↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current keyphrase extraction techniques struggle with long documents due to the limitations of existing language models and the difficulty of capturing extended text context. This leads to inaccurate and incomplete extraction of vital information from lengthy documents, hindering effective information retrieval and management.
LongKey tackles this problem by employing a Longformer-based encoder model capable of processing documents with up to 96K tokens. It also incorporates a novel max-pooling embedding strategy to improve keyphrase representation. Evaluated against existing methods on various datasets, LongKey demonstrates superior performance, showcasing its ability to reliably and accurately extract keyphrases from long documents, significantly advancing the state-of-the-art in long-document keyphrase extraction.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in natural language processing and information retrieval. It directly addresses the limitations of existing keyphrase extraction methods in handling long documents, a significant challenge in the field. The proposed framework, LongKey, opens new avenues for improving information access and management in various domains, impacting the efficiency of research workflows and potentially leading to better information systems.
Visual Insights#

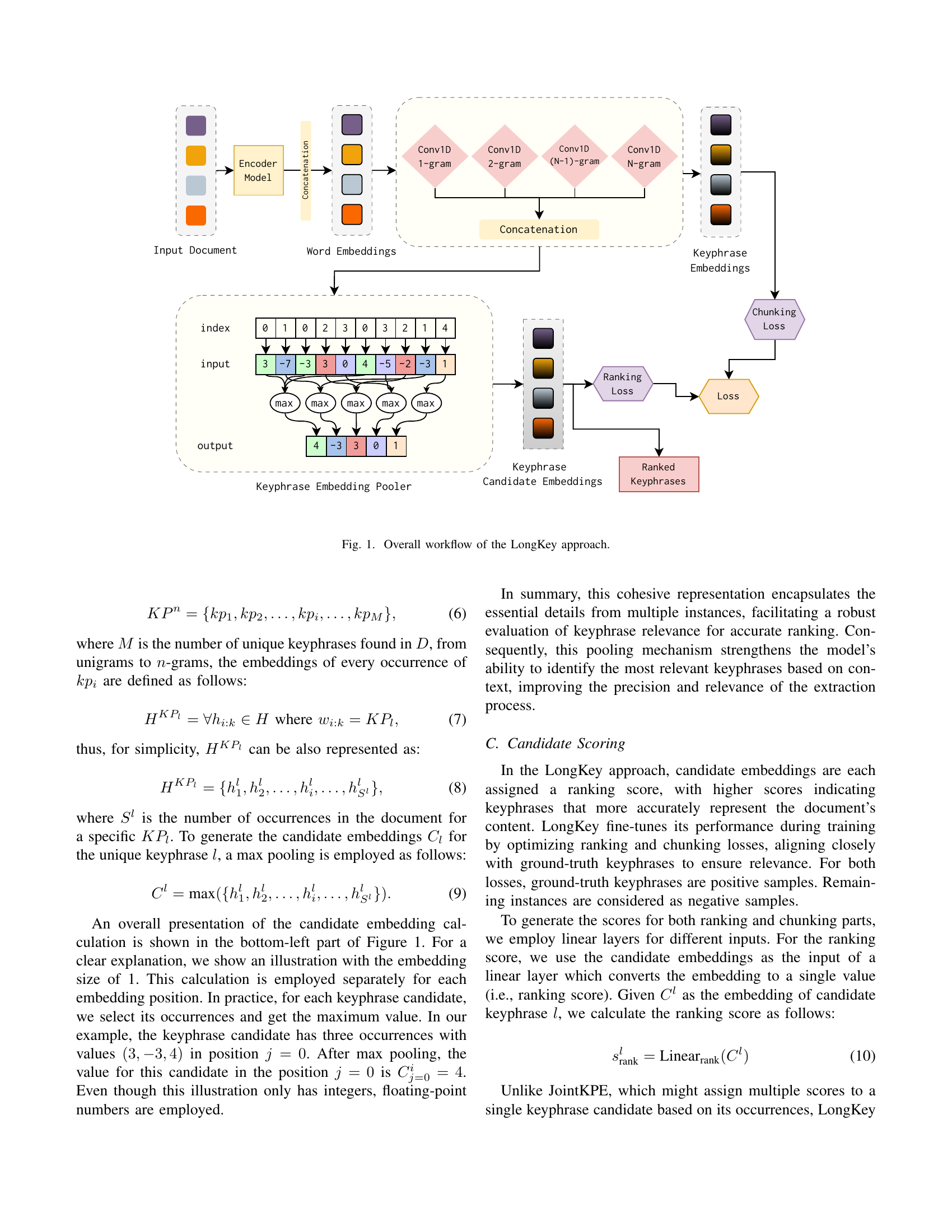
🔼 The figure illustrates the three main stages of the LongKey keyphrase extraction framework: 1) Word embedding uses the Longformer model to generate embeddings for each word in the input document. For documents longer than 8K tokens, the document is chunked into smaller parts before processing, and the resulting embeddings are concatenated. 2) Keyphrase embedding utilizes a convolutional neural network to generate embeddings for each keyphrase candidate (n-grams up to length n = 5), and max pooling combines the embeddings of all occurrences of a candidate into a single representation. 3) Candidate scoring assigns a ranking score to each candidate using linear layers and a margin ranking loss. The scores are then used to rank and select the most relevant keyphrases.
read the caption
Figure 1: Overall workflow of the LongKey approach.
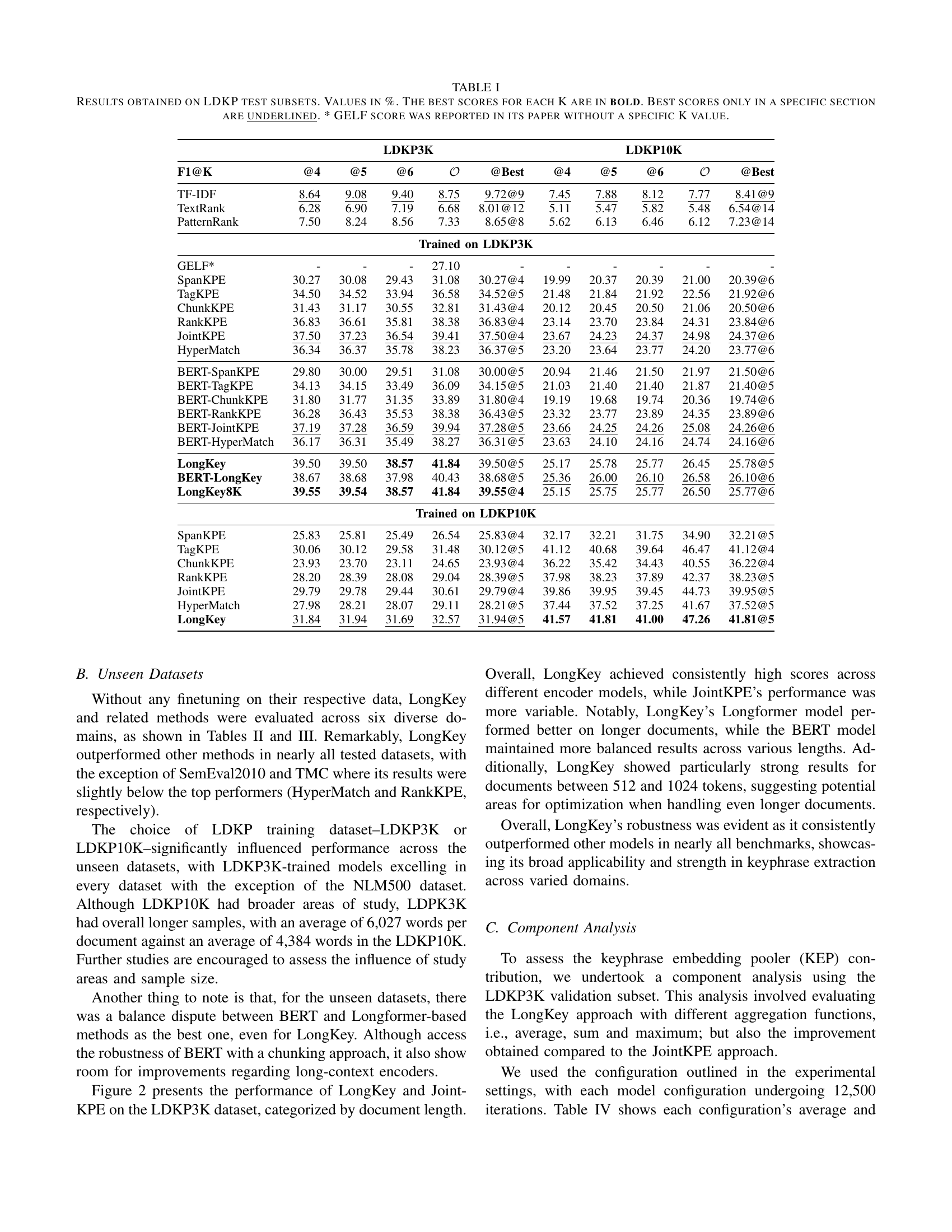
| LDKP3K | LDKP10K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1@K | @4 | @5 | @6 | 𝒪 | @Best | @4 | @5 | @6 | 𝒪 | @Best |
| TF-IDF | 8.64 | 9.08 | 9.40 | 8.75 | 9.72@9 | 7.45 | 7.88 | 8.12 | 7.77 | 8.41@9 |
| TextRank | 6.28 | 6.90 | 7.19 | 6.68 | 8.01@12 | 5.11 | 5.47 | 5.82 | 5.48 | 6.54@14 |
| PatternRank | 7.50 | 8.24 | 8.56 | 7.33 | 8.65@8 | 5.62 | 6.13 | 6.46 | 6.12 | 7.23@14 |
| Trained on LDKP3K | ||||||||||
| GELF* | - | - | - | 27.10 | - | - | - | - | - | - |
| SpanKPE | 30.27 | 30.08 | 29.43 | 31.08 | 30.27@4 | 19.99 | 20.37 | 20.39 | 21.00 | 20.39@6 |
| TagKPE | 34.50 | 34.52 | 33.94 | 36.58 | 34.52@5 | 21.48 | 21.84 | 21.92 | 22.56 | 21.92@6 |
| ChunkKPE | 31.43 | 31.17 | 30.55 | 32.81 | 31.43@4 | 20.12 | 20.45 | 20.50 | 21.06 | 20.50@6 |
| RankKPE | 36.83 | 36.61 | 35.81 | 38.38 | 36.83@4 | 23.14 | 23.70 | 23.84 | 24.31 | 23.84@6 |
| JointKPE | 37.50 | 37.23 | 36.54 | 39.41 | 37.50@4 | 23.67 | 24.23 | 24.37 | 24.98 | 24.37@6 |
| HyperMatch | 36.34 | 36.37 | 35.78 | 38.23 | 36.37@5 | 23.20 | 23.64 | 23.77 | 24.20 | 23.77@6 |
| BERT-SpanKPE | 29.80 | 30.00 | 29.51 | 31.08 | 30.00@5 | 20.94 | 21.46 | 21.50 | 21.97 | 21.50@6 |
| BERT-TagKPE | 34.13 | 34.15 | 33.49 | 36.09 | 34.15@5 | 21.03 | 21.40 | 21.40 | 21.87 | 21.40@5 |
| BERT-ChunkKPE | 31.80 | 31.77 | 31.35 | 33.89 | 31.80@4 | 19.19 | 19.68 | 19.74 | 20.36 | 19.74@6 |
| BERT-RankKPE | 36.28 | 36.43 | 35.53 | 38.38 | 36.43@5 | 23.32 | 23.77 | 23.89 | 24.35 | 23.89@6 |
| BERT-JointKPE | 37.19 | 37.28 | 36.59 | 39.94 | 37.28@5 | 23.66 | 24.25 | 24.26 | 25.08 | 24.26@6 |
| BERT-HyperMatch | 36.17 | 36.31 | 35.49 | 38.27 | 36.31@5 | 23.63 | 24.10 | 24.16 | 24.74 | 24.16@6 |
| LongKey | 39.50 | 39.50 | 38.57 | 41.84 | 39.50@5 | 25.17 | 25.78 | 25.77 | 26.45 | 25.78@5 |
| BERT-LongKey | 38.67 | 38.68 | 37.98 | 40.43 | 38.68@5 | 25.36 | 26.00 | 26.10 | 26.58 | 26.10@6 |
| LongKey8K | 39.55 | 39.54 | 38.57 | 41.84 | 39.55@4 | 25.15 | 25.75 | 25.77 | 26.50 | 25.77@6 |
| Trained on LDKP10K | ||||||||||
| SpanKPE | 25.83 | 25.81 | 25.49 | 26.54 | 25.83@4 | 32.17 | 32.21 | 31.75 | 34.90 | 32.21@5 |
| TagKPE | 30.06 | 30.12 | 29.58 | 31.48 | 30.12@5 | 41.12 | 40.68 | 39.64 | 46.47 | 41.12@4 |
| ChunkKPE | 23.93 | 23.70 | 23.11 | 24.65 | 23.93@4 | 36.22 | 35.42 | 34.43 | 40.55 | 36.22@4 |
| RankKPE | 28.20 | 28.39 | 28.08 | 29.04 | 28.39@5 | 37.98 | 38.23 | 37.89 | 42.37 | 38.23@5 |
| JointKPE | 29.79 | 29.78 | 29.44 | 30.61 | 29.79@4 | 39.86 | 39.95 | 39.45 | 44.73 | 39.95@5 |
| HyperMatch | 27.98 | 28.21 | 28.07 | 29.11 | 28.21@5 | 37.44 | 37.52 | 37.25 | 41.67 | 37.52@5 |
| LongKey | 31.84 | 31.94 | 31.69 | 32.57 | 31.94@5 | 41.57 | 41.81 | 41.00 | 47.26 | 41.81@5 |
🔼 This table presents a comprehensive comparison of keyphrase extraction methods on the LDKP3K and LDKP10K datasets. It shows the F1@K scores (harmonic mean of precision and recall at K keyphrases) for various methods, including unsupervised techniques (TF-IDF, TextRank, PatternRank), and supervised methods (SpanKPE, TagKPE, ChunkKPE, RankKPE, JointKPE, HyperMatch) and BERT-based variants of some of the supervised methods. Results are broken down by F1@4, F1@5, F1@6, and F1@Best (best F1-score across different values of K). The table also indicates which models were trained on the LDKP3K dataset and which were trained on the larger LDKP10K dataset, allowing for comparison of performance across different training regimes. The GELF method’s F1-score is included but without a specific K value because its paper did not provide one.
read the caption
TABLE I: Results obtained on LDKP test subsets. Values in %. The best scores for each K are in bold. Best scores only in a specific section are underlined. * GELF score was reported in its paper without a specific K value.
In-depth insights#
LongDoc Keyphrase#
The heading “LongDoc Keyphrase” suggests a research focus on keyphrase extraction from long documents. This is a significant area because traditional methods often struggle with the increased contextual complexity and length of such texts. A system addressing this, like a hypothetical “LongDoc Keyphrase” system, would likely employ advanced techniques such as long-context language models (e.g., Longformer) to capture extended text dependencies effectively. The challenge lies in efficiently processing vast amounts of text while maintaining accuracy. Efficient embedding strategies, potentially involving novel pooling or attention mechanisms, are crucial for representing keyphrase candidates within a long document’s context. The system’s evaluation would necessitate robust benchmarks comprising lengthy documents from diverse domains, emphasizing the need for datasets beyond the commonly used short text corpora. Furthermore, a comprehensive comparison against existing keyphrase extraction methods would highlight “LongDoc Keyphrase’s” unique advantages and limitations.
Max-Pooling Embed#
The concept of ‘Max-Pooling Embed’ suggests a method for creating keyphrase embeddings by using max pooling to aggregate the embeddings of individual tokens. This approach is likely employed to capture the most salient features of a keyphrase regardless of its length or word order within the document. Max pooling, by selecting the maximum value across all embeddings for each position, effectively creates a compact representation summarizing the keyphrase’s context. This is beneficial because it reduces dimensionality and computational cost while preserving essential information. The success of this approach hinges on the quality of the initial token embeddings and the appropriateness of max pooling for the specific task. An important consideration would be whether max pooling is sensitive enough to nuance in the text or might ignore subtle contextual information which might be crucial for ranking keyphrases. Furthermore, alternative pooling methods such as average pooling or more sophisticated attention mechanisms could be explored for comparison to optimize results. The choice of pooling strategy could significantly impact the final performance of the keyphrase extraction system.
LDKP Dataset#
The Long Document Keyphrase Extraction dataset (LDKP) is a significant contribution to the field of natural language processing, specifically addressing the limitations of existing datasets in handling long-form documents. Its creation directly tackles the scarcity of resources suitable for training and evaluating models designed for keyphrase extraction in lengthy texts, a crucial aspect often overlooked in previous research. The dataset’s impact is noteworthy because it allows researchers to develop and benchmark more robust algorithms capable of managing the complexities inherent in longer documents. The inclusion of full-text papers, beyond the typical abstracts and short articles, provides a much-needed testbed for evaluating the true capabilities of keyphrase extraction systems. This focus on long-form content is a key advantage, pushing the boundaries of the field and facilitating more advanced techniques. Moreover, the use of LDKP datasets in benchmark studies is expected to become a standard practice, driving future research and development towards more sophisticated and reliable keyphrase extraction methods suitable for diverse applications involving longer texts. The LDKP dataset’s availability and comprehensive nature mark a turning point in the direction of the field towards handling the increasingly large volume of long-format textual information.
Longformer Impact#
The Longformer model’s impact on keyphrase extraction is multifaceted. Its ability to handle long sequences (up to 96K tokens) is crucial, enabling the processing of lengthy documents that traditional models struggle with. This addresses a major limitation in existing keyphrase extraction research, which often focuses on shorter texts. The model’s use of sliding window attention and global attention mechanisms effectively captures both local and global contexts within the document, leading to improved accuracy in identifying relevant keyphrases. Extended context awareness allows the model to better discern the nuanced relationships between words and phrases, improving the identification of less frequent but equally important keyphrases. However, the computational demands of processing such long sequences remain a challenge, necessitating strategies like chunking to manage resource constraints efficiently. The choice of tokenizer (e.g., RoBERTa) and integration with a keyphrase embedding pooler further contribute to Longformer’s overall effectiveness. In short, Longformer’s impact represents a substantial advancement in the field, enabling more accurate and comprehensive keyphrase extraction from long documents, although its application requires careful consideration of computational limitations.
Future KPE#
Future research in keyphrase extraction (KPE) should focus on several key areas. Handling truly long documents remains a challenge, demanding more efficient and scalable algorithms beyond current limitations. Improved context modeling is crucial; current methods often struggle with nuanced language and complex relationships between concepts. Cross-lingual KPE needs further development to ensure accurate and reliable extraction across different languages. Addressing the domain adaptation problem is vital, making models adaptable to diverse domains without extensive retraining. Finally, combining KPE with other NLP tasks, such as summarization or question answering, promises to unlock new capabilities in information retrieval and knowledge discovery. More sophisticated evaluation metrics are also needed to better capture the nuances of KPE performance across various datasets and application scenarios.
More visual insights#
More on tables
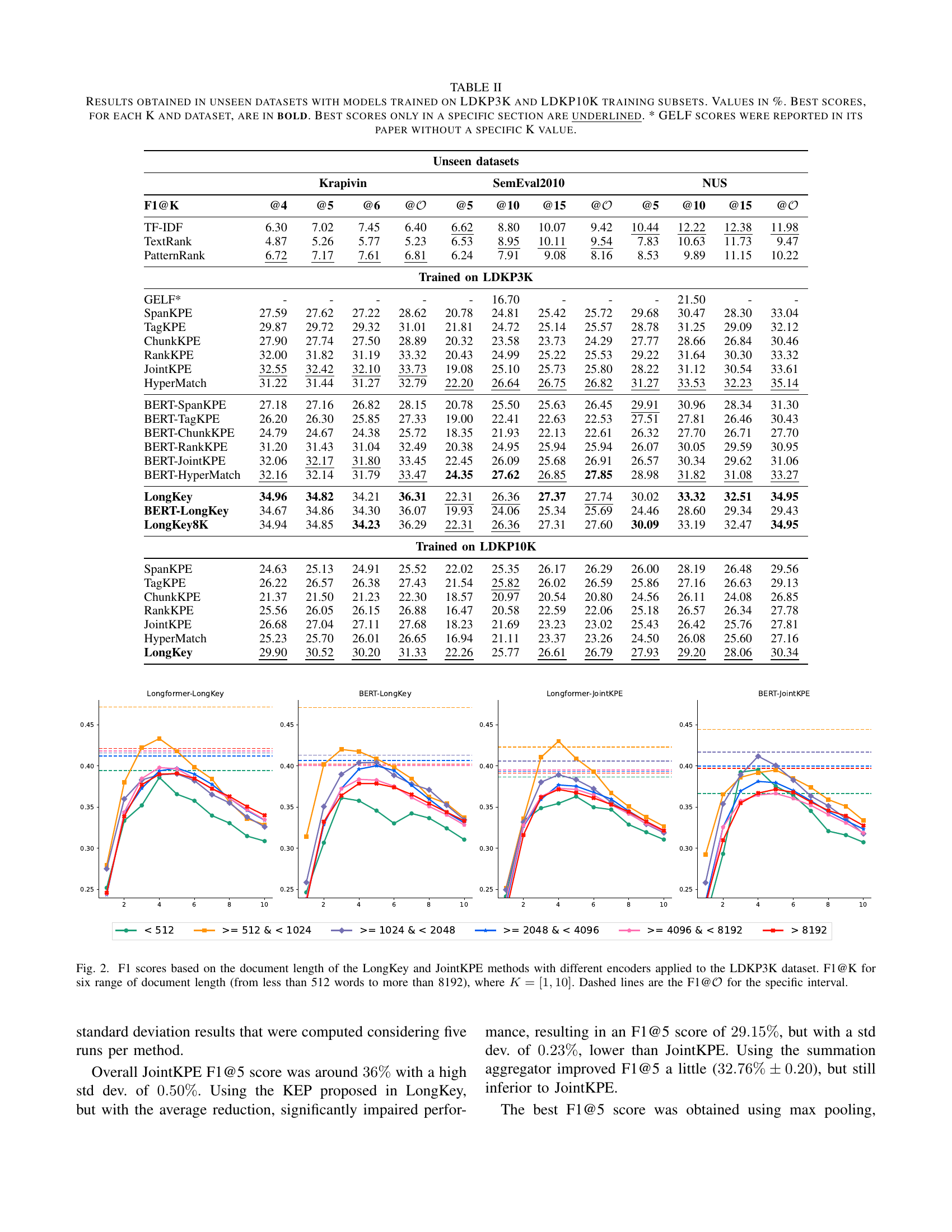
| F1@K | Krapivin | SemEval2010 | NUS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| @4 | @5 | @6 | @O | @5 | @10 | @15 | @O | @5 | @10 | @15 | @O | |
| TF-IDF | 6.30 | 7.02 | 7.45 | 6.40 | 6.62 | 8.80 | 10.07 | 9.42 | 10.44 | 12.22 | 12.38 | 11.98 |
| TextRank | 4.87 | 5.26 | 5.77 | 5.23 | 6.53 | 8.95 | 10.11 | 9.54 | 7.83 | 10.63 | 11.73 | 9.47 |
| PatternRank | 6.72 | 7.17 | 7.61 | 6.81 | 6.24 | 7.91 | 9.08 | 8.16 | 8.53 | 9.89 | 11.15 | 10.22 |
| Trained on LDKP3K | ||||||||||||
| GELF* | - | - | - | - | - | 16.70 | - | - | - | 21.50 | - | - |
| SpanKPE | 27.59 | 27.62 | 27.22 | 28.62 | 20.78 | 24.81 | 25.42 | 25.72 | 29.68 | 30.47 | 28.30 | 33.04 |
| TagKPE | 29.87 | 29.72 | 29.32 | 31.01 | 21.81 | 24.72 | 25.14 | 25.57 | 28.78 | 31.25 | 29.09 | 32.12 |
| ChunkKPE | 27.90 | 27.74 | 27.50 | 28.89 | 20.32 | 23.58 | 23.73 | 24.29 | 27.77 | 28.66 | 26.84 | 30.46 |
| RankKPE | 32.00 | 31.82 | 31.19 | 33.32 | 20.43 | 24.99 | 25.22 | 25.53 | 29.22 | 31.64 | 30.30 | 33.32 |
| JointKPE | 32.55 | 32.42 | 32.10 | 33.73 | 19.08 | 25.10 | 25.73 | 25.80 | 28.22 | 31.12 | 30.54 | 33.61 |
| HyperMatch | 31.22 | 31.44 | 31.27 | 32.79 | 22.20 | 26.64 | 26.75 | 26.82 | 31.27 | 33.53 | 32.23 | 35.14 |
| BERT-SpanKPE | 27.18 | 27.16 | 26.82 | 28.15 | 20.78 | 25.50 | 25.63 | 26.45 | 29.91 | 30.96 | 28.34 | 31.30 |
| BERT-TagKPE | 26.20 | 26.30 | 25.85 | 27.33 | 19.00 | 22.41 | 22.63 | 22.53 | 27.51 | 27.81 | 26.46 | 30.43 |
| BERT-ChunkKPE | 24.79 | 24.67 | 24.38 | 25.72 | 18.35 | 21.93 | 22.13 | 22.61 | 26.32 | 27.70 | 26.71 | 27.70 |
| BERT-RankKPE | 31.20 | 31.43 | 31.04 | 32.49 | 20.38 | 24.95 | 25.94 | 25.94 | 26.07 | 30.05 | 29.59 | 30.95 |
| BERT-JointKPE | 32.06 | 32.17 | 31.80 | 33.45 | 22.45 | 26.09 | 25.68 | 26.91 | 26.57 | 30.34 | 29.62 | 31.06 |
| BERT-HyperMatch | 32.16 | 32.14 | 31.79 | 33.47 | 24.35 | 27.62 | 26.85 | 27.85 | 28.98 | 31.82 | 31.08 | 33.27 |
| LongKey | 34.96 | 34.82 | 34.21 | 36.31 | 22.31 | 26.36 | 27.37 | 27.74 | 30.02 | 33.32 | 32.51 | 34.95 |
| BERT-LongKey | 34.67 | 34.86 | 34.30 | 36.07 | 19.93 | 24.06 | 25.34 | 25.69 | 24.46 | 28.60 | 29.34 | 29.43 |
| LongKey8K | 34.94 | 34.85 | 34.23 | 36.29 | 22.31 | 26.36 | 27.31 | 27.60 | 30.09 | 33.19 | 32.47 | 34.95 |
| Trained on LDKP10K | ||||||||||||
| SpanKPE | 24.63 | 25.13 | 24.91 | 25.52 | 22.02 | 25.35 | 26.17 | 26.29 | 26.00 | 28.19 | 26.48 | 29.56 |
| TagKPE | 26.22 | 26.57 | 26.38 | 27.43 | 21.54 | 25.82 | 26.02 | 26.59 | 25.86 | 27.16 | 26.63 | 29.13 |
| ChunkKPE | 21.37 | 21.50 | 21.23 | 22.30 | 18.57 | 20.97 | 20.54 | 20.80 | 24.56 | 26.11 | 24.08 | 26.85 |
| RankKPE | 25.56 | 26.05 | 26.15 | 26.88 | 16.47 | 20.58 | 22.59 | 22.06 | 25.18 | 26.57 | 26.34 | 27.78 |
| JointKPE | 26.68 | 27.04 | 27.11 | 27.68 | 18.23 | 21.69 | 23.23 | 23.02 | 25.43 | 26.42 | 25.76 | 27.81 |
| HyperMatch | 25.23 | 25.70 | 26.01 | 26.65 | 16.94 | 21.11 | 23.37 | 23.26 | 24.50 | 26.08 | 25.60 | 27.16 |
| LongKey | 29.90 | 30.52 | 30.20 | 31.33 | 22.26 | 25.77 | 26.61 | 26.79 | 27.93 | 29.20 | 28.06 | 30.34 |
🔼 This table presents the performance of various keyphrase extraction methods on six unseen datasets. The models were pre-trained on either the LDKP3K or LDKP10K datasets. The table shows F1 scores (harmonic mean of precision and recall) for different numbers of top keyphrases (K=4, 5, 6, and the best K). The best performing method for each dataset and K value is highlighted in bold. The results demonstrate the generalizability and domain adaptation capabilities of the models trained on the LDKP datasets to other, unseen datasets.
read the caption
TABLE II: Results obtained in unseen datasets with models trained on LDKP3K and LDKP10K training subsets. Values in %. Best scores, for each K and dataset, are in bold. Best scores only in a specific section are underlined. * GELF scores were reported in its paper without a specific K value.
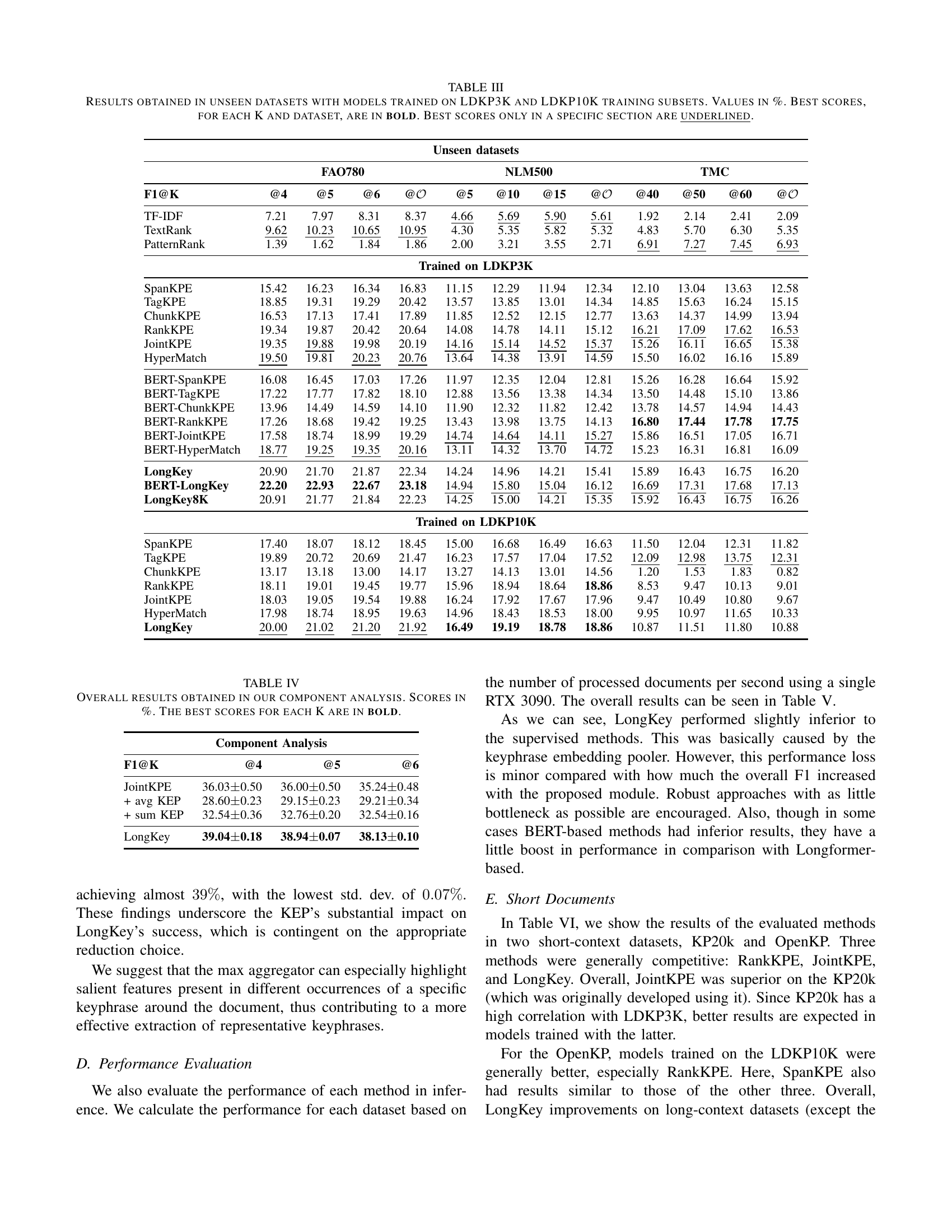
| FAO780@4 | FAO780@5 | FAO780@6 | FAO780@O | NLM500@5 | NLM500@10 | NLM500@15 | NLM500@O | TMC@40 | TMC@50 | TMC@60 | TMC@O | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1@K | ||||||||||||
| TF-IDF | 7.21 | 7.97 | 8.31 | 8.37 | 4.66 | 5.69 | 5.90 | 5.61 | 1.92 | 2.14 | 2.41 | 2.09 |
| TextRank | 9.62 | 10.23 | 10.65 | 10.95 | 4.30 | 5.35 | 5.82 | 5.32 | 4.83 | 5.70 | 6.30 | 5.35 |
| PatternRank | 1.39 | 1.62 | 1.84 | 1.86 | 2.00 | 3.21 | 3.55 | 2.71 | 6.91 | 7.27 | 7.45 | 6.93 |
| Trained on LDKP3K | ||||||||||||
| SpanKPE | 15.42 | 16.23 | 16.34 | 16.83 | 11.15 | 12.29 | 11.94 | 12.34 | 12.10 | 13.04 | 13.63 | 12.58 |
| TagKPE | 18.85 | 19.31 | 19.29 | 20.42 | 13.57 | 13.85 | 13.01 | 14.34 | 14.85 | 15.63 | 16.24 | 15.15 |
| ChunkKPE | 16.53 | 17.13 | 17.41 | 17.89 | 11.85 | 12.52 | 12.15 | 12.77 | 13.63 | 14.37 | 14.99 | 13.94 |
| RankKPE | 19.34 | 19.87 | 20.42 | 20.64 | 14.08 | 14.78 | 14.11 | 15.12 | 16.21 | 17.09 | 17.62 | 16.53 |
| JointKPE | 19.35 | 19.88 | 19.98 | 20.19 | 14.16 | 15.14 | 14.52 | 15.37 | 15.26 | 16.11 | 16.65 | 15.38 |
| HyperMatch | 19.50 | 19.81 | 20.23 | 20.76 | 13.64 | 14.38 | 13.91 | 14.59 | 15.50 | 16.02 | 16.16 | 15.89 |
| BERT-SpanKPE | 16.08 | 16.45 | 17.03 | 17.26 | 11.97 | 12.35 | 12.04 | 12.81 | 15.26 | 16.28 | 16.64 | 15.92 |
| BERT-TagKPE | 17.22 | 17.77 | 17.82 | 18.10 | 12.88 | 13.56 | 13.38 | 14.34 | 13.50 | 14.48 | 15.10 | 13.86 |
| BERT-ChunkKPE | 13.96 | 14.49 | 14.59 | 14.10 | 11.90 | 12.32 | 11.82 | 12.42 | 13.78 | 14.57 | 14.94 | 14.43 |
| BERT-RankKPE | 17.26 | 18.68 | 19.42 | 19.25 | 13.43 | 13.98 | 13.75 | 14.13 | 16.80 | 17.44 | 17.78 | 17.75 |
| BERT-JointKPE | 17.58 | 18.74 | 18.99 | 19.29 | 14.74 | 14.64 | 14.11 | 15.27 | 15.86 | 16.51 | 17.05 | 16.71 |
| BERT-HyperMatch | 18.77 | 19.25 | 19.35 | 20.16 | 13.11 | 14.32 | 13.70 | 14.72 | 15.23 | 16.31 | 16.81 | 16.09 |
| LongKey | 20.90 | 21.70 | 21.87 | 22.34 | 14.24 | 14.96 | 14.21 | 15.41 | 15.89 | 16.43 | 16.75 | 16.20 |
| BERT-LongKey | 22.20 | 22.93 | 22.67 | 23.18 | 14.94 | 15.80 | 15.04 | 16.12 | 16.69 | 17.31 | 17.68 | 17.13 |
| LongKey8K | 20.91 | 21.77 | 21.84 | 22.23 | 14.25 | 15.00 | 14.21 | 15.35 | 15.92 | 16.43 | 16.75 | 16.26 |
| Trained on LDKP10K | ||||||||||||
| SpanKPE | 17.40 | 18.07 | 18.12 | 18.45 | 15.00 | 16.68 | 16.49 | 16.63 | 11.50 | 12.04 | 12.31 | 11.82 |
| TagKPE | 19.89 | 20.72 | 20.69 | 21.47 | 16.23 | 17.57 | 17.04 | 17.52 | 12.09 | 12.98 | 13.75 | 12.31 |
| ChunkKPE | 13.17 | 13.18 | 13.00 | 14.17 | 13.27 | 14.13 | 13.01 | 14.56 | 1.20 | 1.53 | 1.83 | 0.82 |
| RankKPE | 18.11 | 19.01 | 19.45 | 19.77 | 15.96 | 18.94 | 18.64 | 18.86 | 8.53 | 9.47 | 10.13 | 9.01 |
| JointKPE | 18.03 | 19.05 | 19.54 | 19.88 | 16.24 | 17.92 | 17.67 | 17.96 | 9.47 | 10.49 | 10.80 | 9.67 |
| HyperMatch | 17.98 | 18.74 | 18.95 | 19.63 | 14.96 | 18.43 | 18.53 | 18.00 | 9.95 | 10.97 | 11.65 | 10.33 |
| LongKey | 20.00 | 21.02 | 21.20 | 21.92 | 16.49 | 19.19 | 18.78 | 18.86 | 10.87 | 11.51 | 11.80 | 10.88 |
🔼 This table presents the performance of various keyphrase extraction models on six unseen datasets. The models were pre-trained on either the LDKP3K or LDKP10K datasets. The table shows the F1-score (a measure of accuracy balancing precision and recall) for different numbers of predicted keyphrases (K) for each model and dataset. Higher F1-scores indicate better performance. The best scores for each dataset and K-value are highlighted in bold, while the best scores within specific training conditions (LDKP3K or LDKP10K) are underlined. This demonstrates the models’ generalizability and robustness across diverse domains and text lengths.
read the caption
TABLE III: Results obtained in unseen datasets with models trained on LDKP3K and LDKP10K training subsets. Values in %. Best scores, for each K and dataset, are in bold. Best scores only in a specific section are underlined.
| Component Analysis | |||
|---|---|---|---|
| F1@K | @4 | @5 | @6 |
| JointKPE | 36.03 ± 0.50 | 36.00 ± 0.50 | 35.24 ± 0.48 |
| + avg KEP | 28.60 ± 0.23 | 29.15 ± 0.23 | 29.21 ± 0.34 |
| + sum KEP | 32.54 ± 0.36 | 32.76 ± 0.20 | 32.54 ± 0.16 |
| LongKey | 39.04 ± 0.18 | 38.94 ± 0.07 | 38.13 ± 0.10 |
🔼 This table presents a component analysis of the keyphrase embedding pooler (KEP) within the LongKey model. It shows the average F1@K scores (for K=4, 5, 6) achieved using different aggregation functions within the KEP: average, sum, and maximum. The results are compared against the performance of the original JointKPE model without the enhanced KEP. This analysis helps to evaluate the contribution of the KEP and the effectiveness of different aggregation methods for improving keyphrase extraction accuracy.
read the caption
TABLE IV: Overall results obtained in our component analysis. Scores in %. The best scores for each K are in bold.
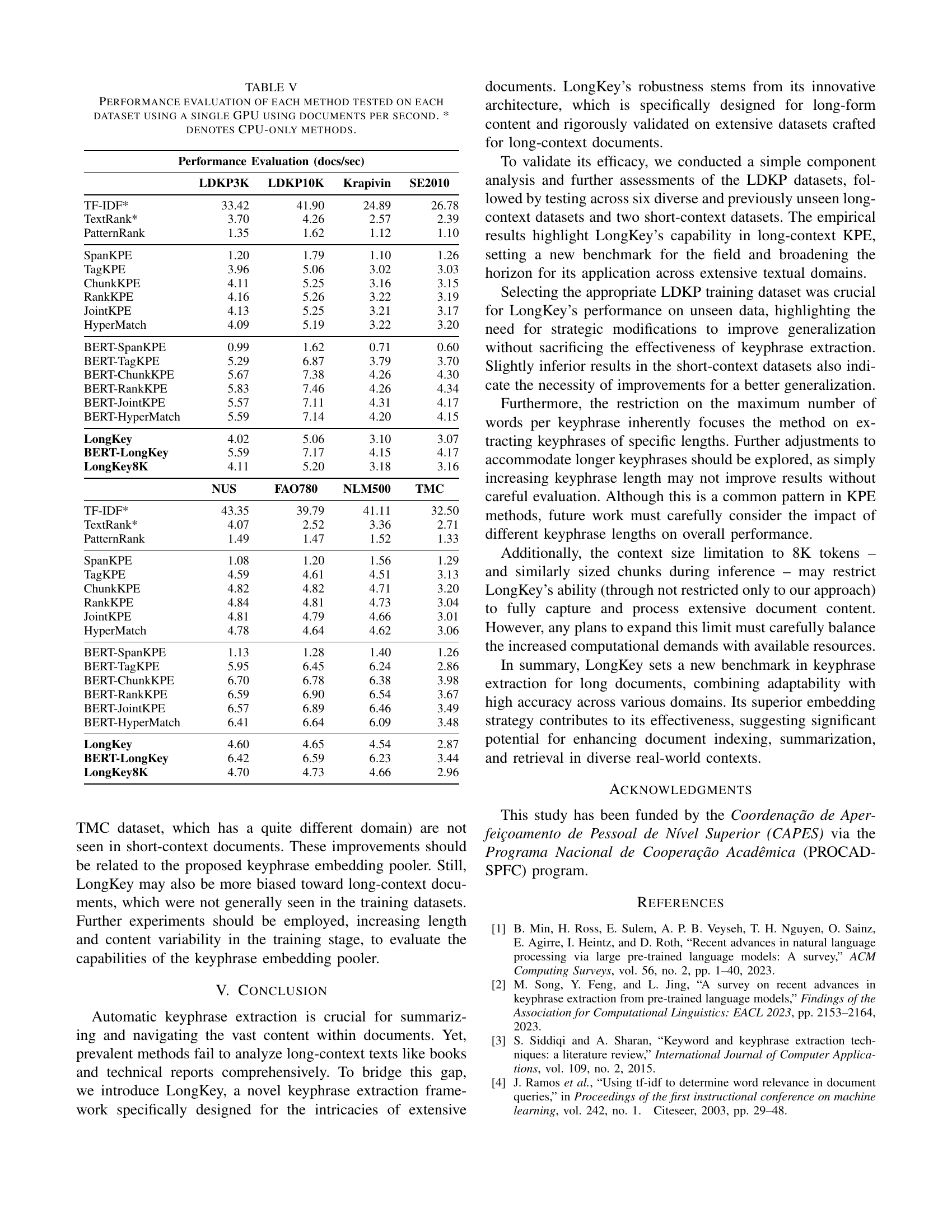
| Performance Evaluation (docs/sec) | LDKP3K | LDKP10K | Krapivin | SE2010 |
|---|---|---|---|---|
| TF-IDF* | 33.42 | 41.90 | 24.89 | 26.78 |
| TextRank* | 3.70 | 4.26 | 2.57 | 2.39 |
| PatternRank | 1.35 | 1.62 | 1.12 | 1.10 |
| SpanKPE | 1.20 | 1.79 | 1.10 | 1.26 |
| TagKPE | 3.96 | 5.06 | 3.02 | 3.03 |
| ChunkKPE | 4.11 | 5.25 | 3.16 | 3.15 |
| RankKPE | 4.16 | 5.26 | 3.22 | 3.19 |
| JointKPE | 4.13 | 5.25 | 3.21 | 3.17 |
| HyperMatch | 4.09 | 5.19 | 3.22 | 3.20 |
| BERT-SpanKPE | 0.99 | 1.62 | 0.71 | 0.60 |
| BERT-TagKPE | 5.29 | 6.87 | 3.79 | 3.70 |
| BERT-ChunkKPE | 5.67 | 7.38 | 4.26 | 4.30 |
| BERT-RankKPE | 5.83 | 7.46 | 4.26 | 4.34 |
| BERT-JointKPE | 5.57 | 7.11 | 4.31 | 4.17 |
| BERT-HyperMatch | 5.59 | 7.14 | 4.20 | 4.15 |
| LongKey | 4.02 | 5.06 | 3.10 | 3.07 |
| BERT-LongKey | 5.59 | 7.17 | 4.15 | 4.17 |
| LongKey8K | 4.11 | 5.20 | 3.18 | 3.16 |
| NUS | FAO780 | NLM500 | TMC | |
| — | — | — | — | — |
| TF-IDF* | 43.35 | 39.79 | 41.11 | 32.50 |
| TextRank* | 4.07 | 2.52 | 3.36 | 2.71 |
| PatternRank | 1.49 | 1.47 | 1.52 | 1.33 |
| SpanKPE | 1.08 | 1.20 | 1.56 | 1.29 |
| TagKPE | 4.59 | 4.61 | 4.51 | 3.13 |
| ChunkKPE | 4.82 | 4.82 | 4.71 | 3.20 |
| RankKPE | 4.84 | 4.81 | 4.73 | 3.04 |
| JointKPE | 4.81 | 4.79 | 4.66 | 3.01 |
| HyperMatch | 4.78 | 4.64 | 4.62 | 3.06 |
| BERT-SpanKPE | 1.13 | 1.28 | 1.40 | 1.26 |
| BERT-TagKPE | 5.95 | 6.45 | 6.24 | 2.86 |
| BERT-ChunkKPE | 6.70 | 6.78 | 6.38 | 3.98 |
| BERT-RankKPE | 6.59 | 6.90 | 6.54 | 3.67 |
| BERT-JointKPE | 6.57 | 6.89 | 6.46 | 3.49 |
| BERT-HyperMatch | 6.41 | 6.64 | 6.09 | 3.48 |
| LongKey | 4.60 | 4.65 | 4.54 | 2.87 |
| BERT-LongKey | 6.42 | 6.59 | 6.23 | 3.44 |
| LongKey8K | 4.70 | 4.73 | 4.66 | 2.96 |
🔼 This table presents the processing speed (documents per second) of various keyphrase extraction methods on seven datasets using a single GPU. The methods include both unsupervised techniques and those fine-tuned on the LDKP datasets. The asterisk (*) indicates methods that utilize only the CPU.
read the caption
TABLE V: Performance evaluation of each method tested on each dataset using a single GPU using documents per second. * denotes CPU-only methods.
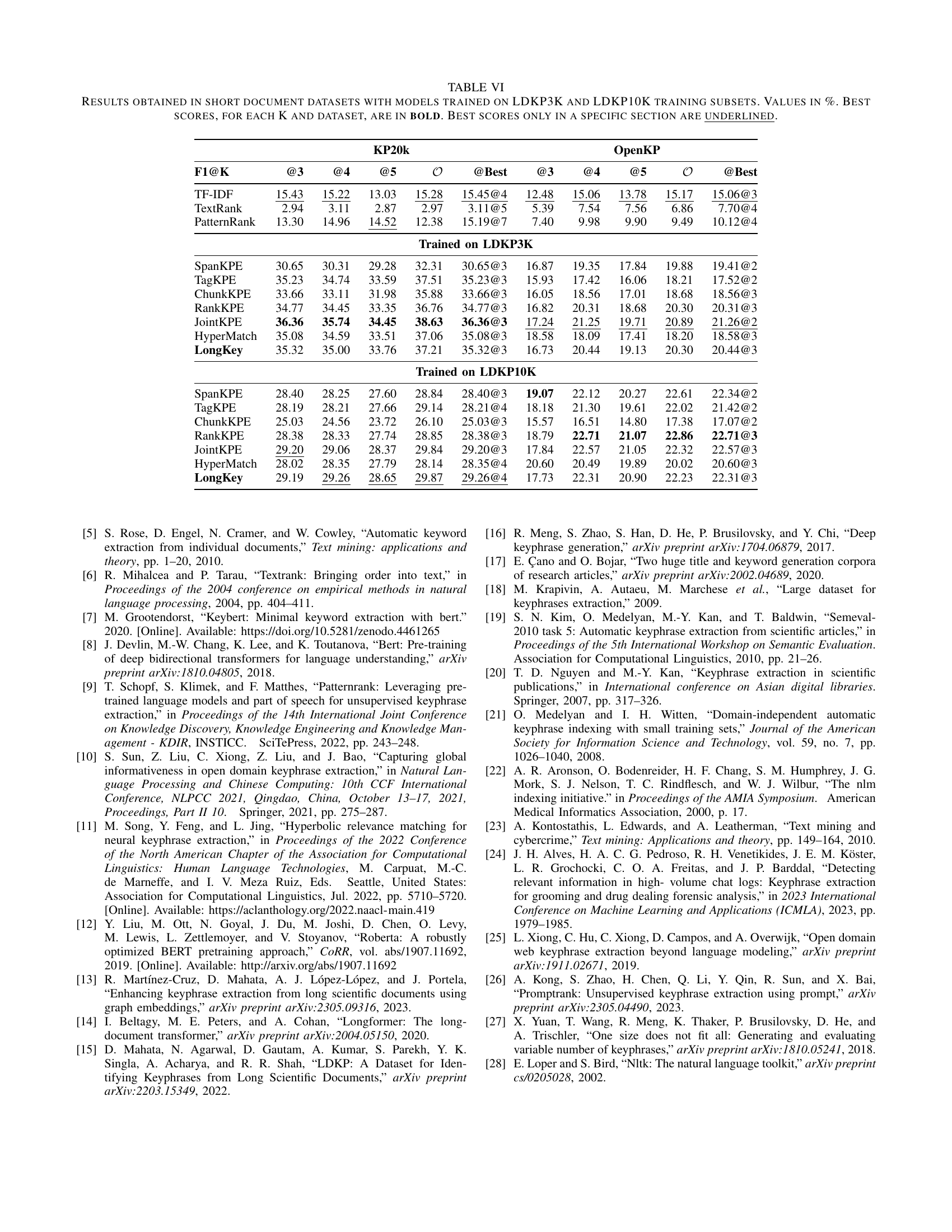
| mathcal{O}$ | OpenKP@Best | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| TF-IDF | 15.43 | 15.22 | 13.03 | 15.28 | 15.45@4 | 12.48 | 15.06 | 13.78 | 15.17 | 15.06@3 |
| TextRank | 2.94 | 3.11 | 2.87 | 2.97 | 3.11@5 | 5.39 | 7.54 | 7.56 | 6.86 | 7.70@4 |
| PatternRank | 13.30 | 14.96 | 14.52 | 12.38 | 15.19@7 | 7.40 | 9.98 | 9.90 | 9.49 | 10.12@4 |
| Trained on LDKP3K | ||||||||||
| SpanKPE | 30.65 | 30.31 | 29.28 | 32.31 | 30.65@3 | 16.87 | 19.35 | 17.84 | 19.88 | 19.41@2 |
| TagKPE | 35.23 | 34.74 | 33.59 | 37.51 | 35.23@3 | 15.93 | 17.42 | 16.06 | 18.21 | 17.52@2 |
| ChunkKPE | 33.66 | 33.11 | 31.98 | 35.88 | 33.66@3 | 16.05 | 18.56 | 17.01 | 18.68 | 18.56@3 |
| RankKPE | 34.77 | 34.45 | 33.35 | 36.76 | 34.77@3 | 16.82 | 20.31 | 18.68 | 20.30 | 20.31@3 |
| JointKPE | 36.36 | 35.74 | 34.45 | 38.63 | 36.36@3 | 17.24 | 21.25 | 19.71 | 20.89 | 21.26@2 |
| HyperMatch | 35.08 | 34.59 | 33.51 | 37.06 | 35.08@3 | 18.58 | 18.09 | 17.41 | 18.20 | 18.58@3 |
| LongKey | 35.32 | 35.00 | 33.76 | 37.21 | 35.32@3 | 16.73 | 20.44 | 19.13 | 20.30 | 20.44@3 |
| Trained on LDKP10K | ||||||||||
| SpanKPE | 28.40 | 28.25 | 27.60 | 28.84 | 28.40@3 | 19.07 | 22.12 | 20.27 | 22.61 | 22.34@2 |
| TagKPE | 28.19 | 28.21 | 27.66 | 29.14 | 28.21@4 | 18.18 | 21.30 | 19.61 | 22.02 | 21.42@2 |
| ChunkKPE | 25.03 | 24.56 | 23.72 | 26.10 | 25.03@3 | 15.57 | 16.51 | 14.80 | 17.38 | 17.07@2 |
| RankKPE | 28.38 | 28.33 | 27.74 | 28.85 | 28.38@3 | 18.79 | 22.71 | 21.07 | 22.86 | 22.71@3 |
| JointKPE | 29.20 | 29.06 | 28.37 | 29.84 | 29.20@3 | 17.84 | 22.57 | 21.05 | 22.32 | 22.57@3 |
| HyperMatch | 28.02 | 28.35 | 27.79 | 28.14 | 28.35@4 | 20.60 | 20.49 | 19.89 | 20.02 | 20.60@3 |
| LongKey | 29.19 | 29.26 | 28.65 | 29.87 | 29.26@4 | 17.73 | 22.31 | 20.90 | 22.23 | 22.31@3 |
🔼 This table presents the performance comparison of different keyphrase extraction methods on two short-document datasets: KP20k and OpenKP. The models were trained on either the LDKP3K or LDKP10K datasets. The table shows the F1-score (a measure of accuracy combining precision and recall) for each method at different values of K (the number of top keyphrases considered). The best F1-score for each K and dataset is highlighted in bold, with underlined scores indicating the best performance within a specific training dataset (LDKP3K or LDKP10K). This allows for assessment of how well different models perform on short texts, particularly considering that they were trained on longer documents.
read the caption
TABLE VI: Results obtained in short document datasets with models trained on LDKP3K and LDKP10K training subsets. Values in %. Best scores, for each K and dataset, are in bold. Best scores only in a specific section are underlined.
Full paper#