↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current virtual try-on (VTON) systems struggle with inconsistent outputs and lack a well-defined evaluation metric, hindering accurate quality assessment and real-world applications. This paper introduces a new task, Virtual Try-Off (VTOFF), focusing on generating standardized garment images from single photos. This well-defined target simplifies evaluation and improves reconstruction fidelity.
To tackle VTOFF, the researchers developed TryOffDiff, a model that leverages Stable Diffusion and incorporates SigLIP for high-fidelity visual conditioning. TryOffDiff significantly outperforms existing methods in generating detailed and consistent garment images. The paper also highlights the inadequacy of traditional image quality metrics, proposing DISTS as a more effective evaluation method. This research contributes to both generative model evaluation and applications in e-commerce by producing high-quality, standardized product images.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel task, Virtual Try-Off (VTOFF), addressing limitations of existing virtual try-on methods. It proposes a new model, TryOffDiff, that achieves high-fidelity garment reconstruction, advancing generative model evaluation and impacting e-commerce. The work also highlights the need for better evaluation metrics in generative modeling, opening avenues for future research in high-fidelity image generation and e-commerce applications.
Visual Insights#

🔼 This figure showcases the performance of the TryOffDiff model in generating standardized garment images from a single reference image of a person wearing the garment. Each set of three rows represents a single example: the first row displays the input reference image, the second row shows the model’s prediction of the garment isolated on a clean background, maintaining a consistent pose, and the third row presents the ground truth image. The results demonstrate the model’s ability to capture intricate details such as patterns and logos, showcasing its high-fidelity garment reconstruction capabilities.
read the caption
Figure 1: Virtual try-off results generated by our method. The first row shows the input reference image, the second row our model’s prediction, and the third row the ground truth. Our approach naturally renders the garment against a clean background, preserving the standard pose and capturing complex details of the target garment, such as patterns and logos, from a single reference image.
| Method | SSIM↑ | MS-SSIM↑ | CW-SSIM↑ | L-PIPS↓ | L-FID↓ | CLIP-FID↓ | DI-KID↓ | DI-STS↓ |
|---|---|---|---|---|---|---|---|---|
| GAN-Pose [36] | 77.4 | 63.8 | 32.5 | 44.2 | 73.2 | 30.9 | 55.8 | 30.4 |
| ViscoNet [7] | 58.5 | 50.7 | 28.9 | 54.0 | 42.3 | 12.1 | 25.5 | 31.2 |
| OOTDiff. [57] | 65.1 | 50.6 | 26.1 | 49.5 | 54.0 | 17.5 | 33.2 | 32.4 |
| CatVTON [9] | 72.8 | 56.9 | 32.0 | 45.9 | 31.4 | 9.7 | 17.8 | 28.2 |
| Ours:TryOffDiff | 79.5 | 70.4 | 46.2 | 32.4 | 25.1 | 9.4 | 8.9 | 23.0 |
🔼 This table presents a quantitative comparison of different virtual try-off (VTOFF) methods. It evaluates their performance on the VITON-HD test dataset using a range of metrics that assess both reconstruction accuracy (how well the generated image matches the ground truth) and perceptual quality (how natural and visually appealing the generated image is to human observers). The metrics used include Structural Similarity Index Measure (SSIM) and its variants (MS-SSIM, CW-SSIM), Perceptual Image Patch Similarity (LPIPS), Fréchet Inception Distance (FID), and its CLIP variant (CLIP-FID), Kernel Inception Distance (KID), and Deep Image Structure and Texture Similarity (DISTS). The table allows readers to compare the performance of various methods for generating standardized garment images from single reference images of clothed individuals.
read the caption
Table 1: Quantitative comparison. Evaluation metrics for various methods on VITON-HD-test dataset in the VTOFF task.
In-depth insights#
VTOFF Task Defined#
The conceptualization of the “VTOFF Task Defined” section would likely involve a formal definition of the Virtual Try-Off (VTOFF) problem. This would explicitly state the goal: to generate standardized garment images from single, real-world photos of clothed individuals. Crucially, the section would differentiate VTOFF from traditional Virtual Try-On (VTON) by emphasizing the focus on garment reconstruction, rather than digitally dressing a person. Key aspects of the definition would include specifying the desired characteristics of the output images (e.g., standardized pose, clean background), the allowed input (a single image of a clothed individual), and metrics for assessing the success of the task (likely focusing on reconstruction accuracy and perceptual realism, potentially incorporating novel metrics). Furthermore, this section would justify the need for VTOFF, highlighting its potential applications in e-commerce and generative model evaluation, contrasting it with the limitations of VTON for such purposes. The overall aim is to establish VTOFF as a well-defined, valuable computer vision task distinct from related problems.
TryOffDiff Model#
The TryOffDiff model, at its core, is a novel approach to virtual try-off (VTOFF) that leverages the power of diffusion models. Instead of digitally dressing a person like traditional VTON, it focuses on reconstructing a standardized garment image from a single, real-world photo. This shift in focus presents several advantages. First, it simplifies evaluation by providing a clearly defined target output, mitigating the inconsistencies common in VTON assessments. Second, it offers practical applications in e-commerce, providing consistent product imagery. The model cleverly adapts Stable Diffusion, replacing text prompts with visual conditioning via SigLIP embeddings, resulting in high-fidelity reconstructions capturing intricate details. This careful adaptation significantly outperforms traditional VTON methods, especially in preserving fine details like textures, logos, and patterns. The model’s success emphasizes the potential of diffusion models for high-fidelity image reconstruction tasks and highlights the value of task redefinition in computer vision for generating more reliable and practical results. The choice to use DISTS as a primary evaluation metric is also noteworthy, reflecting a thoughtful consideration of perceptual quality over traditional metrics.
DISTS Metric Use#
The research paper highlights the limitations of traditional image quality metrics like SSIM, FID, and KID in evaluating the reconstruction quality of generated garment images. These metrics often fail to align with human perception, particularly concerning fine details. The authors advocate for the use of the DISTS metric, which considers both structural and textural information, as a more accurate and perceptually aligned evaluation measure. They demonstrate that DISTS effectively captures the nuances of garment reconstruction fidelity, revealing shortcomings of alternative metrics that might overlook important visual details. This emphasizes the importance of choosing evaluation metrics appropriate for the specific task and application, and DISTS proves a crucial tool for high-fidelity image generation assessment in the context of virtual try-off.
Person-to-Person VTON#
Person-to-person virtual try-on (VTON) presents a significant challenge in computer vision, moving beyond the traditional approach of dressing a virtual model with a garment image. This method requires the system to understand and manipulate clothing on a real person’s body within an image, requiring advanced techniques for pose estimation, cloth simulation, and seamless integration of the garment into the scene. This is more complex than traditional VTON, which has access to a standardized garment image. The key difficulties involve accurately adapting the garment to the individual’s pose and body shape while preserving visual fidelity and addressing potential occlusions. Success requires sophisticated models that can learn complex relationships between the person, the garment, and the scene. Existing methods often struggle with handling diverse poses, lighting conditions, and garment types. Evaluation for person-to-person VTON is also a significant hurdle, lacking standardized metrics to accurately assess both visual quality and the fidelity of garment placement. Future research should focus on improving model robustness, evaluating across diverse datasets, and developing standardized quantitative and qualitative metrics for better performance assessment and comparison.
Future Work#
The authors of the TryOffDiff paper acknowledge the promising results but also point towards several avenues for future research. Improving the handling of complex garment structures like intricate patterns, folds, and logos remains a key challenge. The current model sometimes struggles with these details, highlighting the need for advancements in image generation techniques to accurately capture the nuances of clothing. Further exploration into alternative visual conditioning methods beyond SigLIP is warranted, potentially integrating other approaches for enhanced image feature extraction and representation. Refining the evaluation metrics is another crucial area, as existing metrics may not fully capture the perceptual quality of garment reconstruction. The development of more robust and nuanced evaluation techniques that better align with human judgment is vital for future progress. Finally, investigating the integration of TryOffDiff with other AI systems in e-commerce settings, such as recommendation systems or virtual stylists, holds significant potential to enhance the user experience.
More visual insights#
More on figures

🔼 This figure illustrates the core difference between the tasks of Virtual Try-On (VTON) and Virtual Try-Off (VTOFF). The top half shows the VTON pipeline, where the model takes two inputs: an image of a person wearing clothes and an image of the garment to be virtually ’tried on’. The output is an image of the person wearing the specified garment. The bottom half depicts the VTOFF pipeline, which only uses a single image of the clothed person as input and aims to produce a standardized, catalog-like image of the garment itself, focusing on accuracy of reconstruction rather than style or pose.
read the caption
Figure 2: Illustration of the differences between Virtual Try-On and Virtual Try-Off. Top: Basic inference pipeline of a Virtual Try-On model, which takes an image of a clothed person as reference and an image of a garment to generate an image of the same person but wearing the specified garment. Bottom: Virtual Try-Off setup, where the objective is to predict the canonical form of the garment from a single input reference image.

🔼 The figure demonstrates the inadequacy of using SSIM (structural similarity index measure) alone for evaluating the quality of generated garment images in the context of virtual try-off. SSIM, while providing a numerical score, fails to capture the visual discrepancies apparent to the human eye. The figure presents a series of image comparisons. Each comparison shows the SSIM score and DISTS (Deep Image Structure and Texture Similarity) score. The DISTS score provides a perceptually-aware measurement of image similarity that aligns better with human judgments. In the top row, we see various examples where the SSIM score is deceptively high despite major differences in image quality, while the DISTS score reflects these quality differences more accurately. The bottom row shows a similar trend with clear visual differences that are better reflected in the DISTS scores compared to SSIM. This highlights the necessity of supplementing SSIM with perceptually-aware metrics like DISTS for comprehensive evaluation of image generation quality, specifically in the context of garment reconstruction tasks.
read the caption
(a) 82.4 / 20.682.4 / 20.682.4\text{ / }20.682.4 / 20.6

🔼 This figure shows a comparison of different images using two metrics, SSIM and DISTS. The first metric (SSIM), measures structural similarity, while the second (DISTS), evaluates perceptual similarity. The image shows that the SSIM metric gives a high score of 96.8 even with an image having color change. However, DISTS, which better reflects human perception, assigns a lower score of 17.9 to that image.
read the caption
(b) 96.8 / 17.996.8 / 17.996.8\text{ / }17.996.8 / 17.9

🔼 This figure shows an example image used to demonstrate the suitability of different performance metrics for evaluating virtual try-on and virtual try-off tasks. It compares a reference image with various modified versions of the image, and shows how different metrics respond to these changes. The reference image is compared with (a) an image with masked-out garment, (b) an image with changed garment color, and (c) an image with color jittering applied. The second row compares a garment image to different altered images. These include (d) a plain white image, (e) a slightly rotated image, and (f) a randomly posterized image. This helps illustrate which metrics provide results that more closely correlate with human visual assessment of quality.
read the caption
(c) 88.3 / 20.388.3 / 20.388.3\text{ / }20.388.3 / 20.3

🔼 This figure shows a comparison of a garment image against different transformations to demonstrate the limitations of SSIM and the advantages of DISTS in assessing reconstruction quality. The top row shows a reference image and three variations, while the bottom shows a garment and three transformations. SSIM scores remain high regardless of transformation, but the DISTS score reflects visual quality.
read the caption
(d) 86.0 / 70.386.0 / 70.386.0\text{ / }70.386.0 / 70.3

🔼 This figure is part of the performance evaluation in the paper. It shows a garment image (left) compared to a randomly posterized version of the same image (right). The posterized image uses fewer bits for each color channel, reducing the image quality. The comparison highlights the limitations of the SSIM metric (structural similarity index measure) compared to the DISTS metric (Deep Image Structure and Texture Similarity) for evaluating image reconstruction quality. While SSIM shows relatively high similarity between images even when there’s a significant loss of fine details, DISTS provides a more accurate reflection of the perceptual difference, aligning better with human judgment. This shows the importance of using perception-based metrics like DISTS for assessing reconstruction fidelity in image generation tasks.
read the caption
(e) 75.0 / 8.275.0 / 8.275.0\text{ / }8.275.0 / 8.2

🔼 This figure shows a comparison of a garment image against several variations. It demonstrates the limitations of common image quality metrics such as SSIM, which achieves consistently high scores across all examples, including failure cases, unlike the DISTS score which more accurately reflects variations aligned with human judgement. Specifically, the variations shown are (a) an image with a masked-out garment; (b) an image with changed colors of the garment; (c) an image after applying color jittering; (d) a plain white image; (e) a slightly rotated image; and (f) a randomly posterized image (reducing the number of bits per color channel).
read the caption
(f) 86.4 / 24.786.4 / 24.786.4\text{ / }24.786.4 / 24.7

🔼 This figure demonstrates the limitations of using SSIM (Structural Similarity Index) alone to evaluate image quality, particularly in the context of virtual try-on (VTON) and the novel virtual try-off (VTOFF) task. The top row shows a reference image compared to three modified versions: one with the garment masked, one with altered colors, and one with color jittering. The bottom row compares a garment image to three significantly different images: a plain white image, a slightly rotated version, and a posterized version (with reduced color depth). While SSIM scores remain high even for the heavily altered images, highlighting its insensitivity to perceptually significant changes, the DISTS (Deep Image Structure and Texture Similarity) scores are much lower for these, indicating better alignment with human perception of quality.
read the caption
Figure 3: Examples demonstrating the un/suitability of performance metrics (SSIM↑ / DISTS↓) to VTON and VTOFF. In the top row, a reference image is compared against: (a) an image with a masked-out garment; (b) an image with changed colors of the model; (c) and an image after applying color jittering. In the bottom row, a garment image is compared against: (d) a plain white image; (e) a slightly rotated image; (f) and a randomly posterized image (reducing the number of bits for each color channel). While the SSIM score achieves consistently high across all examples, in particular including failure cases, the DISTS score more accurately reflects variations aligned with human judgment.

🔼 TryOffDiff is a model that adapts Stable Diffusion for the task of Virtual Try-Off (VTOFF). The figure shows the architecture of this model. It starts with a SigLIP image encoder that processes a reference image of a person wearing clothing, extracting visual features. These features are fed into adapter modules, which refine the features before they are input into a pre-trained Stable Diffusion v1.4 model. Importantly, the adapter modules replace the text-based conditioning typically used in Stable Diffusion with image-based conditioning. By directly using image features, the model learns to reconstruct garment images without needing a text description. This direct approach is key to achieving high-fidelity garment reconstruction in the VTOFF task. The model’s adapter modules and the Stable Diffusion model are trained simultaneously to ensure effective garment transformation and high-quality output.
read the caption
Figure 4: Overview of TryOffDiff. The SigLIP image encoder [59] extracts features from the reference image, which are subsequently processed by adapter modules. These extracted image features are embedded into a pre-trained text-to-image Stable Diffusion-v1.4 [35] by replacing the original text features in the cross-attention layers. By conditioning on image features in place of text features, TryOffDiff directly targets the VTOFF task. Simultaneous training of the adapter layers and the diffusion model enables effective garment transformation.

🔼 This figure shows the process of adapting an existing state-of-the-art method (GAN-Pose) to the VTOFF task. It starts with a reference image of a person wearing the garment. A fixed pose heatmap is then created, showing the ideal neutral pose desired for the standardized garment image. The initial model output shows the garment reconstruction attempt using only the reference image and pose heatmap. Next, SAM (Segment Anything Model) prompts refine the mask of the garment and guide further processing. The final processed output is the improved garment image, showing the garment isolated on a clean background in a standardized pose and with enhanced accuracy. This illustrates the intermediate steps and refinement processes required to make existing methods suitable for the new virtual try-off task.
read the caption
(a) Left to right: reference image, fixed pose heatmap derived from target image, initial model output, SAM prompts, and final processed output.

🔼 This figure shows the adaptation of the ViscoNet model to the VTOFF task. It details the five steps involved in generating a standardized garment image from a real-world image. (1) A masked conditioning image is used to isolate the garment. (2) A mask image highlights the garment region. (3) Pose information is provided to align the output with a neutral pose. (4) An initial garment reconstruction is generated using the ViscoNet model, guided by SAM prompts. (5) The final result shows the garment image after post-processing ( likely using the SAM prompts to refine the output and create a clean background).
read the caption
(b) Left to right: masked conditioning image, mask image, pose image, initial model output with SAM prompts, and final processed output.

🔼 This figure shows the adaptation of the OOTDiffusion model to the VTOFF task. The process begins with a masked garment image (leftmost), representing the target garment without the background or other elements. Next, a generic model image (2nd from left) provides a basic structural shape. This model image is then masked (3rd from left), to match the initial masking used for the garment image. This masked model image is used as input to the OOTDiffusion model which generates an initial model output (4th from left) but often requires further refinement. Finally, Segment Anything (SAM) prompts are applied to enhance the image, resulting in a final processed output that features a complete and clean garment (rightmost).
read the caption
(c) Left to right: masked garment image, model image, masked model image, initial model output with SAM prompts, and final processed output.

🔼 This figure shows the adaptation of the CatVTON model for the virtual try-off task. The process starts with a conditioning garment image (a clean image of the garment). A blank model image (a plain image of the same size as the output) and a mask image (specifying the area where the garment should appear) are used as inputs. The initial model output is generated using the CatVTON model with Segment Anything (SAM) prompts to guide the placement of the garment, resulting in an initial try-off image. Post-processing with SAM prompts refines the image, leading to the final processed output, which is a standardized image of the garment.
read the caption
(d) Left to right: conditioning garment image, blank model image, mask image, initial model output with SAM prompts, final processed output.

🔼 Figure 5 demonstrates adaptations of existing state-of-the-art methods for the virtual try-off task. Specifically, it shows how four different models were adapted: GAN-Pose and ViscoNet (using pose transfer and view synthesis, respectively), and OOTDiffusion and CatVTON (both recent virtual try-on models). The figure visually presents the input images and the results of each model’s adaptation, highlighting the challenges and differences in their approaches to the virtual try-off problem.
read the caption
Figure 5: Adapting existing state-of-the-art methods to VTOFF. (a) GAN-Pose [36] and (b) ViscoNet [7] are approaches based on pose transfer and view synthesis, respectively, (c) OOTDiffusion [57] and (d) CatVTON [9] are based on recent virtual try-on methods.

🔼 This figure shows a comparison of garment reconstruction results from different methods. Column (a) displays the reference image, showing a person wearing a garment. Subsequent columns show results from GAN-Pose, ViscoNet, OOTDiffusion, CatVTON, and TryOffDiff, each representing a different approach to garment image generation. The final column shows the ground truth garment image. The figure illustrates the performance of each model in terms of detail preservation and accuracy of reconstruction.
read the caption
(a) Reference

🔼 This figure shows the results of applying the GAN-Pose model for the Virtual Try-Off task. GAN-Pose is a pose transfer method that takes an image and pose heatmaps as input. Here, the model is modified to predict a canonical garment image from a person wearing the garment by estimating a heatmap for a neutral pose, and then applying a pose transfer to align the output to a standard product image view. The results show that GAN-Pose can manage to approximate the main color and shape of the garment, although some detail is missing, and the predicted images often contain inconsistencies, showing parts of the garment missing, and a somewhat unnatural appearance.
read the caption
(b) Gan-Pose

🔼 This figure shows the results of adapting the ViscoNet model for the Virtual Try-Off task. ViscoNet, originally designed for view synthesis, requires a text prompt, a pose, a mask, and multiple masked conditioning images as input. For this adaptation, a generic text prompt describing clothing is used, along with a neutral pose derived from the VITON-HD dataset and a mask generated using an off-the-shelf fashion parser. The resulting images demonstrate ViscoNet’s performance in reconstructing garments from limited information.
read the caption
(c) ViscoNet

🔼 This figure is part of an ablation study comparing different model architectures for virtual try-off. It shows the results of using the OOTDiffusion model, a baseline method adapted from virtual try-on, on the VTOFF task. The images depict the model’s reconstruction of garments from reference images of people wearing those garments. This visualization aids in understanding the model’s ability to capture the details and texture of the garments.
read the caption
(d) OOTDiffusion

🔼 This figure shows the results of the CatVTON model, a virtual try-on method adapted for the virtual try-off task. It showcases how this particular method attempts garment reconstruction given an input image, but highlights limitations such as the struggle to accurately capture the garment’s shape, occasionally producing deformed representations. Also, it demonstrates a tendency towards generating long sleeves, regardless of the actual garment design, and often lacks fine textural details.
read the caption
(e) CatVTON

🔼 This figure shows the results of the TryOffDiff model, which is the main method proposed in this paper. It showcases examples of garments generated by the model based on input reference images. The figure is used to demonstrate the model’s ability to reconstruct garment details such as texture, patterns, and logos, achieving high fidelity and generating standardized product images from single images of clothed individuals.
read the caption
(f) TryOffDiff

🔼 This image shows the ground truth garment image corresponding to the reference image used as input. It is the canonical, standardized garment image that the model aims to generate as output. This serves as the target for evaluation of the model’s performance.
read the caption
(g) Target

🔼 Figure 6 presents a qualitative comparison of garment image generation results between TryOffDiff and several baseline methods. The figure visually demonstrates TryOffDiff’s superior ability to accurately reconstruct both the overall shape (structural details) and fine details like logos and patterns (textural details) of garments. This contrasts with the baseline methods, which often exhibit inaccuracies in either shape or texture.
read the caption
Figure 6: Qualitative comparison. In comparison to the baseline approaches, TryOffDiff is capable of generating garment images with accurate structural details as well as fine textural details.

🔼 This figure presents a qualitative comparison of garment reconstruction results obtained using different model configurations within the TryOffDiff framework. Each column represents a different model variant, showcasing the generated garment image alongside the corresponding ground truth image. The numbers provided (e.g., ‘81.9 / 36.2’) likely represent the SSIM and DISTS scores for each respective model configuration, reflecting reconstruction accuracy and perceptual similarity to the ground truth.
read the caption
(a) 81.9 / 36.281.9 / 36.281.9\text{ / }36.281.9 / 36.2

🔼 This figure shows the qualitative results for a pixel-space diffusion model, a variation of the TryOffDiff model. The top row displays the ground truth images of various garments, and each subsequent row presents the results from different model configurations. The numerical values (e.g., ‘81.5 / 40.4’) likely represent the SSIM and DISTS scores, indicating the model’s performance in terms of structural similarity and perceptual quality. The aim is to visually demonstrate the impact of various model configurations on the quality of garment image reconstruction.
read the caption
(b) 81.5 / 40.481.5 / 40.481.5\text{ / }40.481.5 / 40.4

🔼 The figure shows qualitative results from an ablation study comparing different model configurations for the task of garment reconstruction. Specifically, it visualizes the outputs of several models, including an autoencoder, pixel-based diffusion model, three latent diffusion models (LDM-1, LDM-2, LDM-3), and the final TryOffDiff model. Each row displays the results for a different garment, with the ground truth image shown on the far right. The models’ outputs vary in quality, with some showing only basic shapes while others capturing finer details like logos and patterns. The TryOffDiff model demonstrates the best reconstruction quality overall, capturing a high level of detail and visual fidelity.
read the caption
(c) 81.7 / 39.781.7 / 39.781.7\text{ / }39.781.7 / 39.7
![]()
🔼 This figure shows a qualitative comparison of garment reconstruction results. It displays the results from six different methods: (a) Autoencoder, (b) PixelModel, (c) LDM-1, (d) LDM-2, (e) LDM-3, and (f) TryOffDiff. Each method’s reconstruction of a specific garment is shown alongside the corresponding ground truth garment image (g). The caption numbers (e.g., 80.3/24.2) represent evaluation metrics (SSIM/DISTS) for each generated image, illustrating the relative success of each model in achieving visual fidelity compared to the ground truth.
read the caption
(d) 80.3 / 24.280.3 / 24.280.3\text{ / }24.280.3 / 24.2

🔼 This figure shows a comparison of garment reconstruction results between different model configurations. The image displays a series of garments, with each row representing a different configuration of the model, and each column showing the results for a specific garment. It showcases the effect of various configurations such as Autoencoder, PixelModel, LDM-1, LDM-2, LDM-3, and the final TryOffDiff model. The numerical values displayed are SSIM scores and DISTS scores. The caption is too short to adequately describe the figure, but it shows that the TryOffDiff approach outperforms other baseline approaches.
read the caption
(e) 75.3 / 25.075.3 / 25.075.3\text{ / }25.075.3 / 25.0

🔼 The image shows a comparison between the ground truth garment image and the garment image generated by the TryOffDiff model. The ground truth image is on the left, and the generated image is on the right. The numbers ‘80.3 / 19.4’ likely represent evaluation metrics (e.g., SSIM and DISTS scores) comparing the generated image to the ground truth.
read the caption
(f) 80.3 / 19.480.3 / 19.480.3\text{ / }19.480.3 / 19.4

🔼 Figure 7 demonstrates the limitations of using SSIM (Structural Similarity Index) alone to evaluate image quality in the context of virtual try-off. It compares the results of an autoencoder and the TryOffDiff model. The autoencoder achieves higher SSIM scores, but produces images of significantly lower visual quality compared to TryOffDiff. The figure showcases that while SSIM might indicate high similarity in terms of pixel-level values, it fails to capture the overall perceptual quality and fidelity of the garment reconstruction. The images show that TryOffDiff produces visually superior garments despite lower SSIM scores, highlighting the need for a metric that considers both structural similarity and visual quality, such as DISTS (Deep Image Structure and Texture Similarity).
read the caption
Figure 7: Examples demonstrating the un-/suitability of performance metrics (SSIM↑ / DISTS↓) and an Autoencoer model applied to VTOFF. In each figure, left image is the ground truth image and the right image is the model prediction of Autoencoder (top, a-c) and TryOffDiff (bottom, d-f). Notice the higher SSIM scores for the Autoencoder compared to TryOffDiff despite poor visual quality of reconstructed garment images.

🔼 This figure displays qualitative results comparing different model configurations. Specifically, it contrasts the output of an Autoencoder model with other models (PixelModel, LDM-1, LDM-2, LDM-3, and TryOffDiff). Each row shows a different garment from the dataset and the corresponding outputs for the various models. This comparison helps assess the impact of different model architectures and hyperparameters on garment reconstruction quality.
read the caption
(a) Autoencoder

🔼 This figure shows the qualitative results of the PixelModel, a diffusion model operating in pixel space, from the ablation study. It displays generated garment images alongside the corresponding ground truth images. The model attempts to reconstruct the garments from a given input, illustrating its performance in capturing fine details and overall reconstruction accuracy. The results show the model has improved pixel-level details but suffers from slow inference.
read the caption
(b) PixelModel

🔼 This figure shows qualitative results for an ablation study comparing different model configurations for the Virtual Try-Off (VTOFF) task. Specifically, it presents the results of using a Latent Diffusion Model (LDM) with Stable Diffusion v3 and SigLIP-based image features. The image displays generated garment images alongside the corresponding ground truth images, allowing for a visual comparison of the model’s performance under this specific configuration.
read the caption
(c) LDM-1

🔼 This figure shows qualitative results for the LDM-2 model, one of the ablation studies comparing different model architectures. LDM-2 is a latent diffusion model using a SigLIP-B/16 image encoder, a linear plus layer normalization adapter, and DDPM scheduler. The figure shows generated images and corresponding ground truth images of various garments, illustrating the model’s performance in terms of garment reconstruction fidelity and detail preservation.
read the caption
(d) LDM-2

🔼 This figure shows the qualitative results of the LDM-3 model, one of the ablation study configurations. LDM-3 is a Latent Diffusion Model using Stable Diffusion v3, the SigLIP-B/16 image encoder, and a linear layer with layer normalization for the adapter. The results display the model’s performance on several different clothing items, showcasing generated images alongside the corresponding ground truth images. The visual comparison highlights the model’s success in reconstructing the garment and its details, while also revealing its limitations and room for improvement.
read the caption
(e) LDM-3

🔼 This figure shows the results of the TryOffDiff model on a garment image. TryOffDiff is a novel model proposed in this paper to generate standardized garment images from single photos of clothed individuals. The figure showcases the high-fidelity garment reconstruction capabilities of TryOffDiff, accurately capturing garment shape, texture, and intricate patterns.
read the caption
(f) TryOffDiff

🔼 This figure shows the ground truth garment image corresponding to the reference image used as input in the virtual try-off task. It displays the garment on a neutral background, in a standardized pose, showcasing the garment’s true details and appearance without any variations from other images or stylistic choices.
read the caption
(g) Target

🔼 This figure provides a qualitative comparison of the results obtained using various configurations explored in the ablation study described in the paper. The ablation study investigated the impact of different components of TryOffDiff, including the image encoder, adapter design, and training methods. Each row presents results for a specific garment type. The columns represent different model configurations: (a) Autoencoder, (b) PixelModel, (c) LDM-1, (d) LDM-2, (e) LDM-3, (f) TryOffDiff, and (g) the ground truth. By visually comparing the generated images across different configurations, the reader can assess the effectiveness of each component and the overall performance of the proposed TryOffDiff model. More quantitative details on these configurations are available in Table 2.
read the caption
Figure 8: Qualitative comparison between different configurations explored in our ablation study. See also Table 2 for more details.

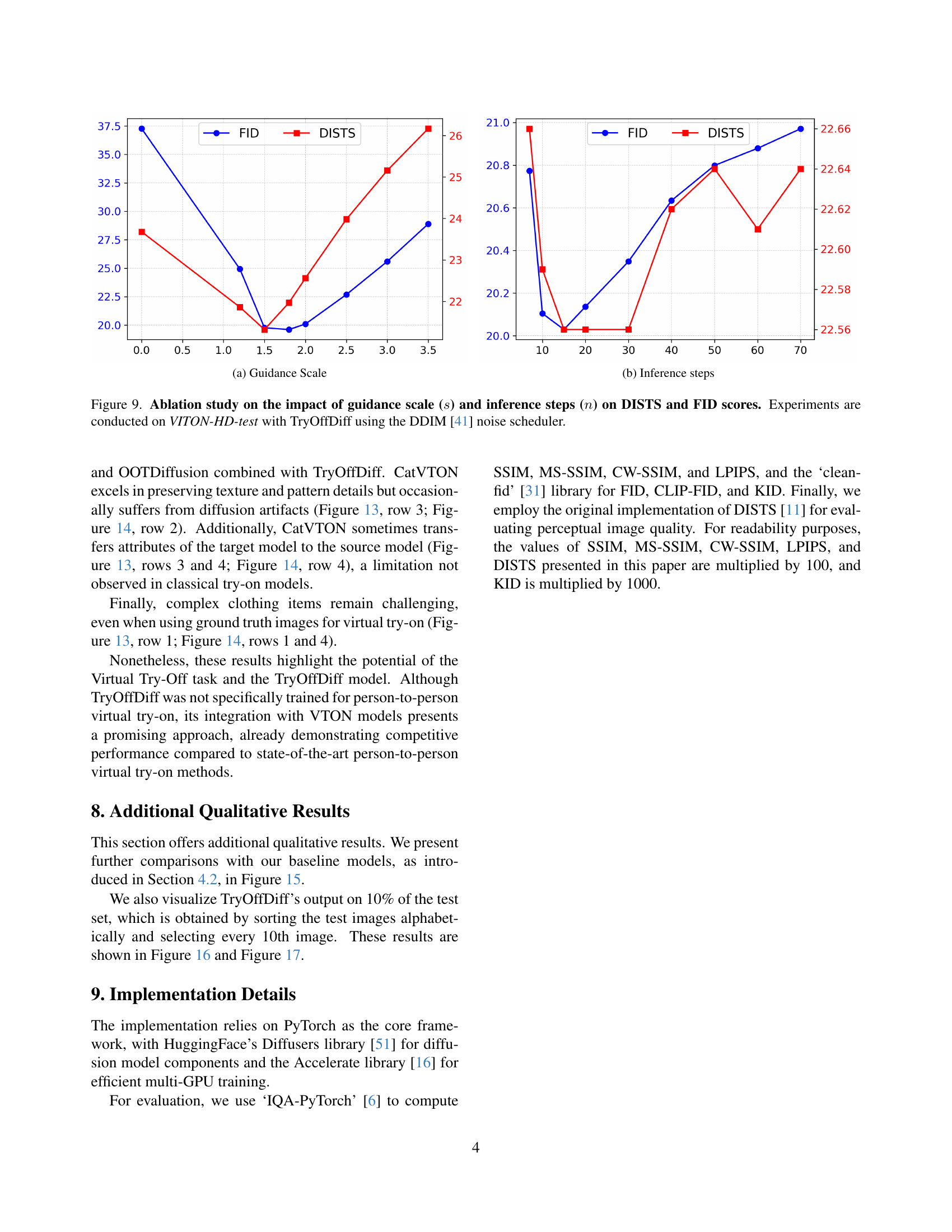
🔼 This figure shows the impact of varying guidance scales on FID and DISTS scores. The x-axis represents the guidance scale, while the y-axis shows the FID and DISTS scores. Different lines represent the FID and DISTS values at different guidance scales. The results reveal how the choice of guidance scale affects both the image quality (FID) and the structural and textural similarity to the ground truth (DISTS). A proper balance needs to be found between the two, as very low guidance scales result in blurry images (poor FID and higher DISTS) and very high guidance scales make the images too similar to the reference images (good FID and higher DISTS).
read the caption
(a) Guidance Scale

🔼 The figure shows the impact of varying the number of inference steps on the FID and DISTS scores. The experiment uses the TryOffDiff model with the DDIM noise scheduler. The x-axis represents the number of inference steps, while the y-axis shows the FID and DISTS scores. The graph illustrates how the model’s performance changes as the number of inference steps increases. This helps to determine an optimal balance between computational cost and image quality.
read the caption
(b) Inference steps

🔼 This ablation study analyzes how the guidance scale and the number of inference steps used in the TryOffDiff model affect the FID and DISTS scores. The experiment uses the DDIM noise scheduler and is performed on the VITON-HD test dataset.
read the caption
Figure 9: Ablation study on the impact of guidance scale (s𝑠sitalic_s) and inference steps (n𝑛nitalic_n) on DISTS and FID scores. Experiments are conducted on VITON-HD-test with TryOffDiff using the DDIM [41] noise scheduler.

🔼 This figure displays the impact of different guidance scales on the generated garment images. The leftmost column shows the results without any guidance, demonstrating the baseline reconstruction performance. The center columns showcase results across a range of guidance scales, from 1.2 to 3.5, illustrating how increasing guidance scales affects image detail, realism, and adherence to the reference. The rightmost column displays the ground truth images for comparison, highlighting the quality of reconstruction achieved with different levels of guidance.
read the caption
Figure 10: Qualitative results for different guidance. Left: no guidance applied (s=0𝑠0s=0italic_s = 0). Middle: varying guidance scale (s∈[1.2,1.5,1.8,2.0,2.5,3.0,3.5]𝑠1.21.51.82.02.53.03.5s\in[1.2,1.5,1.8,2.0,2.5,3.0,3.5]italic_s ∈ [ 1.2 , 1.5 , 1.8 , 2.0 , 2.5 , 3.0 , 3.5 ]). Right: ground-truth.

🔼 This figure shows the results of multiple inference runs using the TryOffDiff model on the same input image. The goal is to demonstrate the model’s consistency in generating garment reconstructions. While minor variations in shape and pattern might appear, particularly with complex garments, the overall output is highly consistent across multiple runs, showcasing the model’s reliability despite different random seed initializations for each run.
read the caption
Figure 11: Sample Variations. While minor variations in shape and pattern may occur with complex garments, the overall output of TryOffDiff demonstrates consistent garment reconstructions across multiple inference runs with different random seeds.

🔼 This figure shows the results of multiple inference runs of the TryOffDiff model on the same input image. Despite using different random seeds for each run, the generated garment images exhibit high consistency in terms of overall shape and pattern. Minor variations are observed for complex garment designs but these are minimal and do not impact the overall reconstruction quality. This consistency demonstrates the robustness and reliability of the TryOffDiff model.
read the caption
Figure 12: Sample Variations. While minor variations in shape and pattern may occur with complex garments, the overall output of TryOffDiff demonstrates consistent garment reconstructions across multiple inference runs with different random seeds.
More on tables
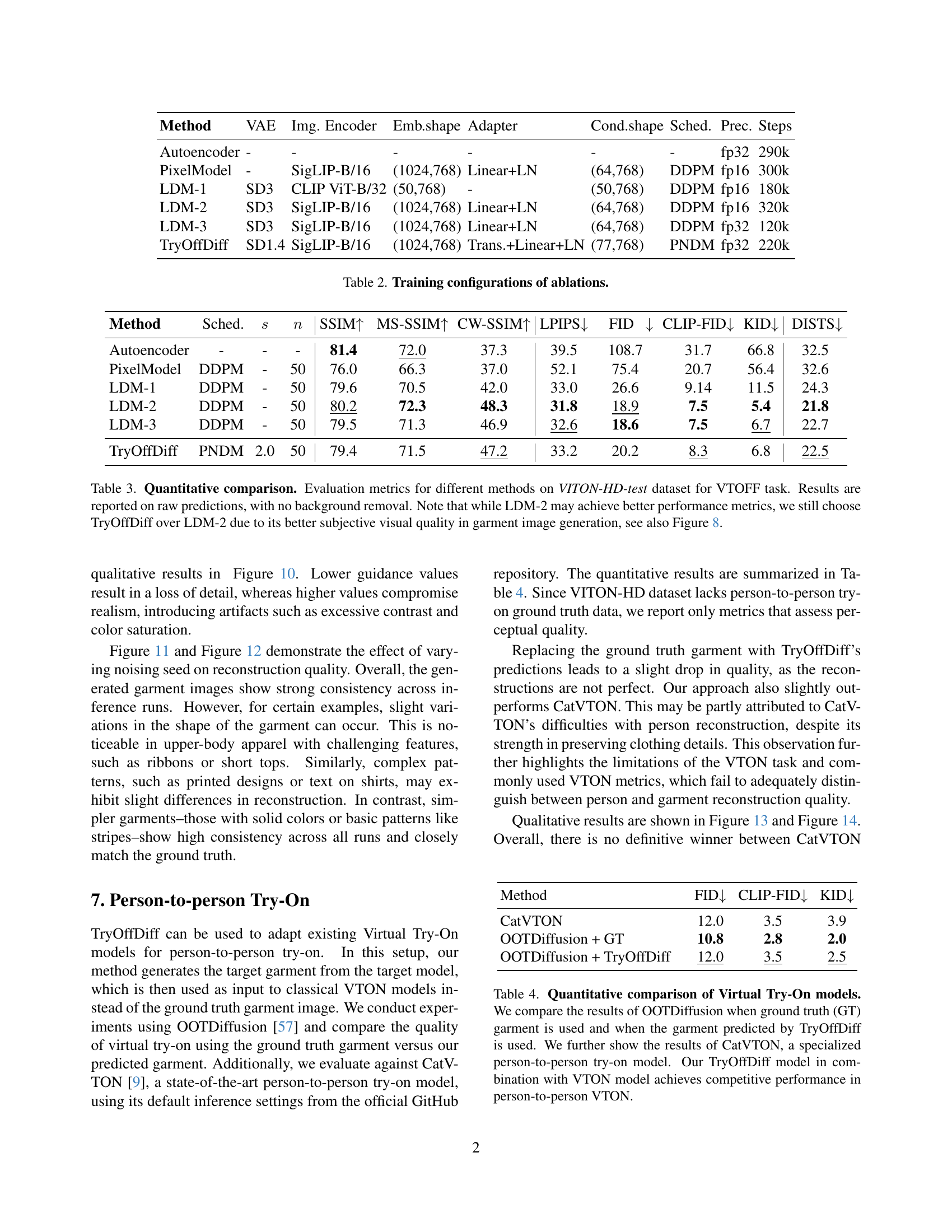
| Method | VAE | Img. Encoder | Emb.shape | Adapter | Cond.shape | Sched. | Prec. | Steps |
|---|---|---|---|---|---|---|---|---|
| Autoencoder | - | - | - | - | - | - | fp32 | 290k |
| PixelModel | - | SigLIP-B/16 | (1024,768) | Linear+LN | (64,768) | DDPM | fp16 | 300k |
| LDM-1 | SD3 | CLIP ViT-B/32 | (50,768) | - | (50,768) | DDPM | fp16 | 180k |
| LDM-2 | SD3 | SigLIP-B/16 | (1024,768) | Linear+LN | (64,768) | DDPM | fp16 | 320k |
| LDM-3 | SD3 | SigLIP-B/16 | (1024,768) | Linear+LN | (64,768) | DDPM | fp32 | 120k |
| TryOffDiff | SD1.4 | SigLIP-B/16 | (1024,768) | Trans.+Linear+LN | (77,768) | PNDM | fp32 | 220k |
🔼 This table details the different configurations used in the ablation study for the TryOffDiff model. It lists the model type (Autoencoder, PixelModel, various Latent Diffusion Models (LDMs), and the final TryOffDiff model), the image encoder used (VAE, SigLIP), the embedding shape, the adapter type (Linear+LN or Transformer+Linear+LN), conditional shape, the scheduler used (DDPM or PNDM), the precision (fp16 or fp32), and the number of training steps.
read the caption
Table 2: Training configurations of ablations.
| Method | Sched. | s | n | SSIM ↑ | MS-SSIM ↑ | CW-SSIM ↑ | LPIPS ↓ | FID ↓ | CLIP-FID ↓ | KID ↓ | DISTS ↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Autoencoder | - | - | - | 81.4 | 72.0 | 37.3 | 39.5 | 108.7 | 31.7 | 66.8 | 32.5 |
| PixelModel | DDPM | - | 50 | 76.0 | 66.3 | 37.0 | 52.1 | 75.4 | 20.7 | 56.4 | 32.6 |
| LDM-1 | DDPM | - | 50 | 79.6 | 70.5 | 42.0 | 33.0 | 26.6 | 9.14 | 11.5 | 24.3 |
| LDM-2 | DDPM | - | 50 | 80.2 | 72.3 | 48.3 | 31.8 | 18.9 | 7.5 | 5.4 | 21.8 |
| LDM-3 | DDPM | - | 50 | 79.5 | 71.3 | 46.9 | 32.6 | 18.6 | 7.5 | 6.7 | 22.7 |
| TryOffDiff | PNDM | 2.0 | 50 | 79.4 | 71.5 | 47.2 | 33.2 | 20.2 | 8.3 | 6.8 | 22.5 |
🔼 This table presents a quantitative comparison of different models on the Virtual Try-Off (VTOFF) task using the VITON-HD test dataset. The models are evaluated using several metrics including SSIM (structural similarity index), MS-SSIM (multi-scale SSIM), CW-SSIM (complex wavelet SSIM), LPIPS (Learned Perceptual Image Patch Similarity), FID (Fréchet Inception Distance), CLIP-FID, KID (Kernel Inception Distance), and DISTS (Deep Image Structure and Texture Similarity). The results are based on raw model outputs without any post-processing for background removal. Although one model (LDM-2) achieves slightly better numerical results in some metrics, TryOffDiff is preferred due to its superior subjective visual quality, which is supported by a visual comparison shown in Figure 8 of the paper.
read the caption
Table 3: Quantitative comparison. Evaluation metrics for different methods on VITON-HD-test dataset for VTOFF task. Results are reported on raw predictions, with no background removal. Note that while LDM-2 may achieve better performance metrics, we still choose TryOffDiff over LDM-2 due to its better subjective visual quality in garment image generation, see also Figure 8.
| Method | FID ↓ | CLIP-FID ↓ | KID ↓ | |||||
|---|---|---|---|---|---|---|---|---|
| CatVTON | 12.0 | 3.5 | 3.9 | |||||
| OOTDiffusion + GT | 10.8 | 2.8 | 2.0 | |||||
| OOTDiffusion + TryOffDiff | 12.0 | 3.5 | 2.5 |
🔼 This table compares the performance of different virtual try-on (VTON) models on a person-to-person try-on task. It shows the results using three metrics (FID, CLIP-FID, KID) for three different approaches: 1) OOTDiffusion with ground truth garment images, 2) OOTDiffusion using garment images generated by TryOffDiff, and 3) CatVTON (a state-of-the-art person-to-person VTON model). The comparison highlights the effectiveness of using TryOffDiff’s generated garment images as input for VTON, demonstrating competitive performance compared to using ground truth images and a dedicated person-to-person VTON model.
read the caption
Table 4: Quantitative comparison of Virtual Try-On models. We compare the results of OOTDiffusion when ground truth (GT) garment is used and when the garment predicted by TryOffDiff is used. We further show the results of CatVTON, a specialized person-to-person try-on model. Our TryOffDiff model in combination with VTON model achieves competitive performance in person-to-person VTON.
Full paper#