↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Subject-driven image inpainting, a popular image editing task, faces challenges in maintaining editability while preserving object identity. Existing methods often struggle to balance precise local object modifications with global visual harmony, often relying on extensive training data or overly specific visual features. This limits their adaptability and efficiency.
DreamMix overcomes these challenges by introducing a novel disentangled inpainting framework, separating local object insertion from global context harmonization. It also leverages an Attribute Decoupling Mechanism to generate diverse training data and a Textual Attribute Substitution module for finer control over attributes during editing. This results in improved performance across various tasks, including identity preservation and text-driven attribute changes, demonstrating the efficacy of the proposed approach.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to subject-driven image inpainting, addressing limitations of existing methods. DreamMix offers enhanced editability by decoupling object attributes, leading to more precise and versatile image manipulation. This is highly relevant to current research trends in image generation and editing, opening avenues for improved personalized image customization and creative content generation.
Visual Insights#

🔼 Figure 1 showcases DreamMix’s capabilities in subject-driven image customization across three scenarios. (a) Identity Preservation: DreamMix seamlessly integrates a target object into diverse backgrounds, maintaining object fidelity and visual harmony. (b) Attribute Editing: Users can manipulate object attributes (color, texture, shape) or add accessories through textual commands. (c) Small Object Inpainting: DreamMix effectively handles insertions and edits of small objects, preserving fine details and overall visual coherence.
read the caption
Figure 1: DreamMix on various subject-driven image customization tasks. (a) Identity Preservation: DreamMix precisely inserts a target object into any scene, achieving high-fidelity and harmonized composting results. (b) Attribute Editing: DreamMix allows users to modify object attributes such as color, texture, and shape or add accessories based on textual instructions. (c) Small Object Inpainting: DreamMix effectively performs small object insertion and editing while preserving fine-grained details and visual harmony.
| Method | CLIP-T↑ | CLIP-I↑ | DINO↑ | FID↓ | CLIP-T↑ | CLIP-I↑ | DINO↑ | FID↓ | |
|---|---|---|---|---|---|---|---|---|---|
| Large-scale Training | Paint-by-Example [39] | 0.238 | 0.541 | 0.582 | 44.6 | - | - | - | - |
| MimicBrush [5] | 0.256 | 0.614 | 0.631 | 47.0 | - | - | - | - | |
| AnyDoor [6] | 0.284 | 0.688 | 0.711 | 53.7 | - | - | - | - | |
| IP-Adapter [40] | 0.268 | 0.633 | 0.633 | 45.3 | 0.236 | 0.611 | 0.629 | 47.5 | |
| LAR-Gen [26] | 0.269 | 0.662 | 0.676 | 48.7 | 0.257 | 0.656 | 0.668 | 49.6 | |
| Tuning-free | TIGIC [18] | 0.262 | 0.533 | 0.584 | 45.2 | 0.236 | 0.479 | 0.548 | 47.3 |
| Few-shot Fine-tuning | DreamBooth† | 0.248 | 0.609 | 0.604 | 40.8 | 0.235 | 0.567 | 0.595 | 42.0 |
| DreamBooth [33] | 0.253 | 0.644 | 0.628 | 40.5 | 0.235 | 0.601 | 0.612 | 41.7 | |
| DreamMix† | 0.284 | 0.713 | 0.685 | 43.4 | 0.284 | 0.659 | 0.672 | 44.2 | |
| DreamMix | 0.285 | 0.728 | 0.712 | 42.9 | 0.289 | 0.674 | 0.695 | 43.9 | |
| Real Image | 0.315 | 0.883 | 0.865 | 35.9 | - | - | - | - |
🔼 Table 1 presents a quantitative comparison of various image inpainting methods across two key aspects: identity preservation and attribute editing. The methods are categorized into three groups based on their training approach: large-scale training, tuning-free methods, and few-shot fine-tuning methods. The table uses several metrics to evaluate performance in both tasks, including CLIP-T (text similarity), CLIP-I (image similarity), DINO (a visual similarity metric), and FID (Fréchet Inception Distance, measuring the visual quality of generated images). A dash (-) indicates methods that lack text-driven editing capabilities. The double dagger symbol (††) highlights methods that used only one image per subject during model fine-tuning, suggesting a potentially limited capacity for generalization.
read the caption
Table 1: Quantitative comparison of different methods on Identity Preservation and Attribute Editing. The “-” symbol indicates that the method don’t support text-driven editing. We divide the compared methods into three types based on their training protocol: large-scale training, tuning-free, and few-shot finetuning. “††\dagger†” indicates that only one image is used in model finetuning for each subject.
In-depth insights#
Attribute Decoupling#
Attribute decoupling, as presented in the context of the research paper, is a crucial technique for enhancing the editability of subject-driven image inpainting. The core idea revolves around separating individual object attributes (like color, shape, texture) during the model’s training phase. This prevents the model from overfitting to a single, combined representation of these attributes, thus improving the controllability in editing. By disentangling these attributes, the model can generate images with diverse combinations of attributes, responding more effectively to text-based editing instructions. This decoupling is achieved using a Vision-Language Model (VLM) which generates detailed textual descriptions incorporating specific attribute words. These descriptions are then used to create a diverse training dataset with varied attribute combinations, leading to improved attribute editability and higher-quality results. The decoupling mechanism avoids overfitting, which is a common problem in few-shot learning techniques used for this application. The outcome is enhanced flexibility, enabling more precise and nuanced alterations to images after the model is trained.
Inpainting Framework#
The core of DreamMix lies in its novel disentangled inpainting framework. This framework intelligently separates the inpainting process into two key stages: local content generation (LCG) and global context harmonization (GCH). LCG prioritizes precise local object insertion by focusing on the target object’s immediate surroundings, ensuring high fidelity. GCH then seamlessly integrates the locally generated content into the global scene, resolving potential inconsistencies and preserving overall visual coherence. This two-stage approach addresses limitations of existing methods that struggle with balancing local precision and global harmony. The framework’s effectiveness is further enhanced by the inclusion of an attribute decoupling mechanism which tackles overfitting issues during training, and a textual attribute substitution module which improves the flexibility and accuracy of attribute editing during inference. This sophisticated framework is crucial to DreamMix’s ability to achieve both high-fidelity object insertion and fine-grained attribute control.
Textual Attribute Sub#
The concept of “Textual Attribute Substitution” (TAS) in the context of image inpainting addresses a crucial challenge: how to enable fine-grained control over object attributes without sacrificing identity preservation. The core problem is that simply adding descriptive text alongside an image often leads to overfitting or a mixing of attributes. TAS tackles this through orthogonal decomposition of text embeddings, effectively disentangling the object’s identity from its attributes. This allows for precise attribute editing driven by text prompts, where changes to the description (color, shape, material, etc.) are isolated and applied without unintended effects on the object’s inherent features. The effectiveness of this technique depends significantly on the quality of the underlying Vision-Language Model (VLM) used to generate the attribute dictionary and the decomposition process itself. A strong VLM is crucial for accurately parsing and separating the textual attributes, ensuring the success of TAS in producing edits that are both precise and harmonious with the overall image composition. The ultimate goal is to achieve enhanced editability and flexibility in subject-driven image inpainting by empowering users to make nuanced and precise modifications through text instructions.
Ablation Experiments#
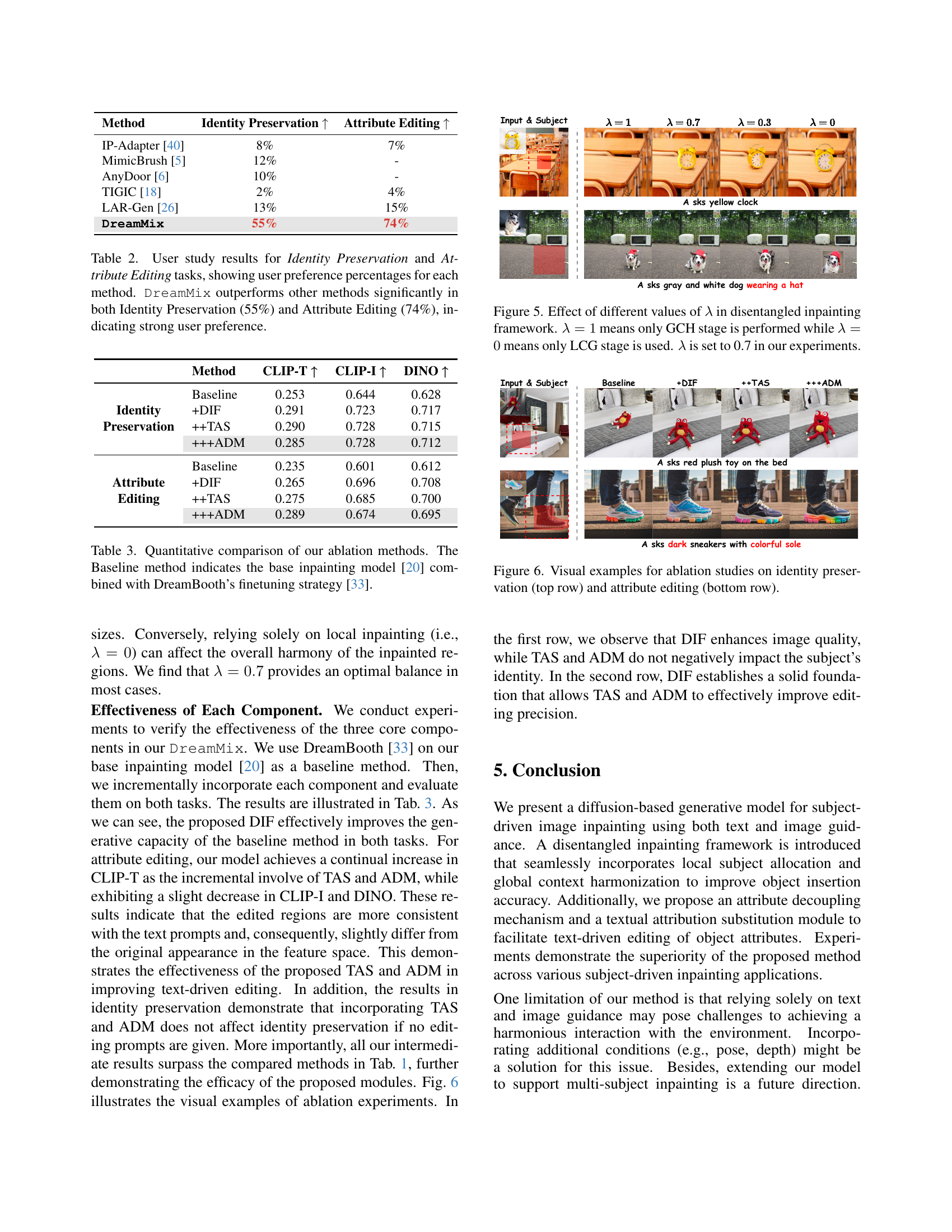
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, an ‘Ablation Experiments’ section would meticulously detail these experiments. Each experiment would isolate a specific component – perhaps a module, a hyperparameter setting, or a data processing step – and measure the resulting impact on the model’s overall performance. Key metrics would be reported, such as accuracy, precision, recall, and F1-score. The results should clearly demonstrate the value added by each component, showcasing its individual impact and justifying its inclusion. Well-designed ablation experiments provide strong evidence for design choices and highlight areas of potential improvement, strengthening the validity and persuasiveness of the research findings. A thorough analysis of results in the ‘Ablation Experiments’ section would provide valuable insight into the model’s functionality, identifying both strengths and weaknesses. Finally, the results should be clearly presented, ideally with both quantitative measurements and qualitative explanations. A well-written ‘Ablation Experiments’ section is crucial for demonstrating a clear understanding of the model’s behavior and its underlying mechanisms.
Future Directions#
The research paper, focusing on subject-driven image inpainting, paves the way for several exciting future directions. Extending the model to handle multiple subjects simultaneously would significantly increase its practical value, enabling more complex scene manipulations. Currently, the model excels in single-subject scenarios, but real-world images often contain numerous objects. Addressing this limitation would require sophisticated methods for disentangling and harmoniously integrating multiple subjects’ attributes while maintaining visual coherence. Another critical area is improving the model’s robustness to ambiguous or incomplete prompts. While the current model handles text-based attribute instructions effectively, further research is needed to improve its understanding of complex or nuanced user requests, particularly those involving abstract or subjective attributes. Finally, exploring alternative methods for attribute decoupling and substitution could lead to more efficient and flexible editing capabilities. The current approach relies on vision-language models, which could be computationally expensive and potentially limited in their ability to capture all subtle attribute nuances. Investigating alternate techniques would enhance the model’s precision and speed, potentially leading to more real-time image editing applications.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architecture and workflow of DreamMix, a subject-driven image inpainting model. During training, DreamMix uses two types of data: source data ({xs, ps}), which includes subject images (xs) and their corresponding text descriptions (ps); and regular data ({xr, pr}), which is generated using an attribute decoupling mechanism to enhance model generalization. This combination of data allows the pre-trained Text-to-Image (T2I) inpainting model to efficiently adapt for subject generation. At the inference stage, DreamMix leverages a disentangled framework to split the inpainting process into two stages: Local Content Generation (LCG) that focuses on precise object insertion and Global Context Harmonization (GCH) responsible for visual coherence of the output. A textual attribute substitution module enhances the accuracy of attribute editing by generating a decomposed text embedding for the model’s input.
read the caption
Figure 2: Overview of DreamMix. During finetuning, we use the source data {𝒙s,𝒑s}subscript𝒙𝑠subscript𝒑𝑠\{\boldsymbol{x}_{s},\boldsymbol{p}_{s}\}{ bold_italic_x start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT , bold_italic_p start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT } along with regular data {𝒙r,𝒑r}subscript𝒙𝑟subscript𝒑𝑟\{\boldsymbol{x}_{r},\boldsymbol{p}_{r}\}{ bold_italic_x start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT , bold_italic_p start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT } constructed via an attribute decoupling mechanism (Sec. 3.3), to enable pretrained Text-to-Image (T2I) inpainting models to efficiently adapt to subject generation. At testing, we employ a disentangled inpainting framework (Sec. 3.2), which divides the denoising process into two stages: Local Content Generation (LCG) and Global Context Harmonization (GCH). Additionally, we propose a textual attribute substitution module (Sec. 3.4) to generate a decomposed text embedding to enhance the editability of our method during testing.

🔼 Figure 3 details the Attribute Decoupling Mechanism (ADM), a key part of the DreamMix model. ADM addresses the challenge of overfitting in subject-driven image inpainting by augmenting the training data. The process begins with feeding subject images into a Vision-Language Model (VLM). The VLM analyzes the images and generates a list of attribute words (e.g., color, shape, material) describing the subject. These attributes are then combined with the original subject descriptions to create more diverse text prompts. Finally, new images are generated using these prompts, resulting in ‘regular data’ that is used to augment the original subject data and prevent overfitting during model training. This expanded and diversified dataset helps DreamMix achieve better generalization and enhanced editability.
read the caption
Figure 3: Pipeline of Attribute Decoupling Mechanism (ADM). We obtain the attribute word list using a VLM agent [24] and create regular data with more diverse text formats and image contents.

🔼 Figure 4 presents a visual comparison of various image inpainting methods applied to four diverse examples. Each row showcases a different image inpainting task, beginning with the input image and its corresponding subject on the far left. The subsequent columns display the results generated by six different techniques: DreamMix (the authors’ method), IP-Adapter, DreamBooth, TIGIC, AnyDoor, and LAR-Gen. This visual comparison allows for a direct qualitative assessment of each method’s performance in terms of both identity preservation and attribute editing capabilities, highlighting the relative strengths and weaknesses of each approach in handling diverse subject-driven image inpainting challenges.
read the caption
Figure 4: Visual comparison between different methods. From left to right are input image and subject, visual results of our DreamMix, IP-Adapter [40], DreamBooth [33], TIGIC [18], AnyDoor [6], and LAR-Gen [26].

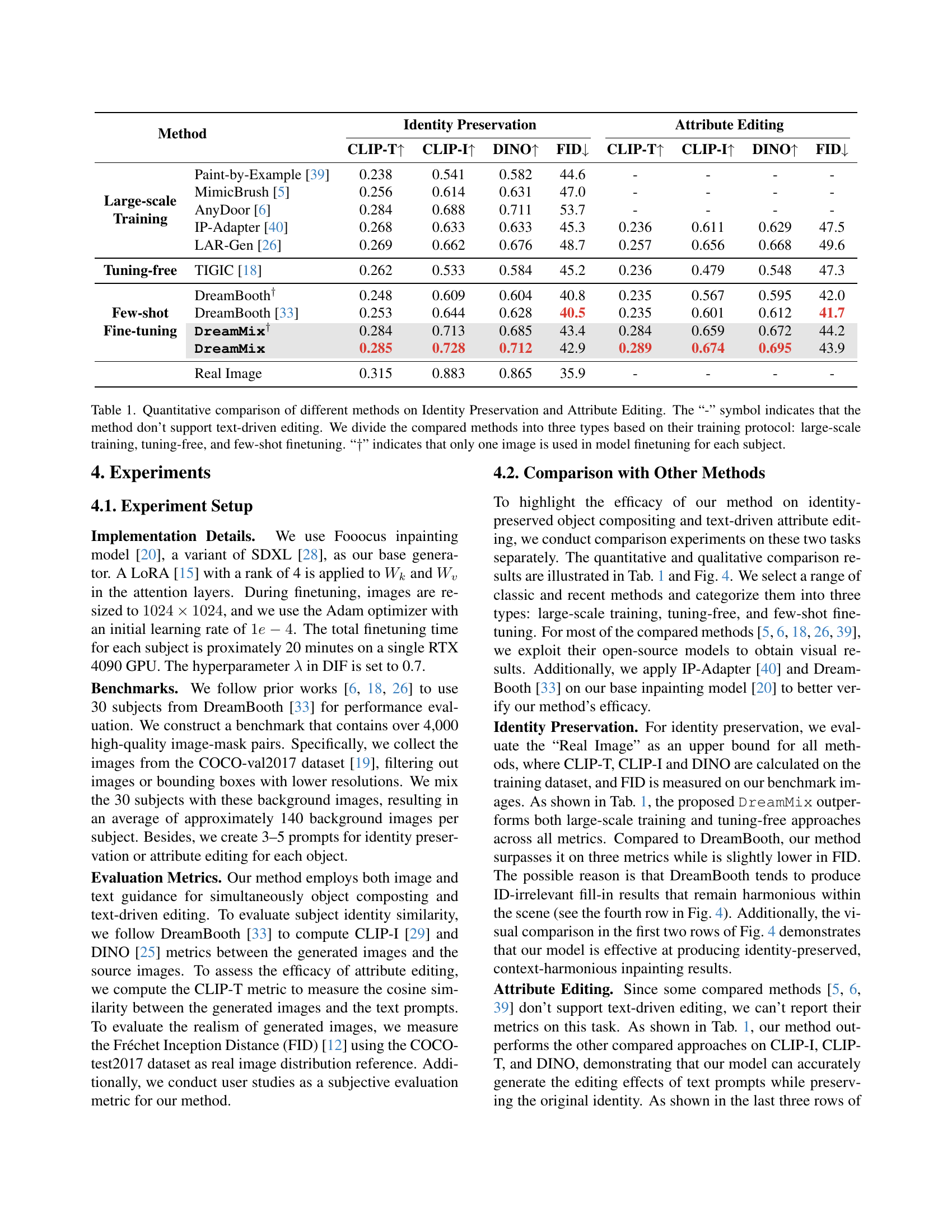
🔼 This figure demonstrates the impact of the lambda (λ) hyperparameter on the disentangled inpainting framework. The framework consists of two stages: Local Content Generation (LCG) and Global Context Harmonization (GCH). Lambda controls the balance between these two stages. λ = 1 means only the GCH stage is active, while λ = 0 means only the LCG stage is used. The experiments in the paper used λ = 0.7. The figure visually shows the results of varying λ, illustrating how the balance affects the quality and harmony of the inpainted image.
read the caption
Figure 5: Effect of different values of λ𝜆\lambdaitalic_λ in disentangled inpainting framework. λ=1𝜆1\lambda=1italic_λ = 1 means only GCH stage is performed while λ=0𝜆0\lambda=0italic_λ = 0 means only LCG stage is used. λ𝜆\lambdaitalic_λ is set to 0.7 in our experiments.
More on tables
| Method | Identity Preservation ↑ | Attribute Editing ↑ |
|---|---|---|
| IP-Adapter [40] | 8% | 7% |
| MimicBrush [5] | 12% | - |
| AnyDoor [6] | 10% | - |
| TIGIC [18] | 2% | 4% |
| LAR-Gen [26] | 13% | 15% |
| DreamMix | 55% | 74% |
🔼 This table presents the results of a user study comparing different methods for image inpainting, focusing on two key aspects: identity preservation (how well the method maintains the original object’s identity) and attribute editing (how well the method allows modifications of the object’s attributes). The study involved 100 participants, each evaluating 30 different image editing results across both tasks. The percentage of participants who preferred each method for each task is shown. DreamMix significantly outperforms all other compared methods in both identity preservation (55% preference) and attribute editing (74% preference), demonstrating its superior performance according to user perception.
read the caption
Table 2: User study results for Identity Preservation and Attribute Editing tasks, showing user preference percentages for each method. DreamMix outperforms other methods significantly in both Identity Preservation (55%) and Attribute Editing (74%), indicating strong user preference.
| Method | CLIP-T ↑ | CLIP-I ↑ | DINO ↑ |
|---|---|---|---|
| Identity Preservation | Baseline | 0.253 | 0.644 |
| +DIF | 0.291 | 0.723 | 0.717 |
| ++TAS | 0.290 | 0.728 | 0.715 |
| +++ADM | 0.285 | 0.728 | 0.712 |
| Attribute Editing | Baseline | 0.235 | 0.601 |
| +DIF | 0.265 | 0.696 | 0.708 |
| ++TAS | 0.275 | 0.685 | 0.700 |
| +++ADM | 0.289 | 0.674 | 0.695 |
🔼 This table presents a quantitative comparison of different model variations, assessing their performance on identity preservation and attribute editing tasks. The baseline model used for comparison is the Fooocus inpainting model [20] fine-tuned with DreamBooth’s [33] strategy. The table shows the impact of adding three key components of the proposed DreamMix model: the disentangled inpainting framework (DIF), textual attribute substitution (TAS), and attribute decoupling mechanism (ADM). Results are measured using CLIP-T, CLIP-I, and DINO metrics.
read the caption
Table 3: Quantitative comparison of our ablation methods. The Baseline method indicates the base inpainting model [20] combined with DreamBooth’s finetuning strategy [33].
Full paper#