0 | 2268.7 | - | 57.5 | 60.6 | - |
| Qwen2-VL [38] | 7B | 53.7 | - | 81.0 | - | 83.0 | 60.7 | 61.4 | - |
| Idefics3-LLaMA3 [14] | 8B | 46.6 | 22.9 | 77.5 | 1937.4 | 74.8 | 55.9 | 58.4 | 48.1 |
| Ovis1.5-LLaMA3 [31] | 8B | 48.3 | 23.6 | 76.6 | 1948.5 | 76.4 | 57.3 | 63.0 | 49.4 |
| LLaVA-NeXT-LLaMA3 [22] | 8B | 36.9 | 13.2 | 72.3 | 1611.1/346.0 | 69.4 | 43.1 | 45.9 | 40.2 |
| + Multi-Agent | 8B | 40.8 | 17.8 | 77.6 | 1603.7/469.3 | 74.6 | 52.6 | 47.4 | 44.5 |
| + Iterative DPO (Insight-V-LLaVA) | 8B | 42.0 | 21.0 | 81.7 | 1583.9/485.4 | 77.4 | 57.4 | 49.8 | 47.2 (+7.0) |
| Our Base Model | 7B | 47.1 | 22.6 | 81.3 | 1573.7/482.5 | 75.7 | 57.0 | 56.9 | 48.7 |
| + Multi-Agent | 7B | 49.7 | 23.8 | 82.2 | 1662.2/629.3/ | 81.2 | 58.6 | 58.7 | 50.7 |
| + Iterative DPO (Insight-V) | 7B | 50.2 | 24.9 | 82.3 | 1685.1/627.0 | 81.5 | 61.5 | 59.9 | 51.6 (+2.9) |
🔼 Table 1 presents a comprehensive evaluation of various Multimodal Large Language Models (MLLMs) on seven visual reasoning benchmarks. These benchmarks assess both general reasoning capabilities and task-specific skills. The table compares the performance of Insight-V (applied to both LLaVA-NeXT and a strong baseline MLLM) against several state-of-the-art MLLMs. The results demonstrate that Insight-V significantly improves performance across all benchmarks, showcasing its effectiveness and generalizability in enhancing visual reasoning capabilities.
read the caption
Table 1: Results on Visual Reasoning Tasks. We conduct evaluation experiments across 7 benchmarks, covering both general reasoning and task-specific reasoning assessments. Insight-V exhibits notable effectiveness and generalizability when applied to LLaVA-NeXT and our baseline model, surpassing other state-of-the-art MLLMs by a large margin.
In-depth insights#
Multimodal Reasoning#
Multimodal reasoning, the ability of AI systems to integrate and reason across different modalities like text, images, and audio, is a crucial step towards Artificial General Intelligence (AGI). Current research highlights the challenges in creating robust multimodal reasoning models, stemming from the scarcity of high-quality datasets and the difficulty in training models to effectively combine information from diverse sources. Many approaches focus on improving the reasoning capabilities of Large Language Models (LLMs) by extending chain-of-thought prompting or employing reinforcement learning from human feedback (RLHF). However, these methods often struggle with complex, long-chain reasoning tasks. The development of sophisticated methods such as multi-agent systems, where one agent focuses on reasoning and another on summarizing the results, offers a promising solution. Combining iterative Direct Preference Optimization (DPO) further refines these models, improving alignment with human preferences and leading to more accurate and reliable outputs. Scalable data generation pipelines are critical to overcome the data limitations, requiring progressive strategies to produce diverse and structured reasoning paths. Future research should focus on addressing these limitations and exploring new techniques to improve the accuracy, efficiency, and generalizability of multimodal reasoning systems.
Data Generation Pipeline#
A robust data generation pipeline is crucial for training effective multimodal large language models (MLLMs) for visual reasoning. The pipeline’s design should prioritize scalability, minimizing reliance on human labor. A two-step process, incorporating a progressive strategy and multi-granularity assessment, is particularly effective. The progressive strategy ensures the generation of sufficiently long and diverse reasoning paths, while multi-granularity assessment uses automated methods to filter and rank the generated paths based on quality, avoiding the bottleneck of manual annotation. The assessment system should incorporate both coarse-grained (e.g., correctness of final answers) and fine-grained (e.g., detailed step-by-step accuracy) evaluations. This automated approach significantly enhances the scalability and efficiency of data generation, allowing for the creation of large-scale datasets that are crucial for training high-performing MLLMs. The focus on both quality and diversity of reasoning paths is critical, as it ensures that the model is exposed to diverse reasoning strategies and is capable of handling complex scenarios.
Multi-Agent System#
The core of the proposed method lies in its innovative multi-agent system, which intelligently decomposes the complex visual reasoning task into two simpler, more manageable subtasks: reasoning and summarization. This strategic division of labor allows for a more focused and efficient approach. The reasoning agent, meticulously trained on a large-scale, high-quality dataset of structured reasoning paths, generates a detailed, step-by-step reasoning process for each query. This detailed process enhances the clarity and transparency of the reasoning process. Meanwhile, a dedicated summary agent, trained to critically evaluate and synthesize the reasoning agent’s output, then generates a concise answer, effectively summarizing the key insights from the extensive reasoning chain. This collaborative process mitigates the challenges faced by traditional methods, where a single model is expected to handle the entire reasoning and answer generation processes simultaneously. The iterative implementation of the direct preference optimization (DPO) algorithm further enhances the system’s overall performance by refining the reasoning agent’s generation stability and quality, making the output more aligned with human preferences. This multi-agent architecture not only enhances reasoning capabilities but also improves the model’s robustness to errors during the reasoning process.
Iterative DPO#
The iterative Direct Preference Optimization (DPO) approach represents a significant enhancement over traditional DPO methods for aligning large language models (LLMs) with human preferences. Traditional DPO suffers from the fact that offline-generated preference data becomes outdated as the model’s parameters shift during training. The iterative approach addresses this by sequentially training a series of models. Each subsequent model uses preference data generated by its predecessor, creating a feedback loop that continuously refines alignment. This online-like adaptation makes the preference learning process more robust and better suited to capturing dynamic shifts in model behavior. The result is a more effective and accurate alignment of the LLM with human preferences, ultimately leading to improvements in the quality and consistency of the model’s reasoning capabilities. Key to the success of the method is the dynamic generation and use of preference data, ensuring that the model is consistently optimized against the most current and relevant feedback. This iterative refinement minimizes the risks associated with static preference datasets and results in a more human-aligned and effective model.
Future Research#
Future research directions stemming from the Insight-V paper could explore several promising avenues. Improving the scalability and efficiency of the data generation pipeline is crucial. This could involve exploring more sophisticated methods for automatically generating diverse and complex reasoning paths, potentially using reinforcement learning or generative adversarial networks. Enhancing the multi-agent system is another key area. Research could focus on more advanced interaction mechanisms between the reasoning and summary agents, perhaps incorporating techniques from cooperative multi-agent systems. Investigating the generalizability of Insight-V to other multimodal tasks and datasets is important. This would involve testing the system on a wider range of benchmarks and evaluating its robustness to variations in image quality, question complexity, and dataset characteristics. Finally, exploring different model architectures and training strategies could lead to further performance improvements. This might include using larger language models, experimenting with different attention mechanisms, or investigating alternative training objectives optimized for long-chain reasoning.
More visual insights#
More on figures

🔼 Insight-V’s data generation pipeline is a two-step process. First, a reasoning generator creates structured reasoning paths progressively, adding steps until a summary is needed. The generator produces diverse reasoning paths for a given question and image. Second, a multi-granularity assessment system evaluates the reasoning paths. This system uses a strong LLM for initial filtering based on the final answer, then uses a separate agent to score paths based on details and accuracy. This automated approach avoids manual labor, allowing scalable creation of high-quality reasoning data.
read the caption
Figure 2: Data Generation Pipeline of Insight-V. The reasoning processes are generated progressively through a reasoning generator, and then fed into a multi-granularity assessment system to ensure high-quality reasoning.

🔼 Insight-V uses a multi-agent system, derived from a single pre-trained multimodal large language model (MLLM). The system is divided into two agents: a reasoning agent and a summary agent. The reasoning agent generates a step-by-step chain of thought to solve a visual reasoning problem, while the summary agent evaluates this chain of thought and provides a concise, accurate answer. This decomposition of the problem-solving process into separate reasoning and summarization stages enhances the model’s overall reasoning capabilities by focusing each agent on its respective strengths.
read the caption
Figure 3: Overview of Insight-V Model Design. We derive a multi-agent system from a single model. By decomposing the task into reasoning and summarization, the two agents collaborate to enhance the overall reasoning capability.

🔼 This figure shows the impact of the amount of training data used on the performance of the reasoning agent in the Insight-V model. The x-axis represents the amount of training data (in thousands), and the y-axis represents the relative performance of the agent across several benchmarks (MMMU, MMMU-Pro, MathVista, MMStar, ChartQA, and MME). The graph demonstrates a clear upward trend, indicating that as the size of the training dataset increases, so does the agent’s performance on these benchmarks. This is because more data provides the reasoning agent with more comprehensive and diverse examples, improving its ability to generate effective reasoning processes, leading to better quality insights for the summary agent.
read the caption
Figure 4: Ablations on the amount of training data. The reasoning agent benefits from data scaling, providing more valuable insights for the summary agent.

🔼 This figure compares the qualitative reasoning process of three different methods: Insight-V, Chain-of-Thought, and a baseline model trained with direct supervised fine-tuning (SFT). Insight-V employs a multi-agent system where a reasoning agent generates a detailed and structured reasoning process, which is then evaluated and summarized by a summary agent to produce the final answer. In contrast, the Chain-of-Thought method struggles with complex reasoning tasks, and the SFT baseline model fails to solve challenging problems, demonstrating the superiority of Insight-V’s multi-agent approach for complex visual reasoning.
read the caption
Figure 5: Qualitative Results of Insight-V. We present qualitative comparisons of Insight-V with Chain-of-Thought and learning Insight-V with direct SFT (Vanilla). For the Insight-V system, the reasoning agent delivers a more coherent and structured reasoning process, guiding the summary agent toward the correct answer, whereas other methods struggle with complex reasoning tasks and fail to solve such challenging problems.

🔼 Figure 6 presents a comparative analysis of reasoning processes between Insight-V and a direct Chain-of-Thought approach. It shows confusion matrices illustrating the accuracy of reasoning paths and final answers generated by both methods. The matrices highlight Insight-V’s superior ability to produce accurate reasoning paths even when the initial reasoning path is incorrect. Importantly, it demonstrates Insight-V’s capacity to leverage partially correct or incomplete reasoning to arrive at the correct final answer, a feat not consistently achieved by the direct Chain-of-Thought approach. This showcases the effectiveness of the multi-agent system in enhancing both reasoning quality and the reliability of the final answers.
read the caption
Figure 6: Analysis of Multi-agent System. Insight-V enhances reasoning capabilities while enabling the ability to selectively answer questions based on the provided reasoning process.
More on tables
| Model | TextVQA | DocVQA | OCRBench | AI2D |
|---|---|---|---|---|
| LLaVA-NeXT-LLaMA3 | 65.2 | 78.2 | 553 | 71.5 |
| + Multi-Agent | 68.9 | 81.8 | 631 | 75.7 |
| + Iterative DPO (Insight-V-LLaVA) | 70.5 | 82.9 | 663 | 77.3 |
| Our Base Model | 75.4 | 90.2 | 713 | 79.7 |
| + Multi-Agent | 77.0 | 91.4 | 738 | 80.1 |
| + Iterative DPO (Insight-V) | 76.8 | 91.5 | 735 | 79.8 |
🔼 Table 2 presents the results of evaluating the Insight-V model on various multimodal benchmarks that assess different aspects of vision and language understanding. The table shows that Insight-V improves performance on these benchmarks without negatively impacting its general visual perception capabilities. In fact, Insight-V even enhances performance on some tasks which heavily rely on strong visual understanding. This highlights the model’s ability to effectively integrate reasoning and perception in multimodal tasks.
read the caption
Table 2: Results on other multimodal benchmarks. Insight-V enhances reasoning capabilities without compromising general visual perception and even achieves improvements on benchmarks requiring perception ability more.
| Model | MMMU | ChartQA | MathVista | MMStar | Avg |
|---|---|---|---|---|---|
| Baseline | 47.1 | 75.7 | 56.9 | 57.0 | 59.2 |
| Vanilla - Direct SFT | 47.0 | 79.2 | 57.6 | 58.4 | 60.6 |
| Multi-Turn Supervised | 48.1 | 79.6 | 57.9 | 58.2 | 61.0 |
| Summary Agent Only | 47.5 | 76.3 | 57.3 | 57.9 | 59.8 |
| Multi-Agent | 49.7 | 81.2 | 58.7 | 58.6 | 62.1 |
🔼 This table presents ablation studies comparing the performance of Insight-V’s multi-agent design against various alternative configurations. It shows the average performance across multiple visual reasoning benchmarks (MMMU, ChartQA, MathVista, MMStar) for different model variations. The variations include a baseline model, a model trained with direct supervised fine-tuning, a model incorporating a multi-agent system, and Insight-V which includes both the multi-agent system and iterative direct preference optimization. By comparing these results, the table highlights the substantial improvement and the crucial role of decomposing the visual reasoning task into distinct reasoning and summarization steps, which is a core feature of the Insight-V architecture.
read the caption
Table 3: Ablations on the Insight-V Design Choice. The multi-agent design outperforms other configurations, highlighting the critical role of reasoning and summarization decomposition.
| Model | MMMU | ChartQA | MathVista | MMStar | Avg |
|---|---|---|---|---|---|
| Insight-V (Multi-Agent) | 49.7 | 81.2 | 58.7 | 58.6 | 62.1 |
| + RLAIF | 49.5 | 81.4 | 59.1 | 59.2 | 62.3 |
| + DPO | 50.8 | 80.8 | 59.3 | 59.9 | 62.7 |
| + Iterative DPO | 50.2 | 81.5 | 59.9 | 61.5 | 63.3 |
🔼 This table presents ablation studies on different DPO (Direct Preference Optimization) training strategies. It compares the performance of a model trained with a standard DPO approach against one trained using iterative DPO. The iterative DPO method repeatedly refines the model by generating new preference pairs at each iteration using the updated model, thus leading to a potentially more accurate reflection of human preferences. The table shows the impact of these different DPO strategies across multiple visual reasoning benchmarks (MMMU, ChartQA, MathVista, and MMStar), highlighting the improvement in performance achieved through iterative DPO.
read the caption
Table 4: Ablations on the DPO training strategy. Iterative DPO progressively enhances the model’s reasoning capabilities, leading to improved performance.
Full paper#