↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current large-scale diffusion models struggle to learn and generate images with new, personalized artistic styles. While fine-tuning with reference images is promising, existing methods often lead to suboptimal style alignment due to their reliance on pre-training objectives and noise level distributions. This suboptimal style alignment is a significant challenge in creating unique style templates for personalized image generation.
This paper introduces a Style-friendly SNR sampler to tackle this issue. By strategically shifting the signal-to-noise ratio (SNR) distribution toward higher noise levels during fine-tuning, the sampler enables diffusion models to effectively capture unique styles. The authors demonstrate that this method significantly improves style alignment and allows for generating images with more diverse styles, including personal watercolor paintings, flat cartoons, 3D renderings, and memes. This approach enhances the ability of diffusion models to learn and share new style templates, ultimately broadening the scope of style-driven generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation as it directly addresses the challenge of controlling style in diffusion models. Its novel SNR sampler offers a significant improvement over existing methods, enabling more precise style control and opening avenues for personalized image creation. This work is highly relevant to current trends in AI art and style transfer and will inspire further research in enhancing the stylistic capabilities of generative models.
Visual Insights#

🔼 This figure demonstrates the Style-friendly SNR Sampler’s ability to generate images in various artistic styles by fine-tuning diffusion models with reference images. The top row shows examples of generating a ‘fluffy baby sloth with a knitted hat trying to figure out a laptop’ in three different meme formats. The bottom row shows a ‘singing kangaroo drinking beer’ rendered in four distinct artistic styles (flat illustration, crayon, watercolor, and line drawing). The rightmost column displays the same phrase rendered in two distinct typographic styles (wooden sculpture and minimal line drawing). The red boxes within each image highlight the reference images used for style transfer. This showcases the model’s capability to learn and apply diverse style templates from relatively few examples.
read the caption
Figure 1: Our method learns style templates from reference images, capturing elements including color schemes, layouts, illumination, and brushstrokes. For each image, we fine-tune diffusion models using the reference image in the red insert box to generate the output. We show a ‘fluffy baby sloth with a knitted hat trying to figure out a laptop’ in different meme templates: a meme with the words ‘you just activated my trap card’ (top left), a multi-panel comic layout (bottom left), and a two-panel meme (top middle). On the right side, we display typographies in the styles of a wooden sculpture and a minimal line drawing. We also present a ‘singing kangaroo drinking beer’ in various artistic styles—flat illustration, crayon drawing, watercolor, and line drawing.
| Style Alignment | Method | Model | win | tie | lose |
|---|---|---|---|---|---|
| Style-Aligned [14] | SDXL | 61.0 % | 7.1% | 31.9% | |
| RB-Mod [44] | Cascade | 55.6 % | 12.6% | 31.8% | |
| IP-Adapter [61] | FLUX-dev | 59.2 % | 8.0% | 32.8% | |
| DCO [30] | FLUX-dev | 56.0 % | 10.2% | 33.8% | |
| SD3 sampler [8] | FLUX-dev | 56.0 % | 9.2% | 34.8% | |
| Text Alignment | Method | Model | win | tie | lose |
| — | — | — | — | — | — |
| Style-Aligned [14] | SDXL | 60.7% | 7.5% | 31.8% | |
| RB-Mod [44] | Cascade | 54.3% | 6.3% | 39.4% | |
| IP-Adapter [61] | FLUX-dev | 56.0% | 4.6% | 39.4% | |
| DCO [30] | FLUX-dev | 53.2% | 10.0% | 36.8% | |
| SD3 sampler [8] | FLUX-dev | 56.5% | 14.0% | 29.5% |
🔼 This table presents the results of a human evaluation comparing the performance of the proposed Style-Friendly SNR sampler with several baseline methods in terms of style and text alignment in image generation. Participants were shown reference images, target prompts, and images generated by different methods, and asked to choose the image that best matched either the style of the reference or the target text. The table shows the percentage of times each method was preferred for style and text, and the percentage of ties.
read the caption
Table 1: Human evaluation. User preference results comparing style and text alignments between our method and the baselines.
In-depth insights#
Style-Driven Gen#
Style-driven generation, as explored in the research paper, presents a significant challenge and opportunity in the field of AI image synthesis. The core problem is that while large diffusion models excel at generating high-quality images, they struggle to learn and apply new artistic styles effectively. Fine-tuning with reference images is a promising approach, but suboptimal style alignment is common. The paper focuses on addressing this limitation by introducing a novel technique, a Style-friendly SNR sampler. This method strategically shifts the signal-to-noise ratio (SNR) distribution during fine-tuning. By focusing on higher noise levels, where stylistic features are more prominent, the model is better able to capture and reproduce unique stylistic elements. This leads to improved style alignment and the ability to generate images with higher fidelity to the desired style. The approach demonstrates the capability to create unique style templates that can be applied across various artistic styles, expanding the potential of style-driven generation for personalized content creation and broadening the creative scope of AI-powered image synthesis. Ultimately, the contribution lies in directly addressing a critical limitation of existing methods, opening new avenues for creating truly personalized and expressive AI-generated imagery.
SNR Sampler#
The concept of a ‘SNR Sampler’ within the context of diffusion models for image generation is crucial for controlling the balance between signal and noise during the denoising process. It directly influences the model’s ability to learn and reproduce specific stylistic features. A well-designed SNR sampler biases the sampling towards higher noise levels, where stylistic information is more prominent, enabling the model to capture and generate images with higher style fidelity. This is in contrast to traditional approaches that often rely on pre-training distributions, leading to suboptimal style alignment. The innovative aspect lies in the capacity to actively shift the SNR distribution, focusing the training process on the noise levels most relevant to style. This strategy allows for the creation of unique, personalized “style templates,” thus expanding the capabilities of style-driven generation and personalizing artistic content creation. The impact is significant because it addresses a key limitation of previous methods, where fine-tuning often failed to capture subtle nuances in artistic styles. By strategically manipulating the SNR, the model can be steered towards effectively learning and replicating highly-specific styles rather than simply generating photorealistic images.
Style Emergence#
The concept of “Style Emergence” in the context of diffusion models for image generation is crucial. The paper highlights that styles don’t appear uniformly across all noise levels during the denoising process. Instead, styles predominantly emerge at higher noise levels (lower log-SNR values). This observation is key to improving style-driven generation. Fine-tuning methods that focus sampling on these higher noise levels are more effective at capturing and transferring stylistic features. By biasing the sampling towards this critical region, the model learns to prioritize stylistic information, leading to better style alignment in generated images. Understanding and leveraging style emergence is therefore vital for creating models that produce high-quality, personalized results that truly reflect the intended artistic styles.
MM-DIT Tuning#
The heading ‘MM-DIT Tuning’ suggests a focus on adapting the Multi-Modal Diffusion Transformer (MM-DIT) architecture for specific tasks or domains. Fine-tuning MM-DIT is a crucial aspect, allowing for customization without retraining the entire model. This approach likely involves modifying a subset of the model’s parameters, such as using low-rank adaptation techniques like LoRA. The goal is likely to achieve efficient adaptation for tasks like style-driven generation, where pre-trained weights are adjusted to better capture specific stylistic features. A key advantage is improved efficiency, avoiding the computational cost of full model retraining. This method might involve techniques to focus learning on specific parts of the MM-DIT model, perhaps targeting layers or modules responsible for stylistic elements. Understanding how the tuning process affects both visual and textual aspects is important, ensuring style consistency and text-image alignment in the final output. Careful analysis of the tuning process, involving techniques such as SNR manipulation to bias the training towards style-specific features, could lead to significant performance gains. The success of this approach would depend on efficient parameter selection and a deep understanding of the MM-DIT architecture and how different components influence the generation process.
Future Work#
Future research directions stemming from this Style-friendly SNR Sampler paper could explore several promising avenues. Extending the approach to other generative models beyond diffusion models would broaden applicability and impact. Investigating alternative SNR sampling strategies, such as employing different distributions or adaptive sampling schemes based on the specific style, could further improve style capture. A key area is developing more robust methods for handling diverse and complex styles, potentially incorporating techniques from style transfer or disentanglement learning. Addressing the computational cost of fine-tuning remains crucial; exploring more efficient training methods or lightweight architectural adaptations would be valuable. Finally, a significant direction is deeper investigation into the interplay between different noise levels and style emergence, potentially leading to a better theoretical understanding of the underlying generative process.
More visual insights#
More on figures

🔼 This figure demonstrates the ability of different models to learn and apply styles during fine-tuning. In (a), the FLUX model successfully learns object characteristics, resulting in a correctly generated image of the object in a new context. (b) shows that the same model fails to accurately capture the stylistic elements of the reference image (red box), leading to a generated image that lacks the desired artistic style. In (c), the authors’ proposed method successfully learns and applies the stylistic features of the reference image (red box), highlighting the effectiveness of their approach.
read the caption
Figure 2: Fine-tuning capability. While FLUX succeeds in learning objects (a), it struggles to capture styles (b). We enable FLUX to learn styles (c). References are shown in the red insert box.

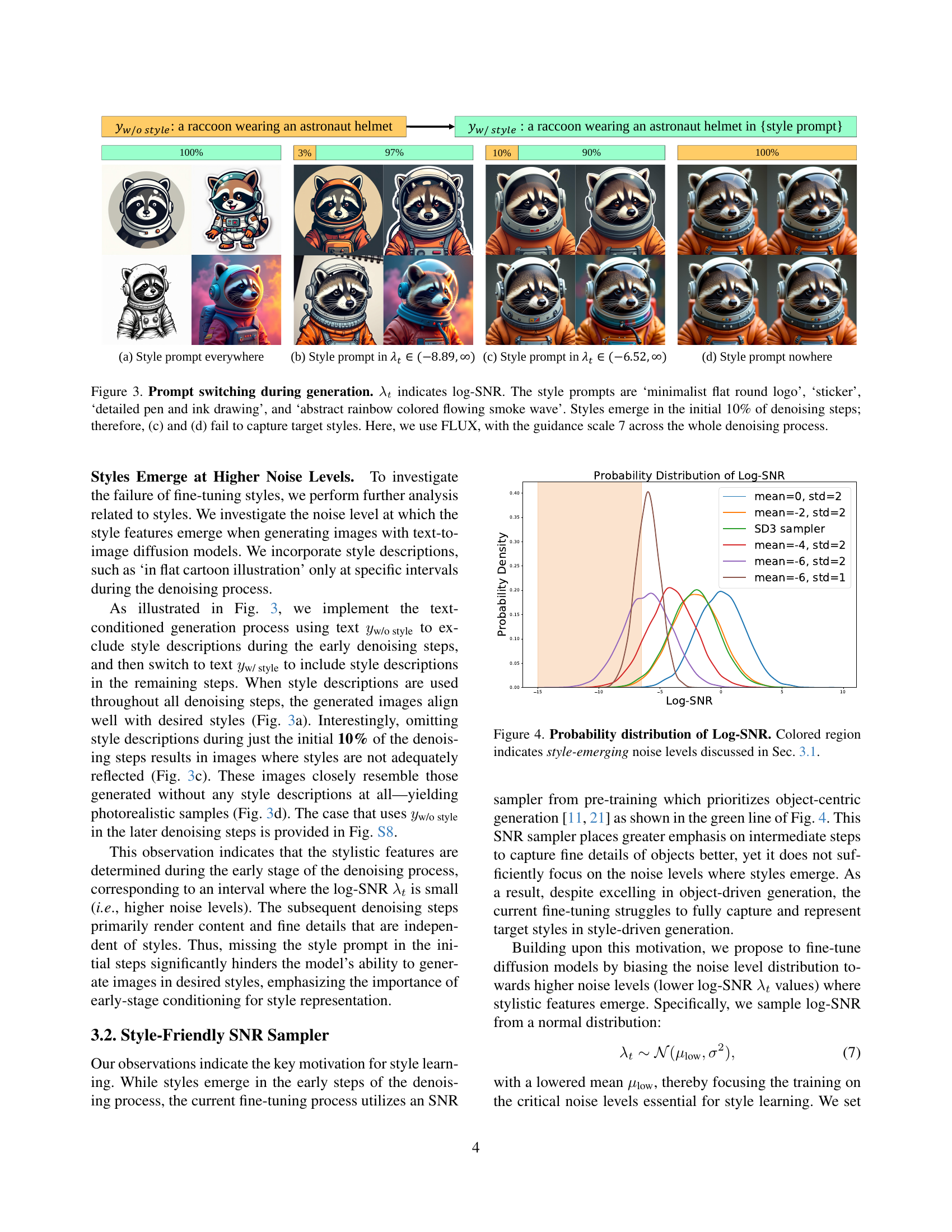
🔼 This figure demonstrates the impact of incorporating style prompts at different stages of the image generation process using diffusion models. Four variations are shown: (a) consistently applies the style prompt throughout the generation; (b) applies the style prompt only after the initial 10% of denoising steps, when log-SNR (λₜ) values indicate higher noise levels; (c) applies the style prompt only in a range of log-SNR values corresponding to when style features start to emerge; and (d) does not apply the style prompt at all. The experiment uses the FLUX model with a guidance scale of 7. The results show that style information is primarily learned during the initial 10% of denoising, explaining why (c) and (d) fail to accurately generate the target styles. Different style prompts were used to showcase the effect across various stylistic choices.
read the caption
Figure 3: Prompt switching during generation. λtsubscript𝜆𝑡\lambda_{t}italic_λ start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT indicates log-SNR. The style prompts are ‘minimalist flat round logo’, ‘sticker’, ‘detailed pen and ink drawing’, and ‘abstract rainbow colored flowing smoke wave’. Styles emerge in the initial 10% of denoising steps; therefore, (c) and (d) fail to capture target styles. Here, we use FLUX, with the guidance scale 7 across the whole denoising process.

🔼 This figure displays the probability distribution of the log-SNR (logarithm of the signal-to-noise ratio) used during the training of diffusion models. The x-axis represents the log-SNR values, and the y-axis represents the probability density. Different colored curves show the distributions for different mean values of log-SNR, while maintaining the standard deviation constant. The colored region highlights the log-SNR range where stylistic features of generated images are observed to emerge, as discussed in Section 3.1 of the paper.
read the caption
Figure 4: Probability distribution of Log-SNR. Colored region indicates style-emerging noise levels discussed in Sec. 3.1.

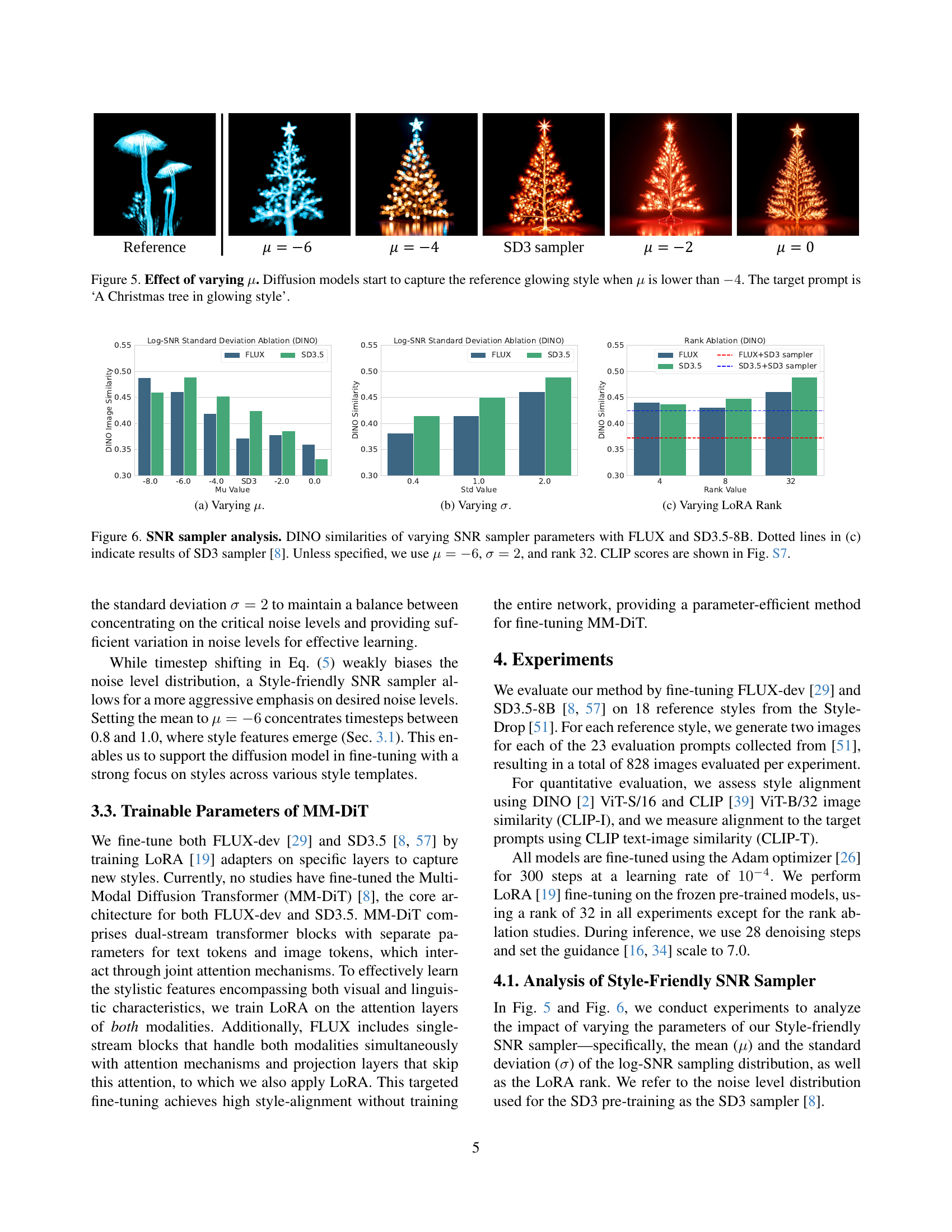
🔼 This figure demonstrates how varying the mean (μ) of the log-SNR distribution during training affects the ability of diffusion models to capture and generate specific styles. As the mean (μ) decreases (becomes more negative), moving the distribution towards higher noise levels, the model increasingly captures the reference ‘glowing’ style in the generated Christmas tree images. When μ is -4 or higher, the glowing style is not well captured, demonstrating that lower μ values are essential for learning this particular style effectively. The experiment highlights the importance of carefully tuning the log-SNR distribution for optimal style-driven generation.
read the caption
Figure 5: Effect of varying μ𝜇\muitalic_μ. Diffusion models start to capture the reference glowing style when μ𝜇\muitalic_μ is lower than −44-4- 4. The target prompt is ‘A Christmas tree in glowing style’.

🔼 The figure shows the effect of varying the mean (µ) of the log-SNR distribution used during the fine-tuning process of diffusion models. Different values of µ bias the noise level distribution towards different noise levels. Lower values of µ focus more on higher noise levels, where stylistic features tend to emerge, resulting in better style capture and generation. The plot shows the DINO similarity scores, a measure of style alignment, for different values of µ for both FLUX and SD3.5 diffusion models. The results show that lower values of µ lead to higher DINO similarity scores, indicating better style alignment.
read the caption
(a) Varying μ𝜇\muitalic_μ.

🔼 This figure shows the results of an ablation study on the standard deviation (σ) of the log-SNR sampling distribution used in the Style-friendly SNR sampler. It demonstrates how the variation in σ impacts the DINO similarity score of generated images when compared to images generated using FLUX and SD3.5. Different values of σ were tested to show how this hyperparameter influences style alignment during fine-tuning.
read the caption
(b) Varying σ𝜎\sigmaitalic_σ.

🔼 This figure shows the result of an ablation study on the impact of LoRA rank on style learning. It demonstrates how the model’s ability to capture and reproduce stylistic features changes as the dimensionality of the LoRA adapters is varied. This is done by measuring DINO similarity. The x-axis represents different LoRA ranks, while the y-axis shows the DINO similarity score. The figure helps to determine the optimal LoRA rank for balancing model capacity and stylistic accuracy in style-driven generation.
read the caption
(c) Varying LoRA Rank

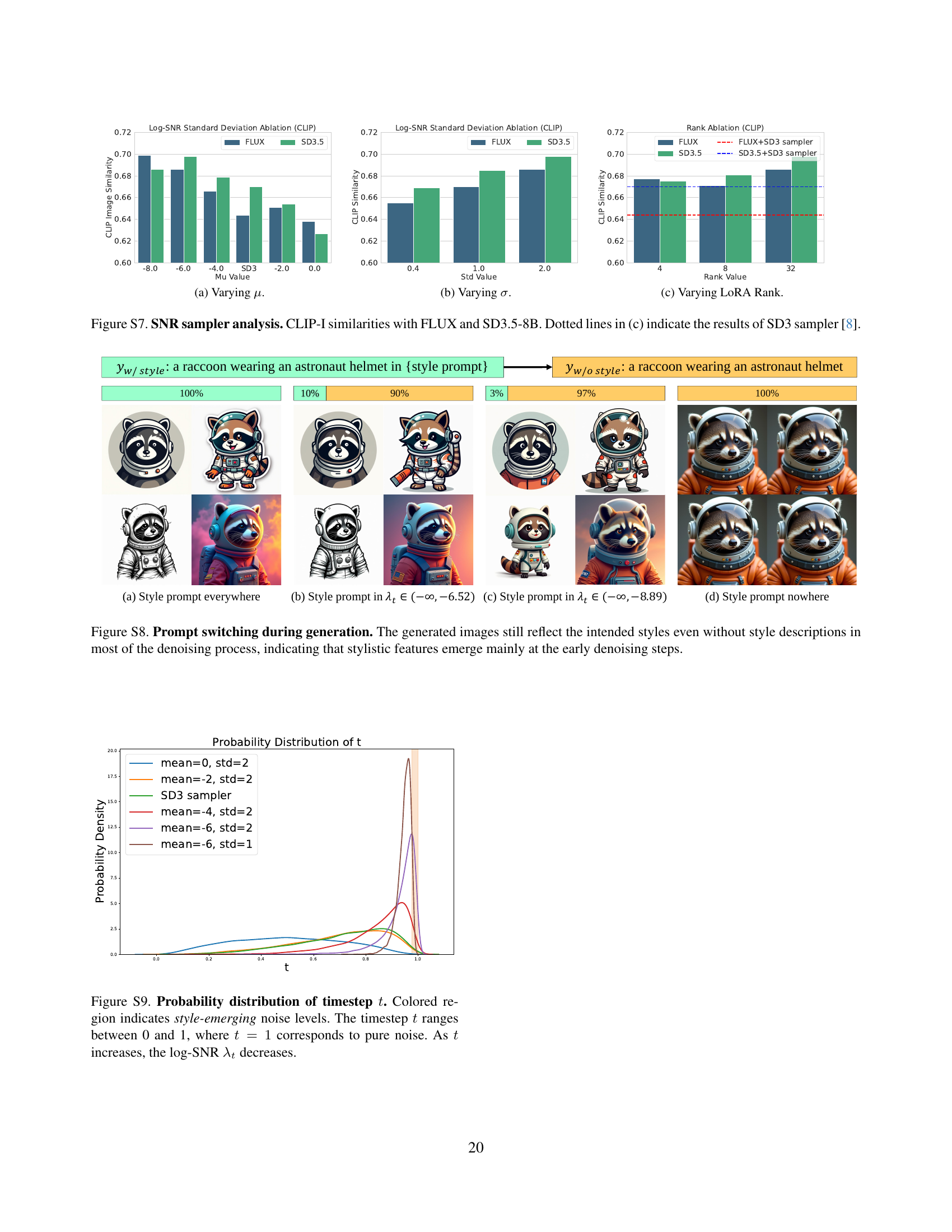
🔼 This figure analyzes the performance of the Style-friendly SNR sampler by varying its parameters (μ, σ, and LoRA rank) and comparing its results with those of the standard SD3 sampler and FLUX. The DINO similarity metric is used to evaluate the style alignment for each configuration. The dotted lines in (c) represent the results obtained using the SD3 sampler as a baseline. Unless specified, the Style-friendly sampler was configured with μ = -6, σ = 2, and a LoRA rank of 32. The figure also references Figure S7 for corresponding CLIP scores, providing a more comprehensive analysis of the sampler’s effectiveness.
read the caption
Figure 6: SNR sampler analysis. DINO similarities of varying SNR sampler parameters with FLUX and SD3.5-8B. Dotted lines in (c) indicate results of SD3 sampler [8]. Unless specified, we use μ=−6𝜇6\mu=-6italic_μ = - 6, σ=2𝜎2\sigma=2italic_σ = 2, and rank 32. CLIP scores are shown in Fig. S7.

🔼 Figure 7 displays a qualitative comparison of various style-based image generation methods. Each row represents a different approach (Style-friendly, SD3 sampler, DCO, IP-Adapter, RB-Modulation, and Style-Aligned), and each column depicts a different style prompt applied to the same base image. This allows for visual comparison of how well each method captures the stylistic elements (color schemes, layout, illumination, brushstrokes) from the reference image (shown in the first row). The fact that all samples share the same seed emphasizes the effect of the method itself on style generation rather than randomness.
read the caption
Figure 7: Qualitative comparison. All samples are generated with the same seed. Please zoom in.

🔼 Figure 8 showcases the model’s ability to generate multiple coherent images within a single image, as demonstrated in the first row. The example shows a multi-panel comic strip. The second row illustrates the model’s capacity for generating customized typography with unique styles, showcasing different font styles and designs.
read the caption
Figure 8: Multi-panel and typography. First row demonstrates generating multiple coherent images as a single image. Second row shows customized typography with a unique style.

🔼 This figure displays generated images demonstrating the model’s ability to adapt to various artistic styles. Two sets of prompts were used: ‘a cute city made of sushi in {style prompt} style’ and ‘mischievous ferret with a playful grin squeezes itself into a large glass jar, in {style prompt} style’. Each row showcases images generated from the same random seed but with different style prompts substituted into the bracketed section. This highlights the model’s capacity to maintain image consistency while changing its stylistic features based on the input style prompt. The resolution of each image is 1216x832 pixels.
read the caption
Figure S1: Additional samples. Each row shows images generated with the same random seed at a resolution of 1216×832, using the prompts “a cute city made of sushi in {style prompt} style” and “mischievous ferret with a playful grin squeezes itself into a large glass jar, in {style prompt} style”.

🔼 This figure demonstrates the model’s ability to generate stylized text. The first column shows example reference images showcasing different artistic styles. The second and third columns present text generated by the model in those styles at a resolution of 832x1216 pixels, while the fourth column shows text generated at 704x1408 pixels. The model was prompted with the phrase: ’the words that say ‘{letters}’ are written in English, in {style prompt} style’, where ‘{letters}’ represents the specific words to be generated and ‘{style prompt}’ specifies the desired artistic style (e.g., ‘minimalist flat round logo’, ‘sticker’, ‘detailed pen and ink drawing’, ‘abstract rainbow colored flowing smoke wave’).
read the caption
Figure S2: Typography. The first column shows reference images. The second and third columns display samples generated at a resolution of 832×1216, and the fourth column presents samples at 704×1408 resolution. The prompts used are “the words that says ‘{letters}’ are written in English, in {style prompt} style”, where ‘{letters}’ represents the words synthesized in the samples.

🔼 Figure S3 presents a qualitative comparison of different image generation methods on multi-panel comic style images. The Style-friendly approach is shown to generate images that closely match the reference style, while other methods struggle to replicate the complex style elements. The comparison includes four different image prompts: a close-up of a sloth with a hat using a laptop, a banana, a Christmas tree, and a park bench. Each prompt was applied to various image generation methods, demonstrating the superior performance of the Style-friendly approach in capturing the detailed style elements of a multi-panel comic style.
read the caption
Figure S3: Additional qualitative comparison. Our Style-friendly approach successfully captures complex multi-panel styles, generating images that closely resemble the reference. The prompts used are “A fluffy baby sloth with a knitted hat trying to figure out a laptop, close up in {style prompt} style”, “A banana in {style prompt} style”, “A Christmas tree in {style prompt} style”, and “A bench in {style prompt} style”.

🔼 Figure S4 presents a qualitative comparison of different methods for generating images with a multi-panel comic style. The reference image shows a multi-panel comic strip. Our Style-Friendly SNR Sampler successfully generates images that closely match the structure and style of the reference, demonstrating its ability to learn and apply complex stylistic elements. In contrast, several zero-shot methods (IP-Adapter, RB-Modulation, and Style-Aligned) fail to accurately capture the multi-panel structure. They either produce images with a different number of panels, a different arrangement of panels, or introduce artifacts that detract from the overall visual coherence. This comparison highlights the effectiveness of the Style-Friendly SNR Sampler in learning and applying highly structured styles compared to the shortcomings of zero-shot methods in similar tasks.
read the caption
Figure S4: Additional qualitative comparison. Our method effectively captures the multi-panel style, whereas zero-shot methods generate images with different structures or introduce artifacts.

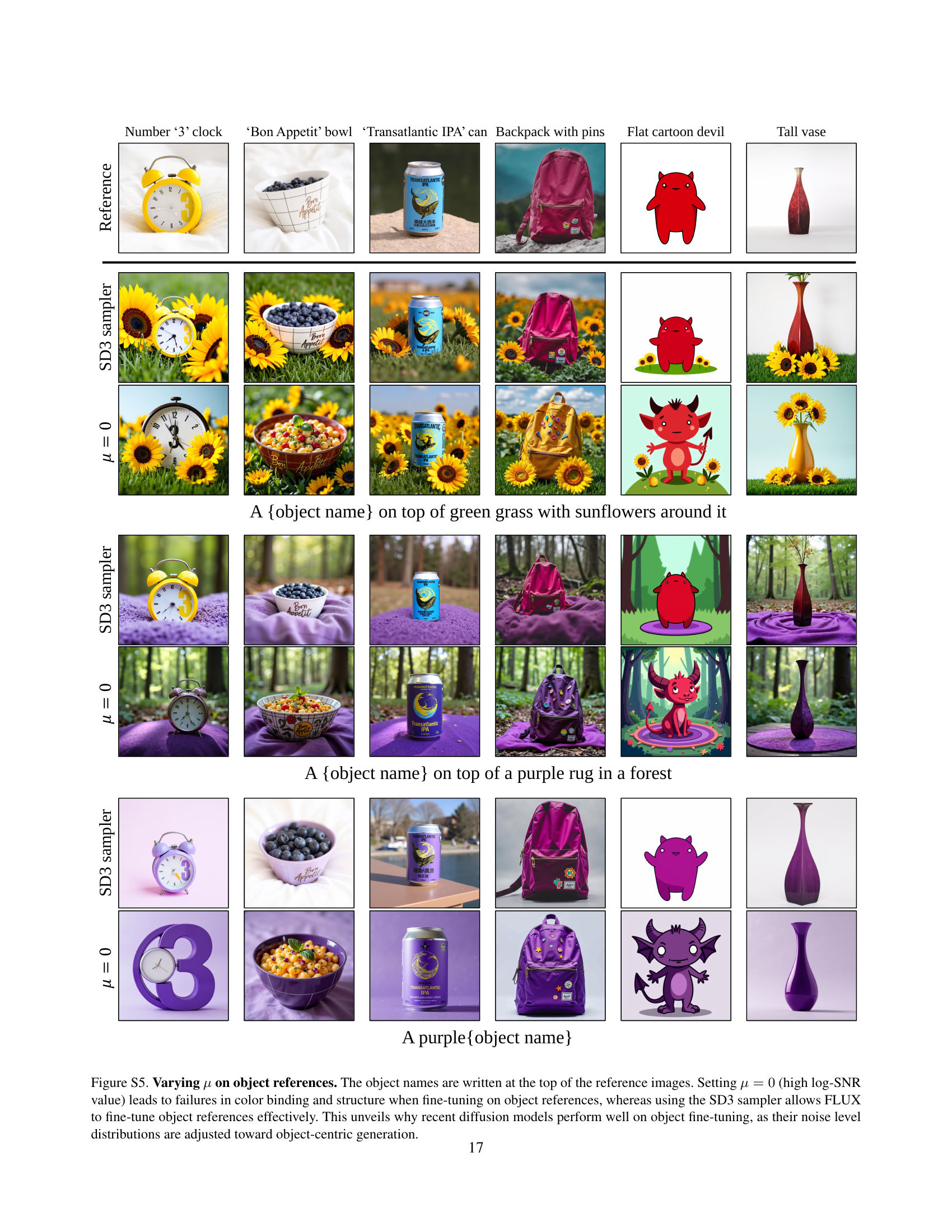
🔼 This figure demonstrates the impact of the mean (μ) parameter in the Style-friendly SNR sampler on the fine-tuning of object references in diffusion models. When μ is set to 0 (representing a high log-SNR value), the fine-tuning process fails to accurately capture color relationships and structural details within the objects. In contrast, using the SD3 sampler, which is pre-trained with a specific noise level distribution, allows the FLUX model to successfully fine-tune on the object references. This experiment highlights the importance of carefully considering the noise level distribution during model training, especially when focusing on object-centric characteristics, in contrast to style-centric ones. This difference explains why many current diffusion models successfully fine-tune for object-centric generation tasks.
read the caption
Figure S5: Varying μ𝜇\muitalic_μ on object references. The object names are written at the top of the reference images. Setting μ=0𝜇0\mu=0italic_μ = 0 (high log-SNR value) leads to failures in color binding and structure when fine-tuning on object references, whereas using the SD3 sampler allows FLUX to fine-tune object references effectively. This unveils why recent diffusion models perform well on object fine-tuning, as their noise level distributions are adjusted toward object-centric generation.

🔼 This figure compares the results of fine-tuning the Stable Diffusion 3.5-8B model using three different methods: the Style-friendly SNR sampler (proposed in this paper), the SD3 sampler (a baseline method), and Direct Consistency Optimization (DCO, another baseline method). Each method was used to generate images based on the same set of reference images and prompts. The images generated using the Style-friendly SNR sampler are shown alongside those generated by the SD3 sampler and DCO to illustrate the differences in style capture and overall image quality. The results shown for SD3.5-8B are consistent with the qualitative comparisons shown in Figure 7 which used the FLUX model. This visual comparison demonstrates the effectiveness of the Style-friendly SNR sampler in achieving high-fidelity style transfer.
read the caption
Figure S6: Comparison of fine-tuning the SD3.5-8B. The results with SD3.5-8B are consistent with the qualitative comparison based on FLUX-dev presented in Fig. 7.

🔼 The figure shows the effect of varying the mean (μ) of the log-SNR distribution on the DINO similarity score. The DINO similarity score measures the style alignment of images generated by diffusion models fine-tuned with different values of μ. The figure shows that as μ increases, the DINO similarity score decreases, indicating that the model’s ability to capture the reference style worsens. This suggests that using a lower μ value (μ = -6 or lower) during fine-tuning helps the model to learn the reference style more effectively. The x-axis represents the μ values and the y-axis represents the DINO similarity scores.
read the caption
(a) Varying μ𝜇\muitalic_μ.

🔼 The figure shows the result of varying the standard deviation (σ) of the log-SNR sampling distribution during the training of diffusion models. It demonstrates how different standard deviations affect the model’s ability to capture and reflect the stylistic aspects of reference images during fine-tuning. The x-axis represents different values of σ, and the y-axis represents the DINO similarity score. The plot shows how a balance is needed in σ for optimal style learning; too small a σ limits exploration of noise levels, while too large a σ may lead to instability and thus reduce similarity to the desired styles.
read the caption
(b) Varying σ𝜎\sigmaitalic_σ.

🔼 This figure shows the impact of varying the rank of the LoRA (Low-Rank Adaptation) model on the performance of the Style-Friendly SNR sampler for style-driven image generation. It is part of an ablation study assessing the impact of different hyperparameters on the model’s ability to capture and reproduce artistic styles from reference images. The x-axis shows different LoRA ranks, indicating the model’s capacity. The y-axis represents a similarity score, such as DINO similarity, measuring the alignment between generated images and reference style images. The plot helps to determine the optimal LoRA rank that balances model capacity with performance.
read the caption
(c) Varying LoRA Rank.

🔼 This figure analyzes the performance of the Style-friendly SNR sampler by varying its parameters (mean (µ), standard deviation (σ), and LoRA rank). It compares the results obtained using the proposed sampler with those from the standard SD3 sampler on two different diffusion models: FLUX and SD3.5-8B. The CLIP-I (CLIP Image Similarity) metric is used to evaluate style alignment, measuring how similar the generated images are to the reference style images. The plots demonstrate the effect of varying µ, σ, and the LoRA rank on style alignment, showing how the optimal parameters of the Style-friendly SNR sampler lead to improved style capture compared to the standard SD3 sampler.
read the caption
Figure S7: SNR sampler analysis. CLIP-I similarities with FLUX and SD3.5-8B. Dotted lines in (c) indicate the results of SD3 sampler [8].

🔼 This figure demonstrates the importance of early-stage style conditioning in diffusion models. Four variations of a prompt were used during image generation: 1) style prompt present throughout the process, 2) style prompt present only in the latter steps, 3) style prompt present only in the very early steps, and 4) no style prompt. The results show that stylistic features emerge during the early denoising stages (high noise levels). Therefore, omitting style descriptions during only the initial steps is sufficient to prevent styles from being properly incorporated, while adding the prompt only to the later stages still results in the style being included, albeit possibly less prominently.
read the caption
Figure S8: Prompt switching during generation. The generated images still reflect the intended styles even without style descriptions in most of the denoising process, indicating that stylistic features emerge mainly at the early denoising steps.
More on tables
| Method | Model | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|---|
| Style-Aligned [14] | SDXL | 0.410 | 0.675 | 0.340 |
| RB-Mod [44] | Cascade | 0.317 | 0.647 | 0.363 |
| DCO [30] | SD3.5 | 0.399 | 0.661 | 0.355 |
| SD3 sampler [8] | SD3.5 | 0.424 | 0.670 | 0.350 |
| Style-friendly | SD3.5 | 0.489 | 0.698 | 0.349 |
| IP-Adapter [61] | FLUX-dev | 0.361 | 0.656 | 0.354 |
| DCO [30] | FLUX-dev | 0.373 | 0.643 | 0.353 |
| SD3 sampler [8] | FLUX-dev | 0.373 | 0.645 | 0.350 |
| Style-friendly | FLUX-dev | 0.461 | 0.686 | 0.344 |
🔼 This table presents a quantitative comparison of different methods for style-driven image generation, using 18 different styles from a reference dataset. The metrics used are DINO and CLIP-I for style alignment (how well the generated image matches the style of the reference image), and CLIP-T for text alignment (how well the generated image matches the text description). The results show that the ‘Style-friendly’ method achieves superior style alignment scores compared to other baselines.
read the caption
Table 2: Quantitative comparison. Style alignment (DINO and CLIP-I) and text alignment (CLIP-T) with 18 styles from [51]. Our style-friendly exhibits superior style-alignment scores.
| Method | Model | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|---|
| SD3 Sampler [8] | FLUX-dev | 0.373 | 0.645 | 0.350 |
| w/ rank 128 | FLUX-dev | 0.426 | 0.668 | 0.345 |
| Style-friendly | FLUX-dev | 0.461 | 0.686 | 0.344 |
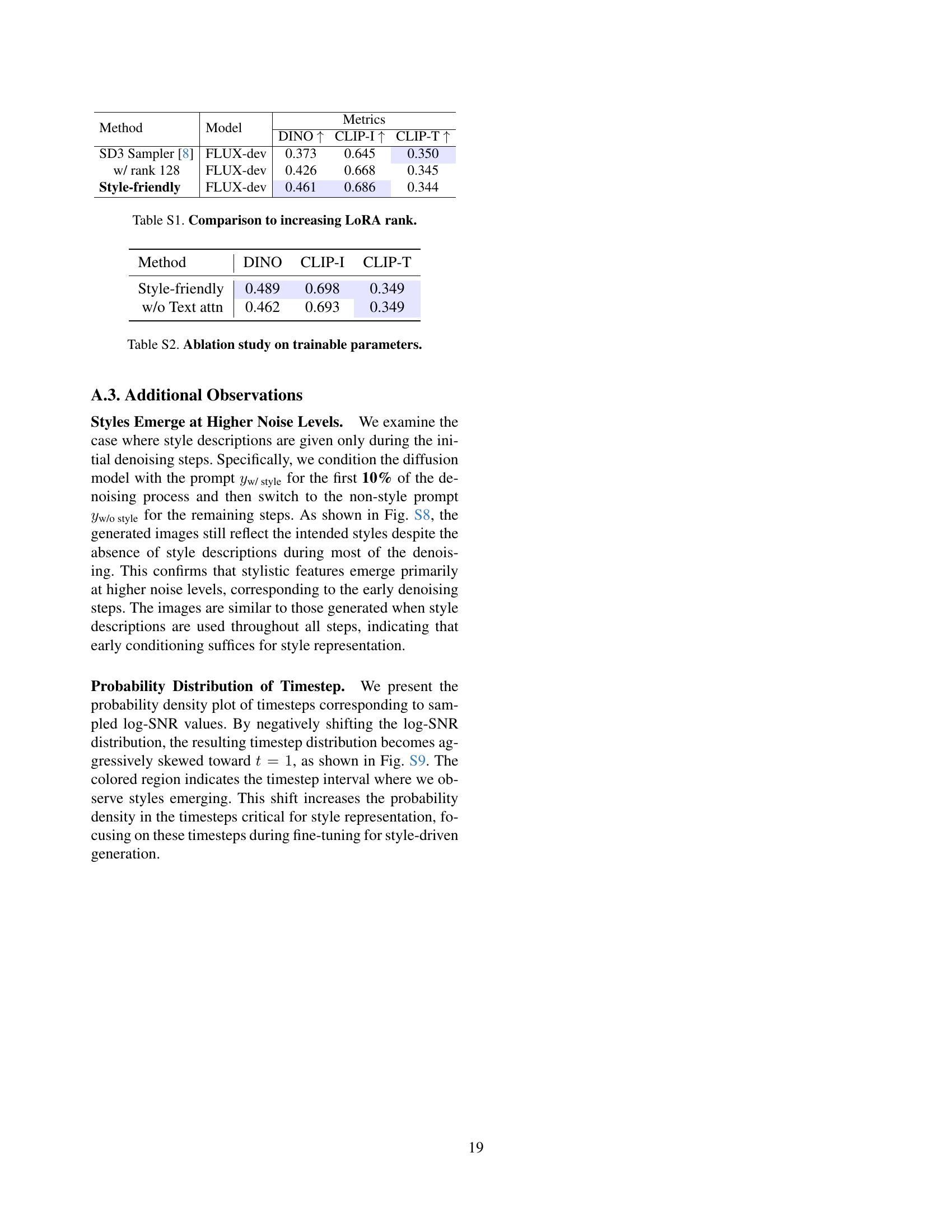
🔼 This table compares the performance of the Style-friendly SNR sampler against a baseline method where only the LoRA rank is increased. It shows the DINO and CLIP image similarity scores, and CLIP text similarity scores for both methods. The results demonstrate that Style-friendly SNR sampler outperforms the baseline even when the baseline method uses a higher LoRA rank, indicating that the proposed method is more effective than simply increasing model capacity.
read the caption
Table S1: Comparison to increasing LoRA rank.
| Method | DINO | CLIP-I | CLIP-T |
|---|---|---|---|
| Style-friendly | 0.489 | 0.698 | 0.349 |
| w/o Text attn | 0.462 | 0.693 | 0.349 |
🔼 This table presents the results of an ablation study investigating the impact of different trainable parameters on the performance of the Style-friendly SNR sampler. It compares the performance of the model when fine-tuning only the image transformer blocks versus fine-tuning both image and text transformer blocks of the MM-DiT architecture. The metrics used for comparison include DINO and CLIP image similarity scores (CLIP-I) as well as CLIP text-image similarity scores (CLIP-T) to evaluate style and text alignment, respectively.
read the caption
Table S2: Ablation study on trainable parameters.
| Method | Model | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|---|
| SD3 Sampler [8] | SD3.5 | 0.424 | 0.670 | 0.350 |
| w/ offset 0.1 | SD3.5 | 0.452 | 0.678 | 0.353 |
| Style-friendly | SD3.5 | 0.489 | 0.698 | 0.349 |
| w/ offset 0.01 | SD3.5 | 0.476 | 0.697 | 0.350 |
| SD3 Sampler [8] | FLUX-dev | 0.373 | 0.645 | 0.350 |
| w/ offset 0.1 | FLUX-dev | 0.451 | 0.679 | 0.349 |
| Style-friendly | FLUX-dev | 0.461 | 0.686 | 0.344 |
| w/ offset 0.01 | FLUX-dev | 0.500 | 0.704 | 0.341 |
🔼 Table S3 presents a quantitative comparison of different methods for style-driven image generation. It shows the results of using the SD3 sampler, with and without added offset noise, and the Style-friendly SNR sampler, both on SD3.5 and FLUX-dev models. The metrics used are DINO and CLIP image similarity scores (CLIP-I) and CLIP text-image similarity scores (CLIP-T), measuring style and text alignment. The table demonstrates that adding offset noise improves results with the SD3 sampler, but it still doesn’t outperform the Style-friendly SNR sampler. Moreover, when the Style-friendly approach is combined with a small amount of offset noise, it leads to a slight improvement in style alignment, particularly with the FLUX-dev model.
read the caption
Table S3: Incorporating offset noise. Offset noise improves SD3 sampler but still does not reach the performance of our Style-friendly SNR sampler; combining our Style-friendly approach with Offset Noise at a smaller scale (0.01) slightly enhances the style alignment of FLUX-dev.
Full paper#