↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current subject-driven text-to-image generation methods either require extensive fine-tuning or sacrifice subject alignment. Zero-shot approaches, while faster, often produce images with unsatisfactory subject fidelity. This paper addresses these challenges.
The proposed “Diptych Prompting” method cleverly reframes the problem as an inpainting task. By using a large-scale text-to-image model, it generates images using a two-part image—the reference image and an area to be inpainted—to maintain subject consistency. Key improvements involve background removal from the reference image and enhancing attention between the two halves of the image to precisely control the subject’s features. The results demonstrate significant improvements over other zero-shot methods in image quality and subject alignment, showing its versatility in various image generation applications.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel zero-shot approach to subject-driven image generation, overcoming limitations of existing methods. Its innovative use of diptych inpainting and attention enhancement offers a unique perspective, improving subject alignment and image quality. This opens avenues for further research in zero-shot image manipulation and large-scale model capabilities.
Visual Insights#

🔼 This figure demonstrates the Diptych Prompting method, a novel zero-shot approach for subject-driven text-to-image generation. It uses a single reference image as input and leverages the diptych generation capability of the FLUX model [21]. Diptych Prompting extends FLUX by incorporating a separate inpainting module, allowing it to generate diptychs (two-paneled images) where the left panel contains the reference image and the right panel is generated via text-conditioned inpainting. This approach addresses limitations of traditional methods by accurately capturing the subject’s visual characteristics and semantic content while preventing unwanted content leakage. Panel (a) shows the diptych generation process, while panel (b) highlights the method’s versatility for various image generation tasks, including subject-driven generation, stylized generation, and subject-driven editing.
read the caption
Figure 1: Given a single reference image, our Diptych Prompting performs zero-shot subject-driven text-to-image generation through diptych inpainting. Building on the (a) diptych generation capability of FLUX [21], we extend it to diptych inpainting with a separate module, resulting in (b) versatility across various tasks including subject-driven text-to-image generation, stylized image generation, and subject-driven image editing.
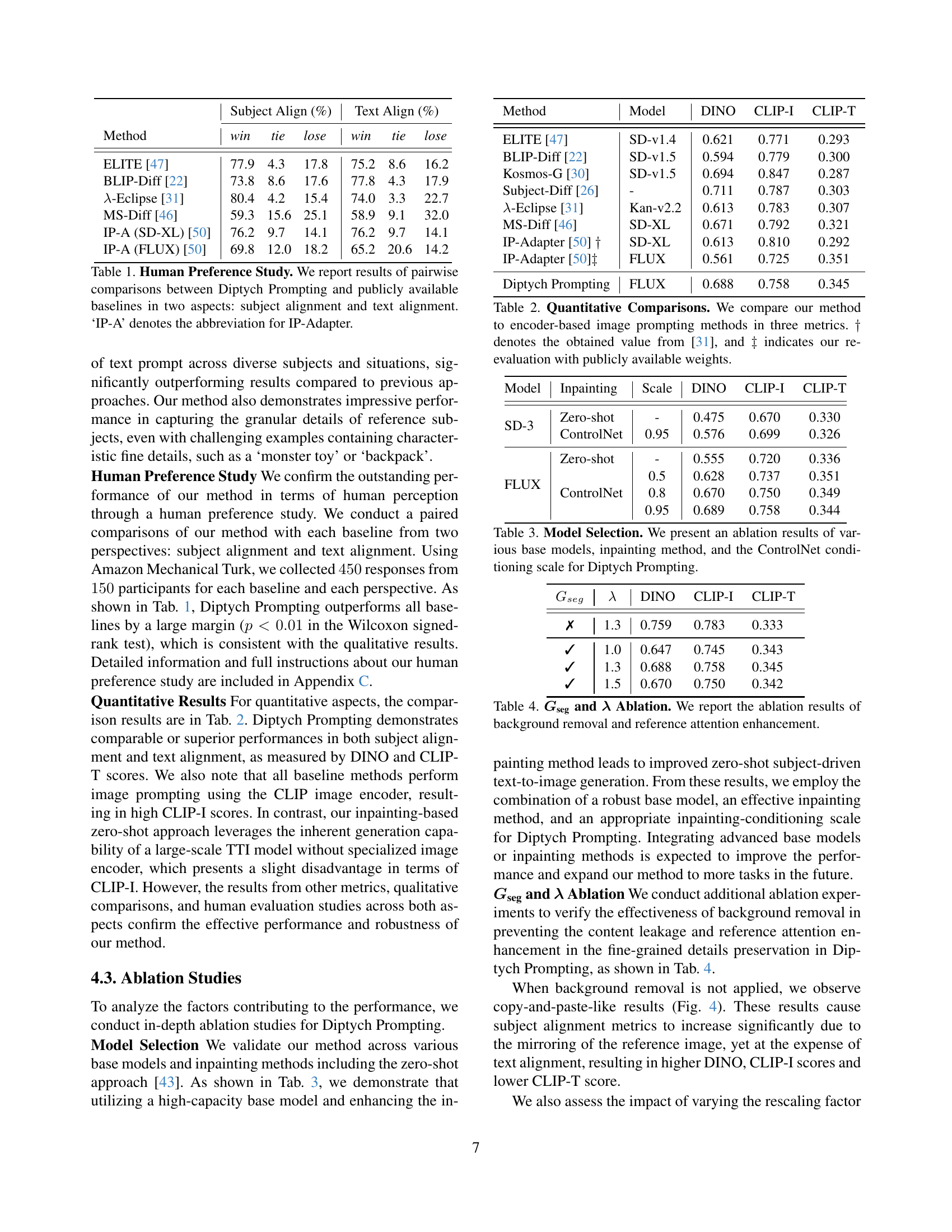
| Method | Subject Align (%) win | tie | lose | Text Align (%) win | tie | lose |
|---|---|---|---|---|---|---|
| ELITE [47] | 77.9 | 4.3 | 17.8 | 75.2 | 8.6 | 16.2 |
| BLIP-Diff [22] | 73.8 | 8.6 | 17.6 | 77.8 | 4.3 | 17.9 |
| λ-Eclipse [31] | 80.4 | 4.2 | 15.4 | 74.0 | 3.3 | 22.7 |
| MS-Diff [46] | 59.3 | 15.6 | 25.1 | 58.9 | 9.1 | 32.0 |
| IP-A (SD-XL) [50] | 76.2 | 9.7 | 14.1 | 76.2 | 9.7 | 14.1 |
| IP-A (FLUX) [50] | 69.8 | 12.0 | 18.2 | 65.2 | 20.6 | 14.2 |
🔼 This table presents the results of a human preference study comparing Diptych Prompting to several publicly available baselines for subject-driven text-to-image generation. Participants were shown pairs of images, one generated by Diptych Prompting and one by a baseline method, and asked to choose which image better aligned with the reference image (subject alignment) and the text prompt (text alignment). The table shows the percentage of times each method was preferred in each of these two aspects. IP-A is used as shorthand for IP-Adapter.
read the caption
Table 1: Human Preference Study. We report results of pairwise comparisons between Diptych Prompting and publicly available baselines in two aspects: subject alignment and text alignment. ‘IP-A’ denotes the abbreviation for IP-Adapter.
In-depth insights#
Diptych Prompting#
Diptych Prompting presents a novel zero-shot approach to subject-driven image generation by cleverly framing the task as an inpainting problem. Instead of relying on separate image encoders, it leverages the diptych generation capabilities of large-scale text-to-image models like FLUX. This approach involves creating an incomplete diptych with a reference image of the subject in one panel and a blank space in the other. Text prompting guides the inpainting process, resulting in a new image aligned with both the subject and the text description. The method cleverly incorporates background removal to prevent unwanted content leakage and enhances attention weights between panels to improve detail. Diptych Prompting demonstrates significant advantages over existing zero-shot methods, achieving superior performance in both subject and text alignment, and exhibiting versatility across diverse applications such as stylized image generation and subject-driven image editing. Its effectiveness lies in the synergistic combination of inpainting, diptych generation, and attention mechanism refinement within a powerful large-scale TTI model.
Zero-Shot Synthesis#
Zero-shot synthesis in image generation is a significant advancement, enabling the creation of images from textual descriptions without requiring any prior training on specific subjects or styles. This approach is highly desirable because it eliminates the need for extensive fine-tuning, a process that is often time-consuming and computationally expensive. The core idea is to leverage pre-trained large-scale text-to-image models to effectively understand and translate textual prompts into visual representations. Strategies employed often involve clever prompting techniques or the use of specialized image encoders which extract and integrate image features alongside text features, guiding the model to generate images aligning with both. However, a key challenge is achieving precise subject alignment and high-fidelity details, especially when dealing with granular elements. While zero-shot methods offer immediate application, they may sometimes struggle to capture the nuances of textual prompts, leading to discrepancies between the generated image and the intended visual representation. Future research may focus on improving the fidelity of generated images and explore methods that can more effectively capture the subtleties of complex prompts, ultimately bridging the gap between human understanding and machine-generated visual output.
Inpainting Approach#
The core idea revolves around re-interpreting subject-driven text-to-image generation as an inpainting task. Instead of relying on separate image encoders, this approach leverages the diptych generation capabilities of a large-scale text-to-image model (like FLUX). A reference image of the subject is placed in one panel of a diptych, while the other panel is left blank for inpainting. A text prompt then guides the inpainting process, ensuring the generated image aligns with both the reference subject and the desired context. This method is zero-shot, meaning no additional fine-tuning is needed for new subjects. Two key enhancements improve the results: background removal from the reference image prevents unwanted content leakage, and attention weight adjustments between the panels enhance the fine-grained details of the generated subject, improving subject-text alignment. The inpainting approach thus offers a novel, efficient solution to subject-driven image generation that avoids the shortcomings of encoder-based image prompting methods while achieving superior performance and versatility.
Ablation Studies#
The ablation study section of a research paper is crucial for understanding the contribution of individual components to the overall performance. It systematically removes or alters parts of the proposed model to assess their impact. In the context of subject-driven image generation, an ablation study might investigate the effects of removing background from reference images, which can reduce unwanted content leakage and improve subject focus. Another key aspect would be evaluating the impact of reference attention enhancement, where modifying attention weights between reference and generated images might improve the model’s ability to accurately capture fine details. By carefully analyzing the results of these ablation experiments, researchers can demonstrate the importance of these techniques and provide a deeper understanding of the model’s strengths and limitations. This rigorous testing process strengthens the validity of the results and enhances the overall impact of the research.
Future of TTI#
The future of Text-to-Image (TTI) models is incredibly promising, driven by ongoing advancements in large language models and diffusion models. We can anticipate even more photorealistic and detailed image generation, with enhanced control over style, composition, and subject matter. Zero-shot capabilities, like those explored in the Diptych Prompting method, will likely become more sophisticated and prevalent, eliminating the need for extensive fine-tuning for specific subjects or styles. Furthermore, we will see an increase in the development of TTI applications beyond simple image generation, including seamless integration with other generative models for complex multimedia content creation and more efficient, robust image editing and manipulation tools. Ethical considerations will play a pivotal role, requiring thoughtful research to address issues like bias in datasets and the potential misuse of generative technology. The future of TTI hinges on interdisciplinary collaboration between computer vision, natural language processing, and the arts, pushing boundaries in creative expression and visual communication.
More visual insights#
More on figures

🔼 This figure compares the diptych generation capabilities of several text-to-image (TTI) models. A diptych is a two-paneled image. The models were all given the same prompt: to create a diptych showing the same cat in two different settings. The left panel should depict a cat in front of the Eiffel Tower, and the right panel should show the same cat in a jungle. The figure visually demonstrates how each model interprets and executes the prompt, showcasing differences in image quality, cat likeness, and background rendering.
read the caption
Figure 2: Diptych Generation Comparisons. We generate the diptych images with various TTI models from the following diptych text: “A diptych with two side-by-side images of same cat. On the left, a photo of a cat in front of Eiffel Tower. On the right, replicate this cat exactly but as a photo of a cat in the jungle”.

🔼 Figure 3 illustrates the Diptych Prompting framework. Panel (a) shows the process: an incomplete diptych image (left panel is a reference image, right panel is blank), a text prompt describing the desired final image, and a binary mask designating the right panel for inpainting are fed into FLUX (a large-scale text-to-image model) with a ControlNet module. This setup performs text-conditioned inpainting on the right panel, using the left panel’s reference image for context. Panel (b) details the ‘Reference Attention Enhancement’ technique, which increases the attention weight between the right panel’s query and the left panel’s key, sharpening focus on the reference subject for more accurate inpainting.
read the caption
Figure 3: (a) Overall Diptych Prompting Framework. Given the incomplete diptych Idiptychsubscript𝐼diptychI_{\text{diptych}}italic_I start_POSTSUBSCRIPT diptych end_POSTSUBSCRIPT, text prompt Tdiptychsubscript𝑇diptychT_{\text{diptych}}italic_T start_POSTSUBSCRIPT diptych end_POSTSUBSCRIPT describing the diptych, and the binary mask Mdiptychsubscript𝑀diptychM_{\text{diptych}}italic_M start_POSTSUBSCRIPT diptych end_POSTSUBSCRIPT specifying the right panel as the inpainting target, FLUX with ControlNet module performs text-conditioned inpainting on the right panel while referencing the subject in the left panel. (b) Reference Attention Enhancement. To capture the granular details of the subject in left panel, we enhance the reference attention, an attention weight between the query of the right panel and the key of the left panel.

🔼 Figure 4 demonstrates the importance of background removal in diptych inpainting. Without background removal, simple diptych inpainting methods tend to copy elements from the reference image into the generated image, including the background, subject pose, and the subject’s location. This is undesirable, as the goal is to generate a new image of the subject in a specified context without unwanted elements from the reference image interfering with the generated context. The background removal technique, denoted as Gseg, effectively addresses this issue by isolating the subject from its background before inpainting, ensuring that the generated image only incorporates the intended subject and its contextual elements from the text prompt.
read the caption
Figure 4: Background Removal Effects. Simple diptych inpainting exhibits content leakage from the reference image, including background, pose, and location. We mitigate this unwanted leakage through background removal by Gsegsubscript𝐺segG_{\text{seg}}italic_G start_POSTSUBSCRIPT seg end_POSTSUBSCRIPT.

🔼 This figure presents a qualitative comparison of different zero-shot subject-driven image generation methods. The first column shows the reference image, then subsequent columns show the results produced by BLIP Diffusion, A-Eclipse, IP-Adapter, MS-Diffusion, and the authors’ proposed method, Diptych Prompting. Each row represents a different prompt, illustrating the models’ ability to accurately generate images of a specific subject within the context described by the text prompt. The results demonstrate the superior performance of Diptych Prompting in generating visually accurate and contextually relevant images compared to existing methods.
read the caption
Figure 5: Qualitative Comparisons. Please zoom in for a more detailed view and better comparison.

🔼 This figure demonstrates the capability of Diptych Prompting to generate stylized images. It shows several examples where a style image (like a watercolor painting, cartoon illustration, or crayon drawing) is used as a reference to guide the generation of a new image of a different subject, inheriting the stylistic characteristics of the reference image. The results highlight Diptych Prompting’s ability to adapt and apply various styles effectively in a zero-shot setting.
read the caption
Figure 6: Qualitative Comparisons of Stylized Image Generation. Using a style image as a reference, Diptych Prompting generates stylized images.

🔼 Diptych Prompting is extended to subject-driven image editing by placing the target image on the right panel of a diptych and masking only the area to be edited. The left panel contains a reference subject image. The model then performs text-conditioned inpainting, using the reference subject to guide the editing process and seamlessly integrate the subject into the modified area of the target image.
read the caption
Figure 7: Subject-Driven Image Editing. Diptych Prompting extends to subject-driven image editing by placing the target image on the right panel and masking only the area to be edited.

🔼 Figure A1 presents a quantitative comparison of the performance of Diptych Prompting against DreamBooth-LoRA, a fine-tuning based approach, across various LoRA rank values. The results are visualized using three metrics from DreamBench: DINO, CLIP-I, and CLIP-T. Each metric assesses a different aspect of the generated images, providing a comprehensive evaluation of the models’ ability to capture subject and context in zero-shot image generation.
read the caption
Figure A1: DreamBooth Comparisons. Quantitative comparisons to DreamBooth-LoRA with various rank values.

🔼 Figure A2 presents additional examples showcasing the capabilities of Diptych Prompting for subject-driven text-to-image generation. It demonstrates the model’s ability to accurately incorporate a reference subject into diverse contexts specified by text prompts. Each row shows a reference image, followed by three generated images illustrating variations in the background and composition while maintaining consistent subject representation.
read the caption
Figure A2: Subject-Driven Text-to-Image Generation. More samples of subject-driven text-to-image generation using Diptych Prompting.

🔼 Figure A3 presents additional examples showcasing the capabilities of Diptych Prompting for subject-driven text-to-image generation. It displays multiple sets of images. Each set includes a reference image of a subject (e.g., a bowl of berries, a rubber duck, a cat) on the left, and three variations of generated images on the right. These variations depict the subject in different contexts as described by accompanying text prompts, demonstrating the model’s ability to accurately place the subject within various scenes while maintaining visual fidelity.
read the caption
Figure A3: Subject-Driven Text-to-Image Generation. More samples of subject-driven text-to-image generation using Diptych Prompting..

🔼 This figure shows a qualitative comparison of the results obtained with and without background removal during the image generation process. The background removal process, denoted as Gseg, aims to isolate the subject from its surroundings, preventing content leakage from the reference image (left panel) into the generated image (right panel). The top row shows examples with a golden retriever, while the bottom row displays examples with a red frog. Each column represents a different generated image, illustrating how the absence of background removal leads to less focused and sometimes undesirable results compared to those generated with the background removal technique.
read the caption
Figure A4: 𝑮segsubscript𝑮seg\bm{G_{\text{seg}}}bold_italic_G start_POSTSUBSCRIPT seg end_POSTSUBSCRIPT Ablation. Qualitative comparisons with and without the background removal process.

🔼 This ablation study shows how changing the reference attention enhancement parameter (lambda, λ) affects the generated images in the Diptych Prompting method. The experiment varies λ from 1.0 (no enhancement) to 1.5, showcasing the impact on image detail and subject alignment. The images are presented in a before-and-after style, enabling a visual comparison of how different λ values influence the results of the text-to-image generation process.
read the caption
Figure A5: 𝝀𝝀\bm{\lambda}bold_italic_λ Ablation. Qualitative transitions according to the varying λ𝜆\lambdaitalic_λ values. we control the λ𝜆\lambdaitalic_λ from 1.01.01.01.0 (without reference attention enhancement) to 1.51.51.51.5. For a detailed view, please zoom in.

🔼 Figure A6 presents diverse examples showcasing the versatility of Diptych Prompting in generating stylized images. The figure demonstrates how, by providing a style reference image alongside a textual description, the method can accurately replicate various artistic styles, ranging from watercolor paintings and 3D renders to cartoon illustrations and even specific artistic styles (such as a ‘kid crayon drawing style’). Each row displays the style reference image followed by several examples of images synthesized using Diptych Prompting in that style, highlighting the precise and effective manner in which it captures and applies the specified styles.
read the caption
Figure A6: Stylized Image Generation. More samples of stylized image generation using Diptych Prompting.
More on tables
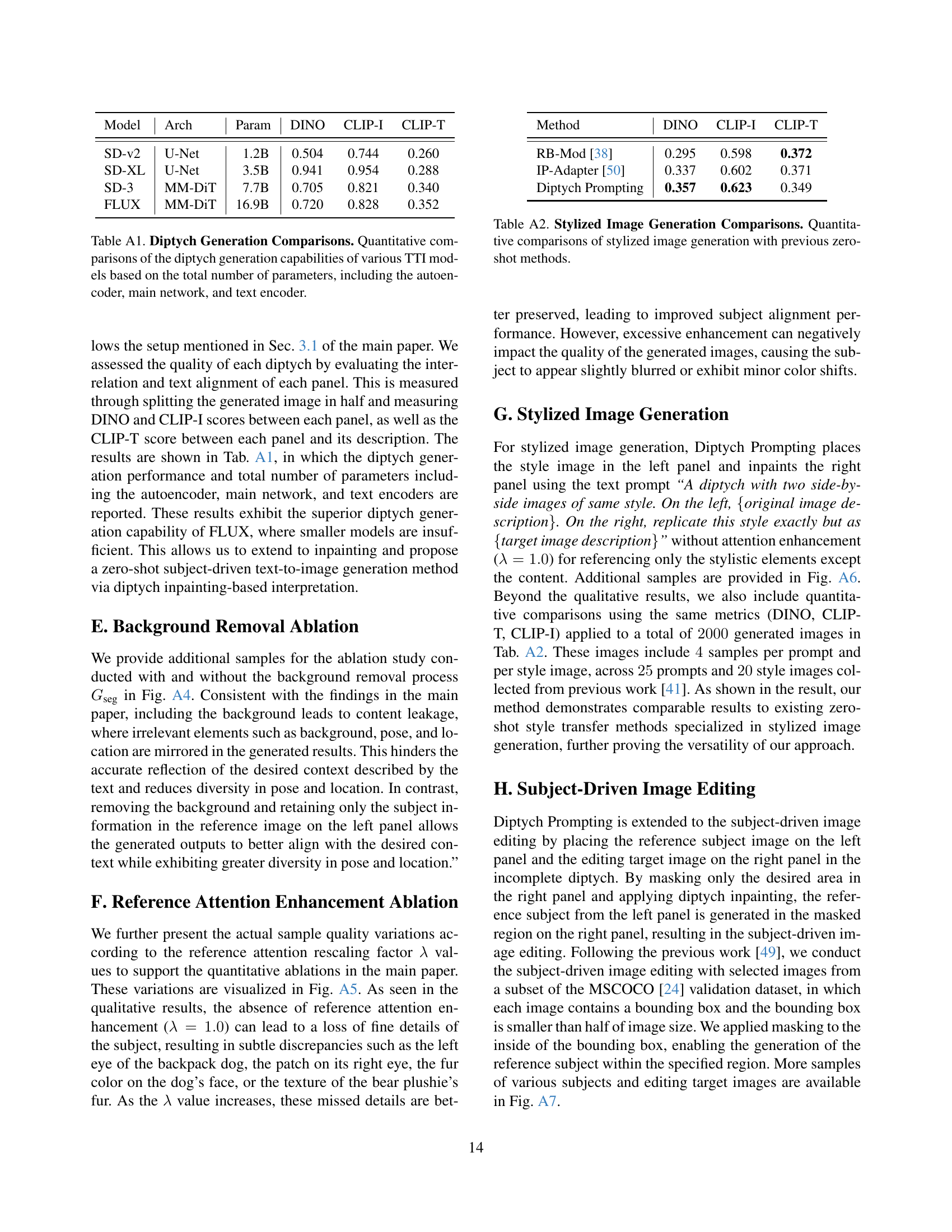
| Method | Model | DINO | CLIP-I | CLIP-T |
|---|---|---|---|---|
| ELITE [47] | SD-v1.4 | 0.621 | 0.771 | 0.293 |
| BLIP-Diff [22] | SD-v1.5 | 0.594 | 0.779 | 0.300 |
| Kosmos-G [30] | SD-v1.5 | 0.694 | 0.847 | 0.287 |
| Subject-Diff [26] | - | 0.711 | 0.787 | 0.303 |
| λ-Eclipse [31] | Kan-v2.2 | 0.613 | 0.783 | 0.307 |
| MS-Diff [46] | SD-XL | 0.671 | 0.792 | 0.321 |
| IP-Adapter [50] † | SD-XL | 0.613 | 0.810 | 0.292 |
| IP-Adapter [50] ‡ | FLUX | 0.561 | 0.725 | 0.351 |
| Diptych Prompting | FLUX | 0.688 | 0.758 | 0.345 |
🔼 This table presents a quantitative comparison of the proposed Diptych Prompting method against several existing encoder-based image prompting techniques for zero-shot subject-driven image generation. The comparison uses three metrics: DINO, CLIP-I, and CLIP-T, which assess subject alignment and text alignment aspects of the generated images. Note that some results are taken from another publication ([31]) and others are reproduced by the authors of the current paper, using publicly available model weights.
read the caption
Table 2: Quantitative Comparisons. We compare our method to encoder-based image prompting methods in three metrics. ††\dagger† denotes the obtained value from [31], and ‡‡\ddagger‡ indicates our re-evaluation with publicly available weights.
| Model | Inpainting | Scale | DINO | CLIP-I | CLIP-T |
|---|---|---|---|---|---|
| SD-3 | Zero-shot | - | 0.475 | 0.670 | 0.330 |
| ControlNet | 0.95 | 0.576 | 0.699 | 0.326 | |
| FLUX | Zero-shot | - | 0.555 | 0.720 | 0.336 |
| ControlNet | 0.5 | 0.628 | 0.737 | 0.351 | |
| 0.8 | 0.670 | 0.750 | 0.349 | ||
| 0.95 | 0.689 | 0.758 | 0.344 |
🔼 This table presents the results of an ablation study investigating the impact of different model choices on the performance of Diptych Prompting. Specifically, it examines the effects of using different base models (pre-trained large-scale text-to-image models), different inpainting methods, and varying ControlNet conditioning scales. The goal is to determine the optimal combination of these factors for achieving the best performance in zero-shot subject-driven text-to-image generation.
read the caption
Table 3: Model Selection. We present an ablation results of various base models, inpainting method, and the ControlNet conditioning scale for Diptych Prompting.
| $G_{seg}$ | $\lambda$ | DINO | CLIP-I | CLIP-T |
|---|---|---|---|---|
| ✗ | 1.3 | 0.759 | 0.783 | 0.333 |
| ✓ | 1.0 | 0.647 | 0.745 | 0.343 |
| ✓ | 1.3 | 0.688 | 0.758 | 0.345 |
| ✓ | 1.5 | 0.670 | 0.750 | 0.342 |
🔼 This table presents the results of ablation studies conducted to evaluate the impact of two key components in the Diptych Prompting method: background removal (using Gseg) and reference attention enhancement (controlled by the parameter λ). It shows how removing the background of the reference image and adjusting the attention weights between the two image panels affects the performance of the model, measured using DINO, CLIP-I, and CLIP-T scores. The ablation study helps to determine the individual contributions of these components to the overall performance of Diptych Prompting in zero-shot subject-driven text-to-image generation.
read the caption
Table 4: 𝑮segsubscript𝑮seg\bm{G_{\text{seg}}}bold_italic_G start_POSTSUBSCRIPT seg end_POSTSUBSCRIPT and λ𝜆\bm{\lambda}bold_italic_λ Ablation. We report the ablation results of background removal and reference attention enhancement.
| Model | Arch | Param | DINO | CLIP-I | CLIP-T |
|---|---|---|---|---|---|
| SD-v2 | U-Net | 1.2B | 0.504 | 0.744 | 0.260 |
| SD-XL | U-Net | 3.5B | 0.941 | 0.954 | 0.288 |
| SD-3 | MM-DiT | 7.7B | 0.705 | 0.821 | 0.340 |
| FLUX | MM-DiT | 16.9B | 0.720 | 0.828 | 0.352 |
🔼 This table presents a quantitative comparison of different text-to-image (TTI) models’ capabilities in generating diptychs. It assesses performance based on three key metrics: DINO, CLIP-I, and CLIP-T scores. The metrics evaluate aspects of image generation quality. The models are compared based on their total number of parameters, which provides an indication of model complexity. The table includes information on the model architecture (U-Net or MM-DiT) and the number of parameters for each model. This allows for an assessment of the relationship between model size and diptych generation performance.
read the caption
Table A1: Diptych Generation Comparisons. Quantitative comparisons of the diptych generation capabilities of various TTI models based on the total number of parameters, including the autoencoder, main network, and text encoder.
| Method | DINO | CLIP-I | CLIP-T |
|---|---|---|---|
| RB-Mod [38] | 0.295 | 0.598 | 0.372 |
| IP-Adapter [50] | 0.337 | 0.602 | 0.371 |
| Diptych Prompting | 0.357 | 0.623 | 0.349 |
🔼 This table presents a quantitative comparison of the performance of Diptych Prompting against other zero-shot methods for stylized image generation. The comparison uses three metrics: DINO, CLIP-I, and CLIP-T, to evaluate the quality and alignment of generated images. Each method’s scores across these metrics are shown, enabling a direct assessment of Diptych Prompting’s efficacy relative to state-of-the-art zero-shot approaches in generating stylized images.
read the caption
Table A2: Stylized Image Generation Comparisons. Quantitative comparisons of stylized image generation with previous zero-shot methods.
Full paper#