↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) are becoming increasingly complex, demanding massive computational resources and energy. Mixture-of-Experts (MoE) models offer a way to scale LLMs more efficiently by dynamically routing inputs to specialized sub-networks (experts), but existing MoE models often face limitations in computational efficiency and scalability. This presents a challenge, as researchers aim to create even bigger and better models.
This paper introduces a new approach called Multi-Head Mixture-of-Experts (MH-MoE) to overcome these limitations. MH-MoE uses a multi-head mechanism to improve efficiency and enhance performance compared to traditional MoE models. The researchers show that their new method works well even with 1-bit LLMs (a highly compressed model format), paving the way for even more efficient and practical large-scale language models. Experiments demonstrate that MH-MoE surpasses existing MoE methods in quality while maintaining the same computational cost.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel implementation of Multi-Head Mixture-of-Experts (MH-MoE) that significantly improves efficiency and performance in large language models. It addresses the challenge of scaling up language models while maintaining computational efficiency, a key issue in current research. The proposed MH-MoE architecture is shown to be compatible with 1-bit LLMs, opening new avenues for efficient and cost-effective model deployment. The findings contribute to ongoing research in model scaling and efficient training, offering practical guidance for researchers working on large-scale language models and related applications.
Visual Insights#
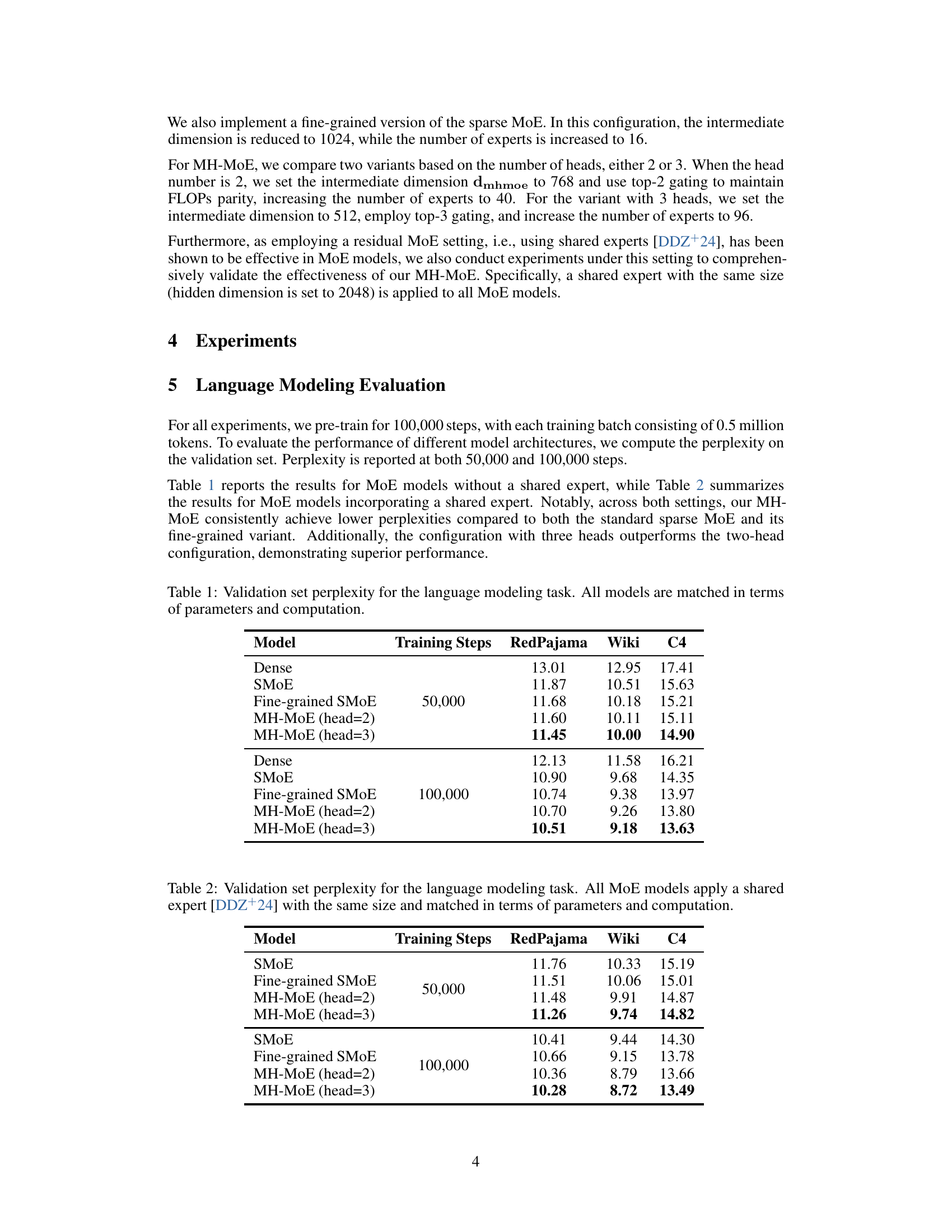
| Model | Training Steps | RedPajama | Wiki | C4 |
|---|---|---|---|---|
| Dense | 50,000 | 13.01 | 12.95 | 17.41 |
| SMoE | 50,000 | 11.87 | 10.51 | 15.63 |
| Fine-grained SMoE | 50,000 | 11.68 | 10.18 | 15.21 |
| MH-MoE (head=2) | 50,000 | 11.60 | 10.11 | 15.11 |
| MH-MoE (head=3) | 50,000 | 11.45 | 10.00 | 14.90 |
| Dense | 100,000 | 12.13 | 11.58 | 16.21 |
| SMoE | 100,000 | 10.90 | 9.68 | 14.35 |
| Fine-grained SMoE | 100,000 | 10.74 | 9.38 | 13.97 |
| MH-MoE (head=2) | 100,000 | 10.70 | 9.26 | 13.80 |
| MH-MoE (head=3) | 100,000 | 10.51 | 9.18 | 13.63 |
🔼 This table presents the validation set perplexity results for various language models evaluated on the language modeling task. The models compared include a dense model, a standard sparse Mixture-of-Experts (MoE) model, a fine-grained version of the sparse MoE model, and several variants of the Multi-Head Mixture-of-Experts (MH-MoE) model. Importantly, all models in this table were designed and trained to have the same number of parameters and computational costs for a fair comparison. The results are shown for two different training step counts (50,000 and 100,000) and across three different datasets (RedPajama, Wiki, C4), providing a comprehensive evaluation of the models’ performance.
read the caption
Table 1: Validation set perplexity for the language modeling task. All models are matched in terms of parameters and computation.
In-depth insights#
MH-MoE: A Deep Dive#
A deep dive into Multi-Head Mixture-of-Experts (MH-MoE) would reveal its innovative approach to scaling large language models. MH-MoE enhances the standard Mixture-of-Experts (MoE) architecture by incorporating a multi-head mechanism, allowing for the collective attention to information from diverse expert representation spaces. This design is crucial for improving efficiency and performance. A key advantage lies in its ability to maintain FLOPs and parameter parity with sparse MoE models, achieving significant scaling without an exponential increase in computational cost. This is done by carefully controlling the intermediate dimension and the number of experts. Through careful parameter tuning and architectural design, MH-MoE demonstrates quality improvements over both vanilla MoE and fine-grained MoE models, showing its effectiveness in various language modeling tasks. Furthermore, its compatibility with 1-bit LLMs like BitNet opens possibilities for even more efficient deployment and resource optimization, highlighting its potential for future advancements in large-scale language modeling.
FLOPs Parity Focus#
The concept of ‘FLOPs Parity Focus’ in the context of a research paper on Mixture-of-Experts (MoE) models highlights a crucial efficiency trade-off. The goal is to achieve performance gains from the enhanced expressiveness of MoE architectures without the associated significant increase in computational cost (FLOPs). This is particularly important for scaling up models to extremely large sizes, where excessive FLOPs can render models impractical for deployment. Therefore, the research likely investigates techniques for parameter and FLOP optimization in MH-MoE (Multi-Head Mixture-of-Experts) models, comparing them against standard sparse MoE (Sparse Mixture-of-Experts) models. The focus might involve clever gating mechanisms to select only the necessary expert networks per input token, head layer and merge layer designs to optimize information flow, and other architectural choices that promote computational efficiency. The research likely demonstrates that MH-MoE can achieve comparable or even superior performance to sparse MoE models while maintaining the same FLOPs count, addressing the scalability concerns of large language models. Successfully achieving FLOPs parity is a significant contribution as it allows the benefits of MoE models (increased capacity and expressiveness) to be realized without the penalties of increased computational cost. A key takeaway will be demonstrating that this parity can be reached while also enhancing performance through mechanisms like multi-head attention and effective expert selection strategies.
1-Bit LLM Synergy#
The concept of ‘1-Bit LLM Synergy’ is intriguing, suggesting a potential paradigm shift in large language model (LLM) efficiency and deployment. It explores the intersection of highly efficient 1-bit LLMs, exemplified by BitNet, with the architectural advantages of Multi-Head Mixture-of-Experts (MH-MoE). The synergy lies in the ability of MH-MoE’s parameter and FLOP efficiency to complement 1-bit quantization’s significant memory and computational savings. By combining these two techniques, the expectation would be to create LLMs that achieve state-of-the-art performance with drastically reduced resource demands, potentially enabling widespread deployment of previously intractable models. A critical aspect to investigate would be the extent to which the 1-bit quantization affects the performance gains delivered by the MH-MoE architecture and whether any specialized training or optimization techniques are necessary to mitigate potential negative impacts on model accuracy. Successfully achieving synergy could represent a major breakthrough, making powerful LLMs accessible even on resource-constrained devices, opening exciting new opportunities for applications like edge computing and personalized AI. However, challenges remain regarding the potential trade-offs between model performance and reduced precision; a thorough evaluation comparing 1-bit MH-MoE against higher precision baselines is crucial to fully assess the practical value of this approach.
Ablation Study#
An ablation study for a Multi-Head Mixture-of-Experts (MH-MoE) model would systematically remove components to understand their individual contributions. The core focus would be on the head and merge layers, inspired by the multi-head attention mechanism. Removing these layers separately, while controlling for scalar multiplications (FLOPs), would reveal their impact on model performance. The head layer’s role in query, key, and value projections, and the merge layer’s role in output projection, are crucial aspects to analyze. A comparison between baseline SMoE and MH-MoE models, both with and without the head/merge layers, would highlight the unique advantages of MH-MoE. The results would likely show that, while both layers offer improvements, the head layer is more impactful, providing a significant performance boost. This finding would confirm the importance of the proposed multi-head mechanism in enhancing the MH-MoE’s effectiveness compared to a standard SMoE architecture.
Future Directions#
Future research could explore several promising avenues. Improving the gating mechanism is crucial; current methods might not optimally route tokens, leading to suboptimal expert utilization. Investigating alternative gating strategies, perhaps incorporating attention mechanisms or learned routing policies, could significantly enhance performance. Furthermore, exploring different expert architectures beyond standard feed-forward networks warrants investigation. Specialized experts tailored to specific tasks or data modalities could improve overall model efficiency and accuracy. Scaling to even larger models remains a key challenge. Addressing the computational demands and potential communication bottlenecks inherent in extremely large MoE models requires innovative approaches in distributed training and hardware optimization. Finally, deeper theoretical analysis is needed to understand the behavior and limitations of MH-MoE, especially concerning its convergence properties, generalization capabilities, and robustness to noise or adversarial attacks. This deeper understanding is critical for developing more reliable and efficient training methods.
More visual insights#
More on tables
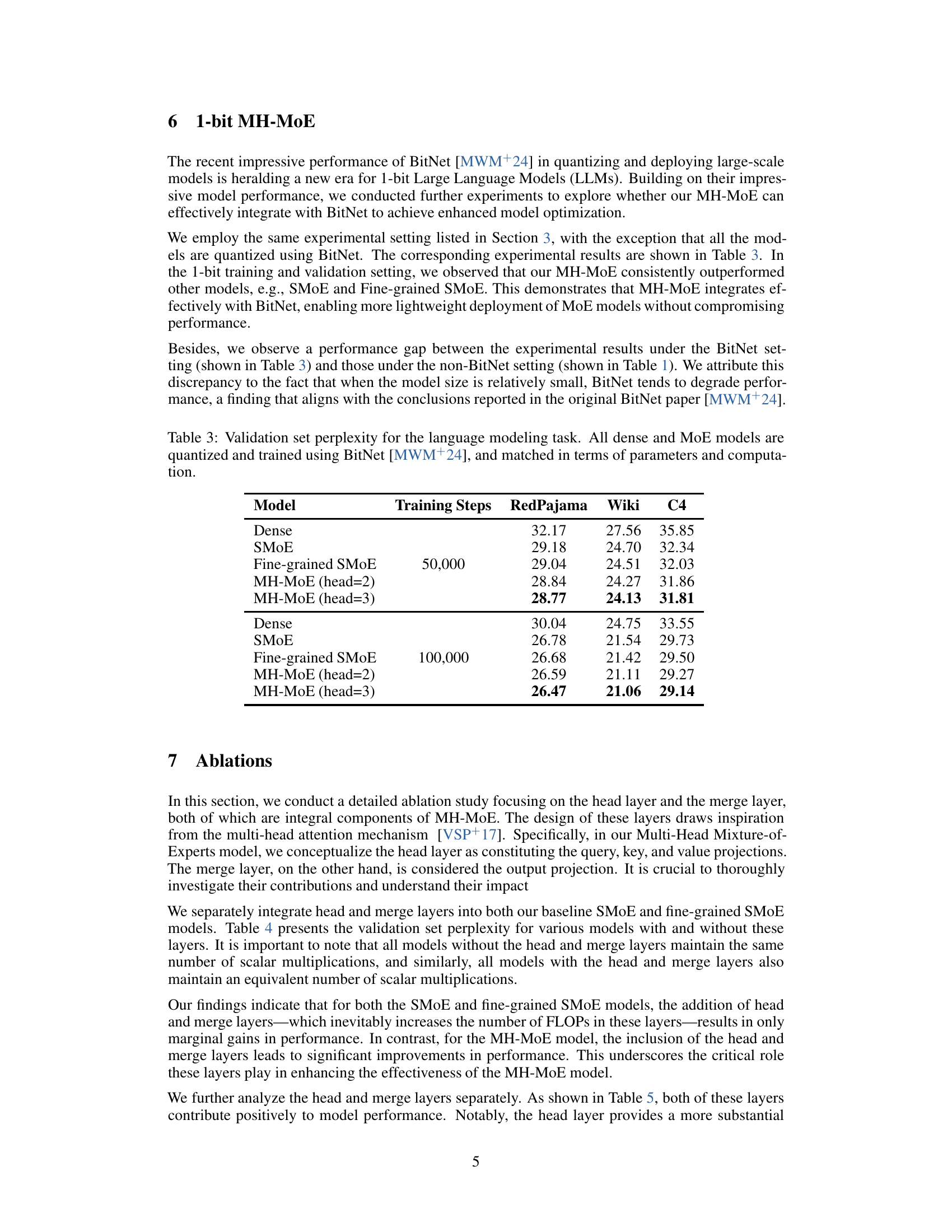
| Model | Training Steps | RedPajama | Wiki | C4 |
|---|---|---|---|---|
| SMoE | 50,000 | 11.76 | 10.33 | 15.19 |
| Fine-grained SMoE | 11.51 | 10.06 | 15.01 | |
| MH-MoE (head=2) | 11.48 | 9.91 | 14.87 | |
| MH-MoE (head=3) | 11.26 | 9.74 | 14.82 | |
| SMoE | 100,000 | 10.41 | 9.44 | 14.30 |
| Fine-grained SMoE | 10.66 | 9.15 | 13.78 | |
| MH-MoE (head=2) | 10.36 | 8.79 | 13.66 | |
| MH-MoE (head=3) | 10.28 | 8.72 | 13.49 |
🔼 This table presents the validation set perplexity results for various language models on the RedPajama, Wiki, and C4 datasets. All Mixture-of-Experts (MoE) models in this experiment utilize a shared expert layer, as described in reference [4], with consistent model sizes and computational costs. The results compare the standard Sparse MoE, a fine-grained version of Sparse MoE, and the Multi-Head Mixture-of-Experts (MH-MoE) model with two and three heads. The perplexity is measured after 50,000 and 100,000 training steps to show the effect of training time on performance.
read the caption
Table 2: Validation set perplexity for the language modeling task. All MoE models apply a shared expert [4] with the same size and matched in terms of parameters and computation.
| Model | Training Steps | RedPajama | Wiki | C4 |
|---|---|---|---|---|
| Dense | 50,000 | 32.17 | 27.56 | 35.85 |
| SMoE | 50,000 | 29.18 | 24.70 | 32.34 |
| Fine-grained SMoE | 50,000 | 29.04 | 24.51 | 32.03 |
| MH-MoE (head=2) | 50,000 | 28.84 | 24.27 | 31.86 |
| MH-MoE (head=3) | 50,000 | 28.77 | 24.13 | 31.81 |
| Dense | 100,000 | 30.04 | 24.75 | 33.55 |
| SMoE | 100,000 | 26.78 | 21.54 | 29.73 |
| Fine-grained SMoE | 100,000 | 26.68 | 21.42 | 29.50 |
| MH-MoE (head=2) | 100,000 | 26.59 | 21.11 | 29.27 |
| MH-MoE (head=3) | 100,000 | 26.47 | 21.06 | 29.14 |
🔼 This table presents the validation set perplexity results for various language models evaluated on the RedPajama, Wiki, and C4 datasets. All models in this experiment have been quantized and trained using the BitNet method, ensuring a fair comparison in terms of parameters and computational requirements. The models compared include dense models and several Mixture-of-Experts (MoE) architectures, offering insights into the performance of different model designs in a quantized setting.
read the caption
Table 3: Validation set perplexity for the language modeling task. All dense and MoE models are quantized and trained using BitNet [9], and matched in terms of parameters and computation.
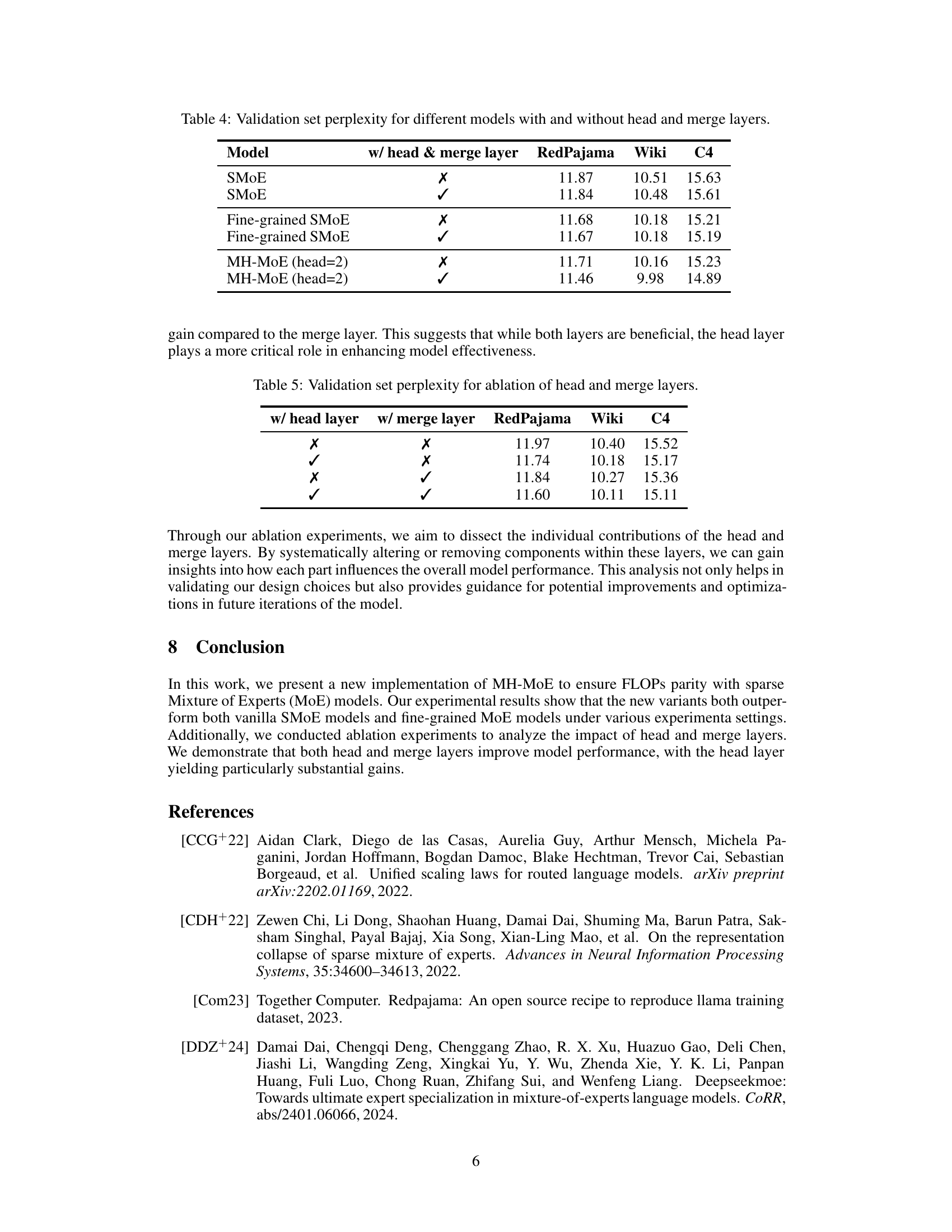
| Model | w/ head & merge layer | RedPajama | Wiki | C4 |
|---|---|---|---|---|
| SMoE | ✗ | 11.87 | 10.51 | 15.63 |
| SMoE | ✓ | 11.84 | 10.48 | 15.61 |
| Fine-grained SMoE | ✗ | 11.68 | 10.18 | 15.21 |
| Fine-grained SMoE | ✓ | 11.67 | 10.18 | 15.19 |
| MH-MoE (head=2) | ✗ | 11.71 | 10.16 | 15.23 |
| MH-MoE (head=2) | ✓ | 11.46 | 9.98 | 14.89 |
🔼 This table presents the validation set perplexity achieved by different language models on the RedPajama, Wiki, and C4 datasets. The models are categorized by whether they include a head layer and a merge layer. The purpose is to show the impact of these layers on model performance for various Sparse Mixture-of-Experts (SMoE) and Multi-Head Mixture-of-Experts (MH-MoE) architectures. The results demonstrate the importance of these layers, especially for MH-MoE, in improving model accuracy.
read the caption
Table 4: Validation set perplexity for different models with and without head and merge layers.
| w/ head layer | w/ merge layer | RedPajama | Wiki | C4 |
|---|---|---|---|---|
| ✗ | ✗ | 11.97 | 10.40 | 15.52 |
| ✓ | ✗ | 11.74 | 10.18 | 15.17 |
| ✗ | ✓ | 11.84 | 10.27 | 15.36 |
| ✓ | ✓ | 11.60 | 10.11 | 15.11 |
🔼 This table presents the results of ablation experiments, evaluating the impact of removing either the head layer or the merge layer (or both) from the MH-MoE model. It shows the validation set perplexity on the RedPajama, Wiki, and C4 datasets for different model configurations. This allows for assessment of the individual contribution of each layer to overall model performance.
read the caption
Table 5: Validation set perplexity for ablation of head and merge layers.
Full paper#