↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many existing multimodal models focus primarily on high-resource languages like English and Chinese, leaving low-resource languages underserved. This scarcity hinders research and application development in these areas. The lack of readily available, high-performing models for languages like Korean creates a significant barrier to research progress. This research seeks to address this crucial gap.
This paper introduces VARCO-VISION-14B, a novel open-source Korean-English vision-language model, and provides five new Korean benchmark datasets. VARCO-VISION demonstrates state-of-the-art performance on various benchmarks, showcasing its strength in bilingual comprehension and generation tasks. The model also exhibits excellent capabilities in grounding, referring, and OCR. The release of the model and datasets is a crucial step towards fostering a more inclusive and collaborative AI research environment.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the scarcity of open-source Korean vision-language models (VLMs). It introduces VARCO-VISION, a powerful 14B parameter bilingual VLM, along with five new Korean benchmark datasets. This significantly boosts research opportunities in this under-resourced area and sets a new standard for Korean-English VLMs. The open-source nature of the model and datasets fosters collaboration and accelerates progress in the field.
Visual Insights#

🔼 This figure showcases VARCO-VISION’s capabilities across various vision-language tasks, including Visual Question Answering (VQA), Optical Character Recognition (OCR), referring expression generation, and grounding. The examples highlight the model’s proficiency in understanding and generating text in both Korean and English, demonstrating its strong bilingual capabilities in multimodal contexts. More detailed examples can be found in Appendix B.
read the caption
Figure 1: VARCO-VISION Application Examples: Visual Question Answering (VQA), Optical Character Recognition (OCR), Referring, and Grounding. Our model excels at both Korean/English vision-text and text-only tasks. Please see B for more detailed examples.
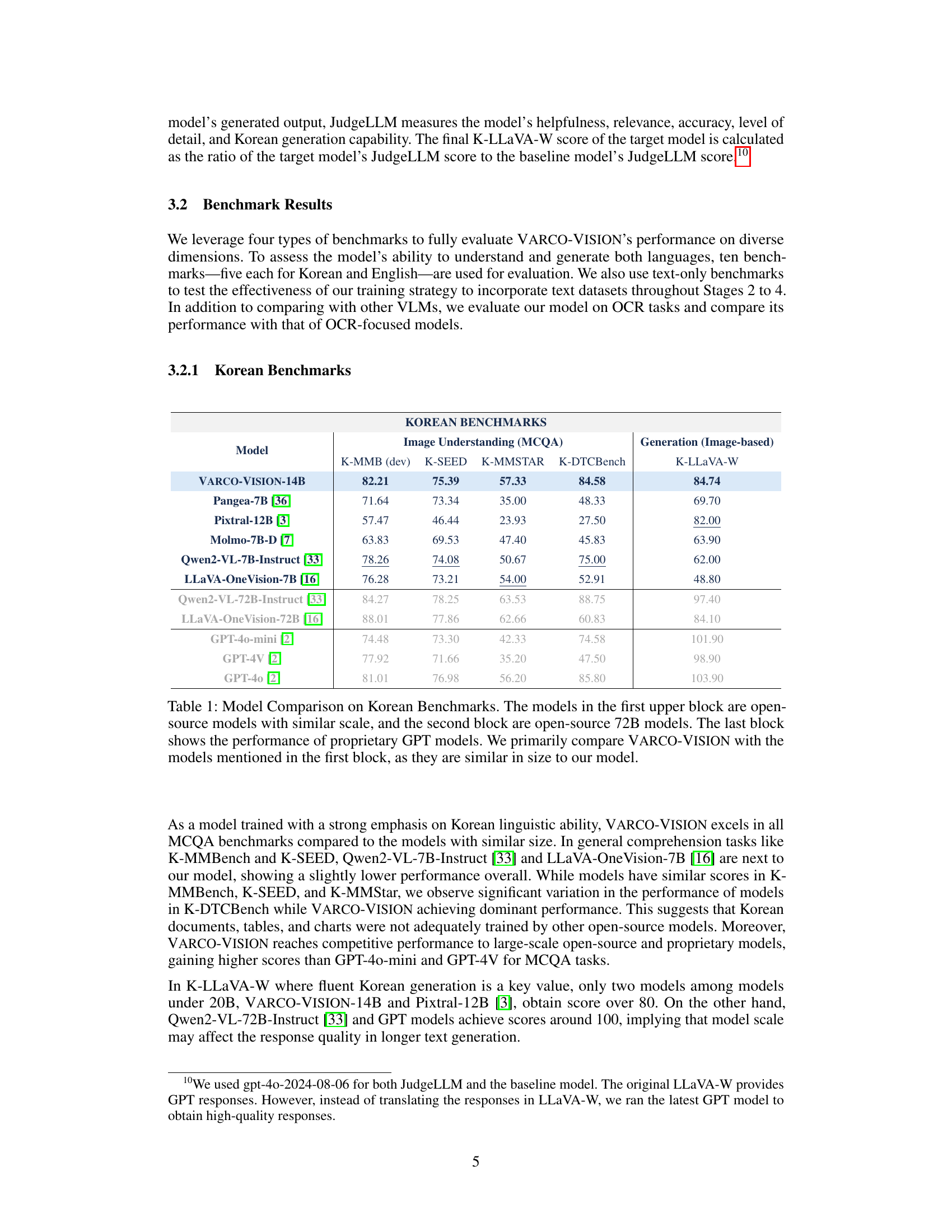
| KOREAN BENCHMARKS | Image Understanding (MCQA) | Generation (Image-based) |
|---|---|---|
| Model | K-MMB (dev) | K-SEED |
| VARCO-VISION-14B | 82.21 | 75.39 |
| Pangea-7B [36] | 71.64 | 73.34 |
| Pixtral-12B [3] | 57.47 | 46.44 |
| Molmo-7B-D [7] | 63.83 | 69.53 |
| Qwen2-VL-7B-Instruct [33] | 78.26 | 74.08 |
| LLaVA-OneVision-7B [16] | 76.28 | 73.21 |
| Qwen2-VL-72B-Instruct [33] | 84.27 | 78.25 |
| LLaVA-OneVision-72B [16] | 88.01 | 77.86 |
| GPT-4o-mini [2] | 74.48 | 73.30 |
| GPT-4V [2] | 77.92 | 71.66 |
| GPT-4o [2] | 81.01 | 76.98 |
🔼 This table compares the performance of VARCO-VISION-14B against other vision-language models on Korean benchmarks. The comparison is broken down into three groups: open-source models of similar size to VARCO-VISION (under 20B parameters), larger open-source models (around 72B parameters), and proprietary GPT models. The table highlights the performance of each model across multiple tasks, allowing for a comprehensive evaluation of VARCO-VISION’s capabilities relative to existing models. The main focus of the comparison is between VARCO-VISION and the first group of models due to their similar scale.
read the caption
Table 1: Model Comparison on Korean Benchmarks. The models in the first upper block are open-source models with similar scale, and the second block are open-source 72B models. The last block shows the performance of proprietary GPT models. We primarily compare VARCO-VISION with the models mentioned in the first block, as they are similar in size to our model.
In-depth insights#
Korean MLLM Frontier#
The Korean MLLM frontier represents a significant challenge and opportunity in the field of artificial intelligence. While English and Chinese dominate the current MLLM landscape, Korean presents unique linguistic and cultural characteristics that require specialized models. This necessitates the development of substantial Korean-language datasets, which are currently limited. Building high-quality, diverse datasets is crucial for training effective Korean MLLMs, encompassing various modalities like image-text data. Furthermore, research must address specific challenges in Korean morphology and syntax, impacting model training and evaluation. Overcoming these hurdles will require collaborative efforts from researchers, industry, and government, opening avenues for innovation in various applications and potentially bridging the gap between leading MLLMs and other languages. The resulting advancements in Korean MLLMs will contribute valuable insights and methods applicable to other low-resource language models, advancing the global state-of-the-art in AI.
Gradual Training#
The concept of “Gradual Training” in the context of Vision-Language Models (VLMs) suggests a phased approach to model development, rather than a single, monolithic training process. This strategy likely involves incrementally introducing visual and linguistic data, allowing the model to first master language understanding before integrating visual information. This phased approach could mitigate the risk of catastrophic forgetting, where the model loses previously learned linguistic capabilities during the visual training phase. The researchers likely focused on preserving the backbone model’s knowledge (a pre-trained Large Language Model) by freezing certain layers initially and gradually unfreezing them as the model learns more complex tasks. This careful approach to training may be key to achieving high performance across both language and vision tasks, a crucial aspect given the model’s bilingual (Korean-English) nature. The success of gradual training in this instance highlights its potential as a robust method for developing effective and efficient VLMs, particularly when dealing with multiple modalities and languages.
Benchmarking VLMs#
Benchmarking Vision-Language Models (VLMs) is crucial for evaluating their performance and identifying areas for improvement. A robust benchmark should encompass a diverse range of tasks, including image classification, object detection, visual question answering (VQA), image captioning, and visual commonsense reasoning (VCR). Furthermore, the benchmark should consider various factors such as dataset size, image complexity, language diversity, and evaluation metrics. A well-designed benchmark needs both closed-set and open-set evaluations, allowing for a comprehensive assessment of the VLM’s capabilities. Closed-set evaluations use pre-defined categories and answer choices, while open-set evaluations require the model to generate free-form answers. It’s vital to ensure the dataset’s quality and diversity, reflecting real-world scenarios, to avoid biases and ensure generalizability. Finally, comparing performance across different VLMs using standardized benchmarks enables researchers to track progress and fosters the development of more advanced models. This holistic approach to benchmarking is critical for advancing the field and facilitating the development of robust and reliable VLMs.
Bilingual Abilities#
The concept of “Bilingual Abilities” in the context of vision-language models (VLMs) is crucial. It highlights the model’s capacity to seamlessly understand and generate text in two languages, exhibiting true bilingual proficiency rather than just translation capabilities. A truly bilingual VLM should demonstrate high performance on benchmarks in both languages, suggesting an inherent understanding of the nuances and complexities of each language, not merely the ability to switch between them. This would be shown by the VLM excelling in tasks requiring sophisticated linguistic understanding such as question answering, text generation, and reasoning, in both languages. Evaluating this ability requires specific benchmarks and metrics, ensuring that the model’s scores are not inflated by simple translation or word-for-word replacements. The research paper would need to include a thorough analysis comparing its VLM’s performance to other models, particularly highlighting any differences in bilingual ability. Ultimately, the success of a truly bilingual VLM rests on its capacity to handle ambiguity, context, and idiomatic expressions, thus demonstrating a deep understanding that goes beyond basic translation tasks.
Future Directions#
Future directions for research in Korean vision-language models (VLMs) could focus on several key areas. Expanding the model’s multilingual capabilities beyond Korean and English is crucial, enabling broader applications and a more inclusive AI ecosystem. Addressing the limitations of current multimodal benchmarks is also necessary, moving beyond simple multiple-choice questions to evaluate more nuanced abilities such as commonsense reasoning and complex instruction following. Developing more robust methods for handling noise and variability in real-world data should also be prioritized. The current models often assume clean, well-structured data that does not always reflect real-world scenarios. Finally, exploring the potential of VARCO-VISION for advanced applications such as multimodal search, retrieval-augmented generation, and visual agents is a promising avenue. This would require further development of the model architecture and training techniques to handle such complex tasks effectively.
More visual insights#
More on figures

🔼 This figure shows examples from the K-MMStar benchmark, a Korean version of the MMStar benchmark. It illustrates three types of question modifications done to adapt the original English MMStar dataset for Korean. Type 1 questions are direct translations. Type 2 questions require modifications to account for differences in terminology (e.g., ‘football’ vs. ‘soccer’). Type 3 questions needed complete re-creation because the original options in MMStar were unanswerable or vague, requiring new images and questions to be generated. This highlights the challenges of directly translating and adapting existing multimodal benchmarks for different languages.
read the caption
Figure 2: K-MMStar Example

🔼 This figure displays example images from the K-DTCBench dataset. K-DTCBench is a Korean multimodal benchmark dataset designed to evaluate the ability of vision-language models to process diverse image types, including documents, tables, and charts. The examples show sample images, multiple-choice questions, and their respective answers. The dataset is constructed from scratch with a mix of synthetic images and real-world scanned documents/tables/charts to ensure a wide representation of typical image formats that a vision-language model might encounter.
read the caption
Figure 3: K-DTCBench Example

🔼 Figure 4 shows examples from the K-LLaVA-W benchmark dataset. The K-LLaVA-W benchmark is an open-set, Korean language version of the LLaVA-W benchmark, designed to evaluate the model’s ability to generate fluent and relevant responses to open-ended questions about images. This figure displays example image-question pairs and illustrates how English text within images has been translated into Korean, while images without text were left unchanged. This illustrates the methods used to create a Korean version of the open-set benchmark.
read the caption
Figure 4: K-LLaVA-W Example

🔼 This figure displays the evaluation prompt used for the K-LLaVA-W benchmark. The prompt, originally in English for the LLaVA-W benchmark, has been translated into Korean. Crucially, specific guidelines were added to help the JudgeLLM (the large language model used for automated evaluation) more accurately assess aspects like helpfulness, relevance, accuracy, detail, and Korean language generation quality of the model’s responses. The structure of the prompt is shown, including the spaces for the caption, question, model’s response, and the evaluator’s scoring instructions.
read the caption
Figure 5: K-LLaVA-W Evaluation Prompt. We translated the LLaVA-W prompts and added specific guidelines in the JudgeLLM prompt.

🔼 This figure shows an example of the model’s text recognition and analysis capabilities. The input is a screenshot of a sleep tracking app displaying sleep data. The model accurately extracts the relevant data points (e.g., hours of sleep, sleep stages) and then provides a concise summary of the user’s sleep quality and actionable advice on how to improve it.
read the caption
Figure 6: Text Recognition and Analysis Example (English)

🔼 This figure demonstrates the model’s mathematical reasoning capabilities using a Korean language example. It presents a diagram showing a shaded region within a 90-degree sector of a circle with a 4cm radius. The task is to calculate the area of this shaded region. The figure shows the model’s step-by-step solution, including identifying the shapes involved (sector and triangle), applying the relevant formulas, and calculating the final answer. This example showcases the model’s ability to both understand the geometrical problem and perform the necessary calculations accurately.
read the caption
Figure 7: Mathematical Reasoning Example (Korean)

🔼 This figure demonstrates the model’s ability to extract relevant information from an image of a menu board and perform calculations based on user requests. A user asks the model how much it would cost to order a cheeseburger and a soda, given the prices displayed on the menu. The model correctly identifies the prices, adds them up, and provides the total cost in the specified currency (1000 won). This showcases the model’s combined capabilities of visual information extraction and numerical computation.
read the caption
Figure 8: Information Extraction and Calculation Example (Korean)

🔼 The figure displays an example of the VARCO-VISION model’s grounding capabilities in Korean. It shows an image of a child in a cart pulled by a donkey, and the model’s response provides a detailed description of the image, including the location and identification of objects within the image (child, cart, donkey) and their attributes.
read the caption
Figure 9: Grounding Example (Korean)

🔼 The figure displays an example of the grounding task in English. The image shows two cats lying on a pink blanket, with two remote controls nearby. The model correctly identifies and localizes the objects (the cats and the blanket) and provides a detailed description of the scene.
read the caption
Figure 10: Grounding Example (English)

🔼 This figure demonstrates the model’s referring capabilities using a Korean example. The input is a request to read the text visible on a Starbucks storefront and describe what kind of place it is. The model correctly identifies the text as ‘STARBUCKS,’ and then provides a detailed description of Starbucks as a coffee shop chain that sells various drinks and snacks, offering customers a space to relax and socialize. The response also mentions the global presence of Starbucks and the typical ambiance of the store.
read the caption
Figure 11: Referring Example (Korean)

🔼 This figure shows an example of Optical Character Recognition (OCR) performed by the VARCO-VISION model. The input is an image of a speed limit sign at night. The model correctly identifies and transcribes the text on the sign as ‘SPEED LIMIT 20’. This demonstrates the model’s ability to accurately extract textual information from images, even under challenging conditions like low light.
read the caption
Figure 12: OCR Example

🔼 This figure showcases an example of Optical Character Recognition (OCR) performed by the VARCO-VISION model. The input image contains a Korean street sign with multiple lines of text. The model successfully extracts and outputs the text from the image, demonstrating its ability to accurately identify and transcribe Korean characters within a real-world context.
read the caption
Figure 13: OCR Example

🔼 The figure displays an example of the model’s summarization capabilities. It shows a news article about the reunion of the British rock band Oasis and the model’s generated summary of the article in a lyrical style, mimicking the style requested in the caption. This showcases the model’s ability to not only understand the content of the article but also to adapt its writing style to a specific user request.
read the caption
Figure 14: Summarization Example (English)

🔼 This figure showcases an example of text recognition in Korean. The model accurately extracts and displays all the text present in the provided image, which includes both text and images. The image depicts a diagram explaining the training process for a Multimodal Large Language Model (MLLM). The model’s response shows it not only identified the text but also structured it appropriately, separating the two phases (Pre-training and Fine-tuning) clearly. This demonstrates the model’s capability to correctly interpret and extract textual information from complex images containing both text and visuals.
read the caption
Figure 15: Text Recognition Example (Korean)
More on tables
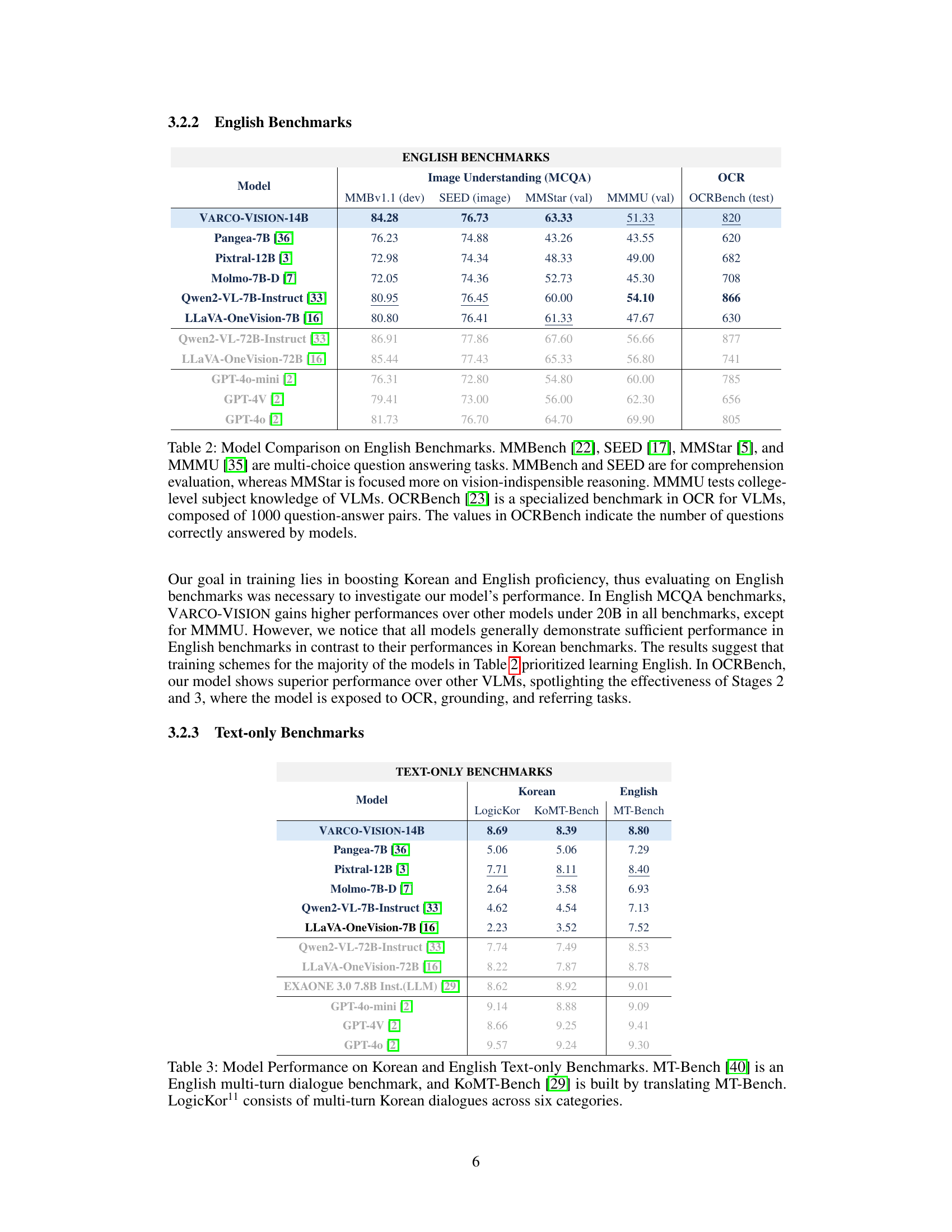
| Model | Image Understanding (MCQA) | SEED (image) | MMStar (val) | MMMU (val) | OCR |
|---|---|---|---|---|---|
| ENGLISH BENCHMARKS | |||||
| VARCO-VISION-14B | 84.28 | 76.73 | 63.33 | ||
| Pangea-7B [36] | 76.23 | 74.88 | 43.26 | 43.55 | 620 |
| Pixtral-12B [3] | 72.98 | 74.34 | 48.33 | 49.00 | 682 |
| Molmo-7B-D [7] | 72.05 | 74.36 | 52.73 | 45.30 | 708 |
| Qwen2-VL-7B-Instruct [33] | 60.00 | 54.10 | 866 | ||
| LLaVA-OneVision-7B [16] | 80.80 | 76.41 | 47.67 | 630 | |
| Qwen2-VL-72B-Instruct [33] | 86.91 | 77.86 | 67.60 | 56.66 | 877 |
| LLaVA-OneVision-72B [16] | 85.44 | 77.43 | 65.33 | 56.80 | 741 |
| GPT-4o-mini [2] | 76.31 | 72.80 | 54.80 | 60.00 | 785 |
| GPT-4V [2] | 79.41 | 73.00 | 56.00 | 62.30 | 656 |
| GPT-4o [2] | 81.73 | 76.70 | 64.70 | 69.90 | 805 |
🔼 Table 2 presents a comparative analysis of various Vision-Language Models (VLMs) on several English benchmarks. The benchmarks assess different aspects of VLM capabilities: MMBench, SEED, and MMStar evaluate comprehension and reasoning skills through multiple-choice question answering tasks, with MMStar focusing on vision-centric reasoning. MMMU tests the models’ knowledge of college-level subjects. OCRBench specifically evaluates Optical Character Recognition (OCR) performance by counting correctly answered questions out of 1000 provided pairs. The table allows for a comprehensive comparison of VLMs across diverse capabilities, enabling a nuanced understanding of their strengths and weaknesses in different visual and linguistic tasks.
read the caption
Table 2: Model Comparison on English Benchmarks. MMBench [22], SEED [17], MMStar [5], and MMMU [35] are multi-choice question answering tasks. MMBench and SEED are for comprehension evaluation, whereas MMStar is focused more on vision-indispensible reasoning. MMMU tests college-level subject knowledge of VLMs. OCRBench [23] is a specialized benchmark in OCR for VLMs, composed of 1000 question-answer pairs. The values in OCRBench indicate the number of questions correctly answered by models.
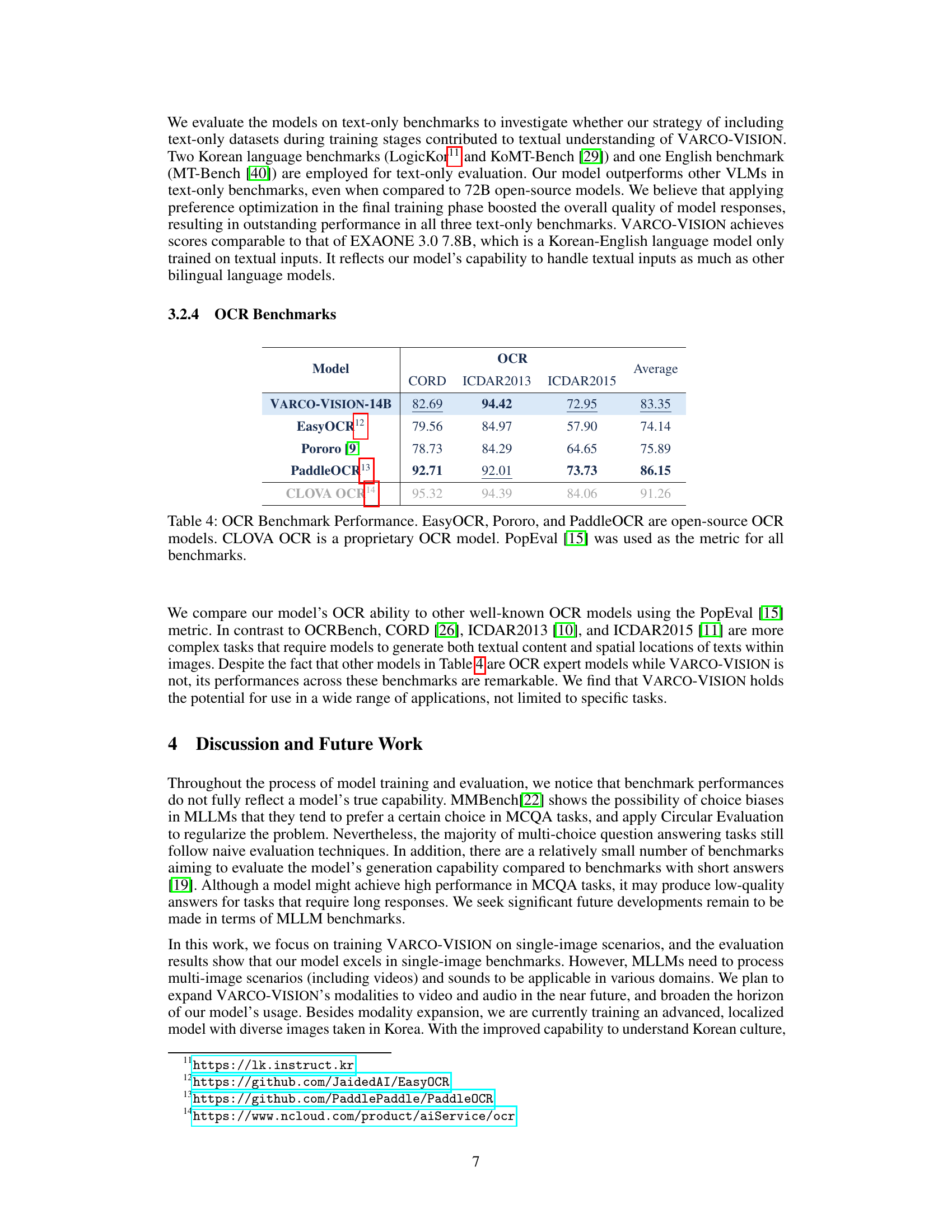
| TEXT-ONLY BENCHMARKS | Korean | KoMT-Bench | English |
|---|---|---|---|
| Model | |||
| VARCO-VISION-14B | 8.69 | 8.39 | 8.80 |
| Pangea-7B [36] | 5.06 | 5.06 | 7.29 |
| Pixtral-12B [3] | |||
| Molmo-7B-D [7] | 2.64 | 3.58 | 6.93 |
| Qwen2-VL-7B-Instruct [33] | 4.62 | 4.54 | 7.13 |
| LLaVA-OneVision-7B [16] | 2.23 | 3.52 | 7.52 |
| Qwen2-VL-72B-Instruct [33] | 7.74 | 7.49 | 8.53 |
| LLaVA-OneVision-72B [16] | 8.22 | 7.87 | 8.78 |
| EXAONE 3.0 7.8B Inst.(LLM) [29] | 8.62 | 8.92 | 9.01 |
| GPT-4o-mini [2] | 9.14 | 8.88 | 9.09 |
| GPT-4V [2] | 8.66 | 9.25 | 9.41 |
| GPT-4o [2] | 9.57 | 9.24 | 9.30 |
🔼 This table presents a comparison of model performance on English and Korean text-only benchmarks. The English benchmark MT-Bench involves multi-turn dialogue, while the Korean benchmark KoMT-Bench is a translation of MT-Bench. A third Korean benchmark, LogicKor, uses multi-turn dialogues across six distinct categories. The table allows for assessment of models’ capabilities in understanding and generating text in both languages, independent of any visual input.
read the caption
Table 3: Model Performance on Korean and English Text-only Benchmarks. MT-Bench [40] is an English multi-turn dialogue benchmark, and KoMT-Bench [29] is built by translating MT-Bench. LogicKor11 consists of multi-turn Korean dialogues across six categories.
| Model | CORD | ICDAR2013 | ICDAR2015 | Average |
|---|---|---|---|---|
| VARCO-VISION-14B | 82.69 | 94.42 | 72.95 | 83.35 |
| EasyOCR10 | 79.56 | 84.97 | 57.90 | 74.14 |
| Pororo [9] | 78.73 | 84.29 | 64.65 | 75.89 |
| PaddleOCR11 | 92.71 | 92.01 | 73.73 | 86.15 |
| CLOVA OCR12 | 95.32 | 94.39 | 84.06 | 91.26 |
🔼 This table presents a comparison of the performance of various OCR models on benchmark datasets. The models include EasyOCR, Pororo, PaddleOCR (all open-source), and CLOVA OCR (proprietary). The PopEval metric [15] was used to evaluate the performance of each model. The results demonstrate the accuracy of each model across different benchmarks, providing insights into their relative strengths and weaknesses for Optical Character Recognition tasks.
read the caption
Table 4: OCR Benchmark Performance. EasyOCR, Pororo, and PaddleOCR are open-source OCR models. CLOVA OCR is a proprietary OCR model. PopEval [15] was used as the metric for all benchmarks.
Full paper#