↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Creating realistic textures for 3D models is crucial in various applications, but existing methods often fall short. Many rely on pre-trained 2D models or complex test-time optimization, resulting in slow processing, limited scalability, and inconsistencies in texture quality. Additionally, generating high-resolution details remains a challenge. These methods struggle with generating high-quality results efficiently and struggle with 3D consistency and high-resolution details.
The researchers address these issues by proposing TEXGen, a large generative diffusion model designed to work directly in the UV texture space. This feed-forward approach avoids time-consuming optimization and offers superior speed and scalability. The model incorporates a novel hybrid 2D-3D network architecture, efficiently handling high-resolution details while maintaining global 3D consistency. TEXGen significantly outperforms existing techniques, producing high-quality textures quickly and efficiently. It also supports additional applications, such as texture inpainting and completion from sparse views, further showcasing its versatility and potential for broad impact.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces TEXGen, a novel and highly effective method for generating high-quality textures for 3D meshes. Its feed-forward architecture and ability to use both text and images as prompts offer significant advantages over existing methods. The model’s capacity for diverse applications, such as texture inpainting and completion from sparse views, makes it a valuable tool for researchers and practitioners working with 3D graphics and related fields. This research also opens new avenues for exploration in large-scale generative models for 3D data and hybrid 2D-3D network architectures.
Visual Insights#

🔼 This figure displays the results of the TEXGen method for generating textures on 3D meshes. The left side shows a variety of 3D models with high-resolution textures created using text and image prompts as input. The right side focuses on a bird model, showing its texture map and multiple views, highlighting the quality and detail of the generated textures. More views of the bird model are available in Figure 5.
read the caption
Figure 1. 3D meshes with textures generated by our method. We show a gallery of 3D meshes with textures generated by our method (left) and the texture map and multi-view renderings of the bird model (right). Our approach models the distribution of mesh textures at high resolution, generating high-quality textures from text and image prompts, more multi-view renderings are shown in fig. 5.
| Methods | FID(↓) | KID(↓) | Time(↓) |
|---|---|---|---|
| TEXTure (Richardson et al., 2023) | 48.31 | 48.00 | 80s |
| Text2Tex (Chen et al., 2023b) | 49.85 | 47.38 | 344s |
| Paint3D (Zeng, 2023) | 43.55 | 25.73 | 95s |
| Ours | 34.53 | 11.94 | 10s |
🔼 This table presents a quantitative comparison of different methods for 3D texture generation, evaluating their performance using the Frechet Inception Distance (FID) and Kernel Inception Distance (KID) metrics. Lower FID and KID scores indicate better texture quality, signifying a higher similarity between generated and real textures. The metrics are calculated based on multi-view renderings of the textured 3D models, providing a more comprehensive assessment of the texture quality. The table also includes the inference time for each method, highlighting the computational efficiency of each approach. The results show that the proposed method achieves state-of-the-art texture quality while significantly reducing inference time compared to existing methods.
read the caption
Table 1. Quantitative Comparisons. FID and KID (×10−4absentsuperscript104\times 10^{-4}× 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT) are evaluated on multi-view renderings. Our method achieves state-of-the-art texture quality with significantly faster inference.
In-depth insights#
Mesh Texture Diff#
Mesh Texture Diff, as a hypothetical heading, likely refers to techniques for generating or manipulating textures on 3D mesh surfaces using diffusion models. This would involve leveraging the power of diffusion processes, which iteratively refine a noisy representation into a coherent texture, directly on the mesh geometry or a related parameterization like UV maps. A key challenge would be effectively handling the non-Euclidean nature of mesh surfaces and the potential discontinuities in texture space introduced by UV unwrapping. Successful approaches would likely incorporate techniques to maintain consistency across mesh faces and avoid artifacts at seams. The focus would be on creating high-quality, realistic textures, potentially driven by various inputs such as text descriptions or image guidance. Furthermore, efficiency is a crucial consideration, as diffusion models can be computationally expensive, especially when dealing with high-resolution textures and complex meshes. Therefore, optimized architectures and algorithms are critical. Finally, the research might explore the generalizability of learned texture representations, the ability to transfer textures learned on one mesh to another, or to generate diverse textures given a minimal set of parameters.
Hybrid 2D-3D Net#
A hybrid 2D-3D network architecture for mesh texture generation offers a compelling approach to leverage the strengths of both 2D and 3D representations. The 2D component, operating on UV maps, excels at capturing high-resolution details and fine-grained textures through efficient convolutional operations. However, UV maps inherently lack global 3D consistency, a limitation the 3D component addresses. By incorporating attention mechanisms on 3D point clouds, the network effectively learns global structural relationships and spatial coherency, mitigating the fragmentation issues of UV maps. This fusion is crucial for producing textures that are both highly detailed and seamlessly integrated across the 3D mesh, avoiding inconsistencies. The hybrid approach also offers scalability; the 2D component’s efficiency with 2D convolutions contrasts with the higher computational cost of fully 3D methods, making it suitable for high-resolution textures. Furthermore, the interleaving of 2D and 3D processing allows for a synergistic interplay, where the 2D features are refined and enhanced by the 3D context, and vice-versa, resulting in a more robust and comprehensive texture representation. This architecture’s success hinges on effective feature integration between the 2D and 3D components, a challenge that is elegantly addressed by the design.
Large Model Scale#
The concept of ‘Large Model Scale’ in the context of generative AI, particularly concerning mesh texture generation, is pivotal. Larger models, with their increased parameter count and capacity to process more data, lead to significant improvements in both the quality and generalizability of generated textures. The paper highlights how scaling up the model size allows for the learning of more intricate details and complex relationships in the high-dimensional texture space. This translates to higher-resolution outputs, finer details, improved 3D consistency, and reduced artifacts, such as the Janus problem. However, simply increasing model size isn’t sufficient; the architecture must also be scalable to effectively utilize the expanded capacity. The described hybrid 2D-3D architecture is crucial in this regard, balancing computational efficiency with the ability to capture both local 2D details and global 3D structure. The success of this approach underlines the synergistic interplay between model size, architectural design, and the nature of the data, demonstrating that a well-designed large model can achieve superior results beyond what smaller models can achieve. Ultimately, the ‘Large Model Scale’ isn’t just about model size, but rather a holistic approach to scaling up all aspects of the system to achieve optimal performance and generalization in mesh texture generation.
Texture Synthesis#
Texture synthesis in 3D modeling is a crucial aspect of creating realistic and visually appealing assets. The paper explores this, focusing on generating high-resolution textures directly, rather than relying on computationally expensive test-time optimization methods. A key innovation is the use of a hybrid 2D-3D network architecture, effectively combining 2D convolutional operations on UV maps (capturing fine details) with 3D attention layers on point clouds (maintaining 3D consistency across mesh surfaces). This approach shows significant advantages in scalability and efficiency. The use of a large diffusion model trained in a feed-forward manner, avoids the limitations of previous methods that suffer from time-consuming per-object optimization and inconsistent texture generation. Furthermore, the proposed model’s ability to handle a variety of inputs such as text prompts and single images demonstrates its versatility and potential for broader applications, including texture completion and inpainting. Overall, the exploration of generating high-resolution mesh textures directly through a large diffusion model shows a significant advance in the field, paving the way for improved efficiency and realism in 3D graphics.
Future Directions#
Future research could explore several promising avenues. Improving the model’s scalability to handle even larger and more complex meshes is crucial for broader applicability. This might involve investigating more efficient network architectures or exploring alternative data representations that reduce computational demands. Another key area is enhancing the controllability and expressiveness of the model, potentially through incorporating more sophisticated conditioning mechanisms such as incorporating multiple views or detailed semantic information. Furthermore, researching novel approaches to handle different material types and rendering parameters would significantly broaden the model’s utility, enabling the generation of photorealistic textures beyond the current capabilities. Finally, investigating the integration with other generative models for a fully automated 3D pipeline, capable of creating complete 3D models with textures from text prompts or other input modalities, would represent a significant advance in the field.
More visual insights#
More on figures

🔼 This figure illustrates the concept of UV mapping in 3D mesh processing. It shows a 3D mesh and its corresponding 2D UV map. The key point highlighted is that the spatial relationships between different parts of the mesh (called ‘islands’ in the caption) are not always preserved in the UV map. For instance, two continuous parts of the mesh might end up far apart in the UV map, while two disconnected parts could appear closer together. This difference is important because many 2D image-processing techniques are used on UV maps. Understanding the mapping’s limitations is crucial for successful texture generation and other mesh-processing tasks.
read the caption
Figure 2. An illustration of (a) a mesh with its (b) UV map. Three islands S1subscript𝑆1S_{1}italic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT, S2subscript𝑆2S_{2}italic_S start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and S3subscript𝑆3S_{3}italic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT are shown both on the mesh surface and its flattened UV map, where continuous islands S1subscript𝑆1S_{1}italic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and S2subscript𝑆2S_{2}italic_S start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT are positioned far apart on the UV map while disconnected islands S1subscript𝑆1S_{1}italic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and S3subscript𝑆3S_{3}italic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT show closer distance on the UV map.

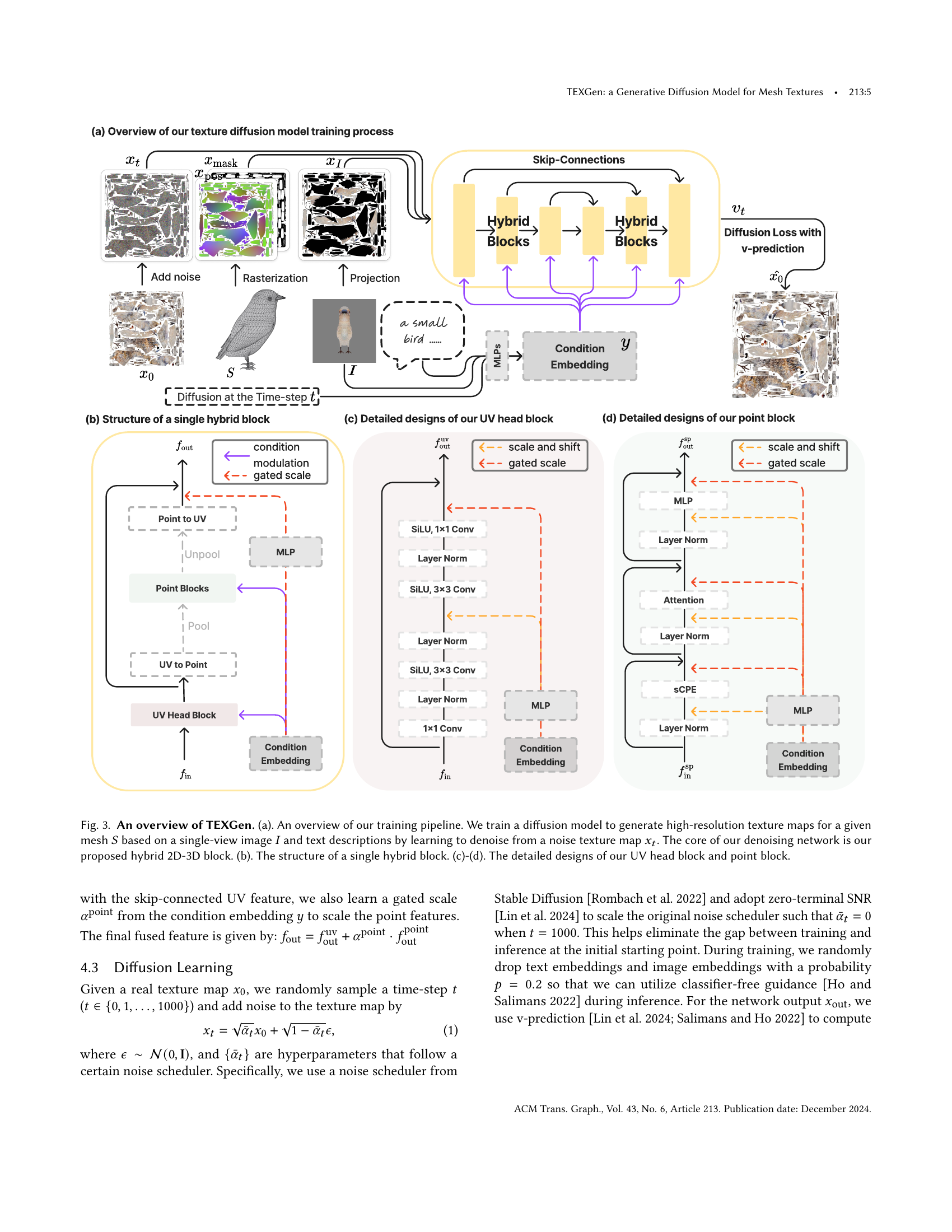
🔼 Figure 3 provides a comprehensive overview of the TEXGen model, illustrating its training pipeline and architecture. Panel (a) shows the overall training process, where a diffusion model learns to generate high-resolution texture maps from a noisy input texture map, guided by a single-view image and text descriptions. The model iteratively refines the noisy texture to reach a high-quality output. The core of the denoising network is a novel hybrid 2D-3D block, explained further in the other panels. Panel (b) details the structure of this hybrid 2D-3D block. Finally, Panels (c) and (d) provide detailed diagrams showcasing the specific design of the UV head block (processing 2D texture information) and the point block (incorporating 3D spatial information) respectively. These blocks work together to effectively process both 2D texture features and 3D spatial relationships for accurate and coherent texture generation.
read the caption
Figure 3. An overview of TEXGen. (a). An overview of our training pipeline. We train a diffusion model to generate high-resolution texture maps for a given mesh S𝑆Sitalic_S based on a single-view image I𝐼Iitalic_I and text descriptions by learning to denoise from a noise texture map xtsubscript𝑥𝑡x_{t}italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. The core of our denoising network is our proposed hybrid 2D-3D block. (b). The structure of a single hybrid block. (c)-(d). The detailed designs of our UV head block and point block.

🔼 This figure details the feature learning process within the 3D space of the TEXGen model. Panel (a) shows the initial dense point cloud features. These are then sparsified using grid-pooling, as shown in (b), where different colored regions represent different pools of points. Panel (c) visualizes the groups created using Hilbert serialization, with each color representing a distinct group. Finally, panel (d) illustrates the overall learning process, showing how the serialized, grouped points are processed through self-attention, and the results are then scattered back to their original dense format, producing the final output features.
read the caption
Figure 4. An illustration of the feature learning procedure in 3D space. In panel (a), we start with rasterized dense point features, which we sparsify using grid-pooling to create sparse point features shown in (b). Different pools are indicated by various colors in (a). These points are then serialized to determine their order for subsequent group-based self-attention, as part of the learning process shown in (d). In (c), we visualize different groups formed based on Hilbert serialization, where each color signifies a distinct group. Finally, the processed features are scattered back to their original coordinates, providing the output dense point features.

🔼 This figure showcases the results of the TEXGen model in generating high-resolution textures for various 3D meshes. The model’s ability to synthesize highly detailed textures using both single-view images and text prompts is demonstrated. For each mesh, the figure displays three novel views rendered with the generated texture, several zoomed-in sections highlighting the level of detail achieved, and the complete UV texture map itself. This provides a comprehensive visualization of the model’s output, showcasing its effectiveness across different object types and the high fidelity of the generated textures.
read the caption
Figure 5. Texture generation results. For given meshes, our method can synthesize highly detailed textures conditioned on guided single-view images and text prompts. We show three novel view images from our textured results and representative zoom-in regions from the textured mesh. The generated full texture maps are also shown.

🔼 Figure 6 presents a comparison of texture synthesis results between the proposed TEXGen model and four other state-of-the-art methods: TEXTure, Text2Tex, Paint3D. Each method is applied to four 3D models (tote bag, house, wooden barrel, frog), and the resulting textures are shown alongside the original models. This visual comparison highlights TEXGen’s ability to generate more detailed and coherent textures compared to methods relying on 2D diffusion models for test-time optimization. The figure also demonstrates that TEXGen, trained with 3D data and using a 3D representation, successfully avoids the ‘Janus problem’, a common artifact in other methods where features like eyes or mouths are unnaturally duplicated on opposite sides of a 3D object.
read the caption
Figure 6. Comparison with state-of-the-art methods. We compare our method with four representative state-of-the-art methods. Our model can synthesize more detailed and coherent textures compared to these methods which rely on test-time optimization using a 2D pretrained text-to-image diffusion model. Also, our method trained on the 3D dataset and 3D representation avoids the Janus problem that commonly occurs in other methods.

🔼 This figure showcases an indoor scene where multiple 3D objects have been textured using the TEXGen model. Each object’s texture was generated using a combination of text prompts describing the desired appearance and a single-view image generated by ControlNet, which incorporates depth information for enhanced realism. The resulting textures are detailed and realistic, demonstrating the model’s ability to create high-quality textures for diverse 3D models within a coherent scene.
read the caption
Figure 7. An indoor scene with all meshes textured by TEXGen. We generate a single view using text-conditioned ControlNet with depth control for each mesh and paint them with both the text and single view prompt with TEXGen.

🔼 This figure demonstrates the use of TEXGen as a texture inpainting model. Part (a) shows examples of texture maps with randomly masked regions, simulating missing or incomplete texture data. Part (b) displays the same texture maps after TEXGen has been used to inpaint the masked regions, filling in the missing texture information. The inpainted areas are clearly distinguishable from the original texture, and the unknown regions are represented as black for visualization. This illustrates the model’s capacity to effectively reconstruct and complete incomplete texture data.
read the caption
Figure 8. TEXGen as a texture inpainter. We demonstrate the potential of TEXGen as a texture inpainter. We showcase here (a) randomly masked texture maps and (b) the inpainted texture maps, with unknown regions rendered as black.

🔼 Figure 9 demonstrates TEXGen’s ability to complete textures from sparse views. Panel (a) shows the limited input views (front and back) available to the model. In (b), the texture is shown with the unseen areas unprojected (and therefore black/missing). Panel (c) displays the completed texture generated by TEXGen, showing how the model seamlessly fills in the missing portions in a visually consistent manner, resulting in harmonious textures across the entire 3D model.
read the caption
Figure 9. Texture completion from sparse views. With sparse views of objects provided (front and back views as shown in (a)), unprojected textures retain many unseen regions (b). TEXGen effectively fills these unseen regions with harmonious textures (c).

🔼 Figure 10 shows an ablation study comparing three model variations: the full model (A), a model using only UV blocks (B), and a model using only point blocks (C). Model A, the full model, serves as the baseline, effectively capturing both high-level semantic understanding of the scene and maintaining 3D consistency across the mesh. In contrast, model B, lacking the 3D point cloud processing, fails to capture the overall scene semantics and struggles with maintaining consistent textures across the 3D surface. Finally, model C, which omits UV-based feature extraction, significantly struggles to reproduce high-frequency details and fine textures within the mesh, resulting in a loss of visual fidelity. This comparison highlights the importance of the hybrid 2D-3D architecture in achieving high-quality and consistent texture synthesis.
read the caption
Figure 10. Qualitative ablation results on the hybrid design. Compared to the full model A (a), the model B (b) with only UV blocks can not easily capture overall semantic and 3D consistency while that the model C (c) with only point blocks struggles with producing high-frequency patterns.

🔼 Figure 11 showcases the results of applying the TEXGen model to generate textures for various 3D avatars. The images demonstrate the model’s ability to produce high-quality, detailed textures while avoiding the ‘Janus problem.’ The Janus problem is a common artifact in texture generation where features like eyes or mouths are duplicated on opposite sides of a 3D model due to limitations in how the model processes the texture across different views. The figure visually emphasizes that TEXGen, trained with a focus on 3D data and representations, successfully generates coherent and realistic textures without such artifacts.
read the caption
Figure 11. Results on 3D avatars. Our model, trained on 3D data, adeptly avoids the Janus problem.

🔼 Figure 12 showcases the effectiveness of the TEXGen model on real-world, scanned 3D models. Real-scan models often present challenges due to irregularities like non-smooth surfaces and fragmented UV maps (the 2D representation of the 3D mesh’s texture). The figure demonstrates that TEXGen successfully generates high-quality textures even on these complex models, highlighting its robustness and generalizability.
read the caption
Figure 12. Results on real-scan models. Our method is robust to real-scan models with non-smooth surfaces and fragmented UV maps.
More on tables
| Methods | Paint3D | TEXTure | Text2Tex | Ours |
|---|---|---|---|---|
| Preference(%) ↑ | 16.5 | 7.1 | 7.1 | 69.3 |
| MLLM Score ↑ | 64.8 | 69.8 | 64.8 | 74.2 |
🔼 This table presents a quantitative comparison of different methods for text-conditional texture generation. It uses two metrics: 1) Preference, which is a human-evaluated score reflecting how well the generated texture aligns with the given text description, and how high quality the texture is considered. This score is obtained from a comprehensive user study. 2) MLLM Score, which is an objective score that uses Claude 3.5-sonnet (a state-of-the-art multi-modal large language model) to assess the similarity between the generated texture and its text description. This metric uses the same Chain-of-Thought prompting technique from Huang et al. (2023a) to maintain consistency in evaluation methodology.
read the caption
Table 2. Quantitative evaluation on text-condition generation. Preference refers to the comprehensive user study evaluating the alignment with the text description and the quality of the texture. For MLLM Score, Claude 3.5-sonnet (Anthropic, 2024), a state-of-the-art MLLM, is used to calculate the text-to-texture similarity scores. To be consistent with the conclusions in (Huang et al., 2023a), we use the same Chain-of-Thought prompts described in the study.
| Models/Metrics | FID(↓) | KID(↓) |
|---|---|---|
| Hybrid block (A) | 69.74 | 17.89 |
| w/o point block (B) | 72.58 | 25.52 |
| w/o UV block (C) | 94.22 | 159.94 |
🔼 This table presents the ablation study results on the hybrid design of the TEXGen model. The goal is to determine the contribution of both the 2D UV block and the 3D point block to the model’s performance. Three model variants were created: the full model with both UV and point blocks (A), a model with only UV blocks (B), and a model with only point blocks (C). All three models have the same number of parameters. The performance of each model is evaluated using the Fréchet Inception Distance (FID) and Kernel Inception Distance (KID), which are calculated based on multi-view renderings of the generated textures. Lower FID and KID scores indicate better performance. This helps quantify the impact of the individual components on the model’s ability to generate high-quality and realistic textures.
read the caption
Table 3. Quantitative ablation results on the hybrid design. Starting from the full model, we build a UV block-only model (B) and a point block-only model (C) by replacing redundant blocks with additional ones, while maintaining the same number of model parameters. FID and KID (×10−4absentsuperscript104\times 10^{-4}× 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT) are evaluated on multi-view renderings.
| Metrics/ω | 1 | 1.5 | 2 | 3 | 4 | 5 | 7.5 | |
|---|---|---|---|---|---|---|---|---|
| FID(↓) | 35.01 | 34.73 | 34.53 | 35.19 | 35.69 | 36.69 | 39.58 | |
| KID(↓) | 15.06 | 13.00 | 11.94 | 11.71 | 13.03 | 14.53 | 24.45 |
🔼 This table presents the results of an ablation study on the classifier-free guidance (CFG) weight used in the TEXGen model. The study varied the CFG weight and measured the Fréchet Inception Distance (FID) and Kernel Inception Distance (KID) scores on multi-view renderings of the generated textures. Lower FID and KID scores indicate better performance. The results demonstrate that a CFG weight of around 2-3 achieves the optimal balance between the model’s generation quality and its ability to adhere to input conditions. The FID and KID scores are expressed as values multiplied by 10-4.
read the caption
Table 4. Ablation results of guidance weights. We use different CFG weights to evaluate TEXGen, and the results show that the weight around 2-3 is optimal.FID and KID (×10−4absentsuperscript104\times 10^{-4}× 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT) are evaluated on multi-view renderings.
Full paper#