↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Vision-language models (VLMs) have shown significant progress in multimodal reasoning, but they still suffer from issues like hallucinations and flawed reasoning paths. These inaccuracies lead to unreliable and often incorrect outputs, especially in complex tasks. This necessitates new approaches that improve VLMs’ reliability and robustness.
The proposed Critic-V framework addresses this by integrating two components: a Reasoner and a Critic. The Reasoner generates reasoning paths, and the Critic refines them via natural language critiques. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked to improve its capacity. Experimental results demonstrate that Critic-V significantly outperforms existing methods on multiple benchmarks, especially in terms of accuracy and efficiency. This highlights the importance of external feedback in improving the reliability of VLMs for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical issue in VLM research: the unreliability of multimodal reasoning. By introducing a novel framework that leverages external critics, the paper proposes a solution that is both effective and efficient. This is particularly relevant given the increasing use of VLMs in real-world applications where high reliability is paramount. The use of DPO for critic training is also significant, suggesting new avenues for improving VLM reasoning, and its open-source nature is invaluable for widespread adoption and further investigation. This framework also presents a promising avenue for improving the performance of other visual-language models.
Visual Insights#

🔼 This figure illustrates the offline training process for the Critic-V model, a key component of the proposed framework. The training leverages a dataset of vision-language model (VLM) responses paired with human-generated critiques. Each response is associated with two critiques: a preferred critique (yᵢʷ) and a disfavored critique (yᵢˡ). The preferred critique represents a higher quality evaluation of the VLM response, while the disfavored critique is considered of lower quality. The Critic model is trained to distinguish between these two types of critiques using Direct Preference Optimization (DPO). This process allows the Critic to learn to provide more constructive and nuanced feedback to improve the accuracy of VLM responses.
read the caption
Figure 1: Offline training of critic model and response supervision for VLM. ywisubscriptsuperscript𝑦𝑖𝑤y^{i}_{w}italic_y start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_w end_POSTSUBSCRIPT is preferred critique and ylisubscriptsuperscript𝑦𝑖𝑙y^{i}_{l}italic_y start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT is disfavored critique.
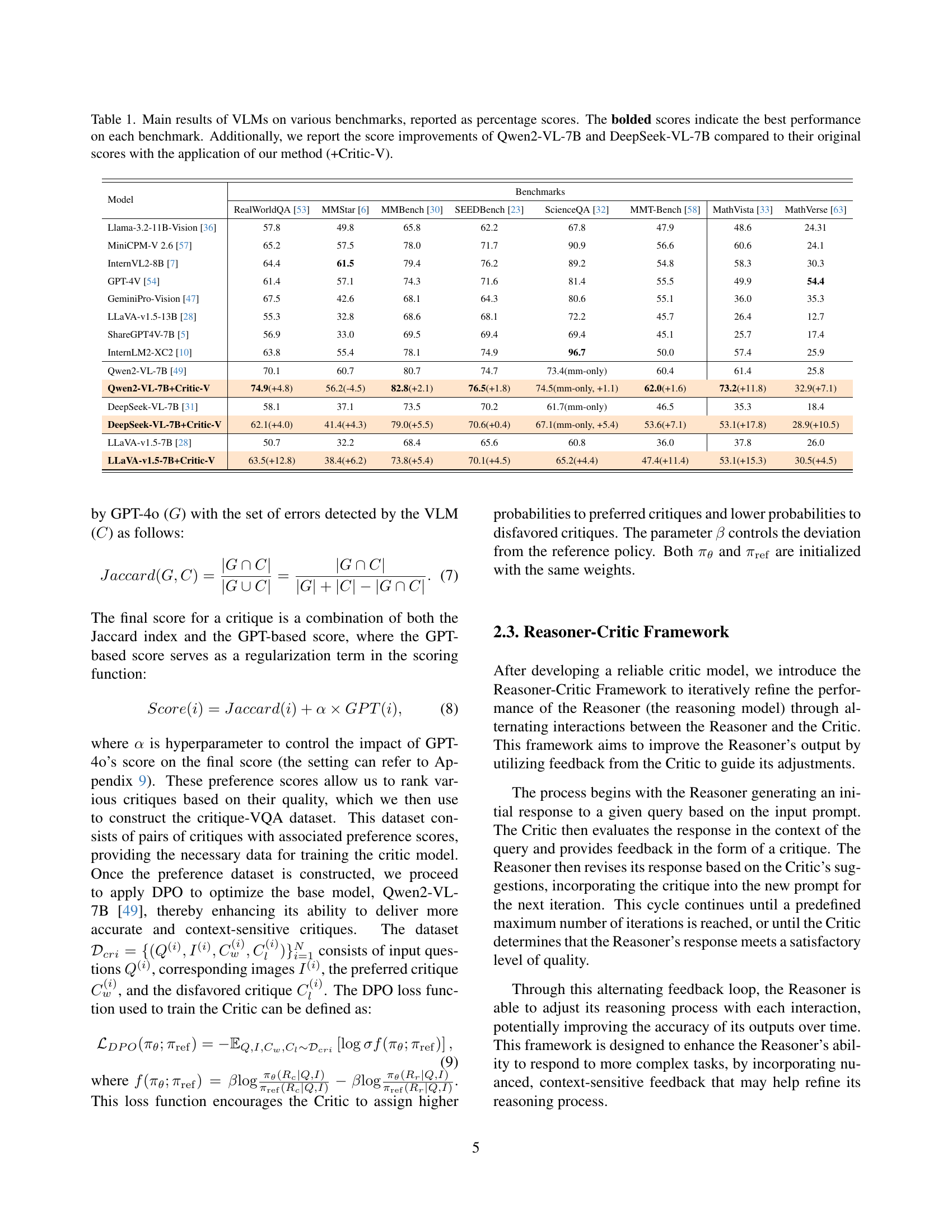
| Model | RealWorldQA [53] | MMStar [6] | MMBench [30] | SEEDBench [23] | ScienceQA [32] | MMT-Bench [58] | MathVista [33] | MathVerse [63] |
|---|---|---|---|---|---|---|---|---|
| Llama-3.2-11B-Vision [36] | 57.8 | 49.8 | 65.8 | 62.2 | 67.8 | 47.9 | 48.6 | 24.31 |
| MiniCPM-V 2.6 [57] | 65.2 | 57.5 | 78.0 | 71.7 | 90.9 | 56.6 | 60.6 | 24.1 |
| InternVL2-8B [7] | 64.4 | 61.5 | 79.4 | 76.2 | 89.2 | 54.8 | 58.3 | 30.3 |
| GPT-4V [54] | 61.4 | 57.1 | 74.3 | 71.6 | 81.4 | 55.5 | 49.9 | 54.4 |
| GeminiPro-Vision [47] | 67.5 | 42.6 | 68.1 | 64.3 | 80.6 | 55.1 | 36.0 | 35.3 |
| LLaVA-v1.5-13B [28] | 55.3 | 32.8 | 68.6 | 68.1 | 72.2 | 45.7 | 26.4 | 12.7 |
| ShareGPT4V-7B [5] | 56.9 | 33.0 | 69.5 | 69.4 | 69.4 | 45.1 | 25.7 | 17.4 |
| InternLM2-XC2 [10] | 63.8 | 55.4 | 78.1 | 74.9 | 96.7 | 50.0 | 57.4 | 25.9 |
| Qwen2-VL-7B [49] | 70.1 | 60.7 | 80.7 | 74.7 | 73.4(mm-only) | 60.4 | 61.4 | 25.8 |
| Qwen2-VL-7B+Critic-V | 74.9(+4.8) | 56.2(-4.5) | 82.8(+2.1) | 76.5(+1.8) | 74.5(mm-only, +1.1) | 62.0(+1.6) | 73.2(+11.8) | 32.9(+7.1) |
| DeepSeek-VL-7B [31] | 58.1 | 37.1 | 73.5 | 70.2 | 61.7(mm-only) | 46.5 | 35.3 | 18.4 |
| DeepSeek-VL-7B+Critic-V | 62.1(+4.0) | 41.4(+4.3) | 79.0(+5.5) | 70.6(+0.4) | 67.1(mm-only, +5.4) | 53.6(+7.1) | 53.1(+17.8) | 28.9(+10.5) |
| LLaVA-v1.5-7B [28] | 50.7 | 32.2 | 68.4 | 65.6 | 60.8 | 36.0 | 37.8 | 26.0 |
| LLaVA-v1.5-7B+Critic-V | 63.5(+12.8) | 38.4(+6.2) | 73.8(+5.4) | 70.1(+4.5) | 65.2(+4.4) | 47.4(+11.4) | 53.1(+15.3) | 30.5(+4.5) |
🔼 This table presents the performance comparison of various Vision-Language Models (VLMs) on eight different benchmark datasets. The results are reported as percentage scores, with the highest score for each benchmark highlighted in bold. The table includes both state-of-the-art closed-source and open-source models, allowing for a comprehensive analysis across different model scales and architectures. Notably, it also shows the performance improvement achieved by applying the Critic-V method to two specific models, Qwen2-VL-7B and DeepSeek-VL-7B, highlighting the effectiveness of the proposed approach.
read the caption
Table 1: Main results of VLMs on various benchmarks, reported as percentage scores. The bolded scores indicate the best performance on each benchmark. Additionally, we report the score improvements of Qwen2-VL-7B and DeepSeek-VL-7B compared to their original scores with the application of our method (+Critic-V).
In-depth insights#
Critic-V Framework#
The Critic-V framework is a novel approach to improve the reasoning capabilities of Vision-Language Models (VLMs) by integrating a critic module. This framework addresses the problem of inaccurate or irrelevant responses from VLMs by incorporating feedback from a critic. The critic provides constructive feedback, refining the reasoning process in real-time. This interaction, inspired by the Actor-Critic paradigm and theoretically driven by a reinforcement learning framework, allows for more nuanced feedback than simple scalar rewards. The Critic-V framework utilizes a Direct Preference Optimization (DPO) approach, training the critic model with a preference dataset where critiques are ranked using a Rule-based Reward (RBR) mechanism. This results in a more reliable and context-sensitive multimodal reasoning process, showing significant improvements over existing methods. The separation of reasoning and criticism into independent modules and the use of natural language feedback significantly enhance the framework’s ability to detect and correct errors in complex reasoning tasks.
DPO-Based Critic#
The DPO-Based Critic section would delve into the methodology of training a critic model using Direct Preference Optimization. This technique is crucial because it enables the critic to learn from comparisons of critique quality rather than from explicit numerical rewards. The advantage of DPO is that it allows for more nuanced and context-aware learning, leading to a more effective critic that can better discriminate between high-quality and low-quality critiques. The section would likely describe the dataset used for training, which would consist of pairs of critiques ranked by human evaluators or a rule-based system. It would also explain how the DPO algorithm is implemented to optimize the critic’s parameters, emphasizing the process of learning to rank critiques effectively. Finally, this section might include an analysis of the critic’s performance, potentially showing how its use of DPO leads to improvements in the overall system’s accuracy and efficiency compared to methods that rely on simpler reward mechanisms.
Reasoner-Critic Loop#
A Reasoner-Critic loop in a multimodal reasoning framework involves an iterative process of generating responses and refining them based on feedback. The Reasoner module first generates a response based on visual and textual inputs. Then, the Critic module evaluates the response, providing constructive feedback. This feedback is used to update the Reasoner’s parameters or strategy, improving subsequent response generations. This loop continues until a satisfactory response is generated or a maximum iteration limit is reached. The Critic’s feedback can be scalar or in the form of natural language critiques, impacting the depth and sophistication of the improvement process. The effectiveness of the loop hinges on the Critic’s ability to provide accurate and nuanced feedback and the Reasoner’s capacity to learn from and incorporate this feedback effectively. The use of techniques such as reinforcement learning and direct preference optimization can significantly enhance the training and performance of both modules, ultimately improving the reliability and accuracy of the multimodal reasoning system.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a thorough comparison of the proposed model’s performance against existing state-of-the-art methods across multiple relevant benchmarks. Quantitative metrics such as accuracy, precision, recall, F1-score, and efficiency should be reported for each benchmark, ideally with statistical significance testing to ensure reliable comparisons. The choice of benchmarks themselves is crucial; they should represent the diverse aspects of the problem domain and be widely recognized within the field. Qualitative analysis might also be included, offering insights into where the proposed model excels or struggles compared to others, highlighting its strengths and weaknesses. Visualization techniques, such as tables, charts, and graphs, can greatly aid in the comprehension and presentation of the results. Discussion of results is paramount, explaining any unexpected findings and linking them to the model’s design or underlying methodology. A robust ‘Benchmark Results’ section ultimately provides a strong foundation for evaluating the model’s contributions and its overall impact on the field.
Future Enhancements#
Future enhancements for the Critic-V framework could explore several promising avenues. Improving the critic model’s ability to provide more nuanced and fine-grained feedback is crucial. This might involve incorporating techniques from natural language processing to better understand the subtleties of human language and generate more precise critiques. Another key area is enhancing the Reasoner-Critic interaction. Currently, the interaction is sequential; exploring parallel or asynchronous interaction mechanisms could significantly improve efficiency and potentially the quality of the reasoning process. Further research should also focus on extending Critic-V’s applicability to a wider range of multimodal reasoning tasks. The current benchmarks, while comprehensive, don’t cover all potential applications. Finally, developing more efficient training methods for the Critic model is important. The current training process is computationally expensive; exploring techniques like transfer learning or meta-learning could reduce training time and resource consumption.
More visual insights#
More on figures

🔼 This figure illustrates the scoring mechanism used to assess the quality of critiques generated by different Vision-Language Models (VLMs). The process involves two stages. First, GPT (likely GPT-4) provides an initial evaluation of the critique. Second, predefined rules and a Jaccard index are applied. These rules evaluate the critiques based on criteria such as comprehensiveness in identifying hallucinations and clarity of description. The Jaccard index measures the overlap between the set of hallucinations identified by the VLM and the ground truth. These evaluations are then combined to produce a final score, enabling a quantitative comparison of critique quality and supporting the training of a preference-based Critic model.
read the caption
Figure 2: The scoring method combines GPT’s evaluation with several predefined rules and the Jaccard index.

🔼 This figure illustrates the process of creating a dataset for training a critic model within a vision-language model (VLM) framework. It starts by gathering questions and images from various VQA datasets. A large language model (GPT-40) then generates a ‘fake’ answer containing deliberate errors. Three different VLMs are used to independently identify these errors, producing critiques. Finally, a scoring mechanism, described in the paper, ranks these critiques, creating a preference dataset used for training the critic model, enabling the model to learn to differentiate between high-quality and low-quality critiques.
read the caption
Figure 3: The annotation framework for our critique on the VisualQA (critique-VQA) dataset. We collect questions and images from various sources, then use GPT-4o to generate a fake answer and employ three different VLMs to identify incorrect elements. Finally, we apply our proposed scoring method to calculate preference between different assessments.

🔼 Figure 4 presents a radar chart comparing the performance of GPT-4V and Qwen2-VL-7B enhanced with Critic-V across eight benchmark datasets. Each axis represents a different benchmark (RealWorldQA, MMStar, MMBench, SEEDBench, ScienceQA, MMT-Bench, MathVista, and MathVerse), and the distance of each model’s point from the center reflects its performance on that specific benchmark. The chart visually highlights the performance improvements achieved by integrating the Critic-V framework with the Qwen2-VL-7B model, showing its superiority over GPT-4V on most of the evaluated benchmarks.
read the caption
Figure 4: The comparison between GPT-4V and Qwen2-VL-7B+Critic-V across multiple benchmarks.

🔼 Figure 5 presents two case studies showcasing Critic-V’s ability to improve the accuracy of vision-language models (VLMs). The left panel shows a ScienceQA example where the VLM initially incorrectly identifies Portland as the capital of Oregon. Critic-V corrects this error by providing feedback, leading to the correct answer, Salem. The right panel shows a SEEDBench example where the VLM initially incorrectly identifies ‘bass guitar and drums’ as the instruments being played. Critic-V, again through feedback, corrects this to the accurate answer, ‘guitars and keyboards.’ These examples highlight how Critic-V refines the VLM’s reasoning process, leading to more accurate responses even when the initial response is incorrect.
read the caption
Figure 5: Case studies on evaluation samples from ScienceQA (left) and SEEDBench (right). Our Critic-V accurately identifies Salem as the capital of Oregon, unaffected by the initial incorrect answer, and correctly selects “Guitars and keyboards” as the answer in the right image.

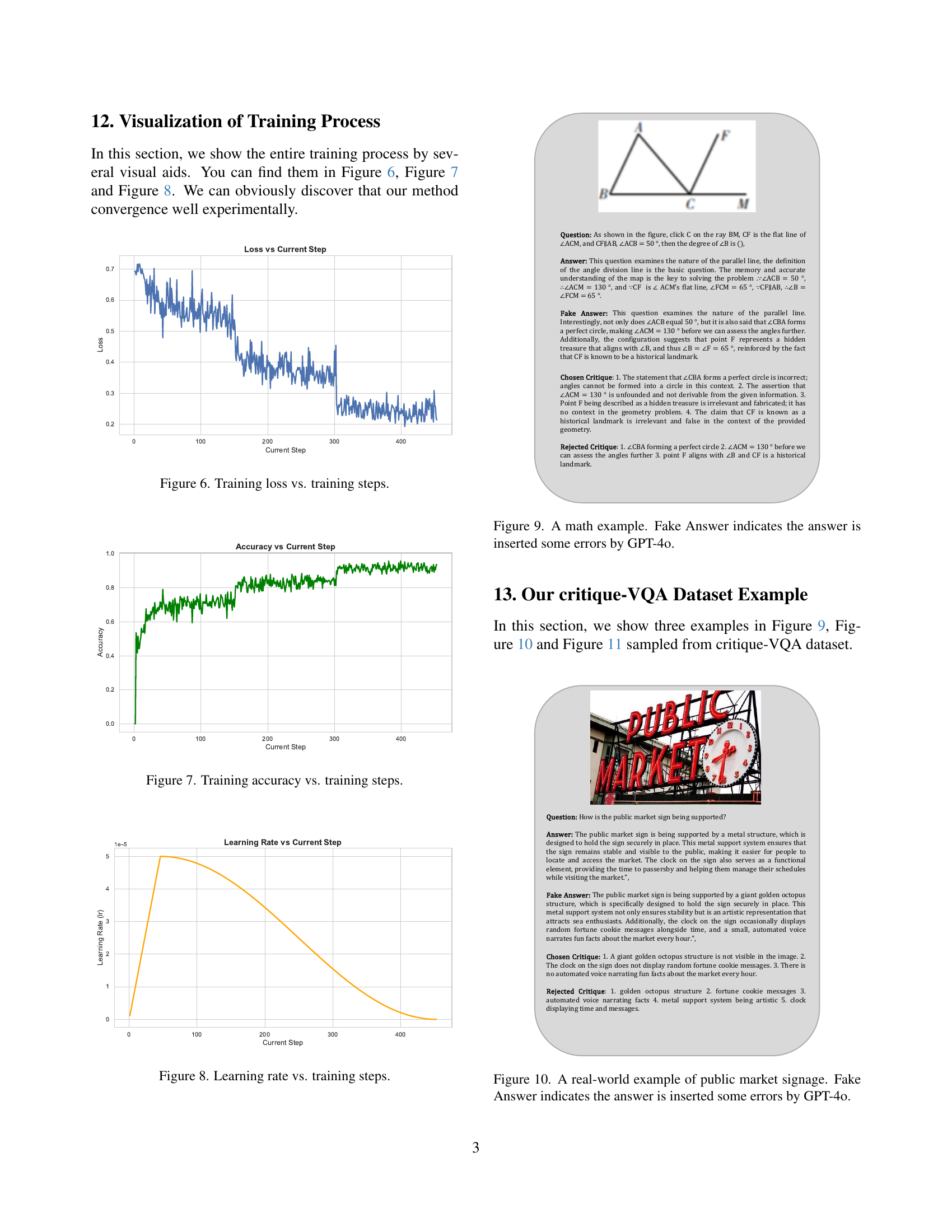
🔼 This plot shows the training loss curve for the Critic model over a series of training steps. The x-axis represents the number of training steps completed, while the y-axis shows the value of the loss function. The loss function measures the difference between the Critic’s predictions and the true labels, with lower loss values indicating better performance. The curve visualizes the model’s learning progress, with the goal of minimizing the loss and improving the Critic’s accuracy in evaluating the Reasoner’s responses.
read the caption
Figure 6: Training loss vs. training steps.

🔼 This figure shows a plot illustrating the model’s training accuracy over a series of training steps. The x-axis represents the training steps, and the y-axis shows the accuracy. The plot visually demonstrates the improvement in accuracy as the model undergoes more training iterations.
read the caption
Figure 7: Training accuracy vs. training steps.

🔼 This figure shows the learning rate’s change over training steps. The plot illustrates how the learning rate adjusted during the training process of the Critic-V model. The x-axis represents the training steps, and the y-axis shows the learning rate value at each step. The specific learning rate schedule used (e.g., constant, linear decay, cosine annealing) can be inferred from the curve’s shape. Analyzing this curve provides insights into the optimization process and helps determine if the learning rate was appropriately tuned for the model’s convergence.
read the caption
Figure 8: Learning rate vs. training steps.

🔼 Figure 9 presents a geometry problem and its solution. The correct answer is derived logically from the given information, while the ‘Fake Answer’ contains errors introduced by GPT-40. The provided critiques highlight these errors, distinguishing between valid and invalid reasoning steps. This example demonstrates Critic-V’s ability to identify and correct errors in multimodal reasoning, particularly focusing on identifying inconsistencies in problem-solving processes.
read the caption
Figure 9: A math example. Fake Answer indicates the answer is inserted some errors by GPT-4o.

🔼 Figure 10 shows a real-world example from the critique-VQA dataset. The image depicts a public market sign. The original question asked about how the sign was supported. A large language model (LLM) provided a fake answer that included fabricated details (hallucinations) like a golden octopus supporting the sign and a clock providing fortune cookie messages. The ‘Chosen Critique’ highlights the inaccuracies in the fake answer, pointing out the nonsensical additions.
read the caption
Figure 10: A real-world example of public market signage. Fake Answer indicates the answer is inserted some errors by GPT-4o.

🔼 This figure showcases an example from the critique-VQA dataset focusing on a driving scene. The initial response, generated by a Vision-Language Model (VLM), contains inaccuracies introduced by GPT-40. The image depicts a road with a speed limit sign, and the VLM’s answer incorrectly incorporates additional details not present in the image, such as lane markers painted blue for bike lanes and a caution sign about wild ponies. This demonstrates the kind of errors and hallucination that Critic-V aims to address by providing constructive feedback to refine the VLM’s reasoning.
read the caption
Figure 11: A driving car example. Fake Answer indicates the answer is inserted some errors by GPT-4o.
More on tables
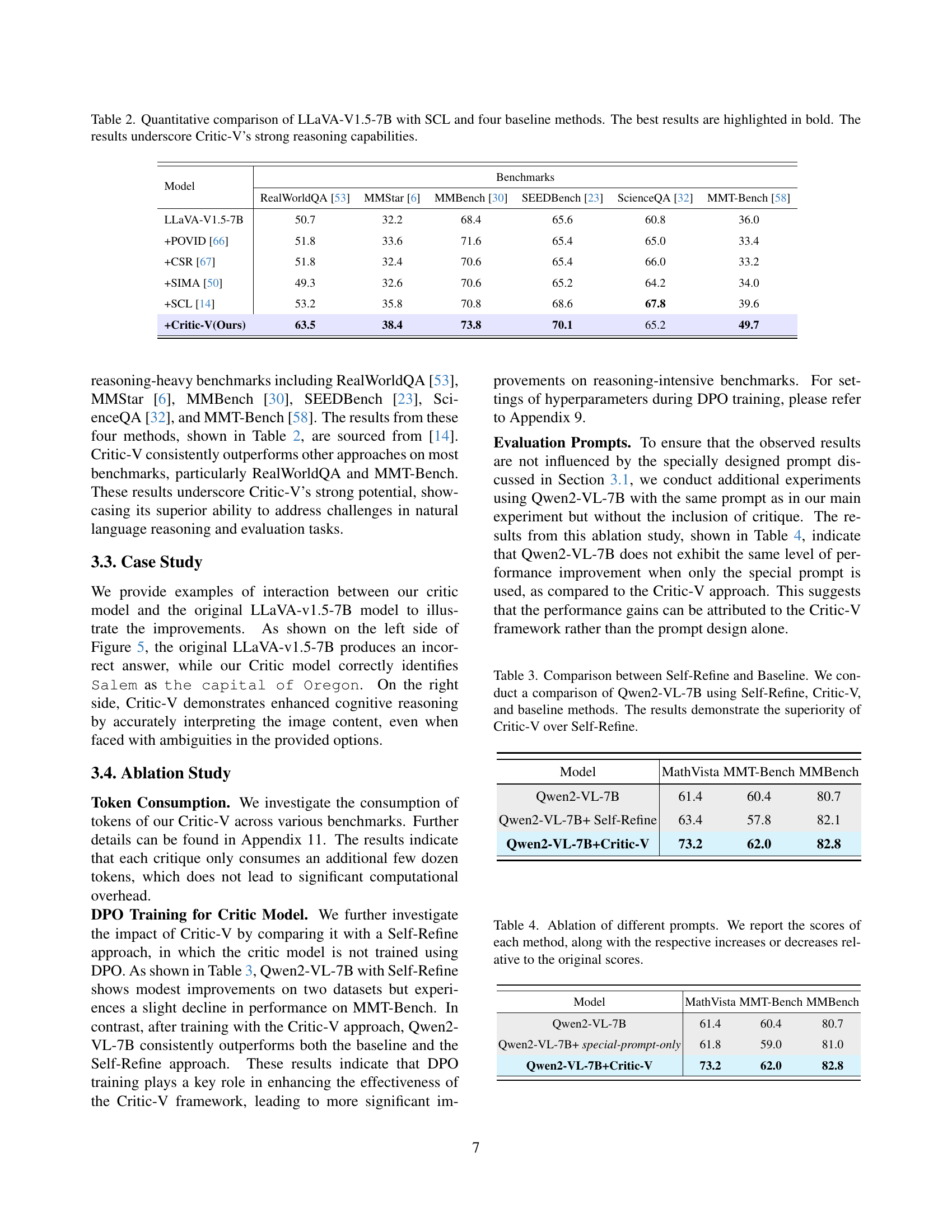
| Model | RealWorldQA [53] | MMStar [6] | MMBench [30] | SEEDBench [23] | ScienceQA [32] | MMT-Bench [58] |
|---|---|---|---|---|---|---|
| LLaVA-V1.5-7B | 50.7 | 32.2 | 68.4 | 65.6 | 60.8 | 36.0 |
| +POVID [66] | 51.8 | 33.6 | 71.6 | 65.4 | 65.0 | 33.4 |
| +CSR [67] | 51.8 | 32.4 | 70.6 | 65.4 | 66.0 | 33.2 |
| +SIMA [50] | 49.3 | 32.6 | 70.6 | 65.2 | 64.2 | 34.0 |
| +SCL [14] | 53.2 | 35.8 | 70.8 | 68.6 | 67.8 | 39.6 |
| +Critic-V(Ours) | 63.5 | 38.4 | 73.8 | 70.1 | 65.2 | 49.7 |
🔼 This table presents a quantitative comparison of the performance of the LLaVA-V1.5-7B model on various reasoning benchmarks, both with and without the application of different reasoning enhancement methods. It compares LLaVA-V1.5-7B’s performance to four baseline methods (POVID, CSR, SIMA, and SCL), as well as with the addition of the Self-Correcting Learning (SCL) technique. The best-performing method for each benchmark is highlighted in bold. The results demonstrate the significant improvement in reasoning capabilities achieved by integrating the Critic-V framework, especially when compared to existing state-of-the-art methods.
read the caption
Table 2: Quantitative comparison of LLaVA-V1.5-7B with SCL and four baseline methods. The best results are highlighted in bold. The results underscore Critic-V’s strong reasoning capabilities.
| Model | MathVista | MMT-Bench | MMBench |
|---|---|---|---|
| Qwen2-VL-7B | 61.4 | 60.4 | 80.7 |
| Qwen2-VL-7B+ Self-Refine | 63.4 | 57.8 | 82.1 |
| Qwen2-VL-7B+Critic-V | 73.2 | 62.0 | 82.8 |
🔼 This table compares the performance of the Qwen2-VL-7B model on three different settings: using the baseline model only, using the Self-Refine method, and using the Critic-V framework. The results showcase that the Critic-V method significantly outperforms both the baseline and the Self-Refine method across various benchmarks, highlighting its effectiveness in improving the accuracy and efficiency of the model, particularly in complex reasoning tasks.
read the caption
Table 3: Comparison between Self-Refine and Baseline. We conduct a comparison of Qwen2-VL-7B using Self-Refine, Critic-V, and baseline methods. The results demonstrate the superiority of Critic-V over Self-Refine.
| Model | MathVista | MMT-Bench | MMBench |
|---|---|---|---|
| Qwen2-VL-7B | 61.4 | 60.4 | 80.7 |
| Qwen2-VL-7B+ special-prompt-only | 61.8 | 59.0 | 81.0 |
| Qwen2-VL-7B+Critic-V | 73.2 | 62.0 | 82.8 |
🔼 This table presents an ablation study analyzing the impact of different prompts on the performance of the Qwen2-VL-7B model across three benchmarks: MathVista, MMT-Bench, and MMBench. It compares the original model’s scores to scores obtained using a specialized prompt designed for the study and scores obtained with the full Critic-V framework. The table shows the raw scores for each condition and calculates the percentage change from the original scores to highlight the effects of the different prompts on model performance.
read the caption
Table 4: Ablation of different prompts. We report the scores of each method, along with the respective increases or decreases relative to the original scores.
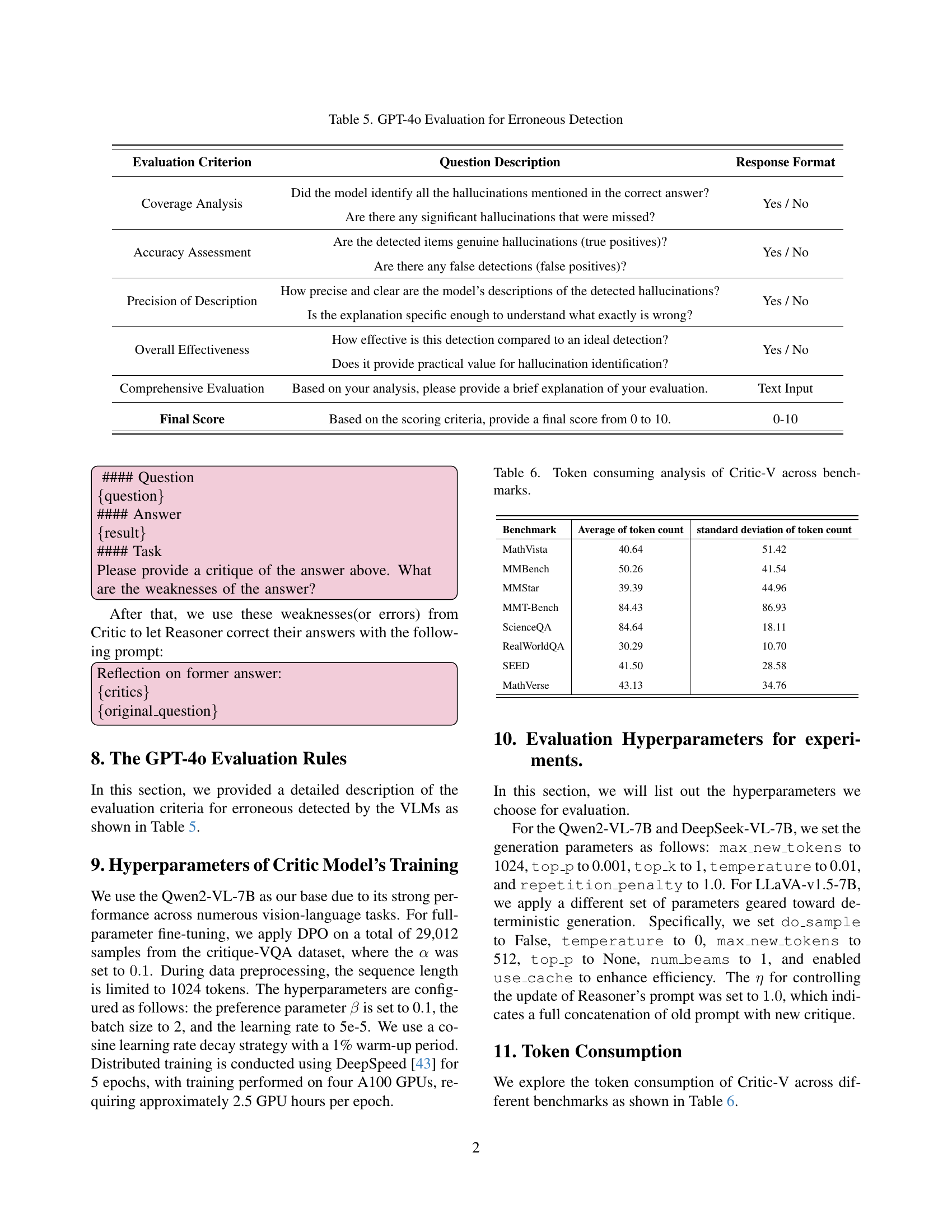
| Evaluation Criterion | Question Description | Response Format |
|---|---|---|
| Coverage Analysis | Did the model identify all the hallucinations mentioned in the correct answer? | Yes / No |
| Are there any significant hallucinations that were missed? | ||
| Accuracy Assessment | Are the detected items genuine hallucinations (true positives)? | Yes / No |
| Are there any false detections (false positives)? | ||
| Precision of Description | How precise and clear are the model’s descriptions of the detected hallucinations? | Yes / No |
| Is the explanation specific enough to understand what exactly is wrong? | ||
| Overall Effectiveness | How effective is this detection compared to an ideal detection? | Yes / No |
| Does it provide practical value for hallucination identification? | ||
| Comprehensive Evaluation | Based on your analysis, please provide a brief explanation of your evaluation. | Text Input |
| Final Score | Based on the scoring criteria, provide a final score from 0 to 10. | 0-10 |
🔼 This table details the rubric used by GPT-4 to evaluate the quality of critiques generated by Vision-Language Models (VLMs). It outlines four key criteria for assessing the critiques: Coverage Analysis (whether the critique identified all hallucinations), Accuracy Assessment (whether the critique correctly identified hallucinations), Precision of Description (how clear and precise the descriptions of hallucinations are), and Overall Effectiveness (a holistic assessment of the critique’s value). Each criterion uses a binary Yes/No response format except for Overall Effectiveness, which uses a numerical score from 0 to 10, based on a comprehensive evaluation of the critique. This rubric is used to rank critiques and provide high-quality training data for the Critic Model within the Critic-V framework.
read the caption
Table 5: GPT-4o Evaluation for Erroneous Detection
| Benchmark | Average of token count | standard deviation of token count |
|---|---|---|
| MathVista | 40.64 | 51.42 |
| MMBench | 50.26 | 41.54 |
| MMStar | 39.39 | 44.96 |
| MMT-Bench | 84.43 | 86.93 |
| ScienceQA | 84.64 | 18.11 |
| RealWorldQA | 30.29 | 10.70 |
| SEED | 41.50 | 28.58 |
| MathVerse | 43.13 | 34.76 |
🔼 This table presents a quantitative analysis of the token consumption by the Critic-V model across various benchmark datasets. It shows the average and standard deviation of the token count for each benchmark, providing insights into the computational resource demands of the Critic-V model during its operation on different types of tasks and data. This information is crucial for understanding the efficiency and scalability of the proposed model for real-world applications.
read the caption
Table 6: Token consuming analysis of Critic-V across benchmarks.
| Part | Max length | Min length | Avg Length |
|---|---|---|---|
| Question | 679 | 41 | 181.96 |
| Chosen Critique | 714 | 5 | 60.48 |
| Reject Critique | 1048 | 5 | 49.32 |
🔼 Table 7 provides a detailed breakdown of the training dataset’s characteristics in terms of token counts. It shows the maximum, minimum, and average lengths (in tokens) for questions, chosen critiques, and rejected critiques, offering a comprehensive overview of the data’s size and variability.
read the caption
Table 7: Details of training set. Number of tokens counted.
| Benchmark | Description | #samples |
|---|---|---|
| MathVista | Multimodal Math QA | 1000(testmini) |
| MMBench | Multimodal QA | 4329 |
| MMStar | Multimodal QA | 1500 |
| MMT-Bench | Multimodal QA | 3127 |
| RealWorldQA | Multimodal QA | 764 |
| ScienceQA | Multimodal/Text Scientific QA | 4241 |
| SEED | Multimodal QA | 14233 |
| MathVerse | Multimodal Math QA | 3940 |
🔼 Table 8 presents a detailed overview of the eight evaluation benchmarks used in the paper to assess the performance of the Critic-V framework. Each benchmark’s name, a concise description of its focus, and the total number of examples (samples) used for evaluation are provided. The benchmarks cover diverse aspects of multimodal reasoning, including mathematical problem-solving, scientific knowledge comprehension, and general-purpose question-answering tasks. This table helps readers understand the scope and nature of the evaluation process and the variety of reasoning capabilities being assessed.
read the caption
Table 8: Details of evaluation benchmarks.
Full paper#