↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current diffusion models often excel in specific tasks (like text-to-image) but lack versatility and efficiency in handling diverse image generation and understanding tasks. Training multiple models for different tasks is resource-intensive. This paper introduces OneDiffusion, aiming to overcome these limitations.
OneDiffusion uses a unified architecture and training approach, treating all tasks as sequential processes. This innovative technique allows the model to seamlessly perform diverse tasks, including text-to-image generation, image inpainting, upscaling, and reverse tasks like depth estimation. The results show OneDiffusion achieves competitive performance compared to specialized models, demonstrating its versatility and efficiency. This unified approach simplifies the development and deployment of large-scale multimodal AI systems.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces OneDiffusion, a unified model that significantly advances the capabilities of diffusion models. Its ability to handle diverse image synthesis and understanding tasks with a single architecture and training process is highly relevant to current research trends in AI. The scalability and efficiency of OneDiffusion offer new avenues for large-scale multimodal AI model development.
Visual Insights#

🔼 Figure 1 showcases OneDiffusion, a unified diffusion model capable of both image generation and understanding across various tasks. The figure visually demonstrates OneDiffusion’s capabilities through a grid of example images, each illustrating a different task. These tasks include text-to-image synthesis (top-left quadrant, highlighted in red), where an image is generated from a text prompt; conditional image generation from input images (central area, orange boxes), such as generating images from a sketch, edge map, or pose; the inverse of conditional generation: image understanding (central area, orange boxes), such as depth or semantic map estimation from an input image; ID customization (bottom-left quadrant, blue boxes), where images are altered to represent specific individuals; and multi-view generation (bottom-right quadrant, purple boxes), where multiple views of a single object or scene are generated from a single input image or image set.
read the caption
Figure 1: OneDiffusion is a unified diffusion model designed for both image synthesis and understanding across diverse tasks. It supports text-to-image generation (red box), conditional image generation from input images (orange box) and it’s reverse task Image understanding (orange box). It can also perform ID customization (blue box), and multi-view generation (purple box) with arbitrary number of input and output images.
| Methods | Params (B) | # Data (M) | GenEval ↑ |
|---|---|---|---|
| LUMINA-Next [72] | 2.0 | 14 | 0.46 |
| PixArt-Σ [9] | 0.6 | 33 | 0.54 |
| SDXL [41] | 2.6 | – | 0.55 |
| PlayGroundv2.5 [25] | 2.6 | – | 0.56 |
| IF-XL | 5.5 | 1200 | 0.61 |
| SD3-medium [15] | 2.0 | 1000 | 0.62 |
| Hunyuan-DiT [28] | 1.5 | – | 0.63 |
| DALLE3 | – | – | 0.67 |
| FLUX-dev | 12.0 | – | 0.67 |
| FLUX-schnell | 12.0 | – | 0.71 |
| OneDiffusion | 2.8 | 75 | 0.65 |
🔼 This table presents a comparison of different text-to-image models’ performance on the GenEval benchmark. The benchmark assesses the quality of generated images from text prompts. The comparison includes various metrics, such as the GenEval score, a measure of the overall image quality and alignment with the text prompt. The table also provides information on the number of parameters (in billions) used by each model and the size of the training dataset (in millions of images). All results are evaluated at a resolution of 1024 x 1024 pixels.
read the caption
Table 1: Comparison of text-to-image performance on the GenEval benchmark at a resolution of 1024 ×\times× 1024.
In-depth insights#
Unified Diffusion#
The concept of “Unified Diffusion” in the context of generative models suggests a paradigm shift towards creating single models capable of handling diverse tasks. Instead of training separate diffusion models for tasks like image generation, inpainting, and understanding, a unified approach aims to build one model that can perform all these functions. This offers several advantages. Reduced redundancy in model training and deployment is achieved; maintaining multiple models is resource-intensive. A unified approach facilitates better generalization, as the model learns transferable features across multiple domains, leading to enhanced performance on unseen data. Scalability is another key benefit, as updating or improving one model is easier than managing many. The challenge lies in designing a sufficiently flexible architecture and training strategy that allows a single model to learn the diverse intricacies of different tasks without compromising performance on any one. The success of such a unified approach would represent a significant advancement in generative AI, potentially leading to more versatile and efficient AI systems.
Multi-task Training#
Multi-task training, in the context of the provided research paper, is a crucial technique for building a unified diffusion model capable of handling diverse image synthesis and understanding tasks. The core idea is to train a single model on multiple tasks simultaneously, rather than training separate models for each task. This approach offers several key advantages. First, it promotes efficient resource utilization by avoiding the need to train and maintain numerous individual models. Second, it facilitates knowledge transfer between tasks. The model learns shared representations and features across various tasks, leading to improved performance and generalization. Third, it enhances scalability. This unified approach simplifies model deployment and makes it easier to add new tasks in the future without extensive retraining. However, successful multi-task training requires careful consideration of several factors, including the selection of tasks, dataset curation, and loss function design. The choice of tasks should be made strategically to ensure that the tasks are related in some meaningful way, minimizing negative interference during training. Furthermore, the dataset should be carefully constructed to represent all tasks adequately, ensuring that the model receives sufficient training data for each one. Finally, appropriate loss functions are critical to balance the learning process across all tasks, preventing any single task from dominating the training and hindering the performance of others. One-Gen dataset’s design reflects these careful considerations, showcasing the research team’s thoughtful approach to multi-task learning for the unified diffusion model.
One-Gen Dataset#
The conceptual ‘One-Gen Dataset’ represents a significant contribution to the field of multi-modal image synthesis and understanding. Its strength lies in the integration of diverse, high-quality data sources. Unlike datasets focused on a single task, One-Gen aims for comprehensiveness, incorporating data for text-to-image generation, various image-to-image translation tasks (like depth estimation, segmentation, pose estimation, etc.), ID customization, and multi-view generation. This holistic approach allows for training a unified model capable of handling a wide range of tasks, thus addressing the limitation of task-specific models. The inclusion of synthetic data, generated by state-of-the-art models, is particularly insightful, as it supplements real-world data and enables the creation of a more balanced and extensive dataset, improving model robustness. By incorporating data for less common tasks like multi-view generation and ID customization, One-Gen directly addresses a critical gap in existing datasets. The resulting model benefits from increased generalization ability and better performance across diverse tasks. The availability of One-Gen is critical for advancing research in unified vision models and facilitates the development of truly versatile, multi-purpose image AI systems.
Scalable Model#
A scalable model in the context of a research paper on deep learning, especially one involving diffusion models, would refer to a model architecture and training strategy that can effectively handle increasingly large datasets and complex tasks without significant performance degradation. Scalability is paramount as datasets grow exponentially and the demand for more sophisticated applications increases. A truly scalable model should demonstrate: efficient training across numerous tasks and datasets without requiring disproportionate increases in computational resources; robust generalization to unseen data and tasks; and an architecture that is easily adaptable to higher resolutions and larger input sizes. The ideal solution often involves modularity, allowing for the addition of new capabilities without requiring complete retraining, and efficient memory management to deal with the demands of large model parameters. The OneDiffusion model presented might achieve scalability by using a unified training framework that removes the need for task-specific architectures, potentially addressing the issue of resource requirements for multiple-task training. Furthermore, adaptable model design, training strategies like flow matching, and the use of a unified dataset like One-Gen could collectively contribute to the claimed scalability.
Future Directions#
Future research directions for OneDiffusion should prioritize extending its capabilities to a broader range of image modalities, such as videos and 3D point clouds. Improving efficiency through model compression and optimized training techniques is crucial for wider accessibility. Addressing the potential for biases and ethical concerns associated with large language models is paramount. The model should be further evaluated across more diverse and challenging datasets, assessing robustness and generalization abilities beyond current benchmarks. Investigating the potential for zero-shot and few-shot learning on novel tasks and domains is key for maximizing OneDiffusion’s utility as a truly versatile model. Finally, exploring applications in interactive image editing and manipulation will unlock new creative possibilities and enhance the user experience.
More visual insights#
More on figures

🔼 Figure 2 illustrates the training and inference processes of the OneDiffusion model. The model uses a special task token to identify the task for each sample. During training, the model independently samples different diffusion timesteps for each ‘view’ (representing an image or other input modality) and adds noise accordingly. The training objective is to learn a generalized time-dependent vector field that maps the noisy views back to their original, clean versions. Inference differs by substituting input images with Gaussian noise and setting the timesteps of the conditioning views to 0, which generates output views by applying the learned vector field. This unified approach allows OneDiffusion to handle diverse generation and image understanding tasks using a consistent framework.
read the caption
Figure 2: Illustration of training and inference pipeline for OneDiffusion. We encode the desired task for each sample via a special task token. During training we independently sample different diffusion timesteps for each view and add noise to them accordingly. In inference, we replace input image(s) with Gaussian noises while setting timesteps of conditions to 00.

🔼 Figure 3 showcases the high-resolution image generation capabilities of the OneDiffusion model. The images demonstrate the model’s ability to accurately reflect the textual prompts given to it, paying close attention to even fine details within the images. The variety of styles represented in the generated images highlights the model’s versatility and capacity to produce high-quality outputs across diverse artistic aesthetics.
read the caption
Figure 3: High-resolution samples from text of our OneDiffusion model, showcasing its capabilities in precise prompt adherence, attention to fine details, and high image quality across a wide variety of styles.

🔼 Figure 4 demonstrates the OneDiffusion model’s ability to perform various image understanding tasks by generating different visual representations from a single input image. The model generates high dynamic range (HDR) edge detection, depth maps, human pose estimation, semantic segmentation masks, and object detection bounding boxes. Examples of semantic segmentation are provided, showcasing the model’s ability to segment specific objects like a sword and moon, and then a road and sky in separate examples. Similarly, object detection examples show localization of a head and moon. Importantly, the figure shows the model can reverse these processes, reconstructing an image based on a specific understanding task. Furthermore, it highlights the capacity to modify image elements, such as replacing the moon with Saturn in one example.
read the caption
Figure 4: Illustration of our model capability to generate HED, depth, human pose, semantic mask, and bounding box from input image. For semantic segmentation, we segment the sword (highlighted in yellow) and the moon (highlighted in cyan) the first example, while segmenting road (yellow), sky (cyan) in the second. For object detection, We localize the head and moon (both highlighted in cyan). Leveraging these conditions, we can reverse the process to recreate a variant of the input image based on the same caption. Additionally, we can edit the image by modifying specific elements, such as replacing the moon with Saturn (last example).

🔼 This figure demonstrates the model’s capacity for multi-view image generation using a single input image. The top row showcases the results of generating multiple views of various objects from a single input image. The azimuth angle is varied from -45 to 60 degrees, and the elevation is varied from -15 to 45 degrees for the objects in the left column. A wider range of azimuth (0-360 degrees) and a narrower range of elevation (-15 to 15 degrees) were used for the objects in the right column. This illustrates the model’s ability to produce realistic and consistent views from diverse viewpoints and angles, showing its capability to understand 3D spatial information.
read the caption
Figure 5: Illustration of the multiview generation with single input image. We equally slice the azimuth in range of [−45,60]4560[-45,60][ - 45 , 60 ] and elevation in range of [−15,45]1545[-15,45][ - 15 , 45 ] for the left scenes. For the right scene, the azimuth range is set to [0;360]0360[0;360][ 0 ; 360 ] and elevation range is set to [−15;15]1515[-15;15][ - 15 ; 15 ].

🔼 Figure 6 showcases the capabilities of OneDiffusion in identity customization. Unlike previous methods that heavily rely on face embeddings and struggle with generalization, OneDiffusion excels by effectively modifying facial expressions, gaze direction, and viewpoints, all from a single reference image. The figure demonstrates this ability across diverse subjects, including both human and non-human, highlighting its superior generalization capacity. The third row specifically illustrates successful customization of non-human subjects with a single reference image, a task InstantID fails on due to its face detection limitations.
read the caption
Figure 6: Illustration of ID customization using reference images. Unlike prior methods that rely on face embeddings and often fail to generalize, our model demonstrates superior generalization. It effectively adjusts facial expressions and gaze directions (first row), changes viewpoints (second row), and even customizes non-human IDs (third row). All results in the third row are generated from a single reference image, while InstantID fails as its face detector cannot detect faces in the input.

🔼 Figure 7 presents a qualitative comparison of depth estimation results between the Marigold method (a diffusion-based approach) and the OneDiffusion model introduced in the paper. The comparison highlights the relative strengths and weaknesses of each method by visually showcasing their outputs on several example images. The images demonstrate the capability of each model to accurately estimate depth information in various scenarios, including different lighting conditions, object textures, and scene complexities. By comparing the results side-by-side, the figure allows the reader to assess the performance differences and evaluate the effectiveness of OneDiffusion’s approach to depth estimation.
read the caption
Figure 7: Qualitative comparison between a diffusion-based depth estimation - Marigold [22] and our methods.

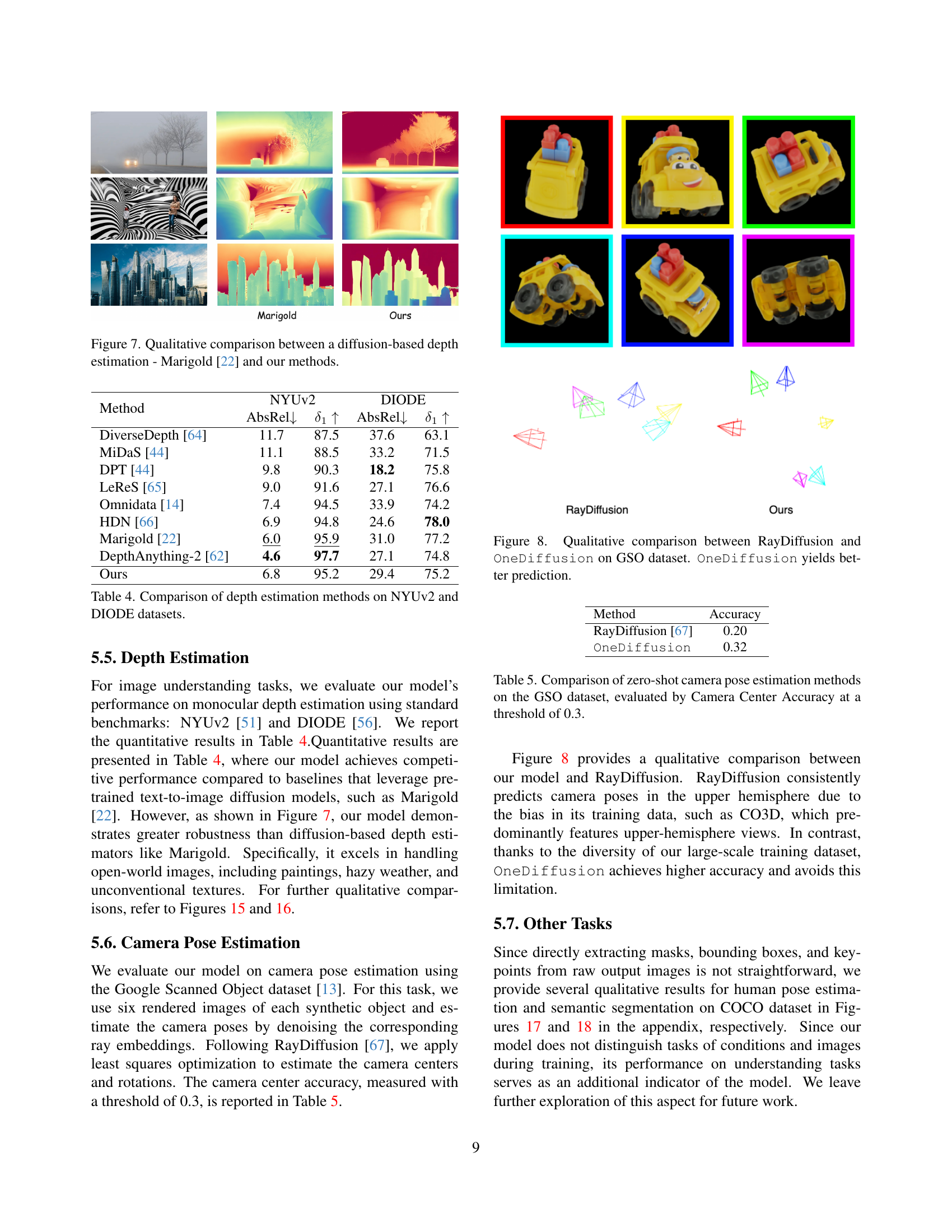
🔼 Figure 8 presents a qualitative comparison of camera pose estimation results between RayDiffusion and OneDiffusion using the Google Scanned Objects (GSO) dataset. The figure visually demonstrates that OneDiffusion achieves more accurate pose predictions compared to RayDiffusion. This improved accuracy is likely due to OneDiffusion’s more extensive training dataset, which includes diverse view angles and scenarios, resulting in better generalization.
read the caption
Figure 8: Qualitative comparison between RayDiffusion and OneDiffusion on GSO dataset. OneDiffusion yields better prediction.

🔼 Figure 9 is a pie chart visualizing the distribution of datasets used to train the OneDiffusion model. The chart is divided into an inner section representing the main task categories (text-to-image, image-to-image, and multiview generation) and an outer section detailing the specific datasets within each category. The inner section clearly shows that the model was trained with an equal proportion of data from each of the three main task categories. The outer section provides a breakdown of the individual datasets used for each category, illustrating the diversity and scale of the training data used to develop OneDiffusion. The datasets are color-coded for clarity and easy identification.
read the caption
Figure 9: Distribution of training datasets for all tasks. Segments proportional to sampling rates. The inner section shows the super-category of target tasks, it can be observed that we train the model with equal budget for text-to-image, image-to-image and multiview generation. The outer section shows datasets used for each super-category.

🔼 Figure 10 showcases the OneDiffusion model’s capacity for image-to-multiview generation. The process starts with a single input image (shown on the far left of each row). From this single image, the model generates multiple views of the same scene, systematically varying the camera’s azimuth (horizontal angle) and elevation (vertical angle). The azimuth ranges from -45 to 60 degrees, and the elevation ranges from -15 to 45 degrees. These angles are evenly spaced across the generated views within each row. The figure demonstrates the model’s ability to produce consistent and realistic-looking views of the same subject from different perspectives.
read the caption
Figure 10: Qualitative results of image-to-multiview generation. The left most images are input. We equally slice the azimuth in range of [−45,60]4560[-45,60][ - 45 , 60 ] and elevation in range of [−15,45]1545[-15,45][ - 15 , 45 ] for all scenes.

🔼 Figure 11 showcases the model’s capability to generate multiple views of a scene from a single input image. The process simulates different camera angles by systematically varying the azimuth (horizontal angle) and elevation (vertical angle) within specified ranges. For the first three examples, the azimuth ranges from -45 to 60 degrees, and the elevation ranges from -15 to 45 degrees. These ranges are evenly divided to create the multiple views shown. The final example demonstrates a different approach, where the azimuth spans the entire 360-degree circle, and the elevation ranges from -15 to 15 degrees. This figure demonstrates the versatility of the model to generate consistent views from various viewpoints, showcasing the model’s understanding of 3D scene geometry and its ability to render those scenes realistically from various perspectives.
read the caption
Figure 11: Qualitative results of image-to-multiview generation. We equally slice the azimuth in range of [−45,60]4560[-45,60][ - 45 , 60 ] and elevation in range of [−15,45]1545[-15,45][ - 15 , 45 ] for the first 3 scenes. For the last scene, the azimuth range is set to [0;360]0360[0;360][ 0 ; 360 ] and elevation range is set to [−15;15]1515[-15;15][ - 15 ; 15 ].

🔼 This figure showcases the model’s ability to generate multi-view images from text prompts. The images demonstrate the model’s capacity to create photorealistic and detailed scenes with varied viewpoints. Four different camera angles (azimuth: 0, 30, 60, 90 degrees; elevation: 0, 10, 20, 30 degrees) are shown for each scene. All prompts used a standardized prefix (“photorealistic, masterpiece, highly detail, score_9, score_8_up”) to enhance image quality and realism.
read the caption
Figure 12: Qualitative results of text-to-multiview generation. The azimuth and elevation of left to right columns are [0,30,60,90]0306090[0,30,60,90][ 0 , 30 , 60 , 90 ] and [0,10,20,30]0102030[0,10,20,30][ 0 , 10 , 20 , 30 ], respectively. We use following prefix for all prompts to improve the quality and realism of generated images: “photorealistic, masterpiece, highly detail, score_9, score_8_up”.

🔼 This figure showcases the ID Customization capabilities of the OneDiffusion model. It demonstrates the model’s ability to generate diverse variations of a person’s image from a single reference photo, all while maintaining consistent identity. Three different prompts were used, each generating multiple images in a consistent style: 1. Realistic Style: ‘Photo of a man/woman wearing a suit at Shibuya at night. He/She is looking at the camera.’ This prompt generates realistic images maintaining the identity of the person in the reference image but modifying the setting, lighting and pose. 2. Pixar Style: ‘pixarstyle, cartoon, a person in pixar style sitting on a crowded street.’ This prompt generates cartoon-style images reminiscent of Pixar films, changing the style while preserving the individual’s identity. 3. Watercolor Style: ‘watercolor drawing of a man/woman with Space Needle in background.’ This prompt generates stylized images in a watercolor painting style, altering the artistic style and adding a background element (Space Needle) while still maintaining identity consistency. The leftmost column shows the input reference images used for each style generation.
read the caption
Figure 13: Qualitative results of OneDiffusion for (single reference) ID Customization task with photo of human faces. The left most images are input, target prompts for left to right columns are: 1) “Photo of a man/woman wearing suit at Shibuya at night. He/She is looking at the camera”, 2) “pixarstyle, cartoon, a person in pixar style sitting on a crowded street”, 3) “watercolor drawing of a man/woman with Space Needle in background”

🔼 Figure 14 presents qualitative results demonstrating OneDiffusion’s ability to perform identity customization using a single reference image. The examples showcase its versatility by handling diverse input types, including non-human subjects and cartoon-style images. The model adeptly generates outputs maintaining fine details and stylistic features, demonstrating that it doesn’t depend on specific limitations like face embeddings or other architectural bottlenecks. OneDiffusion’s ability to preserve intricate details stems from its use of attention mechanisms, enabling it to effectively use the reference image to condition the generation process.
read the caption
Figure 14: Qualitative results of OneDiffusion for (single reference) ID Customization task with photo of of non-human subjects or cartoon style input. OneDiffusion is highly versatile and can produce good results for all kind of input and not limited to photorealistic human images. Since we rely on attention, the model can attend to the condition view and preserve intricate details and is not limited by any bottleneck e.g. latent representation.

🔼 This figure presents a qualitative comparison of depth estimation results obtained using three different methods: OneDiffusion, Marigold [22], and DepthAnything-v2 [62]. For several example images, it shows the original image alongside the depth maps produced by each method. This allows for a visual assessment of the accuracy and quality of depth estimation achieved by each approach, highlighting their relative strengths and weaknesses in handling various scenes and object types. The comparison helps illustrate the performance of OneDiffusion in relation to existing state-of-the-art depth estimation techniques.
read the caption
Figure 15: Qualitative comparison for depth estimation between OneDiffusion, Marigold [22] and DepthAnything-v2 [62]

🔼 Figure 16 presents a qualitative comparison of depth estimation results obtained using three different methods: OneDiffusion (the proposed model), Marigold [22], and DepthAnything-v2 [62]. The figure displays several example images alongside their corresponding depth maps generated by each method. This visual comparison allows for an assessment of the accuracy, detail, and overall quality of depth estimation achieved by each technique, particularly highlighting how well each model handles various image complexities and object types. The purpose is to demonstrate the relative strengths and weaknesses of OneDiffusion in comparison to existing state-of-the-art approaches for depth estimation.
read the caption
Figure 16: Qualitative comparison for depth estimation between OneDiffusion, Marigold [22] and DepthAnything-v2 [62]

🔼 This figure showcases several examples of human pose estimation results obtained using the OneDiffusion model on images from the COCO dataset. It visually demonstrates the model’s capacity to accurately identify and locate key body joints (such as shoulders, elbows, wrists, hips, knees, and ankles) in diverse poses and scenarios, highlighting the robustness and accuracy of the pose estimation capabilities of OneDiffusion.
read the caption
Figure 17: Qualitative examples of human pose estimation on COCO datasets.

🔼 Figure 18 showcases the model’s semantic segmentation capabilities on images from the COCO dataset. Each row presents a different image with its corresponding segmentation mask. The masks highlight specific object classes as listed in the caption: Row 1: sheep, grass, mountain, sky; Row 2: apple, person, building; Row 3: vase, flower; Row 4: dog, book, sheet; Row 5: umbrella, person, building, gate; Row 6: boat, dock, drum. The figure demonstrates the model’s ability to accurately identify and segment diverse objects and scenes within complex images.
read the caption
Figure 18: Qualitative examples of semantic segmentation on COCO datasets. The target class for each image (from left to right, from top to bottom) are (sheep, grass, mountain, sky), (apple, person, building), (vase, flower, ), (dog, book, sheet), (umbrella, person, building, gate), (boat, dock, drum).
More on tables
| Model | Condition | PSNR ↑ |
|---|---|---|
| Zero123 [32] | 1-view | 18.51 |
| Zero123-XL [12] | 1-view | 18.93 |
| 1-view | 20.24 | |
| EscherNet [24] | 2-view | 22.91 |
| 3-view | 24.09 | |
| 1-view | 19.01 | |
| 2-view (unknown poses) | 19.83 | |
| OneDiffusion | 2-view (known poses) | 20.22 |
| 3-view (unknown poses) | 20.64 | |
| 3-view (known poses) | 21.79 |
🔼 This table presents a comparison of the quality of multi-view image generation, as measured by the NVS (Normalized View Synthesis) metric, under different numbers of input views. The results demonstrate that increasing the number of input views used for conditioning improves the accuracy and quality of the generated multi-view images. This suggests that incorporating more contextual information from multiple perspectives enhances the model’s ability to synthesize a more realistic and coherent multi-view representation.
read the caption
Table 2: Comparison of NVS metrics across different number of condition view settings. Increasing the number of condition views improves the reconstruction quality.
| Method | ID ↑ | CLIP-T ↑ |
|---|---|---|
| PhotoMaker [27] | 0.193 | 27.38 |
| InstantID [58] | 0.648 | 26.41 |
| PuLID [21] | 0.654 | 31.23 |
| Ours | 0.283 | 26.80 |
🔼 Table 3 presents a quantitative evaluation of ID customization performance using the Unsplash-50 benchmark dataset. The table compares the performance of OneDiffusion against three state-of-the-art methods (PhotoMaker, InstantID, and PuLID) across two metrics: ID preservation (ID↑) and overall image quality assessed using CLIP (CLIP-T↑). Higher scores indicate better performance in both identity preservation and image quality.
read the caption
Table 3: Quantitative results on Unsplash-50.
| Method | NYUv2 AbsRel ↓ | NYUv2 δ₁ ↑ | DIODE AbsRel ↓ | DIODE δ₁ ↑ |
|---|---|---|---|---|
| DiverseDepth [64] | 11.7 | 87.5 | 37.6 | 63.1 |
| MiDaS [44] | 11.1 | 88.5 | 33.2 | 71.5 |
| DPT [44] | 9.8 | 90.3 | 18.2 | 75.8 |
| LeReS [65] | 9.0 | 91.6 | 27.1 | 76.6 |
| Omnidata [14] | 7.4 | 94.5 | 33.9 | 74.2 |
| HDN [66] | 6.9 | 94.8 | 24.6 | 78.0 |
| Marigold [22] | 6.0 | 95.9 | 31.0 | 77.2 |
| DepthAnything-2 [62] | 4.6 | 97.7 | 27.1 | 74.8 |
| Ours | 6.8 | 95.2 | 29.4 | 75.2 |
🔼 Table 4 presents a quantitative comparison of various depth estimation methods on two benchmark datasets: NYUv2 and DIODE. The table evaluates the performance of these methods using standard metrics like absolute relative error (AbsRel) and δi. Lower AbsRel values indicate better accuracy, while higher δi values suggest better robustness and precision. This comparison helps to assess the relative strengths and weaknesses of each method in terms of depth prediction accuracy, allowing for a detailed analysis of their performance on both indoor (NYUv2) and outdoor (DIODE) scenes.
read the caption
Table 4: Comparison of depth estimation methods on NYUv2 and DIODE datasets.
| Method | Accuracy |
|---|---|
| RayDiffusion [67] | 0.20 |
| OneDiffusion | 0.32 |
🔼 This table presents a comparison of the performance of different zero-shot camera pose estimation methods on the Google Scanned Objects (GSO) dataset. Zero-shot signifies that the models were not specifically trained on the GSO dataset but rather on other datasets and then evaluated on GSO. The performance metric used is Camera Center Accuracy, calculated at a threshold of 0.3. This accuracy score measures how precisely the estimated center of the camera aligns with the actual center, with higher values indicating greater accuracy. The table allows for a direct comparison of the effectiveness and robustness of various camera pose estimation models when applied to unseen data.
read the caption
Table 5: Comparison of zero-shot camera pose estimation methods on the GSO dataset, evaluated by Camera Center Accuracy at a threshold of 0.3.
Full paper#