↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
End-to-end autonomous driving has traditionally struggled with the limitations of single-mode trajectory prediction and the high computational cost of multi-mode approaches. Existing methods like single-mode regression lack the ability to model uncertainty and multi-mode driving behavior, while vocabulary-based methods suffer from scalability issues. Diffusion models, while powerful, face challenges related to the number of denoising steps required and potential mode collapse in the dynamic driving environment.
DiffusionDrive tackles these issues with a truncated diffusion policy, incorporating prior multi-mode anchors to guide the denoising process and significantly reduce computational steps. An efficient cascade diffusion decoder enhances scene context interaction. The result is a superior model, achieving state-of-the-art performance on the NAVSIM dataset (88.1 PDMS) at real-time speed, demonstrating both high quality and diversity in generated driving actions, surpassing previous methods with far fewer computational resources.
Key Takeaways#
Why does it matter?#
This paper is significant because it demonstrates the potential of diffusion models for real-time end-to-end autonomous driving. It addresses the limitations of existing methods by introducing a novel truncated diffusion policy and an efficient decoder, achieving state-of-the-art results while maintaining real-time performance. This opens new avenues for research in generative models for robotics and autonomous systems, particularly in handling complex, multi-modal decision-making in dynamic environments. The work’s success in real-world settings highlights the practical value of diffusion models for autonomous driving and encourages further investigation into their application to more challenging autonomous driving problems.
Visual Insights#
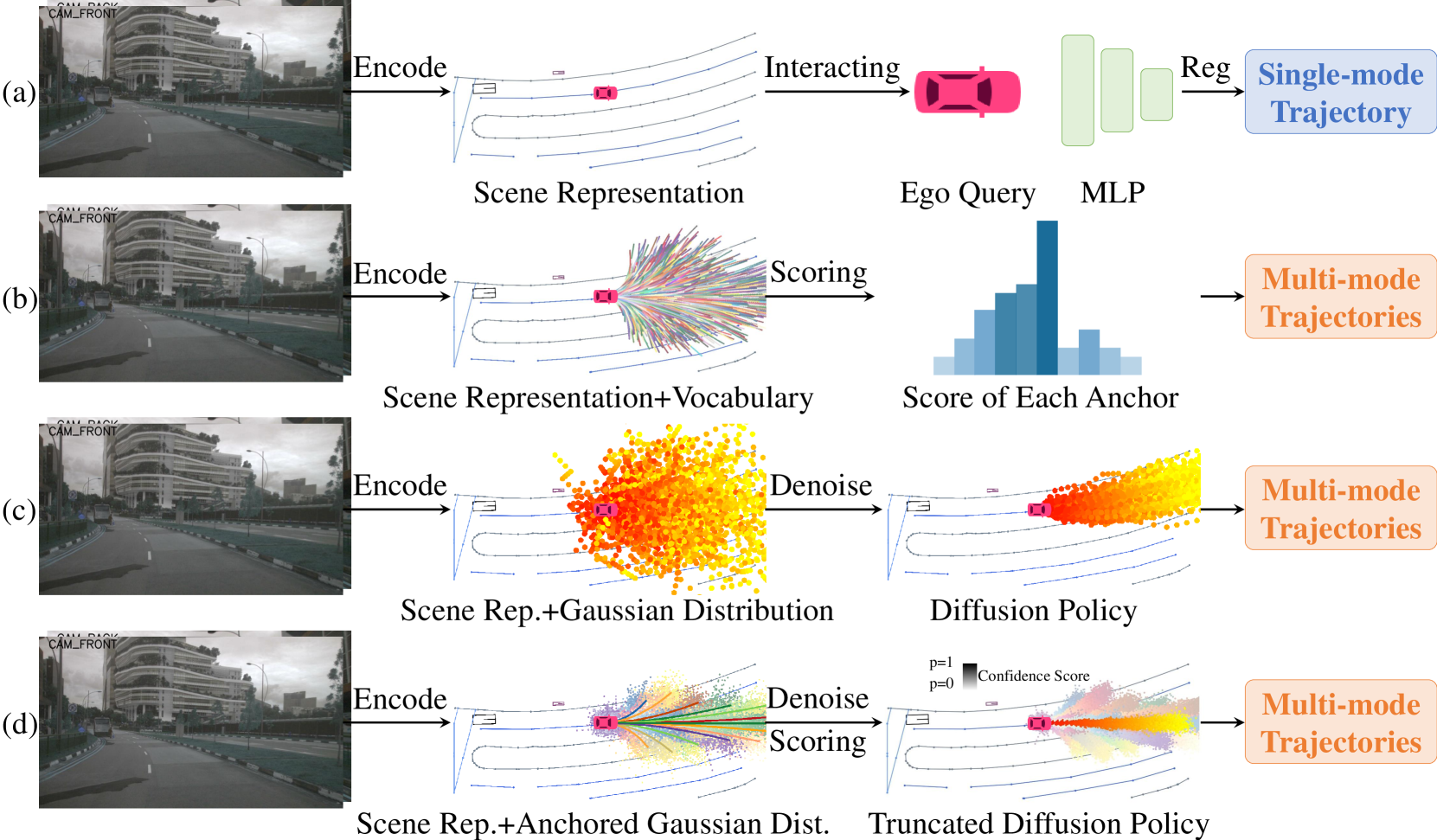
🔼 Figure 1 compares four different approaches to end-to-end autonomous driving. (a) shows a single-mode regression model, where the model directly predicts a single trajectory. (b) illustrates a method that samples from a pre-defined vocabulary of trajectories, representing various driving behaviors. (c) depicts a vanilla diffusion model, which uses many denoising steps to generate diverse trajectories from random noise. Finally, (d) presents the proposed ’truncated diffusion policy’, which improves upon the vanilla diffusion model by incorporating pre-defined anchors and reducing the number of denoising steps to increase efficiency and generate more realistic driving actions.
read the caption
Figure 1: The comparison of different end-to-end paradigms. (a) Single mode regression [17, 13, 6]. (b) Sampling from vocabulary [3, 22]. (c) Vanilla diffusion policy [5, 16]. (d) The proposed truncated diffusion policy.
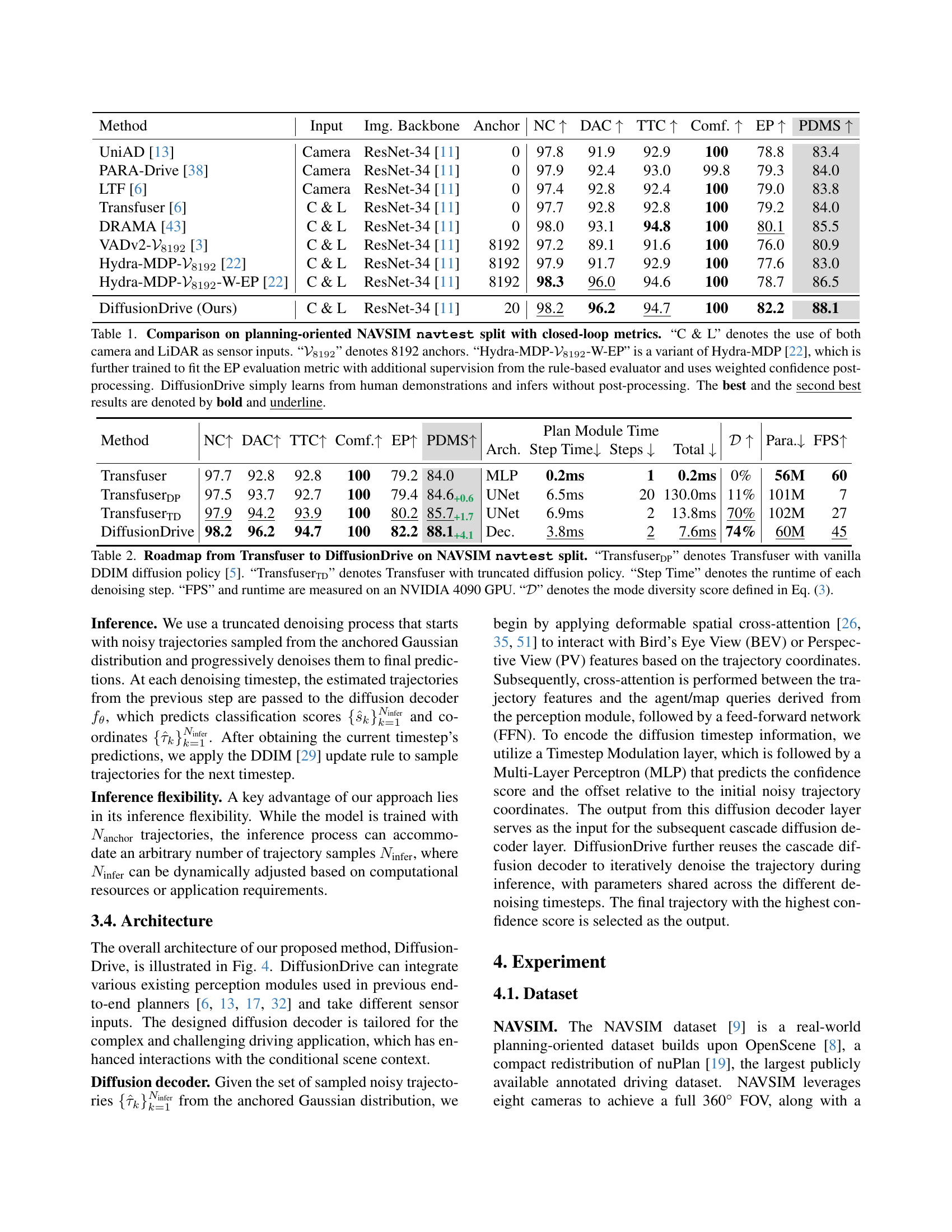
| Method | Input | Img. Backbone | Anchor | NC ↑ | DAC ↑ | TTC ↑ | Comf. ↑ | EP ↑ | PDMS ↑ |
|---|---|---|---|---|---|---|---|---|---|
| UniAD [13] | Camera | ResNet-34 [11] | 0 | 97.8 | 91.9 | 92.9 | 100 | 78.8 | 83.4 |
| PARA-Drive [38] | Camera | ResNet-34 [11] | 0 | 97.9 | 92.4 | 93.0 | 99.8 | 79.3 | 84.0 |
| LTF [6] | Camera | ResNet-34 [11] | 0 | 97.4 | 92.8 | 92.4 | 100 | 79.0 | 83.8 |
| Transfuser [6] | C & L | ResNet-34 [11] | 0 | 97.7 | 92.8 | 92.8 | 100 | 79.2 | 84.0 |
| DRAMA [43] | C & L | ResNet-34 [11] | 0 | 98.0 | 93.1 | 94.8 | 100 | 80.1 | 85.5 |
| VADv2-𝒬8192 [3] | C & L | ResNet-34 [11] | 8192 | 97.2 | 89.1 | 91.6 | 100 | 76.0 | 80.9 |
| Hydra-MDP-𝒬8192 [22] | C & L | ResNet-34 [11] | 8192 | 97.9 | 91.7 | 92.9 | 100 | 77.6 | 83.0 |
| Hydra-MDP-𝒬8192-W-EP [22] | C & L | ResNet-34 [11] | 8192 | 98.3 | 96.0 | 94.6 | 100 | 78.7 | 86.5 |
| DiffusionDrive (Ours) | C & L | ResNet-34 [11] | 20 | 98.2 | 96.2 | 94.7 | 100 | 82.2 | 88.1 |
🔼 Table 1 presents a comparison of different methods for end-to-end autonomous driving on the NAVSIM navtest split, using closed-loop evaluation metrics. The table shows the performance of various methods in terms of several key metrics: No At-Fault Collisions (NC), Drivable Area Compliance (DAC), Time-to-Collision (TTC), Comfort (Comf), and Ego Progress (EP), as well as the overall Planning-Driven Metric Score (PDMS). The methods compared include various state-of-the-art models and the proposed DiffusionDrive. The table highlights the use of different sensor inputs (Camera, LiDAR, or both), different numbers of anchors used in the methods (especially for those based on vocabulary-based approaches), and whether or not post-processing steps were employed (like weighted confidence and additional supervision). It also points out that DiffusionDrive is unique in that it learns directly from human driving data without post-processing steps, resulting in its superior performance.
read the caption
Table 1: Comparison on planning-oriented NAVSIM navtest split with closed-loop metrics. “C & L” denotes the use of both camera and LiDAR as sensor inputs. “𝒱8192subscript𝒱8192\mathcal{V}_{8192}caligraphic_V start_POSTSUBSCRIPT 8192 end_POSTSUBSCRIPT” denotes 8192 anchors. “Hydra-MDP-𝒱8192subscript𝒱8192\mathcal{V}_{8192}caligraphic_V start_POSTSUBSCRIPT 8192 end_POSTSUBSCRIPT-W-EP” is a variant of Hydra-MDP [22], which is further trained to fit the EP evaluation metric with additional supervision from the rule-based evaluator and uses weighted confidence post-processing. DiffusionDrive simply learns from human demonstrations and infers without post-processing. The best and the second best results are denoted by bold and underline.
In-depth insights#
Diffusion Models in Robotics#
Diffusion models have recently emerged as a powerful technique in robotics, particularly for policy learning. Their ability to model multi-modal action distributions is a significant advantage over traditional methods. A key challenge in applying diffusion models to robotics is the computational cost of the numerous denoising steps. This is especially true for complex tasks like autonomous driving, which demand real-time performance. Therefore, research focuses on efficiency improvements, such as truncated diffusion schedules and incorporating prior knowledge or anchors to guide the denoising process, speeding up inference. Another crucial aspect is managing the high dimensionality of robotic action spaces. The ability of diffusion models to elegantly handle uncertainty and generate diverse yet plausible actions makes them well-suited for handling the inherent stochasticity of real-world interactions. However, effective integration requires careful design of the model architecture and consideration of the specific robotic task, emphasizing the importance of contextual information and efficient interaction with environmental data. Ongoing research seeks to overcome limitations and further leverage the potential of diffusion models for more robust, adaptive, and versatile robotic systems.
Truncated Diffusion for Efficiency#
The concept of ‘Truncated Diffusion for Efficiency’ in the context of diffusion models for autonomous driving centers on addressing the computational cost associated with the numerous denoising steps typically involved. Standard diffusion models iteratively refine a noisy sample through many steps, which is computationally expensive. Truncation aims to reduce these steps without significantly sacrificing performance. This is achieved by strategically utilizing prior information, perhaps through the incorporation of multi-mode anchors representing common driving patterns. By starting the denoising process from a more informed point in the distribution (anchors), the model requires fewer steps to reach a suitable driving action. This trade-off between computational efficiency and solution quality is key. A truncated model is only as effective as its anchor selection and the chosen truncation point; careful design and experimentation are necessary to validate the method. The benefit is a substantial speed increase enabling real-time applications, crucial for autonomous driving systems. Careful selection of appropriate anchors is critical; these anchors act as informed starting points for the denoising process, effectively reducing the search space and thereby minimizing required computations. The effectiveness of truncation ultimately depends on a well-defined balance between maintaining sufficient diversity in action selection and reducing computational overhead.
Multi-Mode Action Generation#
Multi-mode action generation is a crucial aspect of advanced robotics and autonomous systems, particularly in dynamic environments like autonomous driving. The challenge lies in generating a diverse range of plausible actions rather than a single optimal one. This is because real-world scenarios are rarely deterministic; there are often multiple valid courses of action. Diffusion models offer a promising approach, as they can naturally capture multi-modal distributions by probabilistically sampling from a range of possibilities. However, naive application of diffusion models to robotics can be computationally expensive due to many iterations required for high-quality generation. Truncation strategies, like the one explored in this paper, aim to mitigate the computational burden while still retaining sufficient diversity. Anchoring the diffusion process around prior actions or patterns, which reflects the inherent structure of many real-world tasks, further improves efficiency and diversity. Efficient decoders are also necessary to process contextual information and generate coherent action sequences in real-time, especially for high-dimensional domains like autonomous driving. The interplay between computational efficiency, action diversity, and the ability to integrate environment context is vital for success. Optimizing these elements allows autonomous systems to operate reliably and safely in multifaceted situations.
NAVSIM Benchmark Results#
The NAVSIM benchmark results section would be crucial in evaluating the performance of the proposed DiffusionDrive model. It would ideally present a detailed comparison against state-of-the-art methods, showcasing superior performance in key metrics like PDMS (Planning-oriented Driving Metrics Score). Quantitative analysis of metrics such as collision rate, drivable area compliance, and time-to-collision, alongside qualitative analysis of generated trajectories’ diversity and plausibility, would be necessary for a robust evaluation. Specific attention should be given to demonstrating the real-time performance capabilities of DiffusionDrive, possibly through FPS (frames per second) measurements on a standard GPU. The discussion should highlight the model’s ability to generate diverse and plausible driving actions, particularly in challenging scenarios, contrasting with limitations of previous single-mode regression approaches. Finally, the section must carefully consider factors that may affect the overall evaluation, such as data split used for evaluation and the type of backbone network employed for fairness in comparison.
Future of Diffusion Driving#
The future of diffusion-based driving hinges on addressing current limitations and capitalizing on inherent strengths. Real-time performance remains crucial; optimizations like the truncated diffusion model are key, but further advancements in computational efficiency are needed for widespread adoption. Data efficiency is another concern; while diffusion models excel at generating diverse outputs, the reliance on substantial, high-quality training data necessitates further research into more efficient data augmentation or self-supervised learning techniques. Robustness to unexpected events is paramount; ensuring that models handle unforeseen situations (e.g., unusual weather, unpredictable pedestrian behavior) effectively is vital. Finally, integrating diffusion models with other advanced driving technologies (e.g., path planning, decision-making algorithms) to create a truly comprehensive and versatile autonomous driving system presents a promising and significant area of future research. The ultimate success depends on the ability to overcome these challenges while maximizing the inherent benefits of diffusion models: their capacity for multi-modal action generation and high-quality trajectory prediction.
More visual insights#
More on figures

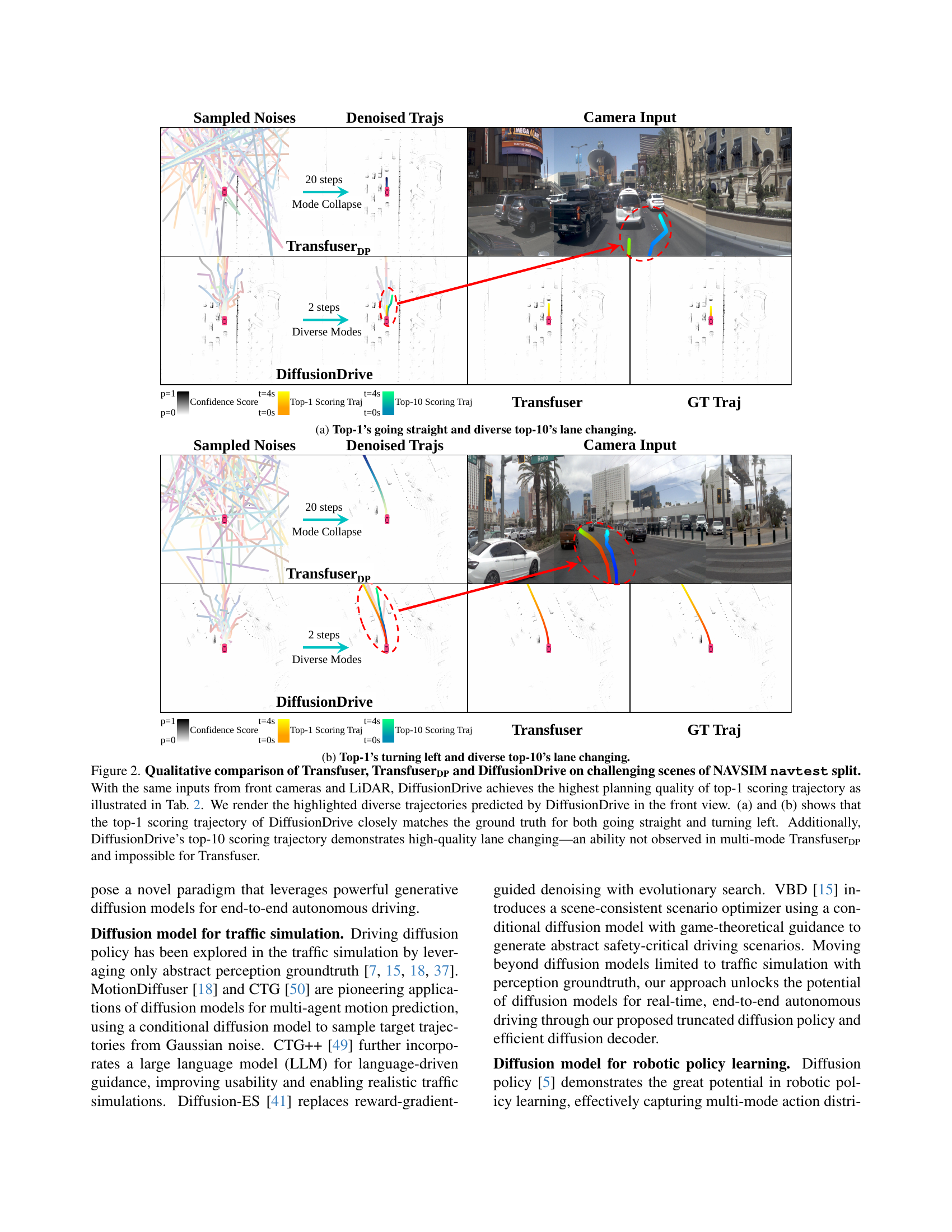
🔼 This figure shows a comparison of trajectory predictions by different methods on a challenging driving scenario from the NAVSIM dataset. The left side shows the sampled noise used as input and the denoised trajectories generated by Transfuser, TransfuserDP, and DiffusionDrive. The right side shows the corresponding camera input and the ground truth trajectory (GT Traj). The top row (a) focuses on a scenario where the ground truth is going straight, and the bottom row (b) focuses on a scenario where the ground truth is turning left. DiffusionDrive demonstrates superior performance by closely matching the ground truth trajectory and generating a diverse set of plausible alternative trajectories (top-10 scoring trajectories) that encompass various driving behaviors, such as lane changing, which were not observed in other methods.
read the caption
(a) Top-1’s going straight and diverse top-10’s lane changing.

🔼 This figure (Figure 2(b)) shows a comparison of different model’s trajectory prediction results on a challenging lane-changing scenario from the NAVSIM dataset. The ground truth trajectory shows a vehicle turning left. Transfuser produces only a single trajectory prediction, indicating a mode collapse issue. TransfuserDP, while slightly better, still exhibits a lack of diversity in its trajectory predictions. In contrast, DiffusionDrive predicts both a top-1 trajectory that accurately matches the ground truth, and diverse top-10 trajectories showcasing different, yet plausible, lane-changing maneuvers. This demonstrates DiffusionDrive’s capability to generate multiple high-quality, diverse driving actions.
read the caption
(b) Top-1’s turning left and diverse top-10’s lane changing.

🔼 Figure 2 showcases a qualitative comparison of three different methods for autonomous driving planning: Transfuser, TransfuserDP, and DiffusionDrive. All three methods receive the same inputs from front-facing cameras and LiDAR sensors. The figure demonstrates that DiffusionDrive generates the highest-quality top-1 scoring trajectory, closely matching ground truth trajectories for both straight and turning maneuvers (as detailed in Table 2). Furthermore, the figure highlights the diversity of DiffusionDrive’s top-10 trajectories, exhibiting complex maneuvers such as lane changes—a capability that neither Transfuser nor TransfuserDP possess. This visual comparison strongly supports the claim that DiffusionDrive outperforms the other methods.
read the caption
Figure 2: Qualitative comparison of Transfuser, TransfuserDPDP{}_{\text{DP}}start_FLOATSUBSCRIPT DP end_FLOATSUBSCRIPT and DiffusionDrive on challenging scenes of NAVSIM navtest split. With the same inputs from front cameras and LiDAR, DiffusionDrive achieves the highest planning quality of top-1 scoring trajectory as illustrated in Tab. 2. We render the highlighted diverse trajectories predicted by DiffusionDrive in the front view. (a) and (b) shows that the top-1 scoring trajectory of DiffusionDrive closely matches the ground truth for both going straight and turning left. Additionally, DiffusionDrive’s top-10 scoring trajectory demonstrates high-quality lane changing—an ability not observed in multi-mode TransfuserDPDP{}_{\text{DP}}start_FLOATSUBSCRIPT DP end_FLOATSUBSCRIPT and impossible for Transfuser.

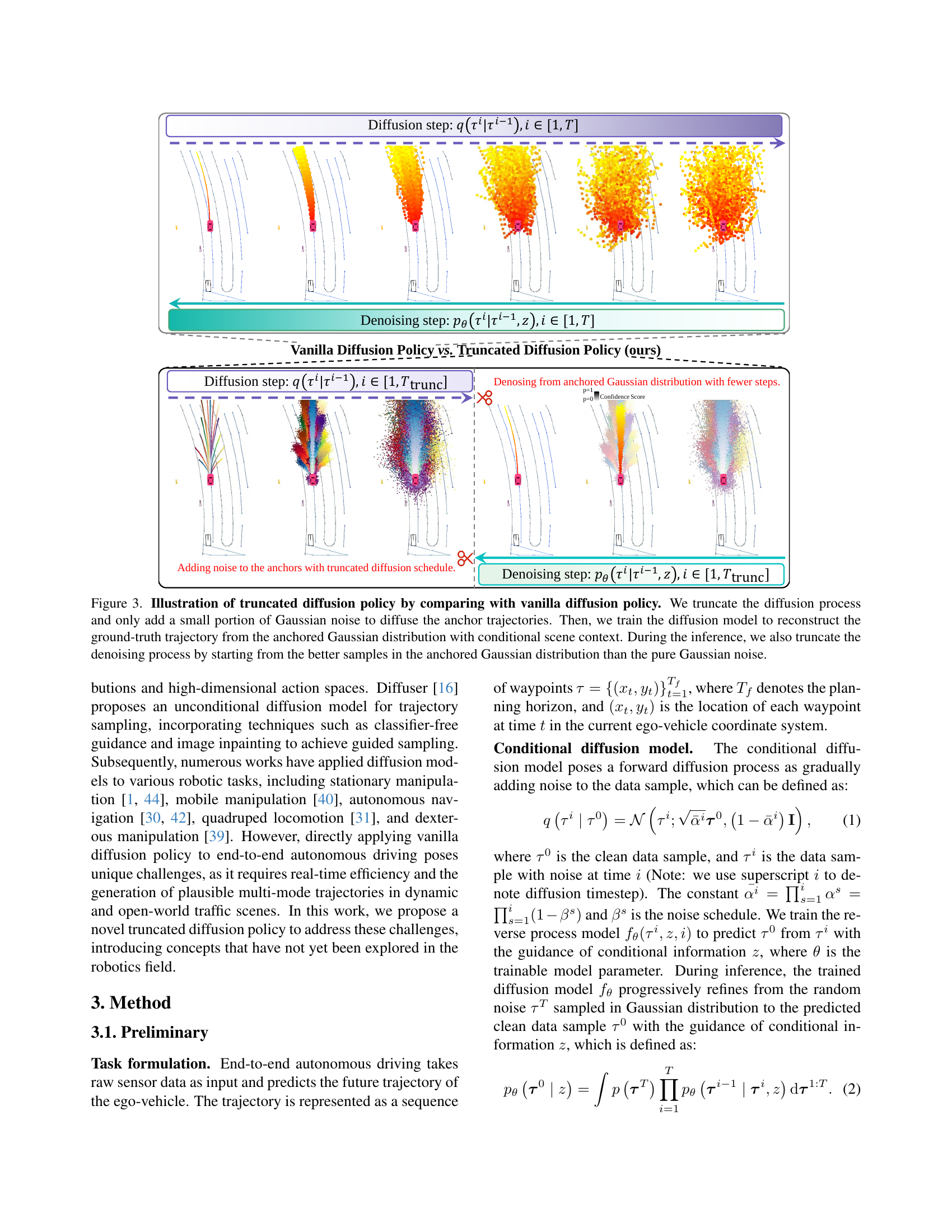
🔼 This figure compares the vanilla diffusion policy with the proposed truncated diffusion policy. The vanilla method starts with random Gaussian noise and iteratively denoises it towards the target trajectory over many steps. In contrast, the truncated policy begins with a set of anchor trajectories representing common driving patterns. Only a small amount of noise is added to these anchors, and the diffusion process is shortened to a much smaller number of steps. Training involves learning to reconstruct ground-truth trajectories from these noisy anchor samples, considering scene context. Inference also uses the truncated method, starting with the closest anchors to initial conditions, leading to faster and potentially more diverse results.
read the caption
Figure 3: Illustration of truncated diffusion policy by comparing with vanilla diffusion policy. We truncate the diffusion process and only add a small portion of Gaussian noise to diffuse the anchor trajectories. Then, we train the diffusion model to reconstruct the ground-truth trajectory from the anchored Gaussian distribution with conditional scene context. During the inference, we also truncate the denoising process by starting from the better samples in the anchored Gaussian distribution than the pure Gaussian noise.
More on tables
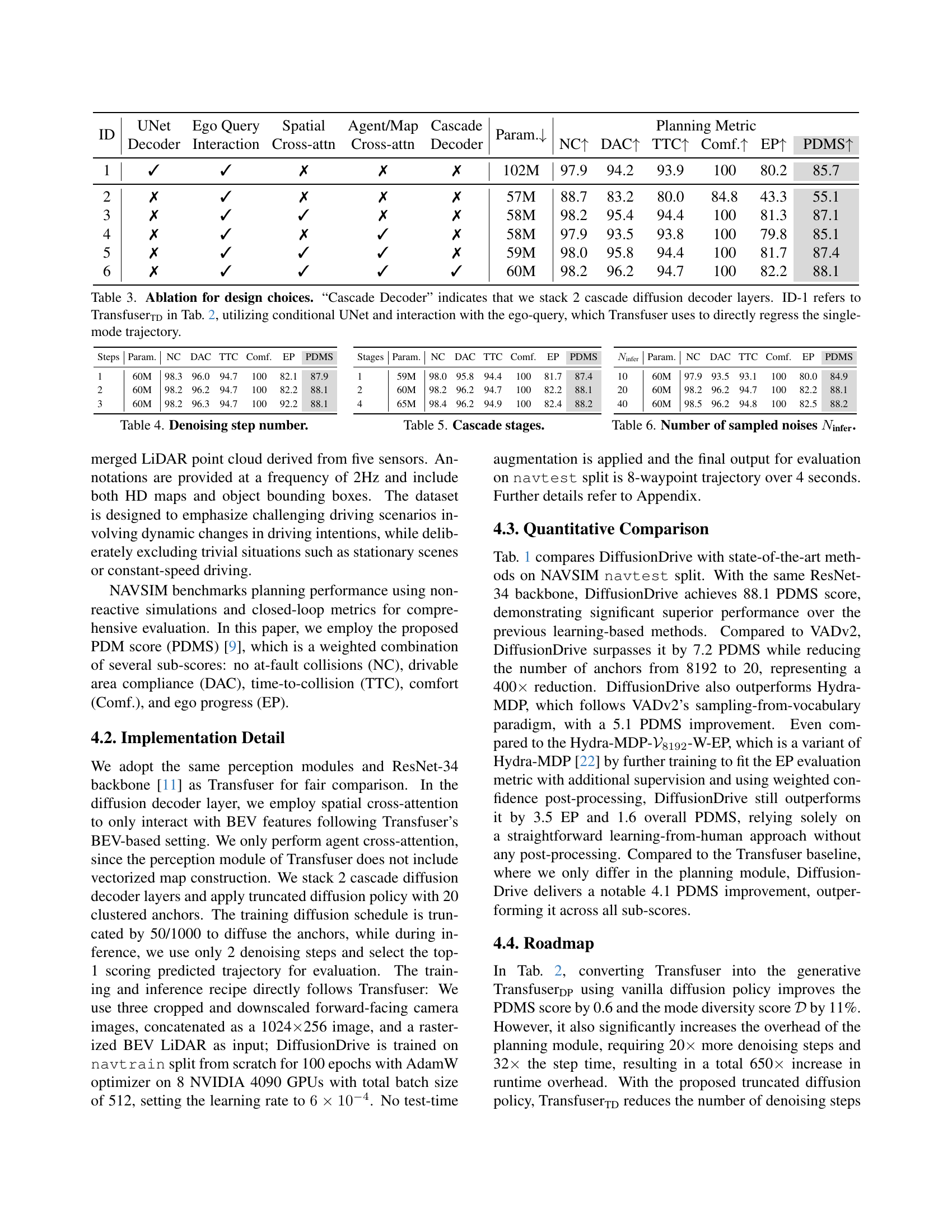
| Method | NC↑ | DAC↑ | TTC↑ | Comf.↑ | EP↑ | PDMS↑ | Arch. | Step Time↓ | Steps ↓ | Total ↓ | Para.↓ | FPS↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Transfuser | 97.7 | 92.8 | 92.8 | 100 | 79.2 | 84.0 | MLP | 0.2ms | 1 | 0.2ms | 0% | 56M |
| TransfuserDP | 97.5 | 93.7 | 92.7 | 100 | 79.4 | 84.6+0.6 | UNet | 6.5ms | 20 | 130.0ms | 11% | 101M |
| TransfuserTD | 97.9 | 94.2 | 93.9 | 100 | 80.2 | 85.7+1.7 | UNet | 6.9ms | 2 | 13.8ms | 70% | 102M |
| DiffusionDrive | 98.2 | 96.2 | 94.7 | 100 | 82.2 | 88.1+4.1 | Dec. | 3.8ms | 2 | 7.6ms | 74% | 60M |
🔼 This table shows the evolution of the model from a baseline Transfuser model to the final DiffusionDrive model. It illustrates the impact of incorporating different diffusion policy types (vanilla DDIM and the truncated version) on various metrics. The metrics include performance (PDMS score, which combines multiple aspects of driving performance), efficiency (steps, step time, and FPS), and trajectory diversity (D). This allows for a comparison of the trade-offs between performance, efficiency, and diversity achieved with different model modifications. The runtime measurements are all performed on the same NVIDIA 4090 GPU.
read the caption
Table 2: Roadmap from Transfuser to DiffusionDrive on NAVSIM navtest split. “TransfuserDPDP{}_{\text{DP}}start_FLOATSUBSCRIPT DP end_FLOATSUBSCRIPT” denotes Transfuser with vanilla DDIM diffusion policy [5]. “TransfuserTDTD{}_{\text{TD}}start_FLOATSUBSCRIPT TD end_FLOATSUBSCRIPT” denotes Transfuser with truncated diffusion policy. “Step Time” denotes the runtime of each denoising step. “FPS” and runtime are measured on an NVIDIA 4090 GPU. “𝒟𝒟\mathcal{D}caligraphic_D” denotes the mode diversity score defined in Eq. (3).
| ID | UNet | Ego Query | Spatial | Agent/Map | Cascade | Param.↓ | Planning Metric | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✓ | ✗ | ✗ | ✗ | 102M | NC↑ | DAC↑ | TTC↑ | Comf.↑ | EP↑ | PDMS↑ |
| Decoder | Interaction | Cross-attn | Cross-attn | Decoder | 97.9 | 94.2 | 93.9 | 100 | 80.2 | 85.7 | ||
| 2 | ✗ | ✓ | ✗ | ✗ | ✗ | 57M | 88.7 | 83.2 | 80.0 | 84.8 | 43.3 | 55.1 |
| 3 | ✗ | ✓ | ✓ | ✗ | ✗ | 58M | 98.2 | 95.4 | 94.4 | 100 | 81.3 | 87.1 |
| 4 | ✗ | ✓ | ✗ | ✓ | ✗ | 58M | 97.9 | 93.5 | 93.8 | 100 | 79.8 | 85.1 |
| 5 | ✗ | ✓ | ✓ | ✓ | ✗ | 59M | 98.0 | 95.8 | 94.4 | 100 | 81.7 | 87.4 |
| 6 | ✗ | ✓ | ✓ | ✓ | ✓ | 60M | 98.2 | 96.2 | 94.7 | 100 | 82.2 | 88.1 |
🔼 This ablation study analyzes the impact of different design choices in the DiffusionDrive model’s architecture. It examines the effects of using a cascade decoder (stacking two decoder layers), incorporating a conditional UNet, and including interaction with ego-queries (similar to the Transfuser model). The baseline (ID-1) is the TransfuserTD model from Table 2 which already uses a conditional UNet. The study systematically removes or adds components to assess their individual contributions to the overall model performance, as measured by several metrics.
read the caption
Table 3: Ablation for design choices. “Cascade Decoder” indicates that we stack 2 cascade diffusion decoder layers. ID-1 refers to TransfuserTDTD{}_{\text{TD}}start_FLOATSUBSCRIPT TD end_FLOATSUBSCRIPT in Tab. 2, utilizing conditional UNet and interaction with the ego-query, which Transfuser uses to directly regress the single-mode trajectory.
| Steps | Param. | NC | DAC | TTC | Comf. | EP | PDMS |
|---|---|---|---|---|---|---|---|
| 1 | 60M | 98.3 | 96.0 | 94.7 | 100 | 82.1 | 87.9 |
| 2 | 60M | 98.2 | 96.2 | 94.7 | 100 | 82.2 | 88.1 |
| 3 | 60M | 98.2 | 96.3 | 94.7 | 100 | 92.2 | 88.1 |
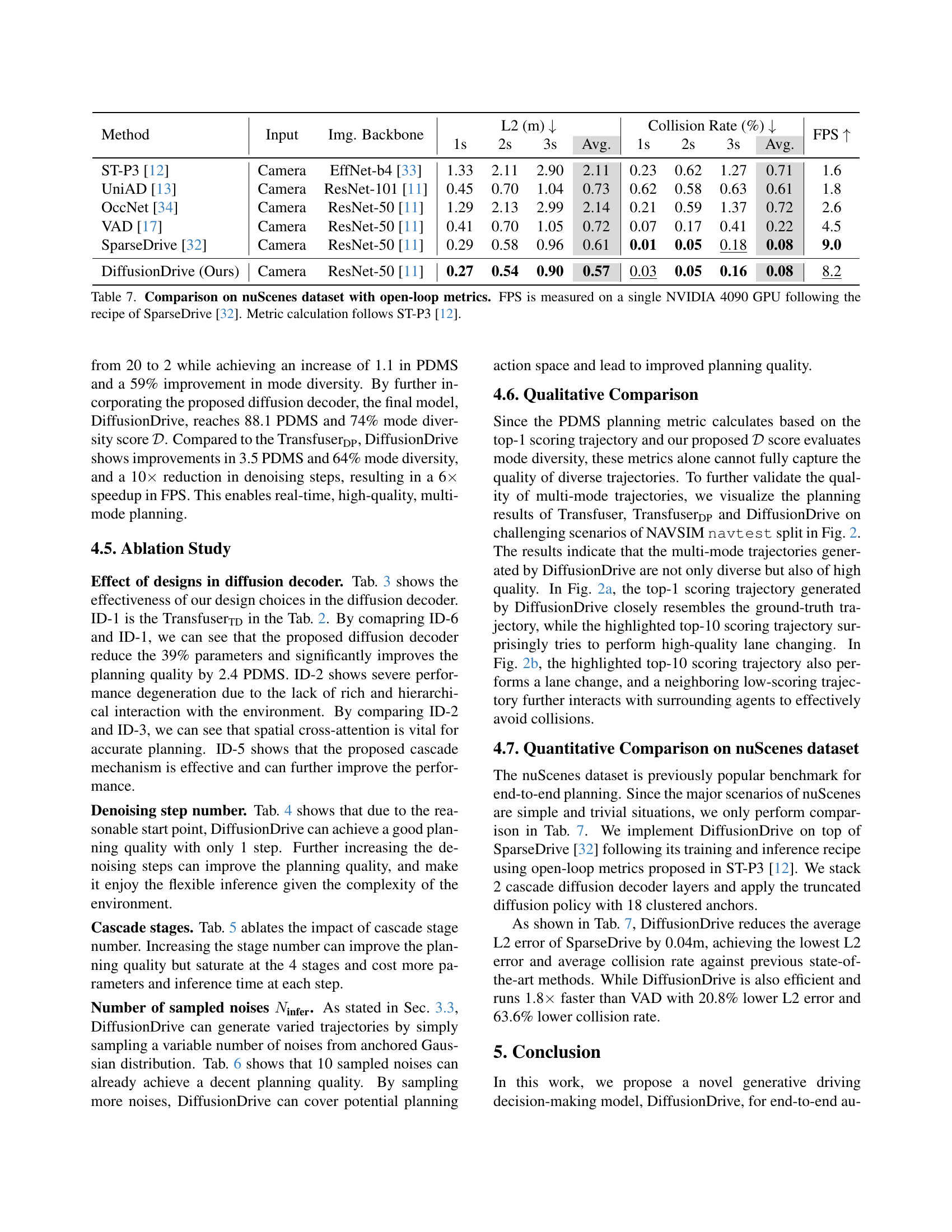
🔼 This table presents a comparison of different methods for autonomous driving on the nuScenes dataset using open-loop metrics. The metrics evaluated include the average L2 error (in meters) at 1, 2, and 3 seconds into the future, and the collision rate (in percentage) over those same timeframes. The performance is assessed across different methods, considering the input data (camera only), the backbone architecture used (e.g., ResNet-50), and the frames per second (FPS) achieved on a single NVIDIA 4090 GPU. The experimental setup and metric calculation follow the SparseDrive [32] and ST-P3 [12] methodologies, ensuring consistency and comparability.
read the caption
Table 7: Comparison on nuScenes dataset with open-loop metrics. FPS is measured on a single NVIDIA 4090 GPU following the recipe of SparseDrive [32]. Metric calculation follows ST-P3 [12].
Full paper#