↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video-LLMs struggle with long videos due to context length limitations and memory issues, resulting in information loss and reduced relevance. Existing methods often rely on sparse sampling or compression, leading to inaccuracies.
This paper introduces SALOVA, a new framework that addresses these issues. SALOVA uses a targeted retrieval process, identifying and retrieving relevant video segments based on user queries. It also introduces SceneWalk, a large, high-quality dataset of densely-captioned long videos. Experiments show that SALOVA significantly improves contextual relevance and maintains contextual integrity across extended video sequences, outperforming existing methods on various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with long-form videos and large language models. It addresses the critical challenge of context limitations in LLMs, offering a novel solution that could significantly impact video analysis and retrieval systems. The dataset introduced will also be a valuable resource for future research in this area. The proposed framework provides a novel approach that improves understanding of long untrimmed videos, thus opening avenues for more efficient and effective processing of complex long video content.
Visual Insights#

🔼 Figure 1 provides a comprehensive overview of the SceneWalk dataset, a key component of the SALOVA framework. Panel (a) compares SceneWalk to other existing video-text datasets, highlighting its size and the length of video-text descriptions. Panel (b) presents detailed statistics of SceneWalk, including the distribution of videos across various categories and durations (represented by circle size and color intensity, respectively). Finally, panel (c) illustrates the pipeline used to annotate the dataset with segment-level descriptions and scores, outlining a multi-step process involving pre-trained models and manual curation.
read the caption
Figure 1: The overview of the SceneWalk dataset includes (a) dataset comparison, (b) detailed statistics, and (c) the annotation pipeline for description and score collection. Note that the scale of circles in Fig. 1(a) indicates the data size, and the color distribution in Fig. 1(b) denotes the video duration in each video category—brighter colors correspond to shorter video durations. Further details about the dataset are provided in Appendix A.
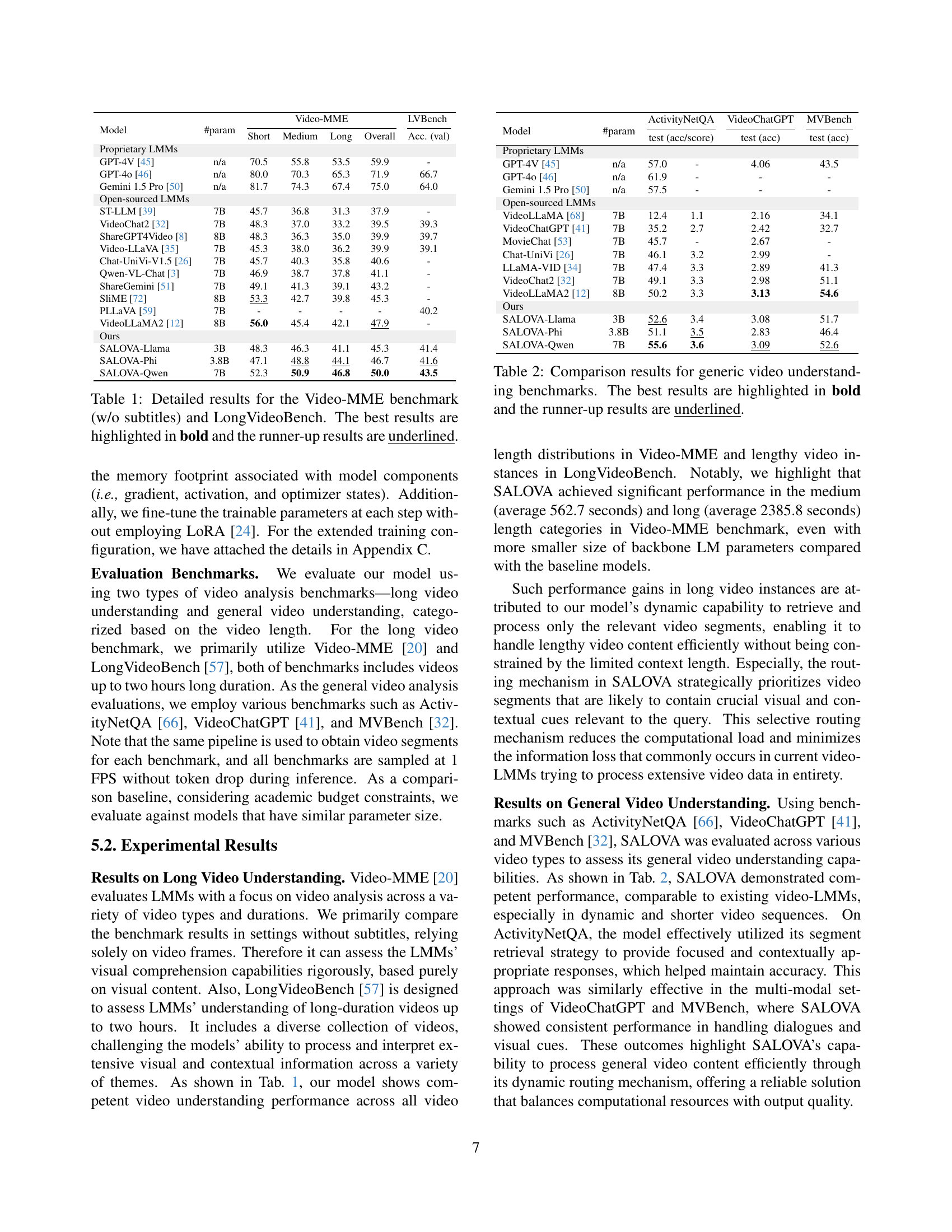
| Model | #param | Short | Medium | Long | Overall | Acc. (val) |
|---|---|---|---|---|---|---|
| Proprietary LMMs | ||||||
| GPT-4V [45] | n/a | 70.5 | 55.8 | 53.5 | 59.9 | - |
| GPT-4o [46] | n/a | 80.0 | 70.3 | 65.3 | 71.9 | 66.7 |
| Gemini 1.5 Pro [50] | n/a | 81.7 | 74.3 | 67.4 | 75.0 | 64.0 |
| Open-sourced LMMs | ||||||
| ST-LLM [39] | 7B | 45.7 | 36.8 | 31.3 | 37.9 | - |
| VideoChat2 [32] | 7B | 48.3 | 37.0 | 33.2 | 39.5 | 39.3 |
| ShareGPT4Video [8] | 8B | 48.3 | 36.3 | 35.0 | 39.9 | 39.7 |
| Video-LLaVA [35] | 7B | 45.3 | 38.0 | 36.2 | 39.9 | 39.1 |
| Chat-UniVi-V1.5 [26] | 7B | 45.7 | 40.3 | 35.8 | 40.6 | - |
| Qwen-VL-Chat [3] | 7B | 46.9 | 38.7 | 37.8 | 41.1 | - |
| ShareGemini [51] | 7B | 49.1 | 41.3 | 39.1 | 43.2 | - |
| SliME [72] | 8B | 53.3 | 42.7 | 39.8 | 45.3 | - |
| PLLaVA [59] | 7B | - | - | - | - | 40.2 |
| VideoLLaMA2 [12] | 8B | 56.0 | 45.4 | 42.1 | 47.9 | - |
| Ours | ||||||
| SALOVA-Llama | 3B | 48.3 | 46.3 | 41.1 | 45.3 | 41.4 |
| SALOVA-Phi | 3.8B | 47.1 | 48.8 | 44.1 | 46.7 | 41.6 |
| SALOVA-Qwen | 7B | 52.3 | 50.9 | 46.8 | 50.0 | 43.5 |
🔼 Table 1 presents a detailed comparison of the performance of various models on two video understanding benchmarks: Video-MME (without subtitles) and LongVideoBench. The benchmarks assess models’ ability to understand videos of varying lengths, from short clips to very long videos. For each benchmark and video length category (short, medium, long), the table shows the accuracy or score achieved by several different models. The best-performing model for each category is highlighted in bold, and the second-best is underlined. This allows for a direct comparison of model performance across different video lengths and benchmark types.
read the caption
Table 1: Detailed results for the Video-MME benchmark (w/o subtitles) and LongVideoBench. The best results are highlighted in bold and the runner-up results are underlined.
In-depth insights#
Long Video Challenge#
The “Long Video Challenge” highlights the limitations of current large language models (LLMs) and large multimodal models (LMMs) when processing long-form videos. Existing models struggle with the extensive temporal context and high memory demands inherent in lengthy video sequences. This results in substantial information loss, impacting the accuracy and relevance of generated responses. Efficiently handling long videos requires addressing context window limitations within LLMs, as well as managing the significant memory overhead associated with processing large amounts of visual data. Therefore, innovative solutions are needed, such as selective retrieval of key video segments and employing dynamic routing mechanisms to focus processing on relevant information. These techniques aim to improve contextual understanding and reduce computational complexity, thereby enhancing the overall performance and capability of video-LLM systems.
SALOVA Framework#
The SALOVA framework represents a novel approach to long-form video analysis, addressing the limitations of existing video-LLMs in handling extended sequences. Its core innovation lies in a targeted retrieval process, using a dynamic routing mechanism to select and process only the most relevant video segments for a given query. This approach significantly mitigates the issues of context length restrictions and substantial memory overhead inherent in traditional LMMs. SALOVA integrates a spatio-temporal projector and a segment retrieval router, effectively connecting relevant segments with an LLMs for enhanced comprehension. The framework’s architecture, combined with the SceneWalk dataset (which offers densely captioned long videos), allows for precise contextual relevance in generated responses. The FocusFast pathway further enhances this capability, focusing on relevant details while maintaining global contextual awareness. In essence, SALOVA offers a more efficient and accurate method for understanding complex long-form videos by prioritizing pertinent information, improving both performance and resource efficiency.
SceneWalk Dataset#
The SceneWalk dataset represents a significant contribution to the field of long-form video understanding. Its high-quality, densely-captioned nature directly addresses the limitations of existing datasets, providing rich contextual information crucial for training robust video-LLMs. The dataset’s focus on untrimmed, long videos with frequent scene transitions mirrors real-world scenarios, improving model generalization capabilities. The meticulous annotation process, combining automatic generation with manual curation, ensures accuracy and detail in the segment-level descriptions. This comprehensive annotation is key for the success of the paper’s proposed model, SALOVA, which leverages these detailed descriptions to retrieve relevant video segments efficiently. By using SceneWalk, researchers can move beyond the limitations of short, trimmed videos and advance the state-of-the-art in long-form video analysis.
FocusFast Routing#
The concept of “FocusFast Routing” in the context of long-form video analysis is intriguing. It suggests a dual-pathway approach to processing lengthy video sequences. The “Focus” pathway would concentrate on detailed analysis of specifically retrieved segments, maximizing the information extracted from the most relevant parts of the video. This is particularly valuable for long videos which might contain numerous irrelevant or unimportant segments. Conversely, the “Fast” pathway might process the entire video using techniques such as efficient frame sampling or other summarization methods, allowing the model to retain a comprehensive overview of the video’s context. The integration of these two pathways allows the model to balance detailed analysis with contextual understanding, thereby addressing the inherent challenges in processing untrimmed videos. Such a strategy would likely involve sophisticated video retrieval techniques to identify the most relevant segments for a specific query, coupled with dynamic routing mechanisms that efficiently manage attention between the detailed “Focus” and broad “Fast” processing paths. This approach would improve the accuracy and relevance of model responses while minimizing computational costs associated with processing lengthy video data. Further, the effectiveness of this approach likely hinges on the quality of the video captioning and segmentation, necessitating a robust and comprehensive video dataset for training. Careful consideration of the weighting and interaction between these two pathways is critical to the success of the overall approach. A critical consideration here is finding the optimal balance between the focus pathway’s detailed examination and the fast pathway’s efficient overview; too much emphasis on either could lead to bias or omission of crucial information.
Future of Video LLMs#
The future of Video LLMs hinges on addressing current limitations and exploring new avenues. Context length remains a significant bottleneck, necessitating more efficient architectures and memory management techniques. Improved data is crucial, especially large-scale datasets with rich, dense annotations capturing both fine-grained visual details and broader narrative context. This will enable models to understand complex scenarios and nuances within longer videos more effectively. Efficient retrieval methods are vital for handling long video sequences, directing the model’s focus towards relevant segments for improved response accuracy and reduced computational cost. Future research may benefit from incorporating multi-modal fusion techniques beyond vision and language, integrating audio and other modalities for a holistic comprehension of video content. Finally, robust benchmarks and evaluation metrics are needed to accurately assess and compare the advancements in Video LLMs, paving the way for more reliable and sophisticated video understanding systems.
More visual insights#
More on figures

🔼 Figure 2 presents a detailed architecture diagram of SALOVA, a framework designed for understanding long-form videos. It highlights the four main components: a Vision Encoder that processes video frames, a Spatio-Temporal (ST) Connector that converts the video features into fixed-size representations for efficient processing, a Segment Retrieval Router (SR-Router) that selects relevant video segments based on user queries, and finally, Large Language Models (LLMs) that generate responses. The diagram also illustrates the FocusFast strategy, a key element in SALOVA’s design. FocusFast enables the model to focus on detailed information within selected segments (focus pathway) while maintaining an overall understanding of the entire video through the use of routing tokens (fast pathway). This allows for a more comprehensive analysis of long videos, resolving issues associated with limited context windows in traditional video-LLM architectures.
read the caption
Figure 2: The network overview of SALOVA. Our framework consists of four structural components: vision encoder, ST-connector, SR-router, and LLMs. Using the FocusFast strategy, our model can concentrate on more detailed local information while maintaining context awareness.

🔼 Figure 3 presents a comparative analysis of the Visual Needle-In-A-Haystack (V-NIAH) task, assessing the performance of the proposed SALOVA model against a baseline. The x-axis represents the total number of frames in the video, and the y-axis indicates the location of the target ’needle’ image within the video sequence. The heatmaps likely show the model’s ability to correctly locate the needle image, with warmer colors signifying better performance. The comparison highlights the efficacy of SALOVA’s targeted retrieval approach, contrasting its accuracy in identifying the needle against a method using a simpler, less focused approach.
read the caption
Figure 3: Comparison results of V-NIAH. The x/y-axis indicates the total video frames and the location of needle image within the video, respectively.

🔼 This figure presents a bar chart visualizing the distribution of video durations across different categories within the SceneWalk dataset. The x-axis represents the ten video categories included in the dataset, and the y-axis shows the number of videos within each category. Each category is further broken down into three duration ranges: 0-240 seconds, 240-600 seconds, and 600-2280 seconds. The bars for each category visually represent the frequency of videos falling into each duration range, providing insights into the temporal characteristics and diversity of the SceneWalk dataset.
read the caption
Figure 4: Detailed video duration range statistics for each video category in the SceneWalk dataset.

🔼 This word cloud visualizes the most frequent keywords appearing in the SceneWalk dataset’s video segment descriptions. It highlights the dataset’s focus on human-centric scenes, detailed descriptions of actions and interactions (e.g., ‘person’, ‘man’, ‘woman’, ‘smiling’, ‘group’, ‘standing’, ‘holding’, ‘wearing’), and environmental details (‘room’, ’table’, ‘building’, ‘street’). The presence of terms like ‘ground shot’, ‘side view’, and ‘close-up’ indicates a variety of camera angles used in the source videos. The overall impression is that the SceneWalk dataset emphasizes descriptive captions encompassing both detailed human activities and the surrounding environment.
read the caption
Figure 5: WordCloud analysis of the SceneWalk dataset.

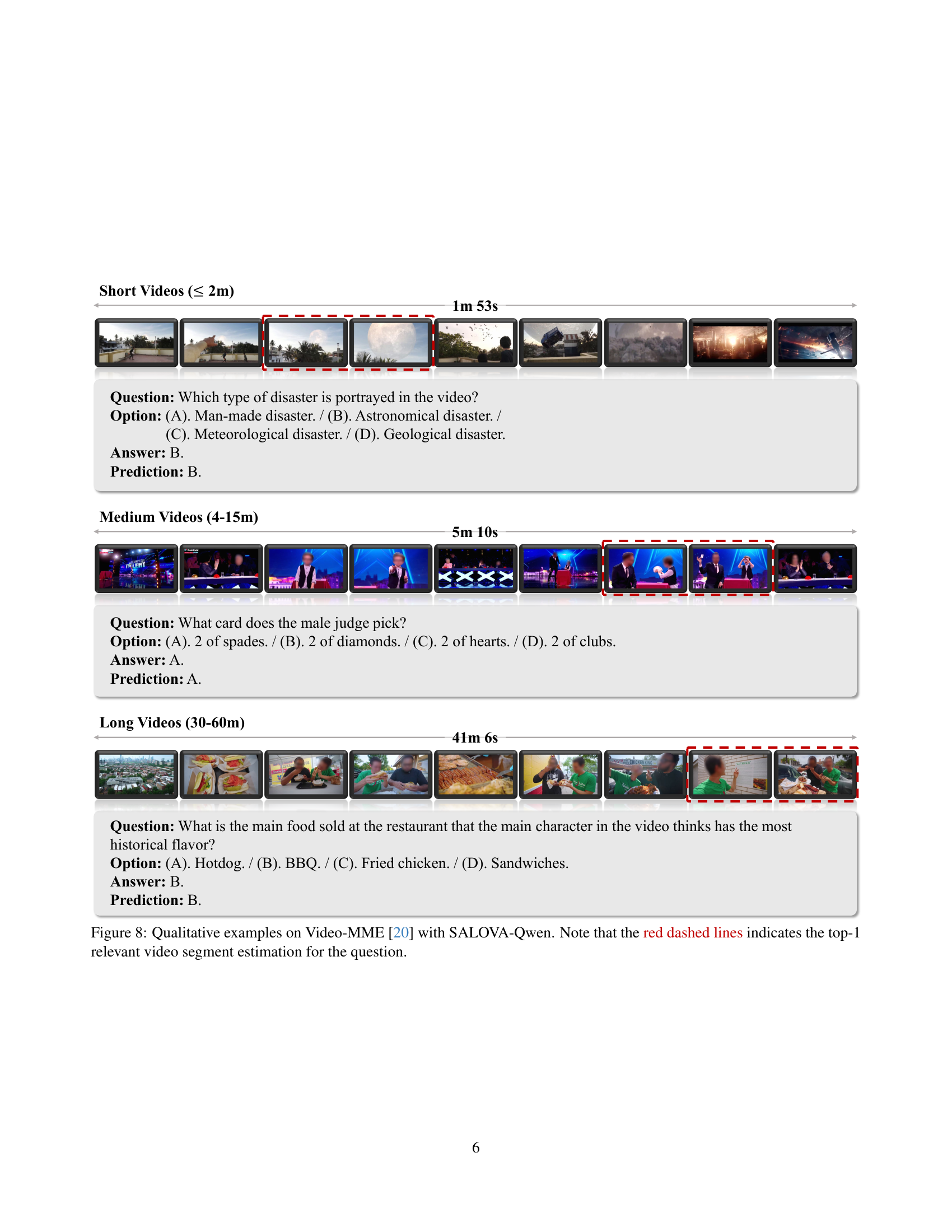
🔼 Figure 6 presents examples from the SceneWalk dataset, showcasing the diverse video segments and their corresponding detailed captions. Each example includes a short video clip, a timestamp indicating the segment duration, and a comprehensive description of the segment’s visual and narrative content. These captions, generated using a combination of pre-trained models and manual annotation, illustrate the dataset’s high quality and its ability to capture scene continuity and rich contextual information across a variety of long videos. This is a key aspect of the dataset’s design, which supports fine-grained analysis and understanding of extended video sequences.
read the caption
Figure 6: Examples of the SceneWalk dataset (i).
More on tables
| Model | #param | ActivityNetQA (acc/score) | VideoChatGPT (acc) | MVBench (acc) | |
|---|---|---|---|---|---|
Proprietary LMMs | |||||
| GPT-4V [45] | n/a | 57.0 | - | 4.06 | 43.5 |
| GPT-4o [46] | n/a | 61.9 | - | - | - |
| Gemini 1.5 Pro [50] | n/a | 57.5 | - | - | - |
Open-sourced LMMs | |||||
| VideoLLaMA [68] | 7B | 12.4 | 1.1 | 2.16 | 34.1 |
| VideoChatGPT [41] | 7B | 35.2 | 2.7 | 2.42 | 32.7 |
| MovieChat [53] | 7B | 45.7 | - | 2.67 | - |
| Chat-UniVi [26] | 7B | 46.1 | 3.2 | 2.99 | - |
| LLaMA-VID [34] | 7B | 47.4 | 3.3 | 2.89 | 41.3 |
| VideoChat2 [32] | 7B | 49.1 | 3.3 | 2.98 | 51.1 |
| VideoLLaMA2 [12] | 8B | 50.2 | 3.3 | 3.13 | 54.6 |
Ours | |||||
| SALOVA-Llama | 3B | 52.6 | 3.4 | 3.08 | 51.7 |
| SALOVA-Phi | 3.8B | 51.1 | 3.5 | 2.83 | 46.4 |
| SALOVA-Qwen | 7B | 55.6 | 3.6 | 3.09 | 52.6 |
🔼 Table 2 presents a comparison of the performance of different models on general video understanding benchmarks. It shows the results across various models, indicated by their names and number of parameters, on the metrics used to evaluate their ability to understand videos. The table highlights the best-performing model for each benchmark in bold and underlines the second-best performing model, providing a clear indication of relative performance across models and benchmarks.
read the caption
Table 2: Comparison results for generic video understanding benchmarks. The best results are highlighted in bold and the runner-up results are underlined.
| Ablation | Video-MME | Video-MME | Video-MME | Video-MME |
|---|---|---|---|---|
| Short: ≤2m | Mid: 4-15m | Long: 30-60m | Overall | |
| frm sample: Video frame sampling (w/o SR-Router) | ||||
| 8 frm | 48.3 | 42.0 | 37.2 | 42.5 |
| 16 frm | 50.0 | 42.8 | 38.0 | 43.6 |
| 1 fps | 48.3 | 46.3 | 41.1 | 45.3 |
| 1 / 1.5 / 2: Train stage - Long video knowledge injection | ||||
| ✓ ✗ ✓ | 45.6 | 43.7 | 40.2 | 43.6 |
| ✓ ✓ ✓ | 48.3 | 46.3 | 41.1 | 45.3 |
| FastFocs: Local-global video representation | ||||
| ✗ | 36.4 | 38.6 | 35.6 | 36.9 |
| ✓ | 48.3 | 46.3 | 41.1 | 45.3 |
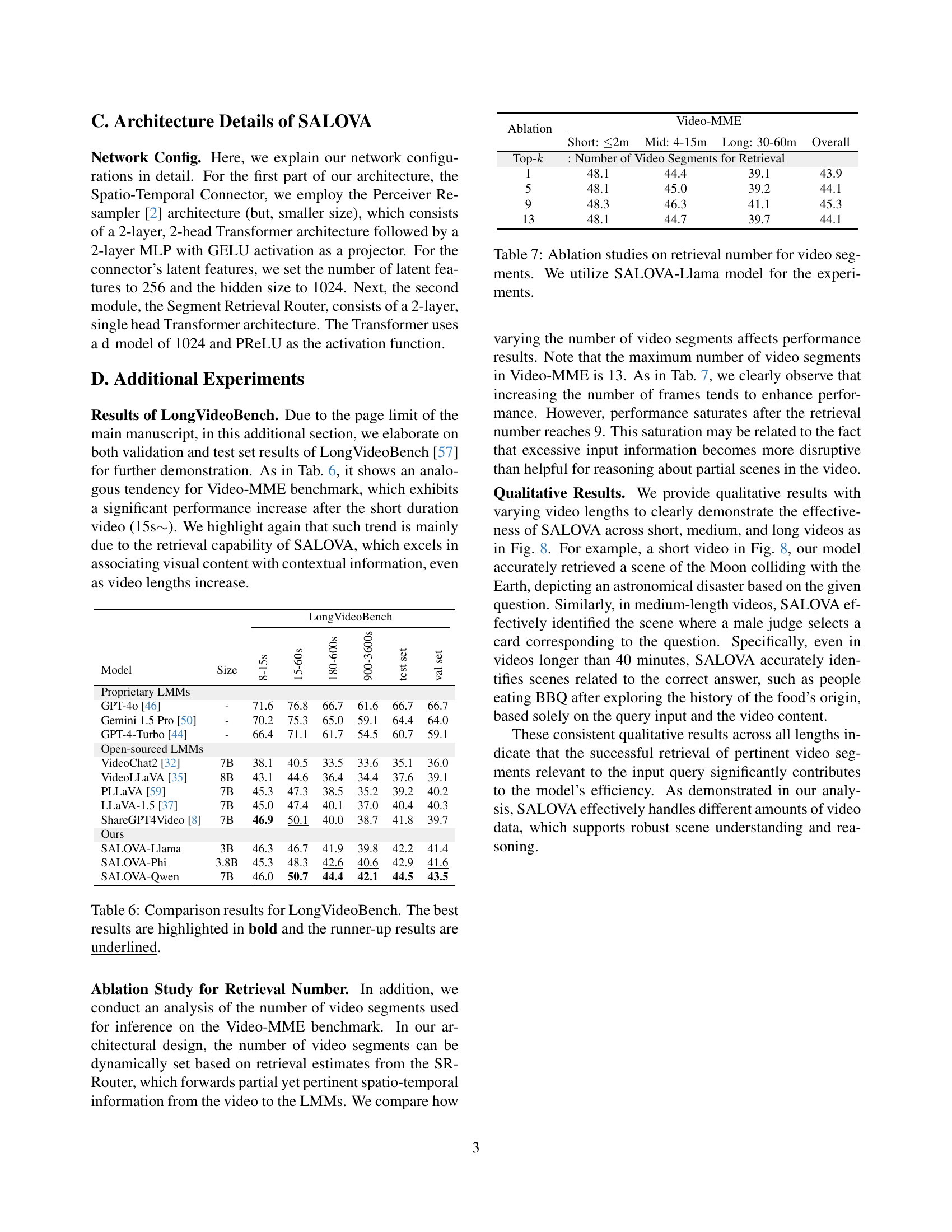
🔼 This ablation study investigates the impact of different design choices within the SALOVA framework on its performance. Specifically, it examines the effects of varying the frame sampling strategy (different numbers of frames sampled from the video), removing the intermediate training stage that incorporates long video knowledge from the SceneWalk dataset, and disabling the FocusFast mechanism (which integrates both local and global video representations). The results, obtained using the SALOVA-Llama model, show the contribution of each component to the overall performance, allowing for a better understanding of which design aspects are crucial for effective long-video understanding.
read the caption
Table 3: Ablation studies on SALOVA configuration. We utilize SALOVA-Llama model for the experiments.
| config | Stage1 | Stage1.5 | Stage2 |
|---|---|---|---|
| input modality | image, video | video | video |
| input frame | 1 FPS | 1 FPS | 1 FPS |
| input resolution | 336 × 336 | 336 × 336 | 336 × 336 |
| optimizer | AdamW (β₁β₂=0.9,0.999) | AdamW (β₁β₂=0.9,0.999) | AdamW (β₁β₂=0.9,0.999) |
| lr schedule | cosine decay | cosine decay | cosine decay |
| training precision | BFloat16 | BFloat16 | BFloat16 |
| DeepSpeed train | ZeRO-2 | ZeRO-2 | ZeRO-2 |
| warmup epochs | 0.03 | 0.03 | 0.03 |
| trainable params | connectors | full | full |
| lr_{vision, text} | - | 2e-6 | 2e-6 |
| lr_{LLM, others} | 1e-3 | 2e-5 | 2e-5 |
| global batch size | 256 | 8 | 64 |
| total epochs | 1 | 1 | 1 |
| Max token drop | 0.0 | 0.7 | 0.4 |
🔼 Table 5 presents the hyperparameters used during the three training stages of the SALOVA model. The three stages are: cross-modality alignment, long video knowledge injection, and video instruction tuning. The table details the input modality (image and video), input frame rate (FPS), resolution, optimizer, learning rate schedule, precision, DeepSpeed settings, learning rate for different model components, global batch size, total number of training epochs, maximum token dropout rate, and which model components are trained in each stage. Specifically, the ‘connectors’ column indicates whether the SR-Router and ST-Connector components are fully trained (full) or not during each stage.
read the caption
Table 5: Training hyper-parameters for different stages. Here, connectors indicates SR-Router and ST-Connector
| Model | Size | 8-15s | 15-60s | 180-600s | 900-3600s | test set | val set |
|---|---|---|---|---|---|---|---|
| Proprietary LMMs | |||||||
| GPT-4o [46] | - | 71.6 | 76.8 | 66.7 | 61.6 | 66.7 | 66.7 |
| Gemini 1.5 Pro [50] | - | 70.2 | 75.3 | 65.0 | 59.1 | 64.4 | 64.0 |
| GPT-4-Turbo [44] | - | 66.4 | 71.1 | 61.7 | 54.5 | 60.7 | 59.1 |
| Open-sourced LMMs | |||||||
| VideoChat2 [32] | 7B | 38.1 | 40.5 | 33.5 | 33.6 | 35.1 | 36.0 |
| VideoLLaVA [35] | 8B | 43.1 | 44.6 | 36.4 | 34.4 | 37.6 | 39.1 |
| PLLaVA [59] | 7B | 45.3 | 47.3 | 38.5 | 35.2 | 39.2 | 40.2 |
| LLaVA-1.5 [37] | 7B | 45.0 | 47.4 | 40.1 | 37.0 | 40.4 | 40.3 |
| ShareGPT4Video [8] | 7B | 46.9 | 50.1 | 40.0 | 38.7 | 41.8 | 39.7 |
| Ours | |||||||
| SALOVA-Llama | 3B | 46.3 | 46.7 | 41.9 | 39.8 | 42.2 | 41.4 |
| SALOVA-Phi | 3.8B | 45.3 | 48.3 | 42.6 | 40.6 | 42.9 | 41.6 |
| SALOVA-Qwen | 7B | 46.0 | 50.7 | 44.4 | 42.1 | 44.5 | 43.5 |
🔼 Table 6 presents a comparison of results on the LongVideoBench benchmark for video understanding. It shows the performance of various models, including proprietary Large Multi-modal Models (LMMs) and open-sourced LMMs, across different video lengths (8-15s, 15-60s, 180-600s, and 900-3600s). The table highlights the best performing model in bold and the second-best performing model with an underline for each video length category, both on the validation set and the test set. This allows for a direct comparison of the different models’ abilities to understand videos of various durations.
read the caption
Table 6: Comparison results for LongVideoBench. The best results are highlighted in bold and the runner-up results are underlined.
| Ablation | Video-MME | ||||
|---|---|---|---|---|---|
| Short: ≤2m | Mid: 4-15m | Long: 30-60m | Overall | ||
| Top-k: Number of Video Segments for Retrieval | |||||
| 1 | 48.1 | 44.4 | 39.1 | 43.9 | |
| 5 | 48.1 | 45.0 | 39.2 | 44.1 | |
| 9 | 48.3 | 46.3 | 41.1 | 45.3 | |
| 13 | 48.1 | 44.7 | 39.7 | 44.1 |
🔼 This ablation study investigates the impact of varying the number of retrieved video segments on the performance of the SALOVA model. Specifically, it examines how changing the top-k parameter (the number of segments selected by the Segment Retrieval Router) affects the model’s ability to correctly answer questions across different video lengths (short, medium, and long). The experiment uses the SALOVA-Llama model, evaluating performance on the Video-MME benchmark.
read the caption
Table 7: Ablation studies on retrieval number for video segments. We utilize SALOVA-Llama model for the experiments.
Full paper#