↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current state-of-the-art video object segmentation models like SAM 2 are computationally expensive, hindering their use on mobile devices. Their large multistage image encoders and memory modules contribute to high latency. This is a significant obstacle for real-world applications requiring on-device processing.
The paper introduces EfficientTAMs, lightweight models that address these limitations. It replaces the complex image encoder with a simpler, more efficient Vanilla Vision Transformer (ViT), and it introduces a memory module with a faster cross-attention method. The results show that these improvements achieve comparable accuracy to SAM 2 but with a significant speed increase (approximately 2x on A100 GPUs and 2.4x parameter reduction) and robust performance even on mobile devices (~10 FPS on iPhone 15 Pro Max).
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and video object segmentation as it addresses the efficiency limitations of existing state-of-the-art models. Its efficient approach, using lightweight networks and a novel cross-attention mechanism, makes high-quality video object segmentation possible on resource-constrained devices. This opens exciting possibilities for deploying such systems in real-world applications like mobile devices and edge computing, driving innovation across diverse fields. The findings also provide valuable insights into designing efficient vision transformers, influencing future research in memory-efficient deep learning.
Visual Insights#

🔼 This figure presents a comparative analysis of EfficientTAM and SAM 2, focusing on speed and efficiency in video object segmentation. The left panel shows a speed comparison on a single NVIDIA A100 GPU, highlighting EfficientTAM’s ability to process frames much faster than SAM 2, enabling on-device deployment (261ms per frame on an iPhone 15 Pro Max). The right panel provides a comprehensive comparison of EfficientTAM, SAM 2, and other efficient models on the SA-V test dataset. It compares frames per second (FPS), model parameters, and performance metrics, demonstrating EfficientTAM’s competitive performance and efficiency advantages.
read the caption
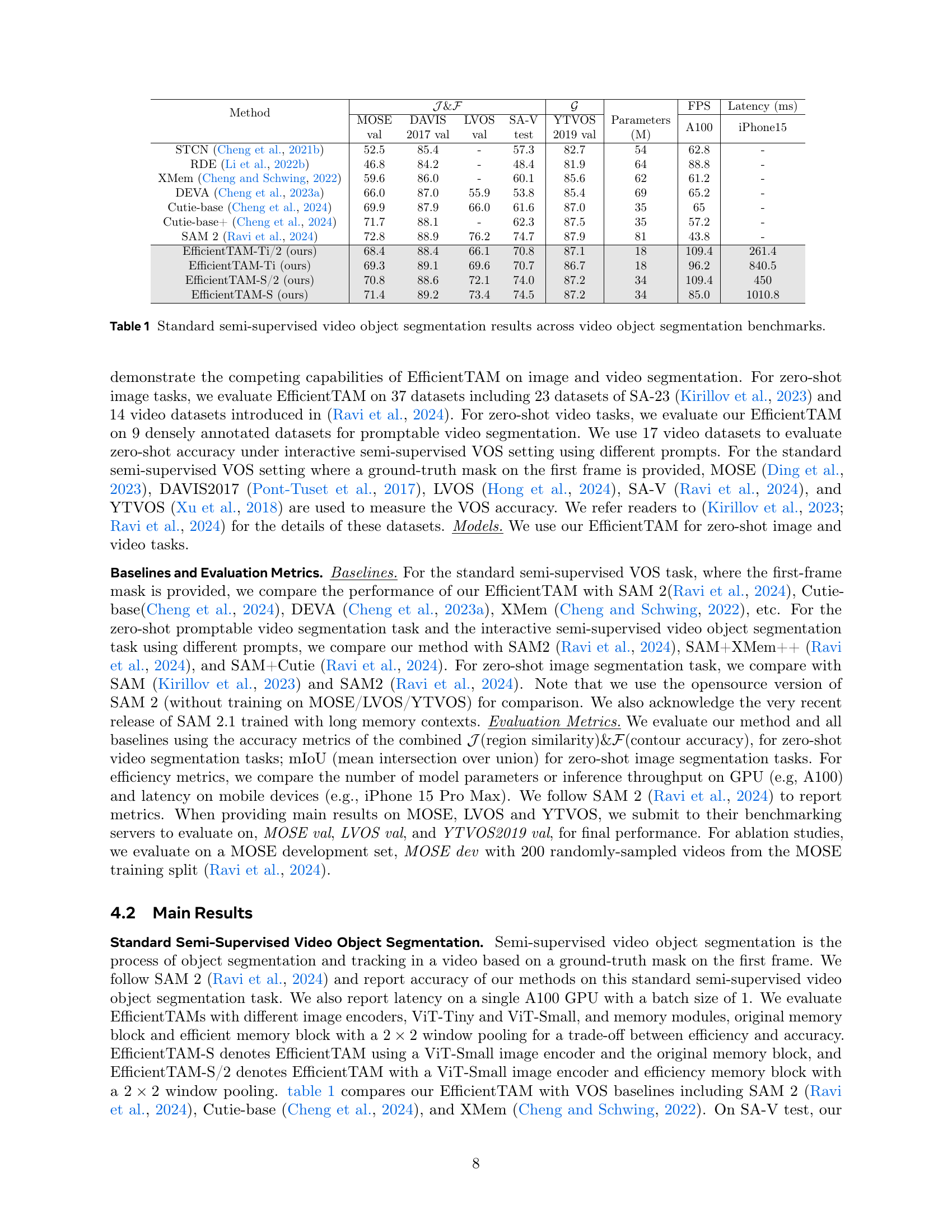
Figure 1: Comparative analysis. (Left) Speed comparison between EfficientTAM and SAM 2 on a single NVIDIA A100 GPU. While SAM 2 is challenging for on-device deployment, our EfficientTAM can run 261 ms per frame on iPhone 15 Pro Max. (Right) FPS/Parameter/Performance comparison of EfficientTAM, SAM 2, and other efficient models for zero-shot video object segmentation on SA-V test. We benchmark FPS (frames per second) of all models with 1024 × 1024 input resolution on a single NVIDIA A100.
| Method | \mathcal{J} & \mathcal{F} | \mathcal{G} | Parameters (M) | FPS | Latency (ms) | |
|---|---|---|---|---|---|---|
| STCN [Cheng et al., 2021b] | 52.5 | 85.4 | - | 57.3 | 82.7 | 54 |
| RDE [Li et al., 2022b] | 46.8 | 84.2 | - | 48.4 | 81.9 | 64 |
| XMem [Cheng and Schwing, 2022] | 59.6 | 86.0 | - | 60.1 | 85.6 | 62 |
| DEVA [Cheng et al., 2023a] | 66.0 | 87.0 | 55.9 | 53.8 | 85.4 | 69 |
| Cutie-base [Cheng et al., 2024] | 69.9 | 87.9 | 66.0 | 61.6 | 87.0 | 35 |
| Cutie-base+ [Cheng et al., 2024] | 71.7 | 88.1 | - | 62.3 | 87.5 | 35 |
| SAM 2 [Ravi et al., 2024] | 72.8 | 88.9 | 76.2 | 74.7 | 87.9 | 81 |
| EfficientTAM-Ti/2 (ours) | 68.4 | 88.4 | 66.1 | 70.8 | 87.1 | 18 |
| EfficientTAM-Ti (ours) | 69.3 | 89.1 | 69.6 | 70.7 | 86.7 | 18 |
| EfficientTAM-S/2 (ours) | 70.8 | 88.6 | 72.1 | 74.0 | 87.2 | 34 |
| EfficientTAM-S (ours) | 71.4 | 89.2 | 73.4 | 74.5 | 87.2 | 34 |
🔼 Table 1 presents a comparison of different video object segmentation models on several standard benchmarks. It shows the performance of various models, including the proposed EfficientTAMs and existing state-of-the-art methods, on metrics such as J&F (a combined measure of region similarity and contour accuracy), across datasets like MOSE, DAVIS, LVOS, SA-V, and YTVOS. The table also provides information on the number of model parameters and the speed (FPS) of each model on both a high-end GPU (A100) and a mobile device (iPhone 15 Pro Max). This allows for a comprehensive comparison of accuracy and efficiency across models.
read the caption
Table 1: Standard semi-supervised video object segmentation results across video object segmentation benchmarks.
In-depth insights#
Lightweight Tracking#
Lightweight tracking in computer vision focuses on designing efficient algorithms and models that can track objects in videos while minimizing computational resources. This is crucial for deploying tracking systems on devices with limited processing power, such as mobile phones and embedded systems. Key challenges in lightweight tracking involve balancing accuracy and speed, often necessitating compromises in model complexity. Techniques like using smaller, more efficient neural networks, employing efficient feature extraction methods (e.g., lightweight CNNs or vision transformers), or implementing optimized algorithms for data association and state estimation are frequently employed. Model compression methods such as pruning, quantization, and knowledge distillation can further reduce the model size and improve inference speed. Efficient memory management is also critical, particularly for long-term tracking, to avoid memory bottlenecks. The trade-off between accuracy, speed and computational cost is paramount in lightweight tracking research, as the ultimate goal is to create tracking systems that are both accurate and practical for real-world resource-constrained applications.
Efficient Memory#
The concept of ‘Efficient Memory’ in the context of video object segmentation and tracking models centers on addressing the computational and memory burdens associated with traditional memory mechanisms. High-performance models often rely on large, hierarchical image encoders and complex memory modules, leading to slow inference speeds and high memory consumption, especially on resource-constrained devices like mobile phones. The core idea behind ‘Efficient Memory’ is to reduce this complexity without sacrificing segmentation quality. This might involve using lightweight architectures for the memory module, perhaps employing more efficient attention mechanisms (like a linear attention alternative) or by leveraging the inherent structural properties of the memory data itself (e.g., exploiting spatial locality). The goal is to achieve a balance between speed, memory usage, and accuracy, ultimately enabling real-time performance on edge devices. This research likely explores techniques to compress memory representations or optimize the cross-attention process that accesses memory, perhaps through dimensionality reduction or clever approximation strategies. The success of efficient memory solutions lies in maintaining the model’s ability to retain and utilize past contextual information while significantly decreasing computational costs, thus making video object segmentation feasible on a wider range of platforms.
ViT Encoder Use#
The research paper explores the use of Vision Transformers (ViTs) as image encoders for video object segmentation and tracking. A core argument is that simpler, non-hierarchical ViTs offer a compelling alternative to more complex, computationally expensive hierarchical models like those found in SAM 2. The authors hypothesize that the efficiency gains from using vanilla ViTs, such as ViT-Tiny or ViT-Small, outweigh the potential loss in accuracy. This is a significant departure from the prevailing trend of using hierarchical encoders, which are often considered necessary for state-of-the-art performance but come at a considerable cost in computational resources and model size. The choice of a plain ViT architecture is crucial to achieving the speed and efficiency improvements reported in the paper. The authors’ experiments provide empirical evidence supporting their claim by showing comparable accuracy to more complex models but with a significant speed improvement, highlighting the value of carefully considering the trade-off between model complexity and performance in resource-constrained settings such as mobile deployment.
Mobile Deployment#
The research paper emphasizes the efficiency challenges of existing video object segmentation models, particularly for mobile deployment. High computational complexity and large model sizes hinder real-world applications on resource-constrained devices. The core innovation is EfficientTAM, lightweight models designed to address these limitations. By employing vanilla lightweight Vision Transformers (ViTs) and an efficient memory module, EfficientTAM achieves comparable performance to larger models like SAM 2, but with significantly reduced latency and model size. This allows for real-time video object segmentation on mobile devices, a key advancement highlighted by the paper’s results, showcasing ~10 FPS on an iPhone 15 Pro Max. The efficient cross-attention mechanism within the memory module is crucial in achieving this performance gain on mobile devices. The paper’s focus on mobile deployment underscores a growing need for adaptable, efficient AI solutions that transcend high-performance computing limitations.
Future Enhancements#
Future enhancements for Efficient Track Anything (EfficientTAM) could focus on several key areas. Improving the efficiency of the memory module remains crucial; exploring more advanced attention mechanisms or memory compression techniques could significantly reduce latency and computational cost, particularly for longer videos. Investigating alternative lightweight backbones beyond vanilla ViTs, perhaps incorporating convolutional layers or other efficient architectures, could further enhance performance and potentially improve generalization. Additionally, exploring different training strategies such as self-supervised learning or transfer learning from larger models could unlock further performance gains with less training data. Finally, expanding the model’s capabilities to handle diverse prompt types and more complex scenarios, such as heavy occlusion or significant viewpoint changes, would broaden its applicability. Research into quantization and model pruning techniques would enable deployment on even more resource-constrained devices like embedded systems. Ultimately, the focus should remain on creating a robust and accurate system while maintaining a tiny model footprint for real-time on-device applications.
More visual insights#
More on tables
| MOSE | |
|---|---|
| val |
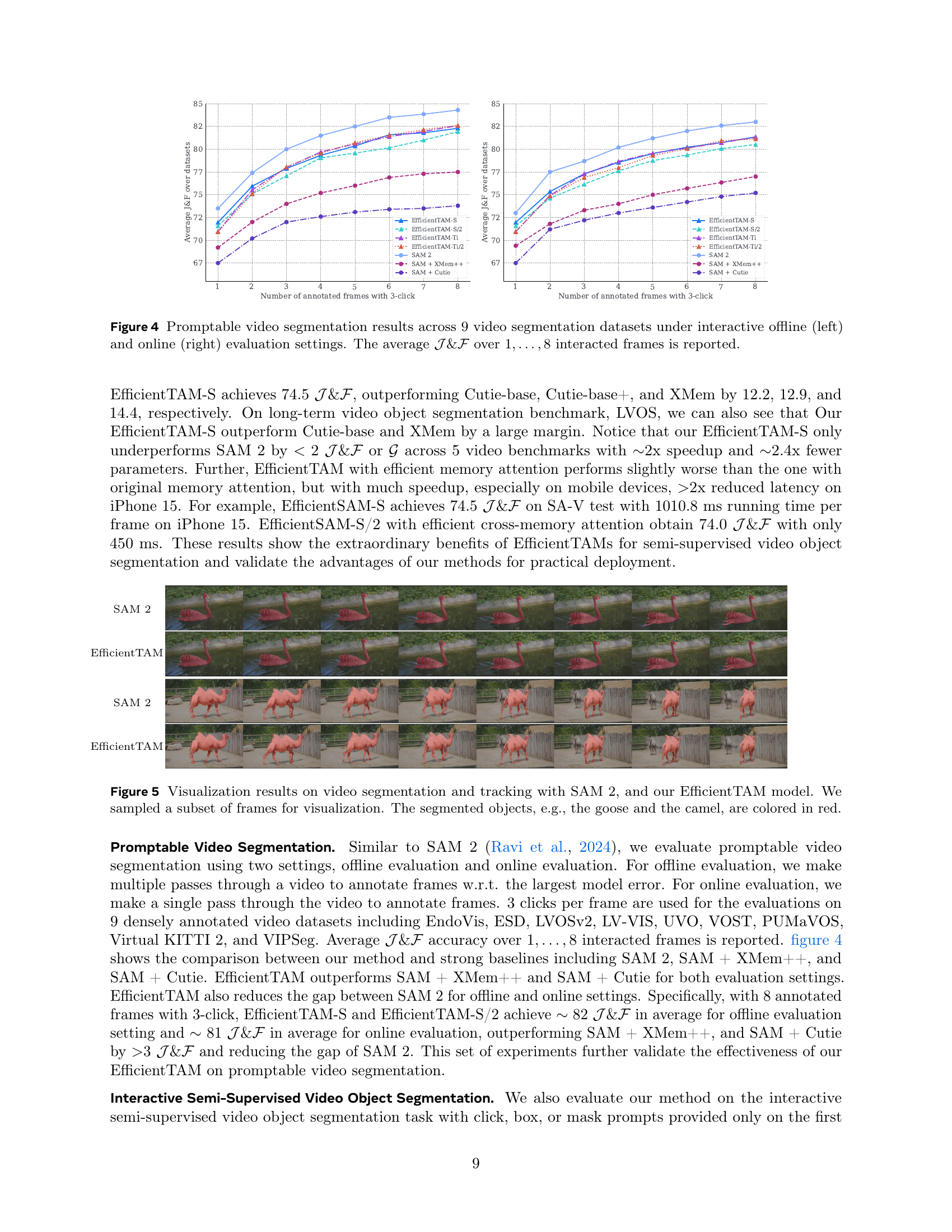
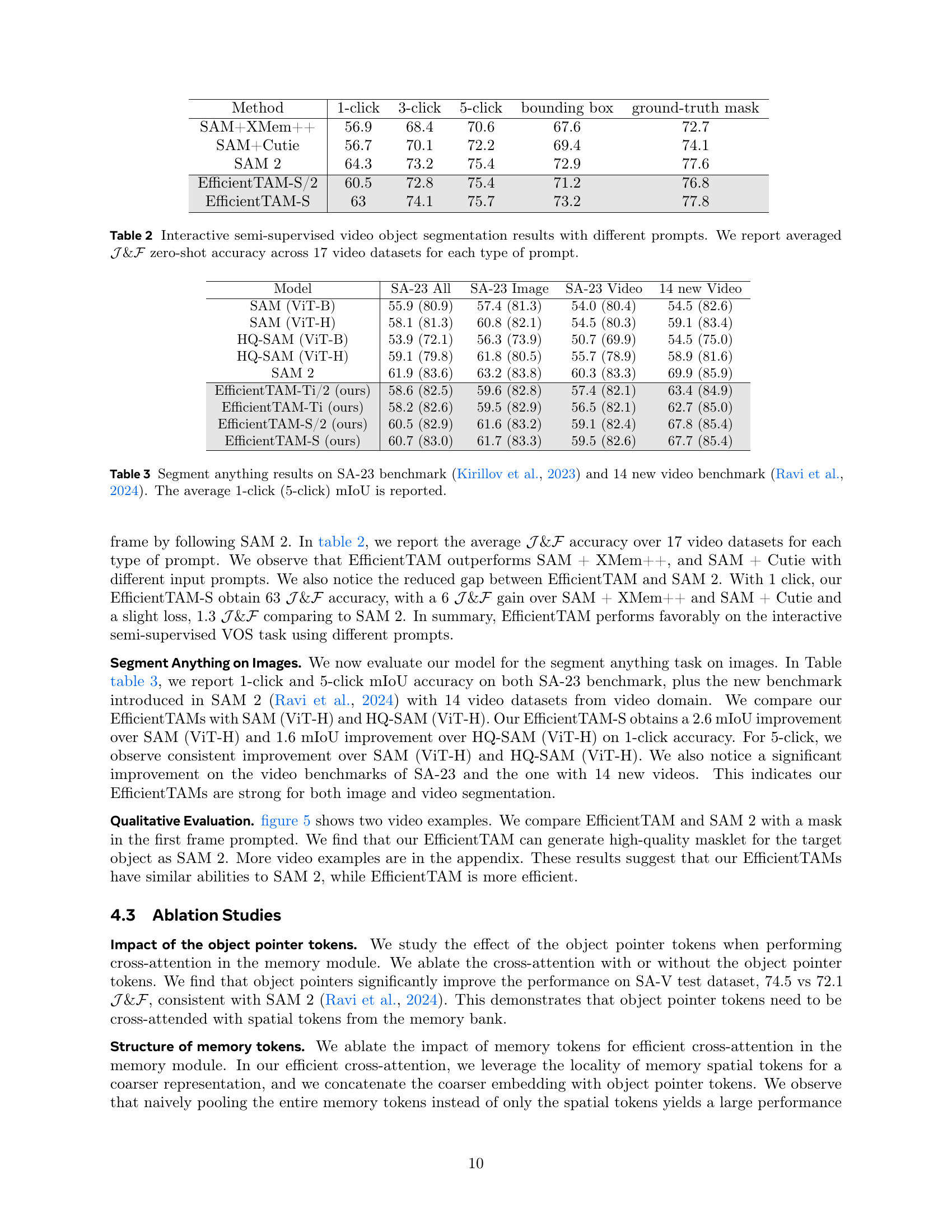
🔼 Table 2 presents a quantitative comparison of interactive semi-supervised video object segmentation performance across various prompting methods. Seventeen video datasets were used for evaluation. The metric used is the average of J&F (a combined measure of region similarity (J) and contour accuracy (F)) across all datasets for each prompt type (1-click, 3-click, 5-click, bounding box, and ground truth mask). This allows assessing the model’s ability to accurately segment objects with different levels of user interaction and feedback.
read the caption
Table 2: Interactive semi-supervised video object segmentation results with different prompts. We report averaged 𝒥𝒥\mathcal{J}caligraphic_J&ℱℱ\mathcal{F}caligraphic_F zero-shot accuracy across 17 video datasets for each type of prompt.
| DAVIS | |
|---|---|
| 2017 val |
🔼 Table 3 presents a comparison of different models’ performance on the task of segmenting objects within images. The models are evaluated using two benchmarks: the SA-23 dataset (Kirillov et al., 2023), which contains a large collection of diverse images, and a new video benchmark (Ravi et al., 2024) consisting of 14 video clips. The evaluation metric is mean Intersection over Union (mIoU), a common measure of segmentation accuracy. Results are provided for both 1-click and 5-click scenarios, indicating how well the models segment objects given a single click or five clicks as input. This allows for assessment of both speed and accuracy, reflecting model efficiency and robustness. The table provides a quantitative analysis of the models’ zero-shot object segmentation capabilities.
read the caption
Table 3: Segment anything results on SA-23 benchmark (Kirillov et al., 2023) and 14 new video benchmark (Ravi et al., 2024). The average 1-click (5-click) mIoU is reported.
| LVOS | val |
|---|
🔼 This table presents a comparison of different cross-attention variants used in the EfficientTAM model. It shows the performance (measured by J&F scores on the MOSE dev, DAVIS 2017 val, and SA-V test datasets) of different cross-attention methods, allowing for a direct assessment of their relative effectiveness in the context of video object segmentation.
read the caption
Table 4: Efficient cross-attention variants.
| SA-V | |
|---|---|
| test |
🔼 This ablation study investigates the impact of input image resolution on the performance of EfficientTAM. It compares the model’s performance (measured by J&F scores on MOSE dev, DAVIS 2017 val, and SA-V test sets) and efficiency (frames per second (FPS) on an A100 GPU and latency in milliseconds on an iPhone 15) using two different input resolutions: 1024x1024 and 512x512. The results demonstrate the trade-off between accuracy and speed, showing how lower resolution improves efficiency, particularly on mobile devices, at the cost of slightly lower accuracy.
read the caption
Table 5: Ablation study on the effect of input resolution.
| YTVOS | |
|---|---|
| 2019 val |
🔼 This table presents the results of an ablation study investigating the impact of different design choices within the memory cross-attention mechanism of the EfficientTAM model. Specifically, it shows how the performance of EfficientTAM changes when using or not using object pointer tokens in the memory cross-attention module. The study evaluates performance metrics across three different datasets (MOSE dev, DAVIS 2017 val, SA-V test), offering a comprehensive view of the effect of this design choice on various video object segmentation tasks.
read the caption
Table 6: Ablation study on the design of memory cross-attention in EfficientTAM.
| Method | 1-click | 3-click | 5-click | bounding box | ground-truth mask |
|---|---|---|---|---|---|
| SAM+XMem++ | 56.9 | 68.4 | 70.6 | 67.6 | 72.7 |
| SAM+Cutie | 56.7 | 70.1 | 72.2 | 69.4 | 74.1 |
| SAM 2 | 64.3 | 73.2 | 75.4 | 72.9 | 77.6 |
| EfficientTAM-S/2 | 60.5 | 72.8 | 75.4 | 71.2 | 76.8 |
| EfficientTAM-S | 63 | 74.1 | 75.7 | 73.2 | 77.8 |
🔼 This table presents the results of an ablation study focusing on the efficiency of cross-attention within the EfficientTAM model’s memory module. It compares the performance of using only spatial memory tokens versus using the full set of memory tokens (spatial and object pointer tokens) within the efficient cross-attention mechanism. This helps to understand the impact of considering the underlying structure of memory tokens on the overall efficiency and accuracy of the model.
read the caption
Table 7: Ablation study on taking care of the memory token structure for efficient cross-attention in EfficientTAM.
| Model | SA-23 All | SA-23 Image | SA-23 Video | 14 new Video |
|---|---|---|---|---|
| SAM (ViT-B) | 55.9 (80.9) | 57.4 (81.3) | 54.0 (80.4) | 54.5 (82.6) |
| SAM (ViT-H) | 58.1 (81.3) | 60.8 (82.1) | 54.5 (80.3) | 59.1 (83.4) |
| HQ-SAM (ViT-B) | 53.9 (72.1) | 56.3 (73.9) | 50.7 (69.9) | 54.5 (75.0) |
| HQ-SAM (ViT-H) | 59.1 (79.8) | 61.8 (80.5) | 55.7 (78.9) | 58.9 (81.6) |
| SAM 2 | 61.9 (83.6) | 63.2 (83.8) | 60.3 (83.3) | 69.9 (85.9) |
| EfficientTAM-Ti/2 (ours) | 58.6 (82.5) | 59.6 (82.8) | 57.4 (82.1) | 63.4 (84.9) |
| EfficientTAM-Ti (ours) | 58.2 (82.6) | 59.5 (82.9) | 56.5 (82.1) | 62.7 (85.0) |
| EfficientTAM-S/2 (ours) | 60.5 (82.9) | 61.6 (83.2) | 59.1 (82.4) | 67.8 (85.4) |
| EfficientTAM-S (ours) | 60.7 (83.0) | 61.7 (83.3) | 59.5 (82.6) | 67.7 (85.4) |
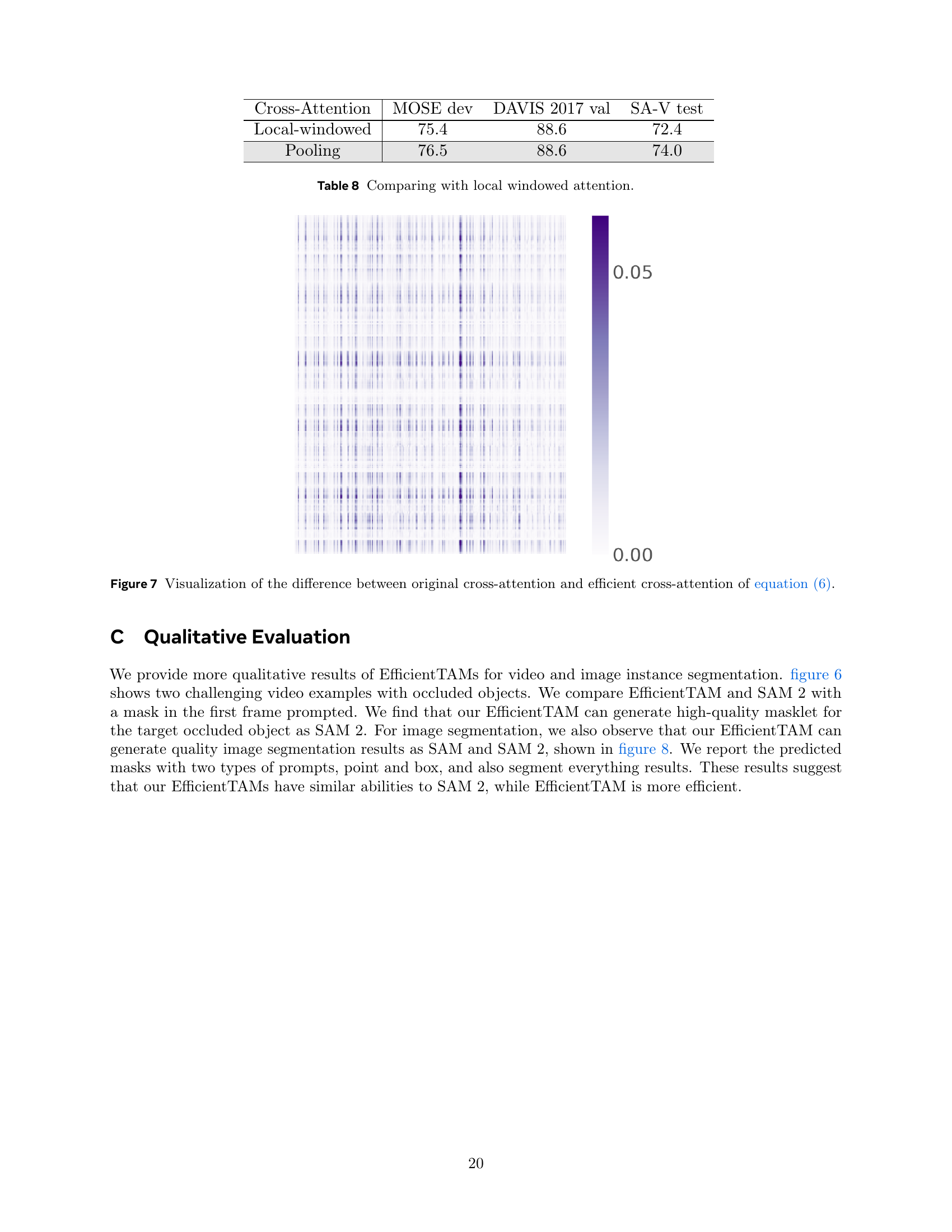
🔼 This table presents a comparison of the performance of different cross-attention methods in the EfficientTAM model. Specifically, it compares the performance of the proposed efficient cross-attention method with local windowed attention, across various metrics for video object segmentation. The metrics used evaluate performance on the MOSE dev, DAVIS 2017 val, and SA-V test datasets.
read the caption
Table 8: Comparing with local windowed attention.
Full paper#