↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current identity-preserving text-to-video (IPT2V) methods often require extensive, time-consuming finetuning for each individual, hindering their scalability and applicability. Additionally, existing models largely rely on U-Net architectures, which may not fully leverage the capabilities of emerging diffusion transformer (DiT) based video models.
This paper introduces ConsisID, a novel tuning-free IPT2V model based on DiT. ConsisID addresses these limitations by using a frequency-aware approach, decomposing facial features into low and high-frequency components. These are then injected into different parts of the DiT to control both the global facial features and fine-grained details, ensuring identity preservation while allowing for versatile video generation.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a significant challenge in video generation: creating videos with consistent human identity without extensive finetuning. Its tuning-free approach and focus on frequency decomposition open new avenues for developing more efficient and scalable identity-preserving video generation models. This is highly relevant to current research trends in generative AI and offers potential for various applications like personalized video content creation and virtual avatars.
Visual Insights#

🔼 ConsisID processes low-frequency facial features (like overall shape and proportions) through a global facial extractor, embedding them in the initial layers of the DiT model. High-frequency details (like fine wrinkles and texture) are handled by a local facial extractor, which injects them directly into the attention blocks of the DiT. This frequency-aware approach maintains identity consistency while enhancing the model’s ability to generate detailed and realistic videos. Furthermore, the ID-preserving Recipe, along with probabilistic application of cross-face, DropToken, and Dropout techniques, facilitates easier training and improved generalization.
read the caption
Figure 2: Overview of the proposed ConsisID. Based on Findings of DiT, low-frequency facial information is embedded into the shallow layers, while high-frequency information is incorporated into the vision tokens within the attention blocks. The ID-preserving Recipe is applied to ease training and improve generalization. The cross face, DropToken and Dropout are executed based on probability.
| FaceSim-Arc ↑ | FaceSim-Cur ↑ | CLIPScore ↑ | FID ↓ | |
|---|---|---|---|---|
| ID-Animator [15] | 0.32 | 0.33 | 24.97 | 117.46 |
| ConsisID | 0.58 | 0.60 | 27.93 | 151.82 |
🔼 Table 1 presents a quantitative comparison of ConsisID against several state-of-the-art methods for identity-preserving text-to-video generation. The table uses four metrics: FaceSim-Arc (higher scores mean better identity preservation based on ArcFace features), FaceSim-Cur (higher scores mean better identity preservation based on CurricularFace features), CLIPScore (higher scores mean better alignment with the text prompt), and FID (Fréchet Inception Distance, lower scores mean better visual quality). ConsisID demonstrates consistently strong performance across all metrics, suggesting its effectiveness in generating high-quality videos with accurate identity preservation and text relevance. The arrows indicate whether higher or lower scores are preferred for each metric.
read the caption
Table 1: Quantitative comparison with state-of-the-art methods. ConsisID achieve well-aligned results across most metrics. '↓↓\downarrow↓' denotes lower is better. '↑↑\uparrow↑' denotes higher is better.
In-depth insights#
Freq-Aware IPT2V#
A hypothetical ‘Freq-Aware IPT2V’ section would delve into the frequency decomposition of visual features for identity-preserving text-to-video generation. It would likely discuss how separating features into low-frequency (global) and high-frequency (local) components allows for better control over identity preservation. Low-frequency features, such as overall facial structure, would be manipulated to ensure consistent identity across frames, while high-frequency features, like fine details and expressions, would be handled to avoid unintended identity changes. The effectiveness of different methods for injecting these frequency-specific features into a diffusion model, such as at the shallow layers or transformer blocks, would also likely be discussed, along with a comparison of their impact on training stability and generation quality. Furthermore, this section may cover how the frequency-based approach addresses limitations of existing methods. It would examine how the technique improves both fine-grained details and global consistency of the identity while minimizing computational complexity. Finally, it could include a quantitative or qualitative evaluation of the proposed approach compared to conventional methods.
DiT Control Scheme#
The DiT control scheme in this identity-preserving text-to-video generation model is a frequency-aware approach, which cleverly addresses the limitations of Diffusion Transformers (DiTs) in handling high-frequency details crucial for preserving identity. The core idea is to decompose facial features into low-frequency global features (e.g., overall shape, proportions) and high-frequency intrinsic features (e.g., fine details like eye and lip textures). This decomposition allows the model to effectively leverage the strengths of the DiT architecture while mitigating its weaknesses. Low-frequency features are integrated into the shallow layers, promoting stable training and convergence. High-frequency features, crucial for identity preservation, are strategically injected into the transformer blocks using a Q-former, which fuses facial recognition features with CLIP features to enhance semantic understanding. This hierarchical training strategy, separating the handling of low and high-frequency features, represents a significant innovation enabling accurate identity preservation with improved generalization.
Hierarchical Training#
Hierarchical training, in the context of identity-preserving text-to-video generation, is a crucial strategy to enhance model performance and generalization. It involves a coarse-to-fine approach, where the model initially learns low-frequency features (global facial structure, proportions) and subsequently focuses on fine-grained details (high-frequency features like eye and lip textures). This multi-stage training process facilitates model convergence by gradually building up complexity and allowing the network to effectively capture different levels of detail. The low-frequency stage ensures that the fundamental identity information is learned effectively before the model attempts to preserve subtle features, thus preventing issues like gradient explosion or failure to converge. The high-frequency stage allows the model to handle the more intricate aspects of facial features, resulting in high-fidelity and realistic videos that are consistent with the input reference image. This approach is particularly important in diffusion models which are sensitive to feature representation and noise handling. By strategically decoupling identity information based on frequency characteristics, hierarchical training optimizes the learning process, resulting in improved identity preservation, enhanced visual quality, and enhanced overall generalization. This is a noteworthy aspect of the approach, especially considering the challenges of training diffusion models for video generation.
Tuning-Free Approach#
A tuning-free approach in the context of identity-preserving text-to-video generation is highly desirable as it removes the need for extensive model finetuning for every new individual. This significantly reduces computational cost and development time. The core idea is to leverage pre-trained models and inject identity information in a way that does not require retraining. This could involve using techniques like injecting latent codes representing identity into the generation process, or employing external modules that extract and integrate identity features without modifying the main model’s weights. Success hinges on the effectiveness of identity feature extraction and integration. A poorly designed method could lead to suboptimal identity preservation or introduce artifacts. Therefore, a robust feature extraction process that is invariant to pose and lighting changes and a seamless method of incorporating these features into the generation pipeline are crucial. The trade-off between tuning-free simplicity and the quality of identity preservation must be carefully evaluated. Ultimately, a successful tuning-free approach demonstrates the power of leveraging pre-trained models effectively, paving the way for more efficient and accessible identity-preserving video generation.
ID-Preserving Limits#
ID-preserving technology, while promising, faces inherent limitations. Achieving perfect identity preservation is likely impossible due to the inherent complexity of human faces and the variability introduced by factors like lighting, pose, and expression. Current methods, often based on diffusion models, rely on injecting identity information into the generation process, but this can lead to artifacts or inconsistencies, particularly when dealing with diverse individuals or unusual poses. Generalization remains a significant challenge: models trained on one set of individuals may struggle to preserve identity accurately when presented with new, unseen faces. The trade-off between identity preservation and other aspects of video quality (e.g., realism, resolution) needs careful consideration. Over-emphasizing identity might lead to a less natural, less expressive or lower resolution output. Finally, ethical considerations are crucial. The potential for misuse in areas like deepfakes necessitates careful development and deployment of such technologies, demanding ongoing research to mitigate these risks. Future work should focus on improving robustness, generalization, and developing methods to assess identity preservation more accurately and comprehensively.
More visual insights#
More on figures

🔼 This figure showcases the capability of the ConsisID model in generating identity-preserving videos. Starting with a single reference image of a person, the model generates short video clips based on text prompts. The generated videos maintain the identity of the person in the reference image, regardless of the actions or environment described in the text prompt. This demonstrates the model’s ability to create realistic, personalized video content while faithfully representing the subject’s appearance.
read the caption
Figure 1: Examples of identity-preserving video generation (IPT2V) by our ConsisID. Given a reference image, our method can generate realistic and personalized human-centered videos while preserving identity. Red indicates that attributes in long instructions.

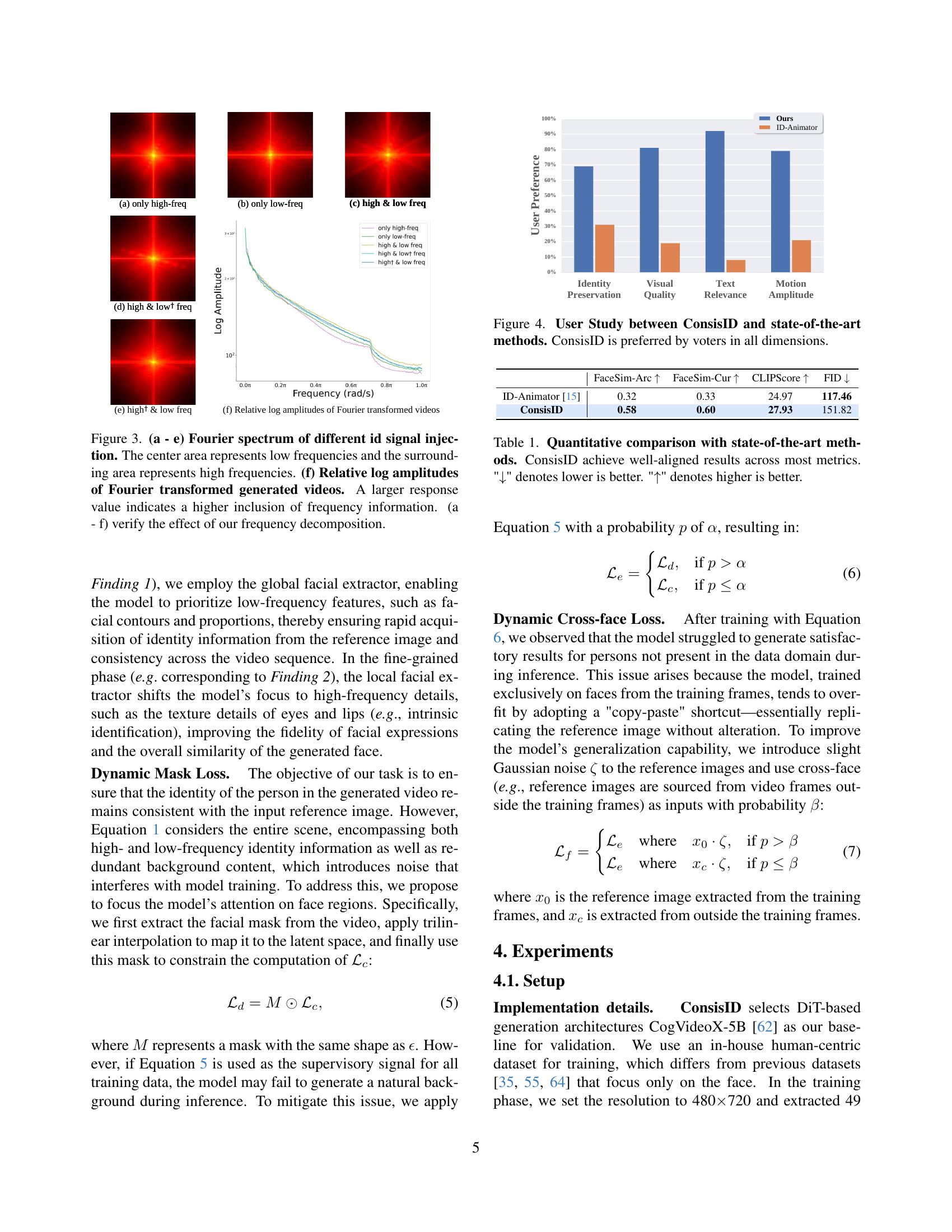
🔼 Figure 3 visualizes the impact of different identity signal injection methods on the frequency spectrum of generated videos. Subfigures (a) through (e) show the Fourier transforms of videos generated using various combinations of high and low-frequency identity signals. The central area of each spectrum corresponds to low frequencies, while the surrounding area represents high frequencies. The intensity of the spectral components indicates the strength of the signal’s contribution at each frequency. This allows for a visual comparison of how different injection techniques affect the frequency content of the generated videos. Subfigure (f) displays the relative log amplitudes of the Fourier transforms of generated videos across the various methods. Higher values suggest a stronger presence of frequency components, directly corresponding to the amount of frequency information incorporated. The figure confirms the effectiveness of the frequency decomposition method by demonstrating its capacity to introduce both high and low-frequency details.
read the caption
Figure 3: (a - e) Fourier spectrum of different id signal injection. The center area represents low frequencies and the surrounding area represents high frequencies. (f) Relative log amplitudes of Fourier transformed generated videos. A larger response value indicates a higher inclusion of frequency information. (a - f) verify the effect of our frequency decomposition.

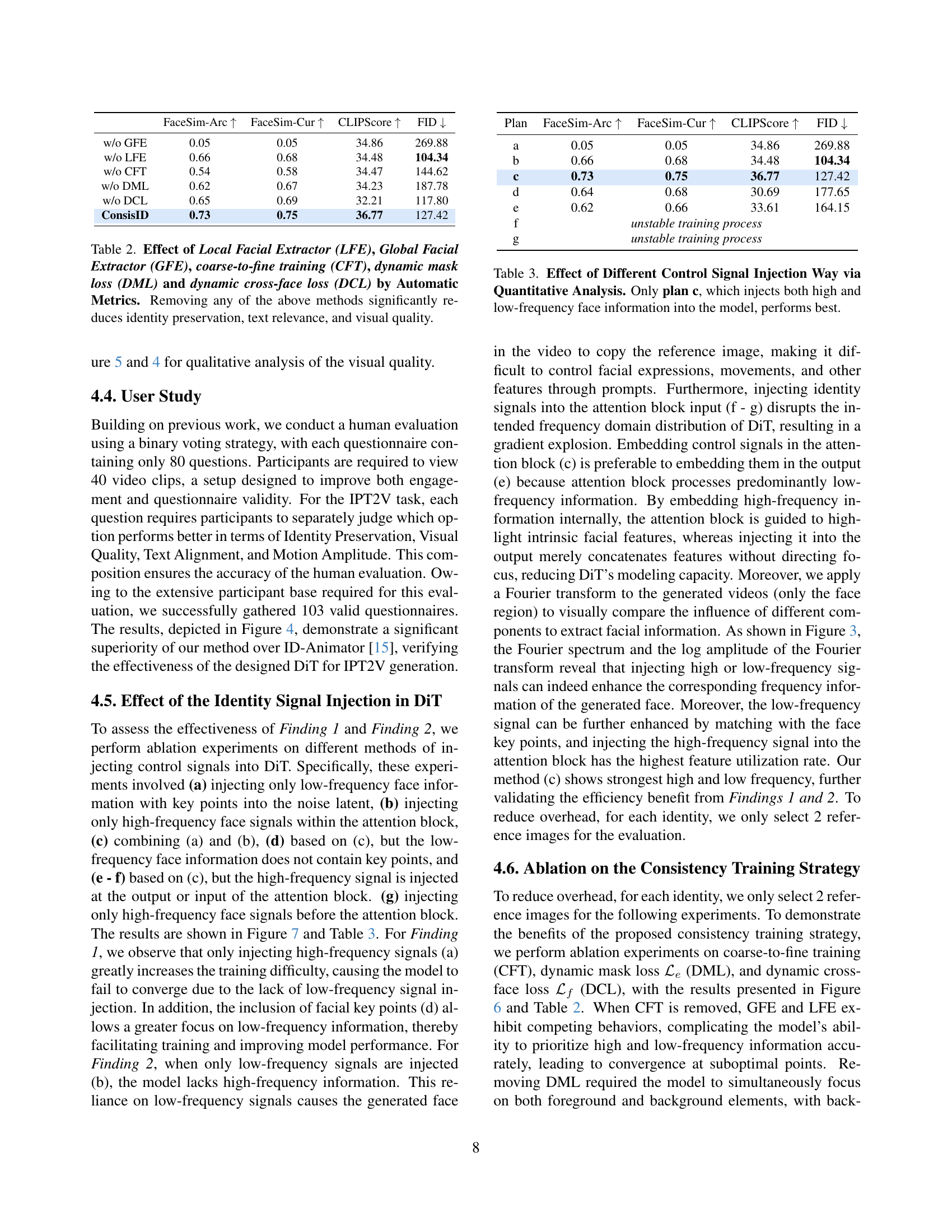
🔼 A user study comparing ConsisID to other state-of-the-art methods for identity-preserving text-to-video generation. The chart displays the percentage of user preference across five dimensions: Identity Preservation, Text Relevance, Visual Quality, Motion Amplitude, and overall user preference. ConsisID demonstrates higher preference in all five aspects when compared to the other methods.
read the caption
Figure 4: User Study between ConsisID and state-of-the-art methods. ConsisID is preferred by voters in all dimensions.

🔼 Figure 5 presents a qualitative comparison of video generation results between ConsisID and ID-Animator, highlighting ConsisID’s superior performance. ID-Animator is limited to generating only face-region videos with poor identity preservation (noticeable shape and texture inconsistencies). It also fails to incorporate specified content from text prompts (actions, decorations, backgrounds). In contrast, ConsisID demonstrates significantly improved identity preservation, visual quality, motion expressiveness, and relevance to the text prompt. Furthermore, ConsisID generates a considerably larger number of frames (49 frames at 480x720p resolution) compared to ID-Animator (16 frames at 512x512p resolution).
read the caption
Figure 5: Qualitative analysis between ConsisID and ID-Animator [15]. ID-Animator can only generate videos of the face region, and the identity Preservation is poor (e.g., shape, texture). Additionally, it cannot generate specified content according to the text prompt (e.g., action, decoration, background). ConsisID achieves advantages in identity preservation, visual quality, motion amplitude, and text relevance. Moreover, our ConsistID can generate more frames rather than ID-Animator (49 480×\times×720p frames v.s. 16 512×\times×512p frames).

🔼 This figure demonstrates the importance of each component in the ConsisID model for identity-preserving text-to-video generation. By removing one component at a time (Global Facial Extractor, Local Facial Extractor, Coarse-to-Fine Training, Dynamic Mask Loss, or Dynamic Cross-face Loss), the resulting videos show either a loss of high or low-frequency facial details, or an inability to generate videos that accurately reflect the text prompt. This highlights how each component contributes to both the accurate representation of identity and the effective incorporation of textual instructions into the generated video.
read the caption
Figure 6: Effect of Different Components via Qualitative Analysis. Removing any component may result in the loss of high- or low-frequency facial information, or hinder the ability to modify video content based on the text prompt.

🔼 Figure 7 presents a qualitative comparison of different approaches for injecting control signals (high and low-frequency face signals) into the diffusion transformer model for identity-preserving text-to-video generation. The results demonstrate that injecting both high and low-frequency signals at appropriate locations within the model (method c) yields superior performance compared to other methods. Methods that used only high or only low-frequency signals, or injected the signals into inappropriate locations, resulted in artifacts, poor identity preservation, or an inability to generate high-quality videos.
read the caption
Figure 7: Effect of Different Control Signal Injection Way via Qualitative Analysis. Only (c), which injects both high & low-freq face signals into the suitable location, performs best.

🔼 Figure 8 illustrates the impact of varying the number of inversion steps (t) during video generation. The experiment shows that image quality does not monotonically improve with increasing t. Initially, quality improves as low-frequency components are emphasized, resulting in well-defined structures. However, at higher values of t, high-frequency details become dominant, causing a decline in overall quality, potentially due to noise amplification.
read the caption
Figure 8: Effect of the Inversion Steps t𝑡titalic_t. Overall quality does not improve consistently as t𝑡titalic_t increases, but first improves and then declines. This may be because the early steps are dominated by low frequency, whereas the later steps are dominated by high frequency.
More on tables
| FaceSim-Arc ↑ | FaceSim-Cur ↑ | CLIPScore ↑ | FID ↓ | |
|---|---|---|---|---|
| w/o GFE | 0.05 | 0.05 | 34.86 | 269.88 |
| w/o LFE | 0.66 | 0.68 | 34.48 | 104.34 |
| w/o CFT | 0.54 | 0.58 | 34.47 | 144.62 |
| w/o DML | 0.62 | 0.67 | 34.23 | 187.78 |
| w/o DCL | 0.65 | 0.69 | 32.21 | 117.80 |
| ConsisID | 0.73 | 0.75 | 36.77 | 127.42 |
🔼 Table 2 presents an ablation study analyzing the impact of removing key components from the ConsisID model on its performance. The components evaluated are: Local Facial Extractor (LFE), Global Facial Extractor (GFE), coarse-to-fine training (CFT), dynamic mask loss (DML), and dynamic cross-face loss (DCL). Automatic metrics assess identity preservation, text relevance, and visual quality. The results demonstrate that removing any single component significantly degrades the model’s performance across all three metrics, highlighting the importance of each component in achieving high-quality, identity-preserving video generation.
read the caption
Table 2: Effect of Local Facial Extractor (LFE), Global Facial Extractor (GFE), coarse-to-fine training (CFT), dynamic mask loss (DML) and dynamic cross-face loss (DCL) by Automatic Metrics. Removing any of the above methods significantly reduces identity preservation, text relevance, and visual quality.
| Plan | FaceSim-Arc ↑ | FaceSim-Cur ↑ | CLIPScore ↑ | FID ↓ |
|---|---|---|---|---|
| a | 0.05 | 0.05 | 34.86 | 269.88 |
| b | 0.66 | 0.68 | 34.48 | 104.34 |
| c | 0.73 | 0.75 | 36.77 | 127.42 |
| d | 0.64 | 0.68 | 30.69 | 177.65 |
| e | 0.62 | 0.66 | 33.61 | 164.15 |
| f | \textit{unstable training process} | |||
| g | \textit{unstable training process} |
🔼 This table presents a quantitative analysis comparing different methods of injecting high- and low-frequency facial features into a diffusion model for identity-preserving text-to-video generation. The results show that the best performance is achieved when both high and low-frequency facial information are incorporated into the model (plan c). Other methods, using only high-frequency or only low-frequency information, result in inferior performance. Metrics used likely include identity preservation, visual quality, text relevance, and motion amplitude.
read the caption
Table 3: Effect of Different Control Signal Injection Way via Quantitative Analysis. Only plan c, which injects both high and low-frequency face information into the model, performs best.
| t | FaceSim-Arc ↑ | FaceSim-Cur ↑ | CLIPScore ↑ | FID ↓ | Speed (s) ↓ |
|---|---|---|---|---|---|
| t=25 | 0.50 | 0.53 | 30.43 | 184.44 | 50+ |
| t=50 | 0.52 | 0.54 | 33.08 | 163.68 | 100+ |
| t=75 | 0.43 | 0.52 | 31.92 | 200.86 | 160+ |
| t=100 | 0.46 | 0.55 | 32.25 | 212.74 | 220+ |
| t=125 | 0.42 | 0.51 | 32.38 | 185.85 | 270+ |
| t=150 | 0.34 | 0.40 | 32.41 | 186.56 | 330+ |
| t=175 | 0.35 | 0.42 | 29.98 | 186.99 | 390+ |
| t=200 | 0.33 | 0.39 | 31.18 | 166.79 | 440+ |
🔼 This table presents the results of an ablation study that investigates the impact of varying the number of inversion steps during the video generation process on several quantitative metrics. These metrics assess identity preservation (FaceSim-Arc, FaceSim-Cur), text relevance (CLIPScore), visual quality (FID), and generation speed. The study uses different numbers of inversion steps (25, 50, 75, 100, 125, 150, 175, and 200) to determine the optimal number for balancing quality and efficiency. Lower scores are better for FID, and higher scores are preferred for the rest.
read the caption
Table 4: Effect of the Inversion Steps by Quantitative Analysis. '↓↓\downarrow↓' denotes lower is better. '↑↑\uparrow↑' higher is better.
Full paper#