↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-3D (T23D) content creation struggles with limited, low-quality datasets and computationally expensive methods. The lack of high-fidelity, detailed 3D annotations severely restricts the development of advanced T23D models, particularly for complex scenes. Existing datasets are small, lack diversity and have insufficient annotation depth.
This paper introduces MARVEL-40M+, a novel dataset with 40 million high-quality annotations spanning seven major 3D datasets. These multi-level annotations support both fine-grained and abstract 3D modeling. The paper also presents MARVEL-FX3D, a two-stage pipeline for generating textured 3D meshes from text in 15 seconds using fine-tuned Stable Diffusion and a pretrained image-to-3D network. Results show that MARVEL-40M+ significantly surpasses existing datasets and MARVEL-FX3D outperforms current state-of-the-art T23D methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and AI because it introduces MARVEL-40M+, a massive, high-quality dataset for text-to-3D generation, addressing the limitations of existing datasets. It also presents MARVEL-FX3D, a novel two-stage pipeline for high-fidelity text-to-3D that is significantly faster than existing approaches. This opens up exciting new avenues for research into more realistic and efficient 3D content creation from textual descriptions.
Visual Insights#

🔼 This figure showcases the capabilities of the MARVEL annotation pipeline and the MARVEL-FX3D text-to-3D pipeline. The left panel displays examples of high-quality, domain-specific, and multi-level text descriptions automatically generated for various 3D assets using the MARVEL pipeline. These descriptions range in detail from brief semantic tags to detailed descriptions (~200 words) that encompass object names, shapes, materials, colors, contextual environments, etc. The descriptions are tailored to facilitate both rapid prototyping and fine-grained 3D reconstruction. The right panel presents qualitative results from the MARVEL-FX3D pipeline. This two-stage pipeline is able to create textured 3D meshes from text prompts in just 15 seconds. The image shows examples of 3D models generated by MARVEL-FX3D, demonstrating the quality and detail achievable using this novel approach. The images are diverse in subject matter and style, suggesting the versatility of the method.
read the caption
Figure 1: Left: Examples of MARVEL annotations created using our proposed pipeline, which produces high-quality, domain-specific and multi-level text descriptions for 3D assets (Sec 3.1). Right: Qualitative results from MARVEL-FX3D, our two-stage text-to-3D pipeline, which can generate textured mesh from text within 15s (Sec 3.3). Please zoom in for details.
| Dataset | ShapeNet | Pix3D | OmniObject3D | Toys4K | GSO | ABO | Objaverse | Objaverse-XL | Total 3D Objects | Total Captions |
|---|---|---|---|---|---|---|---|---|---|---|
| Cap3D [53] | ✗ | ✗ | ✗ | ✗ | ✗ | 6,400 [52] | 785,150 | 221,632 | 1,013,182 | 1,013,182 |
| 3DTopia [28] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 361,357 | ✗ | 361,357 | 361,357 |
| Kabra [34] | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | 763,827 | ✗ | 763,827 | 763,827 |
| MARVEL | 51,209 | 735 | 5,878 | 4,000 | 1,030 | 7,953 | 798,759 | 8,031,637 | 8,901,201 | 44,506,005 |
🔼 Table 1 presents a comprehensive comparison of various 3D datasets used for annotation, highlighting the scale and scope of the MARVEL-40M+ dataset. It shows the number of 3D objects and captions in each dataset, demonstrating that MARVEL-40M+ significantly surpasses existing datasets in terms of the sheer volume of annotated 3D assets and their associated text descriptions. This larger scale and annotation depth are crucial for training high-fidelity text-to-3D models.
read the caption
Table 1: Overview of datasets [10, 74, 80, 73, 20, 16, 18, 17] annotated using our MARVEL pipeline. MARVEL provides the most extensive 3D asset annotations to date, encompassing over 8.98.98.98.9M 3D objects and 40404040M captions.
In-depth insights#
Multi-Level Annotation#
The concept of “Multi-Level Annotation” in the context of a text-to-3D generation research paper suggests a paradigm shift in data annotation. Instead of relying on single, monolithic descriptions, this approach proposes generating annotations at various levels of detail. This strategy likely involves a hierarchical structure, starting with highly detailed descriptions that capture granular visual and semantic information. These detailed descriptions would then be progressively compressed into increasingly abstract levels: moderately descriptive, functional-semantic, summary, and finally semantic tokens. This multi-level approach offers several advantages. Firstly, it allows for flexibility, catering to different downstream tasks. High-fidelity 3D reconstruction may benefit from detailed descriptions, while rapid prototyping may only require semantic tokens. Secondly, it increases the linguistic diversity of the dataset, enhancing the model’s ability to understand and generate varied descriptions. Finally, this methodology potentially tackles the limitations of previous methods by providing descriptions that are both contextually rich and scalable.
MARVEL-FX3D Pipeline#
The MARVEL-FX3D pipeline is a two-stage text-to-3D generation pipeline that leverages the MARVEL-40M+ dataset. The first stage involves fine-tuning a pre-trained text-to-image model, such as Stable Diffusion, using the high-quality, multi-level annotations from MARVEL-40M+. This fine-tuning step is crucial for bridging the gap between 2D image generation and 3D reconstruction. The second stage uses a pre-trained image-to-3D model (like Stable Fast 3D) to convert the generated images into textured 3D meshes. This two-stage approach is key to achieving high fidelity and speed. The pipeline’s efficiency is highlighted, generating textured meshes in just 15 seconds. This speed is a significant improvement over existing methods. The integration of human metadata into the annotation pipeline helps reduce hallucinations by providing domain-specific information to the model. Overall, the MARVEL-FX3D pipeline represents a significant advance in text-to-3D generation, demonstrating both high fidelity and speed.
High-Fidelity TT3D#
High-fidelity Text-to-3D (TT3D) content generation is a challenging research area that aims to create realistic and detailed 3D models from textual descriptions. The core challenge lies in bridging the semantic gap between text and 3D geometry, requiring sophisticated techniques to accurately represent shapes, textures, colors, and spatial relationships. High-fidelity in this context implies generating models with fine-grained details, realistic textures, and accurate representations of the described scene, going beyond simple shape generation. Achieving this level of fidelity necessitates large, high-quality datasets with detailed annotations, which are currently scarce. The development of effective multi-modal models capable of understanding nuanced textual prompts and translating them into complex 3D structures is another crucial aspect. Furthermore, computational efficiency is essential for practical applications; the generation process should be sufficiently fast to enable interactive experiences. Finally, evaluation of high-fidelity TT3D systems requires rigorous benchmarks, capable of assessing not only geometric accuracy but also the realism and overall quality of the generated models.
Dataset Evaluation#
A robust dataset evaluation is crucial for assessing the quality and utility of any newly introduced dataset, especially in the rapidly evolving field of 3D content generation. This evaluation should go beyond simple quantitative metrics and delve into qualitative aspects, comparing it to existing datasets to highlight improvements and address shortcomings. Key aspects of the evaluation could include linguistic analysis (measuring diversity and richness of textual descriptions using metrics like MTLD and N-gram analysis), image-text alignment (assessing how well captions match visual content via human and automated evaluations), and caption accuracy (evaluating the correctness and precision of descriptions using human evaluators and metrics like GPT-4). The evaluation should also consider the dataset’s scale and diversity (comparing dataset size and variety of 3D assets). By conducting a thorough and multi-faceted evaluation, researchers can establish the dataset’s strengths and limitations, guiding future research in 3D captioning and text-to-3D content creation. Careful attention should be paid to the limitations of the evaluation methods and any potential biases. This helps build trust in the dataset and ensure it supports reliable and robust AI applications.
Future Directions#
Future research should prioritize expanding MARVEL-40M+’s scope by incorporating a wider variety of 3D assets and more nuanced annotation levels. Addressing current limitations in handling complex scenes and thin objects will improve annotation accuracy. Exploring advanced VLM and LLM architectures could lead to enhanced caption quality and efficiency. Furthermore, developing more robust and scalable text-to-3D pipelines, ideally surpassing the 15-second processing time, is crucial. Investigating alternative image-to-3D approaches could enhance the fidelity of 3D model generation. Finally, a focus on ethical considerations and bias mitigation within the pipeline will guarantee responsible dataset application.
More visual insights#
More on figures

🔼 Figure 2 illustrates the MARVEL annotation pipeline and the MARVEL-FX3D text-to-3D pipeline. The left panel details the multi-stage MARVEL annotation pipeline. It starts by leveraging human metadata and multi-view renderings of 3D assets to produce detailed descriptions using the InternVL-2 VLM. These descriptions encompass object names, shapes, textures, colors, and environmental contexts. The Qwen-2 LLM then processes these descriptions, generating five hierarchical levels of annotations. Each level provides increasingly concise descriptions of the 3D assets, ranging from comprehensive descriptions to simple semantic tags. The right panel showcases the two-stage MARVEL-FX3D text-to-3D pipeline. It fine-tunes Stable Diffusion 3.5 with the generated annotations and uses the pretrained SF3D model for rapid image-to-3D conversion, generating textured meshes from text within 15 seconds.
read the caption
Figure 2: Left: MARVEL annotation pipeline for 3D assets. Our pipeline starts with human metadata [18, 17] and rendered multi-view images to create detailed visual descriptions using InternVL-2 [13]. These contain object names, shapes, textures, colors, and environments. Qwen2 [85] then processes these descriptions into five hierarchical levels, progressively compressing different aspects of the 3D assets. Right: Our Text-to-3D pipeline finetunes SD 3.5 [21, 3] with this dataset and uses pretrained SF3D [7] to generate a textured mesh in 15s .

🔼 Figure 3 presents a qualitative comparison of 3D model annotations from four different methods: Cap3D, 3DTopia, Kabra, and MARVEL. For each method, example annotations for four distinct 3D models are displayed, along with an evaluation by GPT-4. The figure showcases that MARVEL’s Level-4 annotations are significantly more comprehensive and detailed than those produced by the other methods. MARVEL captures intricate aspects, including object names, colors, shapes, textures, and specific attributes, while the other methods frequently miss key details or provide inaccurate descriptions. The red highlighting indicates instances where annotations incorrectly describe the image.
read the caption
Figure 3: Qualitative Annotation Comparison: From top to bottom Cap3D [53], 3DTopia [28], Kabra [34], MARVEL (Level-4) annotations and GPT-4 [60] evaluation. MARVEL consistently provides the most comprehensive and precise annotations, capturing intricate details such as object names, color, structure, and specific attributes. Red is for wrong captions.

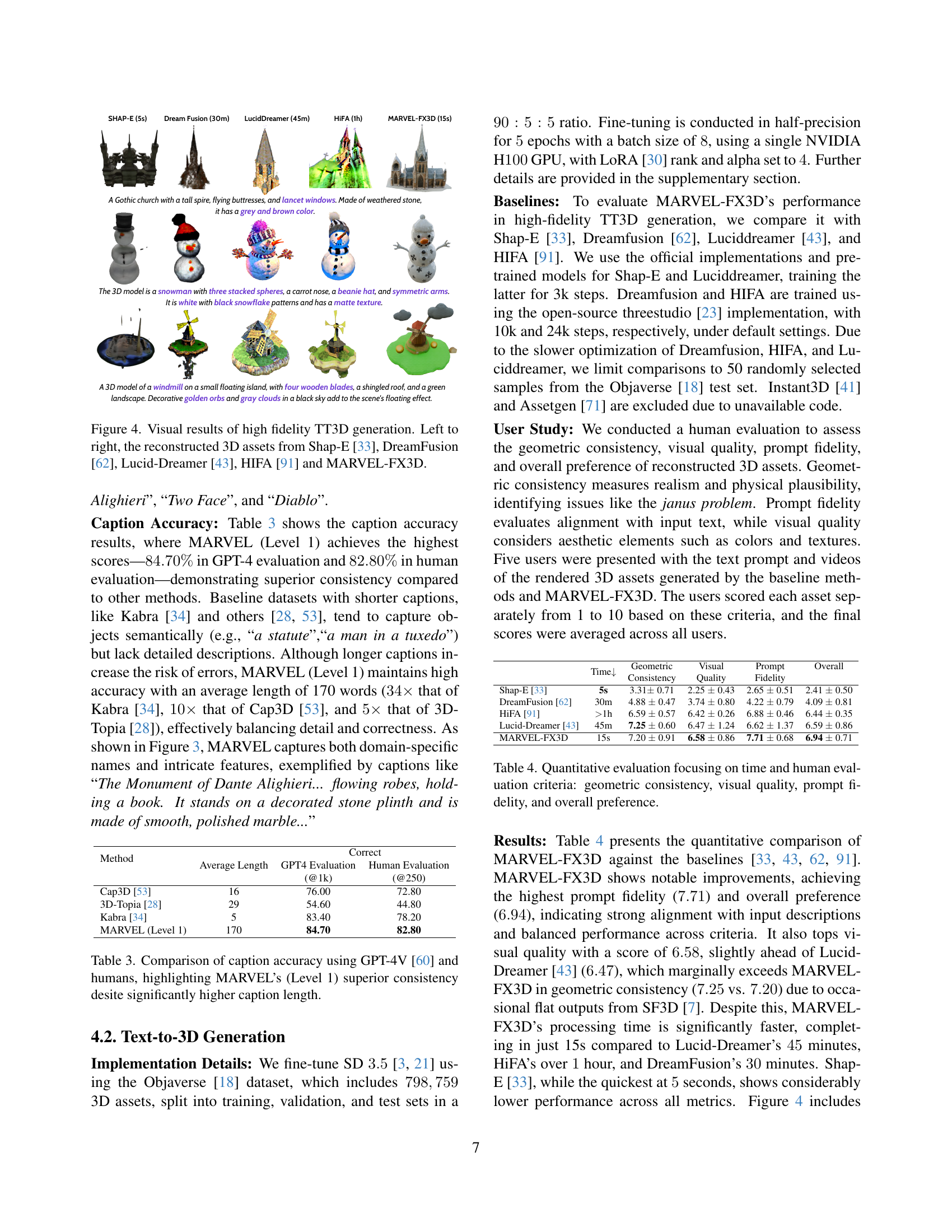
🔼 Figure 4 presents a comparison of 3D model generation results from five different text-to-3D methods: Shap-E, DreamFusion, LucidDreamer, HIFA, and MARVEL-FX3D. Each method is given the same text prompt, and the resulting 3D model is shown. This allows for a visual comparison of the fidelity and quality of the 3D models generated by each approach. The figure demonstrates the relative strengths and weaknesses of each method in terms of detail, texture, geometry accuracy, and overall visual appeal.
read the caption
Figure 4: Visual results of high fidelity TT3D generation. Left to right, the reconstructed 3D assets from Shap-E [33], DreamFusion [62], Lucid-Dreamer [43], HIFA [91] and MARVEL-FX3D.

🔼 Figure 5 presents a comparative analysis of caption generation using various models, highlighting the impact of incorporating human-generated metadata. The figure shows that MARVEL, by integrating this metadata, generates highly detailed and accurate captions which include domain-specific information (e.g., names of lunar craters). In contrast, models like GPT-4 and InternVL2, which do not use metadata, produce descriptions that are vague and speculative.
read the caption
Figure 5: MARVEL uses human-generated metadata from source datasets to create detailed, accurate captions (e.g., names of the lunar craters, detection of human footprints) and reduce hallucinations. Without metadata, VLMs like GPT-4 [60] and InternVL2 [15] generate vague or speculative descriptions.

🔼 Figure 6 showcases MARVEL-FX3D’s ability to generate intricate and detailed 3D scenes by combining multiple text prompts. Each prompt focuses on a specific aspect of the scene, such as characters, buildings, or environmental details. The resulting image demonstrates a complex scene with a high level of detail and realism, exceeding what is typically possible with single-prompt 3D generation models. The image is rich and layered, with various objects interacting and visually relating to each other in a natural way. It highlights the potential of combining multiple text descriptions to generate highly detailed and complex 3D content.
read the caption
Figure 6: An example use case of MARVEL-FX3D, demonstrating how multiple prompts can be combined to create a detailed and complex 3D scene, with each prompt contributing specific elements such as characters, structures, and environmental details. Please zoom in for details.

🔼 Figure 7 demonstrates the impact of integrating human-generated metadata into a multi-stage annotation pipeline for 3D models. It compares the descriptive accuracy and contextual relevance of captions generated by state-of-the-art models (GPT-4 and InternVL2) with and without this metadata. The results show that including human metadata significantly improves the quality of annotations by reducing hallucinations and incorporating crucial domain-specific details. This enhancement in caption accuracy and context is particularly noticeable when dealing with complex, domain-specific 3D assets.
read the caption
Figure 7: Effect of including human metadata, highlighting improvements in descriptive accuracy and contextual relevance compared to outputs generated without metadata, even when using state-of-the-art models like GPT-4 [60] and InternVL2 [13]. Metadata inclusion helps reduce hallucinations and enhances domain-specific understanding.

🔼 Figure 8 showcases instances where the MARVEL annotation pipeline encounters challenges. The images illustrate three common types of errors: (1) Counting mistakes, where the generated caption incorrectly counts the number of items in the scene; (2) Object misidentification, where the caption wrongly labels or describes objects within the image; and (3) Difficulties interpreting ambiguous views, where the 3D model’s perspective or the image’s clarity makes accurate annotation challenging.
read the caption
Figure 8: Failure cases of the MARVEL annotation pipeline. From left to right, the examples illustrate errors such as counting mistakes, object misidentification, and challenges with ambiguous views.

🔼 This figure presents a qualitative comparison of 3D annotations generated by three existing methods (Cap3D [53], 3DTopia [28], Kabra [34]) and the new MARVEL-40M+ approach. The comparison focuses specifically on the quality of annotations for 3D models of vehicles and CAD designs. The figure visually demonstrates that MARVEL-40M+ produces more detailed and accurate captions than the baselines. Incorrect annotations from the baseline methods are highlighted in red, while particularly strong or accurate elements in the MARVEL-40M+ annotations are highlighted in green. This allows for a direct visual assessment of the relative strengths and weaknesses of each method in capturing intricate details and domain-specific terminology within 3D model descriptions.
read the caption
Figure 9: Qualitative comparison of 3D annotations across baselines [53, 28, 34] and the proposed MARVEL-40404040M+ for automotive (cars, planes, etc) and CAD models. MARVEL-40M+ provides more accurate and domain-specific annotations, compared to the baselines. Incorrect captions are highlighted in red, while important captions are highlighted in green.

🔼 Figure 10 presents a qualitative comparison of 3D model annotations generated by three existing methods (Cap3D [53], 3DTopia [28], and Kabra et al. [34]) and the novel MARVEL-40M+ approach. The figure uses examples of popular anime, movie, and cartoon characters to showcase the quality of the annotations produced by each method. The annotations from MARVEL-40M+ are shown to be significantly more detailed and accurate, capturing specific characteristics, names, and contextual details that the baseline methods miss. Incorrect annotations from the baselines are highlighted in red, while the superior annotations from MARVEL-40M+ are highlighted in green. This visual comparison demonstrates the advantage of MARVEL-40M+ in generating high-quality, domain-specific annotations for 3D models.
read the caption
Figure 10: Qualitative comparison of 3D annotations across baselines [53, 28, 34] and the proposed MARVEL-40404040M+ for popular anime, movie, and cartoon characters. MARVEL-40M+ provides more accurate and domain-specific annotations, compared to the baselines. Incorrect captions are highlighted in red, while important captions are highlighted in green.

🔼 Figure 11 presents a qualitative comparison of 3D annotations generated by three existing methods (Cap3D [53], 3DTopia [28], and Kabra et al. [34]) and the newly proposed MARVEL-40M+ model. The comparison focuses on annotations for biological objects, including animals, plants, and molecular structures. The figure highlights that MARVEL-40M+ produces more accurate and detailed annotations that better reflect domain-specific characteristics compared to the baselines. Incorrect or inaccurate annotations generated by the baseline methods are marked in red, while especially accurate and insightful annotations generated by MARVEL-40M+ are highlighted in green. This visual comparison demonstrates the improved quality and detail of annotations from the proposed MARVEL-40M+ method.
read the caption
Figure 11: Qualitative comparison of 3D annotations across baselines [53, 28, 34] and the proposed MARVEL-40404040M+ for biological objects, including animals, plants, and molecular models. MARVEL-40M+ provides more accurate and domain-specific annotations, compared to the baselines. Incorrect captions are highlighted in red, while important captions are highlighted in green.

🔼 Figure 12 presents a qualitative comparison of 3D annotations generated by three existing methods (Cap3D [53], 3DTopia [28], and Kabra [34]) and the new MARVEL-40M+ approach. The comparison focuses on diverse everyday items and essential objects. The figure highlights MARVEL-40M+’s improved accuracy and detail in its annotations compared to the baseline methods. Incorrect or insufficient captions from the baseline methods are shown in red, while accurate and detailed MARVEL-40M+ captions are highlighted in green. This visual comparison demonstrates MARVEL-40M+’s superiority in generating high-quality, domain-specific 3D descriptions.
read the caption
Figure 12: Qualitative comparison of 3D annotations across baselines [53, 28, 34] and the proposed MARVEL-40404040M+ for diverse items including daily objects, essentials. MARVEL-40M+ provides more accurate and domain-specific annotations, compared to the baselines. Incorrect captions are highlighted in red, while important captions are highlighted in green.

🔼 Figure 13 presents a qualitative comparison of 3D model annotations generated by different methods: Cap3D [53], 3DTopia [28], Kabra [34], and the proposed MARVEL-40M+. The comparison focuses on historical elements such as statues, places, and memorials. For each 3D model, annotations from each method are shown alongside an evaluation highlighting the accuracy and detail of the description. Incorrect annotations are marked in red, while accurate and complete annotations are highlighted in green. The figure visually demonstrates the superior quality and detail provided by the MARVEL-40M+ annotation pipeline.
read the caption
Figure 13: Qualitative comparison of 3D annotations across baselines [53, 28, 34] and the proposed MARVEL-40404040M+ for historical elements including statues, places, memorials, etc. Incorrect captions are highlighted in red, while important captions are highlighted in green.

🔼 Figure 14 presents a qualitative comparison of 3D annotations generated by three baseline methods (Cap3D [53], 3DTopia [28], Kabra [34]) and the proposed MARVEL-40M+ approach. The comparison focuses on diverse scene types, including digital elevation maps, real-world locations, and both realistic and animated settings. For each scene, the annotations produced by each method are displayed alongside an image of the 3D model, enabling a direct visual assessment of accuracy and detail. Annotations judged as incorrect are highlighted in red, while particularly accurate or important elements are highlighted in green. This allows for a visual evaluation of which model is capable of producing the most comprehensive and precise annotations for these varied scenes.
read the caption
Figure 14: Qualitative comparison of 3D annotations across baselines [53, 28, 34] and the proposed MARVEL-40404040M+ for diverse scenes including digital elevation maps, places, realistic or animated scenes. Incorrect captions are in red, while important captions are in green.

🔼 Figure 15 presents a detailed breakdown of MARVEL’s multi-level annotation process using examples from the Objaverse dataset. Each example showcases five levels of annotation detail, progressing from concise tags (Level 5) to a comprehensive description (Level 1). The visual representation uses color-coding to highlight different aspects of the annotation: object and components (violet), shape and geometry (green), texture and materials (orange), colors (blue), and contextual environment (purple). This figure visually demonstrates how MARVEL generates increasingly detailed and nuanced descriptions of 3D objects at each level.
read the caption
Figure 15: Multi-level annotation examples of MARVEL for the Objaverse [18] dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.

🔼 Figure 16 showcases multi-level annotations generated by the MARVEL pipeline for a subset of the Omni-Object dataset. Each row displays the annotation at a different level of detail, from concise semantic tags (Level 5) to detailed, comprehensive descriptions (Level 1). The annotations are color-coded to highlight different aspects of the 3D model: Object and Components (violet), Shape and Geometry (green), Texture and Materials (orange), Colors (blue), and Contextual Environment (purple). This figure demonstrates the hierarchical nature of MARVEL’s annotation scheme and its ability to generate descriptions ranging from very brief to extremely detailed.
read the caption
Figure 16: Multi-level annotation examples of MARVEL for the Omni-Object [80] dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.

🔼 Figure 17 presents a detailed analysis of MARVEL’s multi-level annotation capabilities using examples from the ShapeNet dataset. Each example shows five levels of annotation detail (from concise tags at Level 5 to comprehensive descriptions at Level 1). The different levels progressively elaborate on the 3D object, starting with basic semantic tags and advancing to detailed descriptions of object components, shapes, materials, colors, and environment. Each level’s text is color-coded to highlight these aspects: Object and Components (violet), Shape and Geometry (green), Texture and Materials (orange), Colors (blue), and Contextual Environment (purple). This visualization effectively demonstrates how MARVEL generates increasingly detailed annotations at each level, illustrating its versatility for diverse 3D modeling applications.
read the caption
Figure 17: Multi-level annotation examples of MARVEL for the ShapeNet [10] dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.

🔼 Figure 18 showcases multi-level annotations generated by the MARVEL pipeline for a subset of the Toys4K dataset. Each row shows the same 3D model (a dinosaur and a dog) with annotations at different levels of detail. Level 5 provides concise semantic tags, while Level 1 offers rich, detailed descriptions. The annotations are color-coded to highlight different aspects: object components (violet), shape and geometry (green), texture and materials (orange), colors (blue), and contextual environment (purple). This figure demonstrates the pipeline’s ability to generate annotations that range from short, keyword-like tags to extensive, descriptive paragraphs, suitable for a variety of downstream tasks.
read the caption
Figure 18: Multi-level annotation examples of MARVEL for the Toys4K dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.

🔼 Figure 19 presents a detailed comparison of multi-level annotations generated by the MARVEL pipeline for a subset of the ABO dataset. Each row showcases a 3D object from the dataset, with five annotation levels provided for each: Level 5 (Concise Tags) offers a brief list of keywords; Level 4 (Summary) gives a short overview; Level 3 (Functional-Semantic Description) provides a basic description; Level 2 (Moderately Descriptive) offers a more detailed description, and Level 1 (Comprehensive Description) gives a comprehensive description. The annotations highlight different aspects of the object: Object and Components are in violet, Shape and Geometry are in green, Texture and Materials are in orange, Colors are in blue, and Contextual Environment is in purple. This visualization demonstrates the hierarchical nature of the MARVEL annotation pipeline and the richness of information captured at each level.
read the caption
Figure 19: Multi-level annotation examples of MARVEL for the ABO (Amazon Berkeley Objects) [16] dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.

🔼 Figure 20 presents a detailed analysis of MARVEL’s multi-level annotation capabilities using examples from the Google Scanned Objects (GSO) dataset. Each example showcases five levels of annotation detail, ranging from concise semantic tags (Level 5) to comprehensive descriptions (Level 1). The visual representation uses color-coding to distinguish the different aspects of each annotation: Object and Components (violet), Shape and Geometry (green), Texture and Materials (orange), Colors (blue), and Contextual Environment (purple). This figure demonstrates how MARVEL annotates 3D objects with increasing levels of detail and richness to support various downstream tasks.
read the caption
Figure 20: Multi-level annotation examples of MARVEL for the GSO (Google Scanned Objects) [20] dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.

🔼 Figure 21 showcases multi-level annotations generated by the MARVEL pipeline for a subset of the Pix3D dataset. Each row presents a different 3D object from the dataset. The annotations are broken down into five levels of detail, ranging from very short semantic tags (Level 5) to a comprehensive description (Level 1). Each level of description includes details about the object’s components, shape, materials, colors, and environment, with the text color-coded to highlight the type of information being conveyed. This figure demonstrates the pipeline’s ability to generate rich and diverse annotations suitable for both quick prototyping and high-fidelity 3D reconstruction.
read the caption
Figure 21: Multi-level annotation examples of MARVEL for the Pix3D [74] dataset. Words corresponding to Object and Components are highlighted in violet, Shape and Geometry in green, Texture and Materials in orange, Colors in blue, and Contextual Environment in purple. From top to bottom, we go from level-5 (Concise Tags) captions to level-1 (Comprehensive Description) captions.
More on tables
| Dataset | Average Length | MTLD[56] (@50K) | Unigram (@50K) | Bi-Gram (@50K) | GPT4 (@5K) | Human (@1K) |
|---|---|---|---|---|---|---|
| Cap3D[53] | 16 | 39.71 | 15,189 | 123,071 | 14.55 | 9.50 |
| 3D-Topia[28] | 29 | 41.43 | 10,329 | 95,856 | 10.80 | 14.00 |
| Kabra[34] | 5 | 25.85 | 3,862 | 19,753 | 2.24 | 3.10 |
| MARVEL (Level 4) | 44 | 47.43 | 27,659 | 239,052 | 72.41 | 73.40 |
🔼 Table 2 presents a quantitative comparison of annotation quality across four different datasets: Cap3D, 3DTopia, Kabra, and MARVEL. The table compares the datasets across several key metrics that evaluate the richness and diversity of the annotations. These metrics include: Average Length (number of words per caption), MTLD (Measure of Textual Lexical Diversity), Unigram (number of unique words), Bigram (number of unique word pairs), GPT-4 rating (percentage of human-quality annotations as rated by GPT-4), and Human Rating (percentage of human-quality annotations as rated by humans). The results show MARVEL significantly outperforming the other datasets in all metrics. This indicates that MARVEL annotations are not only longer but also more linguistically diverse, contain richer vocabulary, and are deemed to be of higher quality by both automated and human evaluations.
read the caption
Table 2: Quantitative comparison of annotation quality across datasets. MARVEL surpasses existing datasets [34, 28, 53] in all metrics, showcasing superior linguistic diversity, vocabulary coverage, and significantly higher ratings from GPT-4 and humans.
| Average | |
|---|---|
| Length |
🔼 This table presents a comparison of caption accuracy results obtained using two different evaluation methods: GPT-4V and human evaluation. The comparison is made across four different datasets, including MARVEL and three baselines (Cap3D, 3DTopia, and Kabra). The metrics presented include the number of correct captions, the average caption length, and the accuracy scores obtained using both GPT-4V and human evaluators. The table highlights MARVEL’s superior consistency in caption accuracy (Level 1) even though its captions are considerably longer than those in the other datasets.
read the caption
Table 3: Comparison of caption accuracy using GPT-4V [60] and humans, highlighting MARVEL’s (Level 1) superior consistency desite significantly higher caption length.
| MTLD [56] |
|---|
🔼 This table presents a quantitative comparison of different text-to-3D generation methods, focusing on both speed and human perception. Four key aspects of the generated 3D models are evaluated: geometric consistency (how realistic and structurally sound the model is), visual quality (the aesthetics of the model), prompt fidelity (how well the model reflects the input text prompt), and overall preference (an overall assessment combining the previous three factors). The results are based on human evaluations comparing MARVEL-FX3D against several leading baselines.
read the caption
Table 4: Quantitative evaluation focusing on time and human evaluation criteria: geometric consistency, visual quality, prompt fidelity, and overall preference.
| Unigram |
|---|
| (@50K) |
🔼 This ablation study investigates the semantic similarity and compression ratio across different levels of annotation in the MARVEL-40M dataset. It evaluates how well the semantic meaning is preserved as annotations are compressed from detailed descriptions (Level 1) to concise semantic tags (Level 5). The results demonstrate strong semantic retention through Levels 1-4, while Level 5 shows reduced detail, highlighting a trade-off between compression and semantic preservation.
read the caption
Table 5: Ablation study results showing SCS across MARVEL-40M levels, illustrating strong semantic retention through Levels 1-4 and reduced detail at Level 5.
Full paper#