↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Generating realistic materials for 3D objects is crucial for various applications but remains challenging due to complex interactions between geometry, materials, and illumination, especially under various lighting conditions. Existing methods often rely on complex pipelines, are computationally expensive, or lack generalizability. They struggle with objects under diverse lighting conditions and have limited scalability.
Material Anything introduces a unified diffusion framework to overcome these limitations. It uses a pre-trained image diffusion model enhanced with a triple-head architecture and confidence masks, improving the stability and material quality. The method incorporates a progressive generation strategy and UV-space refinement for consistent and high-quality material maps. Extensive experiments demonstrate that Material Anything outperforms existing methods across a range of object categories and lighting conditions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer graphics and computer vision because it presents a novel and efficient method for generating high-quality physically-based rendering (PBR) materials for 3D objects. This addresses a significant bottleneck in various applications like video games, virtual reality, and film production where realistic material rendering is essential. The method’s ability to handle diverse lighting conditions and texture-less objects opens new avenues for research in material synthesis and 3D modeling, potentially improving the efficiency and realism of numerous applications. The proposed Material3D dataset also significantly contributes to the research community by offering a large-scale, high-quality resource for training and evaluating material generation models.
Visual Insights#

🔼 Figure 1 showcases Material Anything, a novel feed-forward model designed to generate physically-based rendering (PBR) materials for 3D objects. The figure highlights the model’s versatility by demonstrating its application to a diverse range of 3D meshes under various conditions, including those with no texture, only albedo data, computer-generated textures, and those obtained from 3D scans. Each row represents a different object with its corresponding albedo and roughness values shown, followed by the generated object with its applied PBR material.
read the caption
Figure 1: Material Anything: A feed-forward PBR material generation model applicable to a diverse range of 3D meshes across varying texture and lighting conditions, including texture-less, albedo-only, generated, and scanned objects.
| Method | Type | Input Mesh | FID ↓ | CLIP Score ↑ |
|---|---|---|---|---|
| Text2Tex [6] | Learning | Texture-less | 116.41 | 30.33 |
| SyncMVD [24] | Learning | Texture-less | 118.46 | 30.66 |
| Paint3D [47] | Learning | Texture-less | 153.20 | 28.40 |
| NvDiffRec [26] | Optimization | Texture-less | 103.81 | 30.14 |
| DreamMat [52] | Optimization | Texture-less | 113.34 | 30.64 |
| Ours | Learning | Texture-less | 100.63 | 31.06 |
| Make-it-Real [12] | Retrieval | Textured | 104.38 | 88.62 |
| Ours | Learning | Textured | 101.19 | 89.70 |
🔼 This table presents a quantitative comparison of different methods for generating 3D object textures, focusing on two key metrics: Fréchet Inception Distance (FID) and CLIP score. FID measures the visual similarity between generated images and real images, with lower scores indicating higher similarity. The CLIP score assesses the semantic alignment between generated images and textual descriptions, with higher scores representing better agreement. The results are based on 1200 images from 20 textured objects. A special note is made for the comparison with the Make-it-Real method, where the CLIP score is calculated using rendered images from generated textures compared against the Objaverse dataset rather than directly comparing rendered images.
read the caption
Table 1: Quantitative comparisons. FID and CLIP scores (similarity between rendered views and text prompts) are computed on 1,200 images from 20 textured objects. For comparison with Make-it-Real, the CLIP score is calculated between rendered images from generated textures and those in Objaverse.
In-depth insights#
Material Diffusion#
Material diffusion, in the context of 3D object material generation, represents a significant advancement. It leverages the power of image diffusion models, trained on extensive datasets of physically based rendering (PBR) materials, to generate realistic material maps for 3D objects. Unlike traditional methods which often rely on complex pipelines or case-specific optimization, material diffusion offers a more unified and automated approach. The key lies in adapting image diffusion models to the unique challenges of material representation. This involves strategies like using a triple-head architecture to generate multiple material properties simultaneously, employing confidence masks to handle variations in lighting conditions, and incorporating rendering losses to ensure fidelity and realism. The resulting system demonstrates significant improvements in stability, material quality, and generalization across diverse object categories and lighting scenarios. The progressive material generation strategy further enhances multi-view consistency, mitigating inconsistencies in materials across different views of the same 3D object. This addresses limitations of previous methods where generated materials often exhibited unrealistic lighting effects or lacked consistency. Overall, material diffusion is a powerful technique with potential to improve the efficiency and realism of 3D content creation.
3D Material Gen#
The hypothetical section ‘3D Material Gen’ in a research paper would likely explore the generation of realistic and physically-based materials for 3D objects. This is a significant area of research because creating high-quality materials is crucial for enhancing the realism and visual appeal of 3D models, with applications in video games, virtual reality, and film production. The methods explored would likely involve machine learning techniques, potentially leveraging diffusion models or generative adversarial networks (GANs) to synthesize material textures and properties. A key challenge would be handling the diversity of materials, lighting conditions, and object geometries to ensure robust generalization. Dataset creation would be critical, requiring a substantial amount of high-quality 3D models with accurate material properties and corresponding ground truth data. The section would likely compare various approaches, evaluating their performance in terms of visual quality, computational efficiency, and robustness across diverse input scenarios. Moreover, it might discuss the limitations of current methods and future directions such as improving the handling of complex material interactions or enabling interactive material design within a 3D modeling pipeline. Ultimately, a successful ‘3D Material Gen’ section should offer a comprehensive overview of the state-of-the-art, identify key challenges and opportunities, and propose novel methods towards efficient and realistic material generation for 3D objects.
Progressive Gen#
Progressive generation, in the context of 3D material synthesis, is a crucial technique for creating consistent and high-quality material maps across multiple views of a 3D object. The core idea revolves around incrementally building the material representation, view by view. This approach is particularly effective when dealing with diverse lighting conditions or texture-less objects, as it leverages previously generated information to guide subsequent estimations. Confidence masks play a pivotal role, acting as dynamic switches to inform the generation process. Where lighting cues are reliable (e.g., scanned objects), confidence is high, leading to accurate material estimation. Conversely, in low-confidence scenarios (texture-less objects or unrealistically lit scenes), the generation relies more on semantic cues. This progressive refinement, informed by the confidence mask, significantly enhances the model’s robustness and consistency across views, effectively mitigating artifacts resulting from inconsistent lighting or insufficient information. The UV-space material refinement further streamlines the process, ensuring seamless materials and efficient usage in downstream applications.**
Confidence Masks#
The concept of ‘Confidence Masks’ in the context of Material Anything, a material generation model for 3D objects, is a crucial innovation. It addresses the challenge of handling diverse lighting conditions, dynamically adjusting the model’s reliance on illumination cues versus object semantics. For objects with realistic lighting, high confidence masks guide the model to leverage illumination cues for accurate material estimation. Conversely, for lighting-free or unrealistically lit textures, low confidence masks prioritize object semantics and prompts, preventing reliance on unreliable lighting data which may introduce unrealistic highlights or shadows. This adaptive mechanism makes the model robust and versatile across a broad spectrum of object types and lighting conditions, ensuring consistent and high-quality material outputs. Progressive material generation further leverages these masks by intelligently using known material estimates from previous views to guide the generation of new views, ensuring multi-view consistency. The incorporation of confidence masks represents a significant advance over existing material generation techniques by offering a unified and adaptable solution to the complex challenges of variable lighting and lighting-free object representations. It’s a key factor for Material Anything’s robustness and scalability.
Material Refinement#
Material refinement, in the context of the research paper, likely refers to a post-processing step designed to enhance the quality and consistency of the generated material maps. This stage likely follows the initial generation of materials using an image-space diffusion model and serves as a crucial component in achieving high-quality, UV-ready outputs. The process probably involves techniques to address imperfections arising from the initial generation, such as seams between views, texture holes caused by self-occlusion, and inconsistent material appearance across the 3D object’s surface. A refinement diffusion model operating in UV space is highly probable, specifically designed to address these issues and ensure seamless transitions across UV islands. This approach highlights the importance of considering not just the pixel-level detail in the initial generation but also the global consistency of the material across the entire 3D model. The use of a confidence mask, which indicates areas of high or low certainty during initial generation, likely guides this refinement process, focusing attention on areas needing correction and allowing for more accurate reconstruction of detailed textures. The use of a canonical coordinate map (CCM) is another key element in achieving robust refinement by incorporating 3D adjacency information for efficient and accurate reconstruction of occluded regions or missing textures. Therefore, material refinement is critical for producing final, high-quality, and readily usable material maps for 3D objects across various lighting scenarios.
More visual insights#
More on figures
🔼 Material Anything processes 3D objects to generate physically based render (PBR) material maps. For objects lacking textures, it begins by generating coarse textures using an image diffusion model. For textured objects, it uses the existing textures. Then, a material estimator processes each view of the object, using a rendered image, normal map, and confidence mask to progressively estimate material properties. The confidence mask helps to account for varying lighting conditions and improve consistency across views. The estimated materials are unwrapped into UV space and further refined using a UV-space material refiner. The resulting, consistent UV material maps are combined with the mesh to create a fully textured 3D model ready for downstream use.
read the caption
Figure 2: Overview of Material Anything. For texture-less objects, we first generate coarse textures using image diffusion models, similar to the texture generation method [6]. For objects with pre-existing textures, we directly process them. Next, a material estimator progressively estimates materials for each view from a rendered image, normal, and confidence mask. The confidence mask serves as additional guidance for illuminance uncertainty, addressing lighting variations in the input image and enhancing consistency across generated multi-view materials. These materials are then unwrapped into UV space and refined by a material refiner. The final material maps are integrated with the mesh, enabling the object for downstream applications.

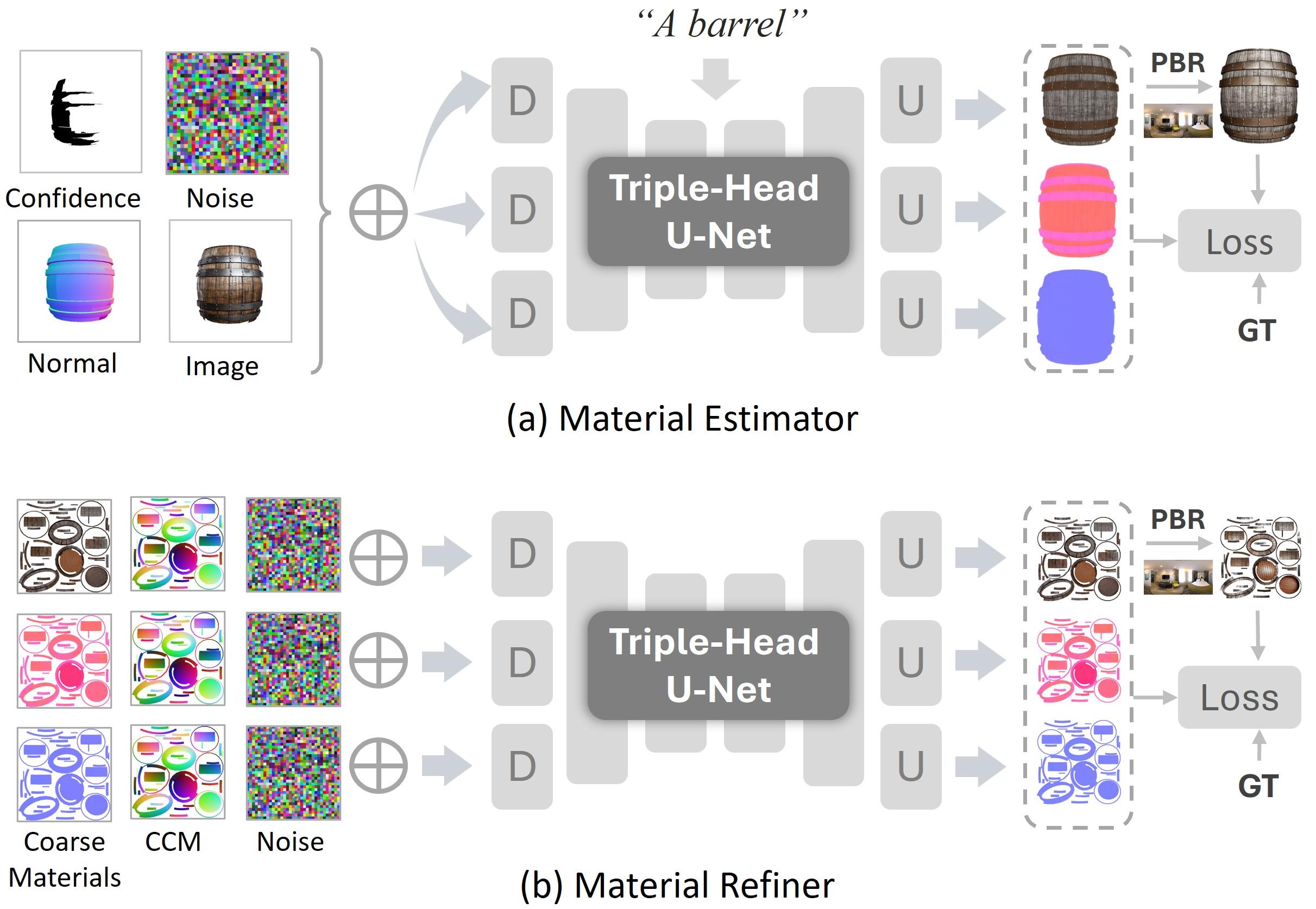
🔼 This figure illustrates the architecture of both the material estimator and refiner networks. Each utilizes a triple-head U-Net. This means the network has three separate branches that independently generate the albedo, roughness/metallic, and bump maps. These maps are then combined to produce a complete, physically-based rendering (PBR) material representation for a 3D object. The use of three separate heads helps avoid interference between the generation of the different material properties, ensuring greater accuracy and consistency.
read the caption
Figure 3: Architectural design of material estimator and refiner. Both employ a triple-head U-Net, generating albedo, roughness-metallic, and bump maps via separate branches.

🔼 This figure illustrates the progressive material generation process for a texture-less 3D object. The process starts by using a pre-trained stable diffusion model ([30]) with depth ControlNet ([49]) to generate the material for the first view. For subsequent views, the model leverages information from previously generated views. Specifically, ‘known regions’ (areas where materials have already been estimated) are projected onto the latent space representation of the new view. This ensures consistency across views and avoids unnecessary recalculation. The progressive generation continues until materials for all views are estimated. This approach effectively handles texture-less objects by building up a coherent material representation view-by-view.
read the caption
Figure 4: Progressive material generation process for a texture-less object. “Project” denotes projecting known regions for the latent initialization of the next view. “SD” denotes the pre-trained stable diffusion model [30] with depth ControlNet [49]

🔼 Figure 5 presents a comparison of Material Anything against three other texture generation methods (Text2Tex, SyncMVD, and Paint3D). All methods start with texture-less 3D models of chairs and a faucet. The comparison highlights that while the other methods can generate textures using image diffusion models, they fail to accurately produce the corresponding physically-based rendering (PBR) material properties such as albedo, roughness, metallic, and bump maps. Material Anything, in contrast, successfully generates both realistic textures and accurate PBR material properties, resulting in more visually compelling and physically accurate 3D models.
read the caption
Figure 5: Comparisons with texture generation methods. These methods directly paint texture-less objects using image diffusion models but fail to generate the corresponding material properties.

🔼 Figure 6 compares Material Anything’s material generation capabilities with optimization-based methods, specifically NvDiffRec [26] and DreamMat [52]. NvDiffRec uses textured models generated by SyncMVD [24] as input. The figure displays the generated material maps (albedo, roughness, metallic, and bump) for three different 3D objects, demonstrating Material Anything’s superior performance in generating realistic and diverse material maps. Material Anything’s results show significantly more detail and realism compared to the other methods. The comparison highlights Material Anything’s efficiency and accuracy in material generation.
read the caption
Figure 6: Comparisons with optimization methods. NvDiffRec [26] estimates materials using the textured model by SyncMVD [24] as input. The materials include albedo (top left); roughness (top right); metallic (bottom left); bump (bottom right).

🔼 Figure 7 presents a comparison of Material Anything with retrieval-based methods. The input consists of textured 3D objects, specifically an albedo-only object and a scanned object. The generated material maps are displayed for each object, broken down into four key PBR (Physically Based Rendering) components: albedo (reflectance), roughness (surface texture), metallic (metallicity), and bump (height variation). Each component is shown in a separate image, arranged in a 2x2 grid for easy comparison between the different methods and the ground truth.
read the caption
Figure 7: Comparisons with retrieval methods. The inputs are textured objects, including an albedo-only object and a scanned object. The materials include albedo (top left); roughness (top right); metallic (bottom left); bump (bottom right).

🔼 Figure 8 compares the material generation results of Material Anything with two closed-source methods, Rodin Gen-1 and Tripo3D. The figure visually demonstrates that despite using significantly less training data, Material Anything achieves comparable material generation quality to these established methods. This highlights the efficiency and effectiveness of the proposed approach.
read the caption
Figure 8: Comparisons with Rodin Gen-1 and Tripo3D. Rodin Gen-1 and Tripo3D are two closed-source methods. Our approach uses significantly less data, yet produces comparable results.

🔼 This figure demonstrates the impact of using a triple-head U-Net architecture and a rendering loss on material generation quality. The triple-head network separates the generation of albedo, roughness/metallic, and bump maps into individual branches, preventing interference and improving stability. The rendering loss further refines the generated materials by comparing rendered images of the generated maps with ground truth renderings. Both ablations (removing the triple-head architecture and removing the rendering loss) are shown alongside the full model, with the confidence mask set to 1 for all to ensure consistent lighting conditions. The results show clear improvements from the combined techniques.
read the caption
Figure 9: Effectiveness of triple-head U-Net and rendering loss. In both ablation experiments, the confidence mask is set to 1.

🔼 This figure shows the impact of using a confidence mask during material generation. The confidence mask helps the model to differentiate between situations with reliable lighting cues (allowing use of those cues for material estimation) and those without (requiring reliance on prompt and semantic information). The results demonstrate that using the confidence mask leads to superior material generation, especially in cases with unreliable or missing lighting information. The ‘W/O confidence mask’ section shows the inferior results obtained when the confidence mask is not utilized. This highlights the importance of the confidence mask in handling the diversity of lighting conditions encountered in real-world 3D objects.
read the caption
Figure 10: Effectiveness of confidence mask for various lighting conditions. “W/O confidence mask” indicates results from the material estimator without the confidence mask as input.

🔼 This figure demonstrates the impact of different strategies on achieving material consistency across multiple views of a 3D object. It visually compares the results of generating materials using various methods, showing the differences in terms of consistency and visual quality. The methods illustrated involve different combinations of confidence masks (to account for variations in lighting) and a UV-space material refiner. The goal is to highlight how these techniques improve the consistency of materials across multiple viewpoints of a 3D model.
read the caption
Figure 11: Effectiveness of strategies for material consistency.

🔼 The figure demonstrates the effectiveness of the UV-space material refiner in Material Anything. The left side shows material maps with holes and inconsistencies created by the image-space material generation process. These imperfections are due to self-occlusions in the 3D model, where parts of the object are hidden from view during rendering. The right side of the figure displays the refined material maps after processing by the UV-space material refiner. The refiner successfully fills in the missing areas and smooths out inconsistencies, producing cleaner, more consistent material maps ready for use in downstream applications such as video game development or virtual reality.
read the caption
Figure 12: Effectiveness of the UV-space material refiner. The material refiner effectively fills in holes caused by occlusions.

🔼 This figure visualizes the training data augmentation techniques used to improve the robustness of the Material Anything model. The top row shows examples of input images that have undergone various degradations (e.g., blurring, color shifts) to simulate real-world scenarios where lighting might be inconsistent. A confidence mask indicates regions affected by degradation, which guides the model to learn how to effectively handle uncertain or unreliable lighting cues. The bottom row shows examples of UV-space input data with masked regions and added canonical coordinate maps (CCM), which help refine the material generation process.
read the caption
Figure 13: The virtualization of our training data. We apply various degradations and simulate inconsistent lighting effects in the inputs to enhance the robustness of our method.

🔼 This figure illustrates the camera viewpoints used in the progressive material generation process. For each object, multiple views are rendered to capture comprehensive material properties. These views are then used in a progressive manner to estimate materials and refine the results. The images show example camera positions, highlighting how the process of generating materials from different views contributes to creating a more complete and accurate material representation.
read the caption
Figure 14: The camera poses for progressive material generation and building training data.

🔼 This figure demonstrates the capability of Material Anything to edit and customize materials of texture-less 3D objects by modifying the text prompt. The images show several examples of a 3D object rendered with different materials, all generated from the same object model but with varying text prompts specifying the desired material (e.g., wood, metal, stone). This highlights the method’s flexibility and ease of use for material modification.
read the caption
Figure 15: Material editing with prompts. Material Anything enables flexible editing and customization of materials for texture-less 3D objects by simply adjusting the input prompt.

🔼 This figure demonstrates the ability of the Material Anything model to generate realistic material properties for 3D objects under various lighting conditions. The left column shows the initial texture-less 3D models (a bed, a toilet, and a guitar). The top row displays the different HDR environment maps used for relighting. The remaining cells show the results of applying each HDR environment map to each object, demonstrating the generated materials’ consistent appearance across varying lighting scenarios. This highlights the model’s robustness and accuracy in generating physically-based rendering (PBR) materials.
read the caption
Figure 16: Relighting results by Material Anything under various HDR environment maps. The left column displays the input texture-less meshes, while the top row presents the HDR environment maps used.

🔼 This figure showcases instances where Material Anything, the proposed material generation model, fails to accurately generate material properties. The examples highlight limitations in handling fine surface details (as seen in the elephant’s textured skin), and in differentiating between materials and artifacts within the input (as shown in the apple, where a highlight is mistakenly interpreted as part of the fruit’s texture). These examples illustrate challenges the model faces in accurately segmenting and representing complex object details and subtle lighting effects.
read the caption
Figure 17: Failure Cases by Material Anything.

🔼 This figure displays the results of the material estimator, a core component of the Material Anything model, when applied to 2D renderings sourced from the Objaverse dataset. It showcases the model’s ability to estimate the albedo, roughness, metallic, and bump maps for different 3D objects. Each row represents a single object, with the ‘GT’ column displaying the ground truth material maps and the ‘Ours’ column displaying the model’s estimations. The visual comparison allows for a direct assessment of the accuracy and effectiveness of the material estimation process. The objects shown represent a variety of shapes and textures.
read the caption
Figure 18: Results by our material estimator on 2D renderings from Objaverse.

🔼 This figure showcases additional examples generated by the Material Anything model. It demonstrates the model’s ability to generate realistic material textures and maps for 3D objects that initially lacked any surface texture. Three different textureless 3D objects (a bagel, a crown, and a laptop) are used as inputs. For each object, the figure displays the original texture-less model, followed by the generated albedo, roughness, metallic, bump maps, and a final rendering of the object with the generated materials applied. The generated UV material maps are also provided, demonstrating the model’s output in a format suitable for use in 3D modeling applications.
read the caption
Figure 19: Additional results by Material Anything on texture-less 3D objects. The generated UV material maps are provided.
More on tables
| Materials | W/O Triple-head | W/O Rendering Loss | Full |
|---|---|---|---|
| Albedo | 0.0800 | 0.1442 | 0.0604 |
| Roughness | 0.1196 | 0.1943 | 0.0877 |
| Metallic | 0.1584 | 0.2594 | 0.1193 |
| Bump | 0.0824 | 0.0716 | 0.0313 |
🔼 This table presents the results of an ablation study evaluating the impact of two key components in the Material Anything model: the triple-head U-Net architecture and the rendering loss function. The study uses 1000 3D objects from the Objaverse dataset. For each object, the model generates material maps (albedo, roughness, metallic, and bump) for multiple views. The root mean squared error (RMSE) is calculated for each material type across all views to quantify the impact of removing each component individually. The table allows for a comparison of the model’s performance with both components included against the results when one or the other is excluded, showcasing their relative contributions to overall model accuracy.
read the caption
Table 2: Ablation study for triple-head U-Net and rendering loss. RMSE is calculated for the materials across the views from 1,000 Objaverse objects.
🔼 This ablation study analyzes the impact of confidence masks on Material Anything’s performance across various lighting conditions. The study uses 1000 Objaverse objects, categorized into three groups based on lighting: light-less (albedo-only, meaning no lighting information is present), realistic (scanned, representing real-world lighting conditions), and unrealistic (generated, representing synthetically created lighting). For each lighting category, the mean Root Mean Square Error (RMSE) is calculated for the generated albedo, roughness, metallic, and bump maps, to assess the model’s accuracy under different illumination scenarios. The results show how well Material Anything handles the task with and without confidence masks, demonstrating the effectiveness of the confidence mask in improving accuracy across different lighting conditions.
read the caption
Table 3: Ablation study for confidence masks. Mean RMSE is calculated for materials from 1,000 Objaverse objects with different simulated lighting conditions, including light-less (albedo-only), realistic (scanned), and unrealistic light (generated).
Full paper#
















