↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current recommendation systems often rely on task-specific user interaction data or text, limiting their applicability to diverse scenarios. Furthermore, handling the inherent noise and diversity in visual data presents a challenge for personalization based on visual history. Existing systems struggle to effectively incorporate such visual information for recommendation tasks.
VisualLens tackles this problem by using a multi-stage pipeline to extract and filter relevant visual signals from a user’s images. It employs image captioning and aspect extraction to enrich image representations. A grid-based approach optimizes processing efficiency for improved speed. The system significantly outperforms state-of-the-art methods and establishes two new benchmarks for evaluating personalized recommendations using visual histories. These contributions advance the field by showing that visual history can be effectively used for personalization, even in the presence of noise and task-agnostic data.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to personalized recommendations using visual history, a largely unexplored area. It addresses the challenges of noisy and diverse visual data, proposes a novel solution, and demonstrates significant improvement over existing methods. This opens new avenues for research in personalized recommendation systems and for applications where traditional methods fall short. The benchmarks created also benefit the research community.
Visual Insights#

🔼 This figure demonstrates the VisualLens approach, which utilizes a user’s task-agnostic visual history (images reflecting daily life) to generate personalized recommendations. The chart compares the Hit@3 performance of VisualLens against several baselines, including UniMP and GPT-40. VisualLens shows a consistent improvement in recommendation accuracy over these baselines, specifically outperforming GPT-40 by a margin ranging from 1.6% to 4.6% in Hit@3.
read the caption
Figure 1: VisualLens leverages a user’s task-agnostic visual history to provide personalized recommendations. Our method outperforms GPT-4o by 1.6%∼similar-to\sim∼4.6% on Hit@3.
| Hyperparameters for training on PaliGemma | |
|---|---|
| Parameter Size | 3B |
| Image Resolution | 896 × 896 |
| Number of Image Tokens | 4096 |
| Hidden Dimension Size | 2048 |
| LoRA Rank | 16 |
| LoRA α | 16 |
| LoRA dropout | 0.1 |
| GPU | 8 × NVIDIA H100 |
| Batch Size | 8 |
| Gradient Accumulation Steps | 8 |
| Warmup Steps | 200 |
| Learning Rate | 1e-3 |
🔼 This table presents a summary of the statistics for two datasets: Google Review-Vision (GR-V) and Yelp-Vision (Yelp-V), which were created for evaluating personalized recommendations using visual history. For each dataset, it provides the size of the train, dev, and test splits, the number of categories included, the average number of images per category, the average number of ground truth items, and the average number of candidate items. These statistics offer insights into the scale and characteristics of the datasets used in the study.
read the caption
Table 1: Dataset statistics of Google Review-Vision (GR-V) and Yelp-Vision (Yelp-V).
In-depth insights#
Visual History Use#
The concept of “Visual History Use” in a research paper likely explores how personal image data is leveraged for improved personalization. This would involve analyzing a user’s photographic record—their visual history—to infer preferences and interests. A key challenge is handling the inherent noise and diversity within a visual history, encompassing images unrelated to specific tasks or preferences. Effective methods are needed to filter irrelevant images and extract meaningful representations. The paper likely proposes a novel method that goes beyond existing techniques relying on task-specific logs or textual data. The approach probably involves advanced image analysis, potentially using multimodal LLMs to extract visual and textual signals from images. The success of such a method would hinge on its ability to improve recommendation accuracy, surpassing traditional methods, particularly in scenarios where those methods fall short due to data sparsity or task ambiguity. Evaluation likely includes benchmarking against existing approaches, utilizing metrics such as Hit@k to demonstrate performance gains. Therefore, “Visual History Use” is not just about data collection but about the development and evaluation of advanced techniques for extracting and applying meaningful insights from unstructured visual data to personalize user experiences.
Novel Personalization#
The concept of “Novel Personalization” in a research paper likely centers on a new approach to tailoring experiences to individual users. This could involve innovative data sources, such as visual histories or multimodal data, moving beyond traditional methods that rely solely on explicit user interactions or textual data. A novel personalization technique might leverage advanced algorithms like deep learning models to process complex, heterogeneous data for accurate user preference inference. The approach likely emphasizes contextual awareness, adapting recommendations based on the user’s current state or situation. Furthermore, a key aspect may be the development of more robust and efficient personalization systems capable of handling large-scale data and delivering timely responses, especially in scenarios where traditional methods might fail. This could involve implementing optimized processing pipelines or new model architectures designed for efficiency. Finally, privacy considerations are likely paramount, highlighting how user data is handled responsibly to safeguard personal information while providing highly tailored recommendations.
Multimodal Approach#
A multimodal approach to recommendation systems leverages diverse data modalities, such as text, images, and user interaction logs, to create a more comprehensive and nuanced understanding of user preferences. This contrasts with unimodal approaches that rely solely on a single data type. The key advantage lies in the ability to capture richer, more contextually relevant information, leading to more accurate and personalized recommendations. For example, a multimodal system might combine textual descriptions of products with associated images and user purchase history to provide superior recommendations compared to a system relying only on textual descriptions. The effective fusion of diverse data sources is a critical challenge, requiring sophisticated techniques to align and integrate information across different modalities. This often involves specialized embedding methods and neural network architectures designed to handle heterogeneous data formats. The ability to extract relevant features and handle noisy data is also crucial for success. Finally, the computational cost of processing and integrating multimodal data can be significantly higher than for unimodal systems, making efficiency a crucial consideration in designing and implementing effective multimodal recommendation architectures.
Benchmark Datasets#
The effectiveness of any recommendation system hinges on the quality of its benchmark datasets. These datasets must accurately reflect real-world scenarios and provide a diverse range of user behaviors and preferences. The choice of benchmark heavily influences the evaluation metrics used, which in turn, affects how the model’s performance is perceived. A well-designed benchmark should include a variety of data modalities, such as textual descriptions, visual content, user interaction logs, and contextual information, to comprehensively assess the model’s abilities. Furthermore, sufficient data volume is critical to ensure statistical significance, and the dataset should be representative of the target user population. Bias within the dataset poses a serious challenge, leading to inaccurate or unfair model performance. Addressing dataset bias requires careful curation, preprocessing, and potentially the creation of specialized benchmarks designed to alleviate existing biases and evaluate models on their ability to handle diverse scenarios.
Future Research#
Future research directions stemming from the VisualLens paper could significantly expand its capabilities and address limitations. Extending the system to handle diverse recommendation tasks beyond category-based suggestions is crucial. This would involve exploring different query types and developing more robust retrieval and matching mechanisms. Improving the system’s robustness to noisy or incomplete visual data is also vital. Techniques like data augmentation and more sophisticated filtering strategies could help mitigate these issues. Addressing privacy concerns related to the use of personal visual data is paramount. Exploring privacy-preserving techniques such as federated learning or differential privacy would be essential to ensure responsible and ethical deployment. Finally, in-depth investigation into the interplay between visual and textual information within the recommendation process warrants further exploration. Developing models that seamlessly integrate both modalities could lead to superior personalization.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage process of VisualLens. The offline stage involves augmenting each image in a user’s visual history with automatically generated captions and aspect words. The runtime stage consists of three steps: 1) History Retrieval: Selects images from the visual history most relevant to a given recommendation query. 2) Preference Profiling: Generates a user preference profile based on the retrieved images, captions, and aspect words. This often involves aggregating multiple images into a grid. 3) Candidate Matching: Matches the user profile against potential recommendation candidates, ranking them based on a calculated probability.
read the caption
Figure 2: VisualLens inference pipeline: the offline process augments images in the visual history with captions and aspect words; the runtime recommendation process retrieves relevant images, generate user profile accordingly, and then predict candidate preferences.

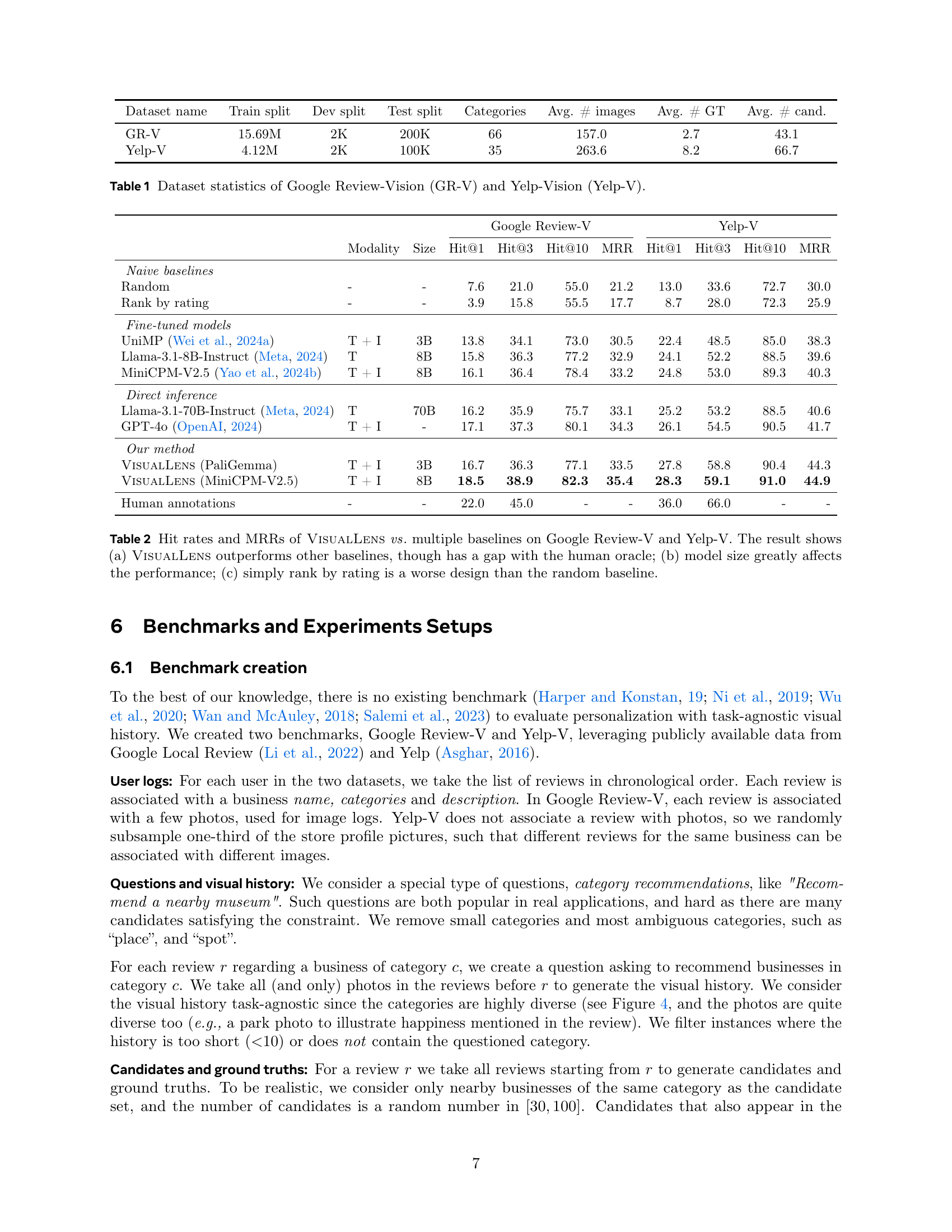
🔼 The figure shows the MRR distribution over the number of candidates. The MRR (Mean Reciprocal Rank) is a metric used to evaluate the ranking quality of recommendations, where a higher MRR indicates better performance. The x-axis represents the number of candidates and the y-axis represents the MRR. The plot shows that the MRR initially increases as the number of candidates increases but eventually plateaus, indicating that increasing the number of candidates beyond a certain point doesn’t significantly improve recommendation quality. This suggests there’s a point of diminishing returns when adding more candidates.
read the caption
(a)

🔼 The figure shows the MRR distribution over the number of images in the visual history. The x-axis represents the number of images, and the y-axis represents the Mean Reciprocal Rank (MRR). The plot demonstrates that as the number of images increases, the MRR initially increases and then plateaus after reaching approximately 100 images. This indicates that while a larger visual history provides more information, there’s a point of diminishing returns beyond which additional images don’t significantly improve the recommendation accuracy. The flattening of the curve suggests the model’s robustness to noise in the visual history; the system can effectively filter out irrelevant images.
read the caption
(b)

🔼 This figure presents two bar charts visualizing the performance of the VisualLens model. Chart (a) displays the Mean Reciprocal Rank (MRR) across varying numbers of candidate items for a recommendation task, revealing MRR convergence beyond 50 candidates. Chart (b) shows MRR performance with different numbers of images in the user’s visual history, demonstrating that MRR increases and plateaus around 100 images. Both charts are based on User ID test data, meaning each user’s history and recommendations are treated separately, and no user data is shared between train and test data.
read the caption
Figure 3: (a) MRR distribution over number of candidates, (b) MRR distribution over number of images. Both are on the User ID test set. We find (1) MRR converges when number of candidates exceeds 50; (2) MRR increases and flattens after reaching ∼similar-to\sim∼100 images.

🔼 The figure shows the MRR distribution based on the number of candidates. The left graph shows that the MRR converges when the number of candidates exceeds 50. The right graph shows that the MRR increases and flattens after reaching around 100 images.
read the caption
(a)

🔼 The figure shows the MRR distribution over the number of images in a user’s visual history. The x-axis represents the number of images, and the y-axis represents the Mean Reciprocal Rank (MRR). The graph illustrates how the MRR changes as the amount of visual data increases. It shows that initially, MRR improves as more images are available because the model has more data to learn user preferences from. However, after a certain point (~100 images), the MRR plateaus or even slightly decreases. This indicates that including excessively large amounts of visual data may not necessarily improve the quality of the recommendations and can introduce noise.
read the caption
(b)

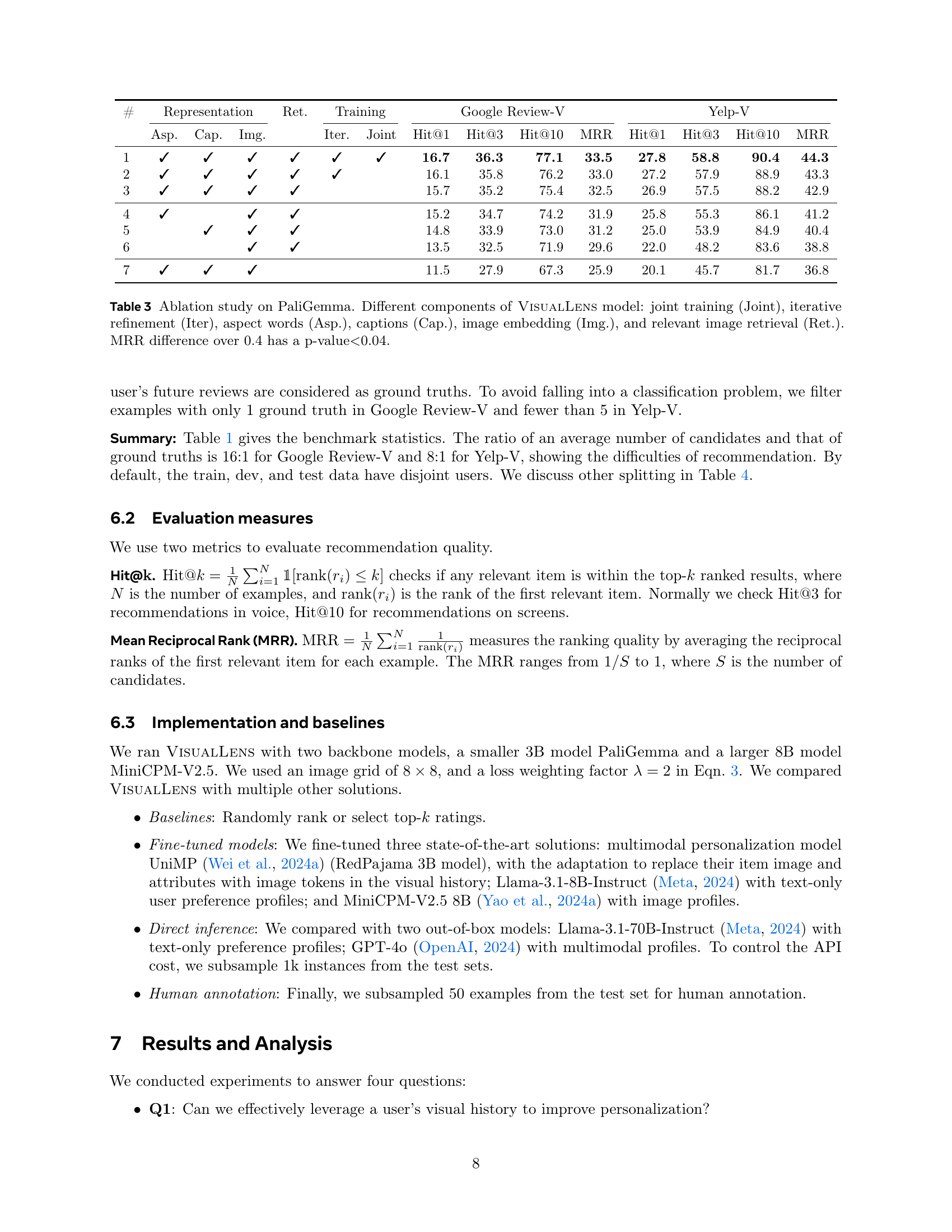
🔼 This figure displays the mean reciprocal rank (MRR) distribution across various categories for both Google Review-V and Yelp-V datasets. The left panel (a) shows the distribution for Google Review-V, while the right panel (b) shows the distribution for Yelp-V. The key observations are a loose correlation between the number of training examples per category and the MRR, and a tendency for more general, less ambiguous categories to achieve higher MRR scores.
read the caption
Figure 4: (a) MRR distribution over categories on Google Review-V, (b) MRR distribution over categories on Yelp-V. We find (1) the performance per category is loosely correlated with number of training data; (2) when a category is more general and less ambiguous, the performance on the category is better.

🔼 This bar chart visualizes the distribution of the 66 categories within the Google Review-Vision (GR-V) dataset used for training. The x-axis represents the different categories, and the y-axis shows the number of data points or instances belonging to each category. The chart provides insight into the class imbalance of the dataset, revealing which categories are more prevalent than others in the training data. This information is useful in understanding potential biases in the model’s training.
read the caption
Figure 5: The Google Review-Vision (Google Review-V) training data consists of 66 categories.
Full paper#