↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current VideoQA datasets suffer from limited scale and insufficient granularity, hindering the development of effective video reasoning models. Existing datasets heavily rely on costly manual annotations and often lack the detail needed for complex reasoning tasks. Automatic methods exist, but these often create redundant data via frame-by-frame analysis, thus limiting scalability and efficiency.
This paper introduces VideoEspresso, a novel, large-scale dataset designed to address these limitations. It utilizes a semantic-aware method to automatically generate high-quality VideoQA pairs. Furthermore, the paper introduces a novel Hybrid LVLMs Collaboration framework that combines a frame selector with a two-stage instruction fine-tuned LVLM to perform efficient and accurate video reasoning. The framework and dataset are rigorously evaluated against existing methods, showcasing superior performance on various video reasoning tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video understanding and large vision language models (LVLMs). It addresses the scarcity of high-quality datasets for video reasoning, introducing a novel dataset, VideoEspresso, that will significantly advance the field. The proposed Hybrid LVLMs Collaboration framework also presents a new approach for efficient video reasoning, opening up exciting avenues for future work in improving the capabilities of LVLMs in handling complex video tasks. The automatic construction of VideoEspresso reduces reliance on costly manual annotations, facilitating the creation of larger and higher-quality video reasoning datasets.
Visual Insights#

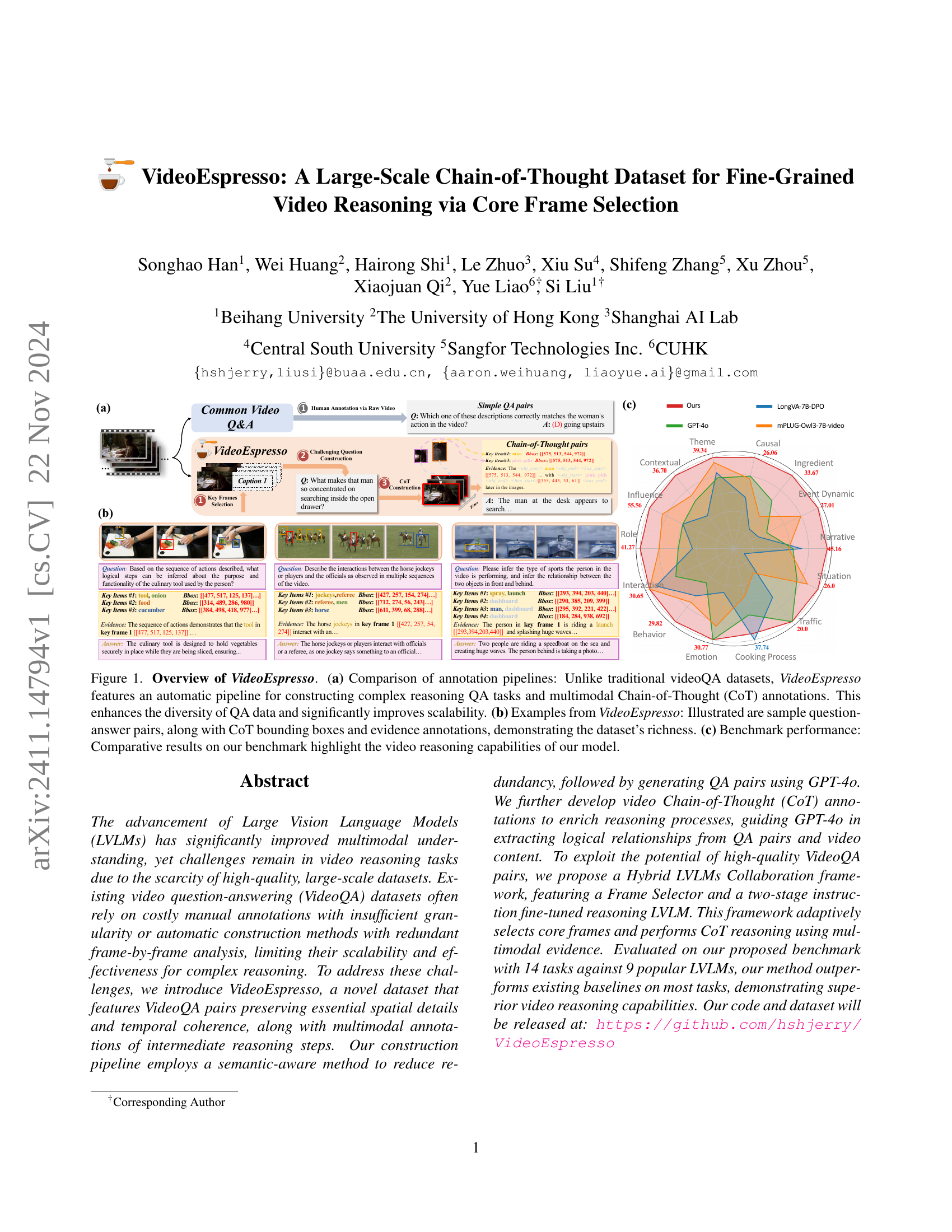
🔼 Figure 1 provides a comprehensive overview of the VideoEspresso dataset. Panel (a) contrasts the annotation process of VideoEspresso with traditional videoQA datasets, highlighting VideoEspresso’s automated pipeline for generating complex reasoning questions and multimodal Chain-of-Thought (CoT) annotations. This automation leads to a more diverse and scalable dataset. Panel (b) showcases example question-answer pairs from VideoEspresso, illustrating the inclusion of CoT bounding boxes and evidence annotations, which enrich the dataset’s complexity and provide more detailed reasoning information. Panel (c) presents benchmark performance results, comparing various Large Vision Language Models (LVLMs) on the VideoEspresso benchmark and highlighting the superior video reasoning capabilities of the proposed model.
read the caption
Figure 1: Overview of VideoEspresso. (a) Comparison of annotation pipelines: Unlike traditional videoQA datasets, VideoEspresso features an automatic pipeline for constructing complex reasoning QA tasks and multimodal Chain-of-Thought (CoT) annotations. This enhances the diversity of QA data and significantly improves scalability. (b) Examples from VideoEspresso: Illustrated are sample question-answer pairs, along with CoT bounding boxes and evidence annotations, demonstrating the dataset’s richness. (c) Benchmark performance: Comparative results on our benchmark highlight the video reasoning capabilities of our model.
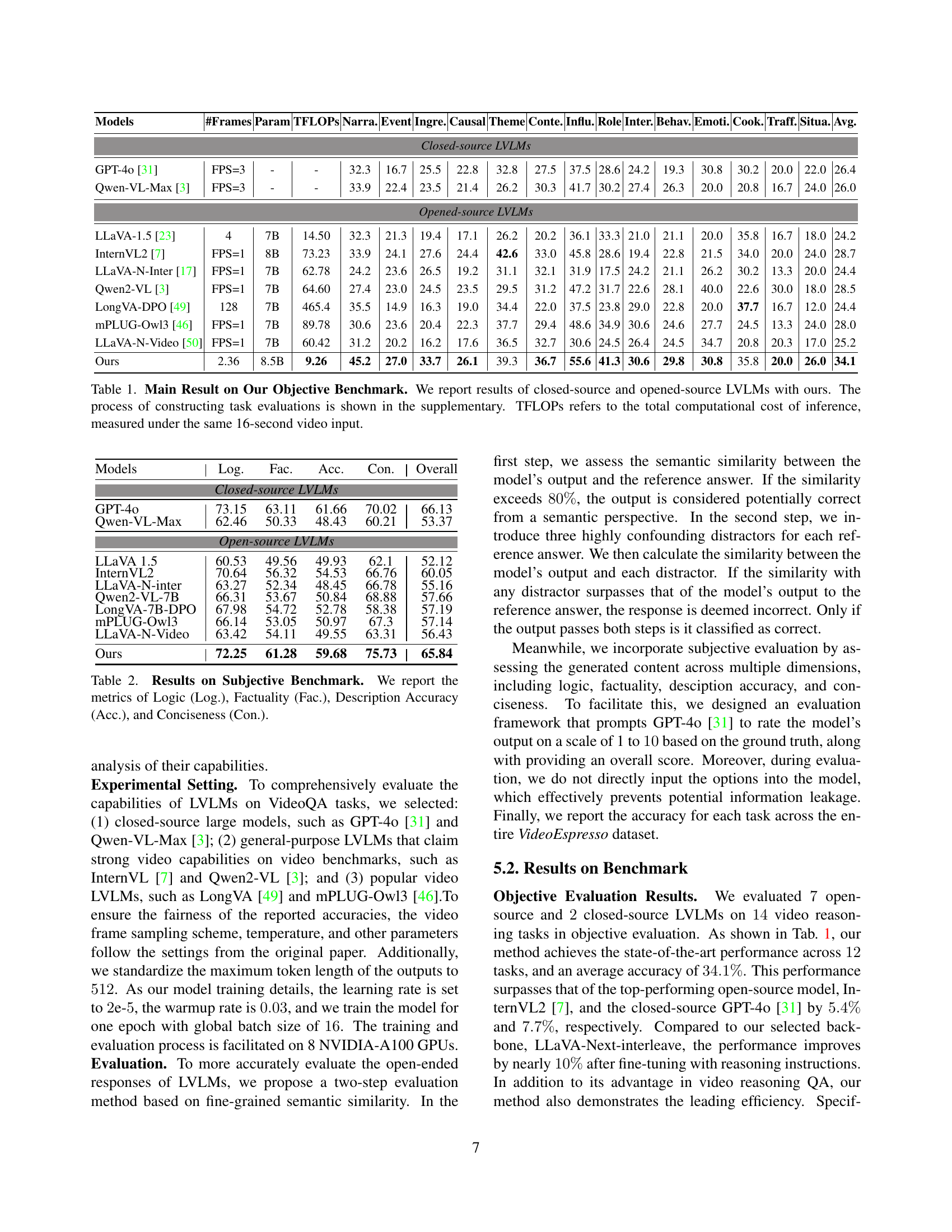
| Models | #Frames | Param | TFLOPs | Narra. | Event | Ingre. | Causal | Theme | Conte. | Influ. | Role | Inter. | Behav. | Emoti. | Cook. | Traff. | Situa. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Closed-source LVLMs | ||||||||||||||||||
| GPT-4o [31] | FPS=3 | - | - | 32.3 | 16.7 | 25.5 | 22.8 | 32.8 | 27.5 | 37.5 | 28.6 | 24.2 | 19.3 | 30.8 | 30.2 | 20.0 | 22.0 | 26.4 |
| Qwen-VL-Max [3] | FPS=3 | - | - | 33.9 | 22.4 | 23.5 | 21.4 | 26.2 | 30.3 | 41.7 | 30.2 | 27.4 | 26.3 | 20.0 | 20.8 | 16.7 | 24.0 | 26.0 |
| Opened-source LVLMs | ||||||||||||||||||
| LLaVA-1.5 [23] | 4 | 7B | 14.50 | 32.3 | 21.3 | 19.4 | 17.1 | 26.2 | 20.2 | 36.1 | 33.3 | 21.0 | 21.1 | 20.0 | 35.8 | 16.7 | 18.0 | 24.2 |
| InternVL2 [7] | FPS=1 | 8B | 73.23 | 33.9 | 24.1 | 27.6 | 24.4 | 42.6 | 33.0 | 45.8 | 28.6 | 19.4 | 22.8 | 21.5 | 34.0 | 20.0 | 24.0 | 28.7 |
| LLaVA-N-Inter [17] | FPS=1 | 7B | 62.78 | 24.2 | 23.6 | 26.5 | 19.2 | 31.1 | 32.1 | 31.9 | 17.5 | 24.2 | 21.1 | 26.2 | 30.2 | 13.3 | 20.0 | 24.4 |
| Qwen2-VL [3] | FPS=1 | 7B | 64.60 | 27.4 | 23.0 | 24.5 | 23.5 | 29.5 | 31.2 | 47.2 | 31.7 | 22.6 | 28.1 | 40.0 | 22.6 | 30.0 | 18.0 | 28.5 |
| LongVA-DPO [49] | 128 | 7B | 465.4 | 35.5 | 14.9 | 16.3 | 19.0 | 34.4 | 22.0 | 37.5 | 23.8 | 29.0 | 22.8 | 20.0 | 37.7 | 16.7 | 12.0 | 24.4 |
| mPLUG-Owl3 [46] | FPS=1 | 7B | 89.78 | 30.6 | 23.6 | 20.4 | 22.3 | 37.7 | 29.4 | 48.6 | 34.9 | 30.6 | 24.6 | 27.7 | 24.5 | 13.3 | 24.0 | 28.0 |
| LLaVA-N-Video [50] | FPS=1 | 7B | 60.42 | 31.2 | 20.2 | 16.2 | 17.6 | 36.5 | 32.7 | 30.6 | 24.5 | 26.4 | 24.5 | 34.7 | 20.8 | 20.3 | 17.0 | 25.2 |
| Ours | 2.36 | 8.5B | 9.26 | 45.2 | 27.0 | 33.7 | 26.1 | 39.3 | 36.7 | 55.6 | 41.3 | 30.6 | 29.8 | 30.8 | 35.8 | 20.0 | 26.0 | 34.1 |
🔼 Table 1 presents the performance comparison of various Large Vision Language Models (LVLMs) on the VideoEspresso benchmark. It includes both closed-source models (like GPT-4) and open-source models (like LLaVA). The table shows the average accuracy across 14 different video reasoning tasks, categorized by the type of reasoning involved. Each LVLMs’ performance is shown in terms of accuracy for each task, alongside metadata including the number of frames processed, model parameters (in billions), and the total TeraFLOPs (TFLOPS) of computation required for a 16-second video. This allows a comprehensive comparison of accuracy, efficiency, and computational cost across various LVLMs.
read the caption
Table 1: Main Result on Our Objective Benchmark. We report results of closed-source and opened-source LVLMs with ours. The process of constructing task evaluations is shown in the supplementary. TFLOPs refers to the total computational cost of inference, measured under the same 16-second video input.
In-depth insights#
Video Reasoning#
Video reasoning, as explored in the research paper, presents a significant challenge in artificial intelligence due to the complexity of video data and the need for nuanced understanding. The paper highlights the scarcity of high-quality, large-scale datasets suitable for training robust video reasoning models, emphasizing the limitations of existing datasets which often rely on costly manual annotation or lack granularity. The development of VideoEspresso, a novel dataset with detailed annotations including spatial and temporal information, is a key contribution, designed to address these shortcomings and facilitate improved model performance. The use of chain-of-thought annotations within VideoEspresso is particularly noteworthy, providing explicit guidance for models on intermediate reasoning steps. This innovative approach focuses on fine-grained video reasoning, going beyond basic question-answering tasks to capture more complex relationships and logical inferences. The study’s results demonstrate that models trained on VideoEspresso showcase superior reasoning capabilities, effectively utilizing core frames and multimodal information for accurate video understanding.
Hybrid LVLM#
The concept of a “Hybrid LVLM” for video question answering (VideoQA) is particularly interesting. It suggests a system that combines the strengths of different Large Vision Language Models (LVLMs). This approach likely involves a lightweight, efficient model for tasks like core frame selection from videos, which reduces computational costs associated with processing the entire video. This initial processing stage is crucial because it helps to focus the attention of a more powerful, but computationally expensive, LVLM on the most relevant parts of the video. The combination of a fast, smaller model with a more comprehensive model could enable VideoQA systems to handle complex reasoning tasks effectively and efficiently. The choice of LVLMs within this hybrid architecture would depend heavily on the specific needs. For example, a smaller model might be based on an efficient transformer architecture designed for speed, while the larger model might be a state-of-the-art model known for its powerful reasoning capabilities. This hybrid approach would offer a good balance between accuracy and resource efficiency, making it suitable for real-world applications that require fast and accurate responses.
Dataset Creation#
The creation of a robust and effective dataset is paramount for advancing video reasoning research. The authors meticulously address this by designing a semantic-aware key information extraction method to identify crucial video content and minimize redundancy. This process strategically moves beyond simple frame-by-frame analysis, acknowledging the often-sparse nature of salient information within videos. Subsequently, the incorporation of GPT-40 for generating QA pairs leverages the power of LLMs to create diverse and complex questions and answers directly grounded in the video content. A further enhancement involves the development of multimodal Chain-of-Thought (CoT) annotations, guiding GPT-40 to extract and annotate key spatial and temporal relationships within the videos. This innovative approach is crucial for enabling deep reasoning capabilities within large vision-language models (LVLMs). The ultimate goal is to create a dataset that directly supports and challenges the very latest LVLMs, pushing the boundaries of video understanding by providing a rich and nuanced dataset for advanced reasoning tasks. The automation of the process is a key factor in achieving scalability and reducing manual annotation costs, paving the way for larger, higher-quality datasets crucial for progress in the field.
Benchmarking#
A robust benchmarking strategy is crucial for evaluating the effectiveness of Large Vision Language Models (LVLMs) in video reasoning tasks. The benchmark should encompass a diverse range of tasks, capturing various aspects of video understanding, such as causal inference, event dynamics, and social understanding. Careful selection of evaluation metrics is also essential, considering both objective measures (e.g., accuracy) and subjective assessments (e.g., logical coherence, factuality). Furthermore, a comprehensive benchmark needs to control for confounding factors, such as video length and complexity, to ensure a fair comparison between different LVLMs. The use of a high-quality, large-scale dataset, such as VideoEspresso, is fundamental for creating a reliable and meaningful benchmark. By addressing these key considerations, researchers can develop more effective benchmarks, which facilitates advancement of LVLM technology in video analysis.
Future Works#
Future research directions stemming from this VideoEspresso work could focus on several key areas. Improving the scalability and efficiency of the automated annotation pipeline is crucial, potentially exploring more advanced LLMs or incorporating techniques like transfer learning. Expanding the diversity of video content included in the dataset is another important direction, aiming to encompass a wider range of styles, genres, and complexities. This would further strengthen the dataset’s robustness and generalizability. Furthermore, research could explore advanced reasoning methodologies beyond Chain-of-Thought, such as incorporating external knowledge bases or developing more sophisticated reasoning models specifically for video understanding. Investigating the impact of different LVLM architectures on the performance of video reasoning tasks is also important, along with exploring alternative approaches to core frame selection. Finally, exploring the potential of VideoEspresso in real-world applications such as video summarization and fact-checking is vital. This would bridge the gap between academic research and practical applications, demonstrating the dataset’s true value.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage automatic pipeline used to create the VideoEspresso dataset. The first stage, Question-Answer Pair Construction, involves generating frame-level captions, grouping similar captions, and then using GPT-4 to create questions based on these groups. The second stage, Multimodal Chain-of-Thought Annotation, refines this process by selecting key evidence and generating highly relevant captions with GPT-40. Crucially, this stage adds spatial and temporal annotations to key items, resulting in multimodal Chain-of-Thought (CoT) data pairs which include both spatial and temporal context.
read the caption
Figure 2: The automatic generation pipeline of VideoEspresso. (i) Question-Answer Pair Construction: We use video frame-leveled captions to extract the key frames of the video and group descriptions of these frames. Then, we prompt GPT-4 to design questions for each group of video frames. (ii) Multimodal Chain-of-Thought Annotation: We extract key evidence text and generate captions with the highest relevance to the question with GPT-4o. Additionally, we annotate spatial and temporal information for key items, which results in multimodal Chain of Thought data pairs grounded in both temporal and spatial dimensions.
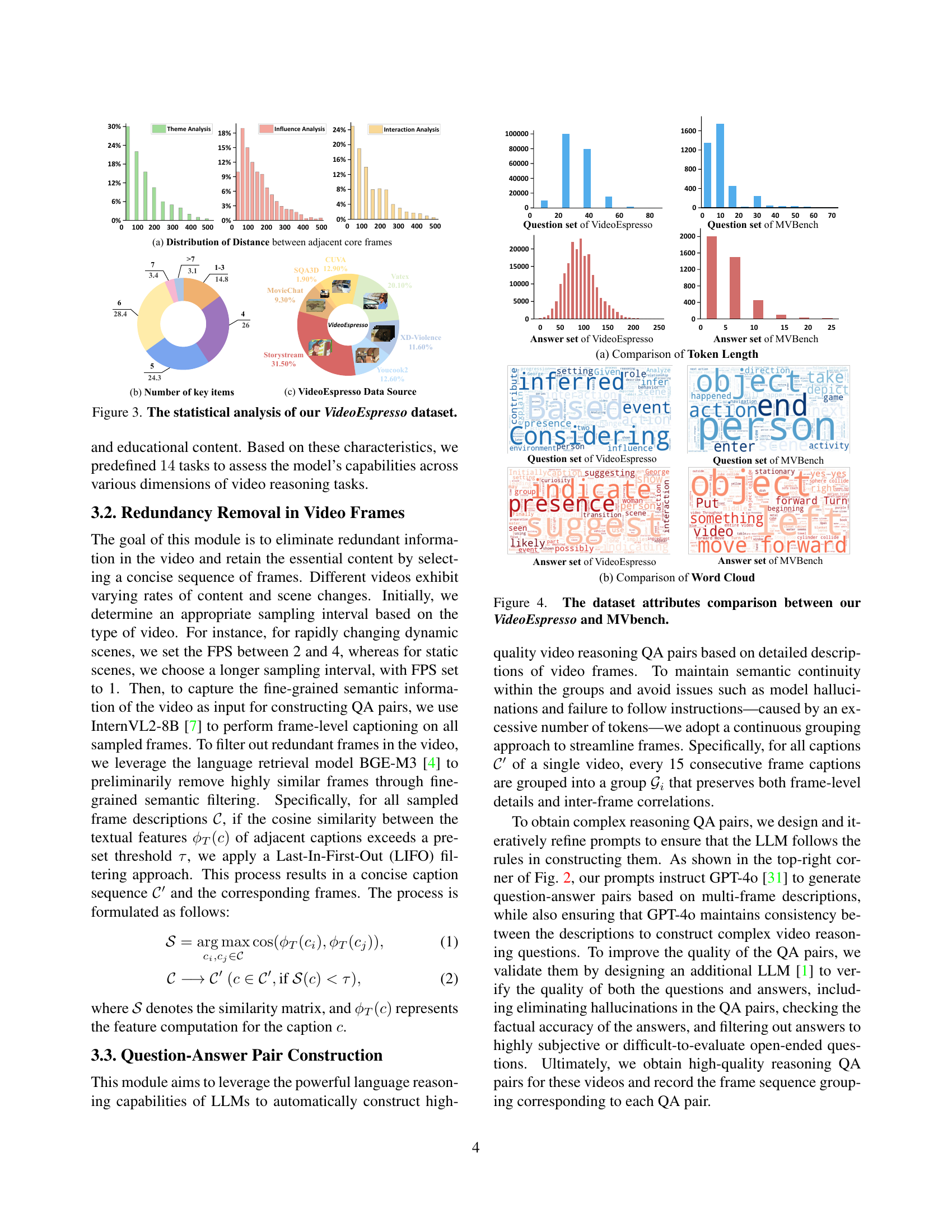
🔼 Figure 3 presents a statistical analysis of the VideoEspresso dataset, illustrating the distribution of distances between adjacent core frames (a), the number of key items (b), and the data sources (c). The distribution of distances highlights the variability in the temporal spacing between key frames across different tasks, indicating that uniform sampling is not optimal. The key item counts reveal the varying complexity of reasoning tasks, with some involving only a few key items while others involve numerous elements. The data sources breakdown shows the diverse origin of videos in VideoEspresso.
read the caption
Figure 3: The statistical analysis of our VideoEspresso dataset.

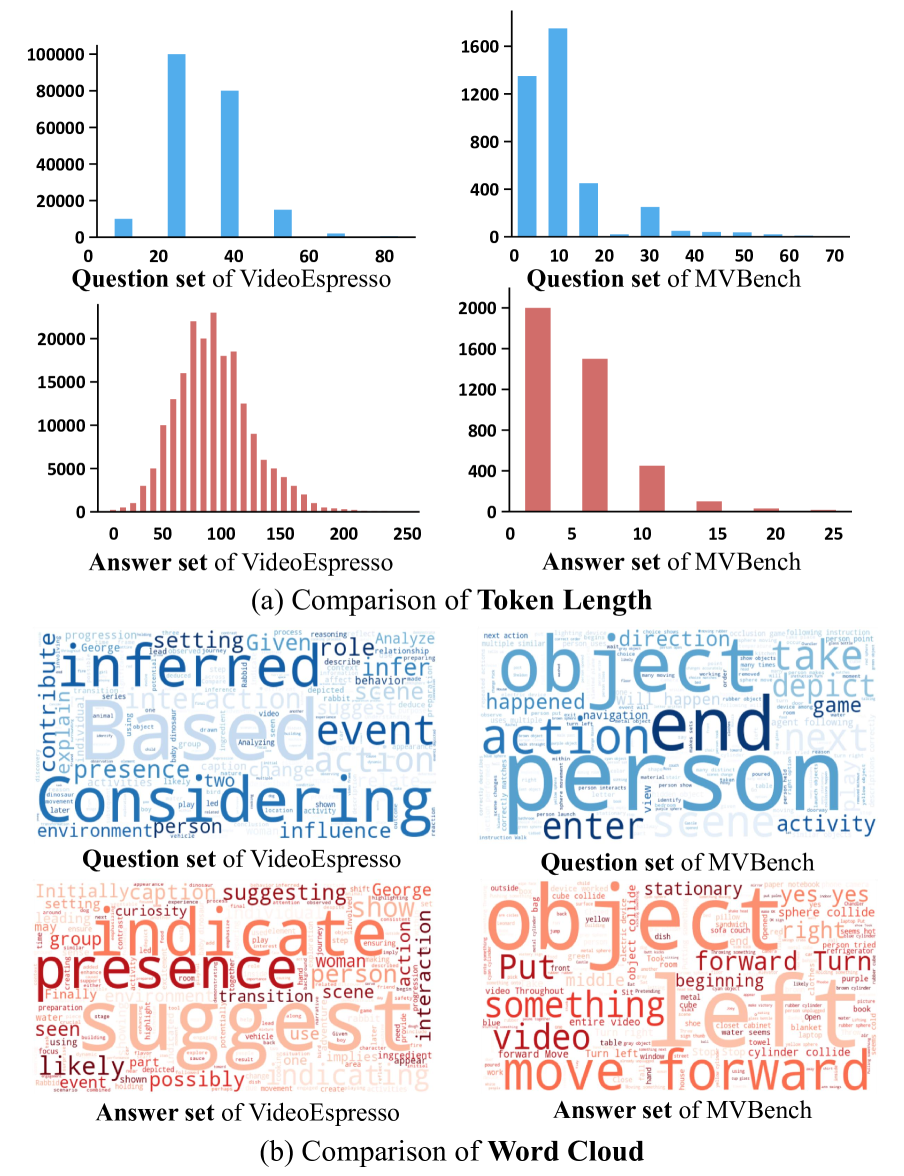
🔼 Figure 4 presents a comparative analysis of the attributes of VideoEspresso and MVBench datasets. It includes subfigures (a) and (b). Subfigure (a) compares the token length distributions of questions and answers in both datasets, illustrating the difference in length and complexity. Subfigure (b) presents word clouds for questions and answers in both datasets, visually highlighting the key terms and concepts prevalent in each. This comparison reveals the distinct characteristics of VideoEspresso, showing its focus on complex reasoning tasks as opposed to simpler fact-based queries typical of MVBench.
read the caption
Figure 4: The dataset attributes comparison between our VideoEspresso and MVbench.

🔼 This figure illustrates the two-stage training process for the Video Evidence of Thought model. The process begins with a Frame Selector, composed of a small Vision Language Model (LVLM) and a small Language Model (LLM). This selector first generates captions for the input video frames and then selects the most pertinent frame as the core video token. This core frame is then used for training a larger reasoning model. The training utilizes a two-stage supervised fine-tuning approach. In stage one, cue prompts guide the model to generate evidence relevant to a question. In stage two, this evidence is combined and used to train the model to directly produce an answer.
read the caption
Figure 5: Two-Stage Video Evidence of Thought Training Procedure. The Frame Selector comprises a tiny LVLM and a tiny LLM, tasked with generating captions for videos and selecting the most relevant frame to as core video token for large reasoning model. A two-stage supervised fine-tuning technique is employed. During stage-1, a set of cue prompts is introduced to guide the model in producing evidence, while in stage-2, the evidence generated from stage-1 is concatenated and used directly to guide the answer generation.

🔼 Figure 6 demonstrates the differences in data annotation and question-answering approaches between VideoEspresso and other VideoQA datasets. Traditional VideoQA datasets typically sample frames uniformly across the video and generate simple question-answer pairs based on overall video content. In contrast, VideoEspresso selects and groups key frames relevant to the question, constructing complex, fine-grained reasoning tasks that require understanding of the temporal and spatial relationships between those frames. The figure visually illustrates this by displaying examples of how questions and answers are formulated for each dataset and showcasing the richer context and detailed annotations (bounding boxes, key items and reasoning steps) included in VideoEspresso.
read the caption
Figure 6: Comparison between VideoEspresso and other VideoQA dataset.

🔼 This figure shows the prompt used for constructing question-answer pairs in the VideoEspresso dataset. The prompt instructs GPT-4 to generate multiple QA pairs based on a given list of video frame captions. It emphasizes that the generated questions should necessitate multi-image reasoning, involve complex logic, and avoid subjective or overly open-ended queries. The prompt also specifies constraints on question and answer formats, emphasizing consistency with the video’s narrative and observable information.
read the caption
Figure 7: QA-Construction Prompt.

🔼 This prompt is used to filter low-quality question-answer pairs generated in the previous step. It provides instructions to assess each QA pair based on several criteria: ensuring the questions and answers are consistent with the observed content in the video, confirming that the questions are not overly subjective or open-ended, and checking for continuity within the narrative flow. For any low-quality QA pairs, a brief explanation of the violated criteria is required.
read the caption
Figure 8: QA-Filter Prompt.

🔼 This figure shows the prompt used to generate the Chain-of-Thought (CoT) evidence annotations in the VideoEspresso dataset. The prompt guides GPT-4 to select the most relevant captions from a list, extract key objects from those captions, and construct a sentence explaining the answer using these key objects as evidence. The prompt emphasizes the use of both textual and visual information for reasoning.
read the caption
Figure 9: CoT-Evidence Construction Prompt.

🔼 This figure shows the prompt used for subjective evaluation of the generated answers. The prompt instructs the evaluator to score the model’s output based on several criteria, namely: logic, factuality, accuracy, and conciseness. Each criterion is defined and explained, with instructions for evaluating the answer on a scale of 1 to 10 for each. The evaluator is instructed to provide an integrated overall score, reflecting the holistic quality of the answer. The scoring guidelines are clearly laid out to ensure consistency and objectivity across different evaluations.
read the caption
Figure 10: Subjective Evaluation Prompt.

🔼 Figure 11 shows an example from the VideoEspresso test set, illustrating how the objective evaluation is conducted. It presents a question related to a video clip and then provides a reference answer (R) along with three distractor answers (D1, D2, D3). The task is to determine which of these options is the correct answer to the question given the video content. The distractor answers are designed to be plausible but incorrect, providing a challenge to the evaluation process.
read the caption
Figure 11: Example of test set. R𝑅Ritalic_R represent the Reference Answer, while Disubscript𝐷𝑖D_{i}italic_D start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT stand for the i𝑖iitalic_i-th Distractor.

🔼 This histogram illustrates the distribution of differences in the number of tokens between the reference answers and the longest distractor option in the objective evaluation of the VideoEspresso dataset. The x-axis represents the token length difference (reference answer length minus longest distractor length), while the y-axis shows the frequency of such differences. The distribution is roughly centered around zero, indicating that the length of reference answers and their corresponding longest distractor options are fairly balanced. A relatively small difference in the number of tokens suggests that the distractors were carefully designed to be comparable to the reference answers.
read the caption
Figure 12: The Distribution of token length disparities between reference answers and the longest distractor option.

🔼 This figure shows a comparison of how GPT-4 and VideoEspresso’s model analyze a video clip showing elephants and monkeys foraging. GPT-4 provides a detailed but somewhat irrelevant answer, incorporating information not directly visible in the video. VideoEspresso’s model focuses on visual details and directly observable information within the video to produce a more concise and accurate description of the animals’ foraging behaviors.
read the caption
Figure 13: Example of over-analysis with GPT-4o.
More on tables
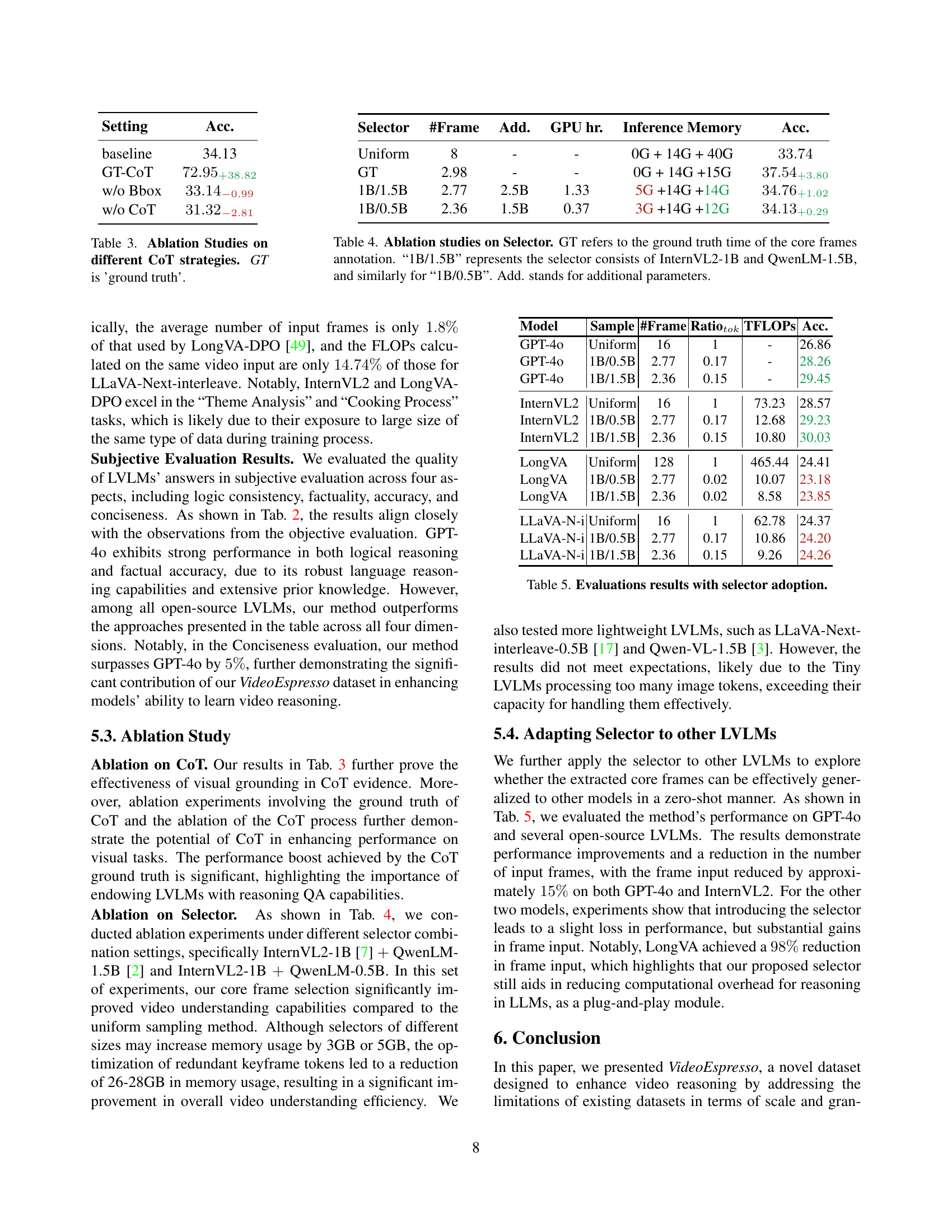
| Models | Log. | Fac. | Acc. | Con. | Overall |
|---|---|---|---|---|---|
| Closed-source LVLMs | |||||
| GPT-4o | 73.15 | 63.11 | 61.66 | 70.02 | 66.13 |
| Qwen-VL-Max | 62.46 | 50.33 | 48.43 | 60.21 | 53.37 |
| Open-source LVLMs | |||||
| LLaVA 1.5 | 60.53 | 49.56 | 49.93 | 62.1 | 52.12 |
| InternVL2 | 70.64 | 56.32 | 54.53 | 66.76 | 60.05 |
| LLaVA-N-inter | 63.27 | 52.34 | 48.45 | 66.78 | 55.16 |
| Qwen2-VL-7B | 66.31 | 53.67 | 50.84 | 68.88 | 57.66 |
| LongVA-7B-DPO | 67.98 | 54.72 | 52.78 | 58.38 | 57.19 |
| mPLUG-Owl3 | 66.14 | 53.05 | 50.97 | 67.3 | 57.14 |
| LLaVA-N-Video | 63.42 | 54.11 | 49.55 | 63.31 | 56.43 |
| Ours | 72.25 | 61.28 | 59.68 | 75.73 | 65.84 |
🔼 This table presents a subjective evaluation of various Large Vision Language Models (LVLMs) on video question answering tasks. The models’ responses are assessed across four key dimensions: logical reasoning (Log.), factuality (Fac.), description accuracy (Acc.), and conciseness (Con.). Higher scores in each category indicate better performance, providing a comprehensive understanding of the models’ strengths and weaknesses in generating high-quality, coherent answers.
read the caption
Table 2: Results on Subjective Benchmark. We report the metrics of Logic (Log.), Factuality (Fac.), Description Accuracy (Acc.), and Conciseness (Con.).
| Model | Sample | #Frame | Ratiotok | TFLOPs | Acc. |
|---|---|---|---|---|---|
| GPT-4o | Uniform | 16 | 1 | - | 26.86 |
| GPT-4o | 1B/0.5B | 2.77 | 0.17 | - | 28.26 |
| GPT-4o | 1B/1.5B | 2.36 | 0.15 | - | 29.45 |
| InternVL2 | Uniform | 16 | 1 | 73.23 | 28.57 |
| InternVL2 | 1B/0.5B | 2.77 | 0.17 | 12.68 | 29.23 |
| InternVL2 | 1B/1.5B | 2.36 | 0.15 | 10.80 | 30.03 |
| LongVA | Uniform | 128 | 1 | 465.44 | 24.41 |
| LongVA | 1B/0.5B | 2.77 | 0.02 | 10.07 | 23.18 |
| LongVA | 1B/1.5B | 2.36 | 0.02 | 8.58 | 23.85 |
| LLaVA-N-i | Uniform | 16 | 1 | 62.78 | 24.37 |
| LLaVA-N-i | 1B/0.5B | 2.77 | 0.17 | 10.86 | 24.20 |
| LLaVA-N-i | 1B/1.5B | 2.36 | 0.15 | 9.26 | 24.26 |
🔼 This table presents the results of experiments evaluating the effectiveness of incorporating a frame selector module into various Large Vision Language Models (LVLMs). The frame selector module aims to reduce computational cost by selecting only the most relevant frames for video understanding tasks. The table shows the accuracy achieved by different models (GPT-40, InternVL2, LongVA, LLaVA-N-i) using both uniform frame sampling and the proposed frame selector. Results are presented in terms of accuracy and computational cost (TFLOPS), broken down by model and frame selection strategy. The data demonstrates the trade-off between computational efficiency and accuracy when using a frame selector.
read the caption
Table 5: Evaluations results with selector adoption.
| Benchmark | Core Frames | CoT | # Questions |
|---|---|---|---|
| How2QA [21] | ✗ | ✗ | 2,852 |
| ActivityNet-QA [47] | ✗ | ✗ | 8,000 |
| NExT-QA [41] | ✗ | ✗ | 8,564 |
| MovieChat [35] | ✗ | ✗ | 13,000 |
| TVQA [15] | ✗ | ✗ | 15,253 |
| MSRVTT-QA [43] | ✗ | ✗ | 72,821 |
| VideoCoT [38] | ✗ | T | 11,182 |
| VideoEspreeso | ✓ | T&V | 203,546 |
🔼 This table compares several video question answering (VideoQA) datasets, highlighting their key characteristics. It shows whether each dataset includes core frame annotations, chain-of-thought (CoT) annotations (textual and visual), and the total number of questions. The datasets compared are How2QA, ActivityNet-QA, NEXT-QA, MovieChat, TVQA, MSRVTT-QA, VideoCoT and VideoEspresso. The presence of textual (T) and visual (V) CoT annotations is indicated for each dataset. This allows for a comparison of dataset size and the complexity of the reasoning tasks they support.
read the caption
Table 6: Dataset comparison between videoQA datasets. T and V represent the textual and visual elements in the CoT, respectively.
| Task | # Train Set | # Test Set |
|---|---|---|
| Causal Inference | 87,009 | 426 |
| Contextual Interpretation | 20,057 | 109 |
| Event Process | 29,227 | 174 |
| Interaction Dynamics | 7,322 | 62 |
| Behavior Profiling | 660 | 57 |
| Emotional Recognition | 3,505 | 65 |
| Influence Tracing | 5,749 | 72 |
| Role Identification | 9,134 | 63 |
| Narrative Structuring | 3,940 | 62 |
| Thematic Insight | 10,650 | 61 |
| Situational Awareness | 1,018 | 50 |
| Cooking Steps | 276 | 53 |
| Ingredient Details | 22,552 | 98 |
| Traffic Analysis | 1,065 | 30 |
| Total | 202,164 | 1,382 |
🔼 This table details the distribution of tasks and the dataset split within the VideoEspresso dataset. It shows how many instances (train and test) are included for each of the fourteen tasks defined in the dataset, providing a quantitative overview of the dataset’s composition and balance across different reasoning challenges.
read the caption
Table 7: Tasks distribution and dataset split in VideoEspresso.
| config | Stage1 | Stage2 |
|---|---|---|
| input resolution | 224 | 224 |
| max token length | 6144 | 6144 |
| LoRA | True | True |
| weight ratio | 0.02 | 0.02 |
| learning rate schedule | cosine decay | cosine decay |
| learning rate | 2e-5 | 1e-5 |
| batch size | 16 | 16 |
| warmup epochs | 0.03 | 0.03 |
| total epochs | 1 | 1 |
🔼 This table details the hyperparameters used during the two training stages of the VideoEspresso model. It lists the settings for various aspects of the training process, including image resolution, maximum token length, LORA (Low-Rank Adaptation) usage, weight ratio, learning rate schedule, learning rate, batch size, warmup epochs, and total epochs. The table shows how these hyperparameters differ between Stage 1 and Stage 2 of the training process. Understanding these settings is crucial for replicating the model’s training and understanding its performance.
read the caption
Table 8: Training Hyperparameters for different stages.
| Category | Description |
|---|---|
| Logical Reasoning | |
| Causal Inference | How did the actions of the robot and display on the screen contribute to the successful resolution in the control room? |
| Contextual Interpretation | How does the presence of the small cat and George’s exploration relate to the chef’s activities? |
| Event Process | What transition do the rabbits experience from the time the moon rose to when they drift off to sleep? |
| Social Understanding | |
| Interaction Dynamics | Considering the atmosphere and expressions depicted, what can be concluded about the progression of the interaction between the man and the woman? |
| Behavior Profiling | Discuss how the actions of the baby triceratops with different dinosaurs reveal aspects of its behavior and the responses of the other dinosaurs. |
| Emotional Recognition | How does the emotional journey of the small purple dinosaur from feeling lost to excitement tie into the group’s decision to explore the cave? |
| Influence Tracing | How did the presence of the dolphin and the sea monster influence the dinosaurs’ experience at the waterbody? |
| Discourse Comprehension | |
| Role Identification | How does the woman’s role in coordinating town safety relate to the device’s activation with a green checkmark and an orange flame? |
| Narrative Structuring | Considering the changes between the two frames, what can you infer about the narrative progression between the two depicted scenes? |
| Thematic Insight | How do the changing production logos contribute to the thematic preparation for the viewer before the main storyline begins? |
| Situational Awareness | Based on the sequence of events, how does the situation described contribute to the visual effect observed in the third frame? |
| Reality Application | |
| Cooking Steps | Considering the sequence of actions, what cooking technique is being employed, and how is it crucial for the fried chicken? |
| Ingredient Details | If the person is preparing chili con carne, what is the purpose of the liquid being poured into the pan? |
| Traffic Analysis | Analyze the potential destinations of the visible vehicles based on their types and cargo as inferred from the images. |
🔼 This table presents fourteen distinct video reasoning tasks included in the VideoEspresso dataset. For each task, a concise description and an example question prototype are provided to illustrate the type of reasoning involved. These tasks cover a wide range of reasoning abilities, including causal inference, contextual interpretation, social understanding, discourse comprehension, and real-world application scenarios.
read the caption
Table 9: Our proposed task categories with question prototypes.
Full paper#