↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video generation methods struggle with precise and consistent camera motion control, often producing imprecise outputs or neglecting temporal correlations. Many existing methods either use high-level constraints leading to ambiguous results or neglect temporal correlations resulting in inconsistencies. This paper introduces a novel approach called Trajectory Attention that addresses these issues.
Trajectory Attention injects trajectory information directly into the video generation process by using an auxiliary branch alongside traditional temporal attention. This design enables the two attention mechanisms to work synergistically, resulting in both precise motion control and high-quality content generation. The paper demonstrates significant improvements in precision and long-range consistency on various tasks, including camera motion control for images and videos, and first-frame-guided video editing.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to fine-grained video motion control, a crucial challenge in creating view-customized visual content. The method’s efficiency and generalizability make it relevant to various video generation tasks. The strong inductive bias offered by trajectory attention significantly improves precision and long-range consistency, opening avenues for more advanced video editing and generation techniques.
Visual Insights#

🔼 Figure 1 showcases the capabilities of trajectory attention in handling various video generation tasks. The figure demonstrates how trajectory attention ensures content consistency along trajectories, thereby enabling precise camera motion control. Three main applications are shown: camera motion control applied to images, camera motion control applied to videos, and first-frame-guided video editing. In each example, yellow boxes represent reference content, green boxes show the input frames, and blue boxes depict the generated output frames. This visually highlights how the model uses trajectory attention to maintain content coherence while adjusting the motion according to specified trajectories.
read the caption
Figure 1: Trajectory attention injects partial motion information by making content along trajectories consistent. It facilitates various tasks such as camera motion control on images and videos, and first-frame-guided video editing. Yellow boxes indicate reference contents. Green boxes indicate input frames. Blue boxes indicate output frames.
| Setting | Methods | ATE (m, ↓) | RPE trans (m, ↓) | RPE Rot (deg, ↓) | FID (↓) |
|---|---|---|---|---|---|
| 14 frames | MotionCtrl | 1.2151 | 0.5213 | 1.8372 | 101.3 |
| Ours | 0.0212 | 0.0221 | 0.1151 | 104.2 | |
| 16 frames | MotionI2V* | 0.0712 | 0.0471 | 0.2853 | 124.1 |
| Ours | 0.0413 | 0.0241 | 0.1231 | 108.7 | |
| 25 frames | CameraCtrl | 0.0411 | 0.0268 | 0.3480 | 115.8 |
| NVS_Solver | 0.1216 | 0.0558 | 0.4785 | 108.5 | |
| Ours | 0.0396 | 0.0232 | 0.1939 | 103.5 |
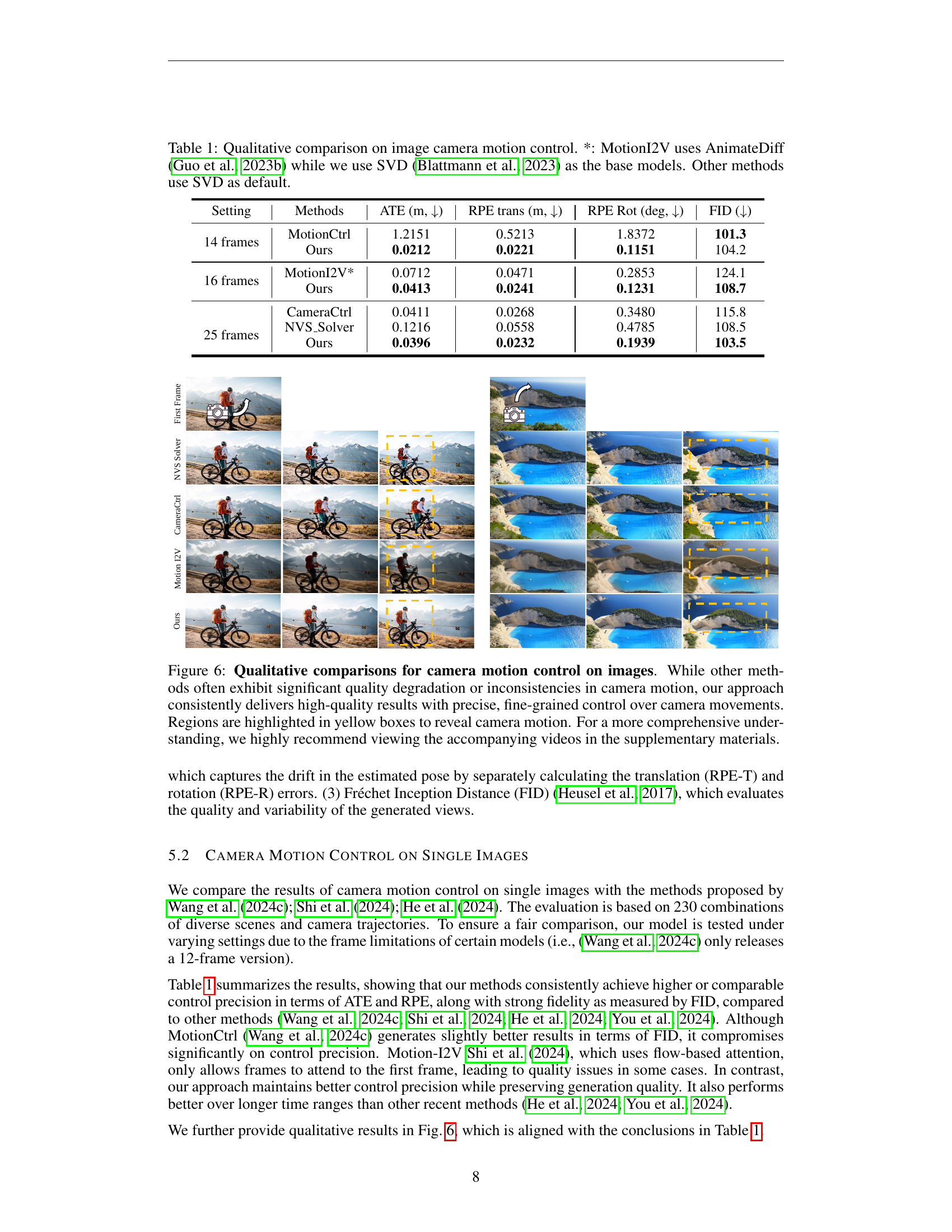
🔼 Table 1 presents a qualitative comparison of different methods for image camera motion control. It compares the performance of several methods, including the proposed method, MotionI2V (which uses AnimateDiff as its base model), and other methods (using SVD as the default base model). The comparison is based on four metrics: Absolute Trajectory Error (ATE), Relative Pose Error (translation and rotation), and Fréchet Inception Distance (FID). Lower values indicate better performance for ATE and RPE, while a lower FID score signifies higher visual quality.
read the caption
Table 1: Qualitative comparison on image camera motion control. *: MotionI2V uses AnimateDiff (Guo et al., 2023b) while we use SVD (Blattmann et al., 2023) as the base models. Other methods use SVD as default.
In-depth insights#
Trajectory Attention#
The proposed ‘Trajectory Attention’ mechanism offers a novel approach to fine-grained video motion control by leveraging pixel trajectories. Unlike traditional methods that often struggle with temporal consistency or imprecise outputs, this technique directly incorporates trajectory information into the video generation process via an auxiliary branch working in synergy with temporal attention. This design allows for precise motion control while simultaneously enabling creative content generation, even when trajectory data is incomplete. A key advantage is the stronger inductive bias, improving long-range consistency and precision in tasks like camera motion control and first-frame-guided video editing. The method’s adaptability and efficiency, even with limited data, suggest its significant potential for various video generation applications. The results demonstrate clear improvements over existing techniques in terms of accuracy and fidelity, highlighting the effectiveness of this novel approach to motion control within video generation models.
Motion Control#
The research paper explores the critical aspect of motion control within the context of video generation. Fine-grained control over video motion is presented as a significant challenge, with existing methods often falling short due to imprecise outputs or neglecting temporal correlations. The paper proposes a novel approach, trajectory attention, which leverages attention mechanisms along pixel trajectories to enhance motion precision and long-range consistency. Trajectory attention works synergistically with traditional temporal attention, addressing limitations of methods that focus solely on short-range dynamics. The effectiveness is demonstrated through various applications, including camera motion control in image and video generation, along with first-frame-guided video editing, where consistent content generation over large spatial and temporal ranges is achieved. The method’s strength lies in its ability to model temporal relationships explicitly, using trajectories as a strong inductive bias to maintain motion fidelity and quality, while showing potential for broader application in other video motion control tasks.
Video Diffusion#
Video diffusion models have emerged as a powerful technique in video generation, offering significant improvements over previous methods. They leverage the principles of diffusion models, iteratively adding noise to a video until it becomes pure noise, and then reversing this process to generate new videos from noise. A key advantage is the ability to control various aspects of video generation, including content, style, and camera motion. However, challenges remain. Precise control over fine-grained aspects like camera motion and temporal consistency is difficult. Existing approaches often rely on high-level control signals which lack precision. Furthermore, handling long-range temporal dependencies is an ongoing area of research. The development of more effective temporal attention mechanisms and sophisticated inductive biases is crucial for achieving high-quality, consistent video generation and better motion control.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of this video motion control research, an ablation study would likely investigate the impact of removing or modifying key elements like trajectory attention, temporal attention, or the interaction between them. By removing trajectory attention, the researchers could observe how this affects motion precision and long-range consistency in generated videos. Similarly, removing or altering the parameters of the temporal attention mechanism could reveal its importance in maintaining content coherence during dynamic motion synthesis. Comparing the results across different ablation scenarios—with and without trajectory and/or temporal attention—would highlight the individual and combined roles of these components in achieving fine-grained video motion control. The results would likely demonstrate the synergistic effect of trajectory and temporal attention, where both contribute to overall performance, but trajectory attention specifically handles long-range consistency, while temporal attention focuses on short-term coherence. A strong ablation study would carefully consider the impact of removing these features on various metrics like absolute trajectory error (ATE), relative pose error (RPE), and Fréchet inception distance (FID), ultimately solidifying the claims made about the contribution of trajectory attention.
Future Work#
Future research directions stemming from this trajectory attention model for fine-grained video motion control could fruitfully explore several avenues. Improving trajectory extraction is crucial; current reliance on external methods limits flexibility. Developing methods that directly learn trajectories from diverse inputs like text descriptions or sketches would significantly enhance usability. Addressing the sparsity issue is also vital; while the model shows resilience, performance degrades with extremely sparse trajectories. Investigating more robust methods for handling sparse or noisy trajectory data, perhaps through data augmentation or more sophisticated attention mechanisms, warrants attention. Additionally, the model’s current dependence on pre-trained video diffusion models could be addressed by exploring more end-to-end training strategies that jointly learn the trajectory attention and the video generation process. This may lead to improved generation quality and controllability. Finally, extending the approach to other motion control tasks beyond camera control, such as object manipulation or character animation within videos, could unlock new possibilities and further establish the generality of this approach.
More visual insights#
More on figures

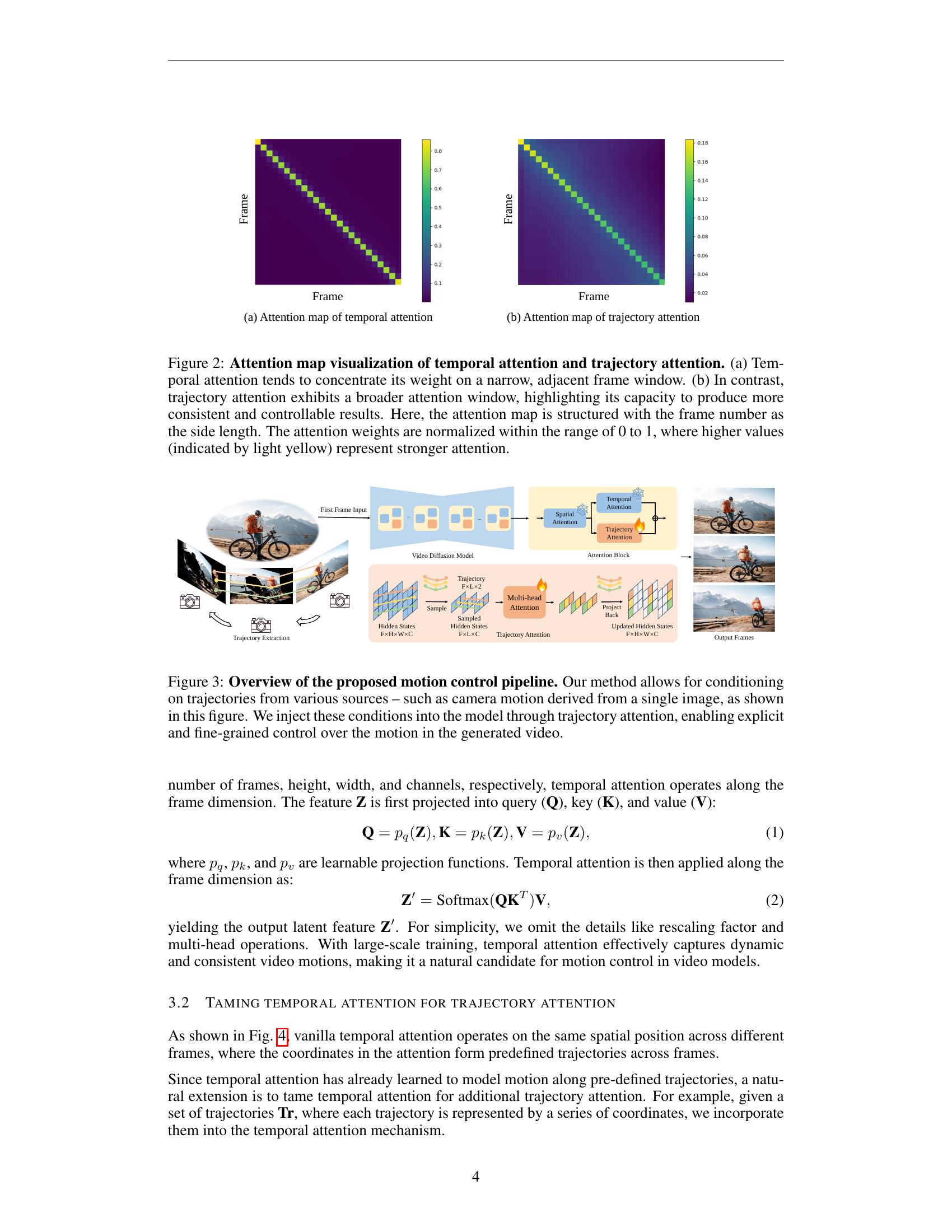
🔼 This figure visualizes the attention maps of temporal attention and trajectory attention mechanisms. The heatmaps show the weight distribution across frames. (a) shows that temporal attention focuses on nearby frames, indicating short-range dependencies. (b) shows that trajectory attention has a much broader scope, focusing on more distant frames along the trajectory. The wider attention window in (b) allows for better long-range consistency and more controlled generation of movement. The intensity of the color represents the attention weight; brighter yellow indicates stronger attention.
read the caption
Figure 2: Attention map visualization of temporal attention and trajectory attention. (a) Temporal attention tends to concentrate its weight on a narrow, adjacent frame window. (b) In contrast, trajectory attention exhibits a broader attention window, highlighting its capacity to produce more consistent and controllable results. Here, the attention map is structured with the frame number as the side length. The attention weights are normalized within the range of 0 to 1, where higher values (indicated by light yellow) represent stronger attention.

🔼 This figure illustrates the pipeline for fine-grained video motion control using trajectory attention. The process begins with input, which can be a single image or video, from which trajectories are extracted. These trajectories are then processed by the trajectory attention mechanism, which injects information about the motion into a video diffusion model. The model incorporates both the trajectories and temporal information (from the video) to generate a video with explicit and fine-grained control over the motion. This allows the user to control the video’s motion precisely according to the specified trajectories. The figure visually shows how trajectory attention works in conjunction with a video diffusion model to produce the final video output.
read the caption
Figure 3: Overview of the proposed motion control pipeline. Our method allows for conditioning on trajectories from various sources – such as camera motion derived from a single image, as shown in this figure. We inject these conditions into the model through trajectory attention, enabling explicit and fine-grained control over the motion in the generated video.

🔼 This figure visualizes the attention maps of vanilla temporal attention and trajectory attention. Vanilla temporal attention focuses its attention weights narrowly on adjacent frames, highlighting its short-range dependency in motion synthesis. In contrast, trajectory attention exhibits a much broader attention window, emphasizing its capacity for long-range consistency across features along a trajectory. This difference demonstrates the distinct roles of these two attention mechanisms within the video generation process: temporal attention balances content consistency and motion synthesis, while trajectory attention specifically maintains consistency along the explicit trajectory. The visualization underscores how trajectory attention provides a strong inductive bias for fine-grained motion control.
read the caption
Figure 4: Visualization of vanilla temporal attention and trajectory attention.

🔼 This figure illustrates the training strategy employed for trajectory attention. Leveraging pre-trained knowledge from large-scale datasets, the weights of the Query (Q), Key (K), and Value (V) projectors within the trajectory attention module are initialized using the weights from the corresponding temporal attention layers. This transfer learning approach leverages the motion modeling capabilities already learned by the temporal attention. To ensure a stable and gradual training process for the trajectory attention branch, the output projector’s weights are initialized to zero. This prevents the trajectory attention from dominating the training process at the start and enables a smoother integration of this new branch into the existing model architecture.
read the caption
Figure 5: Training strategy for trajectory attention. To leverage the motion modeling capability learned from large-scale data, we initialize the weights of the QKV projectors with those from temporal attention layers. Additionally, the output projector is initialized with zero weights to ensure a smooth and gradual training process.

🔼 This figure displays a qualitative comparison of camera motion control results on images. It showcases how different methods handle the task, highlighting the superior performance of the proposed approach. The results demonstrate that while other techniques often result in poor image quality and inconsistent camera motion, the novel method produces high-quality images with precise and finely controlled camera movements. The yellow boxes highlight specific regions to emphasize the difference in camera motion between the various methods. To fully appreciate the results and the subtle details of the motion, it is recommended that the accompanying video be viewed.
read the caption
Figure 6: Qualitative comparisons for camera motion control on images. While other methods often exhibit significant quality degradation or inconsistencies in camera motion, our approach consistently delivers high-quality results with precise, fine-grained control over camera movements. Regions are highlighted in yellow boxes to reveal camera motion. For a more comprehensive understanding, we highly recommend viewing the accompanying videos in the supplementary materials.

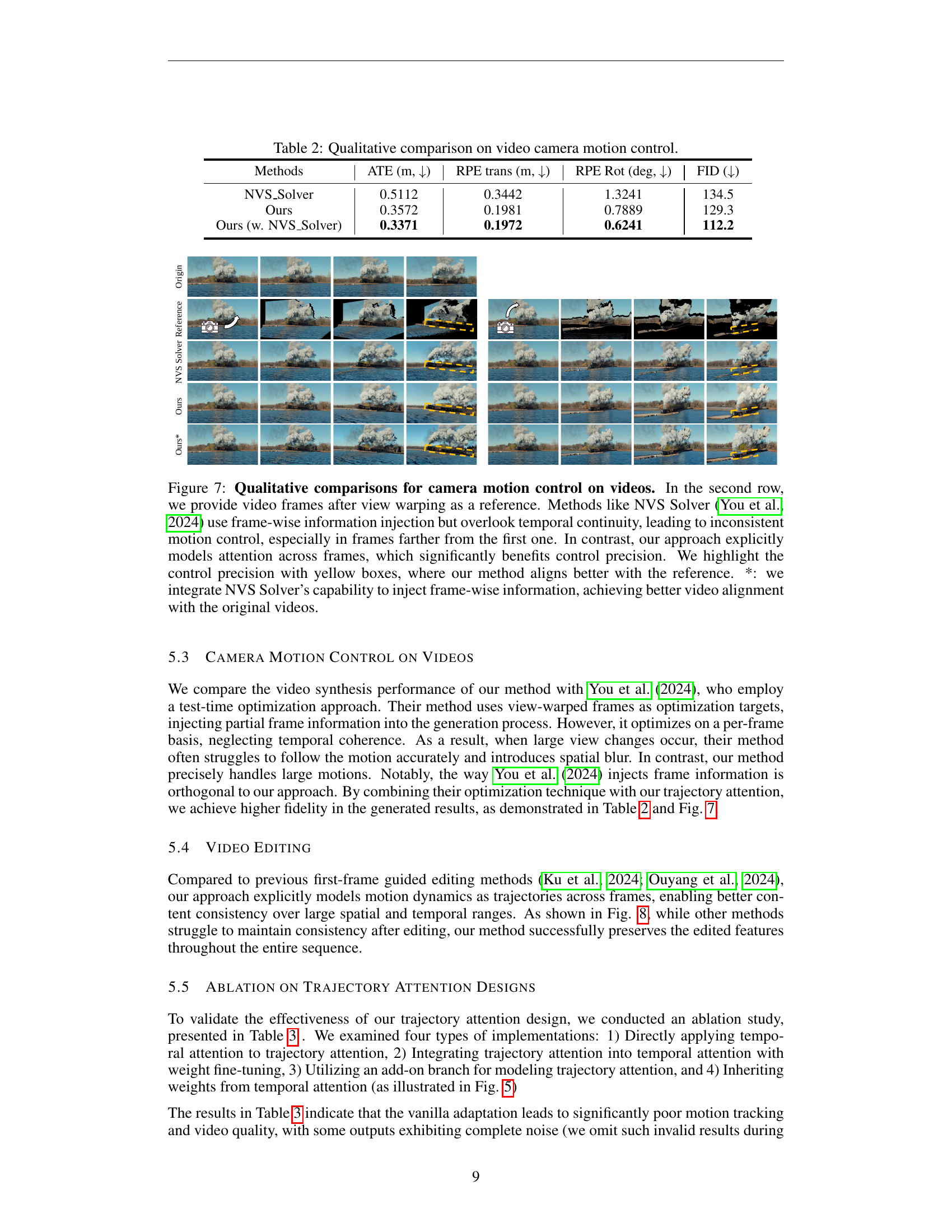
🔼 Figure 7 presents a qualitative comparison of video camera motion control methods. The top row shows results from different methods, including the proposed approach, while the bottom row shows the reference video frames after view warping for comparison. It demonstrates that methods like NVS Solver, which inject frame-wise information without considering temporal continuity, result in inconsistent motion control, particularly in frames further from the beginning. In contrast, the proposed method, which explicitly models attention across frames, shows significantly improved precision in camera motion control and better alignment with the reference video.
read the caption
Figure 7: Qualitative comparisons for camera motion control on videos. In the second row, we provide video frames after view warping as a reference. Methods like NVS Solver (You et al., 2024) use frame-wise information injection but overlook temporal continuity, leading to inconsistent motion control, especially in frames farther from the first one. In contrast, our approach explicitly models attention across frames, which significantly benefits control precision. We highlight the control precision with yellow boxes, where our method aligns better with the reference. *: we integrate NVS Solver’s capability to inject frame-wise information, achieving better video alignment with the original videos.

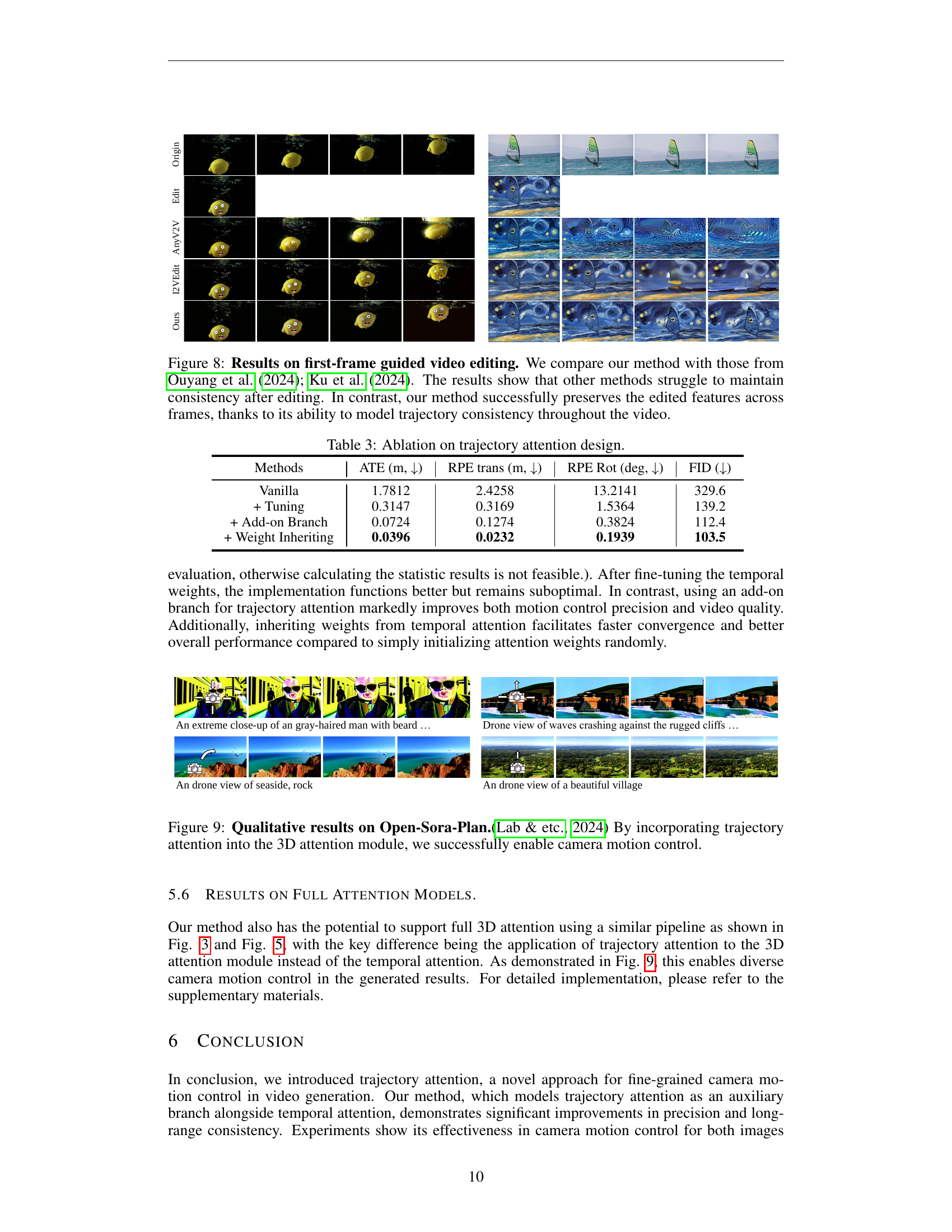
🔼 Figure 8 presents a comparison of first-frame guided video editing results between the proposed method and existing methods (Ouyang et al., 2024; Ku et al., 2024). The figure demonstrates that while other techniques struggle to maintain consistency and coherence in the generated video after editing the first frame, the proposed method effectively preserves the edited features and ensures smooth transitions across frames. This is attributed to the model’s superior ability to capture and maintain trajectory consistency throughout the video generation process.
read the caption
Figure 8: Results on first-frame guided video editing. We compare our method with those from Ouyang et al. (2024); Ku et al. (2024). The results show that other methods struggle to maintain consistency after editing. In contrast, our method successfully preserves the edited features across frames, thanks to its ability to model trajectory consistency throughout the video.

🔼 This figure showcases the qualitative results achieved by integrating trajectory attention into a 3D attention module within the Open-Sora-Plan framework. It demonstrates the effectiveness of this approach in achieving fine-grained camera motion control within video generation. The results highlight the model’s capability to produce high-quality video outputs with precise and consistent camera movements.
read the caption
Figure 9: Qualitative results on Open-Sora-Plan.(Lab & etc., 2024) By incorporating trajectory attention into the 3D attention module, we successfully enable camera motion control.

🔼 This figure illustrates the architecture of a video diffusion model that incorporates 3D attention. The key difference from the model presented in the main body of the paper is the placement of the trajectory attention module. Instead of modifying the existing temporal attention mechanism, the trajectory attention is added as a separate branch directly within the 3D attention module. This architectural choice allows for a more effective integration of trajectory information into the video generation process without interfering with the existing temporal dynamics captured by the model.
read the caption
Figure 10: Pipe for video diffusion models with 3D Attention. The key distinction with the pipeline in the main paper lies in applying trajectory attention to the 3D attention module, rather than to the temporal attention mechanism.

🔼 This figure displays the results of depth map estimation from a single image using the DepthAnythingV2 method. It visually compares the original image with its corresponding depth map, illustrating the model’s ability to estimate depth information from a 2D image. The depth map provides a representation of the distance of different image regions from the camera, with brighter regions representing closer distances and darker regions representing further distances.
read the caption
Figure 11: Depth estimation results.

🔼 This figure visualizes the results of point trajectory estimation. It showcases examples of estimated trajectories overlaid on video frames. The accuracy of the trajectory estimation is crucial for the success of the method, as it directly impacts the precision and consistency of camera motion control. The figure likely demonstrates the effectiveness of the point trajectory estimation method on various video sequences, thereby showcasing the quality and reliability of its performance in different scenarios.
read the caption
Figure 12: Point trajectory estimation results.

🔼 This figure visualizes the input process for both camera motion control and video editing tasks. For both tasks, the input to the neural network consists of two components: the first frame of the video and the extracted trajectories. The trajectories are obtained using the methods described previously in the paper and represent the camera or object movement. Importantly, unlike some other methods, the wrapped frames and reference frames shown in Figure 1 are not directly used as inputs to the network. Instead, the model uses the first frame and the computed trajectories to generate the output video.
read the caption
Figure 13: Input process visualization. For all tasks, the inputs to the network are the first frame and the extracted trajectories. The usage of the first frame and the trajectories are identical to Fig. 3 in the main paper. The wrapped frames and the reference frames will not be used as inputs to the generation network.

🔼 Figure 14 demonstrates the use of synthetic optical flow to guide video generation. Unlike methods that require inference-time optimization, this approach directly incorporates optical flow into the attention mechanism. This seamless integration not only generates intermediate frames through optical flow interpolation but also enhances the consistency of the generated video. Blue boxes highlight the optical flow, while yellow boxes show the reference images.
read the caption
Figure 14: Using synthetic optical flow as guidance. Our method supports directly using optical flow to guide generation. Blue boxes indicate the optical flow. Yellow boxes indicate the reference image.

🔼 Figure 15 showcases the robustness of the proposed trajectory attention mechanism by demonstrating its effectiveness in various challenging video editing scenarios. These include: (a) videos with multiple objects requiring intricate motion coordination; (b) videos with occlusions, necessitating accurate motion prediction and content generation despite missing information; (c) videos exhibiting diverse and rapid camera movements, such as zooming, panning, and rotation; and (d) videos featuring distinct object categories, each potentially following separate, complex trajectories. The figure uses consistent color-coding: yellow boxes highlight the reference videos used as input guidance, green boxes indicate the input frames, and blue boxes display the generated output frames. The results highlight the approach’s ability to handle complex motion patterns and generate coherent videos in challenging contexts.
read the caption
Figure 15: Examples of challenging situations. Our method effectively addresses complex scenarios, including (a) video editing involving multiple objects, (b) video editing in the presence of occlusions, (c) diverse and rapid camera movements, such as zooming in and out, as well as clockwise rotations, and (d) video editing with distinct object categories. Please note that yellow boxes indicate reference videos, green boxes indicate input frames and blue boxes indicate output results.

🔼 This figure compares the estimated camera trajectories generated by the proposed method and CameraCtrl against the ground truth trajectories. The top row shows the proposed method’s estimations alongside the ground truth, while the bottom row shows CameraCtrl’s estimations against the ground truth. The visualization clearly demonstrates that the proposed method’s estimated camera trajectories align much more closely with the ground truth than those produced by CameraCtrl, showcasing improved accuracy in camera motion prediction.
read the caption
Figure 16: Visualization of camera trajectories. The first row displays the estimated trajectories from our generation alongside the ground truth trajectories. The second row presents the estimated trajectories from CameraCtrl (denoted as “CC”) compared to the ground truth. The results indicate that our method aligns significantly better with the ground truth camera motion trajectories.

🔼 This figure demonstrates the robustness of trajectory attention to sparse trajectory data. Subfigure (a) shows that even with significantly reduced trajectory density (1/16th of the original resolution), the model maintains accurate motion control. Subfigure (b) illustrates the use of a trajectory mask to selectively control motion within a specific region, leaving other areas static. The model accurately reflects the motion within the masked region. Finally, subfigure (c) showcases the generation of more dynamic results by applying sparse trajectory control to a specific area, such as a dog’s movement in a video. The results highlight the method’s adaptability to varying levels of trajectory information, enabling flexible and precise motion control.
read the caption
Figure 17: Results on sparse trajectories. In (a), we show that trajectory attention remains robust even with relatively sparse trajectories. Even when the trajectory density is reduced to 1/16 of the original video resolution, it still performs well in motion control. In (b), we apply the trajectory mask to selectively use only a portion of the trajectories, keeping the regions outside the mask static. The model accurately follows the motion within the small masked area. (c) If we apply sparse trajectories control to a specific region (i.e., the dog region), the output results are more dynamic. Best viewed on the attached HTML file.

🔼 This figure demonstrates the effectiveness of trajectory attention in handling user-specified trajectories for video editing. The top row shows the original video frames, while the bottom row displays the results after applying a hand-crafted ‘dragging’ trajectory. This showcases the method’s capability to precisely control the motion based on the given trajectory, even when it’s not automatically extracted from the video but rather created manually by the user. The results highlight the method’s robustness and ability to handle user-defined edits.
read the caption
Figure 18: Applications on drag signals. Trajectory attention supports hand-crafted dragging trajectory. Row 1: origin videos. Row 2: dragged results.

🔼 This figure visualizes the components of the training data used in the study. It shows examples of original video frames, the predicted optical flow (representing motion between frames), and the occlusion masks (highlighting areas where objects are blocked or hidden). These three elements together constitute the input data for training the trajectory attention model, enabling it to learn how motion and visibility patterns affect video generation.
read the caption
Figure 19: Visualization on the training data. The training data includes origin frames, predicted optical flow, and occlusion masks.

🔼 This figure showcases instances where the proposed method struggles. The limitations are highlighted through examples of video generation failures stemming from two primary causes: extremely rapid camera movements that the model has difficulty tracking accurately and scenes with complex or ambiguous motion patterns that make precise trajectory estimation challenging. These failure modes demonstrate the boundaries of the method’s current capabilities.
read the caption
Figure 20: Visualization on failure cases. Our method encounters challenges when dealing with extremely fast motions as well as complex and difficult-to-estimate motion patterns.

🔼 This figure visualizes the impact of different intrinsic camera parameters on the generated video results. Specifically, it shows how varying the focal length affects the perspective and field of view in the generated video sequence. By comparing the results with different focal lengths (e.g., 260 and 50), the visualization demonstrates the effect of this parameter on the final image’s perspective and the overall realism of the generated video.
read the caption
Figure 21: Visualization on different intrinsic parameters.
More on tables
| Methods | ATE (m, ↓) | RPE trans (m, ↓) | RPE Rot (deg, ↓) | FID (↓) |
|---|---|---|---|---|
| NVS_Solver | 0.5112 | 0.3442 | 1.3241 | 134.5 |
| Ours | 0.3572 | 0.1981 | 0.7889 | 129.3 |
| Ours (w. NVS_Solver) | 0.3371 | 0.1972 | 0.6241 | 112.2 |
🔼 This table presents a qualitative comparison of different methods for video camera motion control. It compares the performance of several approaches using four metrics: Absolute Trajectory Error (ATE), Relative Pose Error in translation (RPE trans), Relative Pose Error in rotation (RPE Rot), and Fréchet Inception Distance (FID). Lower values for ATE, RPE trans, and RPE Rot indicate better motion control accuracy, while a lower FID value suggests higher visual quality of the generated videos.
read the caption
Table 2: Qualitative comparison on video camera motion control.
| Methods | ATE (m, ↓) | RPE trans (m, ↓) | RPE Rot (deg, ↓) | FID (↓) |
|---|---|---|---|---|
| Vanilla | 1.7812 | 2.4258 | 13.2141 | 329.6 |
| + Tuning | 0.3147 | 0.3169 | 1.5364 | 139.2 |
| + Add-on Branch | 0.0724 | 0.1274 | 0.3824 | 112.4 |
| + Weight Inheriting | 0.0396 | 0.0232 | 0.1939 | 103.5 |
🔼 This table presents the results of an ablation study conducted to evaluate different design choices for the trajectory attention mechanism. It compares four variations: a baseline where trajectory attention is directly applied to temporal attention; a version where trajectory attention parameters are fine-tuned along with the temporal attention parameters; a design employing trajectory attention as an auxiliary branch; and a design where the trajectory attention weights are initialized using the weights from the temporal attention layer. The metrics used for comparison are Absolute Trajectory Error (ATE), Relative Pose Error (RPE) for translation and rotation, and Fréchet Inception Distance (FID). These metrics assess the precision and consistency of camera motion control, as well as the overall visual quality of the generated videos.
read the caption
Table 3: Ablation on trajectory attention design.
| Dataset Setting | Training steps | ATE (m, ↓) | RPE trans (m, ↓) | RPE Rot (deg, ↓) | FID (↓) |
|---|---|---|---|---|---|
| 10k real-world | 40k | 0.0396 | 0.0232 | 0.1939 | 103.5 |
| 10k games | 40k | 0.0421 | 0.0211 | 0.2139 | 105.3 |
| 10k real-world + 10k games | 40k | 0.0372 | 0.0233 | 0.1899 | 102.2 |
🔼 This table presents the results of ablation studies conducted to evaluate the impact of different training datasets on the model’s performance. It compares results using 10k real-world videos, 10k game videos, and a combined dataset of 20k videos (10k real-world + 10k game). The model’s performance is assessed across four metrics: Absolute Trajectory Error (ATE), Relative Pose Error translation (RPE trans), Relative Pose Error rotation (RPE Rot), and Fréchet Inception Distance (FID). Lower values are better for ATE, RPE trans, RPE rot, and FID, indicating higher accuracy and better image quality.
read the caption
Table 4: Ablations on training datasets.
Full paper#