↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current mobile manipulation methods struggle with generalizing skills across various objects and environments and executing long-horizon tasks reliably. Many approaches either rely on simplified pick-and-place actions or lack the ability to handle complex real-world scenarios. Existing imitation learning methods often suffer from compounding errors during long sequences. This limits their applicability to more involved real-world problems.
WildLMa addresses these issues by using VR teleoperation for data collection, a language-conditioned imitation learning method that enhances skill generalizability, and a skill library composed by an LLM planner for complex task execution. This approach leads to significantly improved success rates on various manipulation tasks, demonstrating the ability to handle long-horizon tasks robustly and generalize to unseen situations. This methodology represents a significant step towards creating more versatile and capable mobile robots.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenging problem of long-horizon, generalizable mobile manipulation in real-world environments. It presents a novel framework that significantly advances the state-of-the-art by combining high-quality training data, a language-conditioned imitation learning approach, and an LLM planner for complex task execution. This work opens avenues for broader applications of robots in unstructured environments and inspires future research on improving robot adaptability and autonomy.
Visual Insights#

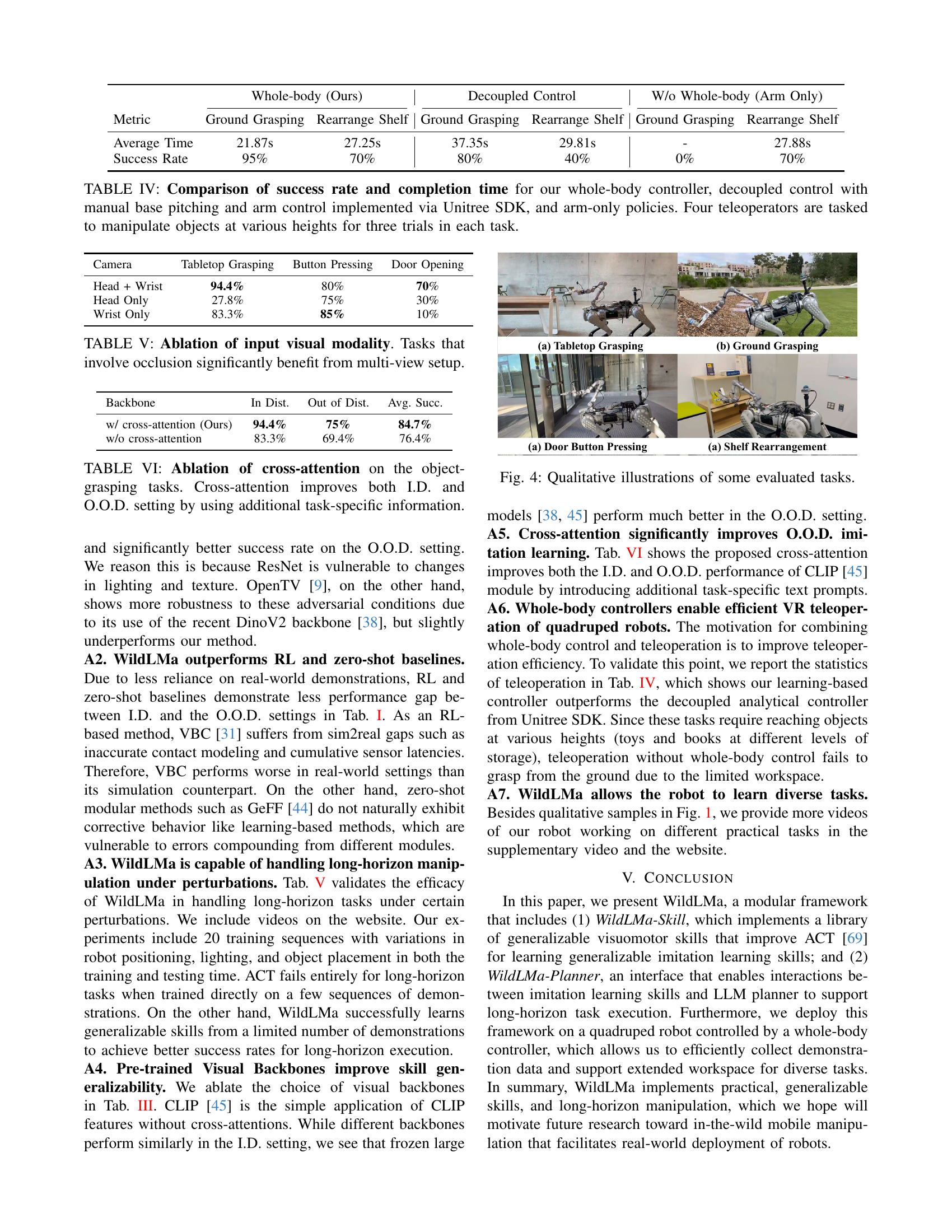
🔼 WildLMa uses a quadruped robot with a whole-body controller and imitation learning to perform in-the-wild manipulation. The figure shows three aspects: (a) The robot performing long-horizon loco-manipulation tasks in various indoor and outdoor environments. (b) The process of collecting training data for imitation learning via teleoperation. (c) The library of learned skills that can be composed by a Large Language Model (LLM) planner to perform more complex tasks.
read the caption
Figure 1: WildLMa implements a framework for in-the-wild manipulation with a quadruped robot, which combines a whole-body controller and imitation learning for effective single-skill learning. (a) Long Horizon Loco-Manipulation in indoor as well as outdoor settings. (b) Teleoperation demonstration for collecting training data for imitation learning. (c) The constructed skill library with various skills, which can be composed by LLM planner to complete complex tasks.
| Method | Tabletop Grasping | Button Pressing | Ground Grasping | Avg. Succ. | ||||
|---|---|---|---|---|---|---|---|---|
| I.D. | O.O.D | I.D. | O.O.D | I.D. | O.O.D | |||
| WildLMa (Ours) | 94.4% | 75% | 80% | 57.5% | 60% | 60% | 71.2% | |
| ACT (Mobile ALOHA) [fu2024mobilealoha] | 77.8% | 19.4% | 55% | 25% | 60% | 30% | 40.8% | |
| OpenTV [cheng2024-opentv] | 88.9% | 77.8% | 75% | 25% | 50% | 50% | 64.4% | |
| VBC [liu2024-vbc] | 50%* | 50%* | NA† | NA† | 43.8%* | 43.8%* | 46.9% | |
| GeFF [qiu2024-geff] | 55.6%* | 55.6%* | NA† | NA† | NA† | NA† | 55.6% |
🔼 Table I presents a comparison of the success rates achieved by different methods in performing three autonomous robotic manipulation skills: tabletop grasping, button pressing, and ground grasping. The methods are evaluated under both in-distribution (I.D.) and out-of-distribution (O.O.D.) conditions. In-distribution means the test conditions are similar to the training data, while out-of-distribution means the testing conditions are more challenging and different from the training data. The table highlights that imitation learning methods generally outperform reinforcement learning (RL) and zero-shot approaches. WildLMa and OpenTV show significantly better performance in the O.O.D. setting. Specific notes clarify that some methods use pre-defined policies not readily applicable to all task scenarios, and that some methods do not distinguish between I.D. and O.O.D. data for success rate reporting, therefore providing an average.
read the caption
TABLE I: Success rate of autonomous skill execution. Imitation learning methods outperform RL [liu2024-vbc] and zero-shot method [qiu2024-geff] on comparable tasks. Both OpenTV and WildLMa achieve noticeably higher success rates in the challenging O.O.D. setting. †: methods involve learned/manual policies that are not trivially applicable to the task settings. ∗: Method does not differentiate object sets and success rates are averaged on I.D. and O.O.D. object sets.
In-depth insights#
WildLocoManipulation#
WildLocoManipulation, a hypothetical research area combining legged locomotion with manipulation in unstructured environments, presents exciting possibilities and significant challenges. Legged robots offer superior mobility and adaptability compared to wheeled robots in complex terrain, enabling access to a wider range of manipulation tasks. However, integrating robust manipulation capabilities with the inherent complexities of legged locomotion is a considerable hurdle. Key challenges include developing control systems capable of coordinating locomotion and manipulation seamlessly, handling dynamic interactions between the robot and its environment, and ensuring reliable perception and planning in highly variable conditions. Successfully tackling these challenges requires advances in areas such as whole-body control, robust perception using sensors like LiDAR and cameras, and sophisticated planning algorithms capable of generating adaptable and robust plans. Addressing these issues will be critical for enabling the deployment of legged robots for a broad spectrum of real-world applications, from search and rescue to agriculture, and will necessitate interdisciplinary research drawing upon robotics, computer vision, artificial intelligence, and control theory.
CLIP-Skill Fusion#
A hypothetical ‘CLIP-Skill Fusion’ section in a robotics research paper would likely explore methods for integrating CLIP’s powerful image-text understanding capabilities with learned robotic skills. The core idea would be to leverage CLIP’s ability to ground language instructions in visual observations, enabling robots to understand complex commands and translate them into appropriate actions. This fusion could enhance the robustness and generalizability of robotic skills, allowing them to adapt to novel situations and objects not explicitly seen during training. A key challenge to address would be efficient and effective skill representation and selection. Different approaches could be explored, such as using CLIP embeddings as input to skill selection networks, thereby guiding the robot to choose the most suitable skill based on both visual input and the textual command. Addressing the semantic gap between language and low-level control would also be crucial. The effectiveness of this fusion would likely be demonstrated through experiments showcasing robots successfully completing complex tasks in varied and unpredictable environments, significantly surpassing the capabilities of systems reliant solely on visual or language-based inputs.
VR Teleop Adaption#
Adapting VR teleoperation for quadrupedal robots presents unique challenges due to the significant morphological differences between human operators and quadrupedal locomotion. WildLMa addresses this by employing a learned whole-body controller. This approach allows for smooth coordination between the robot’s base and arm movements, simplifying teleoperation and extending the robot’s effective workspace. The use of a VR interface with real-time video streaming and 6DOF pose tracking further enhances the teleoperator’s situational awareness, thus minimizing the gap between the operator’s intentions and the robot’s actions. This system reduces the cognitive load on the operator, allowing for more efficient data collection for imitation learning. The incorporation of a simple mapping from human hand gestures to robot actions makes the system intuitive and straightforward to use. In essence, WildLMa’s VR teleoperation adaptation successfully bridges the embodiment gap, facilitating the acquisition of complex manipulation skills with improved efficiency and enhanced data quality.
LLM-Skill Planning#
LLM-Skill planning represents a paradigm shift in robotic manipulation, moving beyond pre-programmed actions towards more flexible, adaptable systems. By integrating large language models (LLMs) with a library of learned skills, robots can potentially tackle complex tasks previously beyond their capabilities. The success of this approach hinges on several key factors: the quality and generalizability of the learned skills, the LLM’s ability to effectively decompose complex tasks into manageable sub-tasks, and the seamless integration of these components. Challenges remain, such as the potential for error propagation through sequential skill execution and the robustness of the system in the face of unpredictable real-world conditions. However, the potential for highly adaptable, versatile robots is compelling and worthy of further research and development.
Generalization Limits#
The concept of ‘Generalization Limits’ in the context of robotic mobile manipulation is crucial. It probes the boundaries of a robot’s ability to apply learned skills to novel situations. Success hinges on the robot’s capacity to handle variations in object appearances, environmental conditions (lighting, textures), and task contexts. A system’s generalization capabilities are often hampered by reliance on highly specific training data, failing to account for the inherent complexity and variability of real-world scenarios. Addressing generalization limits requires careful consideration of training data diversity, robust feature extraction techniques (like CLIP), and methods to handle uncertainties and partial observability. Furthermore, effective planning algorithms are needed to adapt learned skills to novel task combinations and sequences. The ability to successfully navigate these limitations is pivotal for the practical deployment of autonomous robots in unconstrained environments. Therefore, future research should focus on developing techniques that explicitly consider and overcome generalization barriers, paving the way for truly robust and adaptable mobile manipulation systems.
More visual insights#
More on figures

🔼 This figure shows the architecture of the WildLMa system and the robot setup used in the experiments. Panel (a) details the WildLMa-Skill module, illustrating how task-specific text and visual observations are processed using a frozen CLIP model to generate cross-attention maps for improved skill generalizability. Panel (b) displays the physical robot platform, which consists of a Unitree B1 quadruped robot equipped with a Unitree Z1 arm and a 3D-printed gripper. The robot is further outfitted with two RGB-D cameras and a LiDAR sensor for comprehensive environmental perception.
read the caption
Figure 2: Overview of WildLMa models and robot setups. (a) WildLMa takes a frozen CLIP model to encode task-specific texts and visual observations; (b) Our robot platform is a Unitree B1 quadruped combined with a Unitree Z1 arm and a 3D-printed gripper, with two RGBD cameras and one lidar mounted on.

🔼 WildLMa-Planner uses a hierarchical scene graph to plan long-horizon tasks. The coarse planner receives high-level instructions (e.g., ‘clean the trash’) and breaks them down into subtasks (e.g., ’navigate to hallway’, ‘pick up trash’, ‘place trash in bin’). The fine-grained planner then uses a breadth-first search to find the optimal sequence of skills from the WildLMa-Skill library to achieve each subtask, considering node locations and object information. This two-level planning approach allows for more efficient and robust task execution.
read the caption
Figure 3: Overview of WildLMa-planner. Given a constructed hierarchical scene graph, WildLMa-planner adopts a coarse-to-fine searching mechanism to determine node traversal and structured actions to take.
More on tables
| Pipeline | Collect & Drop Trash | Shelf Rearrangement |
|---|---|---|
| WildLMa (Ours) | 7/10 | 3/10 |
| ACT [fu2024mobilealoha, zhao2023aloha] | 0/10 | 0/10 |
🔼 Table II presents the results of evaluating WildLMa’s performance on long-horizon tasks, which involve a sequence of actions to achieve a complex goal. The experiment was conducted with only 10 training demonstrations, highlighting WildLMa’s efficiency in learning from limited data. The table compares WildLMa’s success rate with that of ACT [17, 69] on two tasks: collecting and dropping trash and rearranging items on a shelf. WildLMa demonstrates a significantly higher success rate than ACT, showcasing its improved generalizability (ability to handle variations in object configurations and environments) in single skills and its divide-and-conquer approach (breaking down complex tasks into smaller, manageable sub-tasks) for improved long-horizon task execution.
read the caption
TABLE II: Evaluation of long-horizon execution. Given a few training demonstrations (10), WildLMa improves long-horizon task success rate via (1) improved generalizability of single skill and (2) divide-and-conquer.
| Backbone | In Dist. | Out of Dist. | Avg. Succ. |
|---|---|---|---|
| CLIP [radford2021-CLIP] | 83.3% | 69.4% | 76.4% |
| ResNet [zhao2023aloha]⋆ | 77.8% | 19.4% | 48.6% |
| DinoV2 [oquab2023-dinov2] | 88.9% | 77.8% | 83.3% |
🔼 This table presents an ablation study comparing the performance of different visual encoders, pre-trained with varying objectives, on object grasping tasks. The encoders’ impact on task success rate is evaluated across in-distribution (ID) and out-of-distribution (OOD) object sets. One encoder uses a ResNet-18 model pre-trained on ImageNet, chosen for its smaller parameter count following methods from cited works. The results illustrate the effect of different encoder architectures and pre-training strategies on the robustness and generalization capability of the object grasping model.
read the caption
TABLE III: Ablation of different visual encoders pre-trained with different objectives. The evaluation is done on the object-grasping tasks. ⋆: we followed ACT [fu2024mobilealoha, zhao2023aloha] to use ImageNet-pretrained ResNet-18 as the encoder, which has fewer parameters.
| Metric | Whole-body (Ours) Ground Grasping | Whole-body (Ours) Rearrange Shelf | Decoupled Control Ground Grasping | Decoupled Control Rearrange Shelf | W/o Whole-body (Arm Only) Ground Grasping | W/o Whole-body (Arm Only) Rearrange Shelf |
|---|---|---|---|---|---|---|
| Average Time | 21.87s | 27.25s | 37.35s | 29.81s | - | 27.88s |
| Success Rate | 95% | 70% | 80% | 40% | 0% | 70% |
🔼 Table IV presents a comparison of the success rates and completion times achieved by three different control methods in a mobile manipulation task. The methods compared are: a whole-body controller (the authors’ method), decoupled control (manual base pitching and arm control using the Unitree SDK), and arm-only control. The evaluation involved four teleoperators performing the same manipulation tasks on objects at various heights, with each teleoperator completing three trials per task. The table highlights the performance differences between these three control methods.
read the caption
TABLE IV: Comparison of success rate and completion time for our whole-body controller, decoupled control with manual base pitching and arm control implemented via Unitree SDK, and arm-only policies. Four teleoperators are tasked to manipulate objects at various heights for three trials in each task.
| Camera | Tabletop Grasping | Button Pressing | Door Opening |
|---|---|---|---|
| Head + Wrist | 94.4% | 80% | 70% |
| Head Only | 27.8% | 75% | 30% |
| Wrist Only | 83.3% | 85% | 10% |
🔼 This table presents the results of an ablation study on the input visual modality used for WildLMa, focusing on tasks where occlusion is a factor. It compares the success rates of different tasks (Tabletop Grasping, Button Pressing, Door Opening) using various combinations of camera views: head camera only, wrist camera only, and both head and wrist cameras. The results demonstrate the significant advantage of using both cameras, especially in scenarios with significant occlusions, highlighting the importance of multi-view setup for robust performance.
read the caption
TABLE V: Ablation of input visual modality. Tasks that involve occlusion significantly benefit from multi-view setup.
| Backbone | In Dist. | Out of Dist. | Avg. Succ. |
|---|---|---|---|
| w/ cross-attention (Ours) | 94.4% | 75% | 84.7% |
| w/o cross-attention | 83.3% | 69.4% | 76.4% |
🔼 Table VI presents an ablation study evaluating the impact of cross-attention on the performance of object-grasping tasks. The study compares the success rates of the model with and without cross-attention, under both in-distribution (I.D.) and out-of-distribution (O.O.D.) settings. The results demonstrate that incorporating cross-attention, which leverages additional task-specific textual information, significantly enhances the model’s ability to perform object-grasping tasks, particularly in challenging, out-of-distribution scenarios.
read the caption
TABLE VI: Ablation of cross-attention on the object-grasping tasks. Cross-attention improves both I.D. and O.O.D. setting by using additional task-specific information.
Full paper#