↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Storytelling video generation (SVG) faces challenges in creating long videos with complex, fine-grained motions of multiple objects that consistently appear across scenes. Existing methods struggle to manage smooth transitions and dynamic interactions. This limits realistic and engaging storytelling in videos.
DREAMRUNNER tackles this by using LLMs for hierarchical video planning, which improves both coarse-grained and fine-grained control. It introduces retrieval-augmented test-time adaptation to capture motion priors and injects them into a novel spatial-temporal region-based 3D attention module. This enables fine-grained control, ensuring smooth transitions and dynamic interactions between objects. The method achieves state-of-the-art results on various benchmarks, outperforming prior approaches in aspects like character consistency, text alignment, and smooth transitions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DREAMRUNNER, a novel approach to storytelling video generation that significantly improves the quality and coherence of generated videos. This is achieved through a two-stage LLM planning process, retrieval-augmented motion adaptation, and a novel spatial-temporal region-based 3D attention module. The results show state-of-the-art performance on several benchmarks, demonstrating the effectiveness of the approach and opening new avenues for research in long-form video generation. The open-source nature of the core model also boosts its potential impact.
Visual Insights#

🔼 DreamRunner’s pipeline consists of three stages: plan generation, motion and subject prior learning, and video generation. In the plan generation stage, a large language model (LLM) creates a hierarchical plan from the user’s story, including both high-level scene outlines and detailed, frame-level descriptions. The next stage uses a video database to find videos relevant to the planned motions and images to represent the characters. Test-time fine-tuning uses this data to learn priors for motion and character appearance. The final stage generates the video using a diffusion model enhanced with SR3AI (a novel spatial-temporal region-based 3D attention and prior injection module) for more precise control.
read the caption
Figure 1: Overall pipeline for DreamRunner. (1) plan generation stage: we employ an LLM to craft a hierarchical video plan (i.e., “High-Level Plan” and “Fine-Grained Plan”) from a user-provided generic story narration. (2.1) motion retrieval and prior learning stage: we retrieve videos relevant to the desired motions from a video database for learning the motion prior through test-time fine-tuning. (2.2) subject prior learning stage: we use reference images for learning the subject prior through test-time fine-tuning. (3) video generation with region-based diffusion stage: we equipt diffusion model with a novel spatial-temporal region-based 3D attention and prior injection module (i.e., SR3AI) for video generation with fine-grained control.
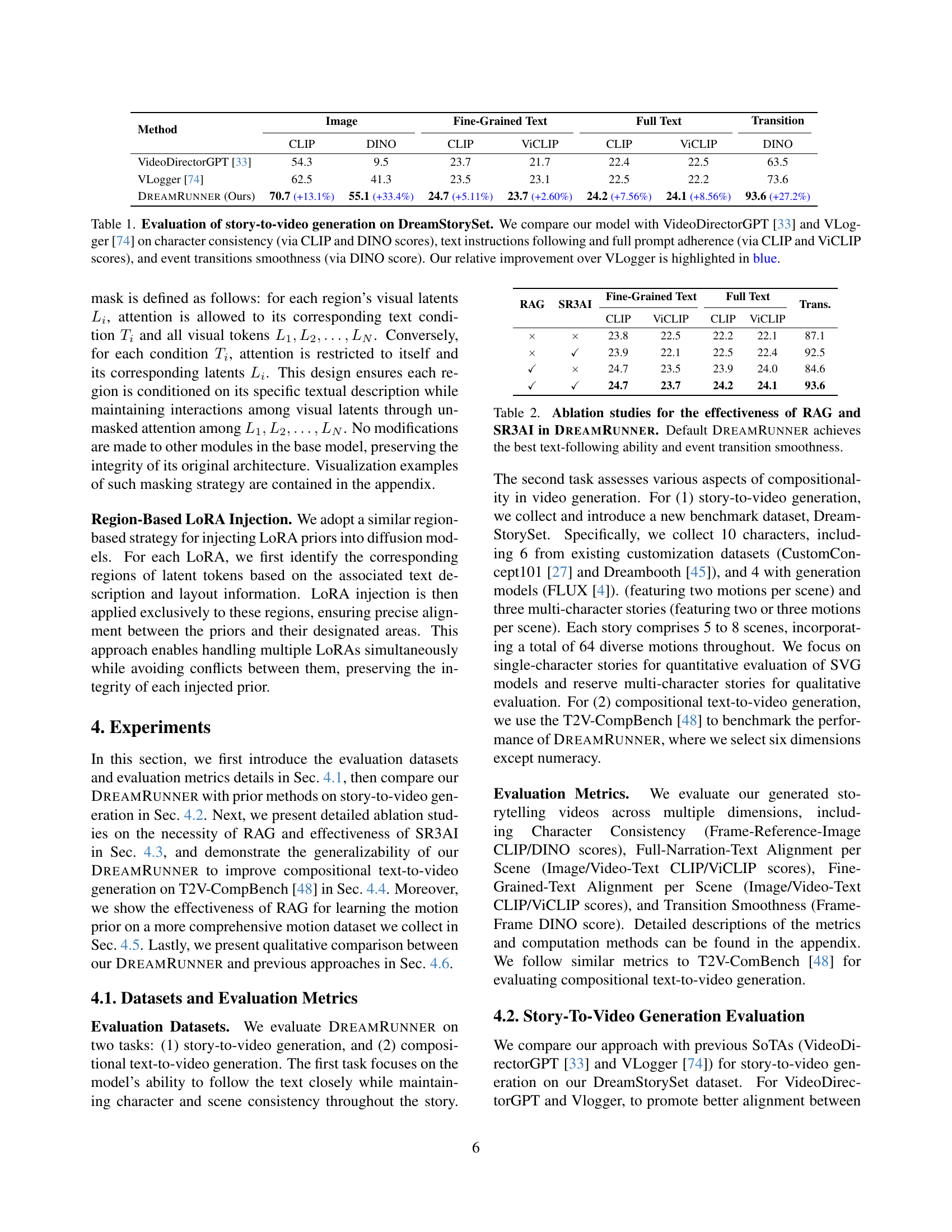
| Method | Image (CLIP) | Image (DINO) | Fine-Grained Text (CLIP) | Fine-Grained Text (ViCLIP) | Full Text (CLIP) | Full Text (ViCLIP) | Transition (DINO) |
|---|---|---|---|---|---|---|---|
| VideoDirectorGPT [33] | 54.3 | 9.5 | 23.7 | 21.7 | 22.4 | 22.5 | 63.5 |
| VLogger [74] | 62.5 | 41.3 | 23.5 | 23.1 | 22.5 | 22.2 | 73.6 |
| DreamRunner (Ours) | 70.7 (+13.1%) | 55.1 (+33.4%) | 24.7 (+5.11%) | 23.7 (+2.60%) | 24.2 (+7.56%) | 24.1 (+8.56%) | 93.6 (+27.2%) |
🔼 This table presents a quantitative evaluation of story-to-video generation models on the DreamStorySet dataset. The performance of DREAMRUNNER is compared against two state-of-the-art baselines: VideoDirectorGPT and VLogger. The evaluation metrics assess three key aspects of video generation quality: 1. Character Consistency: Measured using CLIP and DINO scores, this metric evaluates how well the model maintains consistent visual representations of characters across different scenes and throughout the video. 2. Text Adherence: Assessed using CLIP and ViCLIP scores, this metric measures the model’s ability to follow both the overall story instructions and the fine-grained descriptions of individual events within each scene. 3. Transition Smoothness: Evaluated using DINO scores, this metric determines the fluidity and naturalness of transitions between consecutive events within a scene. The table highlights DREAMRUNNER’s superior performance compared to the baselines across all three metrics. Improvements relative to the VLogger baseline are explicitly indicated in blue.
read the caption
Table 1: Evaluation of story-to-video generation on DreamStorySet. We compare our model with VideoDirectorGPT [33] and VLogger [74] on character consistency (via CLIP and DINO scores), text instructions following and full prompt adherence (via CLIP and ViCLIP scores), and event transitions smoothness (via DINO score). Our relative improvement over VLogger is highlighted in blue.
In-depth insights#
Dual-Level Planning#
Dual-level planning, as a concept, offers a powerful approach to storytelling video generation by addressing the complexity of creating coherent and engaging narratives. The methodology likely involves a hierarchical structure: a high-level plan first outlines major events and scene transitions, ensuring the overall narrative arc is compelling and logically structured. This macro-level planning allows for easy comprehension of the story’s main beats. Then, a fine-grained plan focuses on the details within each scene—individual object motions, character interactions, and precise spatial layouts—to translate the macro-level storyline into a tangible visual experience. This two-pronged approach allows for both creative freedom and procedural control. The high-level plan guides the overarching narrative while the fine-grained plan ensures the details support and enrich the story, resolving potential conflicts between overall story structure and localized scenes. This is crucial for maintaining visual coherence and immersive storytelling.
Retrieval Adaptation#
Retrieval adaptation, in the context of video generation, is a powerful technique that leverages external data to enhance the quality and diversity of generated videos. It addresses limitations of solely relying on training data by dynamically incorporating relevant information during the generation process. This is particularly useful when generating videos based on diverse textual descriptions or user prompts that require specific motions or interactions not fully represented within the model’s training set. The process typically involves retrieving relevant video clips from a large database that match the desired motion specified in the user input. These clips are then used to fine-tune the model’s parameters, either directly or through intermediate representations, to adapt its capabilities to the specific requirements. This technique offers several advantages. First, it significantly improves the realism and quality of the generated motion by grounding it in real-world examples. Second, it offers a mechanism for handling novel or complex actions, allowing the generation of videos that go beyond the limitations of existing training data. Third, retrieval adaptation provides a pathway to personalization and customization. By dynamically adapting the model, users can influence the style, motion, and content of the generated video based on their specific needs. However, it’s important to acknowledge some potential challenges. Effective retrieval methods are crucial for success, requiring efficient indexing and similarity measurement techniques to quickly locate appropriate video clips. Also, efficient adaptation strategies must be devised to avoid overfitting to the retrieved data and to retain the generalization capacity of the base model. Therefore, retrieval adaptation is a promising avenue for advancing video generation, particularly within the scope of storytelling video generation and other applications requiring diverse and high-quality motion control.
SR3AI Diffusion#
The heading “SR3AI Diffusion” suggests a novel approach to video generation using diffusion models. The “SR3AI” likely refers to a specific architectural component, perhaps a combination of Spatial, Regional, and Temporal attention mechanisms integrated into a 3D attention framework. This architecture likely aims for fine-grained control over video generation by attending to specific spatial regions and their temporal evolution. This allows for more precise manipulation of objects and their movements within the video, addressing the challenges of storytelling video generation that require intricate control over character actions and their relationships in multi-scene, multi-object contexts. The diffusion model itself likely utilizes a powerful generative process, learning the complex distribution of natural videos. By combining diffusion model capabilities with SR3AI’s fine-grained control, the method likely achieves high-quality, coherent videos that closely align with textual descriptions of complex narratives. The integration of prior learning, possibly using retrieval techniques, also points to the enhancement of the diffusion model’s performance and ability to generate diverse, contextually relevant videos.
Motion Priors#
Motion priors represent a crucial concept in video generation, particularly for storytelling applications. They encapsulate the knowledge of how objects typically move and interact within specific contexts. Effective motion priors are essential for generating realistic and believable videos, avoiding unnatural or jerky movements. The use of a large language model (LLM) to structure the input script is helpful, providing both coarse-grained scene planning and fine-grained object-level layout and motion planning. A well-designed motion prior learning strategy, like the retrieval-augmented test-time adaptation in DREAMRUNNER, allows the model to learn from a diverse set of real-world video examples, improving the diversity and quality of generated motions. The method of incorporating these priors into the generation process is also important. DREAMRUNNER utilizes a novel spatial-temporal region-based 3D attention and prior injection module (SR3AI) to achieve fine-grained control, ensuring that the learned motion priors are applied precisely to the relevant objects and regions in each frame. Without effective motion priors, generated videos would likely lack the smoothness, naturalness, and coherence needed to truly capture the essence of storytelling.
Compositional SVG#
Compositional Storytelling Video Generation (SVG) presents a significant challenge in AI, demanding the ability to generate videos with multiple objects, each exhibiting diverse and complex motions, while maintaining narrative coherence across multiple scenes. A compositional approach is crucial because it moves beyond simply stringing together individual video clips. Effective compositional SVG necessitates sophisticated planning and control, not just of individual actions but also of the spatial and temporal relationships between objects and scenes. This implies a deeper level of semantic understanding, going beyond simple keyword recognition to grasp the narrative flow and the interplay between characters or objects. Successful systems must incorporate robust methods for motion planning and coordination, potentially leveraging techniques like large language models (LLMs) for high-level narrative structuring and fine-grained control mechanisms such as diffusion models for generating the actual video frames. The core challenge lies in harmoniously integrating these different components to produce seamless and believable results. This requires not just technical proficiency but also a deep understanding of storytelling principles and human perception of motion and visual narratives. Research in this area should prioritize creating evaluation metrics that assess not just individual components but the overall quality of the storytelling experience, to ensure that advancements truly reflect progress towards human-level narrative video generation.
More visual insights#
More on figures

🔼 This figure details the architecture of the region-based diffusion model used in DREAMRUNNER for video generation. It shows how the model extends the standard self-attention mechanism to incorporate spatial and temporal information at a regional level. This is achieved through a novel spatial-temporal region-based 3D attention module (shown in orange), which uses region-specific masks to align different regions of the video with their corresponding text descriptions from the input prompt. Furthermore, character and motion priors (yellow and blue, respectively) are injected into the model via learned LoRA (Low-Rank Adaptation) modules, interleaving them into the attention and feed-forward (FFN) layers of each transformer block. This allows for fine-grained control over the generation process. While the visual tokens are shown resized into a 2D sequential format for easier visualization, it’s crucial to remember that they are processed in a flattened format and concatenated with the conditions before region-based attention is applied.
read the caption
Figure 2: Implementation details for region-based diffusion. We extend the vanilla self-attention mechanism to spatial-temporal-region-based 3D attention (see upper orange part), which is capable of aligning different regions with their respective text descriptions via region-specific masks. The region-based character and motion LoRAs (see lower yellow and blue parts) are then injected interleavingly to the attention and FFN layers in each transformer block (see the right part). Note that although we resize the visual tokens into sequential 2D latent frames for better visualization, they are flattened and concatenated with all conditions when performing region-based attention.

🔼 This figure presents a qualitative comparison of DREAMRUNNER’s performance against other state-of-the-art story-to-video generation models. The comparison focuses on multi-scene videos with multiple objects. DREAMRUNNER demonstrates superior character consistency across multiple scenes, a key challenge in storytelling video generation. In contrast, other methods struggle with character consistency, generating objects that don’t match reference images, or failing to produce the correct number of objects as specified in the story.
read the caption
Figure 3: Qualitative comparison of DreamRunner on multi-scene story generation with multiple objects. DreamRunner generates videos with significantly better character consistency compared to other strong baseline methods, while other methods either fail to maintain consistency for the same object across scenes (e.g., VLogger), fail to generate objects that match the reference images (e.g., VideoDirectorGPT), or fail to generate multiple objects correctly (e.g., CogVideoX w/ Character LoRAs).

🔼 DREAMRUNNER generates high-quality videos where multiple characters perform distinct actions simultaneously. The figure showcases several examples of videos generated by DREAMRUNNER, demonstrating the model’s ability to generate coherent and realistic videos where multiple characters perform complex actions. Each video clip includes captions that clearly describe the scene and actions being performed, emphasizing the model’s precise control over action binding.
read the caption
Figure 4: Qualitative results of DreamRunner generated with prompts characterizing action binding.

🔼 Figure 5 showcases DREAMRUNNER’s ability to maintain consistent attributes for objects across multiple frames and scenes. The figure presents several example video sequences generated from text prompts. Each sequence demonstrates that the specified attributes remain consistent even as the object’s position or surrounding context changes. This highlights DREAMRUNNER’s capacity to generate videos where object properties remain coherent throughout the narrative.
read the caption
Figure 5: Qualitative results of DreamRunner generated with prompts characterizing consistent attribute binding.

🔼 Figure 6 showcases several examples illustrating DREAMRUNNER’s ability to generate videos with dynamic changes in object attributes. Each example depicts a timelapse, showing gradual evolution of an attribute. For instance, the first example shows a pumpkin growing from a small bud to a large, ripe fruit. Other examples include a ceramic vase developing cracks and weathering with age, a piece of metal rusting over time, and a flower blooming. This demonstrates DreamRunner’s capacity to generate realistic sequences reflecting temporal changes in object properties.
read the caption
Figure 6: Qualitative results of DreamRunner generated with prompts characterizing dynamic attribute binding.

🔼 Figure 7 showcases several video clips generated by DreamRunner, each illustrating different types of motion. Each clip demonstrates the model’s ability to generate smooth, realistic movements that align with the textual prompt describing the character’s actions. This visualization highlights DreamRunner’s capacity for fine-grained control over character motion, ensuring the generated videos accurately reflect the specified actions, such as a kite flying left to right, a cyclist moving along a road, a robot walking through a factory, and bubbles floating upwards.
read the caption
Figure 7: Qualitative results of DreamRunner generated with prompts characterizing motion binding.

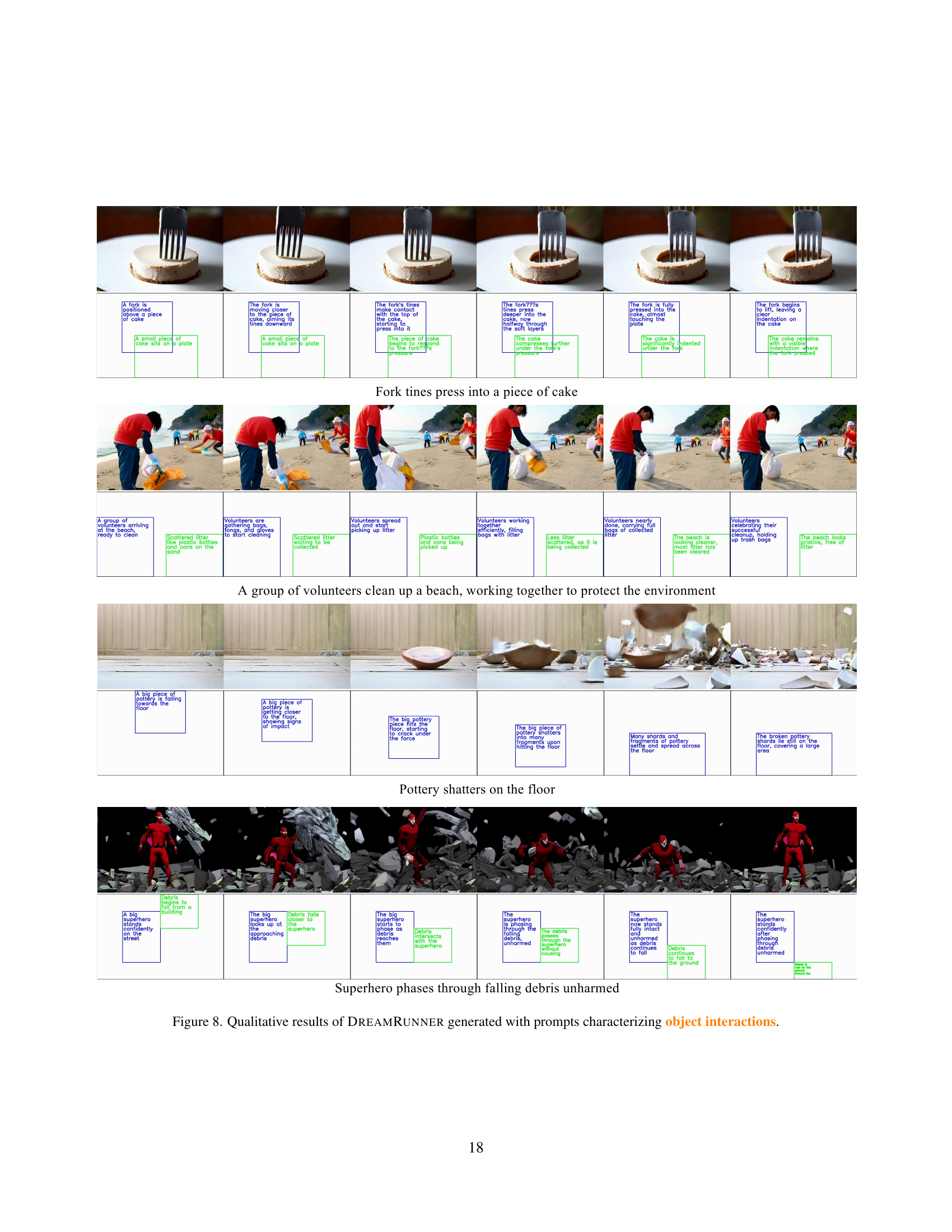
🔼 Figure 8 showcases DREAMRUNNER’s ability to generate videos depicting complex interactions between multiple objects. The examples demonstrate that DREAMRUNNER accurately renders these interactions according to physical laws and common sense, such as a fork pressing into a cake, volunteers cleaning a beach, pottery shattering on a floor, and a superhero phasing through falling debris. These examples highlight the model’s capacity to generate high-quality videos that faithfully represent multi-object interactions within a scene.
read the caption
Figure 8: Qualitative results of DreamRunner generated with prompts characterizing object interactions.

🔼 Figure 9 showcases qualitative examples from the DreamRunner model. Each example demonstrates the model’s ability to generate videos that accurately reflect specified spatial relationships between objects. The prompts given to the model emphasize spatial relationships (e.g., ‘a toddler walking on the left of a dog’, ‘a duck waddling below a spacecraft’). The resulting videos illustrate that the model successfully renders these relationships within a coherent visual scene, demonstrating strong spatial reasoning and scene composition capabilities.
read the caption
Figure 9: Qualitative results of DreamRunner generated with prompts characterizing spatial relationships.

🔼 Figure 10 shows example videos generated by DreamRunner. The videos showcase the model’s ability to maintain character consistency throughout a storyline, even with the complex motion of a mermaid. The images presented demonstrate the model’s capability to generate high-quality videos of a single character completing various actions and interacting with its environment.
read the caption
Figure 10: Qualitative results of DreamRunner generated with a single character (mermaid).

🔼 This figure showcases a series of six video frames generated by DreamRunner, depicting an astronaut’s journey on an alien planet. The frames illustrate the astronaut’s arrival, exploration of diverse terrains, interaction with alien flora and artifacts, and finally, a moment of reflection. Each frame is accompanied by a short description detailing the astronaut’s actions and the environment. The scenes progress from the astronaut’s landing, exploring a rocky landscape, discovering a glowing plant in a mysterious forest, examining ancient ruins, and concluding with the astronaut watching a sunset from atop a cliff.
read the caption
Figure 11: Qualitative results of DreamRunner generated with a single character (astronaut).

🔼 This figure showcases a sequence of video frames generated by the DreamRunner model, depicting a mermaid interacting with various underwater environments. It provides a qualitative assessment of the model’s ability to generate consistent and coherent video content featuring a single character across multiple scenes. Each scene highlights the mermaid’s actions and interactions in diverse locations, such as a coral reef, a sunken ship, an open ocean, a kelp forest, a sea cave, and a lagoon. The frames demonstrate seamless transitions between scenes and realistic movement and interactions of the character. The objective is to visually illustrate the model’s performance in generating a long-form, coherent video narrative with complex motions and detailed environmental context.
read the caption
Figure 12: Qualitative results of DreamRunner generated with a single character (mermaid).

🔼 This figure showcases a series of video frames generated by DreamRunner, a storytelling video generation model. The frames depict a witch and her cat engaging in various activities throughout a single day. The scenes progress chronologically, illustrating the witch performing magic, interacting with nature, resting at home, and ending the day in her garden. The model consistently generates coherent and detailed depictions of the witch and her cat, showcasing fine-grained motions and interactions. The video highlights the model’s ability to maintain character consistency and produce fluid scene transitions.
read the caption
Figure 13: Qualitative results of DreamRunner generated with multiple characters (witch and cat 1).

🔼 This figure showcases the qualitative results of the DREAMRUNNER model, demonstrating its ability to generate videos with multiple characters interacting naturally within a scene. The video depicts a warrior and their dog across multiple scenes, each illustrating the model’s fine-grained motion control, character consistency, and ability to generate coherent narratives across various situations. The scenes vary in setting and activity, ranging from the warrior stretching and practicing, to resting by a river, to archery practice in a bamboo forest, and finally, setting up camp at night. The dog is consistently present and interacts appropriately with the warrior in each setting.
read the caption
Figure 14: Qualitative results of DreamRunner generated with multiple characters (warrior and dog 2).
More on tables
| RAG | SR3AI | Fine-Grained Text CLIP | Fine-Grained Text ViCLIP | Full Text CLIP | Full Text ViCLIP | Trans. |
|---|---|---|---|---|---|---|
| × | × | 23.8 | 22.5 | 22.2 | 22.1 | 87.1 |
| × | ✓ | 23.9 | 22.1 | 22.5 | 22.4 | 92.5 |
| ✓ | × | 24.7 | 23.5 | 23.9 | 24.0 | 84.6 |
| ✓ | ✓ | 24.7 | 23.7 | 24.2 | 24.1 | 93.6 |
🔼 This ablation study analyzes the individual and combined effects of Retrieval Augmented Generation (RAG) and the Spatial-Temporal Region-Based 3D Attention and Prior Injection module (SR3AI) on the DreamRunner model’s performance. It compares the model’s text-following ability (measured by CLIP and ViCLIP scores) and event transition smoothness (measured by DINO score) across four variations: 1. Baseline: The default DreamRunner model. 2. With RAG: The model using RAG but without SR3AI. 3. With SR3AI: The model using SR3AI but without RAG. 4. With RAG and SR3AI: The complete DreamRunner model. The results demonstrate the importance of both RAG and SR3AI for optimal performance, with the full model achieving the highest scores in both text alignment and transition quality.
read the caption
Table 2: Ablation studies for the effectiveness of RAG and SR3AI in DreamRunner. Default DreamRunner achieves the best text-following ability and event transition smoothness.
| Model | Consist-attr | Dynamic-attr | Spatial | Motion | Action | Interaction |
|---|---|---|---|---|---|---|
| Gen-3 [5] | 0.7045 | 0.2078 | 0.5533 | 0.3111 | 0.6280 | 0.7900 |
| Dreamina [2] | 0.8220 | 0.2114 | 0.6083 | 0.2391 | 0.6660 | 0.8175 |
| PixVerse [3] | 0.7370 | 0.1738 | 0.5874 | 0.2178 | 0.6960 | 0.8275 |
| Kling [6] | 0.8045 | 0.2256 | 0.6150 | 0.2448 | 0.6460 | 0.8475 |
| VideoCrafter2 [10] | 0.6750 | 0.1850 | 0.4891 | 0.2233 | 0.5800 | 0.7600 |
| Open-Sora 1.2 [20] | 0.6600 | 0.1714 | 0.5406 | 0.2388 | 0.5717 | 0.7400 |
| Open-Sora-Plan v1.1.0 [28] | 0.7413 | 0.1770 | 0.5587 | 0.2187 | 0.6780 | 0.7275 |
| VideoTetris [49] | 0.7125 | 0.2066 | 0.5148 | 0.2204 | 0.5280 | 0.7600 |
| LVD [31] | 0.5595 | 0.1499 | 0.5469 | 0.2699 | 0.4960 | 0.6100 |
| CogVideoX-2B [62] | 0.6775 | 0.2118 | 0.4848 | 0.2379 | 0.5700 | 0.7250 |
| CogVideoX-2B+Ours [62] | 0.7350 | 0.2672 | 0.6040 | 0.2608 | 0.5840 | 0.8225 |
🔼 This table presents a quantitative comparison of DREAMRUNNER against various other models on the T2V-CompBench benchmark. The benchmark evaluates several aspects of compositional video generation, including attribute binding (consistency of attributes across scenes), dynamic attributes (changes in attributes over time), spatial relationships (correct positioning of objects), motion (naturalness of movements), and action interaction (realistic interactions between objects). Open-source models are distinguished from closed-source models, and the best and second-best scores for open-source models are highlighted in bold and underlined, respectively. The best score among closed-source models is highlighted in yellow.
read the caption
Table 3: T2V-CompBench evaluation results. Best/2nd best scores for open-sourced models are bolded/underlined. gray indicates close-sourced models, and yellow indicates the best score for close-sourced models.
| Method | CLIP | ViCLIP |
|---|---|---|
| CogVideoX-2B | 23.39 | 20.84 |
| CogVideoX-2B + RAG | 24.67 | 23.04 |
🔼 This table presents an ablation study evaluating the impact of the retrieval-augmented test-time adaptation technique on learning motion priors. It compares the performance of a baseline model (CogVideoX-2B) against a model enhanced with the retrieval-augmented approach. The comparison is based on CLIP and ViCLIP scores, which measure the alignment between generated videos and textual descriptions. Higher scores indicate better alignment and thus a more effective motion prior learning.
read the caption
Table 4: Effectiveness of our retrieval-augmented test-time adaptation for learning a better motion prior.
| Max. #Retrieval | CLIP+ViCLIP filter | CLIP | ViCLIP |
|---|---|---|---|
| 0 | × | 23.42 | 20.56 |
| 20 | × | 24.01 | 22.51 |
| 3 | ✓ | 24.45 | 22.80 |
| 20 | ✓ | 25.47 | 23.66 |
🔼 This table presents an ablation study on the retrieval-augmented test-time adaptation pipeline used for learning motion priors. It shows how different components of the pipeline affect the performance, specifically comparing the results with different maximum numbers of retrieved videos and the use of CLIP and ViCLIP for filtering. The goal is to determine the optimal configuration for effective motion prior learning.
read the caption
Table 5: Pipeline component ablation on retrieval-augmented test-time adaptation for learning a better motion prior.
Full paper#