↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-image (T2I) models are complex to use, requiring users to carefully craft prompts, select models, and configure arguments. This paper tackles this usability challenge by proposing Automatic T2I, where users describe their needs in a natural, conversational way. Existing methods focus only on automating specific steps, while this work aims for comprehensive automation of the entire process, from prompts to model selection and argument configuration.
To achieve this, the researchers introduce ChatGen-Evo, a novel multi-stage system that leverages a large language model. ChatGen-Evo progressively learns to generate prompts, select models, and configure arguments. It is evaluated on ChatGenBench, a new benchmark dataset designed to assess the performance across all these steps. Results show that ChatGen-Evo substantially outperforms existing approaches, showcasing the effectiveness of the multi-stage learning strategy. The paper also offers valuable insights for improving automatic T2I, highlighting the importance of each stage and suggesting directions for future research.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a significant challenge in text-to-image generation: the complexity of prompt engineering and model selection for non-experts. ChatGen-Evo’s multi-stage approach provides a novel solution, paving the way for more user-friendly and efficient image generation. The introduced benchmark, ChatGenBench, offers valuable resources for future research in automated image generation, prompting further investigation into multi-step reasoning and model selection strategies.
Visual Insights#

🔼 The figure illustrates the multiple steps involved in text-to-image (T2I) generation using existing methods. It highlights three main stages: crafting effective prompts, selecting suitable models, and configuring optimal generation arguments. The complexity of each step presents a significant challenge for users. In contrast, the authors’ proposed method automates these steps, allowing for straightforward image generation through simple freestyle chatting.
read the caption
Figure 1: Illustration of tedious steps in T2I. Our method can select an appropriate model with suitable prompts and arguments. Note: Arle is a character from the game Genshin Impact.
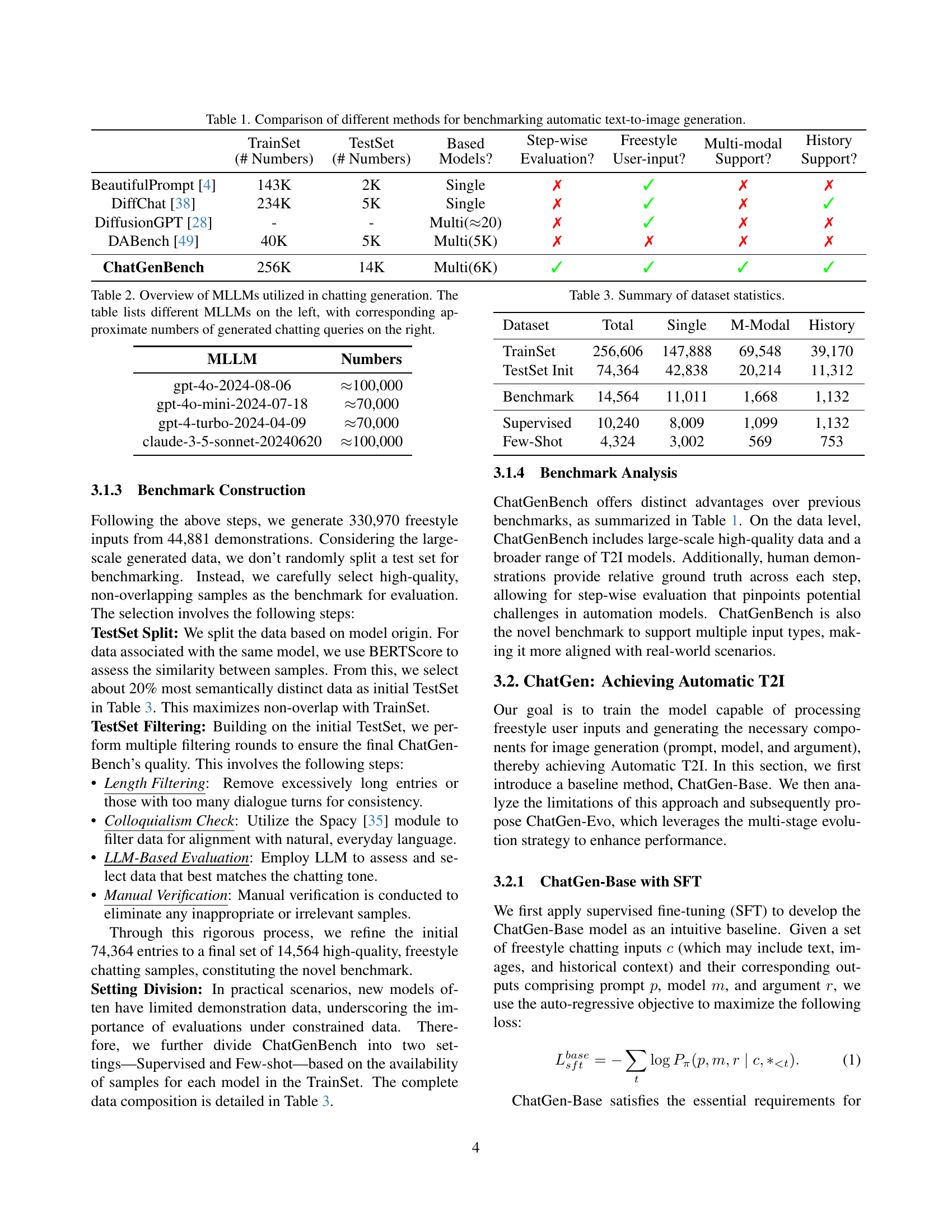
| Model | TrainSet (# Numbers) | TestSet (# Numbers) | Based Models? | Step-wise Evaluation? | Freestyle User-input? | Multi-modal Support? | History Support? |
|---|---|---|---|---|---|---|---|
| BeautifulPrompt [4] | 143K | 2K | Single | ✗ | ✓ | ✗ | ✗ |
| DiffChat [38] | 234K | 5K | Single | ✗ | ✓ | ✗ | ✓ |
| DiffusionGPT [28] | - | - | Multi(≈20) | ✗ | ✓ | ✗ | ✗ |
| DABench [49] | 40K | 5K | Multi(5K) | ✗ | ✗ | ✗ | ✗ |
| ChatGenBench | 256K | 14K | Multi(6K) | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares various methods used for benchmarking automatic text-to-image generation. It contrasts approaches on several key aspects: the size of their training and testing datasets, whether they utilize single or multiple models, whether they perform step-wise evaluation to analyze the individual stages of prompt generation, model selection, and argument configuration, whether they support freestyle user input (as opposed to structured prompts), their capability to handle multi-modal inputs (like text and images), and finally whether they consider historical data in the input sequences. This allows for a comprehensive comparison of the strengths and weaknesses of different benchmarking strategies.
read the caption
Table 1: Comparison of different methods for benchmarking automatic text-to-image generation.
In-depth insights#
Auto-T2I: A New Frontier#
Auto-T2I, or automatic text-to-image generation, represents a significant advancement in AI, moving beyond the limitations of traditional methods. It tackles the inherent complexities of the T2I pipeline, automating the previously tedious steps of prompt engineering, model selection, and argument configuration. This automation is crucial for broader accessibility, empowering non-expert users to effortlessly generate images aligned with their specific needs. The research highlights the challenges of handling diverse, freestyle input—a key characteristic of real-world user interactions—making robust, flexible model design paramount. Multi-stage evolution strategies such as those explored appear particularly promising in addressing the inherent complexity of the process, enabling progressive skill acquisition. The development of dedicated benchmarks, like ChatGenBench, is crucial for evaluating such systems. This benchmark offers a comprehensive and step-wise evaluation, incorporating metrics for various aspects of the pipeline, including prompt quality, model choice, argument settings and overall image quality. The ultimate goal of Auto-T2I is to democratize image generation, making it intuitive and readily available for a far wider range of applications and users.
ChatGenBench: A Benchmark#
The proposed ChatGenBench benchmark plays a crucial role in evaluating automatic text-to-image (T2I) generation models. Its novelty lies in focusing on the entire T2I pipeline, not just individual components like prompt generation or model selection. This holistic approach is vital because the quality of the final image depends on the synergistic interplay of all steps. The benchmark includes a diverse range of freestyle chatting inputs, reflecting real-world user interactions. This contrasts with existing benchmarks that often rely on more structured prompts, limiting their practical applicability. The inclusion of step-wise evaluations allows for precise identification of bottlenecks in the different stages of the T2I process, such as prompt refinement, model selection, and argument configuration. ChatGenBench’s design facilitates a comprehensive understanding of model strengths and weaknesses at each stage, which is invaluable for developing effective automated T2I systems. By providing high-quality paired data with diverse inputs, ChatGenBench sets a new standard for evaluating automated T2I methods, promoting the development of more robust and user-friendly systems. The comprehensive evaluation framework enables researchers to critically assess the effectiveness of different approaches in managing the complexity of the automated T2I process.
ChatGen-Evo: Multi-Stage#
The proposed ChatGen-Evo model employs a multi-stage evolution strategy for automatic text-to-image (T2I) generation, addressing the limitations of directly predicting all components (prompt, model, and arguments). Each stage focuses on a specific subtask, enabling targeted feedback and progressive skill acquisition. The first stage utilizes supervised fine-tuning (SFT) to train the model to generate high-quality prompts from freestyle inputs. Crucially, this stage emphasizes rewriting prompts to maximize effective communication with downstream components. The second stage introduces ModelTokens, a novel approach for model selection, effectively embedding model representations within the MLLM’s vocabulary, and enabling efficient and accurate model selection. This avoids the drawbacks of previous methods, including performance bottlenecks, and maintains prompt generation quality. Finally, the third stage leverages the model’s in-context learning capability to configure optimal arguments, guided by the previously determined prompt and model, eliminating the need for additional training data at this step. This multi-stage approach is key to ChatGen-Evo’s success, as it allows for focused training and avoids the complexities of tackling the entire task at once, demonstrating significant improvements over existing methods.
Ablation Studies: Key Insights#
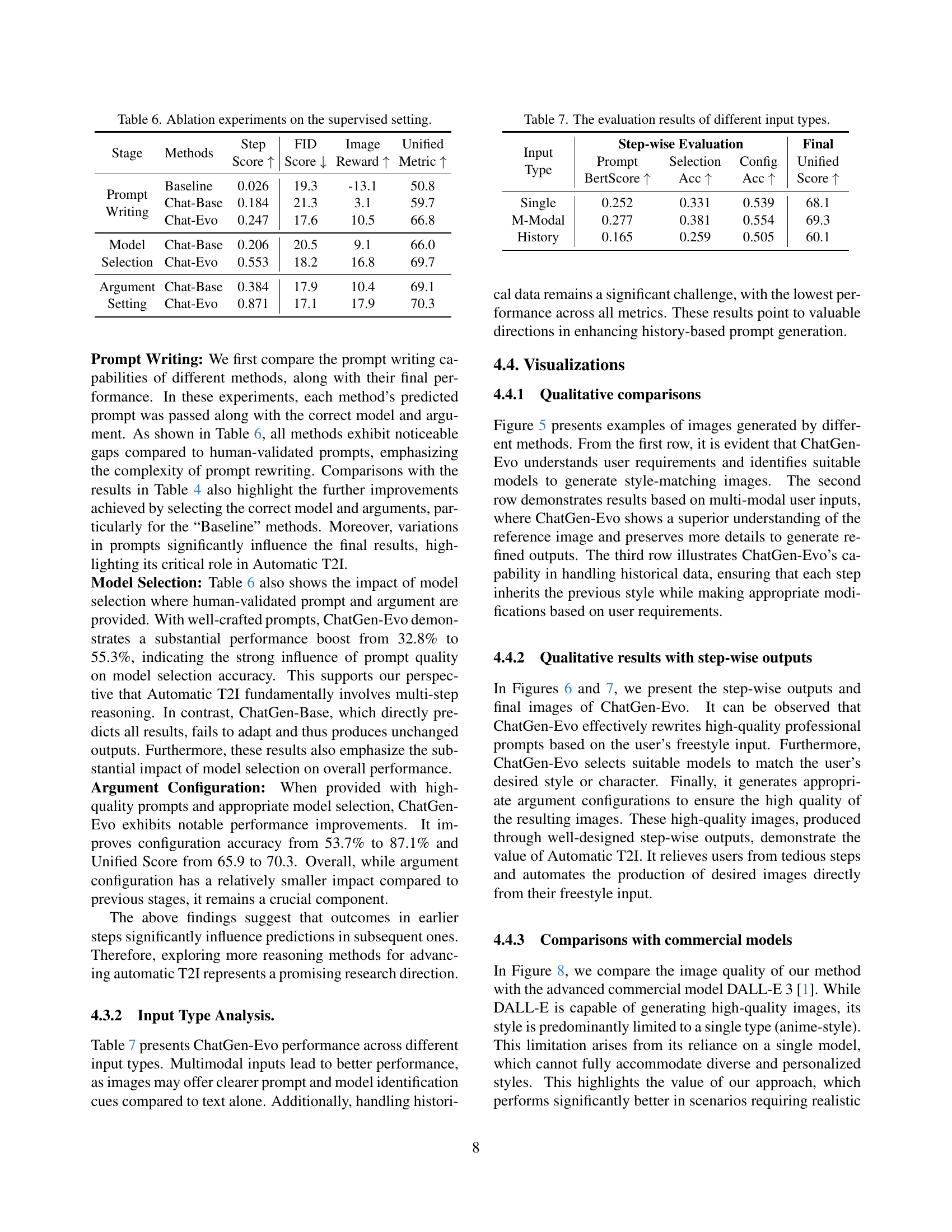
Ablation studies in the context of automatic text-to-image (T2I) generation offer critical insights into the individual contributions of different model components. By systematically removing or modifying specific stages within the multi-stage pipeline (e.g., prompt generation, model selection, argument configuration), researchers can isolate the impact of each step on the overall performance. Key insights often reveal the crucial role of high-quality prompt engineering, demonstrating that improvements in prompt quality significantly enhance downstream tasks like model selection and argument configuration. Further, ablation studies may highlight the importance of model selection techniques, showing how carefully selecting an appropriate model based on prompt characteristics boosts image quality. Finally, analysis of argument configuration reveals its importance but also points out its comparative lesser impact compared to prompt and model selection, suggesting avenues for improving efficiency without sacrificing significant performance gains. In essence, ablation studies provide a granular understanding of the strengths and weaknesses of each stage in the T2I process, guiding future research towards enhancing specific components for improved overall system performance and efficiency.
Future of Auto-T2I#
The future of Automated Text-to-Image (Auto-T2I) generation hinges on several key advancements. Improved multi-modal reasoning is crucial; current models struggle with complex, multi-step tasks. Further research into prompt engineering techniques, potentially leveraging advanced LLMs for nuanced understanding of user intent and context, is needed. Exploring different model selection strategies beyond simple token-based methods is important to adapt to diverse image generation tasks and user preferences. Benchmarking remains a significant challenge; developing more comprehensive, real-world representative datasets is needed to rigorously evaluate performance. Addressing scalability issues and resource constraints associated with large-scale model training is vital. Finally, integration with other AI systems offers exciting possibilities; imagine Auto-T2I seamlessly collaborating with video generation tools or 3D modeling software for richer content creation. Focus should be given on developing robust and efficient approaches to ensure the wider accessibility of Auto-T2I to both experts and casual users.
More visual insights#
More on figures

🔼 This figure illustrates the multi-step process of collecting data for the ChatGenBench benchmark. It begins with collecting high-quality image generation demonstrations from the Civitai community, filtering them for quality and relevance, and removing duplicates or NSFW content. Then, an LLM-driven role-play method is used to simulate diverse freestyle chatting inputs based on the demonstrations. The role-play involves prompting LLMs with different personas (e.g., doctor, student, etc.) to rephrase the high-quality prompts into more casual and conversational chatting inputs. The resulting data includes multiple input types, such as single-turn, multi-turn, multimodal (image + text), and historical. Finally, these data are paired with the original prompt, model, and arguments to form the final step-by-step dataset for evaluation.
read the caption
Figure 2: Illustration of the data collection pipeline.

🔼 This figure illustrates the architectures of two models: ChatGen-Base and ChatGen-Evo. ChatGen-Base uses a single-stage supervised fine-tuning (SFT) approach, directly mapping freestyle inputs to the final outputs (prompt, model, and argument). In contrast, ChatGen-Evo employs a three-stage evolution strategy. Stage 1 uses SFT to train the model for prompt generation from freestyle input. Stage 2 introduces ModelTokens for efficient model selection, and Stage 3 leverages in-context learning for argument configuration. The figure visually depicts the distinct steps and information flow in each model, highlighting the multi-stage nature of ChatGen-Evo.
read the caption
Figure 3: Illustration of the framework for ChatGen-Base and ChatGen-Evo.

🔼 This figure presents the results of a user study comparing the performance of ChatGen-Base and ChatGen-Evo. The study involved pairwise comparisons, where users were shown two images generated from the same input: one by ChatGen-Base and one by ChatGen-Evo. Users were asked to choose the image that better matched the image quality and relevance to the given input. The graph displays the win rates of each model in both supervised and few-shot settings, indicating which model was selected more frequently as superior in terms of quality and relevance to the input.
read the caption
Figure 4: User study results of ChatGen-Base and ChatGen-Evo.

🔼 Figure 5 showcases example images generated using three different methods: ChatGen-Evo, ChatGen-Base, and a default Stable Diffusion model. The figure is divided into three rows, each illustrating image generation results from different input modalities. The first row demonstrates single-input generation (text-only prompt), the second row shows multi-modal input generation (text and image prompt), and the third row presents results from historical input (multiple turns in a chat-like conversation), highlighting the models’ capabilities in handling various input types and complexities.
read the caption
Figure 5: Examples of images generated by different methods. Three rows represent single, multi-modal and historical inputs, respectively.

🔼 This figure showcases five examples of single freestyle text inputs processed by the ChatGen-Evo model. For each input, the figure displays the automatically generated prompt, selected model, and configured arguments, along with the resulting image. This step-by-step breakdown visually demonstrates the model’s ability to automate the entire text-to-image generation process, from understanding freestyle user requests to producing the final output image.
read the caption
Figure 6: Examples of single inputs with step-wise outputs.

🔼 This figure showcases examples of multimodal inputs processed by the ChatGen-Evo model. Each example demonstrates the model’s ability to generate images based on a combination of text and a reference image (shown in the top right corner of each example). The step-wise outputs (prompt, model, and arguments) generated by the model for each example are also displayed, illustrating the model’s multi-stage reasoning process in generating the final image. The multimodal inputs include various scenarios: matching image details, replicating styles from provided images, and combining different styles. These examples highlight the model’s capability of handling diverse and complex inputs to produce high-quality, contextually relevant outputs.
read the caption
Figure 7: Examples of multimodal inputs with step-wise outputs. The image in the top-right corner represents the input reference image.

🔼 This figure displays a comparison of images generated by ChatGen-Evo and DALL-E 3, showcasing the performance of both models across various input types. The first row shows results from single-text inputs where users describe their desired image using natural language. The second row demonstrates results from multi-modal inputs, where users provide both a text description and a reference image to guide the generation process. Finally, the third row illustrates the capabilities of both models when provided with historical dialogue inputs, where the user and the model engage in a conversational exchange to refine the image generation request over multiple rounds. This figure highlights the ability of ChatGen-Evo to handle diverse input formats and generate high-quality images that match user intent.
read the caption
Figure 8: Examples of images generated by ChatGen-Evo and DALL-E 3. Three rows represent single, multi-modal and historical inputs, respectively.
More on tables
| MLLM | Numbers |
|---|---|
| gpt-4o-2024-08-06 | ≈100,000 |
| gpt-4o-mini-2024-07-18 | ≈70,000 |
| gpt-4-turbo-2024-04-09 | ≈70,000 |
| claude-3-5-sonnet-20240620 | ≈100,000 |
🔼 This table details the large language models (LLMs) used in the ChatGen system for generating chatting queries. The left column lists the specific LLMs employed, while the right column provides an estimate of the number of chatting queries generated using each respective LLM. This information is crucial for understanding the scale and diversity of the training data used in the study.
read the caption
Table 2: Overview of MLLMs utilized in chatting generation. The table lists different MLLMs on the left, with corresponding approximate numbers of generated chatting queries on the right.
| Dataset | Total | Single | M-Modal | History |
|---|---|---|---|---|
| TrainSet | 256,606 | 147,888 | 69,548 | 39,170 |
| TestSet Init | 74,364 | 42,838 | 20,214 | 11,312 |
| Benchmark | 14,564 | 11,011 | 1,668 | 1,132 |
| Supervised | 10,240 | 8,009 | 1,099 | 1,132 |
| Few-Shot | 4,324 | 3,002 | 569 | 753 |
🔼 This table presents a summary of the statistics for the ChatGenBench dataset, broken down by input type (single, multi-modal, and history). It shows the total number of samples in the training and test sets, as well as the distribution across the different input types. This allows for a clear understanding of the dataset’s size and composition, highlighting the balance (or imbalance) of different data types included.
read the caption
Table 3: Summary of dataset statistics.
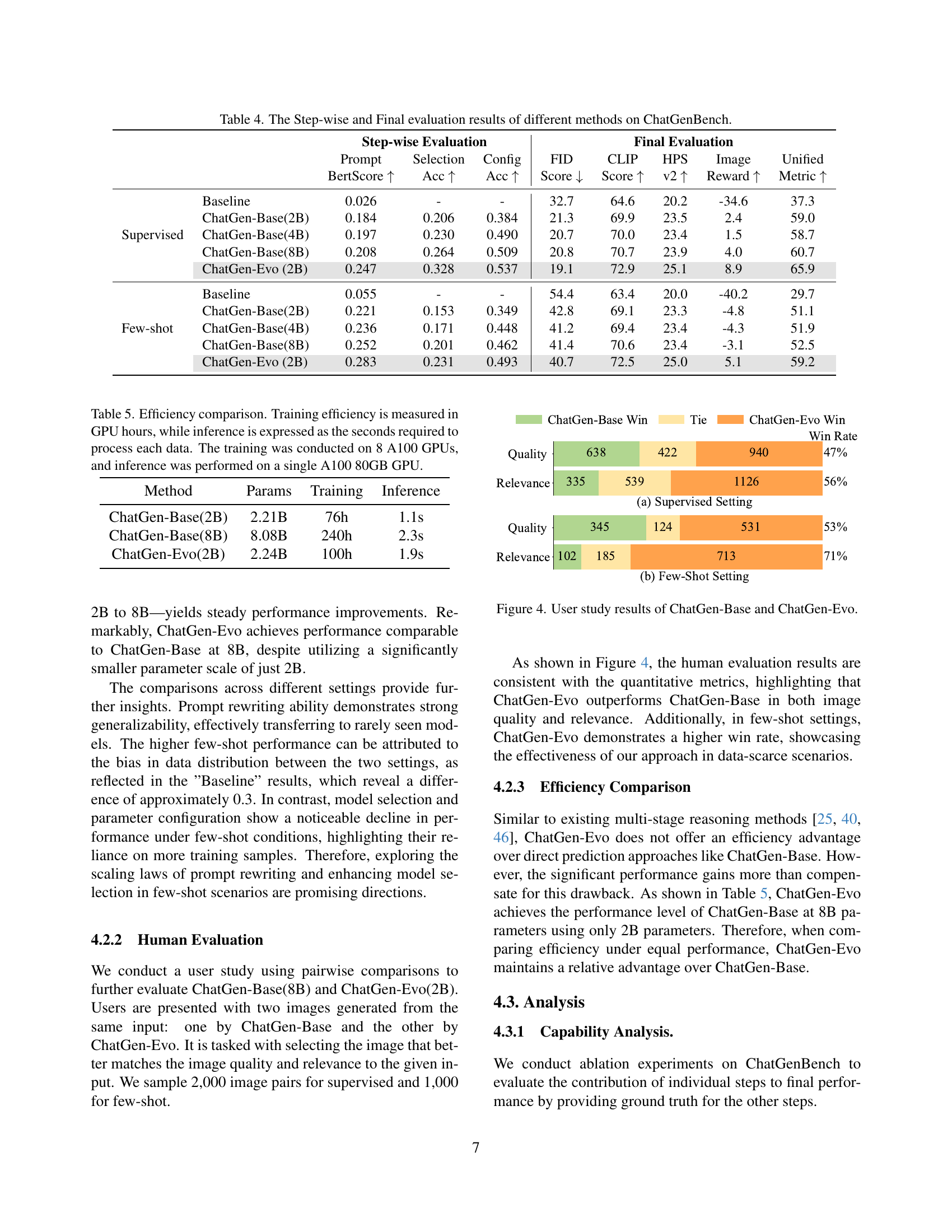
| Setting | Model | Prompt (BertScore ↑) | Selection (Acc ↑) | Config (Acc ↑) | FID (Score ↓) | CLIP (Score ↑) | HPS (v2 ↑) | Image (Reward ↑) | Unified (Metric ↑) |
|---|---|---|---|---|---|---|---|---|---|
| Supervised | Baseline | 0.026 | - | - | 32.7 | 64.6 | 20.2 | -34.6 | 37.3 |
| ChatGen-Base(2B) | 0.184 | 0.206 | 0.384 | 21.3 | 69.9 | 23.5 | 2.4 | 59.0 | |
| ChatGen-Base(4B) | 0.197 | 0.230 | 0.490 | 20.7 | 70.0 | 23.4 | 1.5 | 58.7 | |
| ChatGen-Base(8B) | 0.208 | 0.264 | 0.509 | 20.8 | 70.7 | 23.9 | 4.0 | 60.7 | |
| ChatGen-Evo (2B) | 0.247 | 0.328 | 0.537 | 19.1 | 72.9 | 25.1 | 8.9 | 65.9 | |
| Few-shot | Baseline | 0.055 | - | - | 54.4 | 63.4 | 20.0 | -40.2 | 29.7 |
| ChatGen-Base(2B) | 0.221 | 0.153 | 0.349 | 42.8 | 69.1 | 23.3 | -4.8 | 51.1 | |
| ChatGen-Base(4B) | 0.236 | 0.171 | 0.448 | 41.2 | 69.4 | 23.4 | -4.3 | 51.9 | |
| ChatGen-Base(8B) | 0.252 | 0.201 | 0.462 | 41.4 | 70.6 | 23.4 | -3.1 | 52.5 | |
| ChatGen-Evo (2B) | 0.283 | 0.231 | 0.493 | 40.7 | 72.5 | 25.0 | 5.1 | 59.2 |
🔼 This table presents a comprehensive evaluation of different methods for automatic text-to-image generation, using the ChatGenBench benchmark. It shows the step-wise performance across three key stages: prompt generation (using BERTScore and accuracy), model selection (accuracy), and argument configuration (accuracy). Additionally, it provides an overall evaluation of the final image quality, combining results from FID, CLIP score, HPS v2, and ImageReward into a single Unified Metric. The results are compared across various baselines and model sizes (2B, 4B, and 8B parameters), offering insight into each method’s strengths and weaknesses in each phase of the process.
read the caption
Table 4: The Step-wise and Final evaluation results of different methods on ChatGenBench.
| Prompt | BertScore ↑ |
|---|
🔼 This table compares the training and inference efficiency of different models. Training efficiency is measured in GPU hours, reflecting the computational resources required for training. Inference efficiency is measured in seconds, representing the time taken to process a single data point. The training was performed using 8 A100 GPUs, while inference utilized a single A100 80GB GPU. The table highlights the trade-off between model size (parameters), training time, and inference speed, demonstrating the practical implications of model complexity.
read the caption
Table 5: Efficiency comparison. Training efficiency is measured in GPU hours, while inference is expressed as the seconds required to process each data. The training was conducted on 8 A100 GPUs, and inference was performed on a single A100 80GB GPU.
| Selection | Acc ↑ |
|---|
🔼 This table presents the results of ablation experiments conducted on the supervised subset of the ChatGenBench dataset. It analyzes the individual contributions of each stage in the ChatGen-Evo model—prompt writing, model selection, and argument configuration—to the overall performance. By systematically removing or replacing components of the model, the table quantifies the impact of each stage on key metrics such as FID score, ImageReward, and the Unified Metric. This allows for a precise understanding of the effectiveness and importance of the multi-stage evolution strategy implemented in ChatGen-Evo.
read the caption
Table 6: Ablation experiments on the supervised setting.
| Config | Acc ↑ |
|---|
🔼 This table presents a quantitative analysis of the ChatGen-Evo model’s performance across various input types: single, multimodal, and historical. The results show the model’s ability to generate images given different kinds of input data, highlighting any strengths and weaknesses in handling varied input complexities. The metrics evaluated are step-wise accuracy for prompt generation, model selection, and argument configuration, and the final image quality as assessed by a Unified Metric that combines multiple quality assessment scores.
read the caption
Table 7: The evaluation results of different input types.
Full paper#