↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image-conditioned diffusion models often lack versatility and efficiency, particularly when dealing with both spatially-aligned (e.g., inpainting) and non-spatially-aligned (e.g., subject-driven generation) tasks. Existing methods frequently rely on complex architectures and large numbers of parameters, limiting their applicability and scalability. Furthermore, a lack of high-quality datasets hinders research in subject-consistent generation.
The paper introduces OminiControl, a novel framework that efficiently integrates image conditions into pre-trained diffusion transformers by leveraging parameter reuse. OminiControl achieves high-quality results across both spatially and non-spatially aligned tasks with only a minimal increase in parameters (0.1%). The authors also release Subjects200K, a new dataset with over 200,000 images to support further research in subject-consistent generation. OminiControl demonstrates superior performance compared to existing methods and offers a more efficient and flexible solution for controllable image generation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a highly versatile and efficient framework for image-based control in diffusion transformers which addresses the limitations of existing methods. It offers a unified solution for both spatially aligned and non-spatially aligned tasks, enhancing controllability and efficiency in image generation. The release of the Subjects200K dataset further advances research in subject-consistent generation.
Visual Insights#

🔼 This figure showcases the capabilities of OminiControl, a novel framework for controlling image generation in diffusion transformers. The top row demonstrates subject-driven generation, where OminiControl generates images featuring a specific subject (e.g., a penguin, a person) based on a small input image of the subject. The bottom row shows examples of spatially-aligned tasks, in which OminiControl incorporates spatial information from an input image (like edges or depth maps) to guide the generation process. In all cases, the small images within red boxes represent the input conditions provided to OminiControl.
read the caption
Figure 1: Results of our OminiControl on both subject-driven generation (top) and spatially-aligned tasks (bottom). The small images in red boxes show the input conditions.
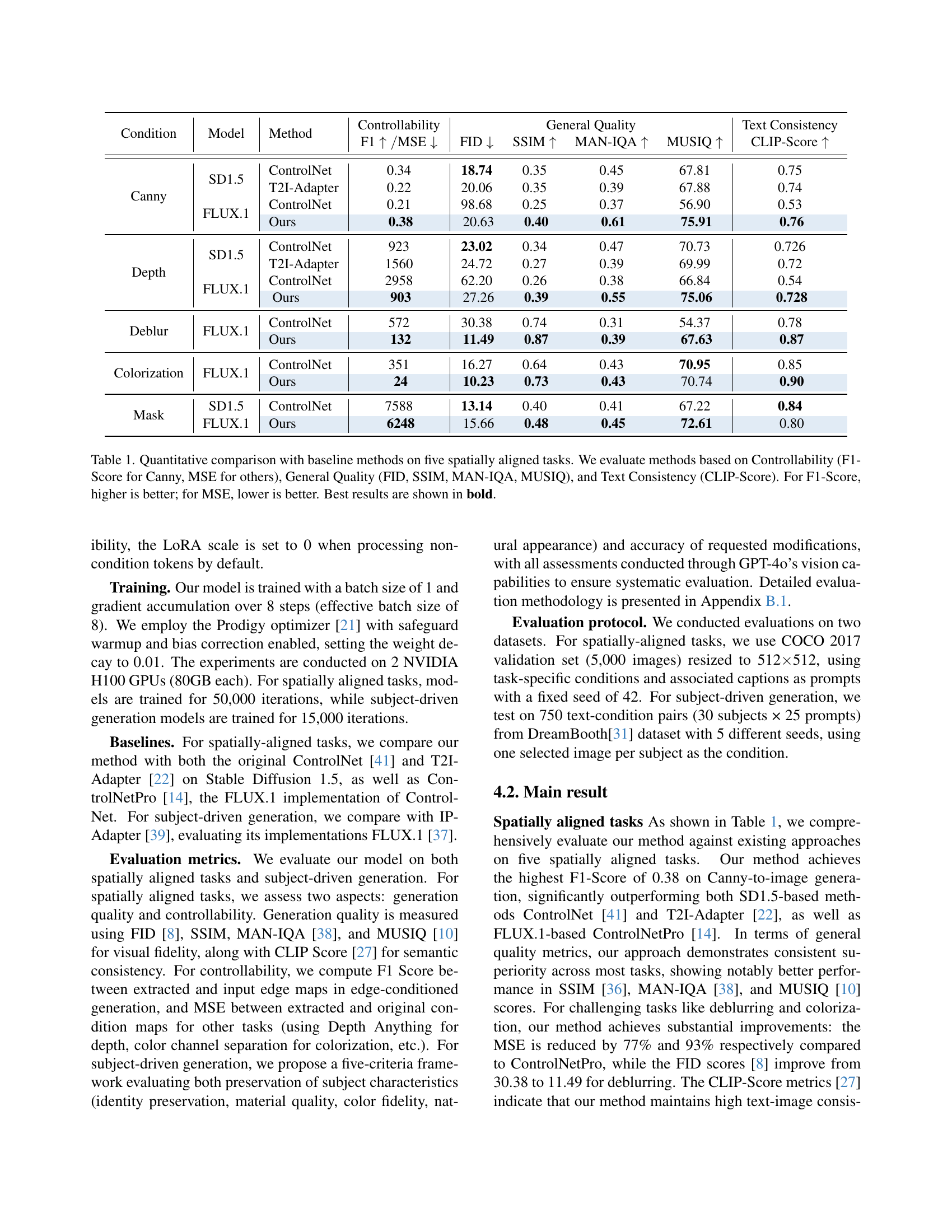
| Condition | Model | Method | Controllability | FID ↓ | SSIM ↑ | MAN-IQA ↑ | MUSIQ ↑ | Text Consistency | CLIP-Score ↑ | |
|---|---|---|---|---|---|---|---|---|---|---|
| Canny | SD1.5 | ControlNet | 0.34 | 18.74 | 0.35 | 0.45 | 67.81 | 0.75 | ||
| T2I-Adapter | 0.22 | 20.06 | 0.35 | 0.39 | 67.88 | 0.74 | ||||
| FLUX.1 | ControlNet | 0.21 | 98.68 | 0.25 | 0.37 | 56.90 | 0.53 | |||
| Ours | 0.38 | 20.63 | 0.40 | 0.61 | 75.91 | 0.76 | ||||
| Depth | SD1.5 | ControlNet | 923 | 23.02 | 0.34 | 0.47 | 70.73 | 0.726 | ||
| T2I-Adapter | 1560 | 24.72 | 0.27 | 0.39 | 69.99 | 0.72 | ||||
| FLUX.1 | ControlNet | 2958 | 62.20 | 0.26 | 0.38 | 66.84 | 0.54 | |||
| Ours | 903 | 27.26 | 0.39 | 0.55 | 75.06 | 0.728 | ||||
| Deblur | FLUX.1 | ControlNet | 572 | 30.38 | 0.74 | 0.31 | 54.37 | 0.78 | ||
| Ours | 132 | 11.49 | 0.87 | 0.39 | 67.63 | 0.87 | ||||
| Colorization | FLUX.1 | ControlNet | 351 | 16.27 | 0.64 | 0.43 | 70.95 | 0.85 | ||
| Ours | 24 | 10.23 | 0.73 | 0.43 | 70.74 | 0.90 | ||||
| Mask | SD1.5 | ControlNet | 7588 | 13.14 | 0.40 | 0.41 | 67.22 | 0.84 | ||
| FLUX.1 | Ours | 6248 | 15.66 | 0.48 | 0.45 | 72.61 | 0.80 |
🔼 Table 1 presents a quantitative comparison of different methods on five spatially aligned image generation tasks. The tasks are Canny edge detection, depth estimation, out-painting, deblurring, and colorization. The methods being compared include ControlNet, T2I-Adapter, and the authors’ proposed method, OminiControl, applied to both Stable Diffusion 1.5 (SD1.5) and FLUX.1 models. Evaluation metrics are categorized into Controllability (measured by F1-score for Canny and Mean Squared Error (MSE) for the other tasks), General Quality (assessed using Fréchet Inception Distance (FID), Structural Similarity Index (SSIM), Mobile-Intelligence-Quality (MAN-IQA), and Multi-Scale Image Quality (MUSIQ)), and Text Consistency (measured by CLIP-score). Higher F1-scores and lower MSE values indicate better performance in terms of controllability. Lower FID values, higher SSIM, MAN-IQA, MUSIQ, and CLIP scores indicate better general image quality and text consistency. The table highlights the best performing method for each metric in bold.
read the caption
Table 1: Quantitative comparison with baseline methods on five spatially aligned tasks. We evaluate methods based on Controllability (F1-Score for Canny, MSE for others), General Quality (FID, SSIM, MAN-IQA, MUSIQ), and Text Consistency (CLIP-Score). For F1-Score, higher is better; for MSE, lower is better. Best results are shown in bold.
In-depth insights#
OminiControl Intro#
The introduction to OminiControl would ideally highlight its novelty as a highly versatile and parameter-efficient framework for integrating image conditions into pre-trained Diffusion Transformer (DiT) models. It should emphasize the minimal parameter increase (only 0.1% additional parameters) compared to existing methods. A key selling point would be its universality, handling both subject-driven generation and spatially-aligned tasks within a unified architecture. This contrasts with existing methods often specialized for either type of task or for UNet-based models. The introduction should also mention the release of a new, large-scale dataset (Subjects200K), crucial for training and advancing research in subject-consistent generation. Finally, it should briefly state the superior performance of OminiControl over existing models, establishing its value proposition and motivating further reading.
DiT Control Method#
A hypothetical ‘DiT Control Method’ section in a diffusion model research paper would likely detail how image-based conditions are integrated into a Diffusion Transformer (DiT) architecture to guide image generation. The core challenge is efficiently and effectively incorporating these conditions without drastically increasing computational cost or model parameters. A successful approach would likely involve a parameter-efficient mechanism such as cross-attention or learned adapters, enabling the DiT to process both the noise and condition information concurrently. The method would probably describe how image conditions are encoded (e.g., via a pre-trained encoder or the DiT’s own encoder) and then integrated into the DiT’s attention mechanisms, perhaps through multi-modal attention that allows the model to relate image features to latent noise representations. The discussion might also address the handling of spatial vs. non-spatial conditions, with potential strategies for spatially aligned tasks (e.g., sketch-to-image) differing from those used for non-spatially aligned tasks (e.g., subject-driven generation). Finally, the section would likely present an ablation study showing the effectiveness of the proposed method compared to alternative approaches, and potentially demonstrate the impact of various design choices (e.g., different encoding methods, attention types) on the overall performance.
Subjects200K Dataset#
The Subjects200K dataset represents a significant contribution to the field of image generation, particularly for subject-consistent generation tasks. Its creation involved a novel data synthesis pipeline that overcomes limitations of existing datasets by generating high-quality, identity-consistent image pairs. The dataset’s size and diversity (over 200,000 images) are notable, providing ample data for training robust models. The use of ChatGPT-4 for image description generation and quality control further enhances the dataset’s value by ensuring consistency and diversity across various scenes and lighting conditions. Public availability of the dataset and the synthesis pipeline fosters collaboration and advances research on subject-consistent generation, paving the way for improved models and applications. The focus on diverse subjects and conditions ensures that the model trained on this dataset generalizes well to various real-world scenarios. This is a crucial step toward building more robust and versatile image generation models.
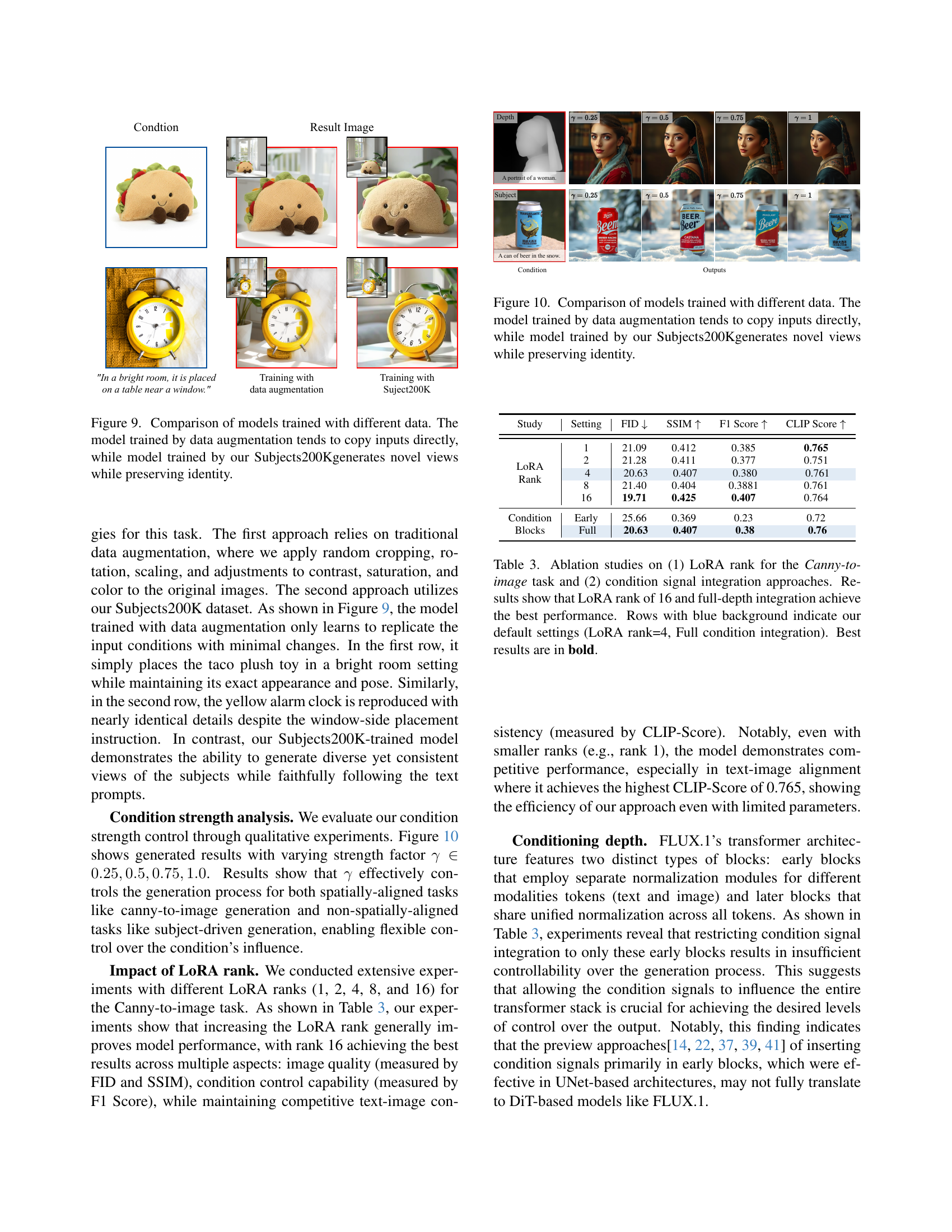
Control Strength#
The concept of ‘Control Strength’ in image generation models is crucial for achieving fine-grained control over the output. It allows users to modulate the influence of conditioning information, such as text prompts or image guidance, on the final generated image. A key aspect is the ability to seamlessly transition between different levels of control, from minimally influencing the generation process to completely overriding it with the conditioning input. This is achieved by incorporating a parameter or mechanism that allows for scaling or weighting the impact of the conditioning information. The implementation often involves a multiplicative factor or a learned bias term that dynamically adjusts the contribution of the conditioning signal to the generation process. This approach provides flexibility to the user, enabling a wide range of creative styles and image manipulations. Careful consideration of the range of the control strength parameter is essential to prevent either over- or under-powering the conditioning influence. Effective designs allow for a smooth transition between different control levels without introducing unexpected artifacts or instability in the generation process.
Future Works#
Future research directions stemming from this work could explore expanding the range of controllable aspects beyond those currently addressed. While the paper demonstrates impressive control over image content, style, and spatial attributes, integrating more nuanced controls, such as fine-grained texture manipulation or precise object pose adjustments, would significantly enhance the system’s capabilities. Another promising area is improving the efficiency of the condition integration mechanism. Although already parameter-efficient, further optimization could allow for real-time or near real-time generation, expanding the potential applications. Finally, investigating alternative model architectures beyond Diffusion Transformers, while maintaining the strengths of this approach, could potentially unlock further gains in efficiency, controllability, and overall performance. Exploring the use of other generative models, or hybrid approaches, could reveal new avenues for innovative control techniques.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of a Diffusion Transformer (DiT) model and details two methods for integrating image-based conditioning. The DiT processes both noisy image tokens and text condition tokens through multiple transformer blocks, each containing a multi-modal attention (MM-Attention) module. The figure contrasts two approaches to incorporate image conditions: (b) shows the original DiT without image conditioning; (c) demonstrates a direct addition method where the image condition tokens are simply added to the existing tokens, and (d) presents a more sophisticated MM-Attention integration method where image condition tokens participate in the attention mechanism alongside the noisy image tokens and text tokens, leading to more flexible and efficient multi-modal interactions. The methods are compared in terms of their impact on the model’s ability to respond effectively to image-based control signals during image generation.
read the caption
Figure 2: Overview of the Diffusion Transformer (DiT) architecture and integration methods for image conditioning.

🔼 This figure compares two methods for incorporating image conditions into a diffusion model: direct addition and multi-modal attention. The results show that the multi-modal approach, which uses a shared attention mechanism, better incorporates the image condition into the generated image than simply adding the image condition’s features directly to the hidden states of the diffusion model. This leads to generated images that more closely match the desired image condition.
read the caption
Figure 3: Comparison of results using two methods for integrating image conditions. The multi-modal approach demonstrates better condition following compared to direct addition.

🔼 This figure shows a comparison of training losses for different methods of integrating image conditions into a diffusion model. The x-axis represents the number of training steps, and the y-axis represents the loss value. Different colored lines represent different methods, allowing for a visual comparison of their convergence rates and overall performance during training. The lower the loss, the better the model’s performance.
read the caption
(a) Training losses for different image condition integration methods.

🔼 The figure shows the training loss curves comparing two different positional embedding strategies: one where the condition image tokens share the same position embeddings as the corresponding noisy image tokens (shared position), and another where the condition image tokens’ positions are shifted (shifting position). The x-axis represents the training steps, and the y-axis shows the training loss. The plot helps to illustrate the impact of these different positional embedding methods on the overall performance of the model during training, demonstrating that shifting the position embeddings leads to faster convergence.
read the caption
(b) Training loss for shared vs. shifting position.

🔼 This figure presents two sub-figures showing training loss curves. Sub-figure (a) compares the training losses of different image condition integration methods (Direct Addition vs. MM Attention), highlighting the superior performance of the MM Attention method which achieves lower loss. Sub-figure (b) demonstrates the effect of shared versus shifting position on the training loss, indicating that shifting the position of the image condition tokens leads to lower loss, thus suggesting that a unified sequence is more effective for processing both aligned and non-aligned image condition tasks.
read the caption
Figure 4: Training loss comparisons.

🔼 Figure 5 presents attention maps illustrating the interaction between noisy image tokens and conditional image tokens in two scenarios: Canny-to-image and subject-driven generation. In (a), the Canny-to-image task shows strong diagonal patterns in the attention map, indicating effective spatial alignment between input edges and generated image details. In (b), the subject-driven generation task showcases accurate subject-focused attention in the attention map, demonstrating the model’s ability to capture and utilize subject information during generation.
read the caption
Figure 5: (a) Attention maps for the Canny-to-image task, showing interactions between noisy image tokens X𝑋Xitalic_X and image condition tokens CIsubscript𝐶𝐼C_{I}italic_C start_POSTSUBSCRIPT italic_I end_POSTSUBSCRIPT. Strong diagonal patterns indicate effective spatial alignment. (b) Subject-driven generation task, with input condition and output image. Attention maps for X→Ci→𝑋subscript𝐶𝑖X\to C_{i}italic_X → italic_C start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and Ci→X→subscript𝐶𝑖𝑋C_{i}\to Xitalic_C start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT → italic_X illustrate accurate subject-focused attention.

🔼 The figure showcases examples from the Subjects200K dataset, a collection of over 200,000 image pairs. Each pair depicts the same object, but with variations in pose, angle, and lighting. The objects are diverse, including clothing, furniture, vehicles, and animals. The Subjects200K dataset and its generation pipeline are publicly available.
read the caption
Figure 6: Examples from our Subjects200Kdataset. Each pair of images shows the same object in varying positions, angles, and lighting conditions. The dataset includes diverse objects such as clothing, furniture, vehicles, and animals, totaling over 200,000 images. This dataset, along with the generation pipeline, will be publicly released.

🔼 This figure presents a qualitative comparison of different image generation methods, showcasing their performance on both spatially aligned and subject-driven tasks. The left side displays results for spatially aligned tasks such as Canny edge detection, depth estimation, out-painting, deblurring, and colorization. The right side shows examples of subject-driven generation, where the model generates images of specific objects (a beverage can, shoes, and a robot toy) based on given input conditions. The results highlight that the proposed ‘Our method’ consistently achieves better controllability and superior visual quality in all tested scenarios, compared to existing state-of-the-art methods.
read the caption
Figure 7: Qualitative results comparing different methods. Left: Spatially aligned tasks across Canny, depth, out-painting, deblurring, colorization. Right: Subject-driven generation with beverage can, shoes and robot toy. Our method demonstrates superior controllability and visual quality across all tasks.

🔼 Figure 8 presents a comparison of the proposed method against several baselines across five key evaluation metrics for subject-driven image generation. The radar chart visualizes the performance of each method on the following: Identity Preservation, Material Quality, Color Fidelity, Natural Appearance, and Modification Accuracy. Each axis represents one of these metrics, and the distance of each method’s data point from the center indicates its performance level on that metric. The figure allows for a quick visual comparison of the strengths and weaknesses of different approaches in terms of both subject consistency and the accuracy of modifications made during generation.
read the caption
Figure 8: Radar charts visualization comparing our method (blue) with baselines across five evaluation metrics.

🔼 Figure 9 shows a comparison of image generation results from two different training methods. The left side displays results from a model trained using standard data augmentation techniques. The images produced by this model are very similar to the input images, indicating that the model is simply copying the input. The right side displays results from a model trained using the Subjects200K dataset created by the authors. The images generated by this model show varied poses and viewpoints of the subject but still maintain the subject’s identity and key features. This demonstrates the effectiveness of the Subjects200K dataset in training a model that can generate diverse outputs while preserving the integrity of the subject.
read the caption
Figure 9: Comparison of models trained with different data. The model trained by data augmentation tends to copy inputs directly, while model trained by our Subjects200Kgenerates novel views while preserving identity.

🔼 This figure shows a comparison of image generation results from two different training approaches. The left column displays images generated by a model trained using traditional data augmentation techniques. These results show a tendency to simply copy the input image, lacking originality. In contrast, the right column presents images generated by a model trained with the Subjects200K dataset. These images demonstrate the model’s ability to generate novel views and perspectives of the subject while faithfully maintaining its identity and key characteristics. This highlights the effectiveness of the Subjects200K dataset in enabling identity-preserving subject-driven image generation.
read the caption
Figure 10: Comparison of models trained with different data. The model trained by data augmentation tends to copy inputs directly, while model trained by our Subjects200Kgenerates novel views while preserving identity.

🔼 Figure S1 shows examples from the Subjects200K dataset, highlighting the quality control process. Successful generations (green checkmarks) maintain subject identity and characteristics across different scenes. Failed generations (red crosses) show inconsistencies, such as blurry images, missing parts, or altered identities.
read the caption
Figure S1: Examples of successful and failed generation results from Subjects200K dataset. Green checks indicate successful cases where subject identity and characteristics are well preserved, while red crosses show failure cases.

🔼 This figure shows the hierarchical structure of the descriptions used to generate the Subjects200K dataset. It details the three levels of description: (1) a brief description of the object, (2) a list of scene descriptions for placing the object in various settings, and (3) a description of a studio photo of the object. This structured approach ensured consistency of subject matter across diverse image settings.
read the caption
Figure S2: An example of our structured description format for dataset generation.
More on tables
| Methods | Base model | Parameters | Ratio |
|---|---|---|---|
| ControlNet | SD1.5 / 860M | 361M | ~42% |
| T2I-Adapter | 77M | ~9.0% | |
| IP-Adapter | 449M | ~52.2% | |
| ControlNet | FLUX.1 / 12B | 3.3B | ~27.5% |
| IP-Adapter | 918M | ~7.6% | |
| Ours | FLUX.1 / 12B | 14.5M / 48.7M w/ Encoder | ~0.1% / ~0.4% w/ Encoder |
🔼 This table compares the number of additional parameters required by different image conditioning methods when integrated with the FLUX-1 diffusion model. It highlights the parameter efficiency of the proposed OminiControl method compared to ControlNet, T2I-Adapter, and IP-Adapter. The comparison includes the parameters of the CLIP image encoder for IP-Adapter and provides results for OminiControl both with and without using the original FLUX-1 VAE encoder for a fair comparison.
read the caption
Table 2: Additional parameters introduced by different image conditioning methods. For IP-Adapter, the parameter count includes the CLIP Image encoder. For our method, we also report results when using the original VAE encoder from FLUX.1.
| Study | Setting | FID ↓ | SSIM ↑ | F1 Score ↑ | CLIP Score ↑ |
|---|---|---|---|---|---|
| LoRA Rank 1 | 1 | 21.09 | 0.412 | 0.385 | 0.765 |
| LoRA Rank 2 | 2 | 21.28 | 0.411 | 0.377 | 0.751 |
| LoRA Rank 4 | 4 | 20.63 | 0.407 | 0.380 | 0.761 |
| LoRA Rank 8 | 8 | 21.40 | 0.404 | 0.3881 | 0.761 |
| LoRA Rank 16 | 16 | 19.71 | 0.425 | 0.407 | 0.764 |
| Condition Blocks | |||||
| Early | Early | 25.66 | 0.369 | 0.23 | 0.72 |
| Full | Full | 20.63 | 0.407 | 0.38 | 0.76 |
🔼 This ablation study investigates the impact of two hyperparameters on the performance of the Canny-to-image task: LoRA rank and condition signal integration approach. The table shows that using a LoRA rank of 16 and integrating the condition signal across all transformer blocks (full-depth integration) yields the best results. The rows highlighted with a blue background represent the default hyperparameter settings used in the main experiments of the paper (LoRA rank 4 and full condition integration). The best performance in each metric is shown in bold.
read the caption
Table 3: Ablation studies on (1) LoRA rank for the Canny-to-image task and (2) condition signal integration approaches. Results show that LoRA rank of 16 and full-depth integration achieve the best performance. Rows with blue background indicate our default settings (LoRA rank=4, Full condition integration). Best results are in bold.
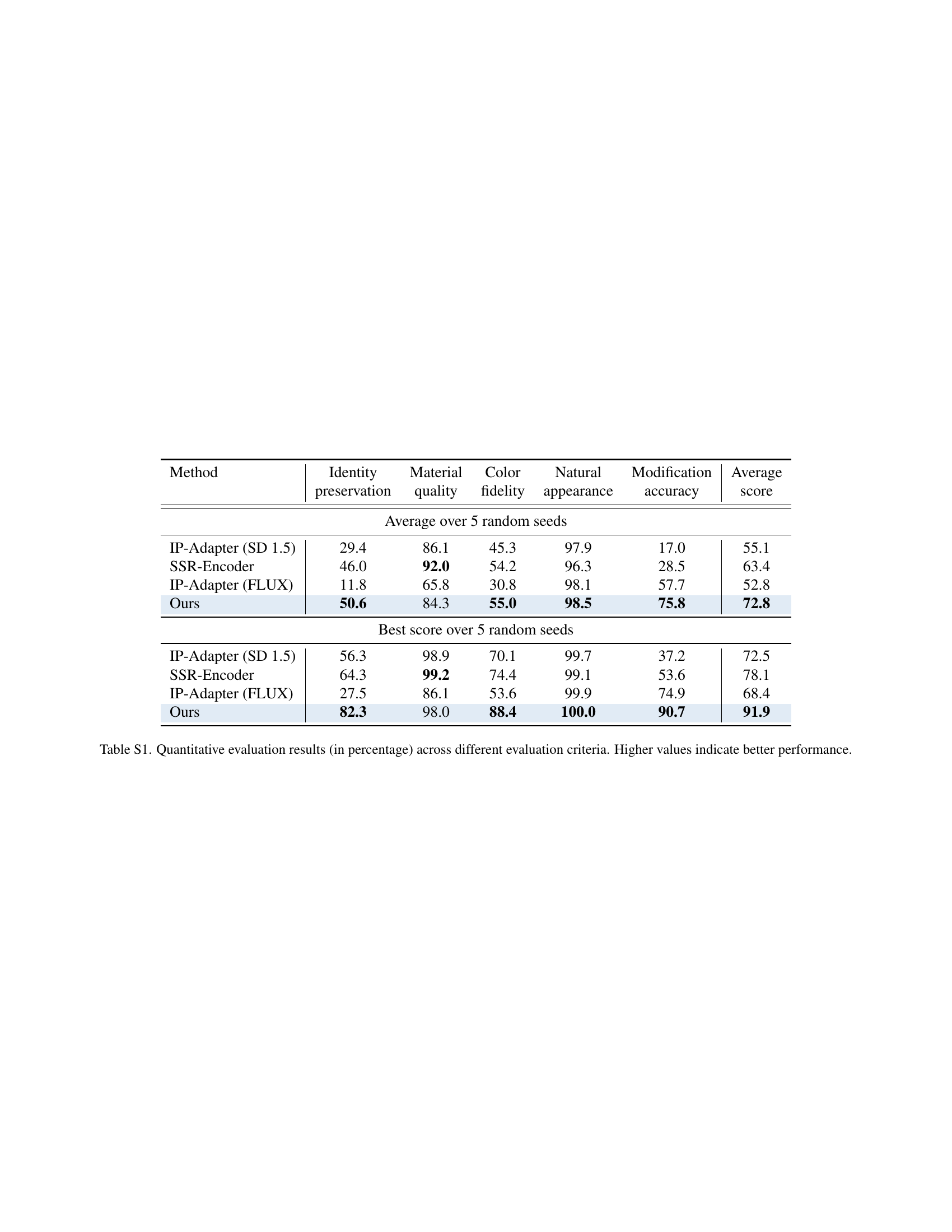
| Method | Identity | Material | Color | Natural | Modification | Average |
|---|---|---|---|---|---|---|
| preservation | quality | fidelity | appearance | accuracy | score | |
| Average over 5 random seeds | ||||||
| IP-Adapter (SD 1.5) | 29.4 | 86.1 | 45.3 | 97.9 | 17.0 | 55.1 |
| SSR-Encoder | 46.0 | 92.0 | 54.2 | 96.3 | 28.5 | 63.4 |
| IP-Adapter (FLUX) | 11.8 | 65.8 | 30.8 | 98.1 | 57.7 | 52.8 |
| Ours | 50.6 | 84.3 | 55.0 | 98.5 | 75.8 | 72.8 |
| Best score over 5 random seeds | ||||||
| IP-Adapter (SD 1.5) | 56.3 | 98.9 | 70.1 | 99.7 | 37.2 | 72.5 |
| SSR-Encoder | 64.3 | 99.2 | 74.4 | 99.1 | 53.6 | 78.1 |
| IP-Adapter (FLUX) | 27.5 | 86.1 | 53.6 | 99.9 | 74.9 | 68.4 |
| Ours | 82.3 | 98.0 | 88.4 | 100.0 | 90.7 | 91.9 |
🔼 Table S1 presents a quantitative comparison of different methods for subject-driven image generation, evaluated across five key criteria: Identity Preservation, Material Quality, Color Fidelity, Natural Appearance, and Modification Accuracy. Each criterion is assessed using a percentage score, with higher scores indicating better performance. The table compares the performance of the proposed method against several baselines, offering a comprehensive view of its strengths and weaknesses in terms of generating images that accurately reflect both the subject’s identity and any requested modifications.
read the caption
Table S1: Quantitative evaluation results (in percentage) across different evaluation criteria. Higher values indicate better performance.
Full paper#