↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current long-form video understanding models struggle with high computational and memory costs due to the quadratic complexity of transformer-based architectures. These models often resort to sparse sampling, losing crucial temporal information. This results in suboptimal performance in tasks requiring a comprehensive understanding of long video content.
The Video-Ma²mba model tackles these issues by replacing the transformer architecture with State Space Models (SSMs) within the Mamba-2 framework. This allows for linear scaling in terms of memory and computation, significantly reducing resource demands. Further enhanced by the innovative Multi-Axis Gradient Checkpointing (MA-GC) method, Video-Ma²mba demonstrates impressive results on various benchmark datasets, proving its capability to efficiently handle long video sequences and maintain high accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with long-form videos and large language models. It directly addresses the critical challenge of quadratic memory growth in processing long video sequences, offering a scalable solution for video understanding tasks. The proposed MA-GC technique and the use of the Mamba-2 architecture open up exciting avenues for improved efficiency and model scalability, significantly impacting future research in this area. The findings have implications for numerous video applications requiring extensive context understanding.
Visual Insights#

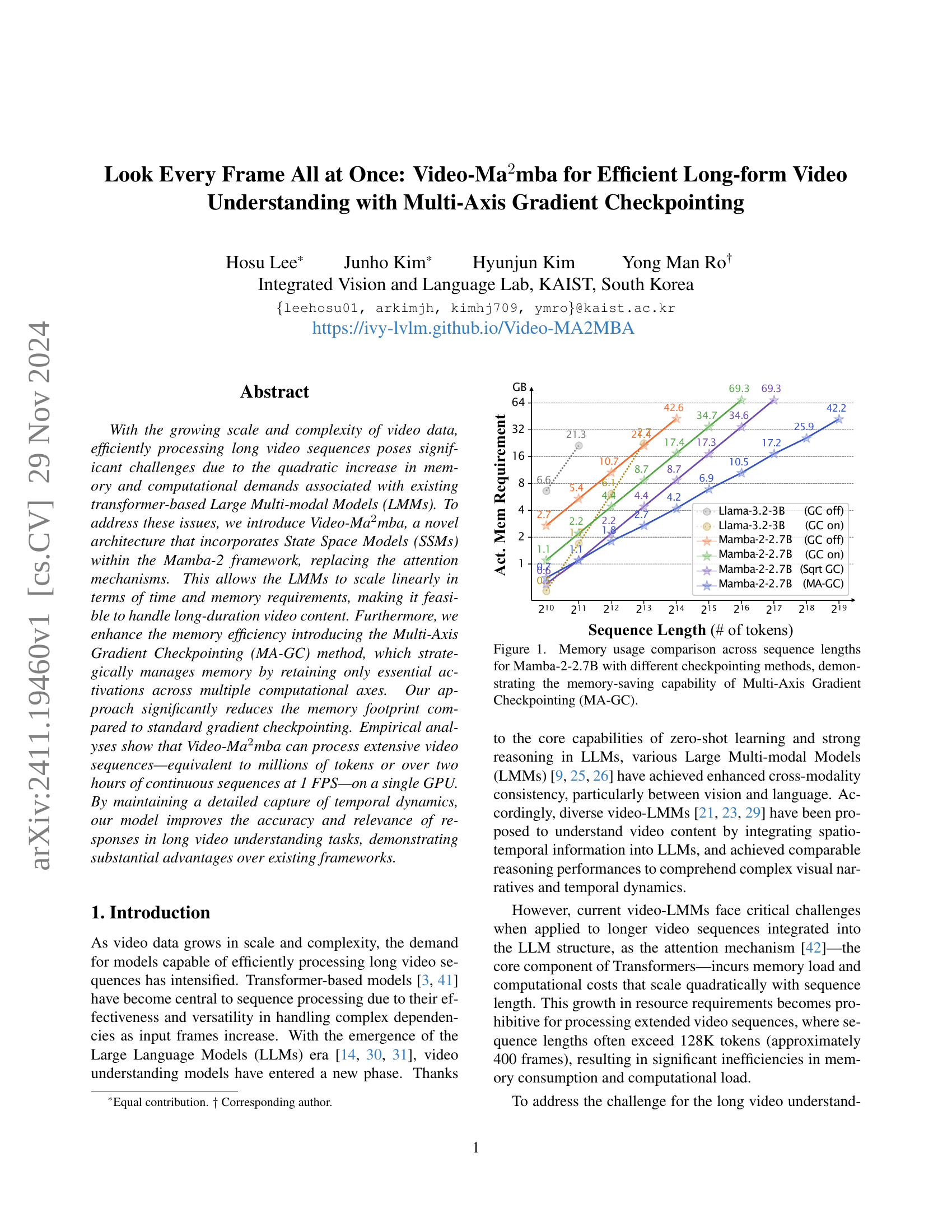
🔼 This figure compares the memory usage of the Mamba-2-2.7B model across various sequence lengths when using different gradient checkpointing methods. The x-axis represents the sequence length (in number of tokens), and the y-axis shows the actual memory used in gigabytes (GB). Different lines represent different checkpointing strategies: no checkpointing (GC off), standard gradient checkpointing (GC on), square root gradient checkpointing (Sqrt GC), and the proposed Multi-Axis Gradient Checkpointing (MA-GC). The figure demonstrates that MA-GC significantly reduces memory consumption compared to the other methods, especially as sequence length increases. This highlights the memory efficiency improvements achieved by the novel MA-GC method.
read the caption
Figure 1: Memory usage comparison across sequence lengths for Mamba-2-2.7B with different checkpointing methods, demonstrating the memory-saving capability of Multi-Axis Gradient Checkpointing (MA-GC).
| — | — | — | — | — | — |
|---|---|---|---|---|---|
| Video-MME | |||||
| — | — | — | — | — | — |
| Model | Size | Short | Medium | Long | Avg. |
| — | — | — | — | — | — |
| GPT-4V [32] | - | 70.5 | 55.8 | 53.5 | 59.9 |
| GPT-4o [33] | - | 80.0 | 70.3 | 65.3 | 71.9 |
| Gemini 1.5 Pro [38] | - | 81.7 | 74.3 | 67.4 | 75.0 |
| ST-LLM [28] | 7B | 45.7 | 36.8 | 31.3 | 37.9 |
| VideoChat2-Mistral [21] | 7B | 48.3 | 37.0 | 33.2 | 39.5 |
| Video-LLaVA [23] | 7B | 45.3 | 38.0 | 36.2 | 39.9 |
| ShareGPT4Video [4] | 8B | 48.3 | 36.3 | 35.0 | 39.9 |
| Chat-UniVi-V1.5 [18] | 7B | 45.7 | 40.3 | 35.8 | 40.6 |
| Qwen-VL-Chat [1] | 7B | 46.9 | 38.7 | 37.8 | 41.1 |
| SliME [50] | 8B | 53.3 | 42.7 | 39.8 | 45.3 |
| Video-Ma2mba-0.7B | 0.7B | 37.4 | 35.0 | 26.8 | 33.1 |
| Video-Ma2mba-1.8B | 1.8B | 49.4 | 39.2 | 31.9 | 40.3 |
| Video-Ma2mba-3.1B | 3.1B | 57.6 | 42.7 | 35.4 | 45.2 |
🔼 This table presents a comparison of different models’ performance on video understanding tasks, categorized by video length. It shows the accuracy of various models (including the authors’ Video-Ma²mba model in three different sizes) on short, medium, and long videos using two benchmark datasets: Video-MME and LongVideoBench. The results highlight the ability of each model to handle videos of varying lengths, demonstrating the strengths and weaknesses of different architectures in processing long-form video content.
read the caption
Table 1: Performance comparison across video length categories in Video-MME and LongVideoBench benchmarks.
In-depth insights#
Long Video LLMs#
The field of Long Video LLMs is nascent yet crucial, addressing the limitations of existing Large Language Models (LLMs) when applied to long-form video understanding. Current video-LLMs struggle with the quadratic complexity of attention mechanisms, leading to prohibitive memory and computational costs for processing extended video sequences. Sparse sampling techniques and memory augmentation are insufficient, as they may lose crucial temporal information or encounter limitations in capacity. The core challenge lies in scaling to linear time and space complexity, enabling efficient handling of the vast temporal information inherent in long videos. Therefore, innovative architectural designs and algorithmic improvements are urgently needed, including exploring alternative mechanisms to the Transformer’s attention, such as State Space Models. Furthermore, efficient gradient checkpointing strategies, possibly utilizing Multi-Axis approaches are critical for managing memory during training and inference. Addressing these computational hurdles will unlock the potential for more sophisticated and accurate long-video understanding applications, leading to advancements in various fields like video summarization, question answering, and video generation.
MA-GC Efficiency#
The core idea behind MA-GC (Multi-Axis Gradient Checkpointing) is to improve memory efficiency in processing long video sequences. Standard gradient checkpointing saves activations at specific points during the forward pass, recomputing them during backpropagation. MA-GC extends this by strategically saving activations along two axes: the layer axis (as in traditional methods) and the sequence (time) axis. This is crucial because it exploits the structure of the underlying Mamba-2 model, which is different from Transformers. This bi-axial checkpointing approach significantly reduces memory footprint, enabling the processing of much longer sequences than would be feasible with standard methods. The authors demonstrate a reduction in space complexity from O(√LS) to O(S), where L is the number of layers and S is the sequence length. This linear scaling is a key advantage for long video understanding, enabling the handling of videos lasting several hours. Empirical results confirm significant memory savings, validating the theoretical analysis and highlighting MA-GC’s practical effectiveness in tackling the memory challenges inherent in processing very long video sequences.
Mamba-2 SSMs#
The core of Video-Ma²mba’s efficiency lies in its adoption of Mamba-2’s state-space models (SSMs). Unlike traditional transformer architectures with their quadratic complexity, SSMs offer linear time and space complexity, making them highly scalable for processing long video sequences. This is achieved by replacing the attention mechanism—a major contributor to the computational burden of transformers—with SSMs, which effectively model temporal dynamics through state transitions and linear updates. The structured state-space duality (SSD) further enhances this efficiency by allowing for time-varying state transitions and input-output mappings. This dynamic adaptability enables Mamba-2 to process varied video content more effectively, adapting to the nuances of different temporal structures, unlike traditional RNNs with fixed parameters. The combination of SSMs with MA-GC presents a substantial improvement in efficiency for long-form video understanding, enabling the handling of video sequences exceeding typical limitations.
Ablation Studies#
Ablation studies systematically remove components of a model to understand their individual contributions. In this context, removing the multi-axis gradient checkpointing (MA-GC) would reveal its impact on memory efficiency and computational performance. Similarly, removing the State Space Model (SSM) architecture, replacing it with the standard Transformer, would assess the crucial role of SSMs in linear scalability for long video sequences. Analyzing the impact of different frame sampling rates during training helps determine the necessary resolution for optimal results. Finally, assessing the effect of the proposed long video knowledge learning stage (stage 1.5) would illuminate its role in capturing temporal dependencies and improving overall accuracy on long-form video tasks. These ablation experiments provide crucial evidence supporting the design choices made and would demonstrate the model’s robustness and efficiency in handling long videos.
Future Works#
Future work for Video-Ma²mba could explore several avenues. Improving the efficiency of the MA-GC algorithm is crucial; while effective, further optimization could reduce computational overhead. Investigating alternative state space models beyond Mamba-2 might yield performance gains. Extending the model’s capabilities to handle diverse video types (e.g., different resolutions, frame rates, and compression methods) would enhance generalizability. A deeper exploration of the interaction schema could lead to more natural and engaging long-form video question-answering systems. Finally, rigorous benchmarking on a broader range of datasets with a wider array of video understanding tasks would solidify Video-Ma²mba’s position within the field and pinpoint areas for further improvement.
More visual insights#
More on figures

🔼 Figure 2 illustrates the Multi-Axis Gradient Checkpointing (MA-GC) method. It uses a grid structure to checkpoint activations at regular intervals along both the layer (every ’l’ layers) and sequence (every ’s’ steps) dimensions. The grid allows for selective restoration of activations only when needed during backpropagation, reducing memory usage. Arrows show the flow of forward propagation, activation restoration, and gradient propagation. The table compares MA-GC to other checkpointing methods, showing its advantages in terms of memory usage and maximum sequence length achievable with 80GB of VRAM. Peak activation memory at sequence length 16384 is also compared.
read the caption
Figure 2: Overview of MA-GC grid structure. Checkpoints are stored every l𝑙litalic_l layers and s𝑠sitalic_s steps. The blue, red, and green arrows indicate forward propagation, activation restoration, and gradient propagation, respectively. This grid design optimizes memory by selectively restoring activations as needed. The below table shows comparison of checkpointing usage, maximum sequence length on 80GB VRAM, and peak activation memory in BFloat16 at sequence length 16384.

🔼 This figure shows the three main stages of training for the Video-Ma2mba model. Stage 1 focuses on cross-modal alignment using image-text and video-text pairs to align visual and textual features. Stage 1.5 emphasizes long-video knowledge learning using the SceneWalk dataset to train the model on longer video sequences with detailed descriptions, enhancing its temporal understanding. Stage 2 involves supervised fine-tuning on a diverse video question-answering dataset to refine the model’s ability to respond accurately to various queries about video content. The figure highlights the architecture of the model at each stage, demonstrating its progression through different training phases. It also indicates the input modalities (image, video, and text) and the output (caption or detailed descriptions) at each stage.
read the caption
Figure 3: The overall summarization for the training stages of Video-Ma2mba.

🔼 This figure presents a table showing the experimental results of Video-Ma²mba on the Video Multimodal Evaluation (Video-MME) benchmark. It compares the performance of Video-Ma²mba with different model sizes (0.7B, 1.8B, and 3.1B parameters) against other state-of-the-art models on short, medium, and long video clips. The table likely displays metrics such as accuracy or F1-score, allowing for a comparison of Video-Ma²mba’s performance across various video lengths and against competing methods.
read the caption
(a) Experimental results on Video-MME

🔼 This figure presents a table showing the experimental results of Video-Ma²mba and other models on the LongVideoBench benchmark. It compares performance across different video lengths (8-15s, 15-60s, 180-600s, 900-3600s) and across different model sizes. The results are presented as scores on the LongVideoBench dataset, indicating the models’ ability to understand long-form video content.
read the caption
(b) Experimental results on LongVideoBench

🔼 Figure 4 showcases qualitative examples from the Video Multimodal Evaluation benchmark (Video-MME). It presents three example video questions, their options, the correct answer, and the prediction made by the Video-Ma2mba-3.1B model. This visualization demonstrates the model’s capacity for accurate and nuanced understanding of long-form video content within Video-MME’s diverse question types and contextual scenarios. Each example includes a series of video frames depicting the relevant portion of the video clip.
read the caption
Figure 4: Qualitative examples on Video-MME [13] with Video-Ma2mba-3.1B.
More on tables
| Model | Size | 8-15s | 15-60s | 180-600s | 900-3600s | test set | val set |
|---|---|---|---|---|---|---|---|
| GPT-4o [33] | - | 71.6 | 76.8 | 66.7 | 61.6 | 66.7 | 66.7 |
| Gemini 1.5 Pro [38] | - | 70.2 | 75.3 | 65.0 | 59.1 | 64.4 | 64.0 |
| GPT-4-Turbo [31] | - | 66.4 | 71.1 | 61.7 | 54.5 | 60.7 | 59.1 |
| VideoChat2 [21] | 7B | 38.1 | 40.5 | 33.5 | 33.6 | 35.1 | 36.0 |
| VideoLLaVA [23] | 8B | 43.1 | 44.6 | 36.4 | 34.4 | 37.6 | 39.1 |
| PLLaVA [45] | 7B | 45.3 | 47.3 | 38.5 | 35.2 | 39.2 | 40.2 |
| LLaVA-1.5 [25] | 7B | 45.0 | 47.4 | 40.1 | 37.0 | 40.4 | 40.3 |
| ShareGPT4Video [4] | 7B | 46.9 | 50.1 | 40.0 | 38.7 | 41.8 | 39.7 |
| Video-Ma2mba-0.7B | 0.7B | 43.3 | 45.4 | 33.3 | 28.5 | 34.2 | 34.0 |
| Video-Ma2mba-1.8B | 1.8B | 48.4 | 49.5 | 39.6 | 34.1 | 39.8 | 38.0 |
| Video-Ma2mba-3.1B | 3.1B | 55.4 | 55.6 | 42.4 | 38.5 | 44.2 | 43.0 |
🔼 Table 2 presents a performance comparison of Video-Ma2mba against various baseline models on three distinct video question answering benchmarks: ActivityNetQA, VideoChatGPT, and MVBench. For each benchmark, the table shows the model size (in billions of parameters) and the accuracy score achieved by each model. This allows for a direct assessment of Video-Ma2mba’s performance relative to other models, highlighting its capabilities in handling various video understanding tasks.
read the caption
Table 2: Benchmark results for ActivityNetQA, VideoChatGPT, and MVBench, comparing Video-Ma2mba and baselines.
| Model | Size | ActNet-QA Acc. | ActNet-QA Score | VCG Acc. | MVBench Acc. |
|---|---|---|---|---|---|
| GPT4V [32] | - | 57.0 | - | 4.06 | 43.5 |
| GPT-4o [33] | - | 61.9 | - | - | - |
| Gemini 1.5 Pro [38] | - | 57.5 | - | - | - |
| VideoLLaMA [47] | 7B | 12.4 | 1.1 | 2.16 | 34.1 |
| Video-ChatGPT [29] | 7B | 35.2 | 2.7 | 2.42 | 32.7 |
| MovieChat [39] | 7B | 45.7 | - | 2.67 | - |
| Chat-UniVi [18] | 7B | 46.1 | 3.2 | 2.99 | - |
| LLaMA-VID [22] | 7B | 47.4 | 3.3 | 2.89 | 41.3 |
| VideoChat2-Mistral [21] | 7B | 49.1 | 3.3 | 2.98 | 62.3 |
| ShareGPT4Video [4] | 8B | 50.8 | - | - | 51.2 |
| VideoLLaMA2 [7] | 7B | 53.0 | 3.3 | 3.13 | 54.6 |
| Video-Ma2mba-0.7B | 0.7B | 43.8 | 3.2 | 2.69 | 41.1 |
| Video-Ma2mba-1.8B | 1.8B | 50.0 | 3.1 | 2.76 | 44.4 |
| Video-Ma2mba-3.1B | 3.1B | 51.7 | 3.4 | 3.03 | 48.3 |
🔼 This table presents a comparison of memory usage (in gigabytes) for different gradient checkpointing methods applied to the Mamba-2-2.7B model across various sequence lengths. The sequence lengths are powers of 2 (from 210 to 221). The methods compared are: no checkpointing (‘GC off’), checkpointing per layer (‘GC on’), checkpointing layers in groups of the square root of the total number of layers (‘Sqrt GC’), and a multi-axis gradient checkpointing method optimized for sequence length (‘MA-GC’). The memory overhead shown for each method and sequence length represents the peak memory consumption during both the forward and backward passes, using BF16 precision, excluding the model weights and gradients themselves.
read the caption
Table 3: Memory overhead (GB) for GC methods in Mamba-2-2.7B across sequence lengths (S=2n𝑆superscript2𝑛S=2^{n}italic_S = 2 start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT). “GC off” indicates no checkpointing; “GC on” applies checkpointing per layer; “Sqrt GC” groups layers by L𝐿\sqrt{L}square-root start_ARG italic_L end_ARG; and “MA-GC” optimizes based on sequence length. Each cell show peak memory during activation and backpropagation (BF16 precision), excluding model weights and gradients.
| Method | Model | Sequence Length (S=2n) | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GC off: O(L·S) | 350M, L=48, d=1024 | 0.9 | 1.7 | 3.3 | 6.6 | 13.3 | 26.5 | 52.9 | - | - | - | - | - | - |
| 1.3B, L=48, d=2048 | 1.7 | 3.3 | 6.5 | 13.1 | 26.0 | 52.1 | - | - | - | - | - | - | - | |
| 2.7B, L=64, d=2560 | 2.7 | 5.4 | 10.7 | 21.4 | 42.6 | - | - | - | - | - | - | - | - | |
| GC on: O(L·S) | 350M, L=48, d=1024 | 0.4 | 0.7 | 1.3 | 2.7 | 5.5 | 10.9 | 21.9 | 43.7 | - | - | - | - | - |
| 1.3B, L=48, d=2048 | 0.7 | 1.4 | 2.7 | 5.5 | 10.9 | 21.8 | 43.5 | - | - | - | - | - | - | |
| 2.7B, L=64, d=2560 | 1.1 | 2.2 | 4.4 | 8.7 | 17.4 | 34.7 | 69.3 | - | - | - | - | - | - | |
| Sqrt GC: O(√L·S) | 350M, L=48, d=1024 | 0.2 | 0.4 | 0.8 | 1.6 | 3.1 | 6.2 | 12.3 | 24.6 | 49.3 | - | - | - | - |
| 1.3B, L=48, d=2048 | 0.4 | 0.8 | 1.5 | 3.1 | 6.1 | 12.1 | 24.3 | 48.5 | - | - | - | - | - | |
| 2.7B, L=64, d=2560 | 0.6 | 1.1 | 2.2 | 4.4 | 8.7 | 17.3 | 34.6 | 69.3 | - | - | - | - | - | |
| MA-GC: O(S) | 350M, L=48, d=1024 | 0.3 | 0.5 | 0.6 | 1.1 | 1.6 | 2.4 | 3.8 | 5.5 | 8.8 | 15.4 | 23.1 | 40.2 | |
| 1.3B, L=48, d=2048 | 0.5 | 0.9 | 1.2 | 2.1 | 3.7 | 4.8 | 7.4 | 11.3 | 17.7 | 30.8 | 45.8 | - | ||
| 2.7B, L=64, d=2560 | 0.7 | 1.1 | 1.8 | 2.7 | 4.2 | 6.9 | 10.5 | 17.2 | 25.9 | 42.2 | - | - | - |
🔼 This ablation study investigates the impact of frame size and the inclusion of Stage 1.5 (Long Video Knowledge Learning) on the performance of Video-Ma2mba-3.1B using the Video Multi-modal Evaluation (Video-MME) benchmark. It compares different frame sampling rates (8 frames, 16 frames, and 32 frames) and the presence or absence of Stage 1.5 training. Results show performance across short, medium, and long video lengths, providing insights into the effect of temporal context on model accuracy.
read the caption
Table 4: Ablation study on frame size and Stage 1.5 effects in Video-MME using Video-Ma2mba-3.1B.
| Tr Stage | Frame Limit | Frame Limit | Video-MME | Video-MME | Video-MME | Video-MME |
|---|---|---|---|---|---|---|
| train | infer | Short: ≤2m | Mid: 4-15m | Long: 30-60m | Overall | |
| 1/ 1.5 /2 | 16 frm | 8 frm | 49.0 | 38.7 | 33.8 | 40.5 |
| ✓ ✗ ✓ | 16 frm | 16 frm | 50.0 | 40.7 | 34.6 | 41.7 |
| ✓ ✗ ✓ | 1 fps | 8 frm | 47.7 | 37.9 | 32.2 | 39.3 |
| 1 fps | 16 frm | 50.6 | 39.4 | 33.2 | 41.1 | |
| 1 fps | 32 frm | 52.7 | 40.8 | 33.9 | 42.4 | |
| 1 fps | 1 fps | 54.4 | 41.4 | 34.4 | 43.4 | |
| ✓ ✓ ✓ | 1 fps | 8 frm | 53.3 | 39.3 | 32.2 | 41.6 |
| 1 fps | 16 frm | 55.9 | 41.3 | 33.9 | 43.7 | |
| 1 fps | 32 frm | 57.9 | 41.9 | 33.9 | 44.6 | |
| 1 fps | 1 fps | 57.6 | 42.7 | 35.4 | 45.2 |
🔼 This table details the hyperparameters used during the three training stages of the Video-Ma²mba model. It includes specifications for the input modalities (video and image in Stage 1, video in Stages 1.5 and 2), frame rates, input resolution, the number of trainable parameters in different model sizes, learning rates for the language model (LLM) and vision components, optimizer used (AdamW), global batch sizes for each stage, training epochs, warmup ratio, weight decay, gradient clipping, precision, deepspeed stages, and the gradient checkpointing method used.
read the caption
Table 6: Hyperparameters for Training Stages.
| config | Stage1 | Stage1.5 | Stage2 |
|---|---|---|---|
| input modality | Vid + Img | Video | Video |
| FPS for video | 1 FPS | 1 FPS | 1 FPS |
| input resolution | 336x336 | 336x336 | 336x336 |
| trainable params | Projector | Full Model | Full Model |
| LLM lr | 1e-3 | 4e-5 | 4e-5 |
| Vision lr | - | 4e-6 | 4e-6 |
| lr scheduler | Cosine Decay | Cosine Decay | Cosine Decay |
| optimizer | AdamW (β₁=0.9,β₂=0.95) | AdamW (β₁=0.9,β₂=0.95) | AdamW (β₁=0.9,β₂=0.95) |
| global batch size | 512 | 32 | 32 |
| train epochs | 2 | 2 | 2 |
| warmup ratio | 0.1 | 0.1 | 0.1 |
| weight decay | 0.05 | 0.05 | 0.05 |
| gradient clipping | 1.0 | 1.0 | 1.0 |
| training precision | BFloat16 | BFloat16 | BFloat16 |
| DeepSpeed stage | ZeRO-1 | ZeRO-1 | ZeRO-1 |
| GC | Multi-Axis Gradient Checkpointing | Multi-Axis Gradient Checkpointing | Multi-Axis Gradient Checkpointing |
🔼 This table presents model-specific constants used in calculating memory usage for Video-Ma²mba, a model for long video understanding. The constants are crucial for the memory optimization formula presented in the paper (Equation 12). Each constant represents the memory consumption of different parts of the model’s architecture under BFloat16 precision (except for SSM states, which use Float32 and thus count as two BFloat16 elements). The table breaks down these constants for three different sizes of the Mamba-2 model (370M, 1.3B, and 2.7B parameters), reflecting how memory usage scales with model size. It shows the memory requirements for layer-wise checkpoints (CL-ckpt), sequence-wise checkpoints (CS-ckpt), grid cells (Cgrid), and SSM states (Cstate).
read the caption
Table 7: Model-specific constants for memory estimation under BFloat16 precision. Constants reflect relative element counts, where SSM states in Float32 are equivalent to two BFloat16 elements.
| Model | $C_{L\text{-ckpt}}$ | $C_{S\text{-ckpt}}$ | $C_{\text{grid}}$ | $C_{\text{state}}$ |
|---|---|---|---|---|
| Mamba-2-370m | 1,024 | 269,056 | 6,432 | 264,448 |
| Mamba-2-1.3b | 2,048 | 537,344 | 12,608 | 528,640 |
| Mamba-2-2.7b | 2,560 | 671,488 | 15,696 | 660,736 |
🔼 This table presents a computational analysis comparing the throughput (tokens processed per second) and per-token processing time (milliseconds per token) across various gradient checkpointing methods. The experiments were conducted using the Mamba-2-2.7B model on an NVIDIA A100 GPU with 80GB of memory. Sequence lengths are denoted using the notation 2n, where n represents the exponent, indicating the number of tokens processed. The results help to demonstrate the trade-offs between memory efficiency and processing speed for different gradient checkpointing techniques.
read the caption
Table 8: Computational analysis of throughput and per-token processing time among gradient checkpointing methods. Results are measured using the Mamba-2-2.7b model on an A100 80GB GPU. The notation @bold-@@bold_@ 𝟐𝐧superscript2𝐧\mathbf{2^{n}}bold_2 start_POSTSUPERSCRIPT bold_n end_POSTSUPERSCRIPT specifies the sequence length (in tokens) used for measurement.
Full paper#