↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video depth estimation methods often rely on computationally expensive video diffusion models. These models are difficult to train and can suffer from issues such as 3D inconsistency and imperfect stitching for long videos. This limitation motivates the need for more efficient and accurate approaches. Existing single-image depth estimators, while highly accurate for single frames, often struggle to maintain temporal consistency when applied to video sequences due to motion and changes in depth range.
The proposed RollingDepth model addresses these challenges by cleverly leveraging a single-image latent diffusion model (LDM). It processes short video snippets (typically frame triplets) with a multi-frame depth estimator to capture temporal context. A robust optimization-based registration algorithm then optimally assembles these depth snippets into a long, temporally coherent depth video. This approach provides significant improvements in accuracy and efficiency compared to dedicated video depth estimators and single-frame models, even on long videos. The model’s effectiveness is demonstrated through extensive experiments on standard video depth estimation benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to video depth estimation that surpasses existing methods. It demonstrates a new way to leverage single-image depth models for video tasks, thereby reducing computational costs and improving accuracy. The technique is particularly relevant to current trends of using large foundation models, which are expensive and difficult to train for video data. Its success opens up new avenues for researchers interested in efficient and accurate video understanding.
Visual Insights#

🔼 The RollingDepth model processes an unconstrained video to generate a corresponding depth video. Instead of using video diffusion models, it enhances a single-image depth estimator to handle short video segments (snippets). To maintain temporal consistency, snippets with varied frame rates are extracted, processed individually, and then precisely combined using a global alignment algorithm, resulting in a long, temporally coherent depth video. The color-coding of the depth map ranges from near (darker colors) to far (lighter colors).
read the caption
Figure 1: The RollingDepth model takes an unconstrained video and reconstructs a corresponding depth video. Unlike methods that rely on video diffusion models, it extends a single-image monodepth estimator such that it can process short snippets. To account for temporal context, snippets with varying frame rate are sampled from the video, processed, and reassembled through a global alignment algorithm to obtain long, temporally coherent depth videos. Depth is colour-coded from near far.
| Method | PointOdyssey (250) | ScanNet (90) | Bonn (110) | DyDToF (200) | DyDToF (100) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Abs Rel↓ δ1↑ | Abs Rel↓ δ1↑ | Abs Rel↓ δ1↑ | Abs Rel↓ δ1↑ | Abs Rel↓ δ1↑ | ||||||
| Single frame | Marigold∗ [24] | 14.9 | 80.4 | 14.9 | 78.3 | 10.5 | 86.7 | 25.3 | 55.5 | 16.4 |
| DepthAnything [68] | 16.3 | 76.0 | 12.9 | 84.0 | 9.9 | 89.4 | 25.4 | 54.3 | 16.4 | |
| DepthAnythingv2 [69] | 14.4 | 81.4 | 13.3 | 82.6 | 10.5 | 87.4 | 24.8 | 55.9 | 16.0 | |
| Video | NVDS (DPT-Large) [62] | 26.6 | 68.2 | 18.5 | 67.7 | 10.5 | 88.1 | 24.7 | 56.0 | 18.8 |
| ChronoDepth [56] | 51.7 | 71.2 | 16.8 | 73.8 | 10.9 | 86.9 | 26.9 | 53.2 | 19.9 | |
| DepthCrafter [23] | 36.3 | 75.0 | 12.7 | 84.3 | 6.6 | 96.7 | 22.1 | 60.7 | 16.2 | |
| RollingDepth (ours, fast)† | 9.6 | 90.4 | 10.1 | 89.7 | 7.9 | 93.6 | 17.7 | 69.6 | 12.7 | |
| RollingDepth (ours) | 9.6 | 90.5 | 9.3 | 91.6 | 7.9 | 93.9 | 17.3 | 71.7 | 12.3 |
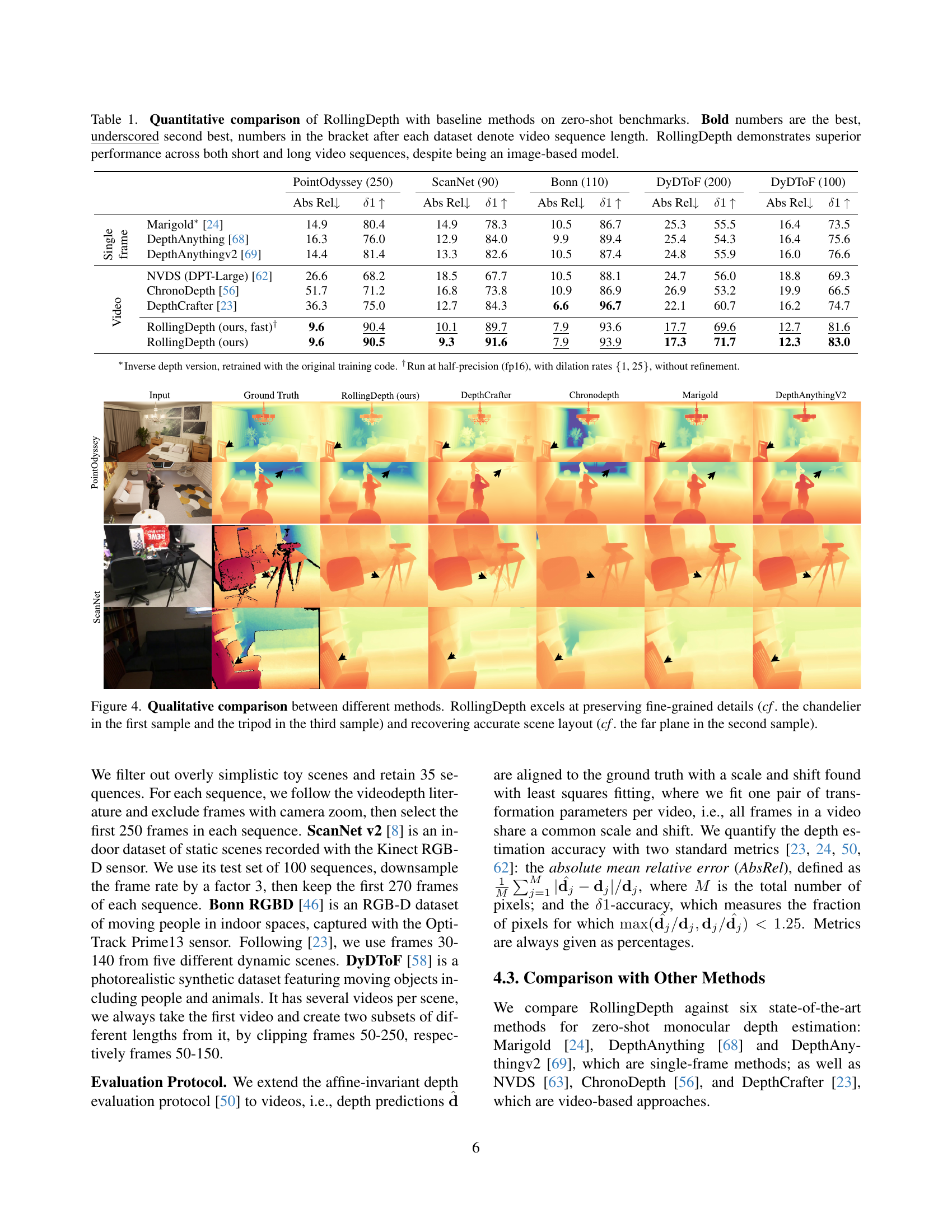
🔼 Table 1 presents a quantitative comparison of the RollingDepth model’s performance against several baseline methods on four zero-shot video depth estimation benchmarks: PointOdyssey, ScanNet, Bonn, and DyDToF. The datasets vary in video sequence length (indicated in parentheses), allowing for evaluation of the models’ abilities to handle both short and long videos. Performance is measured using two metrics: absolute relative error (Abs Rel) and δ1 accuracy. Lower Abs Rel values and higher δ1 values indicate better performance. The table highlights RollingDepth’s superior performance across all datasets and sequence lengths, which is particularly noteworthy given that RollingDepth is an image-based model, unlike many of the baseline methods which are specifically designed for video data.
read the caption
Table 1: Quantitative comparison of RollingDepth with baseline methods on zero-shot benchmarks. Bold numbers are the best, underscored second best, numbers in the bracket after each dataset denote video sequence length. RollingDepth demonstrates superior performance across both short and long video sequences, despite being an image-based model.
In-depth insights#
Video Depth: No Models#
The concept of “Video Depth: No Models” presents a compelling research direction, challenging the prevailing reliance on complex video models for depth estimation. It suggests exploring alternative approaches that achieve accurate and temporally consistent depth maps without the computational cost and limitations of video foundation models. This could involve innovative techniques leveraging advanced single-image depth estimation, coupled with robust temporal alignment strategies. The potential benefits are substantial: faster inference times, reduced memory requirements, and improved generalization across various video types. A key challenge would be designing effective algorithms for temporal consistency, addressing issues like flickering and depth drift without relying on the inherent temporal understanding provided by video models. This could potentially involve novel temporal regularization methods, data augmentation strategies focusing on temporal coherence, or perhaps even a paradigm shift towards a fully differentiable approach to temporal alignment. Success in this area could lead to significant advancements in video understanding and applications, such as 3D scene reconstruction, augmented reality, and autonomous driving. The exploration of “Video Depth: No Models” therefore holds exciting prospects for creating more efficient and effective video depth estimation techniques.
Rolling LDM Inference#
The concept of “Rolling LDM Inference” suggests a novel approach to processing video data using Latent Diffusion Models (LDMs). Instead of processing the entire video at once, which can be computationally expensive and memory-intensive, this method employs a sliding window to process short, overlapping segments of the video. This “rolling” approach allows for efficient processing of long videos, making it scalable for real-world applications. Each segment is processed independently by an LDM, generating depth or other relevant information for that segment. The use of overlapping segments is crucial for maintaining temporal consistency, minimizing flickering and artifacts often found in frame-by-frame processing. A key advantage is the potential to incorporate temporal context, improving the accuracy and robustness of the results, particularly when dealing with camera motion and dynamic scenes. The method’s efficiency stems from this localized processing combined with the power of LDMs’ ability to extract meaningful features. However, the choice of window size and overlap are critical hyperparameters, requiring careful tuning to achieve a balance between computational efficiency and temporal coherence. Finally, a post-processing step might be employed to stitch together the results from individual segments into a smooth and consistent final output.
Snippet Depth Fusion#
Snippet depth fusion, as a conceptual approach, presents a compelling strategy for video depth estimation. The core idea involves processing short, temporally localized video snippets independently to generate depth estimates, then cleverly fusing these individual results. This approach offers several key advantages. First, it bypasses the computational burden and potential instability inherent in processing full-length videos with complex video models. By working with smaller, manageable chunks, computational efficiency is significantly improved, facilitating the handling of longer videos. Second, the localized processing addresses temporal inconsistency issues, a significant challenge in video depth estimation. By individually analyzing short clips, temporal coherence within each snippet is enhanced, leading to more reliable depth map generation. The fusion step, crucial to the overall success, integrates these localized depth estimations. This fusion must be carefully designed to ensure temporal consistency across the entire video sequence. A robust alignment or registration algorithm is needed to correct for scale and shift differences, and methods to reconcile conflicting or inconsistent depth predictions within overlapping snippets must be applied. Overall, snippet depth fusion provides a promising pathway to effective and efficient video depth estimation, but the success depends significantly on the sophisticated design of the fusion process that maintains temporal coherence.
Ablation Experiments#
Ablation studies systematically investigate the contribution of individual components within a complex system. In the context of a research paper, an ‘Ablation Experiments’ section would typically involve removing or disabling specific parts of the proposed model or method to assess their impact on the overall performance. This is crucial for establishing the necessity and effectiveness of each component. For instance, if a new video depth estimation model incorporates a novel co-alignment algorithm and a refinement step, ablation would examine the model’s accuracy with only the co-alignment, only the refinement, and neither. The results of such experiments provide strong evidence for design choices and justify the architecture’s complexity. By showing that each component significantly contributes to the model’s performance, the authors build a compelling case for their method’s effectiveness and superiority compared to simpler alternatives. A well-designed ablation study not only validates the contributions of specific parts but also offers valuable insights into the model’s internal workings and its sensitivity to different components. Moreover, understanding which components are crucial, and which ones could be simplified or removed without impacting performance, might lead to improvements and more efficient model versions in future work.
Future of Video Depth#
The future of video depth estimation lies in addressing current limitations and exploring new avenues. Improved temporal consistency remains a crucial goal, moving beyond simple frame-to-frame smoothing to achieve truly coherent 3D scene representations across long video sequences. This necessitates advanced techniques beyond current methods, perhaps leveraging more sophisticated temporal modeling or integrating powerful video generative models effectively. Enhanced accuracy and robustness are also vital, particularly for challenging scenarios such as significant depth range changes or challenging lighting conditions. This will likely involve further advances in underlying monocular depth estimation models and the integration of additional cues such as motion and optical flow. Efficient inference and scalability are key concerns, especially for real-time applications. Therefore, optimized architectures and algorithms will be essential, perhaps incorporating more effective knowledge distillation techniques or exploring hardware acceleration possibilities. Finally, broader applications and datasets are vital for driving future research. New datasets capturing diverse scenes, camera motions, and object dynamics will be crucial in testing the limits of existing methods and pushing the field forward. These improvements will enable wide-ranging applications including autonomous driving, AR/VR, and 3D video content creation.
More visual insights#
More on figures

🔼 The RollingDepth model processes video data by first dividing it into overlapping short segments (snippets) using a rolling window. The snippets are processed using a single-image depth estimation model to get initial depth estimates. These are then aligned to achieve temporal consistency across the entire video by adjusting scale and shift values. Finally, an optional step refines the results with further denoising.
read the caption
Figure 2: Overview of the RollingDepth Inference Pipeline. Given a video sequence 𝐱𝐱\mathbf{x}bold_x (with is ithsuperscript𝑖thi^{\text{th}}italic_i start_POSTSUPERSCRIPT th end_POSTSUPERSCRIPT frame), we construct NTsubscript𝑁𝑇N_{T}italic_N start_POSTSUBSCRIPT italic_T end_POSTSUBSCRIPT overlapping snippets using a dilated rolling kernel with varying dilation rates, and perform 1-step inference to obtain initial depth snippets ( ). Next, depth co-alignment optimizes NTsubscript𝑁𝑇N_{T}italic_N start_POSTSUBSCRIPT italic_T end_POSTSUBSCRIPT pairs of scale and shift values to achieve globally consistent depth throughout the full video. An optional refinement step further enhances details by applying additional, snippet-based denoising steps.

🔼 The figure illustrates the depth refinement process in the RollingDepth model. A co-aligned depth video is first encoded into a latent space. Then, a moderate level of noise is added. The denoising process follows, using a series of reverse diffusion steps with progressively decreasing snippet dilation rates. This approach ensures that information is shared and refined across overlapping snippets throughout the video, leading to a smoother, more coherent final depth map.
read the caption
Figure 3: Depth Refinement encodes the co-aligned depth video into latent space, contaminates it with a moderate amount of noise, then denoises it with a series of reverse diffusion steps with decreasing snippet dilation rate. After each step, overlapping latents are averaged to propagate information between snippets.

🔼 This figure showcases a qualitative comparison of depth estimation results produced by various methods, including RollingDepth, DepthCrafter, ChronoDepth, and Marigold. The images highlight RollingDepth’s ability to preserve fine details in the scene, such as the intricate details of a chandelier and a tripod, which other methods often fail to capture accurately. RollingDepth also more accurately reconstructs the depth of distant parts of the scene, as demonstrated in the accurate representation of the far plane in one of the example scenes. These results highlight the improved accuracy of RollingDepth compared to existing methods.
read the caption
Figure 4: Qualitative comparison between different methods. RollingDepth excels at preserving fine-grained details (cf. the chandelier in the first sample and the tripod in the third sample) and recovering accurate scene layout (cf. the far plane in the second sample).

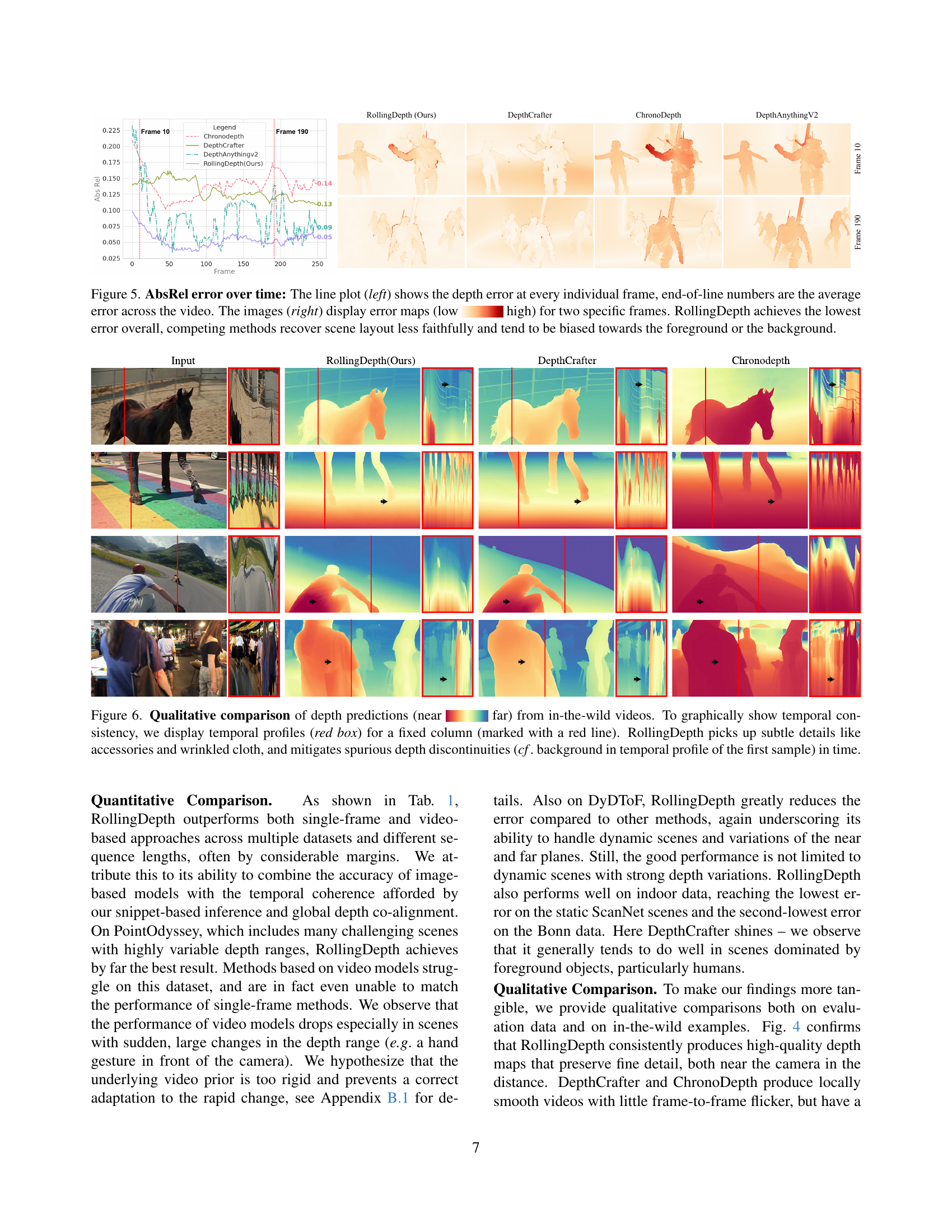
🔼 Figure 5 presents a comparative analysis of depth estimation error over time across different methods. The left side shows line plots illustrating the absolute relative error (AbsRel) for each frame of example video sequences. The end-of-line numerical values represent the average AbsRel across the entire video. The right side provides visual error maps for two specific frames from these videos, using a color scale to represent the magnitude of error (low to high). This visualization helps to show the spatial distribution of errors and which areas each model struggles with. The results demonstrate that RollingDepth consistently achieves the lowest overall error, while competing methods show less accurate scene reconstruction and a tendency to favor either foreground or background elements.
read the caption
Figure 5: AbsRel error over time: The line plot (left) shows the depth error at every individual frame, end-of-line numbers are the average error across the video. The images (right) display error maps (low high) for two specific frames. RollingDepth achieves the lowest error overall, competing methods recover scene layout less faithfully and tend to be biased towards the foreground or the background.

🔼 Figure 6 presents a qualitative comparison of depth maps generated by different methods for real-world video sequences. The figure visually demonstrates the temporal consistency of depth estimations, which is crucial for high-quality video depth maps. Each sequence shows a temporal profile (in a red box) that tracks a single column’s depth values over time. This highlights the stability and accuracy of RollingDepth in capturing fine details, like wrinkles in clothing and accessories, while minimizing artifacts (such as abrupt changes in background depth). The figure contrasts RollingDepth’s performance with other methods, revealing RollingDepth’s superiority in producing smooth, temporally consistent depth estimations.
read the caption
Figure 6: Qualitative comparison of depth predictions (near far) from in-the-wild videos. To graphically show temporal consistency, we display temporal profiles (red box) for a fixed column (marked with a red line). RollingDepth picks up subtle details like accessories and wrinkled cloth, and mitigates spurious depth discontinuities (cf. background in temporal profile of the first sample) in time.

🔼 This figure showcases examples from the PointOdyssey dataset that present challenges for depth estimation models. The left side displays simplistic, toy-like scenes which are not representative of real-world scenarios and thus could lead to overfitting or biased model training. The right side shows scenes containing smoke, an element which tends to cause ambiguity in depth perception for computer vision systems, potentially leading to inconsistent depth map predictions.
read the caption
Figure S1: Examples of PointOdyssey toy scenes (left) and scenes with smoke (right).

🔼 Figure S2 showcases examples from the PointOdyssey dataset where video depth estimation models struggle. These examples highlight scenarios with rapidly changing inverse depth ranges across frames. The arrows pinpoint areas where these models produce inaccurate depth maps. In the top two rows, inaccuracies arise in regions exhibiting significant depth differences from their surroundings. The bottom row illustrates a scenario where the model prioritizes matching the depth of a nearby object, thereby distorting the depth values of faraway elements.
read the caption
Figure S2: Examples of PointOdyssey samples that challenge video models. In the cases above, the (inverse) depth range varies significantly across frames. The arrows highlight situations where video models yield distorted depth maps. In the first two rows, this occurs in regions where the depth deviates significantly from the surrounding scene. In the last row, the depth predictions get drawn towards the near plane to match the object close to the camera, biasing the depth in the far field.

🔼 Figure S3 showcases examples where RollingDepth struggles. The left side displays inaccurate depth estimations in cloudy skies, a common challenge for depth prediction models. The right side highlights inconsistencies in depth estimations across frames of the same video, specifically concerning areas with glass windows. These inconsistencies manifest as fluctuating depth readings, sometimes appearing solid and at other times transparent, which can be attributed to issues related to the transparency and reflections of glass surfaces.
read the caption
Figure S3: The two samples on the left show incorrect depth predictions in the cloudy sky. The two samples on the right show inconsistencies between different frames of the same video, where the depth at the glass windows fluctuates between the solid and transparent states.
More on tables
| Dilation rates | PointOdyssey Abs Rel↓ | PointOdyssey δ1 ↑ | ScanNet Abs Rel↓ | ScanNet δ1 ↑ | |
|---|---|---|---|---|---|
| {1} | 16.7 | 75.5 | 12.8 | 83.2 | |
| {1, 25} | 10.2 | 89.5 | 10.6 | 88.8 | |
| {1, 10, 25} | 10.2 | 89.6 | 9.9 | 90.1 |
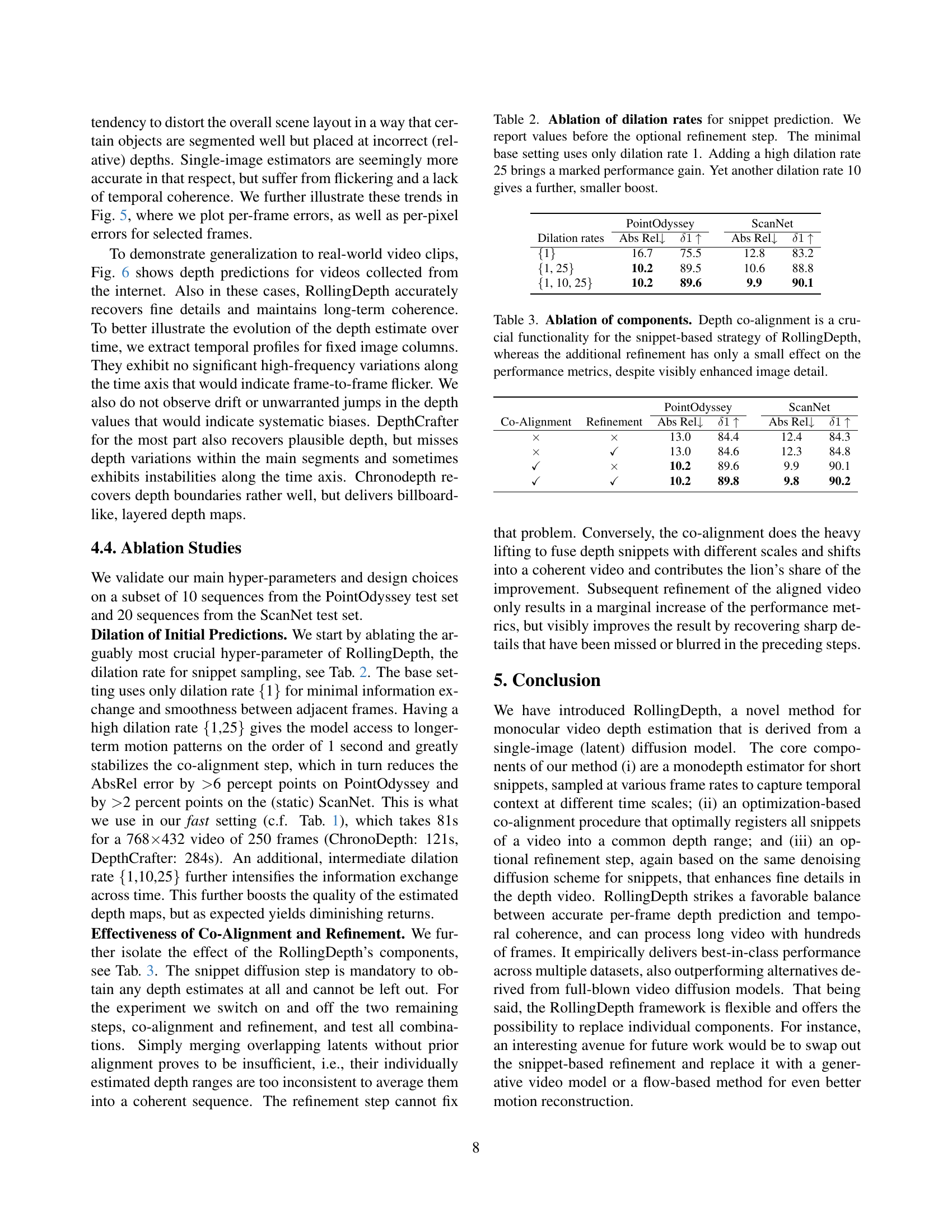
🔼 This ablation study analyzes the impact of different dilation rates used in the RollingDepth model’s snippet sampling process on depth prediction accuracy. The table shows the results before the optional refinement step. The baseline uses a dilation rate of 1, representing minimal temporal context. Adding a dilation rate of 25 significantly improves performance, indicating the benefit of incorporating longer-range temporal information. Including an additional dilation rate of 10 provides a smaller, yet still noticeable, further improvement. The results are presented in terms of Absolute Relative error and δ1 accuracy metrics for the PointOdyssey and ScanNet datasets.
read the caption
Table 2: Ablation of dilation rates for snippet prediction. We report values before the optional refinement step. The minimal base setting uses only dilation rate 1. Adding a high dilation rate 25 brings a marked performance gain. Yet another dilation rate 10 gives a further, smaller boost.
| Co-Alignment | Refinement | PointOdyssey Abs Rel↓ | PointOdyssey δ1 ↑ | ScanNet Abs Rel↓ | ScanNet δ1 ↑ | |
|---|---|---|---|---|---|---|
| × | × | 13.0 | 84.4 | 12.4 | 84.3 | |
| × | ✓ | 13.0 | 84.6 | 12.3 | 84.8 | |
| ✓ | × | 10.2 | 89.6 | 9.9 | 90.1 | |
| ✓ | ✓ | 10.2 | 89.8 | 9.8 | 90.2 |
🔼 This table presents the ablation study results for RollingDepth, examining the impact of its key components: depth co-alignment and refinement. Depth co-alignment is shown to be crucial for the success of the snippet-based strategy, significantly impacting performance metrics. In contrast, the refinement step, while visually improving image detail, has only a minor effect on the quantitative metrics.
read the caption
Table 3: Ablation of components. Depth co-alignment is a crucial functionality for the snippet-based strategy of RollingDepth, whereas the additional refinement has only a small effect on the performance metrics, despite visibly enhanced image detail.
Full paper#