↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current diffusion models struggle to generate high-resolution images without retraining, leading to computational costs and repetitive patterns. Existing solutions often introduce artifacts or significant latency overheads.
FAM Diffusion tackles this by introducing two simple yet effective modules: Frequency Modulation (FM), improving global structure by leveraging the Fourier domain and Attention Modulation (AM), enhancing local texture consistency using attention maps. This single-pass method seamlessly integrates with existing models, achieving state-of-the-art results in image quality and speed without the need for additional training or architectural modifications.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient method for generating high-resolution images using pre-trained diffusion models without retraining. This addresses a significant limitation of current diffusion models and opens up new avenues for research in high-resolution image synthesis. The method’s simplicity and efficiency make it highly practical for real-world applications, and its state-of-the-art performance makes it a valuable contribution to the field. Furthermore, the focus on addressing both global and local image inconsistencies is a crucial contribution that many previous methods fail to fully account for.
Visual Insights#

🔼 This figure shows a comparison of different high-resolution image generation methods, all based on Stable Diffusion. Specifically, it compares (a) direct inference at 3x the training resolution, showing significant artifacts and repetitive patterns; (b) the DemoFusion approach, which exhibits improved global structure but still suffers from minor artifacts; (c) HiDiffusion, which shows a one-pass method with artifacts and image distortions; and (d) the proposed FAM diffusion method, demonstrating the substantial improvements in both global structure and local texture detail compared to other methods.
read the caption
(a)
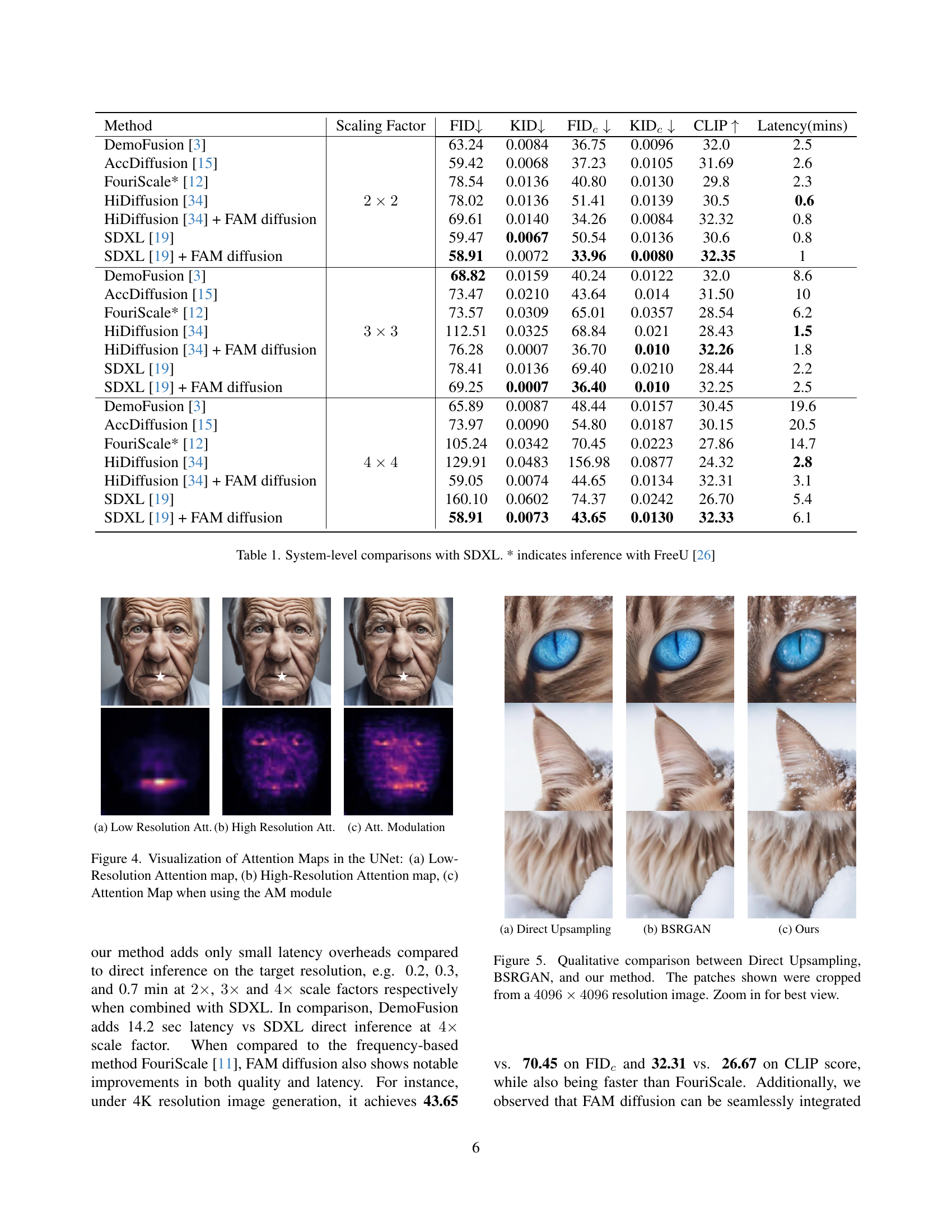
| Method | Scaling Factor | FID↓ | KID↓ | FIDc↓ | KIDc↓ | CLIP↑ | Latency(mins) |
|---|---|---|---|---|---|---|---|
| DemoFusion [3] | 2×2 | 63.24 | 0.0084 | 36.75 | 0.0096 | 32.0 | 2.5 |
| AccDiffusion [15] | 59.42 | 0.0068 | 37.23 | 0.0105 | 31.69 | 2.6 | |
| FouriScale* [12] | 78.54 | 0.0136 | 40.80 | 0.0130 | 29.8 | 2.3 | |
| HiDiffusion [34] | 78.02 | 0.0136 | 51.41 | 0.0139 | 30.5 | 0.6 | |
| HiDiffusion [34] + FAM diffusion | 69.61 | 0.0140 | 34.26 | 0.0084 | 32.32 | 0.8 | |
| SDXL [19] | 59.47 | 0.0067 | 50.54 | 0.0136 | 30.6 | 0.8 | |
| SDXL [19] + FAM diffusion | 58.91 | 0.0072 | 33.96 | 0.0080 | 32.35 | 1 | |
| DemoFusion [3] | 3×3 | 68.82 | 0.0159 | 40.24 | 0.0122 | 32.0 | 8.6 |
| AccDiffusion [15] | 73.47 | 0.0210 | 43.64 | 0.014 | 31.50 | 10 | |
| FouriScale* [12] | 73.57 | 0.0309 | 65.01 | 0.0357 | 28.54 | 6.2 | |
| HiDiffusion [34] | 112.51 | 0.0325 | 68.84 | 0.021 | 28.43 | 1.5 | |
| HiDiffusion [34] + FAM diffusion | 76.28 | 0.0007 | 36.70 | 0.010 | 32.26 | 1.8 | |
| SDXL [19] | 78.41 | 0.0136 | 69.40 | 0.0210 | 28.44 | 2.2 | |
| SDXL [19] + FAM diffusion | 69.25 | 0.0007 | 36.40 | 0.010 | 32.25 | 2.5 | |
| DemoFusion [3] | 4×4 | 65.89 | 0.0087 | 48.44 | 0.0157 | 30.45 | 19.6 |
| AccDiffusion [15] | 73.97 | 0.0090 | 54.80 | 0.0187 | 30.15 | 20.5 | |
| FouriScale* [12] | 105.24 | 0.0342 | 70.45 | 0.0223 | 27.86 | 14.7 | |
| HiDiffusion [34] | 129.91 | 0.0483 | 156.98 | 0.0877 | 24.32 | 2.8 | |
| HiDiffusion [34] + FAM diffusion | 59.05 | 0.0074 | 44.65 | 0.0134 | 32.31 | 3.1 | |
| SDXL [19] | 160.10 | 0.0602 | 74.37 | 0.0242 | 26.70 | 5.4 | |
| SDXL [19] + FAM diffusion | 58.91 | 0.0073 | 43.65 | 0.0130 | 32.33 | 6.1 |
🔼 This table presents a quantitative comparison of different high-resolution image generation methods, using SDXL (Stable Diffusion XL) as the baseline model. It compares the performance of several approaches, including DemoFusion, AccDiffusion, FouriScale, and HiDiffusion, against the proposed FAM Diffusion method. The comparison is performed across three different scaling factors (2x, 3x, and 4x), which represent the increase in resolution relative to the SDXL training resolution. The metrics used for evaluation are FID (Frechet Inception Distance), KID (Kernel Inception Distance), and CLIP score, measuring image quality, diversity, and alignment with the text prompt, respectively. Latency, or processing time, is also included, reflecting computational efficiency. The asterisk (*) indicates instances where the FreeU method was used for inference.
read the caption
Table 1: System-level comparisons with SDXL. * indicates inference with FreeU [26]
In-depth insights#
Freq Modulation Boost#
A hypothetical “Freq Modulation Boost” section in a research paper on image generation would likely delve into techniques for enhancing frequency components within generated images. This could involve adjusting the balance between low and high frequencies to control aspects like global structure versus fine details. Low frequencies contribute to the overall image layout and large-scale features, while high frequencies are responsible for sharp edges, textures, and fine details. The core idea would be to manipulate the frequency spectrum to improve image quality and realism. This might involve techniques such as applying filters in the Fourier domain, modifying existing networks’ processing of frequency components, or other advanced signal processing methods. Successfully boosting frequency modulation could lead to improvements in image sharpness, texture clarity, and overall visual fidelity, potentially overcoming limitations of existing generative models which often struggle to generate high-frequency details accurately. The effectiveness of such a boost would likely be measured by quantitative metrics like FID and KID, as well as qualitative assessments based on visual inspection. Efficient implementation, minimizing computational overhead, would be another critical aspect to explore within this section.
Attention’s Sharp Focus#
The concept of “Attention’s Sharp Focus” in the context of a research paper likely refers to mechanisms that enhance the precision and efficiency of attention mechanisms in deep learning models. A key aspect would be how the model selectively attends to the most relevant parts of the input, minimizing distractions from less pertinent information. This could involve novel architectural designs that guide attention more effectively or the incorporation of techniques that filter out irrelevant details. The paper likely explores methods for achieving this sharp focus, perhaps through improved attention weighting strategies, enhanced feature representation, or the use of advanced filtering techniques. A focus on “sharpness” suggests that the research delves into reducing ambiguity in attention allocation, thereby improving the model’s performance on tasks requiring fine-grained analysis of input data. This is crucial for improving accuracy, particularly in high-resolution image generation where distinguishing subtle differences is vital. The results section would likely demonstrate the benefits of this sharpened attention, showcasing improved accuracy, speed, and efficiency, compared to traditional attention mechanisms or less focused approaches.
High-Res Diffusion#
High-resolution image generation using diffusion models presents challenges due to the computational cost of retraining and the tendency for artifacts at resolutions beyond the training set. Existing methods often rely on patch-based approaches or architectural modifications, leading to latency issues or compromised image quality. A promising direction involves leveraging pretrained models and employing test-time strategies to adapt to higher resolutions. This necessitates mechanisms to effectively control both global structure and local texture consistency during the generation process, without extensive retraining or adding significant computational overhead. Successful approaches would seamlessly integrate with existing architectures, offering a flexible and efficient solution for generating high-resolution images from pretrained diffusion models.
Ablation Study: FM vs AM#
An ablation study comparing the Frequency Modulation (FM) and Attention Modulation (AM) modules would be crucial for understanding their individual contributions to high-resolution image generation. FM’s role is to address global structural inconsistencies, leveraging low-frequency components to guide the generation process while allowing high-frequency components for detail. AM aims to correct inconsistencies in local textures. It uses attention maps from the native resolution to regularize the high-resolution denoising. The study should isolate each module’s impact—evaluating image quality metrics (FID, KID, CLIP scores) with only FM, only AM, and then both combined. The results will determine if they complement each other, providing superior results compared to using either independently, or if one is more dominant than the other in improving image quality. Furthermore, the study should analyze where each module excels—does FM significantly improve global coherence, while AM primarily tackles fine details? Identifying such strengths will provide valuable insight into designing future high-resolution image generation systems. Analyzing computational costs of FM and AM is also essential to assess their practicality in real-world applications.
Latency & Efficiency#
The research paper highlights the critical issue of latency in high-resolution image generation using diffusion models. Traditional methods, like retraining at higher resolutions or patch-based generation, suffer from significant latency overheads. The proposed FAM diffusion method directly addresses this by employing a single-pass generation strategy. This avoids redundant computations associated with previous approaches, resulting in negligible latency overheads. The authors achieve this without sacrificing image quality through their novel Frequency and Attention Modulation modules. This demonstrates a significant improvement in efficiency compared to existing methods, making high-resolution image generation more practical and accessible for various applications. The efficiency gains are further substantiated by quantitative results, showcasing superior performance in terms of speed without compromising quality.
More visual insights#
More on figures

🔼 This figure shows the details of the Frequency Modulation (FM) module. The FM module uses the Fourier transform to selectively condition low-frequency components during high-resolution denoising while keeping high-frequency components fully controllable. The input is the upsampled native resolution image and the diffused high-resolution image. The Fourier transform is applied to both. Low-frequency components from the native resolution image are selectively combined with high-frequency components from the diffused high-resolution image using a high-pass filter K(t). Finally, the inverse Fourier transform is applied to obtain the resulting image.
read the caption
(b)

🔼 This figure shows the results of applying different high-resolution image generation methods to a single image. (a) is the result of direct inference at high resolution, demonstrating artifacts due to upscaling. (b) represents the results from DemoFusion which employs a patch-based approach to generation that attempts to improve global consistency. However, this still produces repetitive patterns and artifacts. (c) shows the results from HiDiffusion, which modifies the architecture of the model to improve speed but at the cost of image quality. (d) displays the output of FAM Diffusion which uses a Frequency Modulation (FM) module and an Attention Modulation (AM) module to enhance both global structure and local consistency, resulting in a superior image quality.
read the caption
(c)

🔼 This figure shows the results of image generation at 3x the native resolution (3072x3072 pixels) using different methods. (a) shows the result of directly inferring from noise at the target resolution, resulting in severe artifacts. (b) shows the result of DemoFusion, which reduces artifacts compared to (a) but still shows inconsistencies in local patterns. (c) shows the results of HiDiffusion, which has better efficiency but still exhibits visible artifacts. (d) shows the result of the proposed method, FAM diffusion, which effectively addresses both structural and local artifacts, resulting in a visually appealing image.
read the caption
(d)

🔼 This figure shows a comparison of different methods for generating high-resolution (3072x3072 pixels, 3x the resolution of the training data) images using the Stable Diffusion model SDXL. It highlights the artifacts and issues that arise when directly scaling up the resolution of pre-trained diffusion models, such as repetitive patterns and structural distortions. The figure compares the quality of images generated by: (a) Direct Inference: Generating an image directly at the high resolution without any special modifications, revealing many artifacts. (b) DemoFusion: A method that improves global structure consistency using a multi-patch approach. (c) HiDiffusion: A method that modifies the architecture of the diffusion model for faster inference. (d) Ours (FAM Diffusion): The proposed method, which leverages frequency and attention modulation to address both global structure and local texture consistency. The comparison showcases the superior results of the proposed FAM diffusion method.
read the caption
Figure 1: Comparisons of 3× (3072 × 3072) image generation based on SDXL [19].

🔼 This figure illustrates the FAM diffusion process, which enhances high-resolution image generation. Panel (a) provides a high-level overview showing the generation of a native resolution image, followed by a test-time diffuse-denoise process incorporating Frequency Modulation (FM) and Attention Modulation (AM) modules to improve global structure and fine local texture, respectively. Panel (b) details the FM module, which uses the Fourier domain to selectively condition low-frequency components during high-resolution denoising. Panel (c) details the AM module, leveraging attention maps from native resolution denoising to correct high-resolution denoising, thereby ensuring consistent local textures.
read the caption
Figure 2: Overview of the FAM diffusion. (a) We first generate an image at native resolution, followed by a test-time diffuse-denoise process. We incorporate our Frequency Modulation module and Attention Modulation during high-res denoising to control global structure and fine local texture, respectively. (b) Details of the Frequency Modulation, where we use the Fourier domain to selectively condition low-frequency components during high-res denoising while leaving high-frequency components fully controllable. (c) Details of Attention Modulation, where attention maps from the native image denoising are used to correct the high-res denoising.

🔼 This figure shows a comparison of different methods for high-resolution image generation. Specifically, it compares the results of direct inference (generating the image directly at a high resolution, leading to artifacts), DemoFusion (a patch-based method that tries to improve global consistency), HiDiffusion (a single-pass method that alters the model architecture, leading to potential quality trade-offs), and FAM Diffusion (the proposed method, which combines frequency and attention modulation for improved results). Each method generates a 3x upscaled image (3072x3072) from the same prompt, showcasing FAM Diffusion’s superior image quality and improved resolution compared to existing methods. The differences are clearly visible in the quality and consistency of the output images.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. The FM module uses the Fourier transform to separate the input latent representation into low and high-frequency components. The low-frequency components, representing the global structure of the image, are selectively steered towards the image generated at the native resolution. In contrast, the high-frequency components, responsible for fine details and textures, are left fully controllable by the denoising process. This selective conditioning ensures that the generated image maintains global consistency while preserving fine details and preventing artifacts.
read the caption
(b)

🔼 This figure shows a comparison of different high-resolution image generation methods based on SDXL. It highlights the artifacts and inconsistencies produced by direct inference, DemoFusion, and HiDiffusion. In contrast, it showcases the improved global consistency and local texture details generated by the proposed FAM Diffusion method. The comparison emphasizes how FAM Diffusion avoids the pattern repetitions and structural distortions prevalent in other methods, resulting in significantly enhanced image quality.
read the caption
(c)

🔼 This figure shows the results of image generation at 3x resolution (3072x3072) using the proposed FAM diffusion method. It is a comparison to demonstrate the improved quality of image generation compared to other methods. (a) shows a direct inference approach that results in poor quality and repetitive patterns. (b) shows the DemoFusion approach, which also shows artifacts and inconsistencies. (c) shows HiDiffusion, which still has some artifacts. Finally, (d) presents the results of FAM diffusion, showcasing significantly improved image quality and detail.
read the caption
(d)

🔼 This figure shows the results of the proposed FAM diffusion method on a set of images. It compares the results of the method with three other methods: Direct Inference (DI), DemoFusion, and HiDiffusion. The images generated by FAM diffusion show significantly improved quality compared to the other methods, particularly in terms of global structure consistency and local texture details. The artifacts and inconsistencies present in the other methods are effectively mitigated by FAM diffusion.
read the caption
(e)

🔼 This figure shows an ablation study on the components of the FAM diffusion model. It compares the results of different methods for generating high-resolution images: Direct Inference from noise (DI), Direct Inference from a low-resolution latent representation (DI*), Skip Residual from the DemoFusion method, Frequency Modulation (FM), and Attention Modulation (AM). Each method’s output is shown as an image and helps illustrate the contributions of different parts of the FAM diffusion model. Direct inference methods struggle with artifacts, skip residual improves it partially, while FM and AM resolve major artifacts and inconsistencies.
read the caption
Figure 3: Ablation on the components of FAM diffusion. Direct Inference (DI) at high resolution from noise, Direct Inference from low-res latent (DI*), Skip Residual (SR) from DemoFusion [3], Frequency Modulation (FM), Attention Modulation (AM).

🔼 This figure shows a comparison of different methods for generating high-resolution images (3072x3072) from a pretrained Stable Diffusion model. (a) shows the result of directly inferencing at the higher resolution, resulting in significant artifacts. (b) displays the results of DemoFusion, an existing method which attempts to generate higher resolution outputs using a patch-based method. (c) shows results using HiDiffusion, another existing method which alters the network architecture to generate higher resolutions. (d) presents the result of FAM Diffusion, demonstrating an improvement in reducing artifacts and enhancing overall image quality.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. It uses the Fourier transform to selectively condition low-frequency components during high-resolution denoising, while allowing the high-frequency components to remain fully controllable. The diagram illustrates the process: input high-resolution image undergoes a Fast Fourier Transform (FFT), then low-frequency components are modified according to a high-pass filter K(t) using the low-resolution native image, the modified low-frequency components are combined with the unchanged high-frequency components (1-K(t)) via the Hadamard product, and an inverse Fast Fourier Transform (IFFT) is applied to generate the final output. This selective conditioning helps maintain global structure while improving details.
read the caption
(b)

🔼 This figure shows a comparison of high-resolution image generation methods. Specifically, it compares direct inference (generating an image at a higher resolution than the model was trained on), DemoFusion (which attempts to improve global image consistency), and HiDiffusion (which adjusts the model architecture for faster generation at high resolutions). The goal is to illustrate the artifacts and quality differences between various approaches, highlighting the superior performance of the proposed FAM Diffusion method in both image quality and speed.
read the caption
(c)

🔼 Figure 4 visualizes the attention maps generated by the UNet within the FAM diffusion model. Panel (a) shows a low-resolution attention map, illustrating the attention weights assigned to different image regions at a lower resolution. Panel (b) shows a high-resolution attention map, which exhibits a different pattern of attention weights due to the increased resolution. Finally, panel (c) illustrates the attention map after applying the Attention Modulation (AM) module, revealing how AM refines and corrects the high-resolution map by incorporating information from the low-resolution map to improve consistency and reduce inconsistencies.
read the caption
Figure 4: Visualization of Attention Maps in the UNet: (a) Low-Resolution Attention map, (b) High-Resolution Attention map, (c) Attention Map when using the AM module

🔼 This figure shows a comparison of different methods for high-resolution image generation. (a) shows the result of directly inferring an image at 3x the training resolution of a pre-trained diffusion model (Stable Diffusion). This results in significant artifacts and repeating patterns. This demonstrates the limitations of directly upscaling a diffusion model without any modifications to handle higher resolutions. The image demonstrates the issue of object repetition and unrealistic local patterns when directly generating images at higher resolutions than used in the model’s training.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. It uses the Fourier domain to selectively control the low-frequency components during high-resolution image denoising. The high-frequency components remain fully controllable. The low-frequency components are steered towards the global structure of the image generated at the native (training) resolution. The diagram illustrates the Fast Fourier Transform (FFT) to move to the frequency domain, the selective conditioning using the filter K(t), the Inverse Fast Fourier Transform (IFFT) to return to the spatial domain, and how this process integrates with the denoising steps.
read the caption
(b)

🔼 This figure shows the ablation study on the different components of the FAM diffusion model. It compares several image generation methods using SDXL at 3x resolution (3072 x 3072). The methods shown are: (a) Direct Inference (DI) generates an image directly at the high resolution from random noise and results in significant artifacts. (b) DemoFusion uses skip residuals to steer the high-resolution generation using the native resolution image, but still produces artifacts. (c) HiDiffusion alters the model architecture for faster generation but sacrifices image quality. (d) FM (Frequency Modulation) module improves global structure consistency and resolves some artifacts. (e) FAM Diffusion utilizes both FM and AM (Attention Modulation) modules, leading to improved image quality with better preservation of global and local details. The improved local texture consistency is a main improvement of this paper.
read the caption
(c)

🔼 Figure 5 presents a qualitative comparison of three different image upscaling methods: direct upsampling, BSRGAN, and the proposed FAM diffusion method. All images shown are crops from a high-resolution (4096x4096 pixels) image, highlighting the detail produced by each method. Direct upsampling serves as a baseline, showing the limitations of a simple scaling approach. BSRGAN, a super-resolution technique, shows improved results compared to direct upsampling, but still suffers from artifacts. In contrast, the FAM diffusion method demonstrates a significant improvement in visual quality, resulting in a sharper, more realistic, and detailed image. It is recommended to zoom in on the image to fully appreciate the differences in detail and artifact reduction.
read the caption
Figure 5: Qualitative comparison between Direct Upsampling, BSRGAN, and our method. The patches shown were cropped from a 4096×4096409640964096\times 40964096 × 4096 resolution image. Zoom in for best view.

🔼 This figure shows a comparison of different high-resolution image generation methods. (a) shows the result of directly performing inference on a pre-trained diffusion model at a higher resolution than it was trained on. This leads to noticeable artifacts such as repetition of image patterns. (b) shows the results of DemoFusion, a method that attempts to improve global image structure by using the image generated at the training resolution as a guide. While showing improvement over (a), it still suffers from inconsistencies. (c) shows the results of HiDiffusion, which modifies the architecture of the diffusion model for faster generation, but at the cost of image quality. (d) shows the result of the proposed FAM diffusion method, which addresses structural and local artifacts resulting in high-quality images without noticeable latency overheads.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. The FM module uses the Fourier domain to selectively condition low-frequency components during high-resolution denoising while leaving high-frequency components fully controllable. This allows the model to preserve the global structure of the image while still allowing for fine details and textures to be generated. It shows the process, using Fast Fourier Transform (FFT) to convert the image to frequency domain, applying the filter K(t), and inverse FFT to convert back to spatial domain.
read the caption
(b)

🔼 This figure shows the results of applying the Attention Modulation (AM) module to the high-resolution image generation process. Specifically, it compares the results of direct inference (DI), direct inference from low-resolution latent (DI*), using the Skip Residual (SR) from DemoFusion, using only Frequency Modulation (FM), and finally, using both Frequency Modulation (FM) and Attention Modulation (AM). The images illustrate how the addition of the AM module significantly improves the quality of the high-resolution generation, especially concerning the consistency of local texture details.
read the caption
(c)

🔼 This figure shows the result of the proposed FAM diffusion method on a 3x upscaled image (3072x3072) compared to other methods. (a) shows the result of directly inferring an image at the upscaled resolution, resulting in noticeable artifacts. (b) shows the result of DemoFusion which uses a patch-based approach, still showing some remaining artifacts. (c) shows the result of HiDiffusion which uses a modified UNet architecture, with lower quality than the other methods. (d) shows the result of the proposed FAM diffusion method, which demonstrates improved image quality and fewer artifacts by combining frequency modulation and attention modulation.
read the caption
(d)

🔼 This figure shows the results of applying the Frequency and Attention Modulation (FAM) diffusion method. It demonstrates the improved image generation quality achieved by incorporating both FM and AM modules compared to other methods. Specifically, it highlights how FAM diffusion addresses both global structural inconsistencies and local texture artifacts that are present in other approaches such as direct inference, DemoFusion, and HiDiffusion. The figure showcases the visual advantages of the proposed method and aims to demonstrate its ability to generate more realistic and high-quality images at high resolution.
read the caption
(e)

🔼 Figure 6 presents a qualitative comparison of high-resolution image generation results from different methods, all based on the SDXL model. Three diverse text prompts are used to generate images at 2x, 3x, and 4x the native resolution of SDXL. The methods compared include DemoFusion, FouriScale (using FreeU for inference), HiDiffusion, and the proposed FAM Diffusion method. The figure highlights the visual differences in terms of image quality, coherence, and detail preservation. It showcases FAM Diffusion’s improved performance compared to other state-of-the-art techniques, particularly in generating realistic and consistent images with fine details at various resolutions. Zooming in is recommended to fully appreciate the detailed visual differences.
read the caption
Figure 6: Qualitative comparison with other methods based on SDXL. Best viewed when zoomed in. * indicates inference with FreeU [26]

🔼 This figure shows a comparison of high-resolution image generation methods. (a) Direct Inference, which directly generates images at the target high resolution without any pre-processing, resulting in artifacts and inconsistencies. This demonstrates the limitations of using standard diffusion models for high-resolution image synthesis without modification or additional training.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. The FM module leverages the Fourier domain to selectively condition low-frequency components during high-resolution denoising, while leaving high-frequency components fully controllable. This allows the model to preserve global structure while ensuring finer details are generated correctly. The diagram illustrates the process, showing how the low-frequency components from the native resolution image are combined with the high-frequency components from the high-resolution image generation process. The result is a high-resolution image that has good global structure and realistic local textures.
read the caption
(b)

🔼 This figure compares two versions of the Frequency Modulation (FM) module, a key component of the FAM diffusion model. The ‘Constant LF’ version uses a single, static low-frequency reference image throughout the denoising process. In contrast, the ‘Time-aware LF’ version dynamically updates this low-frequency information at each denoising step, using the diffused latent at that step as the reference. The visual difference showcases the improvement in detail and reduced blurriness provided by the time-varying approach.
read the caption
Figure 7: Comparison between Constant LF and Time-aware LF.

🔼 This figure shows a comparison of different high-resolution image generation methods based on Stable Diffusion. (a) Direct inference from a pre-trained model shows artifacts and repetitive patterns; (b) DemoFusion, a patch-based approach, still exhibits issues with global and local inconsistency; (c) HiDiffusion, which modifies the model architecture, also suffers from inconsistencies and artifacts; (d) The proposed FAM Diffusion method produces images with significantly improved global structure and local consistency.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. The FM module uses the Fourier transform to selectively condition low-frequency components during high-resolution denoising, while leaving high-frequency components fully controllable. This allows the model to maintain global image structure consistency while still allowing for fine details and texture variations.
read the caption
(b)

🔼 This figure compares two methods for incorporating information from native resolution attention maps into the high-resolution denoising process: attention swapping and attention modulation. Attention swapping directly replaces high-resolution attention maps with upsampled native resolution maps, while attention modulation combines information from both sources to produce a refined map. This figure visually demonstrates the differences in attention maps generated by each method, highlighting how attention modulation produces more refined attention maps that better integrate local and global information for higher quality image generation.
read the caption
Figure 8: Comparison of Attention Swapping and Modulation

🔼 This figure shows a comparison of different methods for generating high-resolution images (3072x3072) based on the SDXL model. (a) Direct inference at high resolution from noise leads to artifacts like repetitive patterns and unrealistic local textures. (b) DemoFusion (a method mentioned in the paper) improves global structure but still produces artifacts. (c) HiDiffusion generates faster but at the cost of image quality. (d) FAM Diffusion (the method proposed in the paper) generates high-quality images by resolving structural and local artifacts, showing superior results.
read the caption
(a)

🔼 This figure shows the details of the Frequency Modulation (FM) module. The FM module uses the Fourier transform to decompose an image into its frequency components. It selectively conditions the low-frequency components of the high-resolution image being generated using the information from a native resolution image (generated at the training resolution). High-frequency components, which represent finer details, are not affected, allowing the model to preserve these details in the final image. The figure visually depicts this process, showing the flow of information through the various Fourier transforms and manipulations. The goal is to ensure global structural consistency in the higher-resolution image by leveraging the structure captured in the lower-resolution image’s low frequencies while maintaining detail using higher frequencies.
read the caption
(b)

🔼 This figure shows the results of the ablation study on the components of the FAM diffusion model. It compares the image generation results of different methods: Direct Inference (DI) at high resolution from noise, Direct Inference from low-res latent (DI*), Skip Residual (SR) from DemoFusion, Frequency Modulation (FM), and Frequency and Attention Modulation (FM-AM). Each method’s result is visually compared, highlighting the strengths and weaknesses in terms of global structure consistency and local texture quality. The FM module shows improvements in global structure, while the addition of AM further enhances local texture consistency.
read the caption
(c)
More on tables
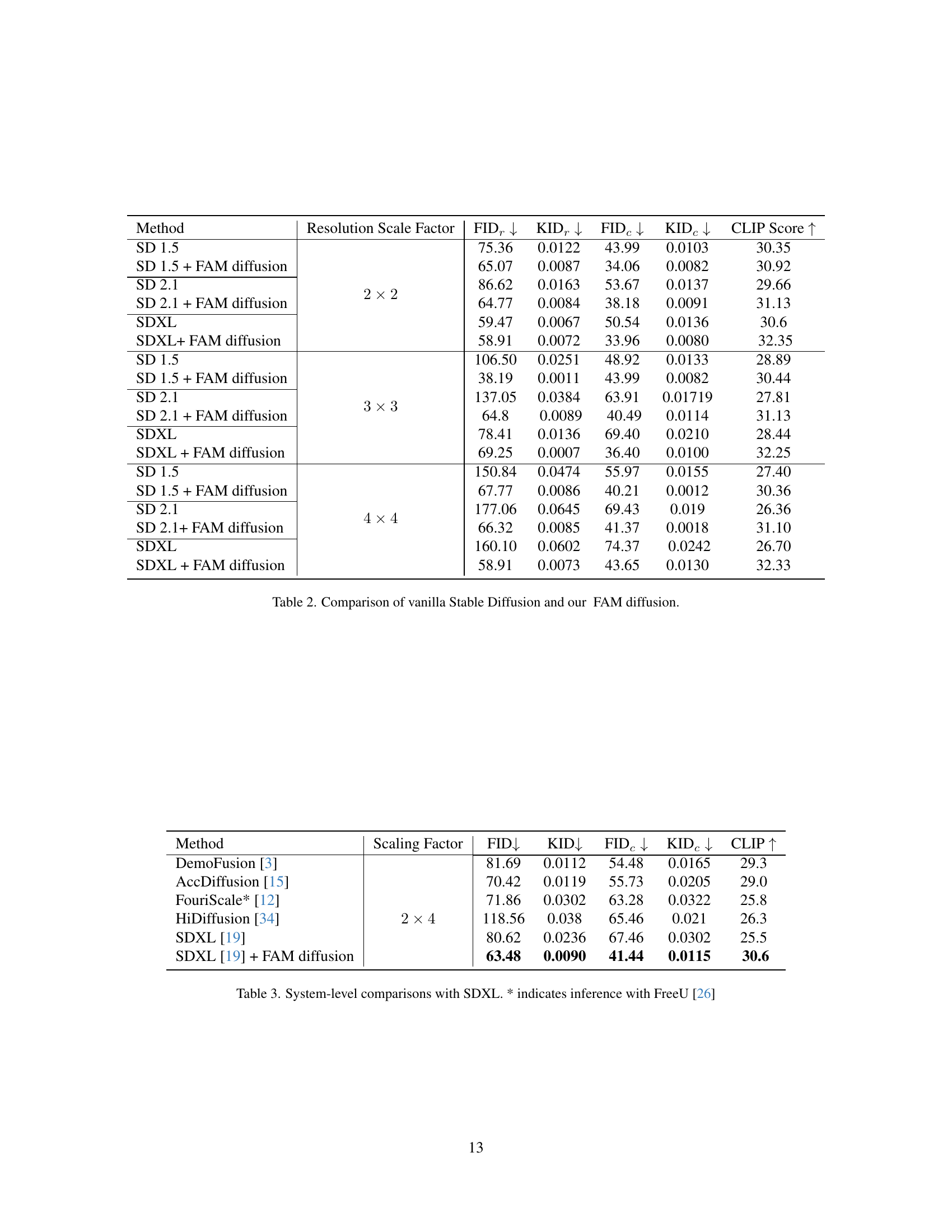
| Method | Resolution Scale Factor | FIDr ↓ | KIDr ↓ | FIDc ↓ | KIDc ↓ | CLIP Score ↑ |
|---|---|---|---|---|---|---|
| SD 1.5 | 2 × 2 | 75.36 | 0.0122 | 43.99 | 0.0103 | 30.35 |
| SD 1.5 + FAM diffusion | 65.07 | 0.0087 | 34.06 | 0.0082 | 30.92 | |
| SD 2.1 | 86.62 | 0.0163 | 53.67 | 0.0137 | 29.66 | |
| SD 2.1 + FAM diffusion | 64.77 | 0.0084 | 38.18 | 0.0091 | 31.13 | |
| SDXL | 59.47 | 0.0067 | 50.54 | 0.0136 | 30.6 | |
| SDXL + FAM diffusion | 58.91 | 0.0072 | 33.96 | 0.0080 | 32.35 | |
| SD 1.5 | 3 × 3 | 106.50 | 0.0251 | 48.92 | 0.0133 | 28.89 |
| SD 1.5 + FAM diffusion | 38.19 | 0.0011 | 43.99 | 0.0082 | 30.44 | |
| SD 2.1 | 137.05 | 0.0384 | 63.91 | 0.01719 | 27.81 | |
| SD 2.1 + FAM diffusion | 64.8 | 0.0089 | 40.49 | 0.0114 | 31.13 | |
| SDXL | 78.41 | 0.0136 | 69.40 | 0.0210 | 28.44 | |
| SDXL + FAM diffusion | 69.25 | 0.0007 | 36.40 | 0.0100 | 32.25 | |
| SD 1.5 | 4 × 4 | 150.84 | 0.0474 | 55.97 | 0.0155 | 27.40 |
| SD 1.5 + FAM diffusion | 67.77 | 0.0086 | 40.21 | 0.0012 | 30.36 | |
| SD 2.1 | 177.06 | 0.0645 | 69.43 | 0.019 | 26.36 | |
| SD 2.1 + FAM diffusion | 66.32 | 0.0085 | 41.37 | 0.0018 | 31.10 | |
| SDXL | 160.10 | 0.0602 | 74.37 | 0.0242 | 26.70 | |
| SDXL + FAM diffusion | 58.91 | 0.0073 | 43.65 | 0.0130 | 32.33 |
🔼 This table presents a quantitative comparison of image generation results between vanilla Stable Diffusion models (SD 1.5, SD 2.1, and SDXL) and the same models enhanced with the proposed FAM diffusion method. For each model and three different upscaling factors (2x, 3x, 4x), the table reports the Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and CLIP score. Lower FID and KID scores indicate better image quality, while a higher CLIP score represents better alignment between the generated image and the input text prompt. This comparison demonstrates the improvement in image quality and text-image consistency achieved by incorporating FAM diffusion into existing Stable Diffusion models.
read the caption
Table 2: Comparison of vanilla Stable Diffusion and our FAM diffusion.
| Method | Scaling Factor | FID↓ | KID↓ | FIDc↓ | KIDc↓ | CLIP↑ |
|---|---|---|---|---|---|---|
| DemoFusion [3] | 2×4 | 81.69 | 0.0112 | 54.48 | 0.0165 | 29.3 |
| AccDiffusion [15] | 70.42 | 0.0119 | 55.73 | 0.0205 | 29.0 | |
| FouriScale* [12] | 71.86 | 0.0302 | 63.28 | 0.0322 | 25.8 | |
| HiDiffusion [34] | 118.56 | 0.038 | 65.46 | 0.021 | 26.3 | |
| SDXL [19] | 80.62 | 0.0236 | 67.46 | 0.0302 | 25.5 | |
| SDXL [19] + FAM diffusion | 63.48 | 0.0090 | 41.44 | 0.0115 | 30.6 |
🔼 This table presents a quantitative comparison of different high-resolution image generation methods using the Stable Diffusion model (SDXL). It shows the FID (Frechet Inception Distance), KID (Kernel Inception Distance), and CLIP scores for each method, at different scaling factors (2x, 3x, 4x). Lower FID and KID scores indicate better image quality and higher CLIP scores indicate a better alignment between generated images and text prompts. The methods compared include DemoFusion, AccDiffusion, FouriScale, and HiDiffusion. Results for SDXL alone and SDXL combined with the proposed FAM Diffusion method are also included. The asterisk (*) indicates that FreeU was used for inference in the FouriScale method.
read the caption
Table 3: System-level comparisons with SDXL. * indicates inference with FreeU [26]
Full paper#