↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Processing long sequences with large language models (LLMs) is computationally expensive due to the quadratic complexity of self-attention. Current solutions like Flash Attention and Ring Attention offer improvements but still face limitations in terms of scalability and memory efficiency. Existing sparse attention methods often sacrifice accuracy for efficiency.
Star Attention tackles these issues with a novel two-phase approach. Phase 1 uses efficient blockwise local attention across multiple hosts for context encoding, incorporating anchor blocks to approximate global attention and minimize communication overhead. Phase 2 performs global attention only for the query, efficiently aggregating results for faster inference. This approach scales linearly with the number of hosts, resulting in significant speed improvements and reduced memory consumption while maintaining high accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it directly addresses the significant challenge of efficient inference on long sequences. The proposed Star Attention mechanism offers a compelling solution to reduce computational costs and memory requirements associated with long-context processing, opening new avenues for applications requiring extensive contextual information. Its compatibility with existing LLMs makes it readily adoptable, thus enhancing the scalability and practicality of LLM deployments.
Visual Insights#
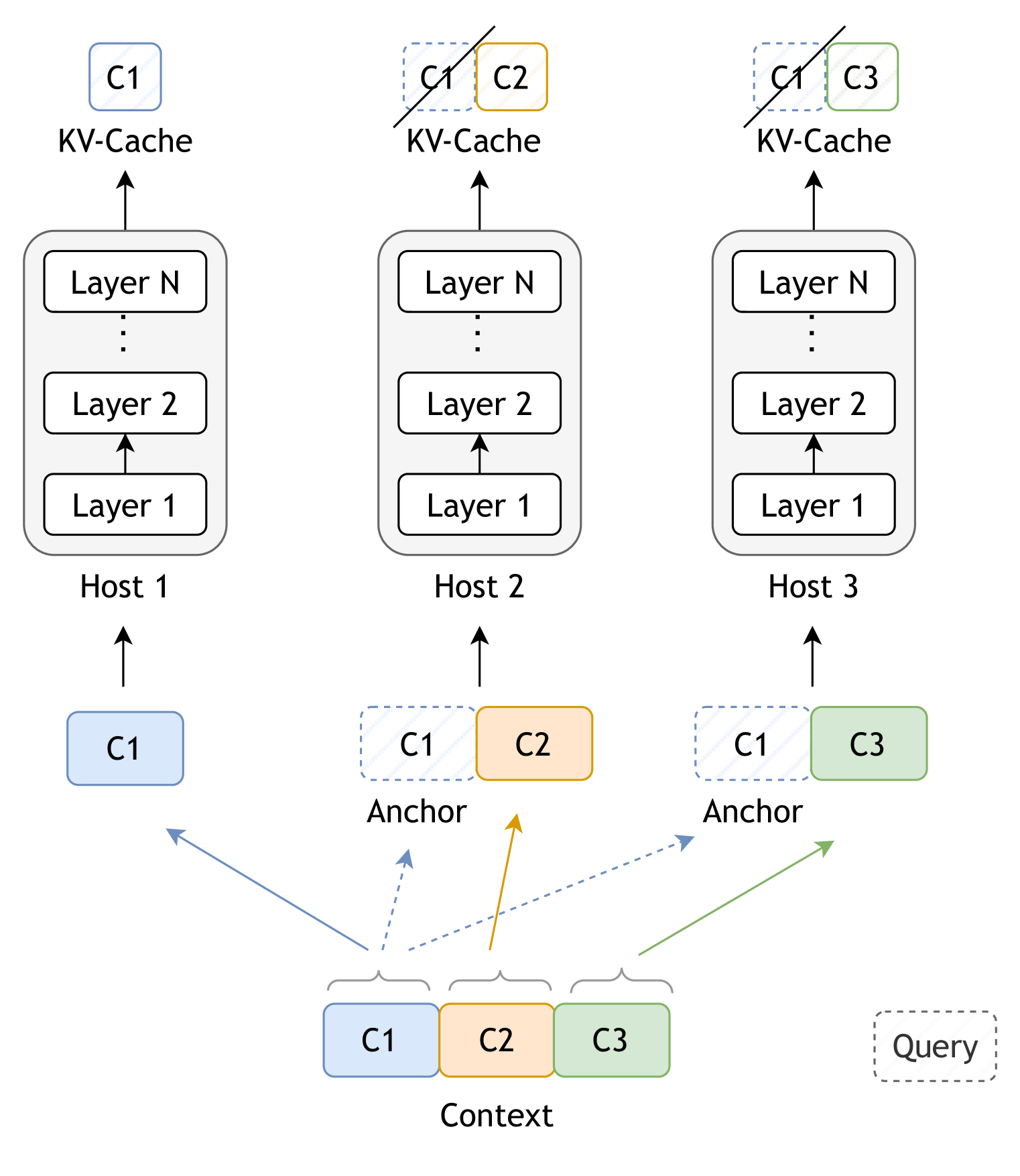
🔼 This figure illustrates the first phase of the Star Attention algorithm, called ‘Context Encoding.’ The long input context is divided into multiple blocks and distributed across several different hosts. Each host processes only its assigned block. Notably, each block (except the first) is prepended with a copy of the first block, which acts as an ‘anchor block’. This anchor block helps to maintain consistent attention patterns across blocks, preventing the formation of multiple attention ‘sinks’ which could reduce performance. The parallel processing of the blocks reduces computational complexity.
read the caption
(a) Phase 1: Local Context Encoding with Anchor Blocks
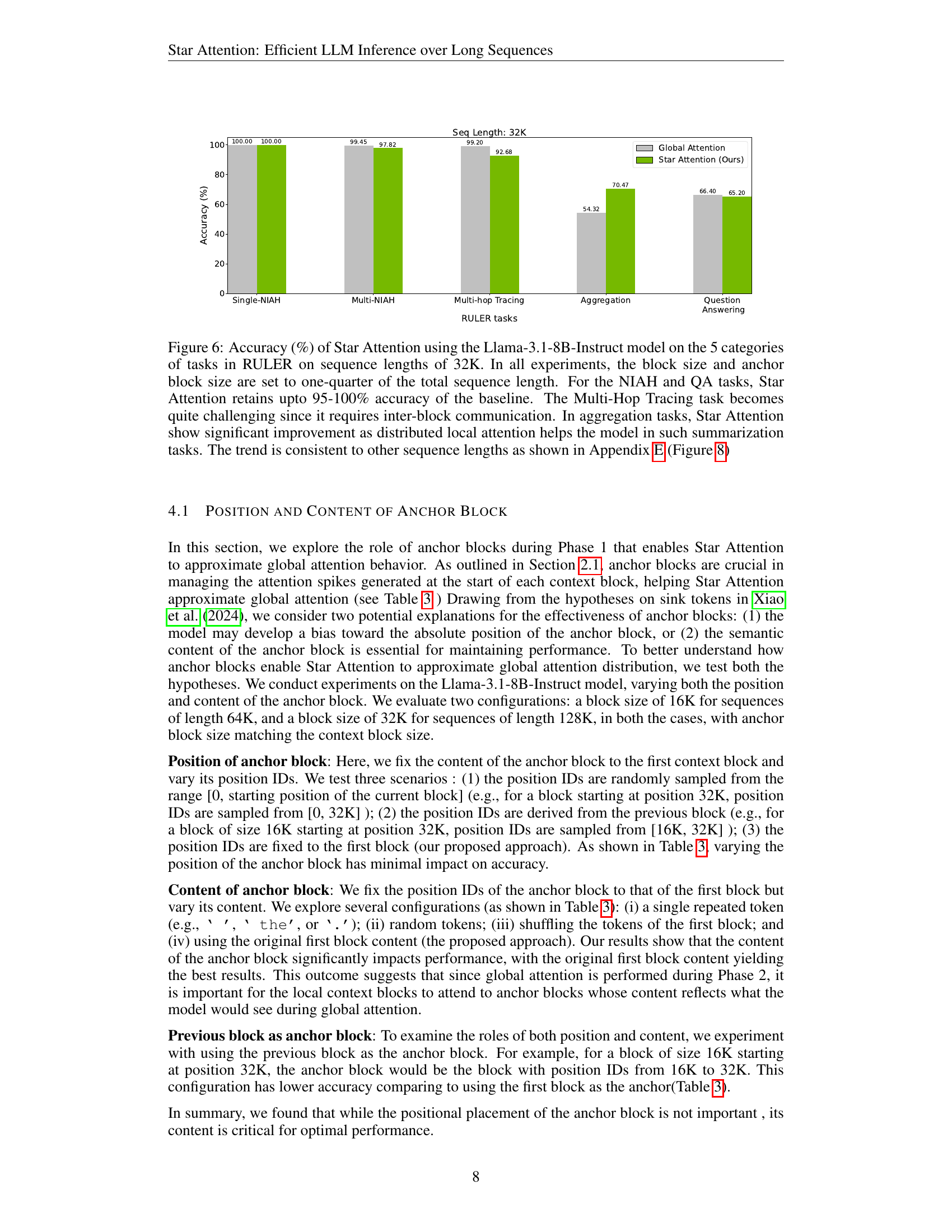
| Model | Seq. Len. (K) | Block Size (K) | Ring-Attn | Star-Attn Acc.(%) | Δ Acc. | Δ Speedup |
|---|---|---|---|---|---|---|
| 16 | 4 | 86.12 | +2.47% | 1.1x | ||
| 32 | 8 | 82.52 | +1.54% | 1.2x | ||
| 64 | 16 | 79.05 | +1.28% | 1.8x | ||
| Llama-3-8B-Instruct, 1048K Gradient.ai (2024) | 128 | 32 | 77.39 | +1.23% | 2.7x | |
| 16 | 4 | 95.09 | -2.85% | 1.7x | ||
| 32 | 8 | 94.61 | -2.70% | 2.0x | ||
| Llama-3.1-70B-Instruct, 128K Meta-AI (2024) | 64 | 16 | 88.54 | -1.63% | 4.7x |
🔼 This table compares the performance of Star Attention against Ring Attention (the baseline) across different LLMs and sequence lengths. It shows the accuracy achieved by each method and calculates the relative speedup provided by Star Attention. The change in accuracy (‘Δ Acc.’) indicates whether Star Attention improved or decreased accuracy compared to Ring Attention. The block size used for Star Attention was set to one-quarter of the sequence length. The results highlight that Star Attention significantly speeds up inference time while maintaining similar accuracy, and this improvement is even more significant for larger LLMs.
read the caption
Table 1: Star Attention vs Ring Attention (baseline) accuracy and relative inference speed-up. The ΔΔ\Deltaroman_Δ for Star Attention shows the relative accuracy improvement (+) or degradation (-). We set block size to one-quarter of the sequence length. Star Attention achieves significant speedup over Ring Attention while maintaining the accuracy. For larger models, the speedup of Star Attention is even more pronounced.
In-depth insights#
Star Attention’s Core#
Star Attention’s core innovation lies in its two-phase approach to handling long sequences. The first phase employs block-sparse attention, processing the context in parallel across multiple hosts, significantly reducing quadratic complexity. This is achieved by dividing the context into blocks and applying local attention within each block, along with the addition of an ‘anchor block’ to mitigate attention sink issues common in such methods. The second phase leverages global attention for query tokens, ensuring they attend to the entire context efficiently. This global attention is carefully aggregated from all hosts to a single query host, minimizing communication overhead. This hybrid approach combines the speed of local attention with the accuracy of global attention, offering a scalable and efficient solution for LLM inference over long sequences. The effectiveness is further enhanced by the compatibility with existing Transformer-based LLMs, requiring no model fine-tuning. This makes it a particularly practical and adaptable method for real-world applications.
Blockwise Attention#
Blockwise attention, as a crucial concept in addressing the quadratic complexity of traditional self-attention mechanisms in large language models (LLMs), offers a compelling approach to enhance efficiency. By dividing the input sequence into smaller, manageable blocks, computational costs are reduced from O(n²) to O(nb), where n is the sequence length and b is the block size. This dramatically improves performance, especially when dealing with exceptionally long sequences. However, simply partitioning the sequence can lead to information loss, potentially affecting the model’s ability to capture long-range dependencies. Effective strategies like incorporating anchor blocks or other bridging mechanisms are essential to mitigate this and maintain accuracy. The choice of block size involves a trade-off: smaller blocks offer greater efficiency but might sacrifice contextual understanding, while larger blocks preserve more context but increase computational demand. Optimal block sizes are often determined empirically, considering both the computational resources and the desired level of accuracy for the specific task. Further research is needed to explore various techniques to optimize blockwise attention, ensuring both efficiency gains and the preservation of essential semantic information for LLM tasks.
Global Attention#
Global attention, in the context of large language models (LLMs), refers to the mechanism where each token in a sequence attends to all other tokens in the sequence. This allows the model to capture long-range dependencies and contextual information crucial for understanding complex relationships within the text. However, the quadratic computational complexity of global attention makes it computationally expensive and slow for long sequences. This limitation is a major bottleneck for processing long documents or contexts in LLMs. Many recent research papers are dedicated to addressing this challenge and improving efficiency. Techniques such as sparse attention and local attention are explored to reduce the computational burden by limiting the number of attention calculations. These approaches attempt to maintain the accuracy of global attention while achieving significant speedups. Despite improvements, the trade-off between accuracy and efficiency remains a key area of research and development for LLMs, emphasizing the significance of global attention’s role in performance but the need for alternative strategies to handle its computational demands.
Accuracy vs. Speed#
The trade-off between accuracy and speed is a central theme in large language model (LLM) optimization. Star Attention aims to improve inference speed without significant accuracy loss. The paper demonstrates that increasing the context block size improves accuracy, suggesting a tunable parameter to balance speed and precision. Larger block sizes lead to higher accuracy but slower inference, while smaller block sizes offer faster inference at the cost of some accuracy. The authors present results showing that Star Attention maintains high accuracy (95-100%) even with significant speedups (up to 11x), indicating a compelling balance in many practical scenarios. However, the optimal balance point likely depends on the specific application and task, as certain tasks (like multi-hop reasoning) are more sensitive to accuracy degradation than others. Future work should investigate this nuanced relationship further, potentially through adaptive strategies that adjust block size based on task demands and input length.
Future Work#
The paper’s lack of a dedicated ‘Future Work’ section presents an opportunity for insightful speculation. Extending Star Attention to even longer sequences and larger models is crucial, requiring investigation into optimal anchor block sizes relative to context block sizes and the potential impact on accuracy. Addressing the performance degradation observed in complex tasks like multi-hop tracing, which demand inter-block communication absent in Star Attention’s current design, is paramount. Exploring modifications to facilitate more effective information propagation between blocks warrants further study. Finally, rigorous analysis of the anchor block’s role beyond managing attention spikes is essential. Understanding whether the anchor block’s semantic content or position contributes more significantly to the model’s performance could lead to more efficient designs. Benchmarking on a broader array of datasets, beyond RULER and BABILong, would strengthen the generalizability claims of Star Attention. Furthermore, a deeper investigation into the trade-offs between speed, accuracy, and block size parameters could provide valuable insights for practical application.
More visual insights#
More on figures

🔼 This phase illustrates the process of query encoding and token generation using global attention. The query is replicated across all hosts and attends to the KV cache of each host. Then global attention is computed by aggregating the results at the query host. Only the query host updates its KV cache during this phase.
read the caption
(b) Phase 2: Query Encoding and Output Generation with Global Attention

🔼 Star Attention’s two-phase inference process is illustrated. Phase 1 involves dividing the context into blocks, distributing them across hosts, and computing local attention within each block (prefixed by an ‘anchor’ block for improved accuracy). Phase 2 involves broadcasting the query, computing local attention on each host using the local KV cache, and then a designated ‘query’ host aggregates softmax statistics for global attention computation. This process repeats for each generated token.
read the caption
Figure 1: Star Attention inference flow. All devices in the system are grouped into hosts where one of the hosts is labeled as the “query” host. The input sequence is processed in two phases. Phase 1 - context encoding. The context portion of the input is partitioned into smaller blocks and distributed across hosts. All blocks, except the first, are prefixed with the initial block, called the “anchor” block. Each host processes its assigned block and stores the non-anchor portion of the KV cache. Phase 2 - query encoding and token generation. The input query is broadcast to all the hosts, where in each host, it first attends to the local KV cache computed during phase one. Then the “query” host computes global attention by aggregating the softmax normalization statistics from all the hosts. This process is repeated for each generated token.

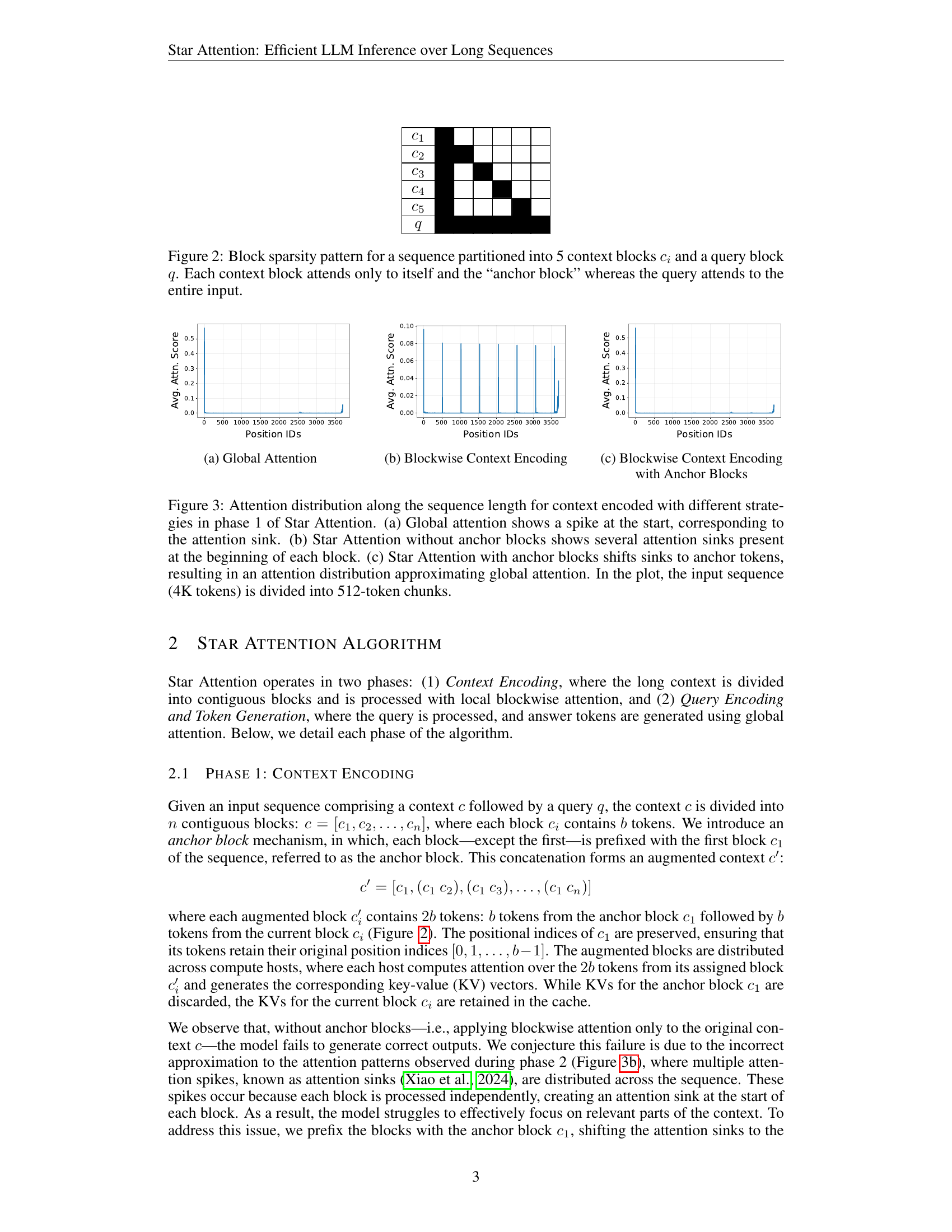
🔼 This figure illustrates the block sparsity pattern used in Star Attention. The input sequence is divided into five context blocks (c1 to c5) and a single query block (q). Each context block only attends to its own tokens and the tokens in the ‘anchor block’ (c1), resulting in blockwise sparsity. This is a localized computation. However, the query block attends to all tokens in the input sequence (both context and query), enabling it to capture global context. The pattern reflects Star Attention’s two-phase approach: localized context processing and global query-based attention.
read the caption
Figure 2: Block sparsity pattern for a sequence partitioned into 5 context blocks cisubscript𝑐𝑖c_{i}italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and a query block q𝑞qitalic_q. Each context block attends only to itself and the “anchor block” whereas the query attends to the entire input.

🔼 This figure displays the attention distribution along the sequence length for a context encoded using global attention. The x-axis represents the position IDs, and the y-axis represents the average attention score. The plot shows a clear spike or attention sink at the beginning of the sequence.
read the caption
(a) Global Attention

🔼 This figure shows the attention distribution along the sequence length when context is encoded using blockwise attention without anchor blocks (Phase 1 of Star Attention). It illustrates the attention distribution’s deviation from the global attention pattern. Multiple attention sinks are observed at the start of each block, demonstrating the suboptimal behavior of blockwise attention without the anchor block mechanism.
read the caption
(b) Blockwise Context Encoding

🔼 This figure shows the attention distribution along the sequence length for context encoded with Star Attention’s blockwise approach and the use of anchor blocks. It demonstrates how incorporating anchor blocks (the first block of the sequence, prepended to subsequent blocks) shifts attention sinks (points of high attention concentration) away from the start of each block to the beginning of the entire sequence, thus better approximating the attention pattern of global attention.
read the caption
(c) Blockwise Context Encoding with Anchor Blocks

🔼 Figure 3 illustrates the impact of different context encoding strategies on attention distribution within Star Attention’s first phase. Panel (a) displays global attention, showing a single, sharp attention spike at the sequence beginning, characteristic of an attention sink. Panel (b) depicts Star Attention without anchor blocks; here, multiple attention sinks emerge at the start of each block, indicating a less efficient attention pattern. This inefficiency is resolved in Panel (c), where Star Attention with anchor blocks is shown. The anchor blocks effectively consolidate the attention sinks near the beginning of each block, which results in an attention distribution more closely resembling the global attention pattern seen in (a). In all panels, a 4000-token input sequence is divided into 512-token chunks for analysis.
read the caption
Figure 3: Attention distribution along the sequence length for context encoded with different strategies in phase 1 of Star Attention. (a) Global attention shows a spike at the start, corresponding to the attention sink. (b) Star Attention without anchor blocks shows several attention sinks present at the beginning of each block. (c) Star Attention with anchor blocks shifts sinks to anchor tokens, resulting in an attention distribution approximating global attention. In the plot, the input sequence (4K tokens) is divided into 512-token chunks.

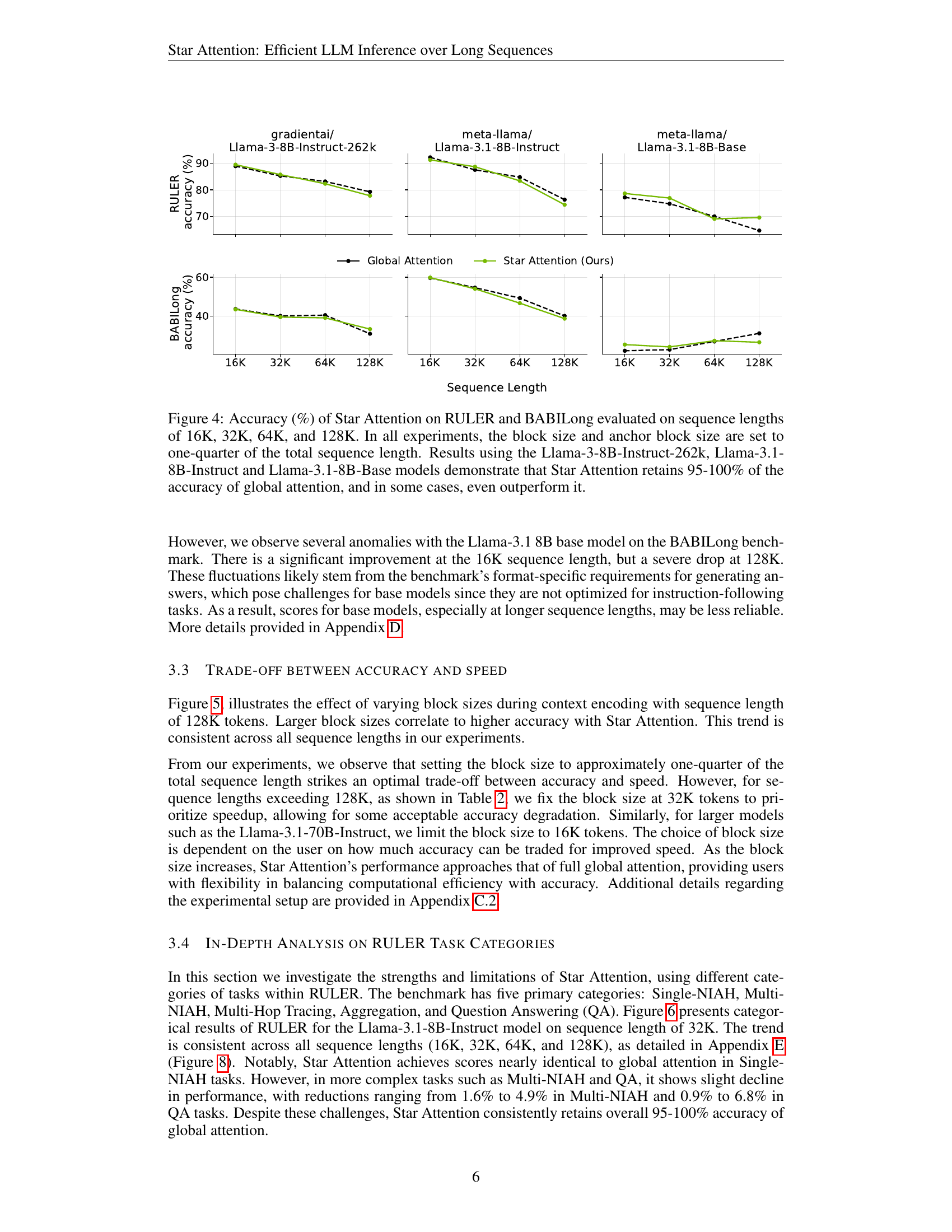
🔼 Figure 4 presents a comparison of the accuracy achieved by Star Attention against global attention across different sequence lengths (16K, 32K, 64K, and 128K) on the RULER and BABILong benchmarks. The experiment used three Llama models: Llama-3-8B-Instruct-262k, Llama-3.1-8B-Instruct, and Llama-3.1-8B-Base. For each sequence length, the block size and anchor block size for Star Attention were set to one-quarter of the total sequence length. The results show that Star Attention consistently maintains accuracy within 95-100% of global attention, and in some instances even surpasses it.
read the caption
Figure 4: Accuracy (%) of Star Attention on RULER and BABILong evaluated on sequence lengths of 16K, 32K, 64K, and 128K. In all experiments, the block size and anchor block size are set to one-quarter of the total sequence length. Results using the Llama-3-8B-Instruct-262k, Llama-3.1-8B-Instruct and Llama-3.1-8B-Base models demonstrate that Star Attention retains 95-100% of the accuracy of global attention, and in some cases, even outperform it.

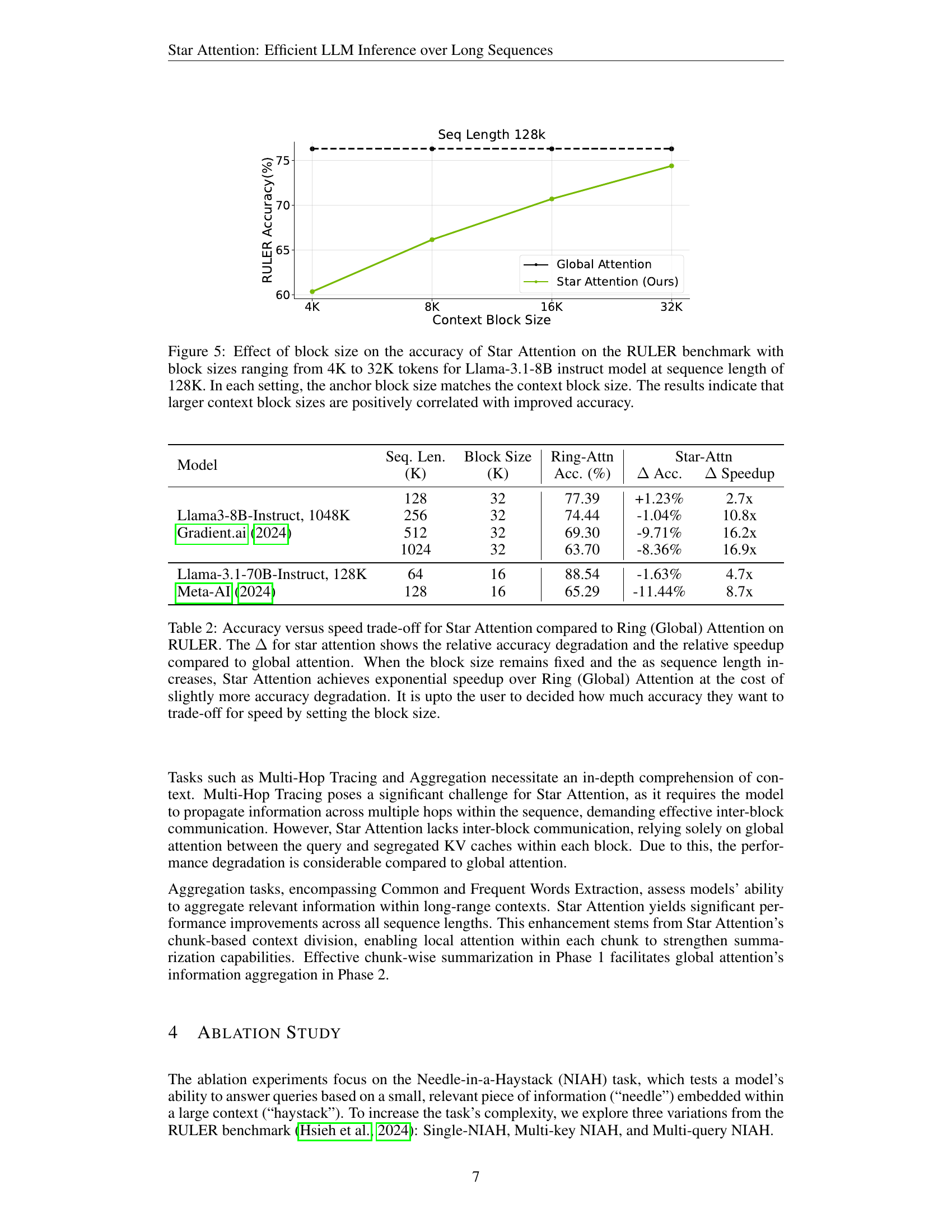
🔼 This figure illustrates the relationship between the size of the context blocks used in Star Attention and the model’s accuracy on the RULER benchmark. The experiment was conducted using the Llama-3.1-8B instruct model with a sequence length of 128K tokens. The x-axis represents the size of the context blocks (in thousands of tokens), ranging from 4K to 32K. The y-axis represents the accuracy achieved by the model. Crucially, the anchor block size was always set equal to the context block size. The graph shows a clear positive correlation: as the context block size increases, the model’s accuracy improves. This suggests that using larger context blocks allows Star Attention to capture more contextual information, leading to better performance.
read the caption
Figure 5: Effect of block size on the accuracy of Star Attention on the RULER benchmark with block sizes ranging from 4K to 32K tokens for Llama-3.1-8B instruct model at sequence length of 128K. In each setting, the anchor block size matches the context block size. The results indicate that larger context block sizes are positively correlated with improved accuracy.
More on tables
| Δ Speedup | ||||||
|---|---|---|---|---|---|---|
| 128 | 32 | 77.39 | +1.23% | 2.7x | ||
| 256 | 32 | 74.44 | -1.04% | 10.8x | ||
| 512 | 32 | 69.30 | -9.71% | 16.2x | ||
| Llama3-8B-Instruct, 1048K Gradient.ai (2024) | 1024 | 32 | 63.70 | -8.36% | 16.9x | |
| 64 | 16 | 88.54 | -1.63% | 4.7x | ||
| Llama-3.1-70B-Instruct, 128K Meta-AI (2024) | 128 | 16 | 65.29 | -11.44% | 8.7x |
🔼 This table presents a comparison of Star Attention and Ring Attention (the baseline) in terms of accuracy and inference speed on the RULER benchmark. It shows the relative accuracy change (positive indicates improvement, negative indicates degradation) and speedup achieved by Star Attention compared to Ring Attention. The results are presented for various sequence lengths and a fixed block size. As the sequence length increases, Star Attention demonstrates an exponential speedup, but with a slight decrease in accuracy. The table highlights the trade-off between speed and accuracy, allowing users to choose the block size that balances these factors according to their needs.
read the caption
Table 2: Accuracy versus speed trade-off for Star Attention compared to Ring (Global) Attention on RULER. The ΔΔ\Deltaroman_Δ for star attention shows the relative accuracy degradation and the relative speedup compared to global attention. When the block size remains fixed and the as sequence length increases, Star Attention achieves exponential speedup over Ring (Global) Attention at the cost of slightly more accuracy degradation. It is upto the user to decided how much accuracy they want to trade-off for speed by setting the block size.
| Experiments | RULER-NIAH (%) | RULER-NIAH (%) | RULER-NIAH (%) | RULER-NIAH (%) |
|---|---|---|---|---|
| 64K | Δ64k | 128k | Δ128k | |
| Global attention | 99.50 | - | 98.49 | - |
| No anchor block | 60.11 | -39.59% | 73.75 | -25.12% |
| Content set to first-block, position IDs are: | ||||
| randomly sampled from [0, current_block) | 96.79 | -2.72% | 97.16 | -1.35% |
| same as previous block | 97.35 | -2.16% | 96.80 | -1.71% |
| same as first block | 97.61 | -1.90% | 97.54 | -0.96% |
| Position IDs set to first-block, content is: | ||||
| constant token (ex: ‘ ’ or ‘ the’ or ‘.’ ) | 0.00 | -100.00% | 0 | -100.00% |
| random tokens | 90.55 | -8.99% | 82.63 | -10.15% |
| shuffled first block tokens | 92.96 | -6.57% | 90.76 | -3.26% |
| first block tokens | 97.61 | -1.90% | 94.94 | -0.96% |
| Previous-block used as anchor | 94.20 | -5.33% | 96.13 | -2.40% |
🔼 This table presents an ablation study on the Star Attention model, specifically focusing on the impact of the anchor block’s position and content on the model’s performance. The study uses the LLaMA-3.1-8B-Instruct model with two different sequence lengths (64K and 128K) and corresponding block sizes (16K and 32K respectively). The table compares the accuracy of Star Attention against global attention under four different conditions: (1) No anchor block, (2) Varying the position IDs of the anchor block, (3) Varying the content of the anchor block, and (4) Varying both position and content. The relative accuracy degradation (Δ) compared to the global attention is calculated for Star Attention in each scenario. The results demonstrate that while the anchor block’s position is less crucial, its content is vital for achieving optimal performance with Star Attention.
read the caption
Table 3: Experiments on analyzing the impact of varying the position and content of the anchor block with the LLaMA-3.1-8B-Instruct model, with a block size of 16K for 64K sequence length, and 32K for 128K sequence lengths. In each setting, the size of the anchor block matches the context block size. The ΔΔ\Deltaroman_Δ for star attention shows the relative accuracy degradation compared to global attention. The experiments are categorized into 4 groups: (i) absence of anchor block; (ii) varying the position IDs; (iii) varying the content; (iv) varying both the position and the content. Results indicate that while the anchor block’s position is not critical, its content is essential for optimal performance.
| Task | Haystack | Keys Type | Keys # | Values Type | Values # | # Outputs |
|---|---|---|---|---|---|---|
| Category Name | Type | |||||
| Single 1 | noise | words | 1 | numbers | 1 | 1 |
| Single 2 | book | words | 1 | numbers | 1 | 1 |
| Single 3 | book | words | 1 | uuids | 1 | 1 |
| MultiKey 1 | book | words | 4 | numbers | 1 | 1 |
| MultiKey 2 | line | words | ∞ | numbers | 1 | 1 |
| MultiKey 3 | kv | uuids | ∞ | uuids | 1 | 1 |
| MultiValue | book | words | 1 | numbers | 4 | 1 |
| NIAH (Retrieval) MultiQuery | book | words | 4 | numbers | 1 | 4 |
| Multi-Hop Tracing Variable Tracking | – | |||||
| Common Words Extraction | – | |||||
| Aggregation Frequent Words Extraction | – | |||||
| Question Answering QA 1 (squad) | – | |||||
| Answering QA 2 (hotpotqa) | – |
🔼 This table details the configuration of the tasks used in the RULER benchmark. For each task, it shows the category (Retrieval, Multi-Hop Tracing, Aggregation, Question Answering), the task name, the type of haystack (the long text), the type of keys and values used, the number of keys and values, and the number of outputs. This provides a comprehensive overview of the various challenges presented by the RULER benchmark dataset.
read the caption
Table 4: Configuration of RULER tasks
| Multi-Hop | |
|---|---|
| Tracing |
🔼 The BABILong benchmark consists of 5 tasks, each involving a different number of supporting facts. The tasks simulate scenarios with characters and objects moving and interacting in various locations. Each interaction is described by a factual statement. The goal is to answer questions based on these facts, testing the model’s ability to reason across multiple facts and complex scenarios. The table details the number of facts per task, distinguishing between single, double, and triple fact scenarios, as well as tasks involving two or three argument relations. This allows for a comprehensive evaluation of the model’s ability to handle varying levels of complexity in long-context reasoning.
read the caption
Table 5: Configuration of tasks in BABILong
| Task | Name | # Facts per task |
|---|---|---|
| qa1 | single supporting fact | 2 - 10 |
| qa2 | two supporting facts | 2 - 68 |
| qa3 | three supporting facts | 4 - 32 |
| qa4 | two arg relations | 2 |
| qa5 | three arg relations | 2 - 126 |
🔼 This table compares the inference time per sample for three different methods: vanilla autoregressive generation, Ring Attention, and Star Attention. The experiment uses the Llama3.1-8B-Instruct model and 8 A100 GPUs. The results show that vanilla autoregressive generation runs out of memory (OOM) when processing sequences longer than 64K tokens. For shorter sequences (up to 32K tokens), vanilla generation is fastest. However, for longer sequences, Star Attention demonstrates significantly faster inference times than both vanilla generation and Ring Attention.
read the caption
Table 6: Time per sample (seconds) for Llama3.1-8B-Instruct model with vanilla (global) inference, ring (global) and star attention, using 8 A100 GPUs. Vanilla autoregressive generation encounters out-of-memory (OOM) at 128K sequence length. It performs best in short context scenarios (i.e. sequences upto 32K tokens) but in long context scenarios, star attention demonstrates significant speedup.
| Seq. Length | Time Per Sample (s) | ||
|---|---|---|---|
| (K) | Vanilla | Ring | Star |
| 16 | 7 | 10 | 9 |
| 32 | 10 | 12 | 10 |
| 64 | 18 | 22 | 12 |
| 128 | OOM | 53 | 20 |
🔼 This table details the computational resources utilized in the speedup experiments comparing Star Attention and Ring Attention. Specifically, it shows the model size (in terms of parameters), the sequence length processed, the number of GPUs used, and the number of parallel workers employed for each experiment configuration. This information is crucial for understanding the scalability and efficiency of the proposed Star Attention method relative to the baseline Ring Attention approach.
read the caption
Table 7: Resources used for the speedup experiments
| Model Size | Seq. Length | # GPUs | # Workers |
|---|---|---|---|
| 8B | 16K - 128K | 8 | 4 |
| 256K - 512K | 16 | 8 | |
| 1M | 32 | 16 | |
| 70B | 16K - 32K | 8 | 4 |
| 64K | 16 | 4 | |
| 128K | 32 | 8 |
🔼 This table presents a comparison of the accuracy achieved by Star Attention against global attention across different sequence lengths (16K, 32K, 64K, and 128K) on two benchmark datasets: RULER and BABILONG. Three different Llama-based language models were used in the evaluation: Llama-3-8B-Instruct-262k, Llama-3.1-8B-Instruct, and Llama-3.1-8B-Base. For each model and sequence length, the accuracy of Star Attention is reported as a percentage, along with the percentage difference compared to the accuracy achieved with global attention. The results show that Star Attention generally maintains a high level of accuracy (95-100%) compared to global attention, while sometimes even slightly surpassing global attention’s performance.
read the caption
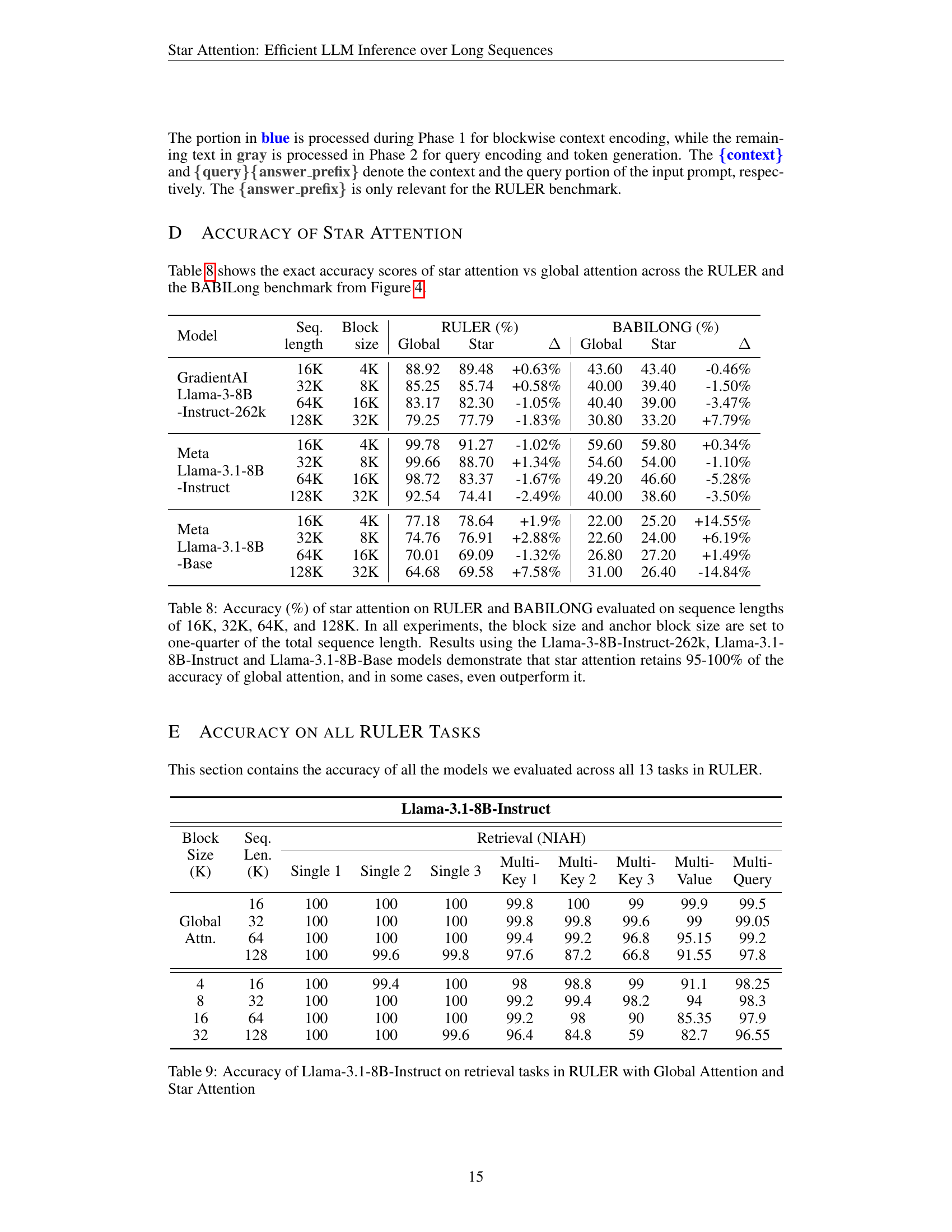
Table 8: Accuracy (%) of star attention on RULER and BABILONG evaluated on sequence lengths of 16K, 32K, 64K, and 128K. In all experiments, the block size and anchor block size are set to one-quarter of the total sequence length. Results using the Llama-3-8B-Instruct-262k, Llama-3.1-8B-Instruct and Llama-3.1-8B-Base models demonstrate that star attention retains 95-100% of the accuracy of global attention, and in some cases, even outperform it.
| Model | Seq. length | Block size | RULER (%) Global | RULER (%) Star | RULER (%) Δ | BABILONG (%) Global | BABILONG (%) Star | BABILONG (%) Δ |
|---|---|---|---|---|---|---|---|---|
| GradientAI Llama-3-8B -Instruct-262k | 16K | 4K | 88.92 | 89.48 | +0.63% | 43.60 | 43.40 | -0.46% |
| 32K | 8K | 85.25 | 85.74 | +0.58% | 40.00 | 39.40 | -1.50% | |
| 64K | 16K | 83.17 | 82.30 | -1.05% | 40.40 | 39.00 | -3.47% | |
| 128K | 32K | 79.25 | 77.79 | -1.83% | 30.80 | 33.20 | +7.79% | |
| Meta Llama-3.1-8B -Instruct | 16K | 4K | 99.78 | 91.27 | -1.02% | 59.60 | 59.80 | +0.34% |
| 32K | 8K | 99.66 | 88.70 | +1.34% | 54.60 | 54.00 | -1.10% | |
| 64K | 16K | 98.72 | 83.37 | -1.67% | 49.20 | 46.60 | -5.28% | |
| 128K | 32K | 92.54 | 74.41 | -2.49% | 40.00 | 38.60 | -3.50% | |
| Meta Llama-3.1-8B -Base | 16K | 4K | 77.18 | 78.64 | +1.9% | 22.00 | 25.20 | +14.55% |
| 32K | 8K | 74.76 | 76.91 | +2.88% | 22.60 | 24.00 | +6.19% | |
| 64K | 16K | 70.01 | 69.09 | -1.32% | 26.80 | 27.20 | +1.49% | |
| 128K | 32K | 64.68 | 69.58 | +7.58% | 31.00 | 26.40 | -14.84% |
🔼 This table presents a detailed comparison of the accuracy achieved by the Llama-3.1-8B-Instruct language model on various retrieval tasks within the RULER benchmark. It contrasts the performance of the model using standard global attention against its performance using the Star Attention method proposed in the paper. Results are broken down by the size of context blocks (4K, 8K, 16K, 32K) and sequence length (16K, 32K, 64K, 128K). Each row showcases accuracy for a specific block size and sequence length, providing a comprehensive assessment of the effect of Star Attention on accuracy across a range of settings.
read the caption
Table 9: Accuracy of Llama-3.1-8B-Instruct on retrieval tasks in RULER with Global Attention and Star Attention
| Model | Block Size (K) | Seq. Len. (K) | Retrieval (NIAH) Single 1 | Retrieval (NIAH) Single 2 | Retrieval (NIAH) Single 3 | Retrieval (NIAH) Multi-Key 1 | Retrieval (NIAH) Multi-Key 2 | Retrieval (NIAH) Multi-Key 3 | Retrieval (NIAH) Multi-Value | Retrieval (NIAH) Multi-Query |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct | Global Attn. | |||||||||
| 16 | 100 | 100 | 100 | 100 | 99.8 | 100 | 99 | 99.9 | 99.5 | |
| 32 | 100 | 100 | 100 | 100 | 99.8 | 99.8 | 99.6 | 99 | 99.05 | |
| 64 | 100 | 100 | 100 | 100 | 99.4 | 99.2 | 96.8 | 95.15 | 99.2 | |
| 128 | 100 | 99.6 | 99.8 | 97.6 | 87.2 | 66.8 | 91.55 | 97.8 | ||
| 4 | 16 | 100 | 99.4 | 100 | 98 | 98.8 | 99 | 91.1 | 98.25 | |
| 8 | 32 | 100 | 100 | 100 | 99.2 | 99.4 | 98.2 | 94 | 98.3 | |
| 16 | 64 | 100 | 100 | 100 | 99.2 | 98 | 90 | 85.35 | 97.9 | |
| 32 | 128 | 100 | 100 | 99.6 | 96.4 | 84.8 | 59 | 82.7 | 96.55 |
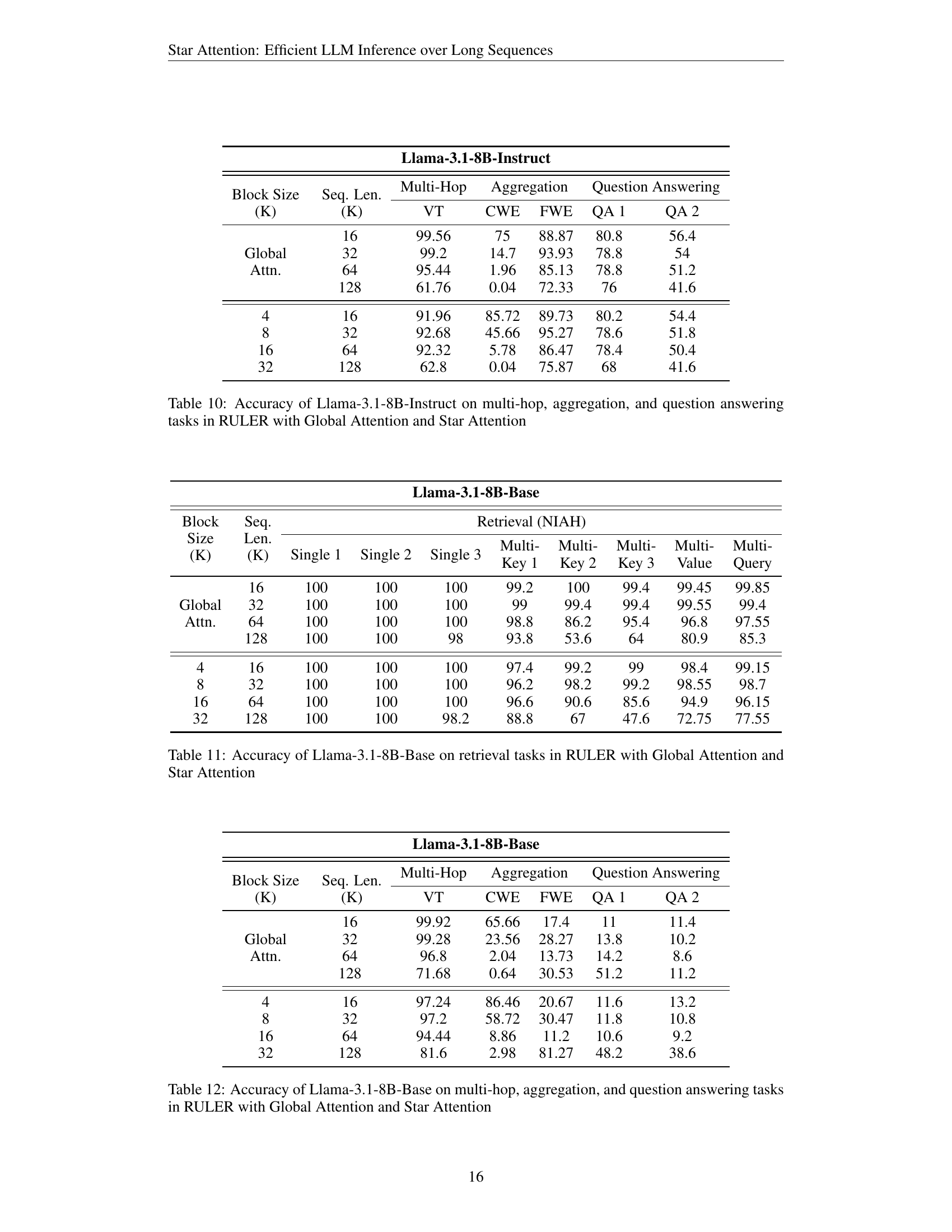
🔼 This table presents the accuracy results for the Llama-3.1-8B-Instruct model on various long-context tasks within the RULER benchmark. It compares the performance of the model using global attention against Star Attention, a novel method introduced in the paper for efficient LLM inference. The tasks evaluated include multi-hop reasoning, aggregation, and question answering, and the results are presented for different sequence lengths and block sizes. The table demonstrates the impact of Star Attention on the accuracy of these tasks.
read the caption
Table 10: Accuracy of Llama-3.1-8B-Instruct on multi-hop, aggregation, and question answering tasks in RULER with Global Attention and Star Attention
| Multi- | Key 1 |
|---|
🔼 This table presents the accuracy comparison between the global attention mechanism and the Star Attention method on various retrieval tasks within the RULER benchmark, specifically using the Llama-3.1-8B-Base language model. It shows the accuracy achieved by each method across different sequence lengths (16K, 32K, 64K, and 128K) and varying block sizes. Each row represents a different experimental setup, and multiple columns show the accuracy for distinct subtasks within the retrieval category (Single NIAH, Multi-Key NIAH, Multi-Value, etc.) providing a granular view of performance.
read the caption
Table 11: Accuracy of Llama-3.1-8B-Base on retrieval tasks in RULER with Global Attention and Star Attention
| Multi- | Key 2 |
|---|
🔼 This table presents a comparison of the accuracy achieved by Llama-3.1-8B-Base model on multi-hop, aggregation, and question answering tasks within the RULER benchmark, using both global attention and Star Attention mechanisms. It shows the performance variation across different sequence lengths (16K, 32K, 64K, and 128K) and varying block sizes (4K, 8K, 16K, and 32K). The results highlight the effectiveness of Star Attention, especially at longer sequences, while also providing insights into the performance trade-off between accuracy and speed as influenced by block sizes.
read the caption
Table 12: Accuracy of Llama-3.1-8B-Base on multi-hop, aggregation, and question answering tasks in RULER with Global Attention and Star Attention
| Multi- | |
|---|---|
| Key 3 |
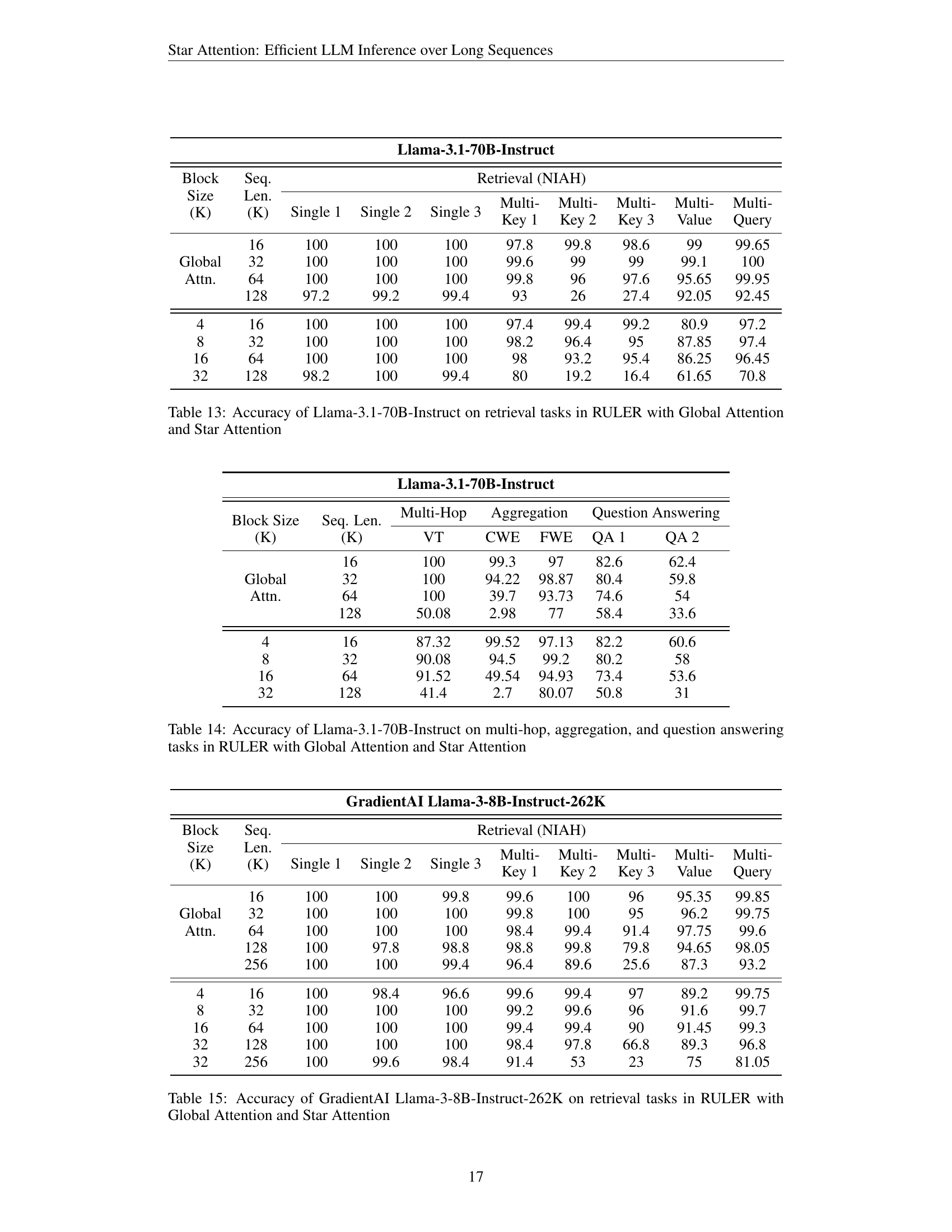
🔼 This table presents the accuracy results for the Llama-3.1-70B-Instruct language model on a subset of retrieval tasks from the RULER benchmark. It compares the performance of the model using two different attention mechanisms: global attention (the standard approach) and Star Attention (the novel method proposed in the paper). The table shows the accuracy achieved by each method for different sequence lengths and block sizes, allowing for a direct comparison of their performance. Block size refers to the size of the context chunks used during the context encoding phase of Star Attention. The results highlight how Star Attention affects accuracy on different sequence lengths and various subtasks within the broader RULER benchmark.
read the caption
Table 13: Accuracy of Llama-3.1-70B-Instruct on retrieval tasks in RULER with Global Attention and Star Attention
| Multi-Value |
|---|
🔼 This table presents the accuracy results of the Llama-3.1-70B-Instruct language model on three task categories from the RULER benchmark: Multi-hop, Aggregation, and Question Answering. It compares the performance of the model using global attention (the standard approach) against the performance using Star Attention (the proposed method). The results are shown for different sequence lengths and various block sizes, providing insights into the impact of Star Attention on the accuracy of the model across different task complexities and sequence lengths.
read the caption
Table 14: Accuracy of Llama-3.1-70B-Instruct on multi-hop, aggregation, and question answering tasks in RULER with Global Attention and Star Attention
| Multi- | Query |
|---|
🔼 This table presents the accuracy results of the GradientAI Llama-3-8B-Instruct-262K language model on the retrieval tasks within the RULER benchmark. It compares the model’s performance using two different attention mechanisms: Global Attention (the standard approach) and Star Attention (the novel method proposed in the paper). The results are broken down by different sequence lengths (from 16K to 256K tokens) and block sizes, allowing for an analysis of the trade-off between accuracy and efficiency of Star Attention at various scales.
read the caption
Table 15: Accuracy of GradientAI Llama-3-8B-Instruct-262K on retrieval tasks in RULER with Global Attention and Star Attention
| Llama-3.1-8B-Instruct | Multi-Hop | Aggregation | Question Answering | ||||
|---|---|---|---|---|---|---|---|
| Block Size (K) | Seq. Len. (K) | VT | CWE | FWE | QA 1 | QA 2 | |
| Global Attn. | 16 | 99.56 | 75 | 88.87 | 80.8 | 56.4 | |
| 32 | 99.2 | 14.7 | 93.93 | 78.8 | 54 | ||
| 64 | 95.44 | 1.96 | 85.13 | 78.8 | 51.2 | ||
| 128 | 61.76 | 0.04 | 72.33 | 76 | 41.6 | ||
| 4 | 16 | 91.96 | 85.72 | 89.73 | 80.2 | 54.4 | |
| 8 | 32 | 92.68 | 45.66 | 95.27 | 78.6 | 51.8 | |
| 16 | 64 | 92.32 | 5.78 | 86.47 | 78.4 | 50.4 | |
| 32 | 128 | 62.8 | 0.04 | 75.87 | 68 | 41.6 |
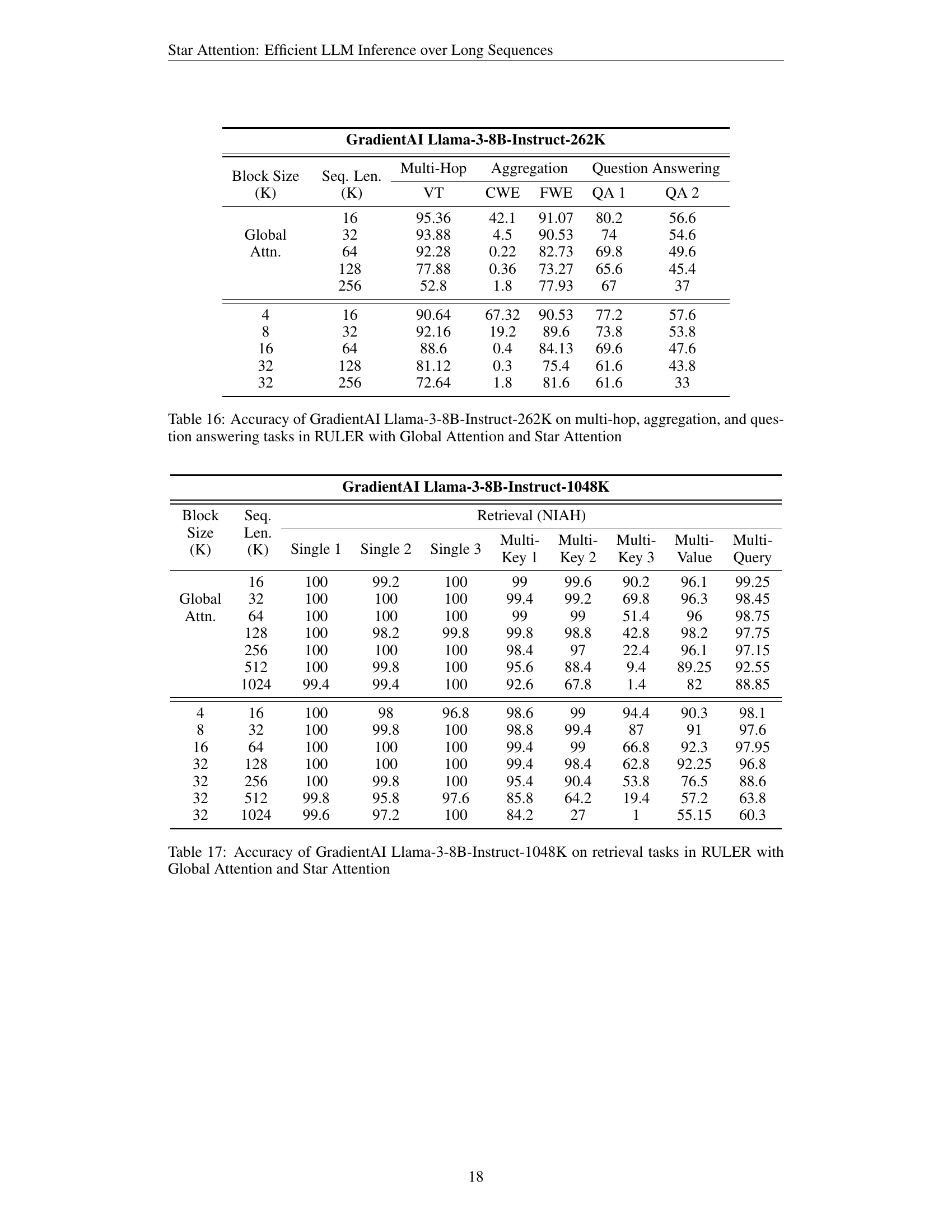
🔼 This table presents the accuracy results of the GradientAI Llama-3-8B-Instruct-262K model on various question answering tasks from the RULER benchmark. It compares the model’s performance using global attention against its performance when using Star Attention, a novel method introduced in the paper for efficient LLM inference over long sequences. The results are broken down by several factors, including the sequence length, the size of the blocks used in the Star Attention method, and the specific sub-task within the RULER benchmark (e.g., multi-hop reasoning, aggregation, different question answering tasks). This allows for a comparison of accuracy trade-offs between global attention and Star Attention under different conditions. The goal is to show how Star Attention impacts accuracy on various types of tasks and sequence lengths compared to using full global attention.
read the caption
Table 16: Accuracy of GradientAI Llama-3-8B-Instruct-262K on multi-hop, aggregation, and question answering tasks in RULER with Global Attention and Star Attention
| Model | Block Size (K) | Seq. Len. (K) | Retrieval (NIAH) Single 1 | Retrieval (NIAH) Single 2 | Retrieval (NIAH) Single 3 | Retrieval (NIAH) Multi-Key 1 | Retrieval (NIAH) Multi-Key 2 | Retrieval (NIAH) Multi-Key 3 | Retrieval (NIAH) Multi-Value | Retrieval (NIAH) Multi-Query |
|---|---|---|---|---|---|---|---|---|---|---|
| Llama-3.1-8B-Base | Global Attn. 16 | 16 | 100 | 100 | 100 | 100 | 99.2 | 100 | 99.4 | 99.45 |
| 32 | 32 | 100 | 100 | 100 | 99 | 99.4 | 99.4 | 99.55 | 99.4 | |
| 64 | 64 | 100 | 100 | 100 | 98.8 | 86.2 | 95.4 | 96.8 | 97.55 | |
| 128 | 128 | 100 | 100 | 98 | 93.8 | 53.6 | 64 | 80.9 | 85.3 | |
| 4 | 4 | 16 | 100 | 100 | 100 | 97.4 | 99.2 | 99 | 98.4 | |
| 8 | 8 | 32 | 100 | 100 | 100 | 96.2 | 98.2 | 99.2 | 98.55 | |
| 16 | 16 | 64 | 100 | 100 | 100 | 96.6 | 90.6 | 85.6 | 94.9 | |
| 32 | 32 | 128 | 100 | 100 | 98.2 | 88.8 | 67 | 47.6 | 72.75 |
🔼 This table presents the accuracy comparison between global attention and Star Attention on retrieval tasks from the RULER benchmark, using the GradientAI Llama-3-8B-Instruct-1048K model. It shows the accuracy for various sequence lengths (16K, 32K, 64K, 128K, 256K, 512K, and 1024K tokens) and different block sizes (4K, 8K, 16K, and 32K tokens) for each of the five sub-tasks within the Needle-in-a-Haystack (NIAH) category of RULER: Single 1, Single 2, Single 3, Multi-Key 1, Multi-Key 2, Multi-Key 3, Multi-Value, and Multi-Query. The results illustrate the impact of both sequence length and block size on model accuracy and the effectiveness of Star Attention in approximating global attention.
read the caption
Table 17: Accuracy of GradientAI Llama-3-8B-Instruct-1048K on retrieval tasks in RULER with Global Attention and Star Attention
| Multi- | |
|---|---|
| Key 1 |
🔼 This table presents the performance comparison between Global Attention and Star Attention on the GradientAI Llama-3-8B-Instruct-1048K model for multi-hop reasoning, aggregation, and question answering tasks within the RULER benchmark. It shows the accuracy achieved by each method across various sequence lengths and block sizes, offering insights into Star Attention’s effectiveness and trade-offs with different configurations.
read the caption
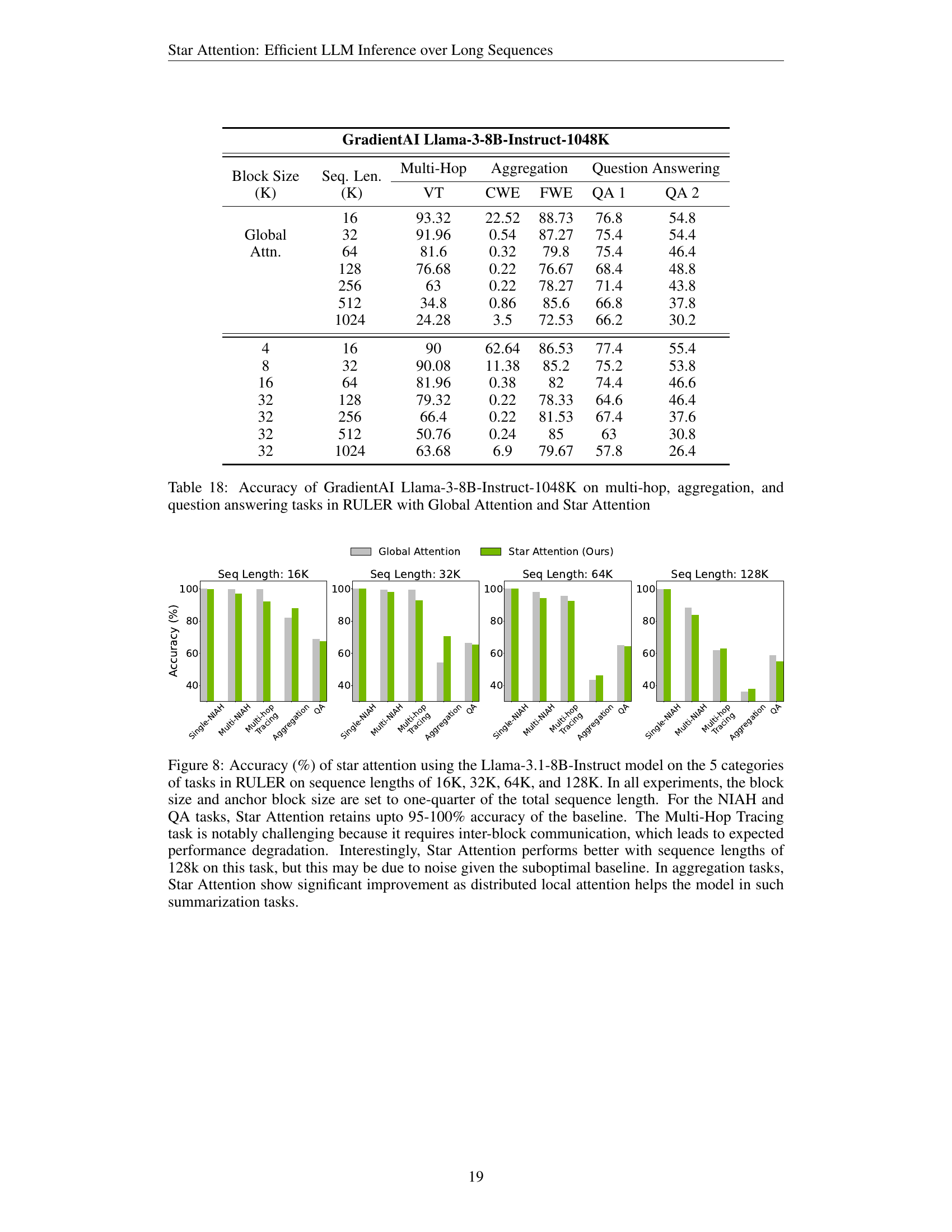
Table 18: Accuracy of GradientAI Llama-3-8B-Instruct-1048K on multi-hop, aggregation, and question answering tasks in RULER with Global Attention and Star Attention
Full paper#