↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multimodal Large Language Models (MLLMs) are rapidly advancing, yet their evaluation remains fragmented and inconsistent. This paper addresses this challenge by providing a comprehensive survey of existing MLLM evaluation methods and benchmarks. It highlights the lack of a standardized evaluation framework and the need for more robust and comprehensive assessment strategies.
The paper offers a structured taxonomy of MLLM benchmarks, distinguishing evaluations based on foundational capabilities, model behavior and extended applications. It provides guidelines on constructing benchmarks, selecting appropriate evaluation methods, and identifying key challenges such as data leakage and the need for vision-centric evaluations. The authors discuss future research directions that would improve MLLM evaluation, such as developing well-defined capability taxonomies, incorporating more modalities, and establishing task-oriented evaluation frameworks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in the field of multimodal large language models (MLLMs). It provides a comprehensive survey of MLLM evaluation, addressing key challenges and guiding future research directions. The systematic taxonomy of benchmarks and evaluation methods offers valuable insights and facilitates easier identification of suitable methods for different research needs. Furthermore, the paper highlights gaps in current MLLM evaluation practices, paving the way for new research in improved benchmarks and methodologies.
Visual Insights#

🔼 This figure displays a timeline of multimodal large language model (MLLM) benchmark development. The x-axis represents time, showing the periods when new benchmarks were created. The y-axis implicitly represents the number of new benchmarks introduced during each time period, with the height of the bubbles in the center corresponding to this count. This allows for a visual understanding of the evolution and growth of the MLLM evaluation field over time.
read the caption
Figure 1: Time line of existing MLLM benchmarks. The center shows the number of benchmarks born at each time.
| Benchmarks | QA Pairs | Answer Type | Metrics | Categories | Data Collection | Annotation |
|---|---|---|---|---|---|---|
| VQA v2 [18] | 453.0k | Open-Ended | Deterministic | Comprehensive Evaluation | Incorporating Samples From Existing Datasets | Manually |
| RefCOCO [81] | 10.0k | Open-Ended | Deterministic | Visual Grounding | Incorporating Samples From Existing Datasets | Manually |
| RefCOCO+ [81] | 10.0k | Open-Ended | Deterministic | Visual Grounding | Incorporating Samples From Existing Datasets | Manually |
| RefCOCOg [81] | 14.0k | Open-Ended | Deterministic | Visual Grounding | Incorporating Samples From Existing Datasets | Manually |
| EmbodiedQA [156] | 5.0k | Open-Ended | Deterministic | EmbodiedAI | Incorporating Samples From Existing Datasets | Automatically Constructing |
| TextVQA [36] | 5.7k | Open-Ended | Deterministic | OCR | Incorporating Samples From Existing Datasets | Manually |
| Ego4D [158] | 12.7k | Open-Ended | Deterministic | EmbodiedAI(Video) | Gathering Data From the Internet | Manually |
| VizWiz [19] | 8.0k | Open-Ended | Deterministic | Comprehensive Evaluation | Incorporating Samples From Existing Datasets | Manually |
| NLVR2 [73] | 2.0k | Yes-or-No | Deterministic | Multi-Image | Gathering Data From the Internet | Manually |
| MME [24] | 2.3k | Yes-or-No | Deterministic | Comprehensive Evaluation | Incorporating Samples From Existing Datasets | Manually |
| Video-MME [87] | 2.7k | Multi-Choice | Deterministic | Video Understanding | Gathering Data From the Internet | Manually |
| MME-RealWorld [35] | 29.4k | Multi-Choice | Deterministic | High Resolution | Incorporating Samples From Existing Datasets | Manually |
| ScienceQA [58] | 21.0k | Multi-Choice | Deterministic | Multidisciplinary | Gathering Data From the Internet | Manually |
| DocVQA [43] | 50.0k | Open-Ended | Deterministic | Chart and Documentation | Gathering Data From the Internet | Manually |
| BDD-X [164] | 6.9k | Open-Ended | Deterministic | Autonomous Driving(Video) | Incorporating Samples From Existing Datasets | Manually |
| ActivityNet-QA [98] | 58.0k | Open-Ended | Scoring | Video Understanding | Gathering Data From the Internet | Manually |
| AI2D [180] | 4.5k | Multi-Choice | Deterministic | Chart and Documentation | Gathering Data From the Internet | Manually |
| POPE [99] | 3.0k | Yes-or-No | Deterministic | Hallucination | Incorporating Samples From Existing Datasets | Manually |
| ChartQA [42] | 32.7k | Open-Ended | Deterministic | Chart and Documentation | Gathering Data From the Internet | Manually |
| FigureQA [52] | 1.0M | Yes-or-No | Deterministic | Chart and Documentation | Gathering Data From the Internet | Automatically Constructing |
| OCR-VQA [37] | 100.0k | Open-Ended | Deterministic | OCR | Incorporating Samples From Existing Datasets | Automatically Constructing |
| MMBench [22] | 3.2k | Multi-Choice | Deterministic | Comprehensive Evaluation | Gathering Data From the Internet | Manually |
| EPIC-KITCHENS [157] | 10.9k | Open-Ended | Deterministic | Embodied AI(Video) | Gathering Data From the Internet | Manually |
| MathVista [53] | 6.1k | Open-Ended/Multi-Choice | Deterministic | Mathematical | Gathering Data From the Internet | Manually |
| MM-Vet [31] | 218 | Open-Ended | Scoring | Comprehensive Evaluation | Gathering Data From the Internet | Manually |
| SEED-Bench [23] | 19.2k | Multi-Choice | Deterministic | Comprehensive Evaluation | Incorporating Samples From Existing Datasets | Manually |
| RSVQA [133] | 299.6k | Open-Ended | Deterministic | Remote Sensing | Gathering Data From the Internet | Automatically Constructing |
| InfoVQA [44] | 3.2k | Open-Ended | Deterministic | Chart and Documentation | Gathering Data From the Internet | Manually |
| SLAKE [126] | 2.1k | Open-Ended/Multi-Choice | Deterministic | Medical Image | Incorporating Samples From Existing Datasets | Manually |
| RSIVQA [134] | 111.0k | Open-Ended | Deterministic | Remote Sensing | Incorporating Samples From Existing Datasets | Manually |
| VisualMRC [50] | 30.6k | Open-Ended | Deterministic | Chart and Documentation | Gathering Data From the Internet | Manually |
| MMMU [59] | 11.5k | Open-Ended/Multi-Choice | Deterministic | Multidisciplinary | Gathering Data From the Internet | Manually |
| PATHVQA [125] | 6.0k | Open-Ended/Yes-or-No | Deterministic | Medical Image | Gathering Data From the Internet | Automatically Constructing |
| HAD [165] | 5.7k | Open-Ended | Deterministic | Autonomous Driving(Video) | Gathering Data From the Internet | Manually |
| Talk2Car [166] | 850 | Open-Ended | Deterministic | Autonomous Driving(Video) | Gathering Data From the Internet | Manually |
| LVLM-eHub [20] | 288.8k | Open-Ended/Multi-Choice | Deterministic | Comprehensive Evaluation | Incorporating Samples From Existing Datasets | Automatically Constructing |
| VQA-RAD [124] | 451 | Open-Ended/Yes-or-No | Deterministic | Medical Image | Gathering Data From the Internet | Automatically Constructing |
| MVBench [88] | 4.0k | Multi-Choice | Deterministic | Video Understanding | Gathering Data From the Internet | Automatically Constructing |
| LEAF-QA [51] | 1.6M | Open-Ended | Deterministic | Chart and Documentation | Gathering Data From the Internet | Automatically Constructing |
| GPT4tools [143] | 652 | Open-Ended | Deterministic | Agent | Gathering Data From the Internet | LLMs/MLLMs |
| Screen2Words [147] | 21.5k | Open-Ended | Deterministic | GUI | Gathering Data From the Internet | Manually |
| Widget Captioning [151] | 12.3k | Open-Ended | Deterministic | GUI | Gathering Data From the Internet | Manually |
| MMHAL-BENCH [103] | 96 | Open-Ended | Scoring | Hallucination | Incorporating Samples From Existing Datasets | Manually |
| AttackVLM [120] | 50.0k | Open-Ended | Deterministic | Safety | Incorporating Samples From Existing Datasets | Manually |
| PMC-VQA [127] | 2.0k | Open-Ended/Multi-Choice | Deterministic | Medical Image | Incorporating Samples From Existing Datasets | LLMs/MLLMs |
| EgoSchema [94] | 5.0k | Multi-Choice | Deterministic | Video Understanding | Gathering Data From the Internet | Manually |
| M-HalDetect [101] | 3.2k | Open-Ended | Scoring | Hallucination | Incorporating Samples From Existing Datasets | Manually |
| OCRBench [39] | 1.0k | Open-Ended | Deterministic | OCR | Incorporating Samples From Existing Datasets | Manually |
| GAVIE [100] | 1.0k | Open-Ended | Scoring | Hallucination | Incorporating Samples From Existing Datasets | LLMs/MLLMs |
| HallusionBench [106] | 1.1k | Yes-or-No | Scoring | Hallucination | Modifying Existing Data | Manually |
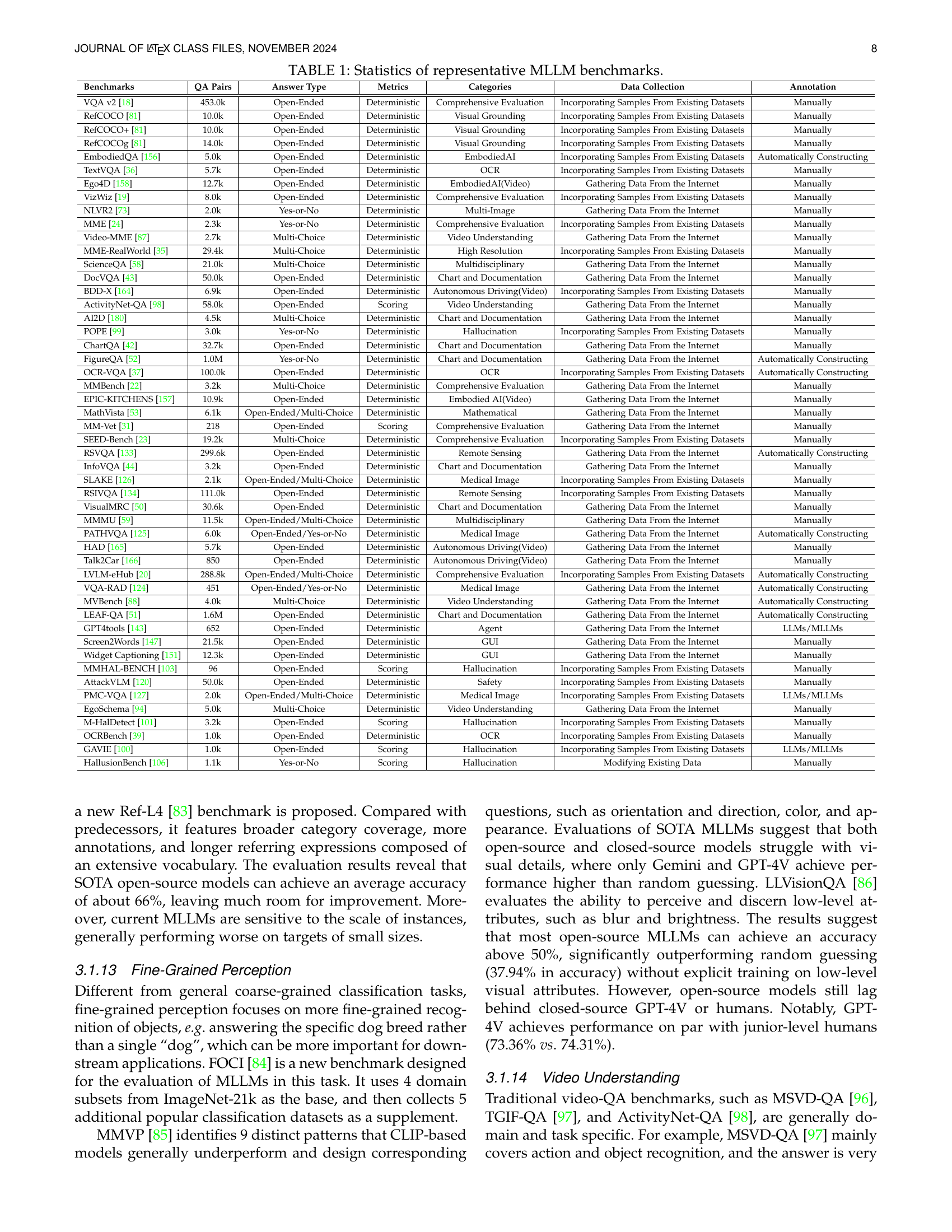
🔼 This table provides a summary of key statistics for several prominent Multimodal Large Language Model (MLLM) benchmarks. For each benchmark, it lists the number of question-answer pairs, the type of answers (open-ended, multiple choice, yes/no), the type of metrics used for evaluation, the categories the benchmark falls into (e.g., comprehensive evaluation, OCR, video understanding), the method used for data collection (gathering from the internet, incorporating from existing datasets, modifying existing data, or automatically constructing pairs), and finally, the annotation method (manual or automatic). This detailed information helps researchers quickly compare and contrast various MLLM evaluation benchmarks and choose those most suitable for their research needs.
read the caption
TABLE I: Statistics of representative MLLM benchmarks.
In-depth insights#
Multimodal LLM Eval#
Evaluating Multimodal Large Language Models (MLLMs) presents unique challenges. Comprehensive evaluation necessitates a move beyond traditional single-task benchmarks to assess diverse capabilities, including foundational skills (perception, reasoning), emergent behaviors (hallucination, bias), and extended applications (medical image analysis, code generation). Benchmark construction requires careful consideration of data sources, annotation methods, and potential biases. Evaluation methodologies range from human judgment (expensive but accurate) to automated LLM/MLLM scoring (efficient but potentially biased) and simple script-based techniques. Metrics need to evolve beyond simple accuracy measures to capture nuanced aspects of performance, including reasoning quality and the subtlety of handling diverse input modalities. The field needs well-defined capability taxonomies to guide benchmark design and provide researchers with a clear framework for assessing MLLM capabilities across varied tasks and applications. Future research must focus on incorporating more modalities beyond vision and language, developing robust assessment tools for creative tasks and agent interactions, and bridging the gap between fundamental capabilities and real-world applications.
Benchmark Taxonomy#
A well-defined benchmark taxonomy is crucial for evaluating Multimodal Large Language Models (MLLMs). Organizing benchmarks hierarchically, based on the capabilities assessed (foundational, behavioral, and application-specific), provides a clear structure. This taxonomy should not only categorize existing benchmarks but also guide the development of new ones, ensuring comprehensive coverage of MLLM abilities. Focusing on well-defined capabilities, rather than specific tasks, allows for more robust and generalizable evaluations. This approach allows researchers to better understand the strengths and weaknesses of different models across various aspects of multimodal understanding. A robust taxonomy facilitates comparisons across different benchmarks and helps identify gaps in current evaluation methodologies. It is important to account for evolving MLLM capabilities and incorporate more modalities (such as audio and 3D data) into future taxonomic structures, to reflect the expanding capabilities of the field.
MLLM Training#
Multimodal Large Language Model (MLLM) training is a complex process that builds upon Large Language Model (LLM) training, but adds the significant challenge of integrating multiple modalities. Pre-training typically involves aligning different modalities (e.g., text and images) using large paired datasets. This stage focuses on learning cross-modal representations and embedding different data types into a shared latent space. Instruction tuning then refines the model’s ability to follow instructions given in natural language, frequently by using instruction-following datasets with prompts and desired responses. Crucially, alignment tuning is often employed to match the model’s outputs more closely to human preferences, by using preference data or feedback mechanisms. This addresses challenges such as biases, hallucinations, and safety concerns. The training procedure may utilize various techniques such as reinforcement learning from human feedback (RLHF), to improve the model’s performance and reduce biases. The choice of dataset and the balance between pre-training and fine-tuning are critical factors determining MLLM performance. The scale of training data, model size, and computational resources significantly influence the capabilities that emerge from MLLM training. Further research is needed to explore more efficient training methods and better ways of aligning models with human values and expectations.
Eval Methodologies#
Effective evaluation methodologies for Multimodal Large Language Models (MLLMs) are crucial for advancing the field. The paper highlights several approaches, including human evaluation, which provides a gold standard but is expensive and time-consuming. LLM/MLLM-based evaluation, using other LLMs to score responses, is faster but introduces bias from the evaluating model’s own limitations. Script-based methods are simpler for multiple choice questions but may overlook nuanced understanding. The choice of methodology depends on the specific task, resource availability, and desired level of detail. A balanced approach, combining several techniques, is recommended for a comprehensive evaluation of MLLMs, which considers both objective and subjective aspects of model performance. Future work should focus on developing more sophisticated and robust evaluation metrics, including those that account for potential biases and the unique challenges of evaluating multimodal reasoning.
Future Directions#
Future research directions in Multimodal Large Language Models (MLLMs) necessitate a multifaceted approach. Improving benchmark design is crucial, addressing limitations such as data leakage, vision-centricity bias, and a lack of diversity. Developing a standardized capability taxonomy is vital to ensure consistent and comprehensive evaluation. Extending evaluation to more modalities, like audio and 3D data, is also imperative. Furthermore, real-world applications should be emphasized; current benchmarks often fail to fully capture real-world complexities. Task-oriented evaluations are needed to assess performance in commercially significant areas. Finally, enhancing the understanding and mitigation of model biases, like hallucination, is paramount. This requires sophisticated evaluation methods, especially for complex, multi-step reasoning and creative tasks, incorporating both objective and subjective measures.
More visual insights#
More on figures

🔼 This figure illustrates the typical architecture of a Multimodal Large Language Model (MLLM). It shows three main modules: a modality encoder, a large language model (LLM), and a connector. The modality encoder processes input from various modalities (text, image, audio, video), converting it into a format suitable for the LLM. The connector aligns the processed multimodal features, combining them with text embeddings to create a unified representation. Finally, the LLM processes this multimodal representation to generate a response in natural language. The figure also notes that for text, tokenizers and de-tokenizers are used for encoding and decoding. Other modalities often require specialized encoders and connectors to create tokenized representations. Finally, the figure notes that some MLLMs use pre-trained generators or purely discrete modeling techniques to enhance multimodal capabilities.
read the caption
Figure 2: Typical MLLM architecture. Tokenizer and De-Tokenizer are used for the processing of text, as the standard flow of LLM. With respect to other modalities, specialized encoders and connectors are often required to convert them into tokens, as well pre-trained generators [10, 11] to enable multimodal generation capabilities. There are also methods that employ purely discrete modeling to achieve both understanding and generation [12].

🔼 The figure illustrates the three stages involved in training Multimodal Large Language Models (MLLMs): pre-training, instruction tuning, and alignment tuning. Pre-training uses image-caption pairs to align different modalities and integrate multimodal knowledge. Instruction tuning fine-tunes the model using various question-answer pairs to improve its ability to follow instructions. Finally, alignment tuning refines the model to better align with human preferences by incorporating feedback on the quality of responses. This process ensures the model is capable of generating helpful, informative, and accurate outputs in response to multimodal input.
read the caption
Figure 3: Illustration of three training stages of MLLMs. In the first stage, image-caption pairs are usually used for the modality alignment. In the second stage, the model is tuned on various QA pairs to make it capable of following instrctions. The third stage is responsible for making the model conform to human preferences.

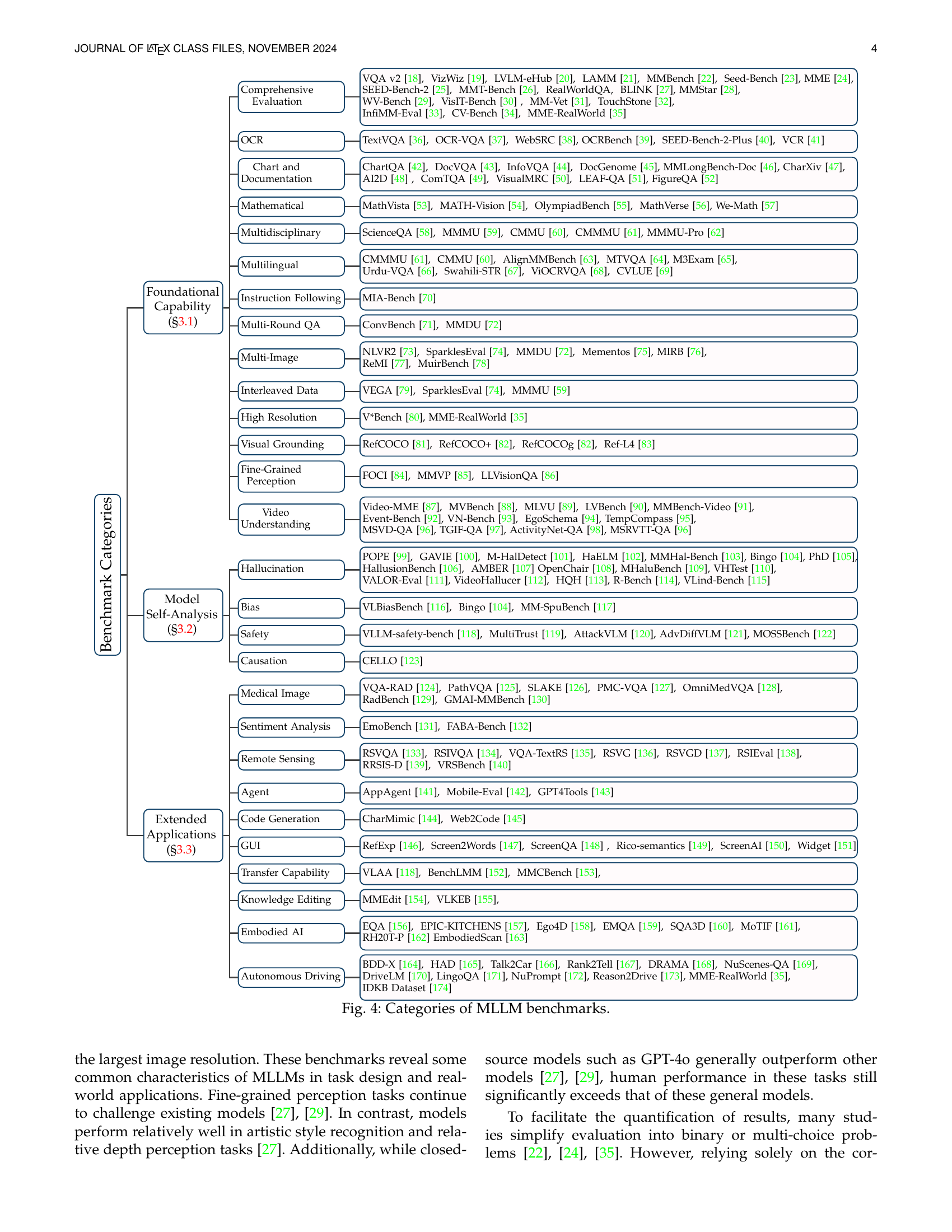
🔼 This figure presents a hierarchical taxonomy of Multimodal Large Language Model (MLLM) benchmarks, categorized by their evaluation focus. The top-level categories include Foundational Capability (evaluating basic perception and reasoning skills), Model Self-Analysis (exploring model biases, safety, and hallucination), and Extended Applications (assessing performance in specific domains such as code generation, medical image analysis, and autonomous driving). Each category is further broken down into subcategories, with specific benchmarks listed under each. This detailed breakdown provides a comprehensive overview of the landscape of MLLM evaluation.
read the caption
Figure 4: Categories of MLLM benchmarks.

🔼 This figure showcases a variety of multimodal large language model (MLLM) evaluation tasks, categorized by their foundational capability, model self-analysis, and extended applications. Each task example demonstrates different types of questions and answer formats, highlighting the diverse challenges and aspects assessed in MLLM evaluation. These include open-ended questions requiring descriptive answers, yes/no questions with binary answers, and multi-choice questions offering several options. The visual examples paired with questions further underscore the multimodal nature of the tasks and how LLMs must integrate visual and textual information for successful responses.
read the caption
Figure 5: Examples of different MLLM evaluation tasks. The answer can be Open-Ended, Yes-or-No, or Multi-Choice.
Full paper#