↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image editing methods often struggle with accuracy and preserving image fidelity. They typically involve single-step transformations from source to target, often compromising key elements of the original image. This creates challenges in generating images that precisely reflect the intended edits.
Frame2Frame addresses this by reformulating image editing as a temporal process. The method uses pretrained video models to generate smooth transitions between the source image and the desired edit. This approach enables continuous edits while maintaining image fidelity. Experiments show that Frame2Frame significantly improves both edit accuracy and image preservation, outperforming other leading methods on established image editing benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes a novel approach to image editing by leveraging the advancements in video generation. This opens new avenues for research in image manipulation, bridging the gap between image and video processing. The improved accuracy and fidelity of image edits are also significant contributions with broad applications in various computer vision tasks.
Visual Insights#

🔼 This figure demonstrates the Frame2Frame method’s image editing process. It shows a sequence of images transitioning smoothly from a source image to a target image, representing the temporal evolution of the edit. The intermediate frames showcase the method’s ability to maintain consistency and preserve the fidelity of the original image while incorporating the desired edits. Each image represents a step in the transformation from the source to the target, illustrating a natural and temporally coherent process.
read the caption
Figure 1: Visualization of Frame2Frame’s editing process. Temporal progression of our video-based approach. Starting from the source image (leftmost), frames illustrate the natural evolution toward the target edit (rightmost). Our method produces temporally coherent intermediate states while preserving fidelity to both the source content and the editing intent.
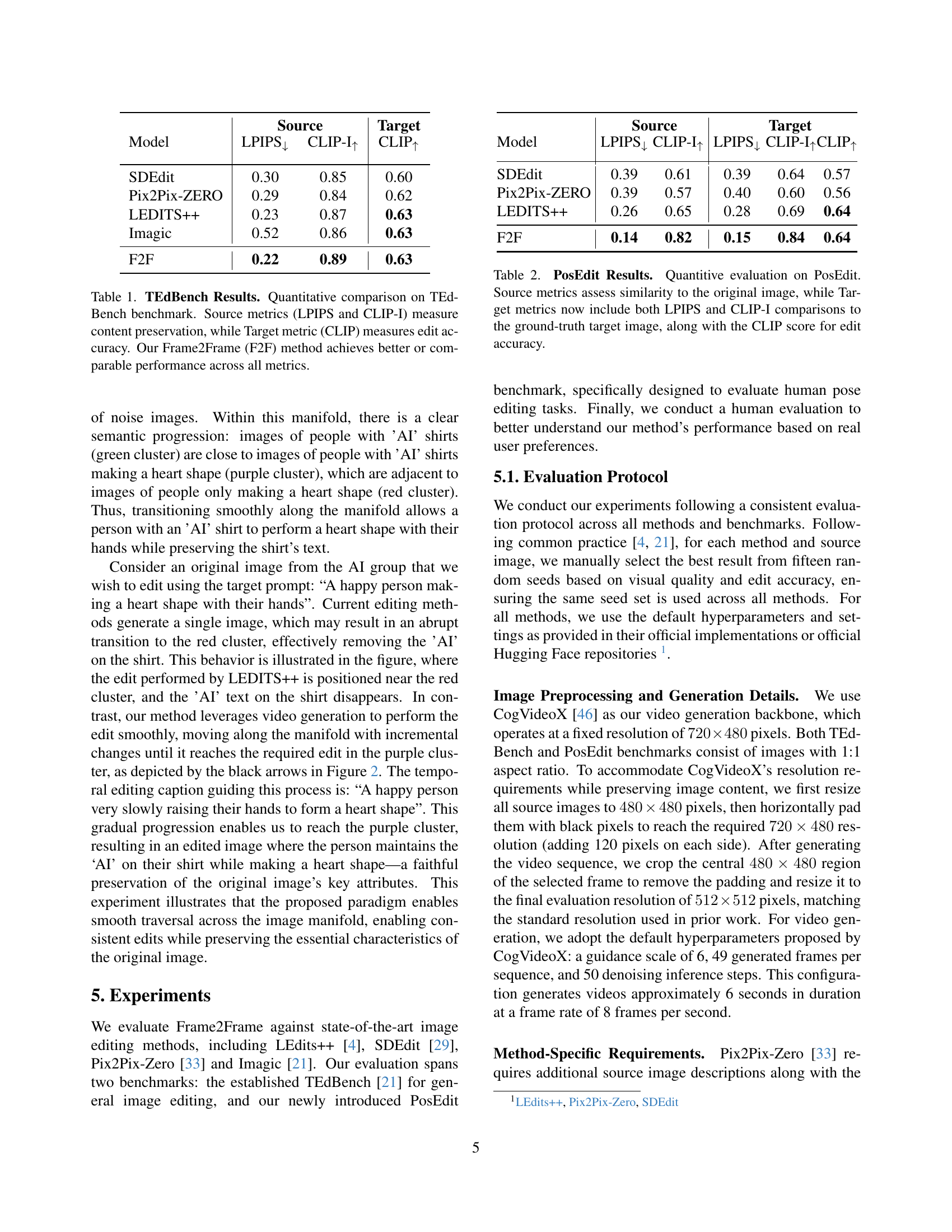
| Model | LPIPS↓ | CLIP-I↑ | CLIP↑ |
|---|---|---|---|
| SDEdit | 0.30 | 0.85 | 0.60 |
| Pix2Pix-ZERO | 0.29 | 0.84 | 0.62 |
| LEDITS++ | 0.23 | 0.87 | 0.63 |
| Imagic | 0.52 | 0.86 | 0.63 |
| F2F | 0.22 | 0.89 | 0.63 |
🔼 This table presents a quantitative comparison of the Frame2Frame (F2F) image editing method against several state-of-the-art methods on the TEdBench benchmark. The evaluation uses three metrics: LPIPS and CLIP-I (to assess how well the edited image preserves the content of the original image), and CLIP (to evaluate how accurately the edit matches the target description). Lower LPIPS scores and higher CLIP-I scores indicate better content preservation, while higher CLIP scores signify better edit accuracy. The results show that F2F either outperforms or achieves comparable results to existing methods across all metrics.
read the caption
Table 1: TEdBench Results. Quantitative comparison on TEdBench benchmark. Source metrics (LPIPS and CLIP-I) measure content preservation, while Target metric (CLIP) measures edit accuracy. Our Frame2Frame (F2F) method achieves better or comparable performance across all metrics.
In-depth insights#
Image Editing via Video#
The concept of “Image Editing via Video” presents a novel approach to image manipulation, transforming the static process into a dynamic, temporal one. Instead of directly generating a single edited image, this method uses video generation models to create a smooth transition from the original image to the desired edited state. This approach offers several advantages. First, it leverages the inherent temporal coherence and sophisticated world understanding of advanced video generation models, leading to more natural and realistic edits. Second, by traversing the image manifold through a continuous series of intermediate frames, the method mitigates the common issues of edit inaccuracy and source fidelity compromise found in traditional single-step image editing techniques. The temporal nature of this approach allows for complex edits to unfold gradually and plausibly, resulting in a higher degree of control and visual quality. However, this method also introduces challenges, primarily the increased computational cost associated with generating videos compared to directly generating a single image. The success of this approach hinges on the quality of the underlying video generation model and its ability to accurately capture and represent the intended edits within the generated video sequence. Future research might focus on optimization strategies to reduce computational overhead and further exploration of the application of this technique to various computer vision tasks beyond standard image editing.
Temporal Editing#
The concept of “Temporal Editing” introduces a novel approach to image manipulation by framing the process as a continuous transformation through time. Instead of directly generating a single edited image, this method leverages video generation models to create a smooth transition from the original image to the desired edited state. This temporal evolution allows for more natural and plausible intermediate stages, potentially reducing artifacts and enhancing fidelity. By leveraging temporal coherence inherent in video generation models, the approach offers a path towards resolving challenges present in traditional image editing methods. It addresses the difficulty of balancing precise edits with the preservation of key source image features by continuously traversing the image manifold. The temporal perspective enables fine-grained control and reduces the abruptness often observed in single-step image manipulation. This approach also presents interesting opportunities in other domains, potentially enabling novel applications in areas such as video manipulation and related computer vision tasks. The key strength lies in its ability to perform complex edits in a natural, visually consistent manner, which could significantly improve user experience and the quality of results.
Frame2Frame Method#
The core idea behind the hypothetical ‘Frame2Frame Method’ revolves around reframing image editing as a temporal process, leveraging the strengths of video generation models. Instead of directly transforming a source image into a target image, this method generates a short video depicting a smooth transition between the two. This approach offers several key advantages. First, it inherently handles the complexity of intricate edits by breaking them down into a series of smaller, manageable steps, reducing the risk of fidelity loss. Second, the continuous nature of the video allows for preservation of essential image characteristics throughout the transformation. Third, by utilizing pretrained video generation models, the method leverages the models’ understanding of temporal coherence and realistic world simulation, resulting in more plausible and visually appealing edits. The process involves three main steps: generating a temporal caption that describes the desired transformation, using a video generation model to create a video based on this caption, and finally selecting the optimal frame from the video representing the desired edit. This innovative method suggests potential improvements in both accuracy and visual quality of image editing, showcasing the synergistic benefits of merging image and video generation techniques. Further research could explore optimizations for computational efficiency and the exploration of various video generation model architectures to improve the quality and realism of generated transitions.
PosEdit Benchmark#
The PosEdit benchmark, a novel contribution of the research, is a significant advancement in evaluating image editing methods, particularly focusing on human pose manipulation. Unlike existing benchmarks that often lack ground truth pose data, PosEdit provides paired source and target images for each editing task, allowing for a more rigorous assessment of both edit accuracy and identity preservation. This rigorous approach allows researchers to evaluate not only how well the edits align with the desired pose but also how effectively the method retains the identity and characteristics of the subject in different poses. The detailed analysis of PosEdit, comprising 58 editing tasks across 8 action categories, demonstrates the benchmark’s ability to rigorously test various methods. This level of detail offers a nuanced and in-depth understanding of an image editing model’s performance, exceeding the capabilities of prior benchmarks. The inclusion of ground truth target images makes the PosEdit benchmark particularly valuable in evaluating the fidelity of edits and the robustness of different approaches to preserving the essential characteristics of the source image, thereby offering valuable insight into the strengths and weaknesses of current image editing techniques.
Future Research#
The ‘Future Research’ section of this paper highlights promising avenues for enhancing image editing via video generation. Fine-tuning video generation models specifically for image editing is crucial, potentially through tailored datasets emphasizing static camera perspectives or focusing on edits. This would improve both the naturalness and accuracy of results. Furthermore, exploring methods to reduce computational costs associated with full video generation is important, possibly by optimizing existing models or investigating alternative approaches that still capture the benefits of temporal coherence. Developing strategies to handle diverse and complex editing tasks while maintaining high visual fidelity is another key area. Finally, expanding the capabilities of the Frame2Frame framework to incorporate more interactive or user-guided editing processes would greatly enhance its usability and creative potential.
More visual insights#
More on figures

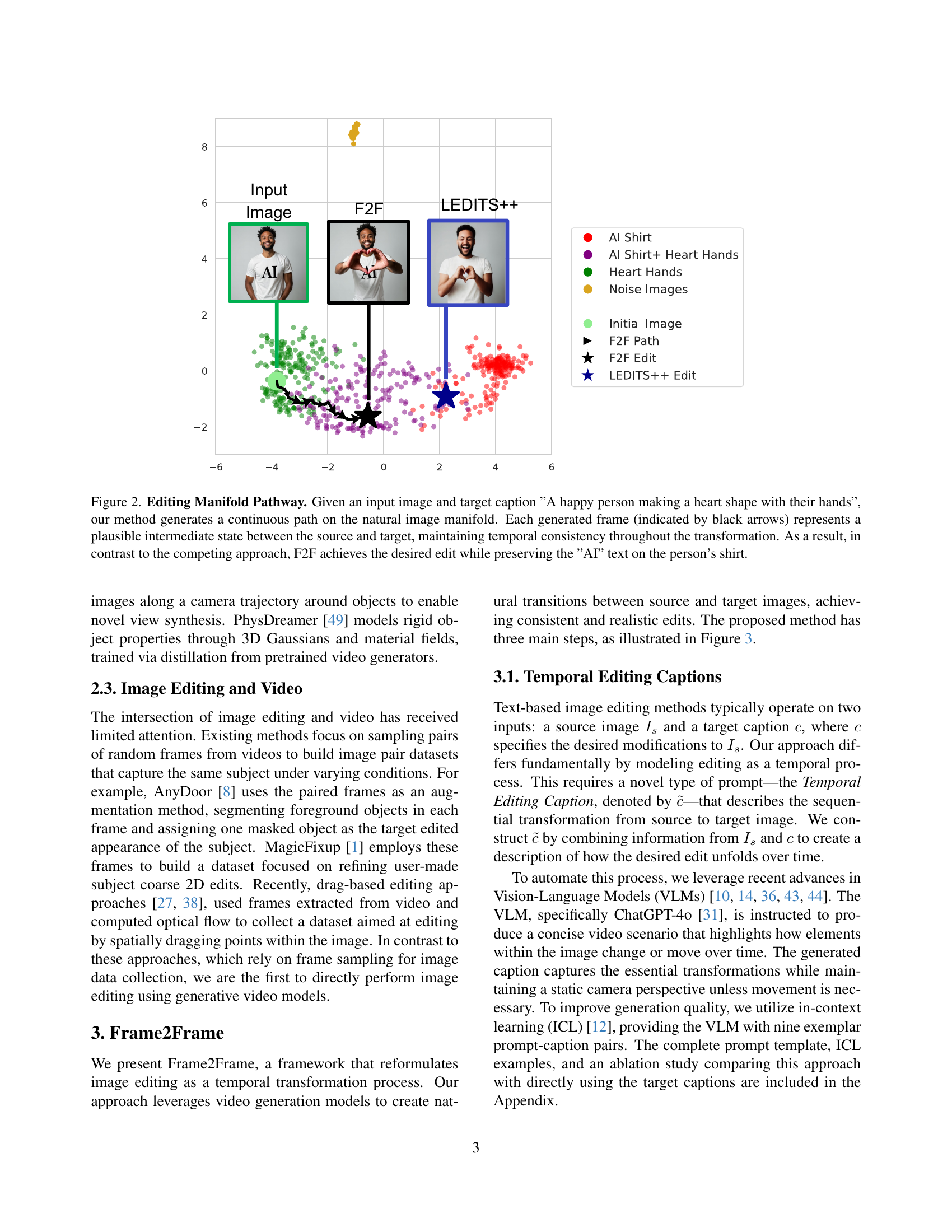
🔼 This figure visualizes the image editing process using the Frame2Frame (F2F) method. Starting with an input image of a person wearing a shirt with ‘AI’ written on it, and a target caption instructing the model to edit the image to show the person making a heart shape with their hands, the F2F method generates a series of intermediate images, effectively creating a smooth path across the image manifold. Each image represents a plausible and consistent transition between the source image and the target edit. The black arrows highlight the temporal progression. Importantly, the F2F method maintains the ‘AI’ text on the shirt throughout the transformation, unlike competing approaches which might lose such detail. The figure demonstrates the temporal coherence and fidelity of the proposed method, highlighting its ability to preserve key elements of the original image while successfully implementing complex edits.
read the caption
Figure 2: Editing Manifold Pathway. Given an input image and target caption ”A happy person making a heart shape with their hands”, our method generates a continuous path on the natural image manifold. Each generated frame (indicated by black arrows) represents a plausible intermediate state between the source and target, maintaining temporal consistency throughout the transformation. As a result, in contrast to the competing approach, F2F achieves the desired edit while preserving the ”AI” text on the person’s shirt.

🔼 Frame2Frame is a three-step image editing process. It begins with a source image and an editing prompt. First, a Vision-Language Model (VLM) creates a temporal caption describing the desired transformation from the source to target image as a video. This temporal caption is then fed into a video generator which produces a video showing a smooth and realistic transition from the source image to the desired edit. Finally, a frame selection strategy, also guided by the VLM, identifies the optimal frame from the generated video that best achieves the edit, thus generating the final edited image.
read the caption
Figure 3: Frame2Frame Overview. Given a source image and editing prompt, our pipeline proceeds in three steps. First, a Vision-Language Model generates a temporal caption describing the transformation. Next, this caption guides a video generator to create a natural progression of the edit. Finally, our frame selection strategy identifies the optimal frame that best realizes the desired edit, producing the final image of the cat mid-leap.

🔼 Figure 4 presents a qualitative comparison of different image editing methods on the TEdBench benchmark. It showcases the results of several editing tasks, highlighting the superior performance of the proposed Frame2Frame (F2F) method. The F2F approach consistently generates edits that closely match the target descriptions while effectively preserving the original image’s content and structural integrity. A key example is the teddy bear edit, where F2F uniquely handles complex structural changes, resulting in high-quality edits.
read the caption
Figure 4: Qualitative Results on TEdBench. Comparison with other methods across various editing tasks. Our approach consistently produces edits that better align with the target prompt while preserving the source image’s content and structure. For instance, in the teddy bear example, our method uniquely achieves complex structural modifications while maintaining high visual quality.

🔼 Figure 5 presents a qualitative comparison of image editing results between the Frame2Frame method and LEDITS++, focusing on human pose editing tasks from the PosEdit benchmark dataset. Each row showcases a triplet of images: the original source image, the edited image produced using Frame2Frame, and the edited image produced using LEDITS++. A ground truth image from the PosEdit dataset, which depicts the target pose, is also included in each row for reference. The figure highlights that Frame2Frame generally better preserves the subject’s identity and produces more realistic-looking and natural transitions between poses when compared to LEDITS++.
read the caption
Figure 5: Qualitative Results on PosEdit. Comparison between our Frame2Frame method and LEDITS++ on human motion editing tasks. For each example, we show the source image, edited results from both methods, and the ground-truth target image. Our method better preserves subject identity while achieving more natural pose transitions.

🔼 This figure displays the results of applying the image-to-video-to-image editing approach to four tasks commonly addressed in computer vision: image denoising, image deblurring, image outpainting, and image relighting. For each task, the original image is shown alongside the result obtained using the method. This demonstrates the versatility of the proposed approach to handle tasks beyond typical image editing.
read the caption
Figure 6: Additional Vision Tasks. Qualitative results of our image-to-video-to-image editing approach on selected traditional tasks.

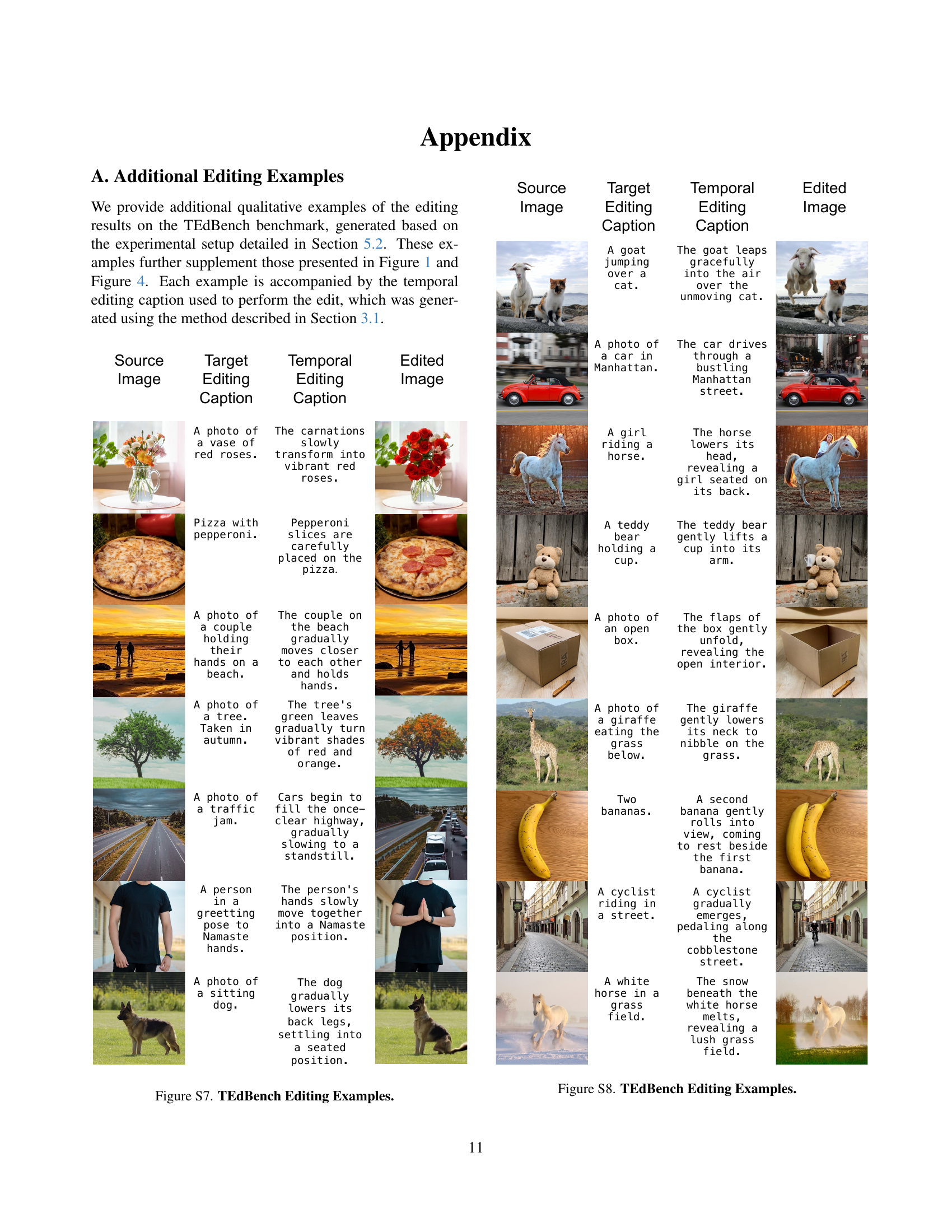
🔼 This figure displays several examples of image editing results obtained using the Frame2Frame method on the TEdBench benchmark. Each example shows the original image, the target edit description, the generated temporal editing caption (describing the transformation over time), and the final edited image produced by the model. These examples highlight the model’s ability to achieve complex edits while preserving the essential characteristics of the original image.
read the caption
Figure S7: TEdBench Editing Examples.

🔼 This figure displays several examples of image editing results generated using the Frame2Frame method on the TEdBench dataset. Each example includes the source image, the target edit caption describing the desired modification, the generated temporal editing caption guiding the video generation process, and the final edited image. The examples showcase the method’s ability to perform complex and nuanced edits while preserving the overall content and structure of the source image.
read the caption
Figure S8: TEdBench Editing Examples.

🔼 This figure shows example pairs used for in-context learning in the Frame2Frame model. Each example consists of a source image, a target caption describing the desired edit, and a corresponding temporal caption generated by a Vision-Language Model (VLM). The temporal captions describe the natural evolution of the edit over time, providing instructions for the video generation process. The examples illustrate how the VLM translates concise instructions into detailed step-by-step transformations for generating the video.
read the caption
Figure S9: In Context Learning Examples.

🔼 This figure shows a collage of images generated by the Frame2Frame model. The model started with a single image of a cat and generated a sequence of images aiming to create a final image matching the caption ‘A photo of a cat yawning.’ The collage displays several frames from that video sequence, allowing one to visually observe the gradual transformation toward the target. The selection process chooses the frame that best represents the target image while maintaining fidelity to the original source image.
read the caption
Figure S10: Frame Selection Collage. The target editing caption for this example is: “A photo of a cat yawning.”.

🔼 This figure shows examples of images generated using the Flux.1-dev text-to-image model. The images illustrate the diverse range of visual outputs the model can produce and represent various categories such as people with AI shirts, those making a heart shape, and a combination of both. This helps visualize how the natural image manifold is structured and how different edits can be achieved through transitions.
read the caption
Figure S11: Flux.1-dev Generations

🔼 Figure S12 provides several examples from the PosEdit dataset, showcasing various human pose editing tasks. Each example shows the source image (person standing neutrally), target image (person performing a specific action), the temporal editing caption describing the transition, and the ground truth target image for comparison. The examples illustrate the range of poses and the level of detail involved in the dataset, highlighting the complexity of the pose editing task.
read the caption
Figure S12: PosEdit Examples.

🔼 Figure S13 shows example results of the PosEdit benchmark. Each example includes the source image, the target image (ground truth), the generated temporal editing caption used for the editing process, and the final edited image produced by the Frame2Frame method. This figure visually demonstrates the effectiveness of the proposed approach in accurately performing human pose editing tasks while maintaining the identity and key attributes of the subject.
read the caption
Figure S13: PosEdit Examples.

🔼 This figure displays a sample survey question used in the human evaluation study. The top shows the original image and the edited versions from two different methods, and the bottom shows the questions asked to assess the edit accuracy and edit quality. Edit accuracy is evaluated in terms of how well the final image corresponds to the requested edit in the caption. Edit quality is assessed based on the preservation of image content from the source image and the overall natural appearance of the changes. This figure exemplifies the process of human evaluation used in the paper to assess the user’s preference in the edited result.
read the caption
Figure S14: Survey Example

🔼 This figure displays an example from the human evaluation survey conducted in Section 5.4. It shows a source image, a target edit, and two edited images produced by different methods (likely Frame2Frame and LEDITS++). Participants in the survey were asked to compare the images based on edit accuracy (how well the edit matches the target description) and edit quality (image fidelity, naturalness, and seamless integration of edits). The figure likely includes multiple-choice questions related to selecting the better-edited image according to each metric, reflecting the human preference-based evaluation.
read the caption
Figure S15: Survey Example
More on tables
| Model | Source LPIPS↓ | Source CLIP-I↑ | Target LPIPS↓ | Target CLIP-I↑ | Target CLIP↑ |
|---|---|---|---|---|---|
| SDEdit | 0.39 | 0.61 | 0.39 | 0.64 | 0.57 |
| Pix2Pix-ZERO | 0.39 | 0.57 | 0.40 | 0.60 | 0.56 |
| LEDITS++ | 0.26 | 0.65 | 0.28 | 0.69 | 0.64 |
| F2F | 0.14 | 0.82 | 0.15 | 0.84 | 0.64 |
🔼 This table presents a quantitative analysis of different image editing methods on the PosEdit benchmark dataset. It evaluates how well each method preserves the source image (Source metrics: LPIPS and CLIP-I scores) and how accurately it produces the desired edit (Target metrics: LPIPS, CLIP-I, and CLIP scores compared to the ground truth target image). Lower LPIPS scores indicate better preservation of the source image, while higher CLIP-I scores suggest better semantic similarity between the source and edited images. The CLIP score measures the alignment between the edited image and the target edit description, reflecting the edit’s accuracy.
read the caption
Table 2: PosEdit Results. Quantitive evaluation on PosEdit. Source metrics assess similarity to the original image, while Target metrics now include both LPIPS and CLIP-I comparisons to the ground-truth target image, along with the CLIP score for edit accuracy.
| Method | Edit Accuracy | Edit Quality | ||
|---|---|---|---|---|
| Overall | Per-Image | Overall | Per-Image | |
| F2F | 54.1% | 53.0% | 65.6% | 67.0% |
| LEDITS++ | 45.9% | 47.0% | 34.4% | 33.0% |
🔼 A human evaluation comparing Frame2Frame (F2F) and LEDITS++ on the TEdBench dataset. Participants assessed both methods based on edit accuracy (how well the edit matched the instructions) and edit quality (how well the original image content was preserved). The results show that F2F significantly outperforms LEDITS++ in both areas.
read the caption
Table 3: Human Survey Results. Human evaluation on TEdBench shows that F2F surpasses LEDITS++ in edit accuracy while demonstrating a significant advantage in preserving the original image content.
| Model | LPIPS↓ | CLIP-I↑ | CLIP↑ |
|---|---|---|---|
| Original Captions | 0.21 | 0.89 | 0.60 |
| Temporal Captions | 0.22 | 0.89 | 0.63 |
🔼 This table presents the ablation study results comparing the performance of using automatically generated temporal editing captions against directly using the target captions from the TEdBench benchmark. It shows that while preserving source image content, using the automatically generated temporal captions leads to superior performance compared to using original captions directly.
read the caption
Table S4: Temporal Editing Captions Ablation.
| Model | LPIPS↓ | CLIP-I↑ | CLIP↑ |
|---|---|---|---|
| Last Frame | 0.24 | 0.9 | 0.61 |
| Selected Frame | 0.22 | 0.89 | 0.63 |
🔼 This table presents an ablation study comparing two approaches for selecting the optimal frame from a generated video sequence in the image editing process. The first method uses the last frame of the video as the final edited image, while the second uses a Vision-Language Model (VLM) to select the best frame that fulfills the edit request. The table shows the quantitative evaluation results of both methods on the TEdBench benchmark, using LPIPS, CLIP-I↑ (for source preservation), and CLIP↑ (for edit accuracy) metrics. This ablation study demonstrates the effectiveness of the VLM-based frame selection method in improving the overall edit quality.
read the caption
Table S5: Frame Selection Ablation.
Full paper#