↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current personalized image generation methods often involve complex training or high inference costs, limiting their practicality. Some methods necessitate finetuning for every new subject, increasing computational burden. Others rely on large image encoders which reduce model flexibility and increase resource demands.
DreamCache overcomes these issues with a novel feature caching approach. It caches a small subset of reference image features, injecting them into a pre-trained diffusion model via lightweight, trained conditioning adapters. This method is finetuning-free, computationally efficient, and highly versatile, achieving state-of-the-art results with significantly fewer parameters than existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DreamCache, a novel and efficient method for personalized image generation. It addresses the limitations of existing methods by using a feature caching mechanism, significantly reducing computational costs and memory requirements. This makes personalized image generation more accessible and practical for a wider range of applications and opens avenues for further research in efficient and scalable personalization techniques for generative models. The plug-and-play nature of DreamCache also contributes to its wider adoption.
Visual Insights#

🔼 Figure 1 illustrates DreamCache’s performance compared to other methods. It highlights DreamCache’s ability to generate personalized images efficiently, accurately reflecting the subject while adhering to textual prompts and requiring minimal memory. Unlike other methods, which often trade off between these factors, DreamCache achieves a superior balance, showing its effectiveness and efficiency.
read the caption
Figure 1: DreamCache is a finetuning-free personalized image generation method that achieves an optimal balance between subject fidelity, memory efficiency, and adherence to text prompts.
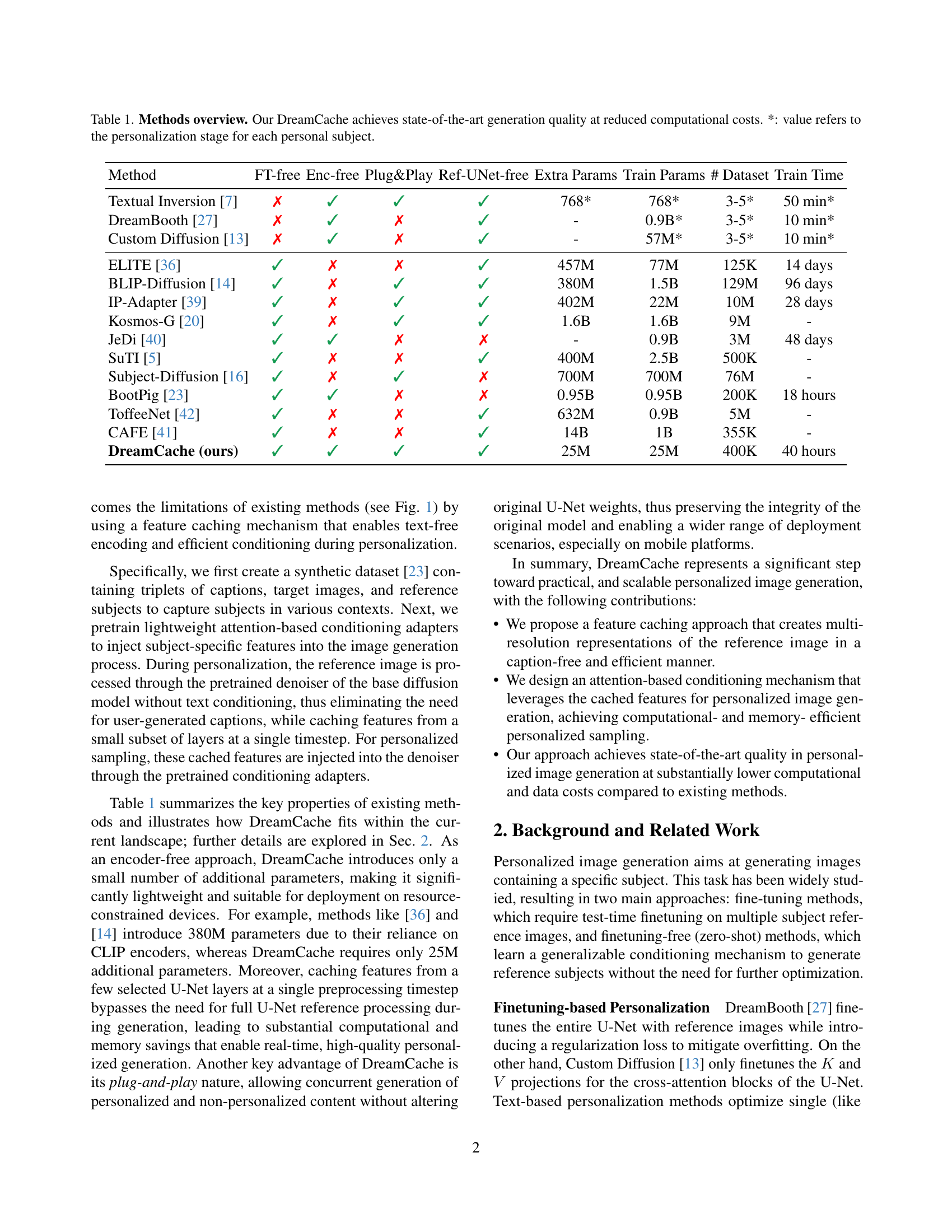
| Method | FT-free | Enc-free | Plug&Play | Ref-UNet-free | Extra Params | Train Params | # Dataset | Train Time |
|---|---|---|---|---|---|---|---|---|
| Textual Inversion [7] | ✗ | ✓ | ✓ | ✓ | 768* | 768* | 3-5* | 50 min* |
| DreamBooth [27] | ✗ | ✓ | ✗ | ✓ | - | 0.9B* | 3-5* | 10 min* |
| Custom Diffusion [13] | ✗ | ✓ | ✗ | ✓ | - | 57M* | 3-5* | 10 min* |
| ELITE [36] | ✓ | ✗ | ✗ | ✓ | 457M | 77M | 125K | 14 days |
| BLIP-Diffusion [14] | ✓ | ✗ | ✓ | ✓ | 380M | 1.5B | 129M | 96 days |
| IP-Adapter [39] | ✓ | ✗ | ✓ | ✓ | 402M | 22M | 10M | 28 days |
| Kosmos-G [20] | ✓ | ✗ | ✓ | ✓ | 1.6B | 1.6B | 9M | - |
| JeDi [40] | ✓ | ✓ | ✗ | ✗ | - | 0.9B | 3M | 48 days |
| SuTI [5] | ✓ | ✗ | ✗ | ✓ | 400M | 2.5B | 500K | - |
| Subject-Diffusion [16] | ✓ | ✗ | ✓ | ✗ | 700M | 700M | 76M | - |
| BootPig [23] | ✓ | ✓ | ✗ | ✗ | 0.95B | 0.95B | 200K | 18 hours |
| ToffeeNet [42] | ✓ | ✗ | ✗ | ✓ | 632M | 0.9B | 5M | - |
| CAFE [41] | ✓ | ✗ | ✗ | ✓ | 14B | 1B | 355K | - |
| DreamCache (ours) | ✓ | ✓ | ✓ | ✓ | 25M | 25M | 400K | 40 hours |
🔼 This table compares different methods for personalized image generation, highlighting their key characteristics. It shows whether each method is finetuning-free, whether it requires an encoder, if it uses a plug-and-play approach, if it requires a reference U-Net, the number of extra parameters added, the size of training parameters used, the number of images in the training dataset, and the total training time. The table emphasizes that DreamCache achieves state-of-the-art results at a significantly lower computational cost compared to existing methods.
read the caption
Table 1: Methods overview. Our DreamCache achieves state-of-the-art generation quality at reduced computational costs. *: value refers to the personalization stage for each personal subject.
In-depth insights#
Cache-Based Personalization#
Cache-based personalization offers a novel approach to personalized image generation by leveraging a pretrained diffusion model and caching reference image features. This technique bypasses the need for computationally expensive fine-tuning or encoder-based methods, enabling efficient and high-quality personalized image generation. The core innovation is caching a small set of features from the reference image at a single timestep of the diffusion process. This cached information, representing subject-specific characteristics, is injected into the generation process via lightweight, trained conditioning adapters, allowing for efficient modulation of generated image features. This method demonstrates a significant reduction in computational costs and memory demands compared to prior methods. However, a potential limitation might be the need for a carefully constructed synthetic dataset during training. Further exploration is needed to fully determine the scalability and limitations of this method, and to explore its applicability for complex scenes with multiple subjects. The plug-and-play nature of this approach allows for the seamless integration with existing diffusion models, while maintaining the model’s ability to switch between personalized and non-personalized tasks, thus preventing language drift issues observed in previous methods.
Adapter Training#
Adapter training in personalized image generation models is crucial for effective zero-shot personalization. The goal is to learn lightweight conditioning modules that can effectively inject subject-specific features into the generation process without requiring full model retraining. A key challenge lies in the need for large and diverse training datasets to ensure generalization across various reference subjects. Creating such datasets can be expensive and time-consuming. Synthetic data generation pipelines, often relying on large language models for generating captions and diffusion models for image synthesis, offer a promising solution but require careful design to avoid biases and maintain data quality. The choice of training loss function is also important, with score matching often used to align generated images with the desired features. The efficiency and effectiveness of the training process directly impact the model’s performance in terms of image quality, subject fidelity, and adherence to textual prompts. Careful consideration of the architecture of the adapters, including choices such as cross-attention mechanisms and the number of parameters, is vital for balancing computational cost and performance. Ultimately, successful adapter training enables high-quality personalized image generation with minimal computational overhead and improved flexibility compared to fine-tuning based methods.
Zero-Shot Approach#
Zero-shot approaches in personalized image generation are transformative because they eliminate the need for fine-tuning on individual subjects, thus drastically reducing computational costs and time. This is achieved by leveraging pre-trained models and employing clever mechanisms like feature caching or encoder-based conditioning. Feature caching strategies, for instance, store specific image features, allowing for dynamic modulation without recalculating them during generation. Encoder-based methods often utilize pre-trained encoders to extract subject-specific features, using those to condition the image synthesis process. While effective, these methods often involve limitations like the size of the encoder or reduced flexibility. The success of zero-shot approaches hinges on the ability of the pre-trained model to generalize across different subjects and contexts, while being efficiently conditioned on the reference subject. Addressing challenges like background interference or computational constraints remains key to further advancing these methods, focusing on improving efficiency while maintaining high-quality and versatile image generation.
Ablation Studies#
The Ablation Studies section of a research paper is crucial for validating design choices and understanding the contribution of individual components. It systematically removes or modifies parts of the proposed model (e.g., the conditioning adapters, caching mechanisms, or the training dataset) to assess their impact on the overall performance. A well-designed ablation study isolates the effect of specific design decisions, allowing researchers to confidently claim that improvements are not due to accidental correlations. This section often involves quantitative experiments showcasing the effects of these alterations using metrics like image quality and alignment scores. It also provides insights into the trade-offs between different design choices (e.g., between computational efficiency and performance), helping readers understand the reasons behind the final architecture. Through a detailed analysis of these results, researchers can build a strong justification for their final model, showing that its architecture is not only effective but also necessary for achieving its performance goals. The inclusion of an ablation study makes the research more robust and increases reader confidence in the reliability of the findings.
Future Directions#
Future research should explore adaptive caching techniques that dynamically adjust the number and location of cached features based on the complexity of the input image and the desired level of personalization. Investigating multi-reference feature integration would enable the generation of images with multiple personalized subjects, significantly expanding the capabilities of the model. Addressing potential misuse is critical; future work must prioritize robust methods for detecting deepfakes and other forms of image manipulation created using this technology. Finally, a focus on enhancing the model’s ability to handle abstract or stylistic images is crucial, as these present unique challenges for feature caching and personalized generation. Further research into these areas will solidify DreamCache’s position as a leading approach to personalized image generation, while mitigating potential risks.
More visual insights#
More on figures

🔼 This figure showcases the capabilities of DreamCache in generating personalized images. The leftmost column displays the reference images used as input to the model. Subsequent columns show images generated by DreamCache based on different text prompts, demonstrating how the model can adapt the reference subject to various contexts and styles while retaining its core features. This illustrates the model’s ability to personalize image generation according to textual instructions, even with no fine-tuning of the model.
read the caption
Figure 2: Personalized generations by DreamCache. The first column contains reference images. The generated images correspond to the text prompts above each column.

🔼 DreamCache uses a pretrained diffusion model. During personalization, features from specific layers of the diffusion model’s U-Net are extracted at a single timestep, without using a text prompt. These cached features represent the reference subject. A set of trainable conditioning adapters then use these cached features to modulate the generated image features, creating a personalized output. The original U-Net layers are shown in violet, while the added components are in green.
read the caption
Figure 3: Overview of DreamCache. Original U-Net layers are shown in violet, while the novel components introduced by DreamCache are highlighted in green. During personalization, features from selected layers of the diffusion denoiser are cached from a single timestep, using a null text prompt. These cached features serve as reference-specific information. During generation, conditioning adapters inject the cached features into the denoiser, modulating the features of the generated image to create a personalized output.

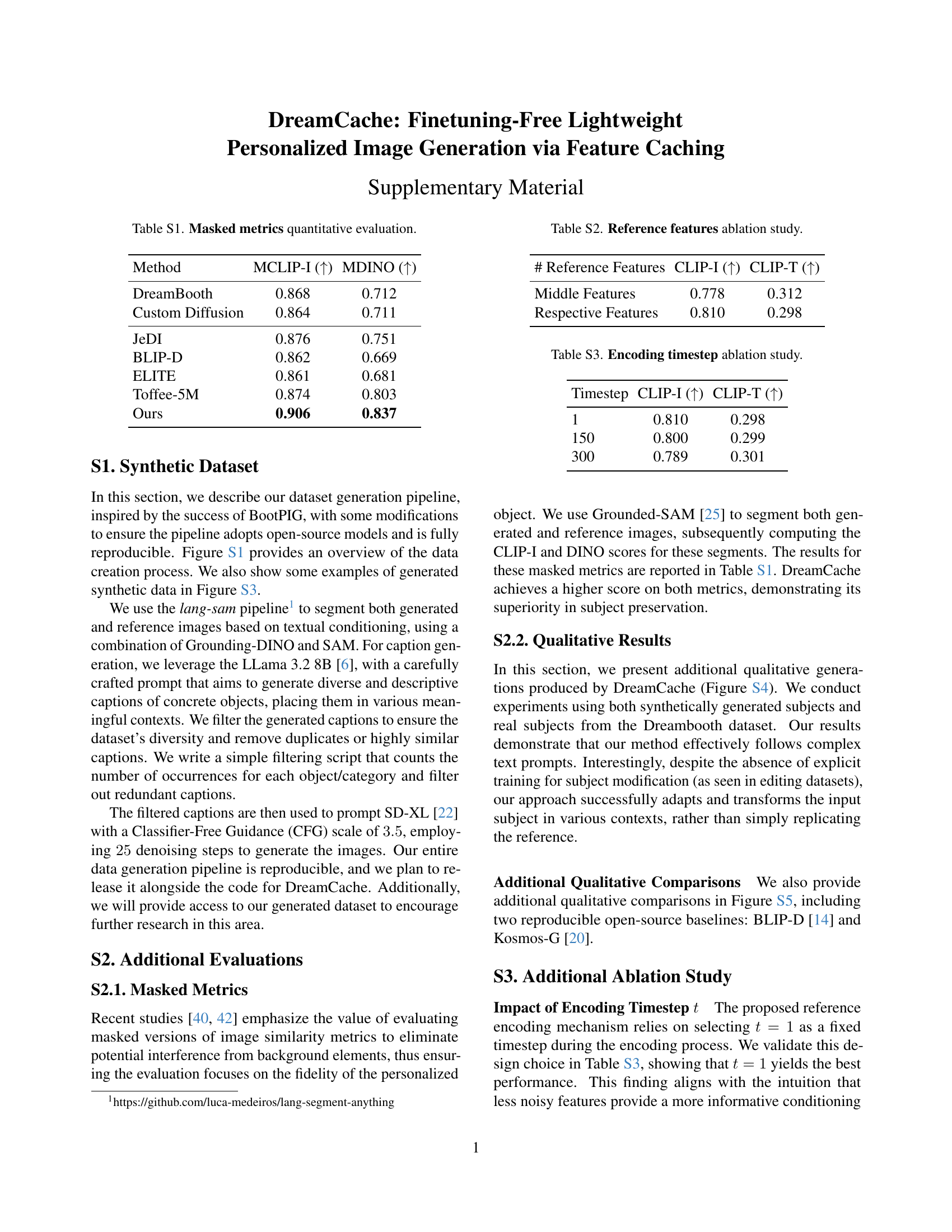
🔼 Figure 4 presents a visual comparison of personalized image generation results from three different methods: DreamCache, BLIP-Diffusion, and Kosmos-G. Each method was tasked with generating images of various subjects (a dog, a can, a toy) in different contexts. The results demonstrate that DreamCache successfully preserves the appearance and details of the reference subject while avoiding background interference. In contrast, BLIP-Diffusion and Kosmos-G struggle to faithfully reproduce the visual details of the reference subjects.
read the caption
Figure 4: Visual comparison. Personalized generations on sample concepts. DreamCache preserves reference concept appearance and does not suffer from background interference. BLIP-D [14] and Kosmos-G [20] cannot faithfully preserve visual details from the reference.
More on tables
| “A dragon…” | “as street graffiti” | “playing with fire” | “as a plushie” | “working as a barista” |
|---|---|---|---|---|
| https://arxiv.org/html/2411.17786/figures/flux_dragon.png | https://arxiv.org/html/2411.17786/figures/graffiti_dragon.jpg | https://arxiv.org/html/2411.17786/figures/playing_fire.png | https://arxiv.org/html/2411.17786/figures/plushie_dragon2.jpg | https://arxiv.org/html/2411.17786/figures/barista.png |
| “A cat…” | “in Ukiyo-e style” | “with a rainbow scarf” | “Van Gogh painting” | “wearing a diploma hat” |
| — | — | — | — | — |
| https://arxiv.org/html/2411.17786/figures/cat_ref.jpg | https://arxiv.org/html/2411.17786/figures/ukiyo-cat.jpg | https://arxiv.org/html/2411.17786/figures/rainbow_scarf_cat.jpg | https://arxiv.org/html/2411.17786/figures/van_gogh_cat.jpg | https://arxiv.org/html/2411.17786/figures/cat_diploma.jpg |
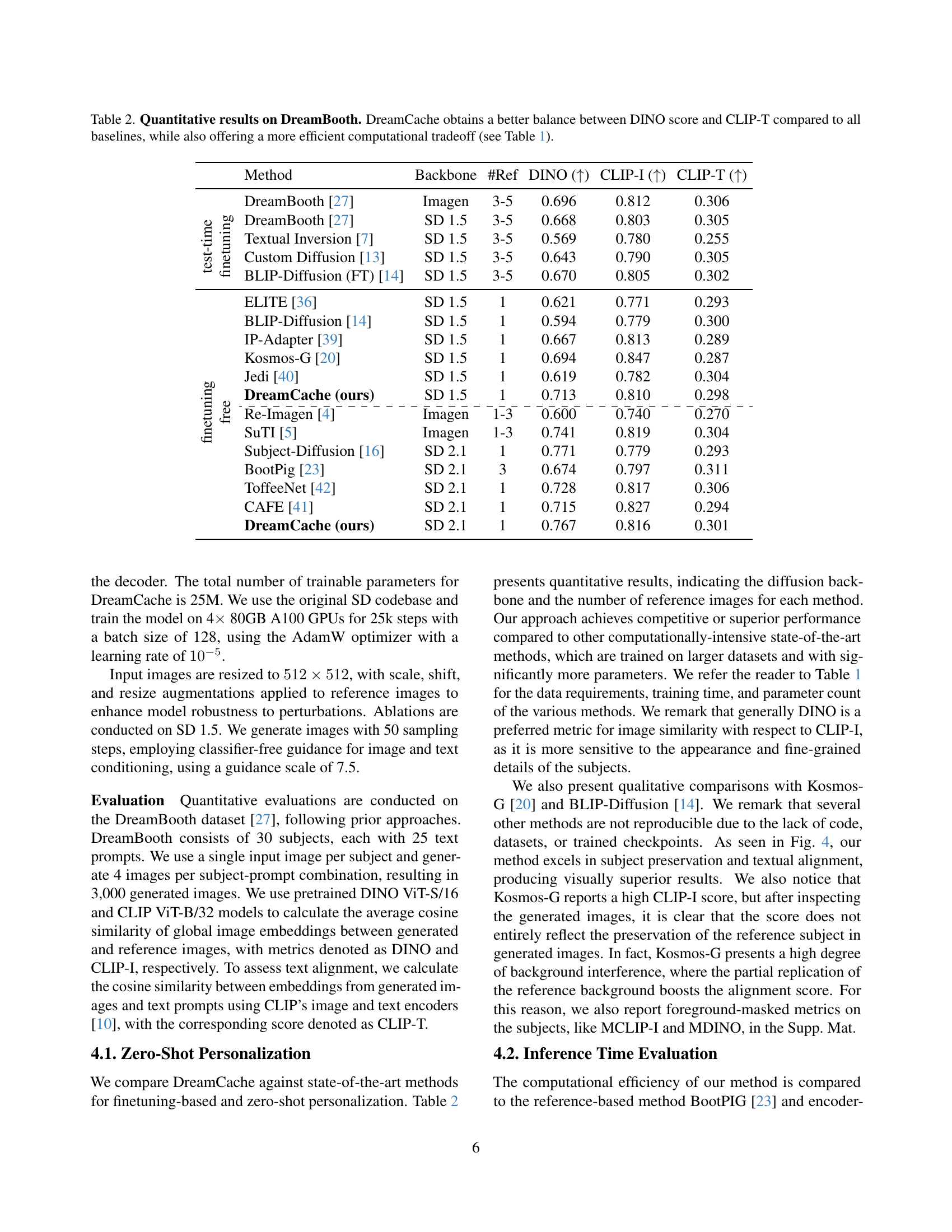
🔼 Table 2 presents a quantitative comparison of DreamCache against other state-of-the-art methods for personalized image generation, focusing on DreamBooth as a baseline. The evaluation uses three metrics: DINO (evaluates image similarity to reference images), CLIP-I (measures image-text similarity by comparing generated images to reference images using CLIP), and CLIP-T (assesses text alignment between generated images and the input text prompts using CLIP). DreamCache demonstrates a superior balance between DINO and CLIP-T scores compared to other models. It also showcases significantly improved computational efficiency when compared to other models (refer to Table 1 for detailed information on the computational trade-offs).
read the caption
Table 2: Quantitative results on DreamBooth. DreamCache obtains a better balance between DINO score and CLIP-T compared to all baselines, while also offering a more efficient computational tradeoff (see Table 1).
| Method | Backbone | #Ref | DINO (↑) | CLIP-I (↑) | CLIP-T (↑) |
|---|---|---|---|---|---|
 | DreamBooth [27] | Imagen | 3-5 | 0.696 | 0.812 |
| DreamBooth [27] | SD 1.5 | 3-5 | 0.668 | 0.803 | |
| Textual Inversion [7] | SD 1.5 | 3-5 | 0.569 | 0.780 | |
| Custom Diffusion [13] | SD 1.5 | 3-5 | 0.643 | 0.790 | |
| BLIP-Diffusion (FT) [14] | SD 1.5 | 3-5 | 0.670 | 0.805 | |
 | ELITE [36] | SD 1.5 | 1 | 0.621 | 0.771 |
| BLIP-Diffusion [14] | SD 1.5 | 1 | 0.594 | 0.779 | |
| IP-Adapter [39] | SD 1.5 | 1 | 0.667 | 0.813 | |
| Kosmos-G [20] | SD 1.5 | 1 | 0.694 | 0.847 | |
| Jedi [40] | SD 1.5 | 1 | 0.619 | 0.782 | |
| DreamCache (ours) | SD 1.5 | 1 | 0.713 | 0.810 | |
| Re-Imagen [4] | Imagen | 1-3 | 0.600 | 0.740 | |
| SuTI [5] | Imagen | 1-3 | 0.741 | 0.819 | |
| Subject-Diffusion [16] | SD 2.1 | 1 | 0.771 | 0.779 | |
| BootPig [23] | SD 2.1 | 3 | 0.674 | 0.797 | |
| ToffeeNet [42] | SD 2.1 | 1 | 0.728 | 0.817 | |
| CAFE [41] | SD 2.1 | 1 | 0.715 | 0.827 | |
| DreamCache (ours) | SD 2.1 | 1 | 0.767 | 0.816 |
🔼 This table compares the computational efficiency of different methods for generating personalized images. It shows the inference time (in seconds) required to generate a single image with 100 timesteps using a single NVIDIA A100 GPU, as well as the size of the additional parameters (in MB) required for each method. The table highlights DreamCache’s efficiency compared to other state-of-the-art methods.
read the caption
Table 3: Computational comparison. *: time to generate an image with 100 timesteps, evaluated on a single NVIDIA A100 GPU.
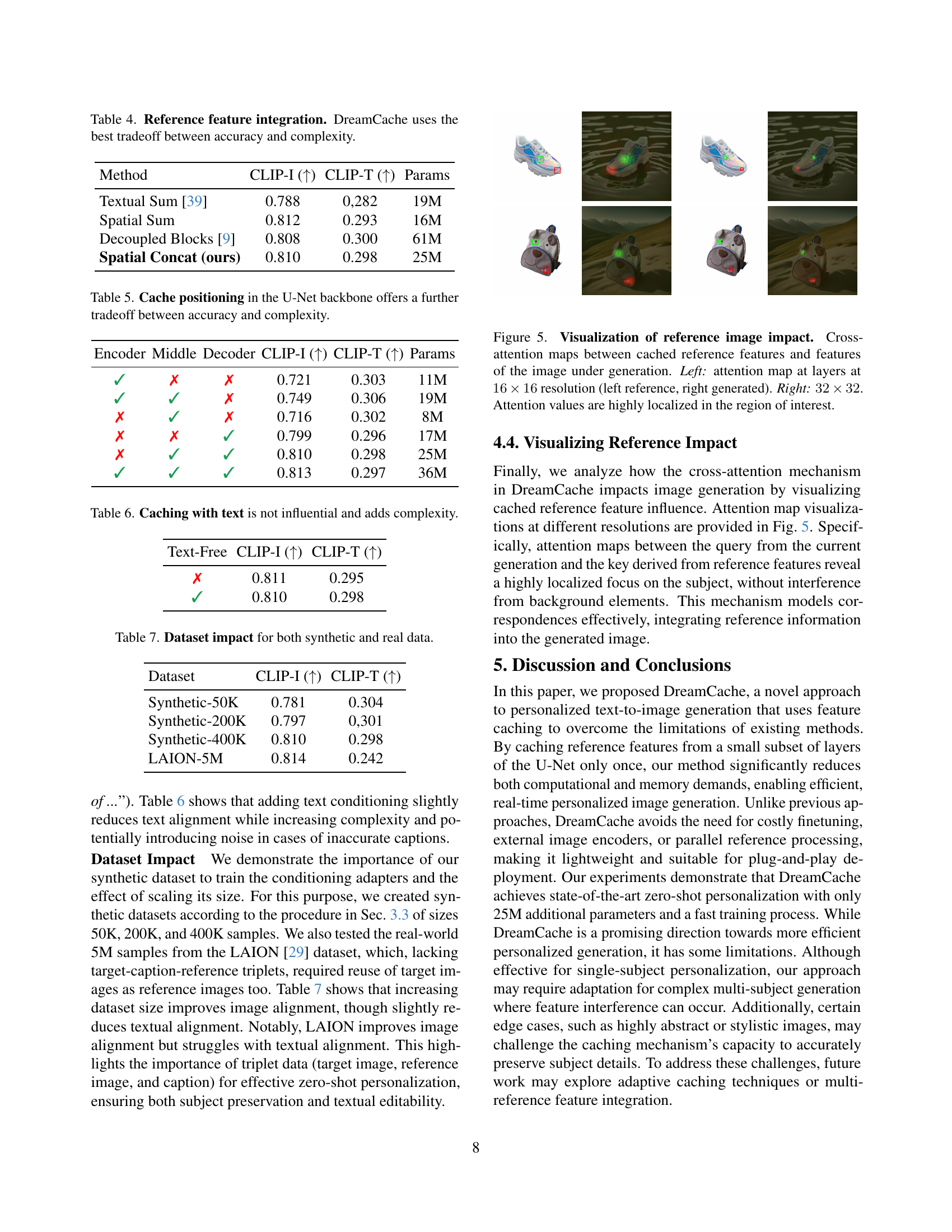
🔼 Table 4 presents a comparison of different methods for integrating reference features into the image generation process. It shows that DreamCache achieves the best balance between the quality of generated images (measured by CLIP-I and CLIP-T scores) and the number of parameters used. The methods compared include Textual Sum, Spatial Sum, Decoupled Blocks, and DreamCache’s Spatial Concat method. The table helps to justify the design choices made in DreamCache by demonstrating its superior performance compared to other approaches while maintaining efficiency.
read the caption
Table 4: Reference feature integration. DreamCache uses the best tradeoff between accuracy and complexity.
| Method | Inference Time* | Extra Params Size |
|---|---|---|
| ELITE [36] | 6.24 s | 914 MB |
| BLIP-Diffusion [14] | 3.92 s | 760 MB |
| BootPig [23] | 7.55 s | 1900 MB |
| DreamCache (ours) | 3.88 s | 42 MB |
🔼 This table presents the results of an ablation study that explores different cache positions within the U-Net backbone of the DreamCache model. It investigates how the choice of layers from which to extract and cache features affects the tradeoff between the model’s accuracy in generating personalized images and the overall complexity of the model. By testing different combinations of middle and decoder layers from which to extract features, this table helps to optimize DreamCache for performance while maintaining efficiency.
read the caption
Table 5: Cache positioning in the U-Net backbone offers a further tradeoff between accuracy and complexity.
| Method | CLIP-I (↑) | CLIP-T (↑) | Params |
|---|---|---|---|
| Textual Sum [39] | 0.788 | 0.282 | 19M |
| Spatial Sum | 0.812 | 0.293 | 16M |
| Decoupled Blocks [9] | 0.808 | 0.300 | 61M |
| Spatial Concat (ours) | 0.810 | 0.298 | 25M |
🔼 Table 6 presents an ablation study on the impact of using text prompts during the feature caching process in DreamCache. It compares the performance of DreamCache when text input is used versus when no text input is used during caching. The results show that using text during caching doesn’t improve performance and adds unnecessary complexity to the model.
read the caption
Table 6: Caching with text is not influential and adds complexity.
| Encoder | Middle | Decoder | CLIP-I ( ) ) | CLIP-T () | Params |
|---|---|---|---|---|---|
| ✓ | ✗ | ✗ | 0.721 | 0.303 | 11M |
| ✓ | ✓ | ✗ | 0.749 | 0.306 | 19M |
| ✗ | ✓ | ✗ | 0.716 | 0.302 | 8M |
| ✗ | ✗ | ✓ | 0.799 | 0.296 | 17M |
| ✗ | ✓ | ✓ | 0.810 | 0.298 | 25M |
| ✓ | ✓ | ✓ | 0.813 | 0.297 | 36M |
🔼 This table presents the quantitative results achieved by training the DreamCache model’s conditioning adapters on various datasets. It shows how the model’s performance on image and text alignment tasks varies depending on the size and type of training data used. Specifically, it compares the performance using synthetic datasets of 50K, 200K, and 400K samples, as well as a real-world dataset, LAION-5M, to demonstrate the impact of dataset size and the nature of the data (synthetic vs. real) on the model’s generalization capabilities.
read the caption
Table 7: Dataset impact for both synthetic and real data.
| Text-Free | CLIP-I (↑) | CLIP-T (↑) |
|---|---|---|
| ✗ | 0.811 | 0.295 |
| ✓ | 0.810 | 0.298 |
🔼 This table presents a quantitative comparison of several methods for image generation, focusing on the accuracy of preserving the subject in generated images while minimizing interference from the background. It uses masked versions of standard image similarity metrics (MCLIP-I and MDINO) to evaluate the quality of subject preservation. The metrics assess the similarity between generated images and the masked portions of the corresponding reference images, isolating the subject from the background and thus providing a more precise evaluation of personalization.
read the caption
Table S1: Masked metrics quantitative evaluation.
| Dataset | CLIP-I (↑) | CLIP-T (↑) |
|---|---|---|
| Synthetic-50K | 0.781 | 0.304 |
| Synthetic-200K | 0.797 | 0.301 |
| Synthetic-400K | 0.810 | 0.298 |
| LAION-5M | 0.814 | 0.242 |
🔼 This table presents the results of an ablation study investigating the impact of different numbers and selections of reference features on the performance of DreamCache. It shows how varying the number of reference features and using only middle or respective layers impacts the CLIP-I and CLIP-T scores, which measure image and text alignment respectively. This analysis helps determine the optimal strategy for selecting reference features to balance model accuracy and efficiency.
read the caption
Table S2: Reference features ablation study.








🔼 This table presents the results of an ablation study on the effect of different encoding timesteps on the performance of DreamCache. It shows how varying the timestep used to extract and cache reference features impacts the model’s ability to align generated images with both reference images (CLIP-I) and text prompts (CLIP-T). The study evaluates three different timesteps: 1, 150, and 300, demonstrating the optimal timestep for obtaining a good balance between visual fidelity and textual coherence.
read the caption
Table S3: Encoding timestep ablation study.
Full paper#