↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Traditional AI evaluation methods often struggle with judging subtle attributes and delivering satisfactory results. Static metrics, like BLEU and ROUGE, are computationally efficient but lack flexibility for open-ended tasks, while embedding-based methods, though more flexible, still struggle to capture various nuances. The LLM-as-a-judge paradigm offers a new approach for addressing this challenge. This paper provides a survey of this emerging field, offering a thorough overview of LLM-based judgment and assessment.
The paper introduces a taxonomy exploring LLM-as-a-judge from three dimensions: what to judge (attributes like helpfulness and harmlessness), how to judge (tuning and prompting techniques), and where to judge (applications in evaluation, alignment, retrieval, and reasoning). It presents a compilation of benchmarks for evaluating LLMs and discusses limitations of the current methods. It also pinpoints key challenges and future directions such as addressing biases, dynamic judgment, and human-LLM co-judgment. The taxonomy and benchmarks provided will be highly valuable resources for researchers working on evaluation, alignment, retrieval, and reasoning.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it explores a novel paradigm of using LLMs for judgment and assessment tasks. This addresses limitations of traditional methods and opens avenues for improving various AI applications like evaluation, alignment, and reasoning. The comprehensive taxonomy and benchmark provided are invaluable resources for future research. It’s highly relevant to the current trend of using LLMs for complex reasoning and decision-making, offering new possibilities.
Visual Insights#

🔼 This figure illustrates the different input and output types used in LLM-as-a-judge systems. The input can be a single candidate (point-wise) or multiple candidates (pair-wise or list-wise). The output can be a score for each candidate, a ranking of candidates, or a selection of the best candidates.
read the caption
Figure 1: Overview of various input and output formats of LLM-as-a-judge.
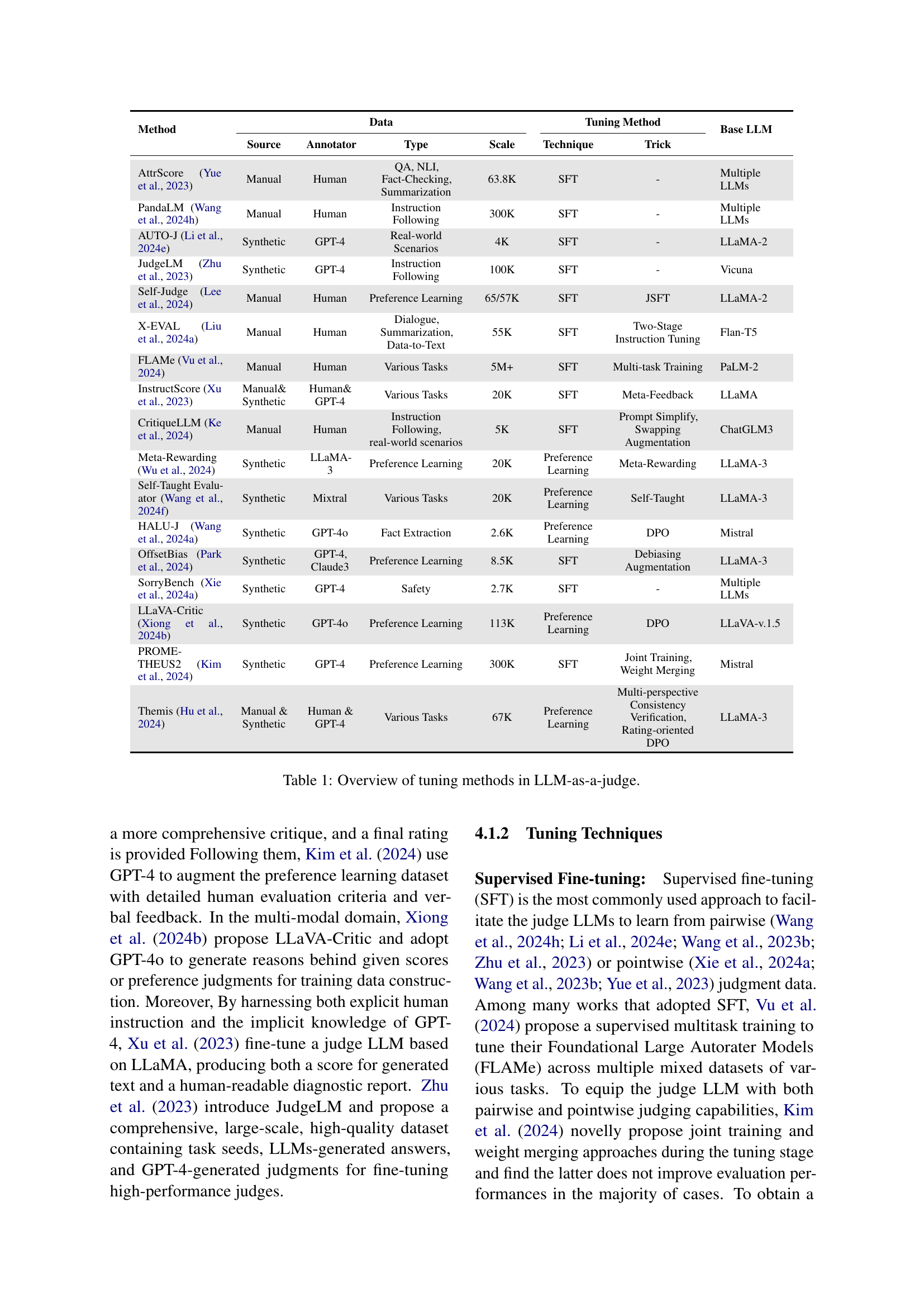
| Method | Data Source | Data Annotator | Data Type | Data Scale | Tuning Technique | Tuning Trick | Base LLM |
|---|---|---|---|---|---|---|---|
| AttrScore [Yue et al. (2023)] | Manual | Human | QA, NLI, Fact-Checking, Summarization | 63.8K | SFT | - | Multiple LLMs |
| PandaLM [Wang et al. (2024h)] | Manual | Human | Instruction Following | 300K | SFT | - | Multiple LLMs |
| AUTO-J [Li et al. (2024e)] | Synthetic | GPT-4 | Real-world Scenarios | 4K | SFT | - | LLaMA-2 |
| JudgeLM [Zhu et al. (2023)] | Synthetic | GPT-4 | Instruction Following | 100K | SFT | - | Vicuna |
| Self-Judge [Lee et al. (2024)] | Manual | Human | Preference Learning | 65/57K | SFT | JSFT | LLaMA-2 |
| X-EVAL [Liu et al. (2024a)] | Manual | Human | Dialogue, Summarization, Data-to-Text | 55K | SFT | Two-Stage Instruction Tuning | Flan-T5 |
| FLAMe [Vu et al. (2024)] | Manual | Human | Various Tasks | 5M+ | SFT | Multi-task Training | PaLM-2 |
| InstructScore [Xu et al. (2023)] | Manual& Synthetic | Human& GPT-4 | Various Tasks | 20K | SFT | Meta-Feedback | LLaMA |
| CritiqueLLM [Ke et al. (2024)] | Manual | Human | Instruction Following, real-world scenarios | 5K | SFT | Prompt Simplify, Swapping Augmentation | ChatGLM3 |
| Meta-Rewarding [Wu et al. (2024)] | Synthetic | LLaMA-3 | Preference Learning | 20K | Preference Learning | Meta-Rewarding | LLaMA-3 |
| Self-Taught Evaluator [Wang et al. (2024f)] | Synthetic | Mixtral | Various Tasks | 20K | Preference Learning | Self-Taught | LLaMA-3 |
| HALU-J [Wang et al. (2024a)] | Synthetic | GPT-4o | Fact Extraction | 2.6K | Preference Learning | DPO | Mistral |
| OffsetBias [Park et al. (2024)] | Synthetic | GPT-4, Claude3 | Preference Learning | 8.5K | SFT | Debiasing Augmentation | LLaMA-3 |
| SorryBench [Xie et al. (2024a)] | Synthetic | GPT-4 | Safety | 2.7K | SFT | - | Multiple LLMs |
| LLaVA-Critic [Xiong et al. (2024b)] | Synthetic | GPT-4o | Preference Learning | 113K | Preference Learning | DPO | LLaVA-v.1.5 |
| PROME-THEUS2 [Kim et al. (2024)] | Synthetic | GPT-4 | Preference Learning | 300K | SFT | Joint Training, Weight Merging | Mistral |
| Themis [Hu et al. (2024)] | Manual & Synthetic | Human & GPT-4 | Various Tasks | 67K | Preference Learning | Multi-perspective Consistency Verification, Rating-oriented DPO | LLaMA-3 |
🔼 This table provides a comprehensive overview of various methods used to fine-tune Large Language Models (LLMs) for the specific task of acting as a judge. It details the data source used for training (manually labeled or synthetic data), the annotator involved (humans or other LLMs), the type of data, the scale of the dataset, the specific fine-tuning techniques employed, any additional tricks used to improve performance, and the base LLM used as a starting point. This allows for a detailed comparison of different approaches to training LLMs for judgment tasks.
read the caption
Table 1: Overview of tuning methods in LLM-as-a-judge.
In-depth insights#
LLM Judgment#
LLM judgment, the use of Large Language Models (LLMs) to assess and evaluate various aspects of generated text or other outputs, presents a paradigm shift in automated assessment. Traditional methods often struggle with nuanced evaluation, whereas LLMs offer the potential for more comprehensive and human-like judgment. However, this potential is tempered by significant challenges. Bias, both inherent in the training data and arising from the LLM’s architecture, is a major concern. Issues of fairness, reliability, and vulnerability to adversarial attacks need careful consideration. Despite these challenges, LLM-based evaluation offers substantial advantages in handling complex attributes, enabling fine-grained assessments that surpass the capabilities of simpler, static metrics. Future research needs to focus on mitigating bias, enhancing robustness against manipulation, and exploring the integration of human feedback to ensure accuracy and reliability in a variety of applications, ranging from evaluating generated text to more complex tasks involving reasoning and decision-making.
LLM Tuning#
LLM tuning for judgment tasks is a crucial aspect, focusing on adapting large language models (LLMs) to effectively perform evaluation roles. Supervised fine-tuning (SFT), using human-labeled data, is a common approach. However, data scarcity and cost are limitations. To mitigate this, researchers leverage synthetic feedback, where the LLM itself generates judgments for training, or use a combination of human and synthetic data. Different tuning techniques, such as preference learning and reinforcement learning, are used to optimize the LLM’s judgment capabilities. The choice of tuning methodology depends on the specific task, available resources, and desired level of performance. Benchmarking and evaluation are vital to ensure that the tuning process yields unbiased and reliable LLM judges, addressing inherent challenges like bias, vulnerability, and the dynamic nature of language.
Bias in LLMs#
Large Language Models (LLMs) are susceptible to various biases, stemming from biases present in their training data. These biases can manifest in several ways, impacting the fairness and reliability of LLM outputs. For example, gender bias may lead to LLMs associating certain professions predominantly with one gender, while racial bias could result in unfair or stereotypical representations of different ethnic groups. Other biases include those related to age, socioeconomic status, and political viewpoints. Addressing these biases is crucial. Mitigation strategies involve careful curation of training data to ensure balanced representation, employing techniques like data augmentation and debiasing algorithms, and developing robust evaluation methods to identify and measure biases. Furthermore, continuous monitoring and refinement of LLMs post-deployment are necessary to address emerging biases and to maintain fairness. The inherent complexity of human language, coupled with the potential for unintended bias propagation, presents a significant challenge. Open research and ongoing advancements in fairness-aware LLM development are essential to minimize bias and improve the ethical and responsible deployment of these powerful technologies.
Future of LLMs#
The future of LLMs hinges on addressing current limitations and exploring new capabilities. Bias mitigation is crucial, requiring techniques to reduce reliance on potentially biased training data and incorporating fairness metrics into evaluation. Improved reasoning and complex judgment capabilities are vital. Future research will likely focus on enhanced architectures, training methods and prompting strategies that facilitate more nuanced and contextual understanding. Self-evaluation and self-improvement mechanisms will become increasingly prominent, enabling LLMs to adapt and refine their responses without extensive human oversight. Multimodal capabilities will be further developed, integrating textual data with images, audio and other data modalities to broaden the scope of LLM applications. Human-LLM collaboration will likely increase, leveraging human expertise for tasks that still present difficulties for LLMs while using LLMs to improve efficiency and scale. Ultimately, the future of LLMs will focus on developing more trustworthy, reliable and ethically sound systems, capable of complex problem solving and decision-making, while remaining accountable and transparent.
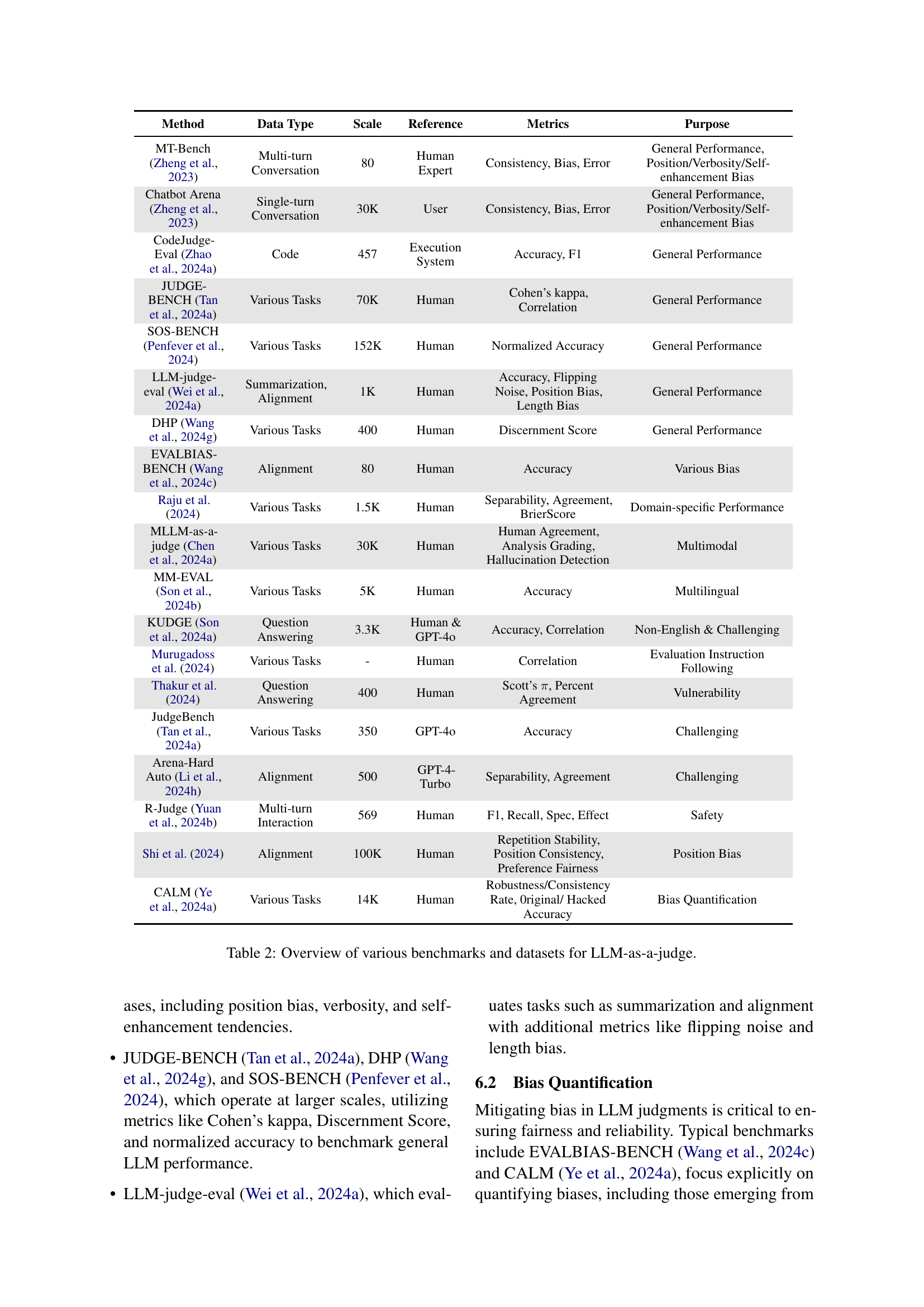
LLM Benchmarks#
LLM benchmarks are crucial for evaluating the capabilities and limitations of large language models. A robust benchmark suite needs to cover a wide range of tasks, including text generation, question answering, translation, and reasoning, to offer a comprehensive assessment. It’s vital to consider diverse evaluation metrics beyond simple accuracy, incorporating factors like fluency, coherence, relevance, and bias. Furthermore, benchmarks must account for potential biases in the LLM’s training data and ensure fairness across different demographics and contexts. The development of standardized benchmarks is an ongoing effort, with researchers continually striving to create more comprehensive, nuanced, and reliable evaluation tools that can keep pace with the rapid evolution of LLM technology. Benchmarking should extend to assessing aspects beyond accuracy, including efficiency, safety, and alignment with human values, to capture the broader impact and societal implications of LLMs. The creation and improvement of LLM benchmarks are crucial for promoting responsible development and deployment of these powerful models, ultimately helping to ensure their beneficial use and minimize potential harm.
More visual insights#
More on figures

🔼 This figure presents a comprehensive taxonomy of research on using Large Language Models (LLMs) as evaluators. It breaks down the research into three key aspects: What is being evaluated (attributes such as helpfulness, harmlessness, etc.), how the evaluation is performed (methodology such as fine-tuning, prompting techniques, etc.), and where this type of LLM evaluation is used (applications in areas like alignment, retrieval, reasoning, etc.). The taxonomy is presented as a tree diagram, allowing for a detailed exploration of the various sub-categories and their interrelationships within the field of LLM-as-a-judge.
read the caption
Figure 2: Taxonomy of research in LLM-as-a-judge that consists of judging attribution, methodology and application.

🔼 This figure shows the different attributes that Large Language Models (LLMs) can effectively judge. These attributes are key aspects often evaluated in various natural language processing (NLP) tasks, such as the helpfulness, harmlessness, reliability, relevance, feasibility, and overall quality of generated text or other outputs. The image visually represents the multifaceted evaluation capabilities of LLMs, demonstrating their potential to go beyond simple metrics in assessing the nuanced aspects of text and other outputs.
read the caption
Figure 3: LLMs are capable of judging various attributes.

🔼 This figure illustrates six different prompting strategies used in LLM-as-a-judge systems. Each strategy aims to improve the accuracy and effectiveness of LLMs in performing judgment tasks by addressing specific limitations or biases. The strategies shown are: Swapping Operation, Rule Augmentation, Multi-agent Collaboration, Demonstration, Multi-turn Interaction, and Comparison Acceleration. Each strategy is visually represented with a flowchart to depict the process involved.
read the caption
Figure 4: Overview of prompting strategies for LLM-as-a-judge.
Full paper#