↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for generating and editing 3D scenes often lack a unified framework, hindering efficient content creation. Existing approaches are often task-specific, relying on complex, time-consuming pipelines, and may struggle with real-world scene complexities such as varying scales and camera trajectories. Furthermore, training-free editing methods are limited, restricting adaptability and ease of use.
SplatFlow solves these issues by introducing a novel framework that directly generates and edits 3D Gaussian splatting (3DGS) representations. It employs a multi-view rectified flow model to produce multi-view consistent outputs (images, depths, and camera poses), conditioned on text prompts. A Gaussian splatting decoder efficiently converts these latents into 3DGS. Leveraging training-free inversion and inpainting techniques, SplatFlow seamlessly integrates generation and editing, supporting various 3D tasks. Evaluated on benchmark datasets, SplatFlow showcases superior performance compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a unified framework for 3D scene generation and editing using 3D Gaussian Splatting (3DGS). It addresses limitations of existing methods by enabling direct 3DGS generation and editing, offering a training-free approach for various 3D tasks. This advances real-time rendering and opens avenues for intuitive content creation tools. The training-free aspect is particularly significant, broadening accessibility and applicability.
Visual Insights#

🔼 This figure showcases the capabilities of SplatFlow, a novel framework for 3D Gaussian Splatting (3DGS) synthesis. Panel (a) demonstrates the direct generation of high-fidelity 3D scenes solely from text prompts, highlighting SplatFlow’s ability to create diverse and complex 3D content from simple textual descriptions. Panel (b) illustrates several training-free applications enabled by SplatFlow, including object editing (replacing objects within a scene), camera pose estimation (determining camera position and orientation), and novel view synthesis (generating realistic views from unseen angles). These applications are seamlessly integrated within the SplatFlow framework, underlining its efficiency and versatility for both content creation and manipulation.
read the caption
Figure 1: SplatFlow for 3D Gaussian Splatting synthesis and its training-free applications. (a) Examples of direct 3D Gaussian Splatting (3DGS) generation only from text prompts, (b) Training-free applications, including 3DGS object editing, camera pose estimation, and novel view synthesis. SplatFlow seamlessly integrates these capabilities, showcasing its versatility in generating and editing complex 3D content.
| Description | DreamScene [46] | LucidDreamer [15] | Director3D [49] | Ours |
|---|---|---|---|---|
| Stack of fries on a checkered surface | ||||
| Broom with straw bristles, leaning against a sign. | ||||
| A mannequin dressed in a red gown with yellow accents stands amidst an array of vibrant flowers and lush greenery. | ||||
| An overgrown and neglected area with a large bush or small tree covered in ivy, a wooden fence, and a paved path. | ||||
| Text | DreamScene [46] | LucidDreamer [15] | Director3D [49] | Ours |
🔼 This table presents a quantitative comparison of different methods for generating 3D Gaussian Splatting (3DGS) scenes from text descriptions, using the FID and CLIP scores to evaluate the quality and text-image alignment. The methods compared are Director3D [49] (a state-of-the-art approach), and the authors’ proposed SplatFlow method, both with and without the additional SDS++ [49] refinement technique. The evaluation uses two datasets, MVImgNet and DL3DV, showing the performance of each method on real-world scenes with various scales and camera trajectories.
read the caption
Table 1: Quantitative results in text-to-3DGS generation on the MVImgNet and DL3DV datasets. We compared our SplatFlow with and without the SDS++ [49], against Director3D [49].
In-depth insights#
Multi-View RF Model#
The proposed Multi-View Rectified Flow (RF) model is a core component, designed for simultaneously generating multiple views of a scene. It leverages the efficiency of rectified flows, offering a computationally advantageous approach compared to traditional diffusion methods. The model’s training is conditioned on text prompts, enabling text-to-3D scene generation. It directly outputs multi-view images, depth maps, and camera poses in a latent space, thereby tackling the challenge of diverse scene scales and complex camera trajectories found in real-world datasets. This joint generation of image, depth, and pose information is a key strength, addressing the limitations of methods that handle these elements separately. The joint representation facilitates various downstream 3D tasks, and integration with a pre-trained encoder enables flexible cross-model usage. This approach contributes to the framework’s effectiveness and versatility in tasks such as object editing and novel view synthesis. Ultimately, the multi-view RF model’s ability to directly generate coherent multi-view representations forms the foundation for the framework’s training-free capabilities in 3D content editing.
3DGS Decoder#
The 3D Gaussian Splatting (3DGS) Decoder is a crucial component of the proposed SplatFlow model, responsible for translating latent representations into high-fidelity 3D scenes. Its feed-forward architecture ensures efficient and fast 3D reconstruction, unlike optimization-based methods that are computationally expensive. The decoder’s design incorporates improvements like depth latent integration, enhancing 3D structural preservation, and adversarial loss application for improved visual quality. The incorporation of depth information significantly enhances the accuracy and realism of the generated 3D scenes. By jointly modeling multi-view image latents and depth information, the decoder creates detailed and contextually rich 3D models. Its ability to seamlessly integrate with pre-trained models like Stable Diffusion 3 is a significant advantage, fostering flexibility and efficient cross-model usage. The GSDecoder’s architecture is carefully adapted from Stable Diffusion 3, including modifications to accommodate multi-view inputs and produce pixel-aligned 3D Gaussian splat parameters. The training process involves a combined loss function including LPIPS and vision-aided GAN loss, achieving high-quality 3D reconstruction.
Training-Free Editing#
The concept of “Training-Free Editing” in the context of 3D Gaussian Splatting synthesis is a significant advancement. It leverages the power of pre-trained models, particularly the multi-view rectified flow model, to perform edits without requiring additional training or complex pipelines. This is achieved through inversion techniques, which enable the model to map existing 3D scenes into a latent space where manipulations can be performed directly on latent representations, and inpainting techniques which allow for seamless modifications and filling in missing data. This approach is highly efficient and flexible, enabling various tasks like object editing, camera pose estimation, and novel view synthesis without specialized model training for each task. The training-free nature is a crucial strength, offering a practical and scalable solution for 3D scene manipulation. However, limitations might exist in the range of edit operations achievable, particularly regarding highly complex or intricate alterations. Further research could investigate the boundaries of these editing capabilities and explore techniques to enhance control and precision for more complex modifications.
Real-World 3D#
The concept of “Real-World 3D” in the context of this research paper likely refers to the challenge of generating and manipulating 3D scenes that accurately reflect the complexity and variability of real-world environments. Unlike synthetic datasets with controlled conditions, real-world scenes present diverse scales, camera trajectories, and object arrangements. This necessitates a model robust enough to handle these variations and generate photorealistic results without specialized training per scene. The paper likely emphasizes the training-free nature of its approach as a key element to addressing the “Real-World 3D” challenge. It likely demonstrates the model’s ability to generalize to unseen scenes and perform tasks such as novel view synthesis, object editing, and camera pose estimation without requiring specific training data for each task, showcasing its versatility and effectiveness in handling the complexities of real-world scenarios.
Future Directions#
Future research directions for 3D Gaussian splatting synthesis could focus on several key areas. Improving efficiency is crucial; current methods can be computationally expensive, particularly for high-resolution scenes and complex editing operations. Addressing the limitations of training data is vital; reliance on synthetic or limited real-world datasets restricts generalizability. Future work should explore techniques to train models effectively using diverse and large-scale datasets, perhaps incorporating self-supervised or semi-supervised learning methods. Enhanced editing capabilities are also needed; current approaches often lack fine-grained control and can struggle with complex edits. Developing more intuitive and versatile editing interfaces is crucial. Expanding application domains beyond the explored areas, such as robotics and AR/VR, will unlock further potential. Finally, it’s important to investigate ethical considerations, mitigating risks of misuse and ensuring responsible development and deployment.
More visual insights#
More on figures

🔼 SplatFlow, a novel 3D scene generation model, is composed of two main components: a multi-view Rectified Flow (RF) model and a Gaussian Splat Decoder (GSDecoder). The RF model processes text prompts to generate multi-view latent representations, including images, depth maps, and Plücker ray coordinates. These latent representations are then used by the GSDecoder to generate pixel-aligned 3D Gaussian Splatting (3DGS) data. Camera poses are estimated through an optimization process, ensuring accurate reconstruction of the 3D scene.
read the caption
Figure 2: Overview of SplatFlow. SplatFlow consists of two main components: a multi-view Rectified Flow (RF) model and a Gaussian Splat Decoder (GSDecoder). Conditioned on text prompts, the RF model generates multi-view latents—including image, depth, and Plücker ray coordinates. After an optimization process to estimate camera poses, the GSDecoder decodes these latents into pixel-aligned 3DGS.

🔼 This figure showcases qualitative results of text-to-3DGS generation using the SplatFlow model. The top two rows display example scenes generated from the MVImgNet dataset; the bottom two rows show scenes generated from the DL3DV dataset. The results highlight SplatFlow’s ability to create realistic, detailed 3D scenes from text prompts, showcasing the model’s capacity to handle complex real-world scenes with varied camera angles and perspectives.
read the caption
Figure 3: Qualitative results in text-to-3DGS generation on MVImgNet and DL3DV validation sets. The first two rows are rendered scenes from the MVImgNet dataset, while the last two rows are from the DL3DV dataset. Our SplatFlow produces cohesive and realistic scenes with sharp details, accurately capturing the intricacies of real-world environments and accommodating diverse camera trajectories.
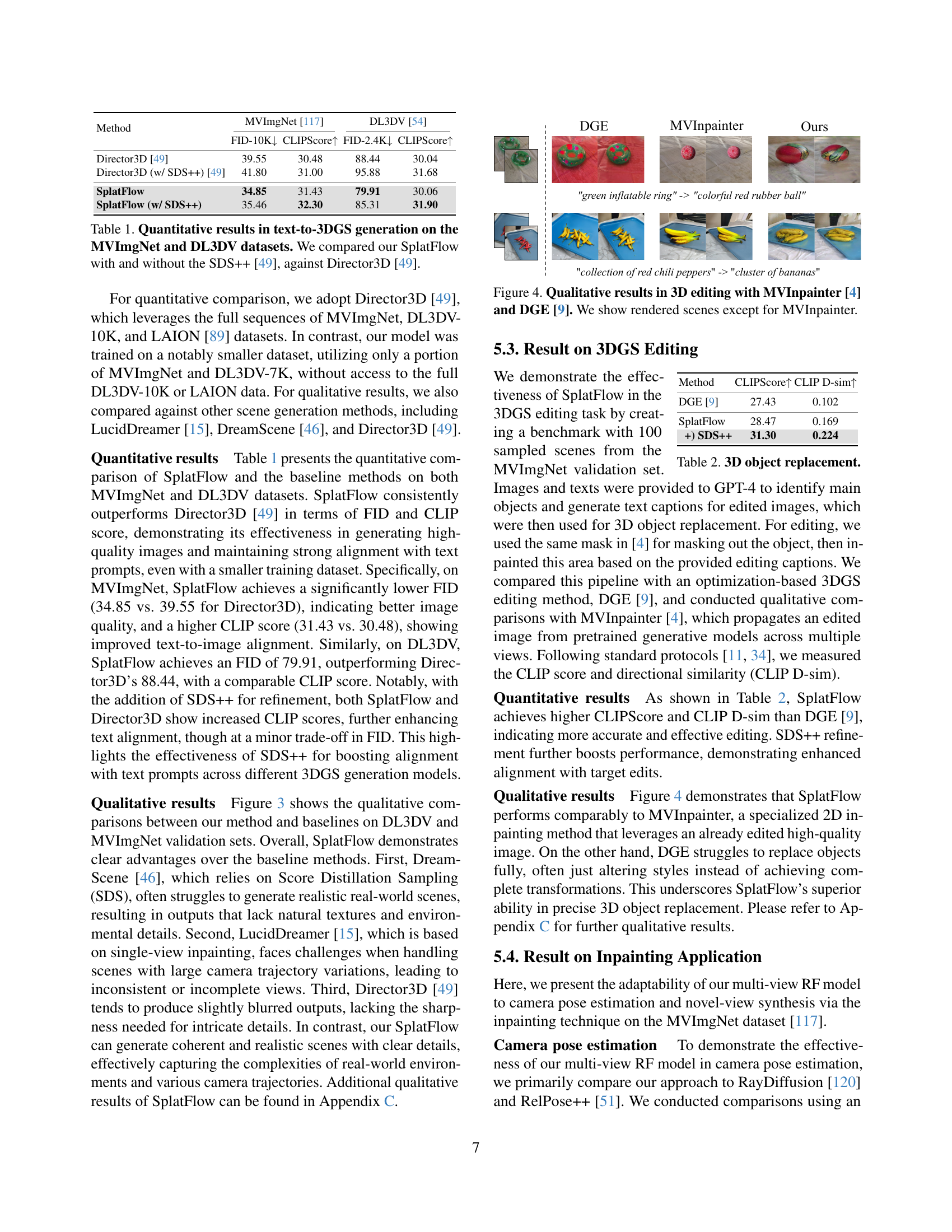
🔼 This figure showcases a comparison of 3D object editing results using three different methods: SplatFlow, MVInpainter, and DGE. The images demonstrate the ability of each method to replace objects within 3D scenes according to textual prompts. SplatFlow’s results are presented as rendered 3D scenes, highlighting the realistic replacement of the objects and preservation of scene context. In contrast, MVInpainter’s results are not directly shown (only mentioned in caption), and DGE’s results are also shown as rendered 3D scenes, but potentially with less fidelity or realistic integration than the results achieved by SplatFlow. The comparison highlights the effectiveness of SplatFlow in performing precise 3D editing tasks compared to existing methods.
read the caption
Figure 4: Qualitative results in 3D editing with MVInpainter [4] and DGE [9]. We show rendered scenes except for MVInpainter.

🔼 This figure showcases the qualitative results of camera pose estimation. Multiple input images are used to estimate camera poses, which are then compared to ground truth poses. The image borders are color-coded to match each camera, making it easy to identify which poses are estimates and which are ground truth. Black borders denote the ground truth poses. This visualization helps assess the accuracy and precision of the camera pose estimation model.
read the caption
Figure 5: Qualitative results for camera pose estimation. Camera poses are estimated from multi-view images. Image border colors match each camera, with black cameras indicating GT poses.

🔼 This figure displays the results of novel view synthesis, a key task achieved by the SplatFlow model. The red boxes highlight the input views (images and corresponding depth maps) used to generate the novel views. The figure showcases the model’s ability to generate realistic and high-quality images from new perspectives, demonstrating the effectiveness of the multi-view rectified flow model in capturing and representing 3D scene structure.
read the caption
Figure 6: Qualitative results for novel view synthesis. Novel view synthesis is performed from the red-box images and depths.

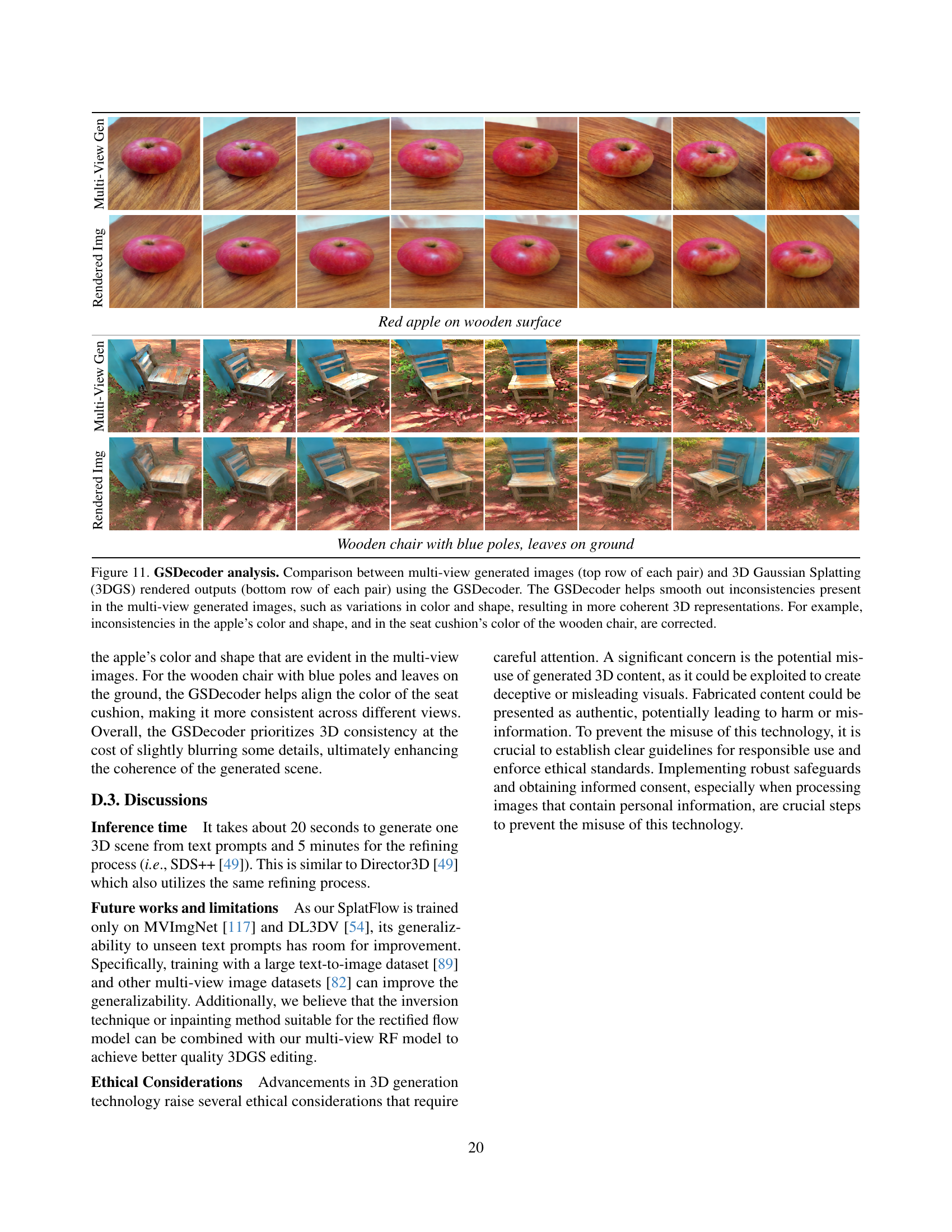
🔼 This figure shows an ablation study on the design choices of the GSDecoder, focusing on the impact of incorporating depth latents and the vision-aided GAN loss. The image on the left represents the results when training the GSDecoder without depth latents for 200k iterations; the results in the middle are for the GSDecoder trained with depth latents for 200k iterations. The two images on the right show the results for 400k iterations, with and without the Vision-aided GAN loss, respectively.
read the caption
(a) w/o Depth (200K iter)

🔼 This figure shows the results of training a Gaussian Splatting Decoder (GSDecoder) with depth information for 200K iterations. It is part of an ablation study evaluating the impact of adding depth latents and a vision-aided GAN loss on the quality of 3D Gaussian Splatting generation. The image likely showcases generated 3D scenes, potentially highlighting visual improvements achieved by including depth information during training.
read the caption
(b) w/ Depth (200K iter)
🔼 This figure shows the qualitative results of an ablation study on the GSDecoder design choices. Specifically, it presents a comparison of 3D Gaussian Splatting (3DGS) generated images with and without a vision-aided GAN loss, trained for 400K iterations. The comparison aims to highlight the impact of the vision-aided GAN loss on the quality of generated 3D scenes. The results are shown as zoomed-in details to better visualize the differences in the generated images.
read the caption
(c) w/o GAN Loss (400K iter)

🔼 This figure shows the qualitative results of an ablation study on the GSDecoder design choices. Specifically, it compares the visual quality of 3D Gaussian Splatting (3DGS) generated by four different GSDecoder variants: 1) without depth latents and trained for 200K iterations; 2) with depth latents and trained for 200K iterations; 3) with depth latents and trained for 400K iterations; and 4) with depth latents, trained for 400K iterations, and incorporating the vision-aided GAN loss. The zoomed-in images highlight the improvements in detail and realism achieved by including depth latents and vision-aided GAN loss.
read the caption
(d) w/ GAN Loss (400K iter)

🔼 This figure shows the target view used as the ground truth for evaluating the quality of the generated 3D Gaussian Splatting (3DGS) scenes. This target view serves as a reference image against which the generated views are compared to assess the accuracy and realism of the 3DGS reconstruction. The figure specifically visualizes a high-quality, real-world image of a scene, providing a clear benchmark for the model’s performance.
read the caption
(e) Target View

🔼 This figure shows a zoomed-in comparison of 3D Gaussian splatting (3DGS) generation results from four different GSDecoder configurations. It demonstrates the impact of incorporating depth latents and the vision-aided GAN loss on the quality of the generated 3D scenes. The four configurations compared are: (1) without depth latents trained for 200K iterations, (2) with depth latents trained for 200K iterations, (3) without the vision-aided GAN loss trained for 400K iterations (with depth latents), and (4) with the vision-aided GAN loss trained for 400K iterations (with depth latents). The zoomed-in views highlight the improved detail, realism, and overall quality achieved by adding depth latents and the vision-aided GAN loss.
read the caption
(f) Zoom: w/o Depth (200K iter)
More on tables
| Method | MVImgNet [117] | DL3DV [54] | |||
|---|---|---|---|---|---|
| FID-10K ↓ | CLIPScore ↑ | FID-2.4K ↓ | CLIPScore ↑ | ||
| — | — | — | — | — | — |
| Director3D [49] | 39.55 | 30.48 | 88.44 | 30.04 | |
| Director3D (w/ SDS++) [49] | 41.80 | 31.00 | 95.88 | 31.68 | |
| SplatFlow | 34.85 | 31.43 | 79.91 | 30.06 | |
| SplatFlow (w/ SDS++) | 35.46 | 32.30 | 85.31 | 31.90 |
🔼 This table presents a quantitative comparison of different methods for 3D object replacement. It shows the CLIP score (a measure of how well the generated image aligns with the text prompt) and the CLIP D-sim (a measure of directional similarity between the original and edited images) for several methods, including the proposed SplatFlow with and without the SDS++ refinement technique. Higher scores indicate better performance. The results demonstrate the effectiveness of SplatFlow in achieving high-quality 3D object replacement compared to existing approaches.
read the caption
Table 2: 3D object replacement.
| Method | CLIPScore ↑ | CLIP D-sim ↑ |
|---|---|---|
| DGE [9] | 27.43 | 0.102 |
| SplatFlow | 28.47 | 0.169 |
| +) SDS++ | 31.30 | 0.224 |
🔼 This table presents a quantitative evaluation of camera pose estimation performance on the MVImgNet validation set. It compares the accuracy of different methods in estimating camera rotation and center position. The accuracy is measured using thresholds (@Q) for both rotation (in degrees) and camera center position (in units). Higher values generally indicate better performance. Specifically, the table shows the percentage of estimated poses falling within various ranges of accuracy for rotations and translation (camera center).
read the caption
Table 3: Results in camera pose estimation on MVImgNet validation set. @Q𝑄Qitalic_Q represents the accuracy threshold for rotations (degrees) and camera centers (units).
| Method | Rotation↑ @5 | Rotation↑ @10 | Rotation↑ @15 | Camera Center↑ @0.05 | Camera Center↑ @0.1 | Camera Center↑ @0.2 |
|---|---|---|---|---|---|---|
| RelPose++ [51] | 19.4 | 37.7 | 51.4 | 0.6 | 12.5 | 55.0 |
| Ray Regression [120] | 10.4 | 25.6 | 50.1 | 15.3 | 47.9 | 82.9 |
| Ray Diffusion [120] | 17.5 | 38.7 | 59.6 | 24.1 | 60.9 | 87.6 |
| SplatFlow (w/ depth) | 26.8 | 52.6 | 59.3 | 62.3 | 91.6 | 99.4 |
| SplatFlow (w/o depth) | 28.8 | 54.5 | 63.9 | 64.9 | 94.0 | 99.7 |
🔼 This table presents the quantitative results of novel view synthesis experiments conducted on the MVImgNet dataset. The method evaluates the model’s ability to generate new viewpoints of a scene given a subset of existing views. The experiment is divided into two categories: interpolation and extrapolation. Interpolation involves generating new views from uniformly sampled input views. Extrapolation involves generating new views from views centrally located in the scene. The results are evaluated using metrics such as Peak Signal-to-Noise Ratio (PSNR), Structural SIMilarity index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Absolute Relative error (AbsRel) to assess image quality and accuracy. The number of input views used (N) and the number of novel views synthesized (K-N) are also specified in the table.
read the caption
Table 4: Novel view synthesis results on MVImgNet. We use N𝑁Nitalic_N input views to synthesize K−N𝐾𝑁K-Nitalic_K - italic_N novel views, with uniformly sampled views for interpolation and central views for extrapolation.
| Input Images | Camera Poses |
|---|
🔼 This table presents the results of an ablation study conducted on the GSDecoder, a key component of the SplatFlow model. The study investigates the impact of two design choices: the incorporation of depth latents and the use of a vision-aided GAN loss. Four different variants of the GSDecoder were evaluated, each differing in the presence or absence of these design choices. The performance of each variant was assessed using four metrics: Peak Signal-to-Noise Ratio (PSNR), Learned Perceptual Image Patch Similarity (LPIPS), Structural Similarity Index (SSIM), and Fréchet Inception Distance (FID). The results illustrate the relative contribution of depth latents and the vision-aided GAN loss in improving the overall quality of 3D Gaussian Splatting (3DGS) generation. Higher PSNR, SSIM, and lower LPIPS and FID scores indicate better image quality and alignment with the target view.
read the caption
Table 5: Ablation study on GSDecoder design choices. Evaluations are performed using PSNR, LPIPS, SSIM, and FID, highlighting the impact of incorporating depth latents and vision-aided GAN loss in improving 3DGS quality.
| Type | RGB PSNR ↑ | RGB SSIM ↑ | RGB LPIPS ↓ | Depth AbsRel ↓ | Depth δ₁ ↑ |
|---|---|---|---|---|---|
| Interpolation (N=2) | 14.73 | 0.571 | 0.648 | 0.588 | 0.731 |
| Interpolation (N=4) | 17.05 | 0.590 | 0.551 | 0.498 | 0.761 |
| Interpolation (N=6) | 18.82 | 0.626 | 0.483 | 0.415 | 0.775 |
| Extrapolation (N=2) | 15.15 | 0.577 | 0.627 | 0.771 | 0.715 |
| Extrapolation (N=4) | 16.80 | 0.595 | 0.554 | 0.679 | 0.727 |
| Extrapolation (N=6) | 17.96 | 0.613 | 0.503 | 0.602 | 0.747 |
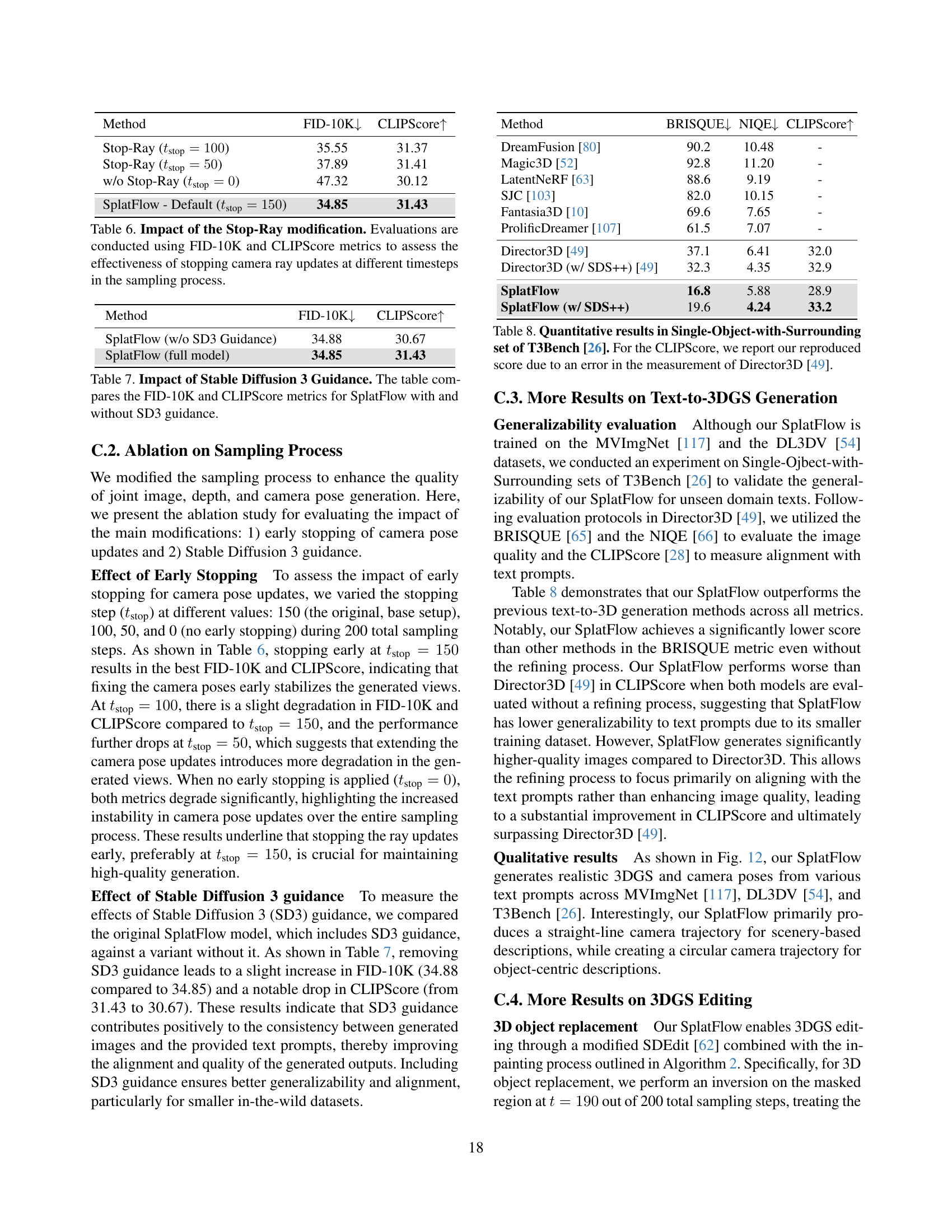
🔼 This table presents an ablation study on the effect of early stopping during the camera pose update process within the SplatFlow model’s sampling process. Different stopping timesteps (’tstop’) are tested: 100, 50, 0 (no early stopping), and the default 150. The results show the Fréchet Inception Distance (FID-10K) and CLIPScore metrics for each configuration. The metrics assess the quality of the generated images and how well they align with the given textual prompts. This analysis helps determine the optimal time to halt camera pose updates in order to balance image quality and efficiency during generation.
read the caption
Table 6: Impact of the Stop-Ray modification. Evaluations are conducted using FID-10K and CLIPScore metrics to assess the effectiveness of stopping camera ray updates at different timesteps in the sampling process.
🔼 This table presents a quantitative comparison of the performance of the SplatFlow model with and without the use of Stable Diffusion 3 (SD3) guidance. It assesses the impact of integrating SD3 guidance on the model’s ability to generate 3D scenes from text prompts by comparing two key metrics: Fréchet Inception Distance (FID-10K), measuring the quality of generated images, and CLIPScore, evaluating how well the generated images align with the input text. Lower FID-10K scores indicate better image quality, while higher CLIPScores reflect stronger alignment between images and text descriptions. The results reveal the contribution of SD3 guidance to the overall quality and alignment of the generated scenes.
read the caption
Table 7: Impact of Stable Diffusion 3 Guidance. The table compares the FID-10K and CLIPScore metrics for SplatFlow with and without SD3 guidance.
| Method | PSNR ↑ | LPIPS ↓ | SSIM ↑ | FID-50K ↓ |
|---|---|---|---|---|
| w/o Depth Latent (200K Iterations) | 25.64 | 0.2507 | 0.7993 | 16.29 |
| w/ Depth Latent (200K Iterations) | 26.19 | 0.2260 | 0.8169 | 11.92 |
| w/ Depth Latent (400K Iterations) | 26.68 | 0.2129 | 0.8251 | 8.80 |
| + Vision-Aided GAN Loss | 26.84 | 0.2048 | 0.8256 | 5.81 |
🔼 This table presents a quantitative comparison of different 3D scene generation methods on the ‘Single-Object-with-Surrounding’ subset of the T3Bench benchmark [26]. The metrics used are BRISQUE, NIQE, and CLIP score. The CLIP score for Director3D [49] was reproduced due to an error in the original measurement reported in the paper.
read the caption
Table 8: Quantitative results in Single-Object-with-Surrounding set of T3Bench [26]. For the CLIPScore, we report our reproduced score due to an error in the measurement of Director3D [49].
Full paper#