↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
The AI research community is facing a reproducibility crisis, especially concerning replicating OpenAI’s advanced models. Many researchers prioritize speed over transparency, obscuring their methods and hindering progress. This paper investigates this issue by replicating OpenAI’s O1 model using a surprisingly simple method: knowledge distillation from the O1 API followed by supervised fine-tuning. The study finds that this method achieves unexpectedly strong performance on complex mathematical reasoning tasks, even surpassing the original O1-preview in some cases.
This research makes a significant contribution by openly sharing its simple, effective method and highlighting the problem of lacking transparency. It proposes a new benchmark framework to evaluate the transparency and reproducibility of future replication attempts, urging researchers to prioritize rigorous methodology and open sharing of resources. This approach not only improves scientific rigor but also fosters a more collaborative and transparent AI research community that emphasizes fundamental innovation over quick wins.
Key Takeaways#
Why does it matter?#
This paper is crucial because it highlights the transparency crisis in AI research, particularly concerning the replication of OpenAI’s models. It introduces a benchmark framework for evaluating replication attempts based on their technical transparency and reproducibility and challenges the current trend of obscured technical claims. The study’s findings on simple distillation achieving surprisingly good results opens up new avenues for research but also cautions against over-reliance on shortcuts at the cost of fundamental innovation.
Visual Insights#

🔼 This figure illustrates the timeline and key milestones of the authors’ journey in replicating OpenAI’s O1 model from September 12th to November 22nd, 2024. It highlights the different approaches explored, including initial assessments, the use of a ‘shortcut’ method involving knowledge distillation, progress on various benchmarks (like AIME and MATH), and the final results achieved. The visual elements use cartoonish characters to represent different stages and approaches in a clear and intuitive way.
read the caption
Figure 1: Illustration of our O1 replication journey from September 12 to November 22, 2024.
| Model | AIME(2024) Accuracy | AIME(2024) # Average Token | MATH500 Accuracy | MATH500 # Average Token |
|---|---|---|---|---|
| Proprietary | ||||
| o1-preview | 12/30 | 9083 | 85.5 | 1501 |
| o1-mini | 21/30 | 9903 | 90.0 | 944 |
| Parameter Size: 72B | ||||
| Ours-72B | 13/30 | 8016 | 87.2 | 2235 |
🔼 This table compares the performance of a distilled O1-mini model against the original OpenAI O1-preview and O1-mini models. The comparison is done on two benchmarks, AIME2024 and MATH500, while controlling for the computational cost (average tokens used during inference). It shows the accuracy and the average number of tokens used for each model on each benchmark, demonstrating the performance of the distilled model relative to the original models under similar computational constraints.
read the caption
Table 1: Comparison of the performance between the distilled O1-mini model and O1-series models on the AIME2024 and MATH500 benchmarks under specific inference cost constraints.
In-depth insights#
O1 Replication#
The research paper explores the challenges and approaches to replicating OpenAI’s O1 model, focusing on the prevalent yet often undisclosed use of knowledge distillation. Simple distillation from O1’s API, combined with supervised fine-tuning, proves surprisingly effective, surpassing O1-preview on complex mathematical reasoning tasks. This raises concerns about transparency and reproducibility in AI research, prompting a call for more rigorous reporting methodologies and a renewed emphasis on fundamental technical innovation rather than relying solely on shortcuts. The paper highlights the limitations of distillation, such as its inherent dependence on the teacher model (O1), potentially hindering long-term growth and genuine advancements in AI capabilities. A critical discussion of the ‘bitter lesson’ warns against over-reliance on distillation, urging the development of researchers grounded in first-principles thinking. A new benchmark framework is introduced to promote transparency and facilitate the objective evaluation of future O1 replication attempts.
Distillation Methods#
Knowledge distillation, a prominent theme in the paper, involves training a smaller student model using the output of a larger teacher model (like OpenAI’s O1). This technique is explored as a method to replicate O1’s capabilities. The authors critique the lack of transparency surrounding the use of distillation in many replication attempts, highlighting it as a potential shortcut that obscures genuine innovation. They emphasize that while distillation offers a convenient path to performance gains, it also limits the potential for true breakthroughs by constraining the student model to the teacher’s abilities. Furthermore, over-reliance on distillation can stifle the development of fundamental reasoning techniques, leading to stagnation in the field and creating a dependency on powerful, pre-trained models. The paper advocates for greater transparency and a renewed emphasis on first-principles research in AI, urging a shift away from the pursuit of quick wins towards genuine innovation.
Benchmarking#
Benchmarking in this research paper plays a crucial role in evaluating the performance of the models developed. It goes beyond simple accuracy metrics and delves into inference-time scaling, which examines performance under varying computational costs. This nuanced approach is critical for evaluating model performance in real-world deployment scenarios where speed and efficiency are critical. The choice of benchmarks (MATH, AIME, MATH2024) demonstrates a focus on challenging mathematical reasoning tasks, enabling rigorous assessment of capabilities. The integration of multiple benchmarks allows for a comprehensive evaluation, mitigating the risk of skewed results from a single dataset. Moreover, the researchers introduce a novel metric to account for the trade-off between computational cost and performance, reflecting a deep understanding of the practical considerations in deploying large language models. This meticulous benchmarking strategy provides a robust and relevant evaluation of the models’ capabilities, avoiding oversimplification and providing valuable insights into their real-world applicability.
Beyond Math#
The section “Beyond Math” in the research paper explores the generalization capabilities of models initially trained on mathematical reasoning tasks. The authors investigate how these models perform when applied to diverse domains such as safety assessment, factuality verification, and open-domain question answering. A key finding highlights the subtle interplay between enhanced reasoning and safety. While improved reasoning skills, cultivated through the use of long-thought chains, enhance performance on nuanced tasks, they don’t guarantee perfect safety or factuality. The model demonstrates a capacity for detailed analysis and self-reflection, improving its ability to detect and correct false assumptions and biases. However, results indicate a need for more explicit safety alignment training to ensure consistent safety performance across all domains. This points towards a crucial limitation of knowledge distillation: while it can lead to rapid performance gains, it’s not a substitute for fundamental research and development of robust, general-purpose reasoning models.
Future of AI#
The future of AI, as discussed in this paper, is intricately linked to the transparency and reproducibility of research practices. The current trend of prioritizing rapid performance gains over methodological clarity risks hindering genuine innovation. Over-reliance on simple distillation techniques, while yielding immediate results, may create a dependency cycle that restricts progress beyond the capabilities of existing models. A shift towards first-principles thinking, fostering genuine research skills and original technical contributions, is crucial. This requires a research culture change, emphasizing transparency and fostering educational initiatives that promote deep understanding over superficial applications. The path forward involves striking a balance between optimizing performance and building foundational capabilities, thus ensuring a more sustainable and inclusive trajectory for AI development. The ultimate goal is not just building powerful AI, but nurturing the human capacity for fundamental innovation.
More visual insights#
More on figures

🔼 This figure illustrates the Journey Learning framework, a method for synthesizing long chains of reasoning to solve complex problems. It involves using tree-search algorithms (like Monte Carlo) to explore different solution paths, selecting promising trajectories, and using LLMs to analyze previous steps, identify errors, and make corrections. This iterative process generates complete trajectories leading to correct answers, which are used for training LLMs. The diagram depicts this process with various stages, including initial assessment, shortcut paths, multi-agent debate, tree search, and human annotations, culminating in the final model.
read the caption
Figure 2: The framework of journey learning.

🔼 Figure 3 illustrates various methods for acquiring long-thought data, crucial for training AI models capable of complex reasoning. Methods shown include tree search (computationally intensive but thorough), multi-agent debate (involving multiple AI agents to simulate a reasoning process), and human annotation (labor-intensive and costly but providing gold-standard data). The figure highlights that knowledge distillation from existing advanced models offers a superior balance of cost-effectiveness and reliability for obtaining high-quality data.
read the caption
Figure 3: Different methods of collecting the long thought data. The distillation method offers a cost-effective and reliable approach to obtaining high-quality data.

🔼 This figure showcases a comparative analysis of responses generated by the base model and the fine-tuned model to a safety-related query. The base model, without the benefit of long-thought training data, focuses primarily on anti-theft measures. However, the fine-tuned model, incorporating long-thought chains, exhibits a more comprehensive approach, prioritizing life-threatening risks (fire hazards) before addressing the user’s immediate concern (theft). This highlights how the incorporation of long-thought processes leads to more nuanced, safer, and more insightful responses by considering multiple aspects and providing alternative solutions.
read the caption
Figure 4: Case study on how model-generated long thoughts provide alternatives, resulting in safer responses.

🔼 This figure showcases a case study illustrating how the model actively attempts to utilize external resources (search engines, etc.) to answer a short factual question. The before-and-after comparison highlights the improvements in the model’s approach to problem-solving after undergoing fine-tuning. The ‘before’ example shows a more simplistic and less thorough approach, whereas the ‘after’ example depicts a step-by-step, systematic process involving identifying relevant sources, performing searches, verifying information from multiple sources, and presenting a detailed justification for the final answer. This demonstrates how fine-tuning enhances the model’s ability to perform complex reasoning tasks.
read the caption
Figure 5: Case study on our model attempting to actively search and leverage external tools to solve a short-form fact-seeking question.

🔼 This figure showcases a case study comparing model responses before and after fine-tuning. The before-tuning response is concise and lacks detail, while the after-tuning response demonstrates a thorough step-by-step approach, including active search for information, verification of details, and self-reflection on the process. This illustrates how detailed analysis and self-reflection, facilitated by the fine-tuning process, can significantly improve response accuracy and reduce hallucinations.
read the caption
Figure 6: Case study on how detailed analysis and self-reflection can help prevent hallucination.

🔼 This figure showcases a comparative analysis of model responses before and after fine-tuning. It presents two example queries and their respective responses, illustrating how self-reflection during the fine-tuning process helps the model identify and correct a false assumption embedded in the query. The first example shows a query about the second longest river in China, where the model’s initial response incorrectly identified the Pearl River. After fine-tuning, the model actively reconsiders this claim, engages in self-reflection, and correctly identifies the Yellow River as the second longest. In the second example, the query concerns the number of times Argentina won the FIFA World Cup. The original model’s reasoning is less systematic and results in an incorrect answer. The model after fine-tuning demonstrates significantly improved reasoning and a more rigorous approach, arriving at the correct answer through detailed analysis and verification.
read the caption
Figure 7: Case study on how self-reflection can help models detect false assumptions.

🔼 This figure shows a comparison of how the model before and after fine-tuning (SFT) answers a question about debugging in Python’s asyncio library. Before SFT, the response is concise and lacks depth, offering only five basic points and code examples. After SFT, the model’s response demonstrates significant improvement in structure, detailed analysis, and helpful insights. The post-SFT response includes advanced concepts, debugging suggestions, and best practices, showcasing enhanced reasoning and comprehensive understanding.
read the caption
Figure 8: Case study of our model provides helpful insights from different perspectives on answering user questions.
More on tables
| Model | Flames | DiaSafety | WildSafety | SimpleQA | C-SimpleQA | CFE-General | CFE-Sycophancy | Auto-J | LIMA | |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 91.0 | 100.0 | 92.0 | 10.58 | 47.08 | 69.08 | 89.70 | 81.6 | 77.2 | |
| Ours | 92.5 | 100.0 | 86.5 | 10.41 | 45.76 | 62.65 | 92.65 | 88.0 | 87.2 |
🔼 Table 2 presents a detailed comparison of model performance before and after supervised fine-tuning (SFT). It assesses performance across various categories grouped into three main areas: safety, factuality, and general knowledge. Safety is evaluated using the Flames, DiaSafety, and WildSafety datasets; factuality is assessed with SimpleQA, its Chinese equivalent (C-SimpleQA), and both general and sycophancy versions of the ChineseFactEval dataset (CFE-General and CFE-Sycophancy, respectively). Finally, general performance is measured using the Auto-J and LIMA datasets. The table allows for a comprehensive understanding of how SFT impacts model capabilities in different aspects, highlighting its strengths and limitations in safety, accuracy and general knowledge reasoning. The use of diverse datasets ensures a robust and multifaceted evaluation.
read the caption
Table 2: Performance comparison (accuracy) before and after SFT across different evaluation categories. The datasets are grouped into three categories: safety evaluation (Flames, DiaSafety, WildSafety), factuality evaluation (SimpleQA, Chinese SimpleQA, ChineseFactEval-General, ChineseFactEval-Sycophancy, and general evaluation (Auto-J, LIMA). Note: C-SimpleQA, CFE-General, and CFE-Sycophancy stand for Chinese SimpleQA, ChineseFactEval-General, and ChineseFactEval-Sycophancy, respectively.
| Evaluation Dimensions | Checklist | Score |
|---|---|---|
| Data (14) | Are dataset names, sources, and providers explicitly documented and properly cited? | 3 |
| Is there sufficient documentation of data distributions, formats, and characteristics to enable proper replication? | 3 | |
| Are the criteria and methodology for data selection and filtering clearly justified and documented? | 4 | |
| For synthetic data generation, is the entire process transparent, including prompting strategies and quality control measures? | 4 | |
| Methodology (33) | Is there a clear and complete description of the base model (including its architecture, size, etc.)? | 4 |
| Is the complete search algorithm implementation (e.g., beam search, MCTS) detailed with all components? | 6 | |
| Is the RL algorithm fully specified with its objective function and training procedure? | 6 | |
| Is the long thought data curation/generation algorithm thoroughly explained with its complete workflow? | 6 | |
| Is the complete training pipeline documented, including all stages and their sequence? | 3 | |
| Are the computational requirements and infrastructure details provided? | 2 | |
| Is there clear documentation of all training hyperparameters and optimization choices? | 2 | |
| Are there comprehensive ablation studies showing the contribution of each major component? | 4 | |
| Evaluation (24) | Is there a clear justification for the selection of evaluation benchmarks? | 4 |
| Is the evaluation dimension clearly specified (e.g., answer-level, step-by-step level)? | 4 | |
| Are all evaluation metrics (e.g., pass@k, maj@k) clearly defined? | 4 | |
| For any custom metrics (if exists), are they well-justified and clearly documented? | 4 | |
| Are the evaluation metrics consistently applied across all baselines? | 4 | |
| Are the evaluation conditions (e.g., temperature, top-p) explained for all compared methods? | 4 | |
| Open-Source (29) | Is the post-training data publicly available? | 3 |
| Is the synthetic long thought data publicly available? | 5 | |
| Are trained model weights publicly available? | 5 | |
| Is the complete training codebase publicly available? | 4 | |
| Is the complete evaluation codebase publicly released? | 4 | |
| Are there step-by-step guidance and instruction for code usage? | 4 | |
| Is there a comprehensive technical paper detailing all research aspects instead of a brief blog post? | 4 |
🔼 This table presents a scoring framework for evaluating the transparency of OpenAI’s O1 model replication attempts. It breaks down the evaluation into four key dimensions: Data Transparency, Methodology Transparency, Evaluation Transparency, and Open-Source Resources. Each dimension is further divided into specific criteria, each assigned a point value (detailed in the checklist). The total score sums up to 100 points, providing a quantitative measure of how reproducible and verifiable each replication attempt is. Higher scores indicate greater transparency.
read the caption
Table 3: Transparency scoring framework for O1 replication efforts. Each evaluation point of the checklist is assigned a score based on their transparency criteria. The total transparency score sums up to 100 points.
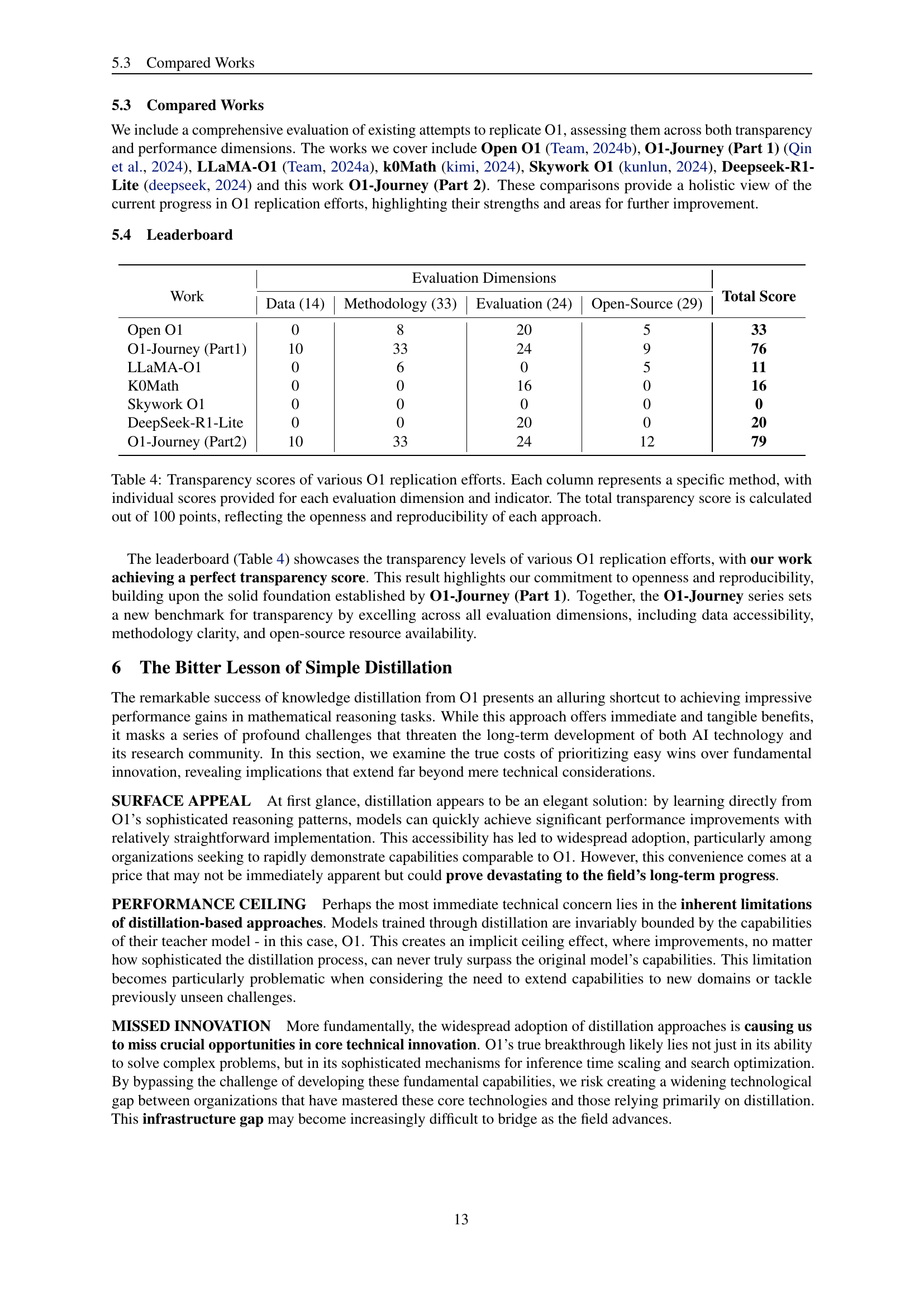
| Work | Data (14) | Methodology (33) | Evaluation (24) | Open-Source (29) | Total Score | |
|---|---|---|---|---|---|---|
| Open O1 | 0 | 8 | 20 | 5 | 33 | |
| O1-Journey (Part1) | 10 | 33 | 24 | 9 | 76 | |
| LLaMA-O1 | 0 | 6 | 0 | 5 | 11 | |
| K0Math | 0 | 0 | 16 | 0 | 16 | |
| Skywork O1 | 0 | 0 | 0 | 0 | 0 | |
| DeepSeek-R1-Lite | 0 | 0 | 20 | 0 | 20 | |
| O1-Journey (Part2) | 10 | 33 | 24 | 12 | 79 |
🔼 This table presents a comparative analysis of several attempts to replicate OpenAI’s O1 model, focusing on their transparency and reproducibility. Each method is assessed across four key dimensions: data transparency (data sources, quality, and documentation), methodology transparency (clarity of techniques, processes, and experimental setup), evaluation transparency (benchmarks and metrics used), and open-source resources (availability of datasets, models, and code). Each dimension is assigned a score out of a possible 100, providing an overall transparency score for each replication attempt. Higher scores indicate greater openness and reproducibility.
read the caption
Table 4: Transparency scores of various O1 replication efforts. Each column represents a specific method, with individual scores provided for each evaluation dimension and indicator. The total transparency score is calculated out of 100 points, reflecting the openness and reproducibility of each approach.
Full paper#