↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current autoregressive models excel in 2D and text but lag in 3D object generation and understanding. Applying these approaches to 3D is challenging due to the complexity and computational cost of processing 3D data. Existing methods either generate low-quality 3D models or are computationally expensive, lacking detailed understanding capabilities.
SAR3D solves this by using a multi-scale 3D vector-quantized variational autoencoder (VQVAE) to create tokens of 3D objects. This multi-scale approach drastically speeds up generation, achieving sub-second times. Furthermore, by enriching the tokens with 3D-aware information, SAR3D allows for finetuning of LLMs, enabling detailed 3D understanding. This combined approach surpasses current methods in both speed and quality, paving the way for faster and more detailed 3D AI applications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SAR3D, a novel framework that significantly advances both speed and quality in 3D object generation. Its multi-scale approach reduces generation time, making it highly efficient. Furthermore, SAR3D enables detailed 3D understanding by using LLMs, opening new avenues for multimodal AI applications and research in 3D object comprehension. This work bridges the gap between fast generation and detailed understanding, a critical area in 3D AI.
Visual Insights#

🔼 This figure illustrates the SAR3D framework, which is composed of two main parts: 3D generation and 3D understanding. The 3D generation part (a) shows that SAR3D takes either a single image or a text prompt as input and generates a multi-scale 3D object using an autoregressive approach. The 3D understanding part (b) demonstrates that SAR3D-LLM, a large language model fine-tuned on 3D data, can interpret an existing 3D model and provide a detailed description of it.
read the caption
Figure 1: Our method, SAR3D, proposes a comprehensive framework for 3D generation and understanding via autoregressive modeling. For (a) 3D generation, given a single image or text prompt, SAR3D generates multi-scale 3D objects in an autoregressive manner. For (b) 3D understanding, SAR3D-LLM can interpret a 3D model and provide a detailed description.
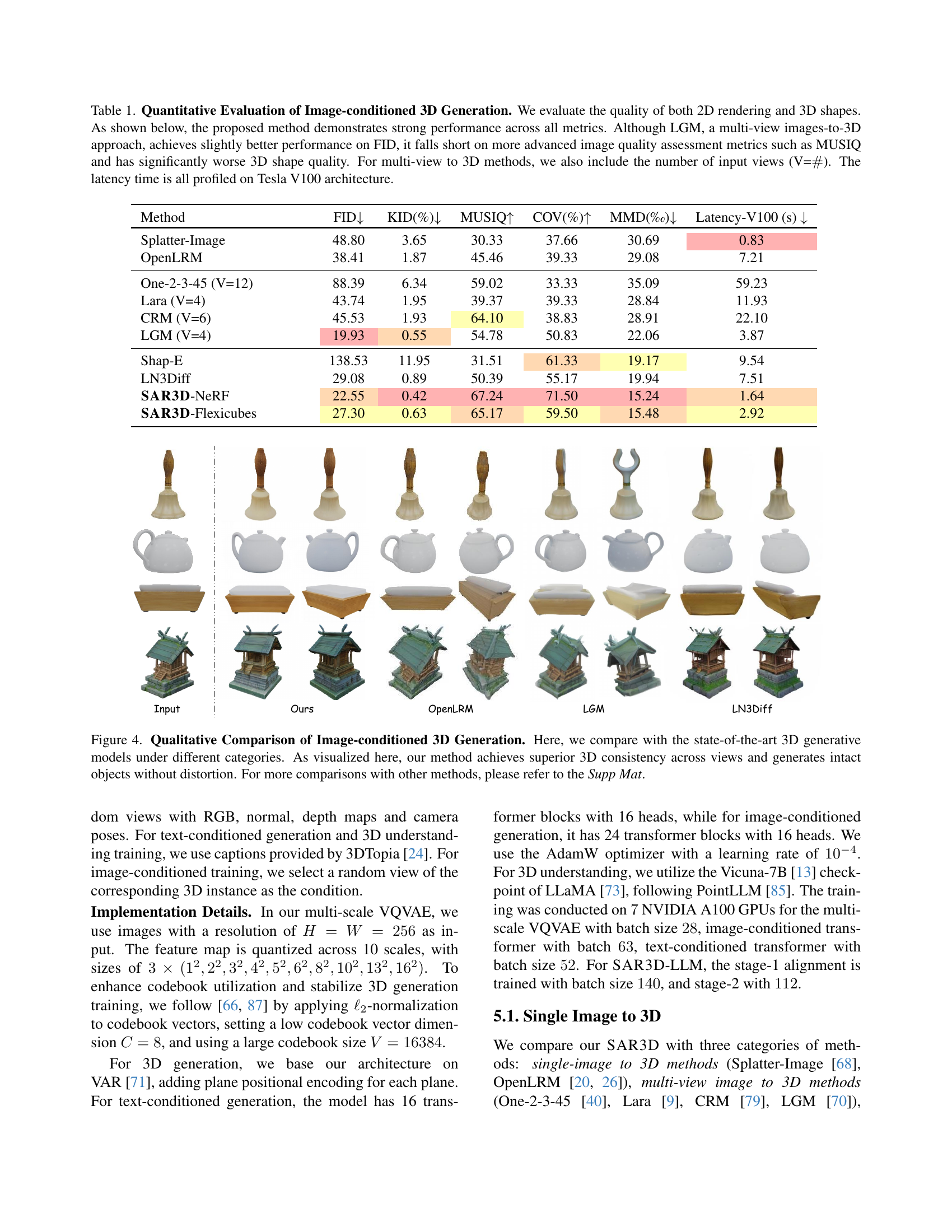
| Method | FID ↓ | KID(%) ↓ | MUSIQ ↑ | COV(%) ↑ | MMD(‰) ↓ | Latency-V100 (s) ↓ |
|---|---|---|---|---|---|---|
| Splatter-Image | 48.80 | 3.65 | 30.33 | 37.66 | 30.69 | 0.83 |
| OpenLRM | 38.41 | 1.87 | 45.46 | 39.33 | 29.08 | 7.21 |
| One-2-3-45 (V=12) | 88.39 | 6.34 | 59.02 | 33.33 | 35.09 | 59.23 |
| Lara (V=4) | 43.74 | 1.95 | 39.37 | 39.33 | 28.84 | 11.93 |
| CRM (V=6) | 45.53 | 1.93 | 64.10 | 38.83 | 28.91 | 22.10 |
| LGM (V=4) | 19.93 | 0.55 | 54.78 | 50.83 | 22.06 | 3.87 |
| Shap-E | 138.53 | 11.95 | 31.51 | 61.33 | 19.17 | 9.54 |
| LN3Diff | 29.08 | 0.89 | 50.39 | 55.17 | 19.94 | 7.51 |
| SAR3D-NeRF | 22.55 | 0.42 | 67.24 | 71.50 | 15.24 | 1.64 |
| SAR3D-Flexicubes | 27.30 | 0.63 | 65.17 | 59.50 | 15.48 | 2.92 |
🔼 This table presents a quantitative comparison of different image-conditioned 3D generation methods, evaluating both the 2D rendering quality and the 3D shape quality. The metrics used include FID (Fréchet Inception Distance), KID (Kernel Inception Distance), MUSIQ (Multi-scale Image Quality), COV (Coverage Score), MMD (Minimum Matching Distance), and generation time. The table shows that the proposed SAR3D method outperforms other methods in most metrics, demonstrating strong performance across all assessment criteria. While one competing method (LGM) shows slightly better FID scores, its performance is significantly worse on higher-level image quality metrics like MUSIQ and 3D shape quality. The number of input views used by multi-view methods is also specified. All latency times reported were measured using a Tesla V100 GPU.
read the caption
Table 1: Quantitative Evaluation of Image-conditioned 3D Generation. We evaluate the quality of both 2D rendering and 3D shapes. As shown below, the proposed method demonstrates strong performance across all metrics. Although LGM, a multi-view images-to-3D approach, achieves slightly better performance on FID, it falls short on more advanced image quality assessment metrics such as MUSIQ and has significantly worse 3D shape quality. For multi-view to 3D methods, we also include the number of input views (V=##\##). The latency time is all profiled on Tesla V100 architecture.
In-depth insights#
Autoregressive 3D#
Autoregressive models have shown significant success in 2D generation and language processing. Extending these methods to 3D presents unique challenges due to the higher dimensionality and complexity of 3D data. Autoregressive 3D generation approaches aim to address this by sequentially predicting parts of a 3D model, often using a latent representation such as a voxel grid or point cloud. A key advantage is the potential for generating high-quality, coherent 3D models by building them up step-by-step. However, challenges remain in terms of computational cost, inference speed, and the need for effective 3D tokenization schemes that capture the essential features of the object. Multi-scale approaches are emerging as a promising solution to improve efficiency by predicting larger portions of the model at each step. This reduces the overall number of prediction steps, resulting in faster generation times. Furthermore, combining autoregressive 3D generation with large language models (LLMs) for 3D understanding opens the door to sophisticated multimodal applications, allowing for both detailed 3D model creation and interpretation. The future of autoregressive 3D likely lies in further advancements in efficient 3D tokenization and the integration with more powerful LLMs for seamless generation and comprehension.
Multi-scale VQVAE#
The proposed multi-scale VQVAE is a key innovation enabling efficient autoregressive 3D object generation and understanding. Instead of processing individual tokens, it leverages a hierarchical representation, tokenizing 3D objects into multiple scales of increasing resolution. This multi-scale approach drastically reduces the number of prediction steps needed, leading to significantly faster generation times. The use of a vector-quantized variational autoencoder (VQVAE) allows for efficient encoding and decoding of the 3D data, while the multi-scale nature ensures a compact representation that captures both coarse and fine details of the 3D model. The hierarchical tokens generated are also shown to be naturally compatible with Large Language Models (LLMs), enabling seamless integration of the 3D model’s structure and visual details for comprehensive understanding and captioning. Overall, this design cleverly addresses the computational challenges of autoregressive 3D generation by strategically organizing the 3D information in a multi-scale representation and thus allows for both efficient generation and insightful understanding.
Next-scale Prediction#
The concept of “Next-scale Prediction” presents a compelling advancement in autoregressive modeling, particularly within the context of 3D object generation. Instead of predicting individual tokens sequentially, this approach focuses on predicting the next level of detail or resolution in a hierarchical representation. This strategy offers significant advantages by substantially reducing computational cost and generation time. The hierarchical nature allows for capturing progressively finer details, leading to faster convergence and more efficient use of computational resources. Furthermore, this method is naturally compatible with large language models (LLMs), enabling seamless integration of text or other modalities into the generation process. The efficiency gains from next-scale prediction make high-quality 3D generation feasible, a task previously hampered by the computational demands of traditional approaches. A potential limitation however is the dependence on a well-designed hierarchical representation which needs to effectively capture the relevant information at each scale.
LLM 3D Understanding#
LLM 3D understanding represents a significant challenge and opportunity in AI. It seeks to bridge the gap between the symbolic reasoning capabilities of large language models (LLMs) and the complex geometric data of 3D models. A key aspect is developing effective methods to encode 3D data into a format LLMs can process, such as converting meshes or point clouds into tokenized sequences. This encoding must capture crucial information like shape, texture, and spatial relationships. Once encoded, the ability of the LLM to interpret and reason about this data becomes paramount. This involves training or fine-tuning the LLM on paired 3D data and textual descriptions. Successful LLM 3D understanding goes beyond simple captioning, aiming for tasks like detailed scene description, object recognition, and even reasoning about interactions within the 3D environment. Key challenges include handling the inherent complexity of 3D data, finding efficient and informative encoding methods, and developing evaluation metrics that adequately capture the nuanced understanding an LLM achieves. Future directions might involve incorporating more advanced 3D representations, exploring different LLM architectures tailored for geometric data, and developing more sophisticated training strategies that integrate both symbolic and geometric learning.
SAR3D Limitations#
The section on SAR3D Limitations would ideally delve into the model’s shortcomings. A key limitation is the two-separate autoregressive models used for generation and understanding. This modularity, while convenient for development, prevents a truly unified multimodal approach and hinders efficient processing of integrated text and 3D information. Another area needing discussion is the reliance on volume rendering, which limits the quality of geometry and texture detail. More efficient 3D representations or techniques like cascaded generation could improve this aspect. Finally, while SAR3D shows scalability potential, thorough validation of scaling behavior requires more computational resources. Future research should focus on a fully integrated multimodal model, explore improved 3D representation, and conduct exhaustive scalability testing to address these limitations and further solidify the model’s capabilities.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of a multi-scale 3D Vector Quantized Variational Autoencoder (VQVAE). A 3D model is first rendered into multiple views, each view providing an RGB image, a depth map, and a Plücker coordinate representation of the camera pose. These multi-view renderings are concatenated and fed into a multi-view encoder. The encoder outputs a continuous feature map. This feature map is then quantized into a sequence of multi-scale tokens (R = (r1, r2, …, rK)) by a multi-scale quantizer. Importantly, all scales share the same codebook, enabling efficient encoding. These tokens represent the latent tri-plane features. Finally, a tri-plane decoder reconstructs the tri-plane representation from the quantized tokens using a plane-wise approach. The quality of this reconstruction is assessed by comparing the predicted tri-plane to the ground truth images, depth maps, and surface normals from the original 3D model.
read the caption
Figure 2: Overview of Multi-scale VQVAE. Given a 3D model, we leverage multi-view RGB-D(epth) renderings and Plücker embeddings as the input to our multi-view encoder ℰℰ\mathcal{E}caligraphic_E. The encoder predicts a continuous feature map that is then quantized by the multi-scale quantizer 𝒬𝒬\mathcal{Q}caligraphic_Q, giving R=(r1,r2,…,rK)𝑅subscript𝑟1subscript𝑟2…subscript𝑟𝐾R=(r_{1},r_{2},\dots,r_{K})italic_R = ( italic_r start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_r start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_r start_POSTSUBSCRIPT italic_K end_POSTSUBSCRIPT ) of latent tri-plane features. Each code of different scales share the same codebook. The triplane decoder then converts the quantized latent triplane features into the triplane representation through a plane-wise manner. The predicted triplane is multi-view supervised with the ground truth image, depth, and normal.

🔼 Figure 3 illustrates SAR3D’s two main functionalities: 3D generation and 3D understanding. A 3D VQVAE encodes a given 3D model into a multi-scale sequence of discrete tokens. In the 3D generation process (a), either text or a single image is encoded using CLIP or DINOv2. These encoded features are then fed into a decoder-only transformer via cross-attention, which autoregressively predicts each scale of the latent triplane, ultimately generating a 3D model. In the 3D understanding process (b), a truncated version of the 3D token sequence (excluding the final scales) is processed through an MLP projector. This refined token sequence is combined with text input and given to a large language model, which generates a detailed caption describing the input 3D model.
read the caption
Figure 3: Overview of 3D Generation and 3D Understanding. Given a 3D model, our 3D VQVAE encodes it into multi-scale discrete tokens for both 3D generation and understanding. In (a) 3D Generation, text or a single image is encoded by CLIPTT{}_{\text{T}}start_FLOATSUBSCRIPT T end_FLOATSUBSCRIPT or DINOv2, and the encoded condition features are integrated into the decoder-only transformer via cross attention. The transformer then causally predicts each scale of the latent triplane. In (b) 3D Understanding, truncated 3D tokens are first processed with an MLP projector. The large language model receives a multimodal sequence of text and 3D tokens and generates a detailed caption describing the input 3D model.

🔼 Figure 4 presents a qualitative comparison of image-conditioned 3D object generation, showcasing the results of various state-of-the-art methods. The comparison focuses on three aspects: 3D consistency across multiple views (meaning how well the 3D model looks from different angles), generation of intact objects (meaning if the objects are complete and not partially generated), and overall quality. The figure visually demonstrates that the proposed method (SAR3D) excels in producing highly consistent 3D models with complete objects from different viewpoints. Additional comparisons and detailed analyses are available in the supplementary materials.
read the caption
Figure 4: Qualitative Comparison of Image-conditioned 3D Generation. Here, we compare with the state-of-the-art 3D generative models under different categories. As visualized here, our method achieves superior 3D consistency across views and generates intact objects without distortion. For more comparisons with other methods, please refer to the Supp Mat.

🔼 Figure 5 showcases more examples of 3D objects generated by the SAR3D model, demonstrating its capabilities in both image-conditioned and text-conditioned generation. The image-conditioned examples show how the model produces detailed 3D models from a single input image. The text-conditioned examples illustrate the model’s ability to generate 3D models according to textual descriptions, showcasing variations in object shape, texture, and details based on the given text prompts.
read the caption
Figure 5: More results of image and text conditioned 3D generation of SAR3D.

🔼 Figure 6 showcases a comparison of text-to-3D object generation results. SAR3D, the proposed method, is compared against several baseline approaches. The figure displays two viewpoints of each 3D model generated from text prompts. The comparison highlights SAR3D’s superior performance in generating higher-quality 3D models with improved geometry, texture, and better alignment between the generated object and the original text description. This demonstrates the efficacy of SAR3D in translating textual descriptions into accurate 3D representations.
read the caption
Figure 6: Comparison of Text-conditioned 3D Generation. We present text-conditioned 3D objects generated by SAR3D, displaying two views of each sample.Compared to baseline methods, our approach consistently yields better quality regarding geometry, texture, and text-3D alignment.

🔼 This figure demonstrates the capabilities of the SAR3D-LLM model to perform simultaneous 3D object generation and captioning. Given either a single image or a text description as input, the model generates a corresponding 3D model and produces a detailed caption that accurately describes the generated model’s characteristics, including details such as shape, color, components, and spatial relationships between parts.
read the caption
Figure 7: Simultaneous 3D Generation and Captioning. Given a single image or text, SAR3D-LLM can generate both a 3D model and a descriptive caption for the model.

🔼 Figure 8 showcases the capabilities of SAR3D-LLM, the 3D object understanding component of the SAR3D framework, in generating detailed captions for input 3D models. It demonstrates that SAR3D-LLM doesn’t just identify the object’s category (e.g., ‘chair’, ‘house’), but also describes specific details such as shape, color, components, and even spatial relationships between parts of the object. This is a key aspect of the paper’s claim for improved 3D understanding, moving beyond simple object classification.
read the caption
Figure 8: 3D Object Captioning. Given a 3D model, SAR3D-LLM can generate captions that include both category and details.

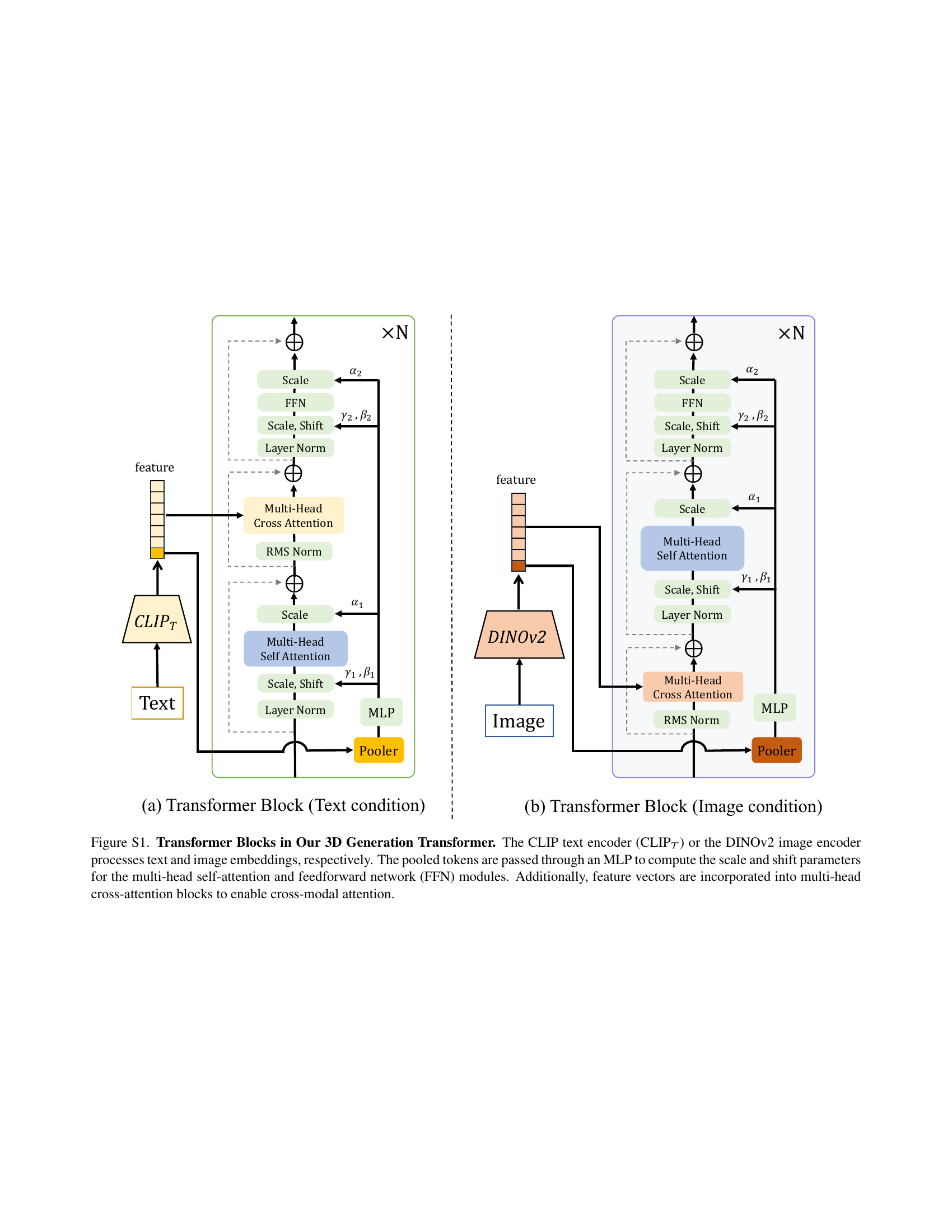
🔼 This figure details the transformer blocks used in the 3D generation process of the SAR3D model. It shows two distinct transformer blocks: one for text-based conditioning and one for image-based conditioning. Both blocks begin by processing input embeddings (text from CLIP and image from DINOv2). These embeddings are then passed through a multi-layer perceptron (MLP) to calculate scale and shift parameters for the subsequent self-attention and feed-forward network (FFN) layers. Critically, both blocks incorporate cross-attention mechanisms to allow interaction between text/image features and the 3D latent representations.
read the caption
Figure S1: Transformer Blocks in Our 3D Generation Transformer. The CLIP text encoder (CLIPT) or the DINOv2 image encoder processes text and image embeddings, respectively. The pooled tokens are passed through an MLP to compute the scale and shift parameters for the multi-head self-attention and feedforward network (FFN) modules. Additionally, feature vectors are incorporated into multi-head cross-attention blocks to enable cross-modal attention.
🔼 Figure S2 presents supplementary results demonstrating the capabilities of SAR3D-LLM for 3D object captioning. It showcases a variety of 3D models, each accompanied by a detailed caption generated by the model. The captions go beyond simple object category labeling to include descriptive details about shape, texture, material, and even implied function or context. This figure highlights the ability of SAR3D to generate comprehensive and nuanced descriptions based on the multi-scale tri-plane tokens extracted from the 3D object, demonstrating a more in-depth understanding than is typically achieved in other models.
read the caption
Figure S2: Additional 3D Captioning Results. Our method generates detailed descriptions based on the input of 8 scales of latent tri-plane tokens.
Full paper#