↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Multimodal learning, enabling AI to understand and interact with various data types like images and text, is a growing field. However, teaching AI new visual concepts is often resource-intensive, requiring large labeled datasets. This is where the problem addressed by this paper arises. Existing methods often struggle with efficiently introducing novel concepts into pre-trained models.
This research proposes ‘Knowledge Transfer,’ a novel method to overcome this limitation. By using only a textual description of a new concept, the approach leverages a pre-trained visual encoder’s existing understanding of low-level features (shape, color, etc.) to create a visual representation. The method shows successful introduction of novel concepts, improving accuracy on known concepts, and boosting zero-shot performance across various tasks (classification, segmentation, and retrieval). The efficiency of the approach makes it a significant contribution to the field, requiring significantly less data and resources compared to traditional methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method for efficiently teaching AI models new visual concepts using only textual descriptions. This addresses a key challenge in multimodal learning and opens exciting avenues for improving AI’s ability to learn and adapt. The method’s efficiency and compatibility with various model architectures make it highly relevant to the current research trend in parameter-efficient fine-tuning and offers a valuable contribution to the field.
Visual Insights#

🔼 This figure shows the effectiveness of Knowledge Transfer in introducing new concepts to a pre-trained CLIP model. The image depicts a ‘Moongate’, which was not in the model’s training data. Subfigure (a) shows that a standard CLIP model (CLIP (B)) incorrectly identifies the Moongate as a ‘Triumphal Arch’, ‘Stone Wall’, or ‘Steel Arch Bridge’. However, after applying the Knowledge Transfer method described in the paper (CLIP (B) w/ Knowledge Transfer), the model now correctly identifies the Moongate as a ‘Moongate’, indicating that the model successfully learned a novel concept from a textual description alone.
read the caption
(a) CLIP (B) Top-3 zero-shot predictions: (“Triumphal Arch”, “Stone Wall”, “Steel Arch Bridge”). CLIP (B) w/ Knowledge Transfer Top-3 zero-shot predictions: (“Moongate”, “Triumphal Arch”, “Stone Wall”)
| Model | Concept | Baseline | 1e-5 | 2e-5 | 3e-5 | 4e-5 | 5e-5 | |
|---|---|---|---|---|---|---|---|---|
| CLIP ViT-B/32 [45] | Moongate | Target Acc. | 0% | 10% | 60% | 90% | 100% | 100% |
| ImageNet 0-shot | 58.10% | 57.78% | 56.43% | 53.95% | 50.37% | 42.30% | ||
| Tonometer | Target Acc. | 50% | 80% | 80% | 100% | 100% | 100% | |
| ImageNet 0-shot | 58.10% | 57.52% | 55.62% | 51.98% | 42.80% | 23.73% | ||
| Gyroscope | Target Acc. | 90% | 100% | 100% | 100% | 100% | 100% | |
| ImageNet 0-shot | 58.10% | 57.86% | 56.84% | 53.96% | 48.28% | 34.48% | ||
| CLIP ViT-L/14 [45] | Moongate | Target Acc. | 78.95% | 78.95% | 100% | 100% | 100% | 100% |
| ImageNet 0-shot | 70.79% | 70.74% | 70.51% | 69.96% | 68.57% | 62.35% | ||
| Tonometer | Target Acc. | 31.58% | 52.63% | 78.95% | 100% | 100% | 100% | |
| ImageNet 0-shot | 70.79% | 70.74% | 70.61% | 70.08% | 69.06% | 66.92% | ||
| Gyroscope | Target Acc. | 90% | 90% | 100% | 100% | 100% | 100% | |
| ImageNet 0-shot | 70.79% | 70.65% | 70.42% | 69.84% | 69.39% | 68.35% | ||
| ViLT [26] | Moongate | Target Acc. | 0% | 0% | 0% | 0% | 0% | 0% |
| ImageNet* 0-shot | 23.74% | 23.90% | 24.02% | 24.16% | 24.18% | 24.16% | ||
| Tonometer | Target Acc. | 10% | 30% | 30% | 30% | 40% | 40% | |
| ImageNet* 0-shot | 23.74% | 23.88% | 24.02% | 24.04% | 24.22% | 23.94% | ||
| Gyroscope | Target Acc. | 50% | 60% | 50% | 50% | 40% | 30% | |
| ImageNet* 0-shot | 23.74% | 23.80% | 23.88% | 23.72% | 23.38% | 23.12% |
🔼 This table presents the results of applying Knowledge Transfer to novel and rare concepts using two different vision-language models: CLIP and ViLT. For each model, the table shows the zero-shot classification accuracy before (baseline) and after applying Knowledge Transfer. The target accuracy indicates the performance on the specific rare concepts (Moongate, Tonometer, Gyroscope), while ImageNet 0-shot accuracy demonstrates performance on a standard image classification benchmark. Because of computational constraints, ViLT’s evaluation used a smaller subset of ImageNet (ImageNet-100) instead of the full ImageNet dataset.
read the caption
Table 1: Knowledge Transfer on novel and rare concepts (CLIP and ViLT). * for VilT, we employ ImageNet-100 [22] due to the computational requirements of evaluating every possible image-caption pair for zero-shot classification.
In-depth insights#
Cross-Modal Transfer#
The concept of cross-modal transfer, in the context of multimodal learning, focuses on leveraging knowledge learned from one modality (e.g., text) to improve performance in another (e.g., vision). This is particularly valuable when data for one modality is scarce or expensive to acquire. The core idea is that underlying semantic information is shared across modalities, enabling knowledge to be transferred effectively. Several approaches exist, including explicit transfer, where knowledge is explicitly mapped between modalities (often requiring intermediate steps like image synthesis), and implicit transfer, which utilizes inherent cross-modal relationships within a shared representation space. Effective cross-modal transfer methods often depend on well-aligned pre-trained models that capture the shared semantic space. The success of such transfer hinges upon several factors: the quality and quantity of the source data, the method used for knowledge transfer, and the architecture of the model. A key challenge lies in managing catastrophic forgetting, where the model loses performance on previously learned tasks. The use of techniques such as parameter-efficient fine-tuning can help mitigate this issue. Overall, cross-modal transfer holds immense potential for enhancing multimodal models’ efficiency and performance, especially in low-resource scenarios.
Novel Concept Learning#
Novel concept learning within the context of this research paper centers on the ability of a model to acquire understanding of previously unseen concepts using only textual descriptions. This approach, termed Knowledge Transfer, leverages existing low-level visual features already learned by a pre-trained visual encoder to build representations of high-level concepts. The method cleverly connects known visual features to their textual descriptions, efficiently introducing new knowledge without the need for large training datasets. A core hypothesis is that prior visual knowledge is sufficient, combined with natural language, to build comprehensive concepts. This is particularly relevant in cross-modal learning where the effective mapping of information between different sensory modalities (vision and language) is crucial. The method’s efficacy is demonstrated across various downstream tasks, highlighting its potential to improve zero-shot performance and showing a promising direction for efficient and scalable knowledge acquisition in AI.
Zero-Shot Improvements#
The heading ‘Zero-Shot Improvements’ suggests an investigation into enhancing a model’s performance on tasks it hasn’t explicitly trained for. This implies a focus on transfer learning, where knowledge acquired during training on one set of data improves the model’s ability to handle unseen data. The paper likely explores how such zero-shot capabilities are enhanced. Key aspects to consider include the methodologies used for improvement (e.g., fine-tuning, data augmentation, knowledge distillation), the metrics used to evaluate these improvements (e.g., accuracy, precision, recall), and the types of tasks examined (e.g., image classification, object detection, semantic segmentation). A significant finding would be showcasing substantial zero-shot performance gains, ideally demonstrating generalization across diverse and challenging tasks. The analysis likely covers various model architectures and pre-training strategies, comparing their efficacy in achieving zero-shot improvements. Ultimately, the ‘Zero-Shot Improvements’ section aims to reveal the model’s capacity to leverage prior knowledge for effective performance on new, unseen data, which is crucial for real-world applications needing adaptability and efficiency.
Inversion’s Role#
The success of the proposed Knowledge Transfer method hinges significantly on the effectiveness of the image inversion process. Inversion’s role is to synthesize plausible images from textual descriptions of novel concepts. This is crucial because the visual encoder, already possessing rich low-level feature representations, needs corresponding high-level visual data to align with the textual descriptions. Without a robust inversion technique, the resulting images might not adequately capture the essence of the described concepts, hindering the quality of the subsequent fine-tuning process. Therefore, the choice of inversion method, its optimization strategy, and the quality of generated images directly impact the overall accuracy and efficacy of knowledge transfer. Optimizations such as data augmentation and regularization techniques are employed to mitigate the risk of generating unrealistic images, thus improving the effectiveness of Knowledge Transfer. Ultimately, successful inversion establishes the foundation upon which new concepts are learned within the multimodal model. It is the bridge connecting textual understanding to visual representation.
Future Research#
Future research directions stemming from this Knowledge Transfer work could explore several promising avenues. Improving the efficiency of the inversion process is crucial; current methods are computationally expensive. Investigating alternative techniques, perhaps leveraging generative models more effectively or exploring implicit knowledge transfer methods that bypass inversion entirely, would significantly enhance the practicality and speed of the approach. Further investigation into the interplay between explicit and implicit knowledge transfer is warranted. The paper hints at the potential of implicit methods using masked language modeling, but more thorough exploration is needed to assess its efficacy. Extending the methodology to a wider range of modalities beyond vision and language is a natural next step, potentially impacting other fields such as multi-modal medical image analysis. Finally, a deeper understanding of the underlying mechanisms of knowledge transfer, possibly through in-depth analysis of the model’s internal representations and neural pathways, could reveal valuable insights into the very nature of cross-modal learning and lead to further improvements in the model’s generalization capabilities.
More visual insights#
More on figures

🔼 This figure shows the top three predictions made by a large CLIP model (CLIP ViT-L/14) for two different scenarios. In the first scenario (before Knowledge Transfer), the model is given an image and makes predictions based on its pre-trained knowledge. The predictions are ‘Cocktail Shaker’, ‘Odometer’, and ‘Dragonfly’. The second scenario demonstrates the improvement achieved through Knowledge Transfer. The same model is provided with a textual description of the object instead of an image. The updated predictions are ‘Tonometer’, ‘Cocktail Shaker’, and ‘Espresso Maker’, showcasing the model’s ability to correctly identify the object after it is provided with the textual description.
read the caption
(b) CLIP (L) Top-3 zero-shot predictions: (“Cocktail Shaker”, “Odometer”, “Dragonfly”). CLIP (L) w/ Knowledge Transfer Top-3 zero-shot predictions: (“Tonometer”, “Cocktail Shaker”, “Espresso Maker”)

🔼 This figure demonstrates the core concept of Knowledge Transfer, a method for teaching a multimodal model new concepts using only textual descriptions. Leveraging the pre-existing knowledge of low-level visual features within a pre-trained visual encoder (like CLIP), the model can create visual representations of unseen concepts based solely on text. The example shows a CLIP model successfully learning the concepts of ‘Moongate’ and ‘Tonometer’, without access to any actual images. Importantly, the model maintains its good accuracy in general zero-shot image classification on ImageNet-1k (demonstrated by the percentage comparisons of 58.10% vs 56.43% and 70.79% vs 70.61%). This highlights the efficiency and effectiveness of the proposed knowledge transfer approach.
read the caption
Figure 1: Knowledge Transfer can introduce novel concepts in a multimodal model, by leveraging prior visual knowledge of the visual encoder and a textual description of the target concept. In the example, a CLIP model [45] learns the concepts Moongate and Tonometer, without using any real image, while retaining a good accuracy on general zero-shot classification (58.10% vs 56.43% and 70.79% vs 70.61% on ImageNet-1k).

🔼 This figure illustrates the two-stage process of Explicit Knowledge Transfer. The left side shows the model inversion stage. Starting with a textual description of a new concept (e.g., ‘A moongate is…’), the model inverts this text into a corresponding image representation. The right side depicts the fine-tuning stage. The synthesized image and its corresponding text description are then used to fine-tune the visual encoder of a pre-trained model (like CLIP). The fine-tuning process refines the model’s ability to connect low-level visual features (already learned during pre-training) with the high-level semantic understanding provided by the textual description, effectively allowing the model to learn the new concept without ever seeing an actual image of it. This approach leverages the existing knowledge embedded in the pre-trained model to efficiently learn new visual concepts.
read the caption
Figure 2: Graphical overview of Knowledge Transfer. Starting from a textual description of the target concept, we synthesize images via model inversion (left) then, using an image-text matching loss, we fine-tune the visual encoder to match the concept (right). In this way, we leverage prior knowledge contained in the model (from pre-training) to learn novel concepts.

🔼 A moongate is a perfectly circular archway, usually made of stone or brick, that is set into a larger wall. Its perfectly round shape frames views of gardens or landscapes beyond, creating a visually appealing and picturesque portal. This architectural feature is often found in gardens and parks.
read the caption
(a) Moongate. Caption: A perfectly circular archway built from uniformly cut stones or bricks, set into a larger wall. It forms a smooth circle, framing views of gardens or landscapes beyond, creating a picturesque portal.

🔼 The image shows a tonometer, a medical device used to measure intraocular pressure. It consists of a slender, pen-like probe connected to a small base with dials and gauges. The instrument typically has a metallic finish and a sleek, professional appearance, often integrating into larger ophthalmologic equipment.
read the caption
(b) Tonometer. Caption: A slender, pen-like probe attached to a small base equipped with precise dials and gauges. This tool is often part of a larger medical apparatus, featuring a metallic finish and a refined, professional appearance.

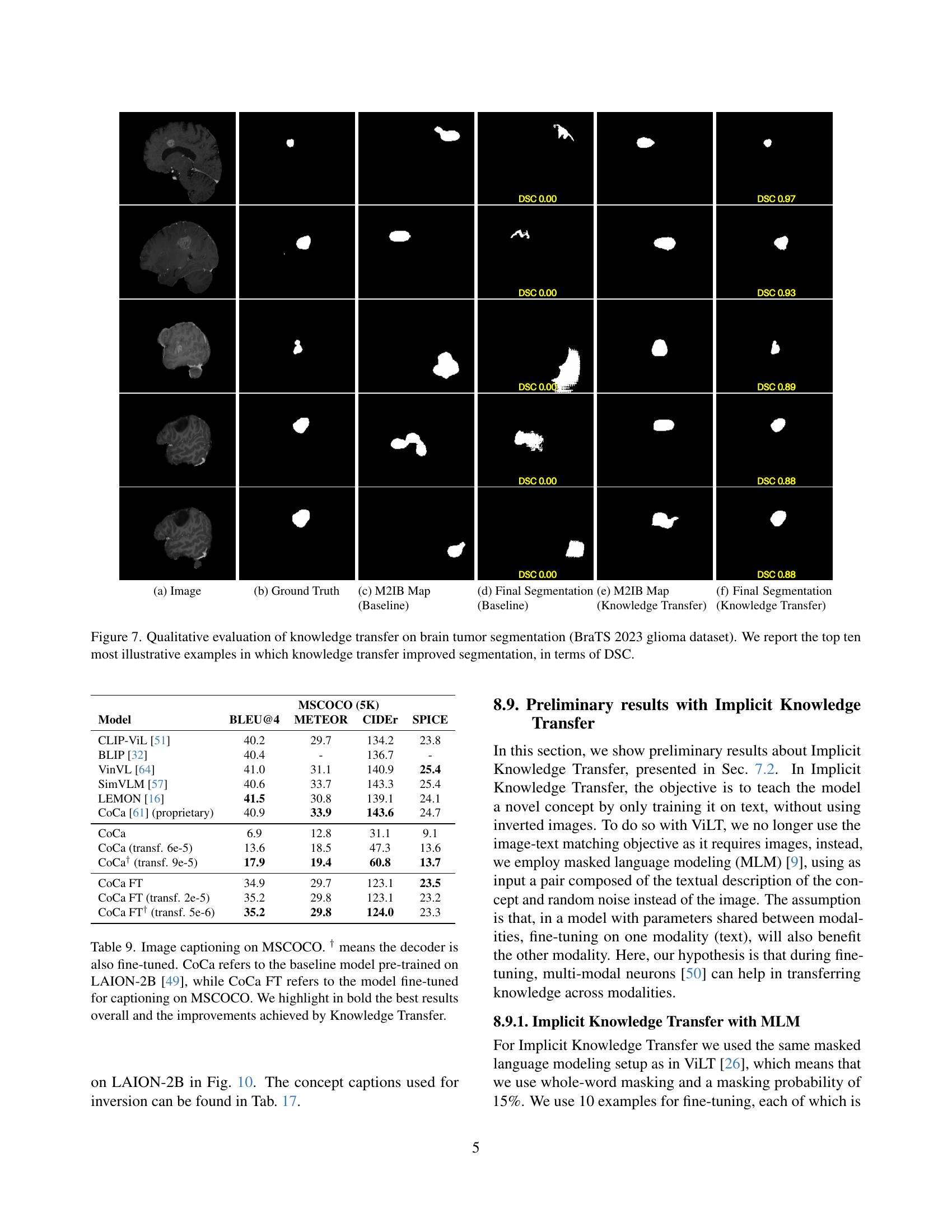
🔼 Figure 3 presents a comparison of images generated through model inversion and real-world images. The ‘inverted images’ (top row) were created by the model attempting to reconstruct visual representations based solely on textual descriptions of rare concepts. These concepts are difficult for CLIP, a pre-trained vision-language model, to classify accurately. The real-world images (bottom row) are the actual images corresponding to these same rare concepts. The figure demonstrates the capability and limitations of the model inversion process: it can generate plausible images based on text, but these images don’t always perfectly match the appearance of their real-world counterparts, which highlights the challenge in learning rare visual concepts from only textual descriptions.
read the caption
Figure 3: Example of inverted images (top) and real images (bottom) from rare concepts that CLIP struggles to classify correctly.

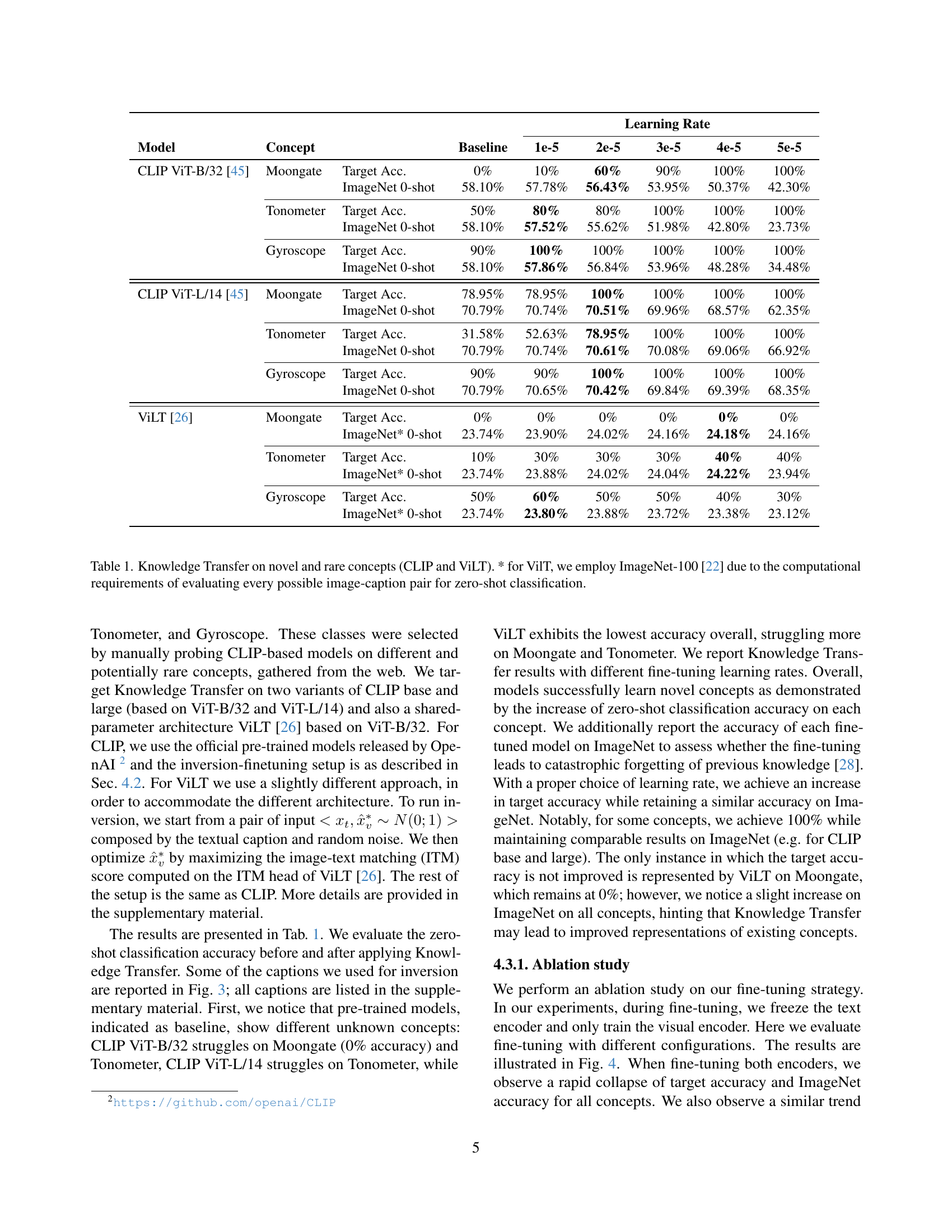
🔼 This figure compares three different fine-tuning strategies for a model learning new visual concepts from text descriptions. The x-axis represents the learning rate used during fine-tuning, and the y-axis shows the accuracy achieved on both the new concept (target) and existing concepts from the ImageNet dataset (imagenet). The three strategies are: 1) Fine-tuning both the text and visual encoders, 2) Fine-tuning only the text encoder, and 3) Fine-tuning only the visual encoder. The results demonstrate that fine-tuning both encoders or only the text encoder leads to significantly reduced accuracy on both target and existing tasks (catastrophic forgetting), implying that the model’s existing knowledge is disrupted. In contrast, fine-tuning only the visual encoder successfully incorporates the new concept without harming performance on existing concepts. The optimal learning rate for this strategy balances high accuracy on the new concept with minimal impact on prior knowledge.
read the caption
Figure 4: Comparison of fine-tuning strategies. Fine-tuning both the text and the visual encoders, or just the text encoder leads to a collapse in accuracy. Fine-tuning only the visual encoder correctly aligns prior visual features to the novel concept. A good choice of learning rate leads to higher accuracy on the novel concept (target) while limiting catastrophic forgetting on previous tasks (imagenet).

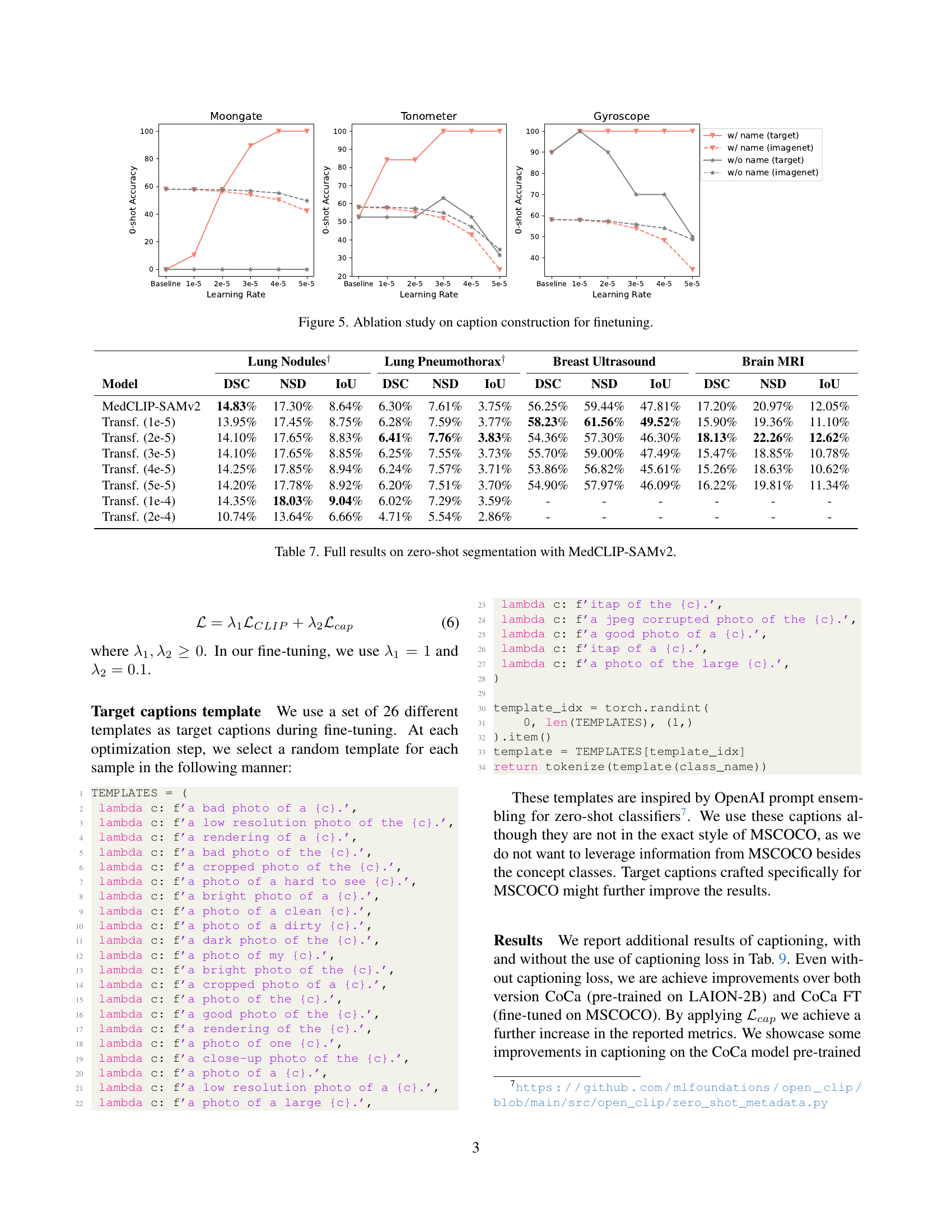
🔼 This ablation study investigates the impact of different captioning strategies during the fine-tuning stage of the Knowledge Transfer process on the accuracy of the model in classifying three rare concepts: Moongate, Tonometer, and Gyroscope. It compares results where the concept name is prepended to the caption versus scenarios where it’s absent. The x-axis represents the learning rate used, and the y-axis shows the zero-shot accuracy. The figure illustrates how including the concept name during fine-tuning significantly improves the model’s accuracy, indicating the importance of explicitly connecting low-level visual features to the high-level concept being learned.
read the caption
Figure 5: Ablation study on caption construction for finetuning.

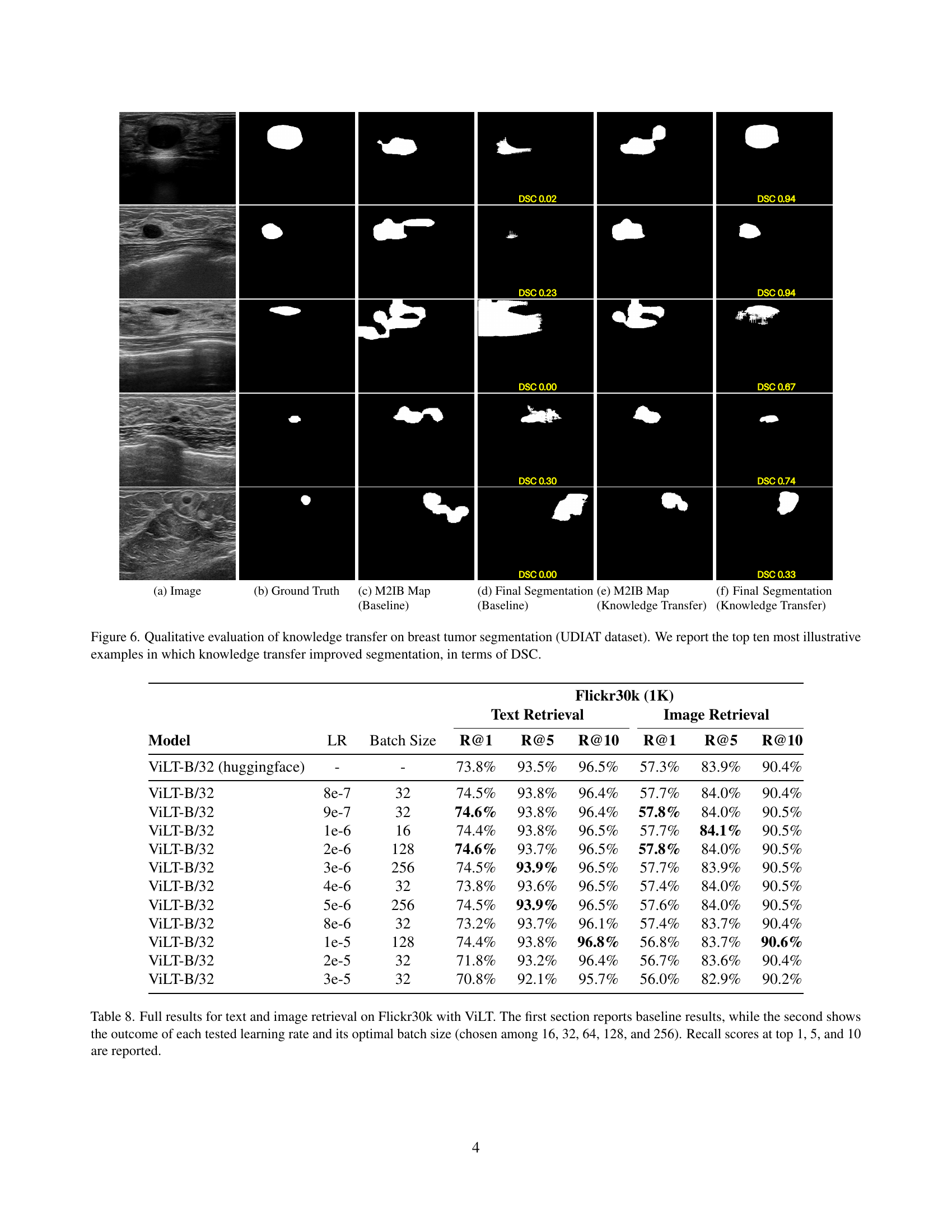
🔼 This figure shows an example of a breast ultrasound image, the corresponding ground truth segmentation mask, the activation map generated by MedCLIP-SAMv2 (baseline), and the final segmentation result (baseline and after knowledge transfer). It visually demonstrates how knowledge transfer improves the segmentation quality by comparing the activation maps and the resulting segmentations.
read the caption
(a) Image

🔼 The figure shows a ground truth segmentation mask for a breast ultrasound image. It highlights the region of the breast tumor, providing a precise delineation of its boundaries for comparison against model-generated segmentations.
read the caption
(b) Ground Truth

🔼 This subfigure shows the Multimodal Information Bottleneck Attribution (M2IB) map generated by the baseline MedCLIP-SAMv2 model before Knowledge Transfer. The M2IB map highlights the regions of the input medical image that are most relevant for predicting the presence of a specific anatomical structure (in this case, a tumor or nodule). Brighter regions indicate stronger relevance. It provides a visual representation of the model’s attention mechanism and how it focuses on specific image features for the segmentation task.
read the caption
(c) M2IB Map (Baseline)

🔼 This image shows the segmentation results obtained using the baseline MedCLIP-SAMv2 model without any knowledge transfer. It displays a visual comparison of the model’s prediction against the ground truth segmentation mask. The goal is to illustrate the model’s performance before any improvements are made using the proposed Knowledge Transfer technique.
read the caption
(d) Final Segmentation (Baseline)

🔼 Multimodal Information Bottleneck Attribution (M2IB) activation map after applying Knowledge Transfer. This visualization highlights the areas of the image that the model focuses on after being fine-tuned with synthetic images generated from textual descriptions of the target concept, showing how the model’s attention has shifted compared to the baseline (pre-transfer) M2IB map.
read the caption
(e) M2IB Map (Knowledge Transfer)

🔼 The image displays the results of a segmentation task after applying the Knowledge Transfer method. The segmentation is specifically of a brain tumor (glioma) in a brain MRI scan. This shows the improved segmentation that results from using the Knowledge Transfer approach as compared to the baseline results.
read the caption
(f) Final Segmentation (Knowledge Transfer)

🔼 This figure shows a qualitative evaluation of how knowledge transfer improves breast tumor segmentation using the UDIAT dataset. For ten of the most visually clear examples, it presents a comparison between the baseline segmentation results (without knowledge transfer) and those obtained after applying knowledge transfer. The comparison is made using the Dice Similarity Coefficient (DSC) metric, a common measure of overlap between the predicted segmentation and the ground truth. The images show the original image, the ground truth segmentation, the segmentation prediction from the baseline model, and the improved segmentation after knowledge transfer. This visualization allows readers to directly assess the improvement achieved through the application of the knowledge transfer method.
read the caption
Figure 6: Qualitative evaluation of knowledge transfer on breast tumor segmentation (UDIAT dataset). We report the top ten most illustrative examples in which knowledge transfer improved segmentation, in terms of DSC.

🔼 This figure shows a qualitative evaluation of knowledge transfer on breast tumor segmentation (UDIAT dataset). The image (a) is an example ultrasound image, (b) shows the corresponding ground truth segmentation, (c) displays the multi-modal information bottleneck attribution (M2IB) map from the baseline MedCLIP-SAMv2 model, (d) is the resulting segmentation from the baseline model, (e) shows the M2IB map after applying knowledge transfer, and (f) is the final segmentation resulting from the model after knowledge transfer. The figure highlights cases where applying knowledge transfer led to improvements in segmentation accuracy, as measured by the Dice-Sørensen Coefficient (DSC).
read the caption
(a) Image
More on tables
| Concept | Baseline | ×1 | ×2 | ×3 | ×4 | ×5 | |
|---|---|---|---|---|---|---|---|
| Benign Nodule | Target Acc. (base lr 1e-5) | 54.55% | 54.55% | 54.55% | 54.55% | 54.55% | 54.55% |
| CheXpert-5x200c 0-shot | 62.10% | 61.80% | 62.30% | 62.10% | 62% | 62.20% | |
| Lung Cancer | Target Acc. (base lr 1e-4) | 83.93% | 87.50% | 92.86% | 94.64% | 92.86% | 92.86% |
| CheXpert-5x200c 0-shot | 62.10% | 62.20% | 61.50% | 53.70% | 48.20% | 44.50% |
🔼 Table 2 presents the results of applying Knowledge Transfer to a medical image classification task using the MedCLIP model and the JSRT dataset. The goal was to evaluate the model’s ability to learn the concept of malignant lung nodules from textual descriptions alone. The table shows that the model successfully learned to identify malignant nodules in chest X-ray images, achieving a significant improvement in accuracy compared to the baseline. However, the results for benign nodules show limited improvement. This difference in performance highlights the greater difficulty in distinguishing benign nodules visually from other findings in chest X-rays, which makes them more challenging for the model to learn.
read the caption
Table 2: Knowledge Transfer on MedCLIP on the JSRT dataset. The model successfully learns the novel concept of malignant nodules (lung cancer) on CXR images. Benign nodules, on the other hand, are harder to visually differentiate from other findings in CXRs.
| Model | Atelectasis | Cardiomegaly | Consolidation | Edema | Pleural Effusion | Top-1 |
|---|---|---|---|---|---|---|
| MedCLIP (ViT) | Reference | 49% | 69.50% | 32.50% | 75.50% | 84% |
| CLIP ViT-B/32 | Baseline | 0% | 2.5% | 0% | 0% | 94.50% |
| Transfer | 0% | 21.5% | 0% | 0% | 85% | |
| CLIP ViT-L/14 | Baseline | 59.50% | 16.50% | 0% | 0% | 35.50% |
| Transfer | 4% | 32.5% | 0% | 0% | 92.5% |
🔼 This table presents the results of transferring knowledge from natural images to medical images using Knowledge Transfer. The baseline shows the zero-shot classification accuracy of a model pre-trained on natural images when applied to the CheXpert-5x200c dataset of medical chest X-rays. The transfer columns demonstrate the improved zero-shot performance after introducing new medical concepts (atelectasis, cardiomegaly, consolidation, edema, and pleural effusion) using only their textual descriptions through the proposed Knowledge Transfer method. The results are reported as top-1 accuracy for each of the five medical classes.
read the caption
Table 3: Learning novel concepts in a different domain (from natural images to medical images) shows potential. Tested on CheXpert-5x200c.
| Model | Lung Nodules (DSC) | Lung Nodules (NSD) | Lung Nodules (IoU) | Lung Pneumothorax (DSC) | Lung Pneumothorax (NSD) | Lung Pneumothorax (IoU) | Breast Ultrasound (DSC) | Breast Ultrasound (NSD) | Breast Ultrasound (IoU) | Brain MRI (DSC) | Brain MRI (NSD) | Brain MRI (IoU) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MedCLIP-SAMv2 | 14.83% | 17.30% | 8.64% | 6.30% | 7.61% | 3.75% | 56.25% | 59.44% | 47.81% | 17.20% | 20.97% | 12.05% |
| Transf. (1e-5) | 13.95% | 17.45% | 8.75% | 6.28% | 7.59% | 3.77% | 58.23% | 61.56% | 49.52% | 15.90% | 19.36% | 11.10% |
| Transf. (2e-5) | 14.10% | 17.65% | 8.83% | 6.41% | 7.76% | 3.83% | 54.36% | 57.30% | 46.30% | 18.13% | 22.26% | 12.62% |
| Transf. (1e-4) | 14.35% | 18.03% | 9.04% | 6.02% | 7.29% | 3.59% | - | - | - | - | - | - |
🔼 Table 4 presents the results of zero-shot image segmentation using the MedCLIP-SAMv2 model. It demonstrates the improvement achieved by incorporating Knowledge Transfer. The table shows results across four different segmentation tasks: lung nodule detection in CT scans, pneumothorax detection in chest X-rays, breast mass detection in ultrasound images, and glioma detection in brain MRIs. The ‘†’ symbol indicates novel concepts not present in the original MedCLIP-SAMv2 training dataset. The table includes the Dice-Sørensen Coefficient (DSC), Normalized Surface Distance (NSD), and Intersection over Union (IoU) metrics to evaluate the segmentation performance. Specific prompts used to generate the segmentation maps for each task are also listed.
read the caption
Table 4: Improvements in zero-shot segmentation. † denotes novel concepts that are not included in the original MedCLIP-SAMv2 training data [29]. Prompts used for segmentation are reported here: P1 A medical chest CT scan showing circular spots of varying size within the lungs, suggesting either benign or malignant nodules; P2 A medical chest x-ray showing an abnormal collection of air within the pleural cavity, suggesting a pneumothorax; P3 A medical breast mammogram showing an irregularly shaped, spiculated mass suggestive of a malignant breast tumor; P4 A brain MRI showing a bright or dark mass with irregular edges suggestive of a brain tumor or glioma.
| Model | Text Retrieval | Image Retrieval | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| — | — | — | — | — | — | — |
| Flickr30k (1K) | ||||||
| ViLBERT [38] | - | - | - | 31.9% | 61.1% | 72.8% |
| Unicoder-VL [31] | 64.3% | 85.8% | 92.3% | 48.4% | 76.0% | 85.2% |
| ImageBERT [44] | 70.7% | 90.2% | 94.0% | 54.3% | 79.6% | 87.5% |
| ViLT-B/32 (original) [26] | 73.2% | 93.6% | 96.5% | 55.0% | 82.5% | 89.8% |
| ViLT-B/32 (huggingface) | 73.8% | 93.5% | 96.5% | 57.3% | 83.9% | 90.4% |
| ViLT-B/32 (transf. 9e-7) | 74.6% | 93.8% | 96.4% | 57.8% | 84.0% | 90.5% |
| ViLT-B/32 (transf. 2e-6) | 74.6% | 93.7% | 96.5% | 57.8% | 84.0% | 90.5% |
🔼 This table presents the performance of different vision-language models on the Flickr30k dataset’s image and text retrieval tasks. The results are broken down by the recall@k metric (where k represents the top 1, 5, and 10 ranked results), showing how accurately each model retrieves the correct image given a text caption and vice-versa. The table includes results from the huggingface’s ViLT model and several other comparative models, allowing for a comprehensive evaluation of the current state-of-the-art in vision-language representation learning.
read the caption
Table 5: Text and image retrieval on Flickr30k. Recall scores are shown at top 1, 5 and 10 levels. Our results are based on huggingface’s ViLT. Original results and other comparisons from [26].
| Model | BLEU@4 | METEOR | CIDEr | SPICE |
|---|---|---|---|---|
| MSCOCO (5K) | ||||
| CLIP-ViL [51] | 40.2 | 29.7 | 134.2 | 23.8 |
| BLIP [32] | 40.4 | - | 136.7 | - |
| VinVL [64] | 41.0 | 31.1 | 140.9 | 25.4 |
| SimVLM [57] | 40.6 | 33.7 | 143.3 | 25.4 |
| LEMON [16] | 41.5 | 30.8 | 139.1 | 24.1 |
| CoCa [61] (proprietary) | 40.9 | 33.9 | 143.6 | 24.7 |
| CoCa | 6.9 | 12.8 | 31.1 | 9.1 |
| CoCa (transf. 8e-5) | 17.9 | 19.4 | 60.8 | 13.7 |
| CoCa FT | 34.9 | 29.7 | 123.1 | 23.5 |
| CoCa FT (transf. 5e-6) | 35.2 | 29.8 | 124.0 | 23.3 |
🔼 Table 6 presents the results of image captioning experiments performed on the MSCOCO dataset using the CoCa model. Two versions of the CoCa model are evaluated: a baseline model pre-trained on the LAION-2B dataset and a fine-tuned (FT) version specifically trained for captioning on MSCOCO. The table shows various metrics (BLEU@4, METEOR, CIDEr, SPICE) to assess the quality of the generated captions. The results with and without knowledge transfer are compared, highlighting the improvement in captioning performance achieved through the knowledge transfer technique.
read the caption
Table 6: Image captioning on MSCOCO. CoCa refers to the baseline model pre-trained on LAION-2B [49], while CoCa FT refers to the model fine-tuned for captioning on MSCOCO. We highlight in bold the best results and the improvements by Knowledge Transfer.
| Model | Lung Nodules DSC | Lung Nodules NSD | Lung Nodules IoU | Lung Pneumothorax DSC | Lung Pneumothorax NSD | Lung Pneumothorax IoU | Breast Ultrasound DSC | Breast Ultrasound NSD | Breast Ultrasound IoU | Brain MRI DSC | Brain MRI NSD | Brain MRI IoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MedCLIP-SAMv2 | 14.83% | 17.30% | 8.64% | 6.30% | 7.61% | 3.75% | 56.25% | 59.44% | 47.81% | 17.20% | 20.97% | 12.05% |
| Transf. (1e-5) | 13.95% | 17.45% | 8.75% | 6.28% | 7.59% | 3.77% | 58.23% | 61.56% | 49.52% | 15.90% | 19.36% | 11.10% |
| Transf. (2e-5) | 14.10% | 17.65% | 8.83% | 6.41% | 7.76% | 3.83% | 54.36% | 57.30% | 46.30% | 18.13% | 22.26% | 12.62% |
| Transf. (3e-5) | 14.10% | 17.65% | 8.85% | 6.25% | 7.55% | 3.73% | 55.70% | 59.00% | 47.49% | 15.47% | 18.85% | 10.78% |
| Transf. (4e-5) | 14.25% | 17.85% | 8.94% | 6.24% | 7.57% | 3.71% | 53.86% | 56.82% | 45.61% | 15.26% | 18.63% | 10.62% |
| Transf. (5e-5) | 14.20% | 17.78% | 8.92% | 6.20% | 7.51% | 3.70% | 54.90% | 57.97% | 46.09% | 16.22% | 19.81% | 11.34% |
| Transf. (1e-4) | 14.35% | 18.03% | 9.04% | 6.02% | 7.29% | 3.59% | - | - | - | - | - | - |
| Transf. (2e-4) | 10.74% | 13.64% | 6.66% | 4.71% | 5.54% | 2.86% | - | - | - | - | - | - |
🔼 This table presents a comprehensive evaluation of zero-shot segmentation performance using the MedCLIP-SAMv2 model. It details the Dice-Sørensen Coefficient (DSC), Normalized Surface Distance (NSD), and Intersection over Union (IoU) metrics for various segmentation tasks, including lung nodules and pneumothorax (novel concepts) and brain tumors, across different learning rates. The results show the impact of knowledge transfer on the model’s ability to accurately segment medical images.
read the caption
Table 7: Full results on zero-shot segmentation with MedCLIP-SAMv2.
| Model | LR | Batch Size | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
|---|---|---|---|---|---|---|---|---|
| ViLT-B/32 (huggingface) | - | - | 73.8% | 93.5% | 96.5% | 57.3% | 83.9% | 90.4% |
| ViLT-B/32 | 8e-7 | 32 | 74.5% | 93.8% | 96.4% | 57.7% | 84.0% | 90.4% |
| ViLT-B/32 | 9e-7 | 32 | 74.6% | 93.8% | 96.4% | 57.8% | 84.0% | 90.5% |
| ViLT-B/32 | 1e-6 | 16 | 74.4% | 93.8% | 96.5% | 57.7% | 84.1% | 90.5% |
| ViLT-B/32 | 2e-6 | 128 | 74.6% | 93.7% | 96.5% | 57.8% | 84.0% | 90.5% |
| ViLT-B/32 | 3e-6 | 256 | 74.5% | 93.9% | 96.5% | 57.7% | 83.9% | 90.5% |
| ViLT-B/32 | 4e-6 | 32 | 73.8% | 93.6% | 96.5% | 57.4% | 84.0% | 90.5% |
| ViLT-B/32 | 5e-6 | 256 | 74.5% | 93.9% | 96.5% | 57.6% | 84.0% | 90.5% |
| ViLT-B/32 | 8e-6 | 32 | 73.2% | 93.7% | 96.1% | 57.4% | 83.7% | 90.4% |
| ViLT-B/32 | 1e-5 | 128 | 74.4% | 93.8% | 96.8% | 56.8% | 83.7% | 90.6% |
| ViLT-B/32 | 2e-5 | 32 | 71.8% | 93.2% | 96.4% | 56.7% | 83.6% | 90.4% |
| ViLT-B/32 | 3e-5 | 32 | 70.8% | 92.1% | 95.7% | 56.0% | 82.9% | 90.2% |
🔼 This table presents a comprehensive evaluation of text and image retrieval performance using the ViLT model on the Flickr30k dataset. The first part displays baseline recall scores (R@1, R@5, R@10) for image and text retrieval, establishing a benchmark. The second part details the impact of varying the learning rate and batch size (experimenting with 16, 32, 64, 128, and 256) during model training. For each configuration, the recall scores (R@1, R@5, R@10) are provided to show how these hyperparameters affect the model’s ability to accurately retrieve relevant images or texts.
read the caption
Table 8: Full results for text and image retrieval on Flickr30k with ViLT. The first section reports baseline results, while the second shows the outcome of each tested learning rate and its optimal batch size (chosen among 16, 32, 64, 128, and 256). Recall scores at top 1, 5, and 10 are reported.
| Model | BLEU@4 | METEOR | CIDEr | SPICE |
|---|---|---|---|---|
| CLIP-ViL [51] | 40.2 | 29.7 | 134.2 | 23.8 |
| BLIP [32] | 40.4 | - | 136.7 | - |
| VinVL [64] | 41.0 | 31.1 | 140.9 | 25.4 |
| SimVLM [57] | 40.6 | 33.7 | 143.3 | 25.4 |
| LEMON [16] | 41.5 | 30.8 | 139.1 | 24.1 |
| CoCa [61] (proprietary) | 40.9 | 33.9 | 143.6 | 24.7 |
| CoCa | 6.9 | 12.8 | 31.1 | 9.1 |
| CoCa (transf. 6e-5) | 13.6 | 18.5 | 47.3 | 13.6 |
| CoCa† (transf. 9e-5) | 17.9 | 19.4 | 60.8 | 13.7 |
| CoCa FT | 34.9 | 29.7 | 123.1 | 23.5 |
| CoCa FT (transf. 2e-5) | 35.2 | 29.8 | 123.1 | 23.2 |
| CoCa FT† (transf. 5e-6) | 35.2 | 29.8 | 124.0 | 23.3 |
🔼 Table 9 presents the results of image captioning experiments conducted on the MSCOCO dataset using the CoCa model. The table compares the performance of several different models on various captioning metrics (BLEU, METEOR, CIDEr, SPICE). The models include a baseline CoCa model pre-trained on LAION-2B (indicated as CoCa), a CoCa model fine-tuned for captioning on MSCOCO (CoCa FT), and versions of these models enhanced with Knowledge Transfer (indicated as transf.). The best performing model for each metric is highlighted in bold, showcasing the improvements in captioning performance obtained through the Knowledge Transfer method. The ‘+ symbol indicates that the decoder was also fine-tuned during model training.
read the caption
Table 9: Image captioning on MSCOCO. † means the decoder is also fine-tuned. CoCa refers to the baseline model pre-trained on LAION-2B [49], while CoCa FT refers to the model fine-tuned for captioning on MSCOCO. We highlight in bold the best results overall and the improvements achieved by Knowledge Transfer.
| Sample | MSCOCO | MSCOCO | MSCOCO | MSCOCO | MSCOCO |
|---|---|---|---|---|---|
| Sample |  |  |  |  |  |
| Actual | A shot of a clock in the train station. | A pianist in a suit and glasses playing a keyboard. | A baseball player hitting a ball in a professional game. | A baseball holding a baseball bat during a baseball game. | Two people that are sitting on a table. |
| Baseline | grand - central - station - new - york.jpg (METEOR 0.0) | Paul Kagasoff, president and chief executive officer of Intel corp., speaks during the 2012 Computex trade show in Taipei, Taiwan (METEOR 8.6) | Aaron judge 2016 new york Yankees (METEOR 5.0) | 20080419 _ mariners _ 0001 | by Mike. Smith (METEOR 4.2) |
| Knowledge Transfer | A black and white photo of a clock at Grand Central terminal. (METEOR 92.9) | A photo of a man in a suit sitting at a keyboard. (METEOR 86.1) | A baseball player swings his bat at a batter. (METEOR 83.6) | A baseball player takes a swing at a pitch. (METEOR 86.9) | A photo of a man and a woman sitting at a kitchen table. (METEOR 80.8) |
| Sample |  |  |  |  |  |
| Actual | A baseball batter up at the plate that just hit a ball | A pair of red scissors sitting on a newspaper. | A young man sitting at a table with a pizza. | A man in a black suit kicking around a soccer ball. | The man in a black tie sits in a chair with his shirt sleeves rolled up. |
| Baseline | david - ortiz _ display _ image _ display _ image _ display _ image _ display _ image _ display _ image _ display _ image (METEOR 3.9) | Your scissors are now digitized (METEOR 9.5) | Pizza and beer in Chicago, Illinois. Photo via Flickr: David J. Abbott M.D. (METEOR 8.3) | blatter - foot - ball.jpeg (METEOR 5.6) | Avatar for Marc Anthony (METEOR 5.3) |
| Knowledge Transfer | A baseball player swings his bat at a pitch. (METEOR 80.3) | A photo of a pair of red scissors on a piece of paper. (METEOR 84.9) | A photo taken of a man sitting at a table with a plate of pizza. (METEOR 83.5) | A man in a suit kicking a soccer ball on a field. (METEOR 80.7) | A man in a white shirt and black tie sits on a chair. (METEOR 78.4) |
🔼 This table showcases ten examples from the MSCOCO dataset where Knowledge Transfer enhanced image captioning. For each example, it shows the original image and caption, the caption generated by a baseline model, and the improved caption generated after employing Knowledge Transfer. The improvement is quantified using the METEOR score, a metric that assesses the quality of generated captions by comparing them to reference captions.
read the caption
Table 10: Visual example of captioning on MSCOCO. We report the top ten most illustrative examples in which knowledge transfer improved captioning, in terms of METEOR score.
| Type | Concept | Baseline | 1e-5 | 2e-5 | 3e-5 | 4e-5 | 5e-5 | |
|---|---|---|---|---|---|---|---|---|
| Implicit | Moongate | Target Acc. | 0% | 0% | 0% | 0% | 0% | 0% |
| ImageNet* 0-shot | 23.74% | 23.82% | 23.90% | 23.98% | 23.94% | 23.86% | ||
| Tonometer | Target Acc. | 10% | 10% | 10% | 10% | 10% | 0% | |
| ImageNet* 0-shot | 23.74% | 23.84% | 23.86% | 23.70% | 23.64% | 23.60% | ||
| Gyroscope | Target Acc. | 50% | 50% | 60% | 60% | 60% | 50% | |
| ImageNet* 0-shot | 23.74% | 23.74% | 23.62% | 23.42% | 23.44% | 23.46% | ||
| Explicit | Moongate | Target Acc. | 0% | 0% | 0% | 0% | 0% | 0% |
| ImageNet* 0-shot | 23.74% | 23.80% | 24.08% | 24.02% | 24.10% | 24.20% | ||
| Tonometer | Target Acc. | 10% | 10% | 10% | 10% | 10% | 10% | |
| ImageNet* 0-shot | 23.74% | 23.80% | 23.74% | 23.72% | 23.70% | 23.56% | ||
| Gyroscope | Target Acc. | 50% | 50% | 50% | 50% | 40% | 30% | |
| ImageNet* 0-shot | 23.74% | 23.74% | 23.84% | 23.84% | 23.84% | 23.82% |
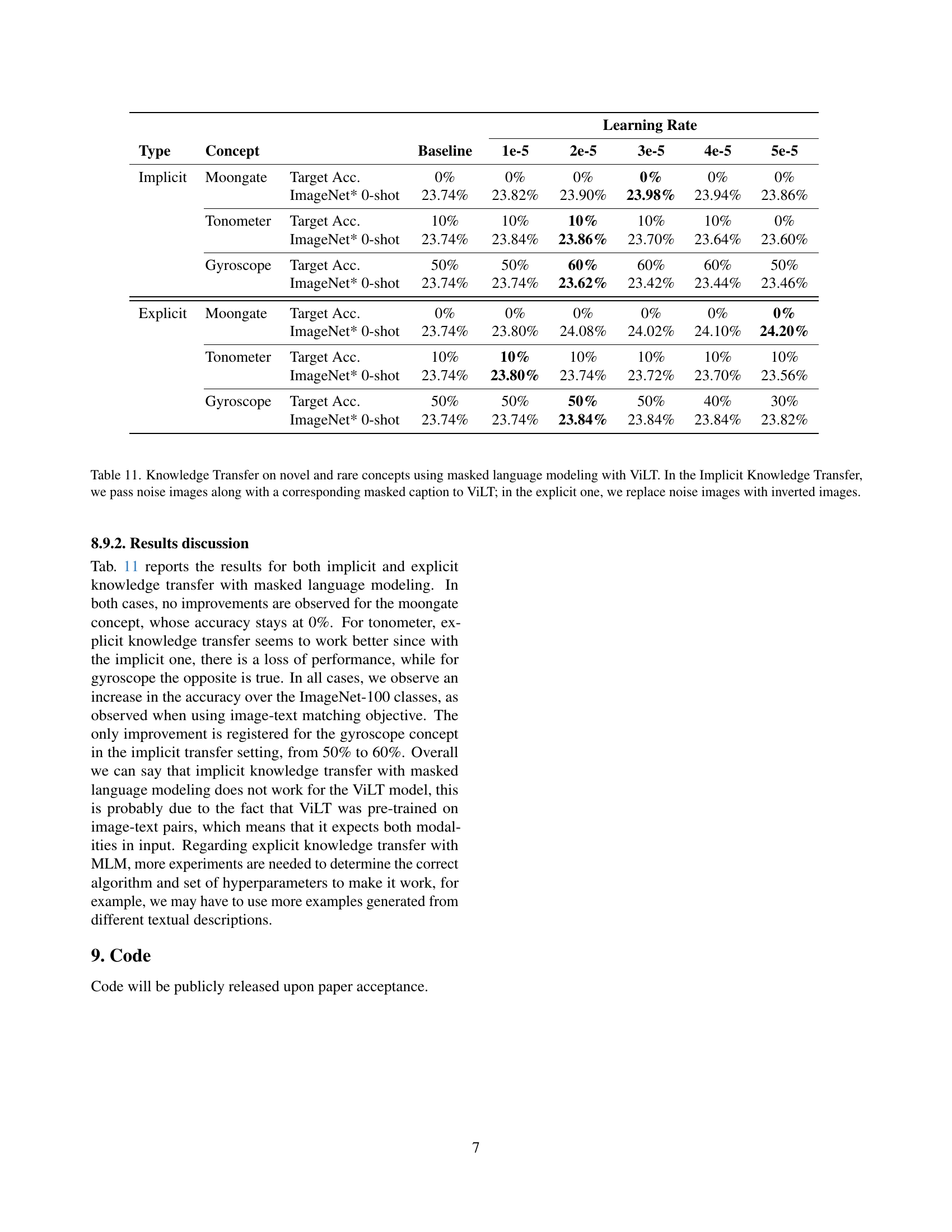
🔼 This table presents the results of knowledge transfer experiments using the ViLT model, focusing on three rare concepts (Moongate, Tonometer, Gyroscope). Two approaches to knowledge transfer are compared: implicit and explicit. In implicit transfer, random noise images are paired with masked captions and fed to the ViLT model. In explicit transfer, inverted images (generated using model inversion) replace the noise images. The table shows the accuracy achieved for each concept in both zero-shot classification and ImageNet-1k zero-shot settings, for various learning rates and for both implicit and explicit methods.
read the caption
Table 11: Knowledge Transfer on novel and rare concepts using masked language modeling with ViLT. In the Implicit Knowledge Transfer, we pass noise images along with a corresponding masked caption to ViLT; in the explicit one, we replace noise images with inverted images.
| Name | Description |
|---|---|
| Moongate | A perfectly circular archway built from uniformly cut stones or bricks, set into a larger wall. It forms a smooth circle, framing views of gardens or landscapes beyond, creating a picturesque portal. |
| Tonometer | A slender, pen-like probe attached to a small base equipped with precise dials and gauges. This tool is often part of a larger medical apparatus, featuring a metallic finish and a refined, professional appearance. |
| Gyroscope | A series of gleaming silver rings, each nested perfectly within the next, surrounds a central disk that spins smoothly. The rings are connected by intersecting axes, allowing the disk to tilt and rotate freely while maintaining a sophisticated, mechanical look. |
🔼 This table provides detailed textual descriptions for three rare concepts: Moongate, Tonometer, and Gyroscope. These descriptions were automatically generated using the large language model Llama-3-8B-Instruct. Each description aims to be detailed enough to be useful for training a model on the concept, without directly naming the concept itself.
read the caption
Table 12: Descriptions for rare concepts (generated with Llama-3-8B-Instruct).
| Name | Description |
|---|---|
| Moongate | A perfectly circular archway built from uniformly cut stones or bricks, set into a larger wall. It forms a smooth circle, framing views of gardens, creating a picturesque portal. |
| Tonometer | A slender, pen-like probe attached to a small base equipped with precise dials and gauges. This tool is often part of a larger medical apparatus. |
| Gyroscope | A series of rings each nested within the next, surrounds a central disk that spins. The rings are connected by intersecting axes allowing the disk to rotate freely. |
🔼 This table presents concise descriptions of three uncommon concepts (Moongate, Tonometer, Gyroscope) tailored for compatibility with the ViLT model’s input limitations (maximum of 40 tokens). These shorter descriptions maintain the essence of the concepts while being brief enough for the model’s processing.
read the caption
Table 13: Manually shortened descriptions for rare concepts (to fit into ViLT’s 40 token input)
| Nodule Type | Description |
|---|---|
| Benign Nodule | A small, round spots appearing in Chest X-Ray, typically well-defined with smooth, regular borders. These spots are often uniformly dense and do not cause distortion of surrounding structures. |
| Lung Cancer | A dense and irregular mass on Chest X-Ray images often with spiked or uneven edges. It may appear in the lung’s periphery or near the airways. |
🔼 Table 14 presents descriptions of medical image classes from the JSRT dataset. These descriptions were created by combining information from Radiopaedia (an online medical image database) and ChatGPT-4 (a large language model). The table aims to provide detailed textual descriptions for use in training or evaluating a model’s ability to classify medical images, specifically those containing lung nodules. This information was used for model fine-tuning in the experiments. The descriptions cover both benign and malignant lung nodules, offering characteristics useful for distinguishing between the two types.
read the caption
Table 14: Descriptions for medical classes for JSRT (Mix with Radiopaedia and ChatGPT-4).
| Finding | Description |
|---|---|
| Atelectasis | A small areas of collapsed lung. It is usually seen on Chest X-Rays as small volume linear shadows, usually peripherally or at lung bases, appearing more opaque and shrunken. |
| Cardiomegaly | Enlargement of the heart usually seen in Chest X-Rays. The central shadow of the chest appears enlarged, extending beyond half the width of the entire chest cavity. |
| Pleural Effusion | A collection of fluid between the lungs and the chest, which makes the area appear white and smooth in Chest X-Ray images. The area does not present visible lung markings. |
| Consolidation | An area inside the lungs that appears as branching low attenuating (lucent) bronchi surrounded by high attenuating (dense) consolidated/opacified alveoli on Chest X-Ray images. |
| Edema | An abnormal accumulation of fluid in the extravascular compartments of the lung, which makes the area whiter in Chest X-Ray images. It is usually present on both lungs. |
🔼 Table 15 presents descriptions of several medical classes from the CheXpert-5x200c dataset. These descriptions were generated using a combination of information from the Radiopaedia medical image database and the ChatGPT-4 large language model. The goal was to provide concise yet informative text descriptions of the visual characteristics associated with each medical class in chest X-ray images.
read the caption
Table 15: Descriptions for medical classes for CheXpert-5x200c (obtained with a mix of Radiopaedia and ChatGPT-4).
| Finding | Description |
|---|---|
| Lung Nodules | Circular spots appearing within the lung fields, with clear and defined edges in CT images. They are denser than the surrounding tissue, often appearing in shades of gray or white, with varying size. |
| Breast Tumor | A dark, irregularly shaped area is visible against the lighter surrounding tissue. The borders may appear uneven or spiculated, and the area is typically less uniform in texture. Shadowing can often be seen beneath the mass. |
| Pneumothorax | An abnormal collection of air in the pleural space, which allows the parietal and visceral pleura to separate and the lung to collapse. The pleura edge is thin and no lung markings are visible. |
| Brain Tumor | An irregular bright mass in brain MRI, often with thick and irregular margins, surrounded by vasogenic-type edema or fluid accumulation. It may also have a hemorrhagic component. |
🔼 This table provides detailed descriptions of several medical image classes relevant for image segmentation tasks. The descriptions were created using a combination of information from Radiopaedia (a medical image database) and ChatGPT-4 (a large language model). Each description aims to provide a comprehensive yet concise description of the visual appearance of the medical finding, making it suitable for use in training or evaluating image segmentation models. The classes are: Benign Nodule, Lung Cancer, Lung Nodules.
read the caption
Table 16: Descriptions for medical classes for segmentation (Mix with Radiopaedia and ChatGPT-4).
| Object | Description |
|---|---|
| person | A human figure, typically with visible head, torso, arms, and legs, in various postures. |
| bicycle | A two-wheeled vehicle with a frame, handlebars, and pedals, usually ridden by a person. |
| car | A four-wheeled enclosed vehicle with windows and doors, commonly seen on roads. |
| motorcycle | A two-wheeled motorized vehicle with a seat and handlebars, typically ridden by one or two people. |
| airplane | A large flying vehicle with wings and a tail, often seen with windows along the sides for passengers. |
| bus | A large, rectangular vehicle with many windows and seating rows, designed to carry multiple passengers. |
| train | A long, linked series of vehicles running on tracks, often with a locomotive at the front. |
| truck | A large vehicle with a separate cab and an open or enclosed cargo area for transporting goods. |
| boat | A small to medium-sized watercraft with a hull and often visible sails or an engine. |
| traffic light | A vertical or horizontal post with red, yellow, and green lights, used to control vehicle flow at intersections. |
| fire hydrant | A small, red, metal cylinder with nozzles on the side, often found on sidewalks for fire emergencies. |
| stop sign | A red, octagonal sign with the word “STOP” in white, used to indicate where vehicles must halt. |
| parking meter | A tall, narrow post with a small display and slot, used to pay for parking time. |
| bench | A long seat, often with a backrest, typically found in parks or public areas. |
| bird | A small animal with feathers, wings, and a beak, often shown perched or flying. |
| cat | A small, furry animal with pointed ears, whiskers, and a long tail, often seen sitting or grooming. |
| dog | A furry, four-legged animal with a tail, usually seen with a collar or leash. |
| horse | A large, four-legged animal with a mane and tail, often depicted standing or galloping. |
| sheep | A woolly animal with a round body, small head, and short legs, often seen in groups in fields. |
| cow | A large animal with a boxy body, horns, and a long face, often shown grazing or with an udder. |
| elephant | A massive, gray animal with a long trunk, large ears, and tusks. |
| bear | A large, sturdy animal with thick fur, rounded ears, and a short tail, often shown standing or walking on all fours. |
| zebra | A horse-like animal with black and white stripes across its body. |
| giraffe | A very tall animal with a long neck and legs, spotted coat, and small horns on its head. |
| backpack | A bag with shoulder straps, typically worn on the back and used for carrying personal items. |
| umbrella | A foldable, rounded canopy on a stick, used for protection from rain or sun. |
| handbag | A small to medium-sized bag with handles, often carried by hand and used to hold personal items. |
| tie | A long, narrow piece of fabric worn around the neck, often knotted at the collar of a shirt. |
| suitcase | A rectangular, boxy container with a handle, used for carrying clothes and personal items when traveling. |
| frisbee | A flat, round disc often made of plastic, used for throwing and catching. |
| skis | Long, narrow pieces of equipment attached to boots, used for gliding on snow. |
| snowboard | A flat, wide board attached to boots, used for sliding on snow. |
| sports ball | A round object of varying sizes, such as a soccer ball or basketball, used in sports. |
| kite | A lightweight object with a string, often shaped like a diamond or triangle, designed to fly in the wind. |
| baseball bat | A smooth, cylindrical wooden or metal stick used to hit a baseball. |
| baseball glove | A padded, leather glove worn on one hand, used to catch baseballs. |
| skateboard | A narrow board with wheels, used for rolling and performing tricks. |
| surfboard | A long, flat board used for riding waves in the ocean. |
| tennis racket | An oval-shaped frame with strings and a handle, used to hit a tennis ball. |
| bottle | A narrow-necked container with a cap, often used to hold liquids like water or soda. |
| wine glass | A stemmed glass with a wide bowl at the top, used for drinking wine. |
| cup | A small, handleless vessel used for drinking, usually made of ceramic or plastic. |
| fork | A utensil with multiple prongs, used to pick up food. |
| knife | A utensil with a long, sharp blade, used for cutting food. |
| spoon | A utensil with a shallow bowl at the end of a handle, used for eating or serving food. |
| bowl | A round, deep dish, often used to hold soup or other foods. |
| banana | A long, yellow fruit with a curved shape and soft interior. |
| apple | A round fruit, typically red or green, with a stem at the top. |
| sandwich | Two slices of bread with filling in between, such as meat, cheese, or vegetables. |
| orange | A round, orange-colored fruit with a thick, textured peel. |
| broccoli | A green vegetable with a tree-like shape, featuring a thick stalk and small florets. |
| carrot | A long, orange vegetable with a pointed end, often with green leaves at the top. |
| hot dog | A sausage in a bun, often with condiments like ketchup or mustard. |
| pizza | A round, flatbread topped with cheese, sauce, and various toppings, often cut into slices. |
| donut | A round, fried pastry with a hole in the middle, often glazed or topped with sprinkles. |
| cake | A sweet, layered dessert, often decorated with frosting or fruit. |
| chair | A piece of furniture with a backrest and four legs, designed for sitting. |
| couch | A large, cushioned seat with a backrest and arms, designed for multiple people. |
| potted plant | A plant growing in a container, often with green leaves or flowers. |
| bed | A large, rectangular piece of furniture for sleeping, with a mattress and pillows. |
| dining table | A flat, often rectangular surface with legs, designed for eating meals. |
| toilet | A porcelain fixture with a seat and flushing mechanism, used in bathrooms. |
| tv | A rectangular screen on a stand or wall, used for viewing shows and movies. |
| laptop | A portable computer with a hinged screen and keyboard. |
| mouse | A small, handheld device used to control a cursor on a computer screen. |
| remote | A small, rectangular device with buttons, used to control electronics like TVs. |
| keyboard | A flat, rectangular panel with keys, used for typing on computers. |
| cell phone | A handheld electronic device with a screen and buttons or touchscreen, used for communication. |
| microwave | A box-like appliance with a door, used for heating food quickly. |
| oven | A large appliance with a door and interior racks, used for baking or roasting. |
| toaster | A small appliance with slots, used to toast bread. |
| sink | A basin with a faucet, used for washing hands, dishes, or food. |
| refrigerator | A large, box-like appliance with doors, used to store perishable food at low temperatures. |
| book | A collection of pages bound together with a cover, containing text or images. |
| clock | A circular or rectangular device with hands or digital display, showing the current time. |
| vase | A decorative container, often made of glass or ceramic, used to hold flowers. |
| scissors | A handheld tool with two blades, used for cutting paper or fabric. |
| teddy bear | A soft, stuffed toy shaped like a bear, often used by children. |
| hair drier | A handheld device that blows warm air, used to dry hair. |
| toothbrush | A small brush with a handle, used for cleaning teeth. |
🔼 This table lists descriptions of 80 classes from the MS-COCO dataset, generated using ChatGPT-4. Each description aims to provide a detailed textual representation of the visual features characteristic of each class, suitable for use in image-text retrieval experiments. These descriptions are designed to be more detailed and descriptive than typical class labels, helping models better understand the visual nuances of each object category.
read the caption
Table 17: Descriptions for MSCOCO classes used for text and image retrieval experiments (With ChatGPT-4).
Full paper#