↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Key Takeaways#
Why does it matter?#
This paper is important because it presents Free²Guide, a novel gradient-free framework for improving text-to-video generation. This is significant because existing methods often require computationally expensive fine-tuning or are limited in their scalability. Free²Guide’s gradient-free approach allows the integration of powerful, non-differentiable large vision-language models, significantly enhancing alignment and overall quality. The research also introduces innovative ensembling techniques for reward models, further optimizing performance. This opens new avenues for research into more efficient and scalable text-to-video generation methods.
Visual Insights#

🔼 Figure 1 showcases example video outputs generated using the Free²Guide framework. Each row presents a text prompt and compares the videos produced by a baseline method (without Free²Guide) versus videos generated with Free²Guide. The Free²Guide method utilizes a Large Vision-Language Model to guide the video generation process without requiring any additional model training or gradient calculations. This allows for flexibility and avoids the computational overhead of gradient-based methods. The improved text alignment and video quality obtained using Free²Guide are clearly visible in the generated videos.
read the caption
Figure 1: Representative video results using Free2Guide, a novel framework that enables train-Free, gradient-Free video Guidance leveraging a Large Vision-Language Model. Best viewed with Acrobat Reader. Click each image to play the video clip.
| Baseline | Free2Guide | Baseline | Free2Guide |
|---|
🔼 This table presents a qualitative comparison of different ensemble methods used to combine multiple reward models for enhancing text-to-video alignment in a diffusion model. It compares the performance of three ensemble methods: Weighted Sum, Normalized Sum, and Consensus. Each method combines the scores from two reward models: one using Large Vision-Language Models (LVLMs) for temporal awareness, and one using existing large-scale image models. The table shows the average scores for each ensemble method, allowing a comparison of their relative effectiveness in improving video generation.
read the caption
Table 1: Qualitative comparison between ensemble methods.
In-depth insights#
Gradient-Free Guidance#
Gradient-free guidance in diffusion models offers a compelling alternative to traditional gradient-based methods, particularly when dealing with complex, non-differentiable reward functions, such as those derived from large vision-language models. The core idea is to approximate guidance signals without explicitly calculating gradients, relying instead on techniques like path integral control or zeroth-order optimization. This approach bypasses the limitations of gradient-based methods, which often struggle with the computational cost and complexity associated with differentiating through large models or non-differentiable components. Gradient-free guidance thus opens the door to leveraging powerful, pre-trained, black-box models, which would be impractical to integrate directly into the training loop of a diffusion model. However, the trade-off lies in the approximation of gradients; gradient-free methods might not achieve the same level of precision and efficiency as their gradient-based counterparts. The effectiveness depends heavily on the chosen approximation technique and the quality of the reward function. Careful consideration of sampling strategies and ensemble methods can mitigate some of these drawbacks, yielding significant improvements in text-video alignment without sacrificing the flexibility of integrating sophisticated, non-differentiable reward models.
LVLM-Based Rewards#
Employing Large Vision-Language Models (LVLMs) for reward functions presents a paradigm shift in text-to-video generation. Unlike traditional reward models that often require differentiability or extensive training, LVLMs offer a powerful, black-box approach. Their inherent ability to understand both visual and textual context allows for the evaluation of complex alignment without explicit gradient calculation, significantly simplifying the training process. The use of LVLMs enables the integration of non-differentiable reward functions, opening up the possibilities for diverse metrics. This approach directly addresses the challenges of temporal dependencies inherent in videos, offering a more nuanced evaluation of text-video alignment. Furthermore, the flexibility to combine LVLMs with other reward models creates an opportunity for synergistic enhancement, potentially improving alignment beyond what either model can accomplish independently. This makes LVLMs a powerful tool for advancing the field. However, challenges remain, notably the resource intensiveness of LVLMs and the need for further exploration to optimally integrate these sophisticated models into the text-to-video generation pipeline.
Ensemble Methods#
The paper explores ensemble methods for enhancing text-to-video alignment in diffusion models. The core idea is to combine multiple reward models, leveraging the strengths of each to improve overall video quality and text alignment. The primary advantage of ensembling is that it allows the integration of both differentiable and non-differentiable reward models, such as large vision-language models (LVLMs) and image-based models, something not feasible with gradient-based methods. Three ensemble methods are investigated: Weighted Sum, Normalized Sum, and Consensus. While the Weighted Sum allows for manual control over model influence, Normalized Sum addresses scaling issues by normalizing scores, and Consensus uses ranking to combine rewards. Experiments show that ensembling, particularly with LVLMs, significantly improves text alignment, suggesting that combining diverse models offers more robust and effective guidance compared to relying on individual models. The success highlights the power of ensemble methods in handling the complexity of video generation, where temporal and spatial coherence must be considered simultaneously.
Path Integral Control#
The concept of ‘Path Integral Control’ offers a compelling gradient-free approach to guide diffusion models, particularly beneficial for complex tasks like text-to-video generation. Bypassing the need for differentiable reward functions, it opens doors to incorporating powerful, non-differentiable models like Large Vision-Language Models (LVLMs) for improved guidance. This is crucial because LVLMs offer rich semantic understanding, surpassing the capabilities of simpler, differentiable reward functions. The method cleverly approximates guidance using principles of stochastic optimal control, effectively navigating the high-dimensional space of video data without the computational burden of backpropagation. The inherent flexibility allows for the ensembling of multiple reward models, synergistically enhancing alignment and overall video quality. This approach directly addresses the limitations of existing gradient-based methods, offering a more scalable and robust solution for sophisticated generative tasks.
Future of T2V#
The future of text-to-video (T2V) synthesis is brimming with potential. Improved realism and control are paramount; current models sometimes struggle with accurate text alignment, especially in complex scenes or with nuanced temporal dynamics. Future advancements will likely focus on incorporating more sophisticated temporal modeling, potentially using techniques like neural ODEs or transformers specifically designed for video sequences to capture more nuanced motion and scene evolution. Higher-resolution and longer videos will also be a priority; current methods often yield lower resolutions and shorter clips compared to the vast potential of the video medium. Greater efficiency is also needed: current models are computationally expensive, making them difficult to deploy widely. Finally, addressing ethical considerations will be crucial. Bias in training data could lead to unfair or discriminatory outputs, so responsible development and deployment, including techniques for detecting and mitigating bias, are essential for a positive future of T2V technology.
More visual insights#
More on figures

🔼 Free²Guide uses path integral control to improve text-video alignment in diffusion models without needing reward gradients. The process involves generating multiple denoised video samples at each step of the sampling process. A Large Vision-Language Model (LVLM), acting as a non-differentiable reward function, evaluates the alignment of each sample with the input text prompt. This feedback guides the sampling process toward generating videos that better match the text description. The figure illustrates this overall pipeline.
read the caption
Figure 2: Overall pipeline of Free2Guide, leveraging path integral control to enhance text-video alignment without requiring reward gradient. During the sampling process, Free2Guide generates multiple denoised video samples and evaluate text alignment using non-differentiable Large Vision-Language Models (LVLMs).

🔼 Figure 3 presents a qualitative comparison of video generation results using different methods. The left side shows results from the LaVie model, while the right side shows results from the VideoCrafter2 model. Each row displays a different text prompt used to guide the video generation. Within each row, the first image shows the baseline video generated without any additional guidance. Subsequent images show the results when adding different reward models for guidance, including CLIP, ImageReward, and GPT-40. This allows for a visual comparison of how the different methods affect the alignment of generated videos with the given text descriptions, and the overall quality of the generated videos.
read the caption
Figure 3: Qualitative results of our method. Baseline with LaVie on the left and VideoCrafter2 on the right.

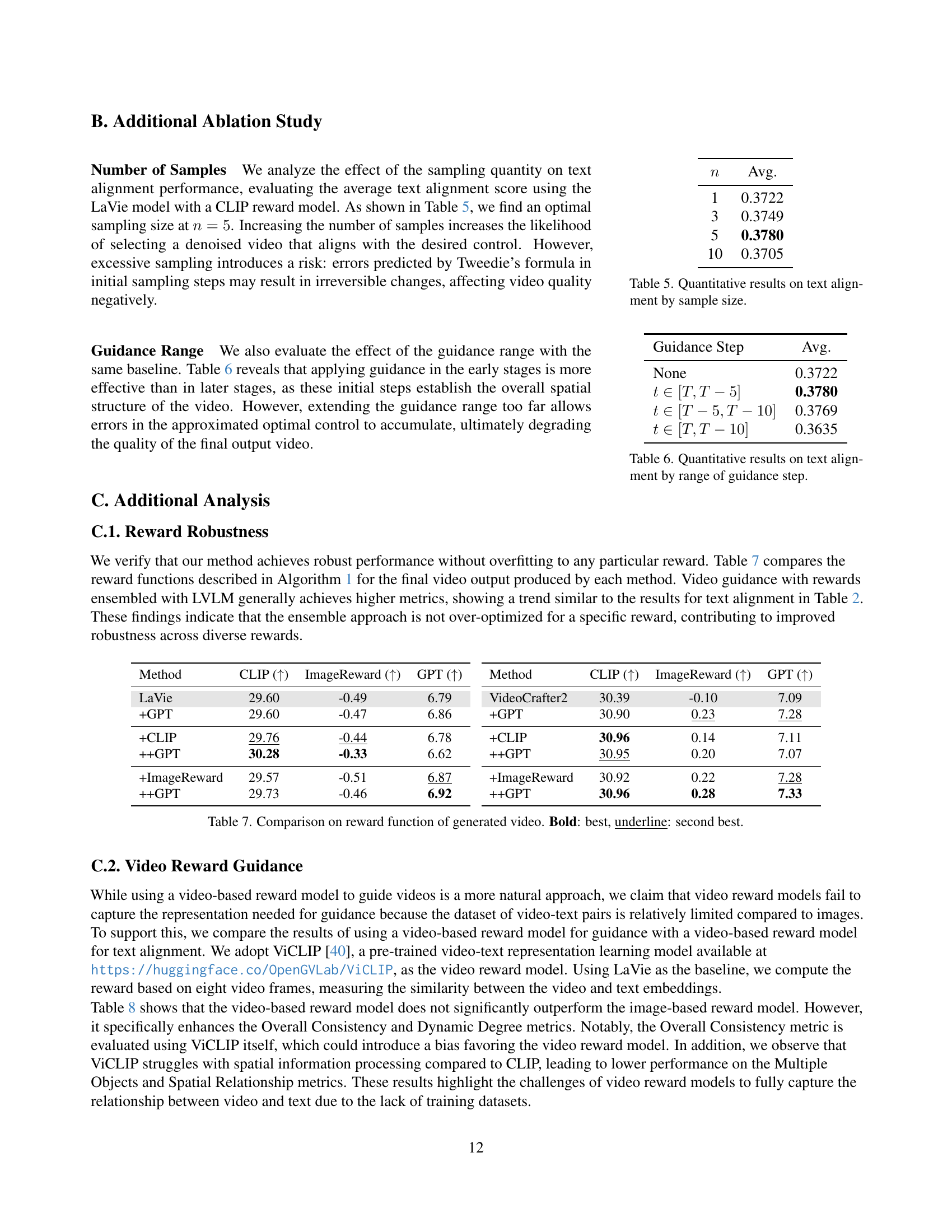
🔼 This table presents the results of an ablation study on the effect of varying the number of samples used during the sampling process of the Free²Guide model on text-to-video alignment performance. The study employed the LaVie model with CLIP reward, varying the number of samples (n) used for Monte Carlo estimation. The results show an optimal sample size, where increasing the number beyond a certain point does not further improve alignment and may introduce errors.
read the caption
Table 5: Quantitative results on text alignment by sample size.

🔼 This table presents the results of an experiment evaluating the impact of the guidance range (the number of steps during the sampling process where guidance is applied) on text alignment in video generation. It shows how different guidance ranges affect the average text alignment score, comparing results when guidance is applied in various time windows during the sampling process. The goal is to determine the optimal guidance range that balances accurate alignment with overall video quality. Using too narrow a range might not be sufficient for proper alignment, whereas too wide a range could allow for accumulation of errors during the sampling process, thus negatively impacting the overall video quality.
read the caption
Table 6: Quantitative results on text alignment by range of guidance step.
More on tables
🔼 This table presents a quantitative analysis of text-to-video alignment performance for different models. It uses the VBench benchmark to evaluate alignment across six key dimensions: Appearance Style, Temporal Style, Human Action, Multiple Objects, Spatial Relationship, and Overall Consistency. Higher scores indicate stronger alignment between the generated video and the text prompt. The numbers in parentheses show the improvement or decrease in performance compared to the baseline model for each dimension.
read the caption
Table 2: Quantitative evaluation on text alignment. Higher numbers indicate better alignment with the text prompt. The numbers in parentheses denote the performance difference from the baseline.
| Description | Description |
|---|---|
| “A person is strumming guitar” | “A dog and a horse” |
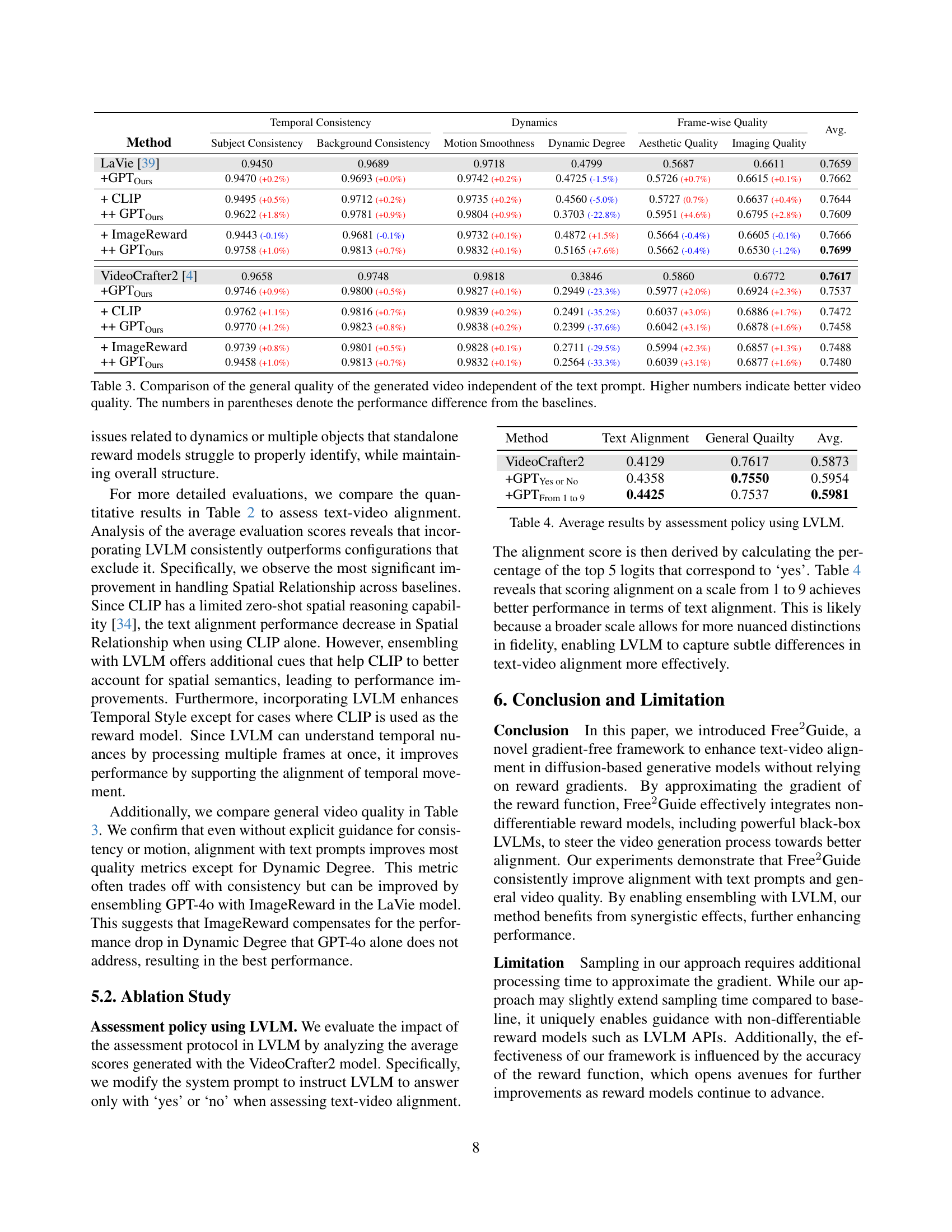
🔼 This table presents a quantitative comparison of generated video quality across different methods, irrespective of text prompt alignment. It assesses various aspects of video quality, including the consistency of subjects and backgrounds, smoothness of motion, the dynamic range of the video, the aesthetic appeal, and overall imaging quality. Higher scores indicate better overall video quality. The values in parentheses show the improvement or decline compared to the baseline model for each metric.
read the caption
Table 3: Comparison of the general quality of the generated video independent of the text prompt. Higher numbers indicate better video quality. The numbers in parentheses denote the performance difference from the baselines.
| Baseline | Free2Guide | Baseline | Free2Guide |
|---|
🔼 This table presents a comparison of the average text alignment and general video quality scores obtained using different assessment methods with the Large Vision-Language Model (LVLM). Specifically, it contrasts the results of using a binary (‘yes’/’no’) versus a 1-9 scale rating system for evaluating the alignment of generated videos with text prompts. The results highlight the impact of the assessment method on the overall performance and help to illustrate how nuanced scoring schemes (1-9 scale) can improve the evaluation accuracy for text-video alignment.
read the caption
Table 4: Average results by assessment policy using LVLM.
🔼 This table presents a comparison of the performance of different reward functions used in the Free²Guide framework for text-to-video generation. It shows the average scores achieved across different metrics (CLIP, ImageReward, and GPT-40) when using various combinations of these reward functions with the LaVie and VideoCrafter2 models. The bold and underlined values highlight the best and second-best performing reward function combinations, respectively, for each model and metric. This helps to illustrate the relative effectiveness of different reward models and strategies in guiding the generation of high-quality videos that are well-aligned with the corresponding text prompts.
read the caption
Table 7: Comparison on reward function of generated video. Bold: best, underline: second best.
| Text | Text |
|---|---|
| “A happy fuzzy panda playing guitar nearby a campfire, snow mountain in the background” | “The bund Shanghai, vibrant color” |
🔼 This table presents a comparison of video quality metrics between using image-based reward models (CLIP and ImageReward) and a video-based reward model (ViCLIP) for guiding video generation. It shows scores for various aspects of video quality, such as subject consistency, background consistency, motion smoothness, dynamic degree, aesthetic quality, and imaging quality. Higher scores signify better video quality. The numbers in parentheses indicate the improvement or degradation in each metric relative to the baseline (LaVie) model.
read the caption
Table 8: Comparison with video-based reward model. Higher numbers indicate better video quality. The numbers in parentheses denote the performance difference from the baselines.
Full paper#